Mit der Wissensdatenbanken für Amazon Bedrockkönnen Sie Fundamentmodelle (FMs) sicher anschließen Amazonas Grundgestein zu Ihren Unternehmensdaten für Retrieval Augmented Generation (RAG). Der Zugriff auf zusätzliche Daten hilft dem Modell, relevantere, kontextspezifischere und genauere Antworten zu generieren, ohne die FMs neu zu trainieren.
In diesem Beitrag besprechen wir zwei neue Funktionen der Wissensdatenbanken für Amazon Bedrock, die speziell für Folgendes gelten RetrieveAndGenerate API: Konfigurieren der maximalen Anzahl von Ergebnissen und Erstellen benutzerdefinierter Eingabeaufforderungen mit einer Wissensdatenbank-Eingabeaufforderungsvorlage. Diese können Sie nun neben dem Suchtyp als Abfrageoptionen auswählen.
Übersicht und Vorteile neuer Funktionen
Mit der Option „Maximale Ergebnisanzahl“ haben Sie die Kontrolle über die Anzahl der Suchergebnisse, die aus dem Vektorspeicher abgerufen und zur Generierung der Antwort an das FM übergeben werden sollen. Auf diese Weise können Sie die Menge der zur Generierung bereitgestellten Hintergrundinformationen anpassen und so mehr Kontext für komplexe Fragen oder weniger für einfachere Fragen bereitstellen. Sie können bis zu 100 Ergebnisse abrufen. Diese Option trägt dazu bei, die Wahrscheinlichkeit eines relevanten Kontexts zu erhöhen, wodurch die Genauigkeit verbessert und die Halluzination der generierten Antwort verringert wird.
Mit der benutzerdefinierten Wissensdatenbank-Eingabeaufforderungsvorlage können Sie die standardmäßige Eingabeaufforderungsvorlage durch Ihre eigene ersetzen, um die Eingabeaufforderung anzupassen, die zur Antwortgenerierung an das Modell gesendet wird. Dadurch können Sie den Ton, das Ausgabeformat und das Verhalten des FM anpassen, wenn er auf die Frage eines Benutzers antwortet. Mit dieser Option können Sie die Terminologie so anpassen, dass sie besser zu Ihrer Branche oder Ihrem Fachgebiet passt (z. B. Gesundheitswesen oder Recht). Darüber hinaus können Sie benutzerdefinierte Anweisungen und Beispiele hinzufügen, die auf Ihre spezifischen Arbeitsabläufe zugeschnitten sind.
In den folgenden Abschnitten erklären wir, wie Sie diese Funktionen mit dem verwenden können AWS-Managementkonsole oder SDK.
Voraussetzungen:
Um diesen Beispielen folgen zu können, benötigen Sie eine vorhandene Wissensdatenbank. Anweisungen zum Erstellen eines solchen finden Sie unter Erstellen Sie eine Wissensbasis.
Konfigurieren Sie die maximale Anzahl von Ergebnissen über die Konsole
Um die maximale Anzahl von Ergebnissen über die Konsole zu nutzen, führen Sie die folgenden Schritte aus:
- Wählen Sie auf der Amazon Bedrock-Konsole Wissensbasen im linken Navigationsbereich.
- Wählen Sie die von Ihnen erstellte Wissensdatenbank aus.
- Auswählen Testen Sie die Wissensdatenbank.
- Wählen Sie das Konfigurationssymbol.
- Auswählen
Datenquelle synchronisieren bevor Sie mit dem Testen Ihrer Wissensdatenbank beginnen.

- Der KonfigurationenZ. Suche ArtWählen Sie einen Suchtyp basierend auf Ihrem Anwendungsfall aus.
Für diesen Beitrag verwenden wir die Hybridsuche, da sie Semantik- und Textsuche kombiniert, um eine höhere Genauigkeit zu bieten. Weitere Informationen zur Hybridsuche finden Sie unter Wissensdatenbanken für Amazon Bedrock unterstützen jetzt die Hybridsuche.
- Erweitern Sie die Funktionalität der Maximale Anzahl von Quellblöcken und legen Sie die maximale Anzahl an Ergebnissen fest.

Um den Wert der neuen Funktion zu demonstrieren, zeigen wir Beispiele, wie Sie die Genauigkeit der generierten Antwort erhöhen können. Wir verwendeten Amazon 10K-Dokument für 2023 als Quelldaten für die Erstellung der Wissensdatenbank. Wir verwenden zum Experimentieren die folgende Abfrage: „In welchem Jahr stieg der Jahresumsatz von Amazon von 245 Milliarden US-Dollar auf 434 Milliarden US-Dollar?“
Die richtige Antwort auf diese Frage lautet „Der Jahresumsatz von Amazon stieg von 245 Milliarden US-Dollar im Jahr 2019 auf 434 Milliarden US-Dollar im Jahr 2022“, basierend auf den Dokumenten in der Wissensdatenbank. Wir haben Claude v2 als FM verwendet, um die endgültige Antwort basierend auf den aus der Wissensdatenbank abgerufenen Kontextinformationen zu generieren. Als FMs der Generation werden auch Claude 3 Sonnet und Claude 3 Haiku unterstützt.
Wir haben eine weitere Abfrage ausgeführt, um den Vergleich des Abrufs mit verschiedenen Konfigurationen zu demonstrieren. Wir haben dieselbe Eingabeabfrage verwendet („In welchem Jahr stieg der Jahresumsatz von Amazon von 245 Milliarden US-Dollar auf 434 Milliarden US-Dollar?“) und die maximale Anzahl an Ergebnissen auf 5 festgelegt.
Wie im folgenden Screenshot gezeigt, lautete die generierte Antwort „Leider kann ich Ihnen bei dieser Anfrage nicht weiterhelfen.“

Als nächstes setzen wir die maximalen Ergebnisse auf 12 und stellen dieselbe Frage. Die generierte Antwort lautet: „Amazons jährlicher Umsatzanstieg von 245 Milliarden US-Dollar im Jahr 2019 auf 434 Milliarden US-Dollar im Jahr 2022.“

Wie in diesem Beispiel gezeigt, können wir basierend auf der Anzahl der abgerufenen Ergebnisse die richtige Antwort abrufen. Wenn Sie mehr über die Quellenangabe erfahren möchten, die die endgültige Ausgabe darstellt, wählen Sie Quellendetails anzeigen um die generierte Antwort basierend auf der Wissensdatenbank zu validieren.
Passen Sie mithilfe der Konsole eine Wissensdatenbank-Eingabeaufforderungsvorlage an
Sie können die Standard-Eingabeaufforderung auch je nach Anwendungsfall mit Ihrer eigenen Eingabeaufforderung anpassen. Führen Sie dazu auf der Konsole die folgenden Schritte aus:
- Wiederholen Sie die Schritte im vorherigen Abschnitt, um mit dem Testen Ihrer Wissensdatenbank zu beginnen.
- Ermöglichen Generieren Sie Antworten.

- Wählen Sie das Modell Ihrer Wahl für die Antwortgenerierung aus.
In diesem Beitrag verwenden wir das Claude v2-Modell als Beispiel. Das Modell Claude 3 Sonnet und Haiku steht ebenfalls zur Generierung zur Verfügung.
- Auswählen
Jetzt bewerben fortfahren.

Nachdem Sie das Modell ausgewählt haben, wird ein neuer Abschnitt mit dem Namen „ Vorlage für Wissensdatenbank-Eingabeaufforderungen erscheint unter Konfigurationen.
- Auswählen
Bearbeiten um mit der Anpassung der Eingabeaufforderung zu beginnen.
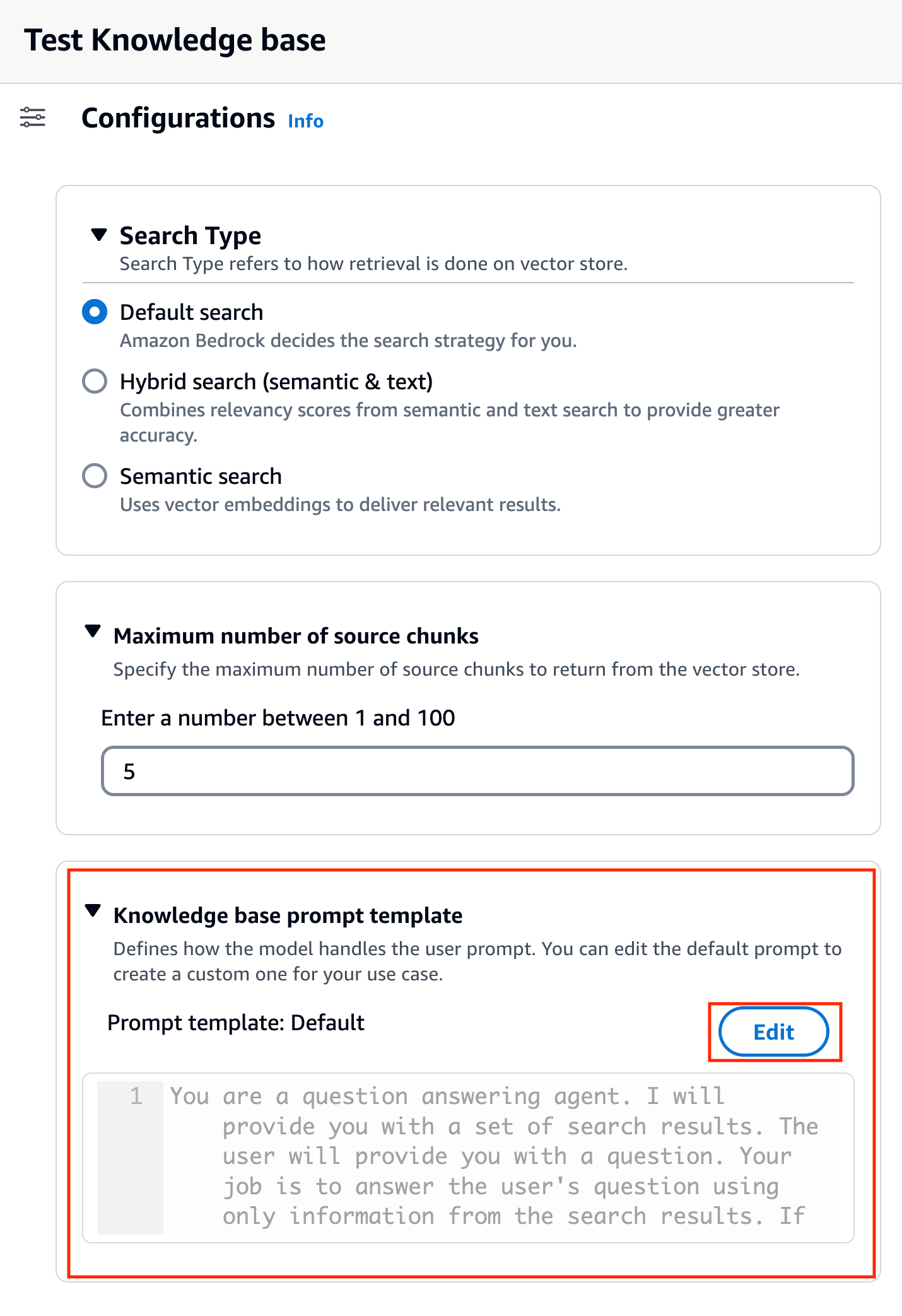
- Passen Sie die Eingabeaufforderungsvorlage an, um anzupassen, wie Sie die abgerufenen Ergebnisse verwenden und Inhalte generieren möchten.
In diesem Beitrag haben wir einige Beispiele für die Erstellung eines „Financial Advisor AI-Systems“ unter Verwendung von Amazon-Finanzberichten mit benutzerdefinierten Eingabeaufforderungen gegeben. Best Practices für Prompt Engineering finden Sie unter Schnelle technische Richtlinien.
Wir passen nun die Standard-Eingabeaufforderungsvorlage auf verschiedene Arten an und beobachten die Antworten.
Versuchen wir zunächst eine Abfrage mit der Standardeingabeaufforderung. Wir fragen: „Wie hoch war der Umsatz von Amazon in den Jahren 2019 und 2021?“ Nachfolgend sehen Sie unsere Ergebnisse.

Anhand der Ausgabe stellen wir fest, dass die Freiformantwort auf der Grundlage des abgerufenen Wissens generiert wird. Die Zitate werden ebenfalls als Referenz aufgeführt.
Nehmen wir an, wir möchten zusätzliche Anweisungen zum Formatieren der generierten Antwort geben, z. B. zur Standardisierung als JSON. Wir können diese Anweisungen als separaten Schritt nach dem Abrufen der Informationen als Teil der Eingabeaufforderungsvorlage hinzufügen:
Die endgültige Antwort hat die erforderliche Struktur.

Durch Anpassen der Eingabeaufforderung können Sie auch die Sprache der generierten Antwort ändern. Im folgenden Beispiel weisen wir das Modell an, eine Antwort auf Spanisch bereitzustellen.

Nach dem Entfernen $output_format_instructions$ Aus der Standardeingabeaufforderung wird das Zitat aus der generierten Antwort entfernt.
In den folgenden Abschnitten erklären wir, wie Sie diese Funktionen mit dem SDK nutzen können.
Konfigurieren Sie die maximale Anzahl von Ergebnissen mithilfe des SDK
Um die maximale Anzahl von Ergebnissen mit dem SDK zu ändern, verwenden Sie die folgende Syntax. In diesem Beispiel lautet die Abfrage: „In welchem Jahr stieg der Jahresumsatz von Amazon von 245 Milliarden US-Dollar auf 434 Milliarden US-Dollar?“ Die richtige Antwort lautet: „Der jährliche Umsatz von Amazon steigt von 245 Milliarden US-Dollar im Jahr 2019 auf 434 Milliarden US-Dollar im Jahr 2022.“
DienumberOfResults' Option unter 'retrievalConfiguration' ermöglicht Ihnen die Auswahl der Anzahl der Ergebnisse, die Sie abrufen möchten. Die Ausgabe der RetrieveAndGenerate Die API umfasst die generierte Antwort, die Quellenangabe und die abgerufenen Textblöcke.
Im Folgenden sind die Ergebnisse für verschiedene Werte von ' aufgeführt.numberOfResults' Parameter. Zuerst stellen wir ein numberOfResults = 5.
Dann legen wir los numberOfResults = 12.
Passen Sie die Eingabeaufforderungsvorlage für die Wissensdatenbank mit dem SDK an
Um die Eingabeaufforderung mithilfe des SDK anzupassen, verwenden wir die folgende Abfrage mit verschiedenen Eingabeaufforderungsvorlagen. In diesem Beispiel lautet die Abfrage „Wie hoch war der Umsatz von Amazon in den Jahren 2019 und 2021?“
Das Folgende ist die Standard-Eingabeaufforderungsvorlage:
Das Folgende ist die angepasste Eingabeaufforderungsvorlage:
Mit der Standard-Eingabeaufforderungsvorlage erhalten wir die folgende Antwort:
![]()
Wenn Sie zusätzliche Anweisungen rund um das Ausgabeformat der Antwortgenerierung bereitstellen möchten, z. B. die Standardisierung der Antwort in einem bestimmten Format (z. B. JSON), können Sie die vorhandene Eingabeaufforderung anpassen, indem Sie weitere Anleitungen bereitstellen. Mit unserer benutzerdefinierten Eingabeaufforderungsvorlage erhalten wir die folgende Antwort.

DiepromptTemplate' Option in 'generationConfigurationMit „ können Sie die Eingabeaufforderung anpassen, um die Antwortgenerierung besser steuern zu können.
Zusammenfassung
In diesem Beitrag haben wir zwei neue Funktionen in den Wissensdatenbanken für Amazon Bedrock vorgestellt: das Anpassen der maximalen Anzahl von Suchergebnissen und das Anpassen der Standard-Eingabeaufforderungsvorlage für RetrieveAndGenerate API. Wir haben gezeigt, wie diese Funktionen auf der Konsole und über das SDK konfiguriert werden, um die Leistung und Genauigkeit der generierten Antwort zu verbessern. Durch Erhöhen der maximalen Ergebnisse erhalten Sie umfassendere Informationen, während Sie durch Anpassen der Eingabeaufforderungsvorlage die Anweisungen für das Basismodell verfeinern können, um sie besser an bestimmte Anwendungsfälle anzupassen. Diese Verbesserungen bieten mehr Flexibilität und Kontrolle und ermöglichen Ihnen die Bereitstellung maßgeschneiderter Erlebnisse für RAG-basierte Anwendungen.
Weitere Ressourcen für die Implementierung in Ihrer AWS-Umgebung finden Sie im Folgenden:
Über die Autoren
 Sandeep Singh ist Senior Generative AI Data Scientist bei Amazon Web Services und unterstützt Unternehmen bei Innovationen mit generativer KI. Er ist spezialisiert auf generative KI, künstliche Intelligenz, maschinelles Lernen und Systemdesign. Seine Leidenschaft gilt der Entwicklung modernster KI/ML-gestützter Lösungen zur Lösung komplexer Geschäftsprobleme für verschiedene Branchen sowie der Optimierung von Effizienz und Skalierbarkeit.
Sandeep Singh ist Senior Generative AI Data Scientist bei Amazon Web Services und unterstützt Unternehmen bei Innovationen mit generativer KI. Er ist spezialisiert auf generative KI, künstliche Intelligenz, maschinelles Lernen und Systemdesign. Seine Leidenschaft gilt der Entwicklung modernster KI/ML-gestützter Lösungen zur Lösung komplexer Geschäftsprobleme für verschiedene Branchen sowie der Optimierung von Effizienz und Skalierbarkeit.
 Suyin Wang ist ein AI/ML Specialist Solutions Architect bei AWS. Sie verfügt über einen interdisziplinären Bildungshintergrund in den Bereichen maschinelles Lernen, Finanzinformationsdienste und Wirtschaft sowie jahrelange Erfahrung in der Entwicklung von Anwendungen für Datenwissenschaft und maschinelles Lernen, die reale Geschäftsprobleme lösten. Es macht ihr Spaß, Kunden dabei zu helfen, die richtigen Geschäftsfragen zu identifizieren und die richtigen KI/ML-Lösungen zu entwickeln. In ihrer Freizeit singt und kocht sie gerne.
Suyin Wang ist ein AI/ML Specialist Solutions Architect bei AWS. Sie verfügt über einen interdisziplinären Bildungshintergrund in den Bereichen maschinelles Lernen, Finanzinformationsdienste und Wirtschaft sowie jahrelange Erfahrung in der Entwicklung von Anwendungen für Datenwissenschaft und maschinelles Lernen, die reale Geschäftsprobleme lösten. Es macht ihr Spaß, Kunden dabei zu helfen, die richtigen Geschäftsfragen zu identifizieren und die richtigen KI/ML-Lösungen zu entwickeln. In ihrer Freizeit singt und kocht sie gerne.
 Sherry Ding ist ein leitender Lösungsarchitekt für künstliche Intelligenz (KI) und maschinelles Lernen (ML) bei Amazon Web Services (AWS). Sie verfügt über umfangreiche Erfahrung im maschinellen Lernen und hat einen Doktortitel in Informatik. Sie arbeitet hauptsächlich mit Kunden aus dem öffentlichen Sektor an verschiedenen geschäftlichen Herausforderungen im Zusammenhang mit KI/ML und hilft ihnen, ihre Reise zum maschinellen Lernen in der AWS Cloud zu beschleunigen. Wenn sie nicht gerade Kunden betreut, genießt sie Outdoor-Aktivitäten.
Sherry Ding ist ein leitender Lösungsarchitekt für künstliche Intelligenz (KI) und maschinelles Lernen (ML) bei Amazon Web Services (AWS). Sie verfügt über umfangreiche Erfahrung im maschinellen Lernen und hat einen Doktortitel in Informatik. Sie arbeitet hauptsächlich mit Kunden aus dem öffentlichen Sektor an verschiedenen geschäftlichen Herausforderungen im Zusammenhang mit KI/ML und hilft ihnen, ihre Reise zum maschinellen Lernen in der AWS Cloud zu beschleunigen. Wenn sie nicht gerade Kunden betreut, genießt sie Outdoor-Aktivitäten.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-custom-prompts-for-the-retrieveandgenerate-api-and-configuration-of-the-maximum-number-of-retrieved-results/

