In dieser zweiteiligen Serie demonstrieren wir, wie Modelle für 3D-Objekterkennungsaufgaben beschriftet und trainiert werden. In Teil 1 besprechen wir den von uns verwendeten Datensatz sowie alle Vorverarbeitungsschritte, um Daten zu verstehen und zu kennzeichnen. In Teil 2 zeigen wir Ihnen, wie Sie ein Modell mit Ihrem Dataset trainieren und es in der Produktion bereitstellen.
LiDAR (Light Detection and Ranging) ist eine Methode zur Bestimmung von Entfernungen, indem ein Objekt oder eine Oberfläche mit einem Laser anvisiert und die Zeit gemessen wird, die das reflektierte Licht benötigt, um zum Empfänger zurückzukehren. Unternehmen für autonome Fahrzeuge verwenden in der Regel LiDAR-Sensoren, um ein 3D-Verständnis der Umgebung um ihre Fahrzeuge herum zu generieren.
Da LiDAR-Sensoren zugänglicher und kostengünstiger werden, nutzen Kunden zunehmend Punktwolkendaten in neuen Bereichen wie Robotik, Signalkartierung und Augmented Reality. Einige neue Mobilgeräte enthalten sogar LiDAR-Sensoren. Die wachsende Verfügbarkeit von LiDAR-Sensoren hat das Interesse an Punktwolkendaten für Aufgaben des maschinellen Lernens (ML) erhöht, wie 3D-Objekterkennung und -verfolgung, 3D-Segmentierung, 3D-Objektsynthese und -rekonstruktion sowie die Verwendung von 3D-Daten zur Validierung der 2D-Tiefenschätzung.
In dieser Serie zeigen wir Ihnen, wie Sie ein Objekterkennungsmodell trainieren, das auf Punktwolkendaten läuft, um die Position von Fahrzeugen in einer 3D-Szene vorherzusagen. In diesem Beitrag konzentrieren wir uns speziell auf die Kennzeichnung von LiDAR-Daten. Die Standardausgabe des LiDAR-Sensors ist eine Folge von 3D-Punktwolkenbildern mit einer typischen Erfassungsrate von 10 Bildern pro Sekunde. Um diese Sensorausgabe zu beschriften, benötigen Sie ein Beschriftungstool, das 3D-Daten verarbeiten kann. Amazon Sagemaker Ground Truth erleichtert das Beschriften von Objekten in einem einzelnen 3D-Frame oder über eine Folge von 3D-Punktwolkenframes zum Erstellen von ML-Trainingsdatensätzen. Ground Truth unterstützt auch die Sensorfusion von Kamera- und LiDAR-Daten mit bis zu acht Videokameraeingängen.
Daten sind für jedes ML-Projekt unerlässlich. Insbesondere 3D-Daten können schwierig zu beschaffen, zu visualisieren und zu kennzeichnen sein. Wir benutzen das A2D2-Datensatz in diesem Beitrag und führen Sie durch die Schritte, um es zu visualisieren und zu beschriften.
A2D2 enthält 40,000 Frames mit semantischer Segmentierung und Punktwolken-Labels, einschließlich 12,499 Frames mit 3D-Bounding-Box-Labels. Da wir uns auf die Objekterkennung konzentrieren, interessieren uns die 12,499 Frames mit 3D-Bounding-Box-Labels. Diese Anmerkungen umfassen 14 fahrrelevante Klassen wie Auto, Fußgänger, LKW, Bus usw.
Die folgende Tabelle zeigt die vollständige Klassenliste:
| Index | Klassenliste |
| 1 | Tier |
| 2 | Fahrrad |
| 3 | Bus |
| 4 | Auto |
| 5 | Wohnwagentransporter |
| 6 | Radfahrer |
| 7 | Einsatzfahrzeug |
| 8 | Motorradfahrer |
| 9 | Motorrad |
| 10 | Fußgänger |
| 11 | Trailer |
| 12 | LKW |
| 13 | Nutzfahrzeug |
| 14 | Lieferwagen/SUV |
Wir werden unseren Detektor so trainieren, dass er speziell Autos erkennt, da dies die häufigste Klasse in unserem Datensatz ist (32616 der insgesamt 42816 Objekte im Datensatz sind als Autos gekennzeichnet).
Lösungsüberblick
In dieser Serie behandeln wir, wie Sie Ihre Daten mit Amazon SageMaker Ground Truth visualisieren und kennzeichnen und demonstrieren, wie Sie diese Daten in einem Amazon SageMaker-Schulungsauftrag verwenden, um ein Objekterkennungsmodell zu erstellen, das auf einem Amazon SageMaker-Endpunkt bereitgestellt wird. Insbesondere verwenden wir ein Amazon SageMaker-Notebook, um die Lösung zu betreiben und alle Etikettierungs- oder Schulungsaufträge zu starten.
Das folgende Diagramm zeigt den Gesamtfluss der Sensordaten von der Kennzeichnung über das Training bis zum Einsatz:

Sie erfahren, wie Sie ein Echtzeit-3D-Objekterkennungsmodell mit trainieren und bereitstellen Amazon Sage Maker Ground Truth mit den folgenden Schritten:
- Laden Sie ein Punktwolken-Dataset herunter und visualisieren Sie es
- Bereiten Sie Daten vor, die mit gekennzeichnet werden sollen Amazon SageMaker Ground Truth Punktwolken-Tool
- Starten Sie einen verteilten Amazon SageMaker Ground Truth-Trainingsauftrag mit MMDetection3D
- Werten Sie Ihre Trainingsauftragsergebnisse aus und erstellen Sie ein Profil mit Ihrer Ressourcenauslastung Amazon SageMaker-Debugger
- Stellen Sie eine asynchrone bereit SageMaker-Endpunkt
- Rufen Sie den Endpunkt auf und visualisieren Sie 3D-Objektvorhersagen
AWS-Dienste, die zum Implementieren dieser Lösung verwendet werden
Voraussetzungen:
Das folgende Diagramm zeigt, wie Sie eine private Belegschaft erstellen. Eine schriftliche Schritt-für-Schritt-Anleitung finden Sie unter Erstellen Sie eine Amazon Cognito-Belegschaft mithilfe der Seite "Beschriftungsarbeitskräfte".

Starten des AWS CloudFormation-Stacks
Nachdem Sie sich nun die Struktur der Lösung angesehen haben, stellen Sie sie in Ihrem Konto bereit, damit Sie einen Beispiel-Workflow ausführen können. Alle Bereitstellungsschritte im Zusammenhang mit der Labeling-Pipeline werden von AWS CloudFormation verwaltet. Das bedeutet, dass AWS Cloudformation Ihre Notebook-Instance sowie alle Rollen oder Amazon S3-Buckets erstellt, um die Ausführung der Lösung zu unterstützen.
Sie können den Stack in der AWS-Region starten us-east-1 auf der AWS CloudFormation-Konsole mit der Stack starten
Taste. Um den Stack in einer anderen Region zu starten, verwenden Sie die Anweisungen in der README-Datei der GitHub-Repository.
![]()

Das Erstellen aller Ressourcen dauert ungefähr 20 Minuten. Sie können den Fortschritt über die AWS CloudFormation-Benutzeroberfläche (UI) überwachen.
Sobald Ihre CloudFormation-Vorlage ausgeführt wird, kehren Sie zur AWS-Konsole zurück.
Öffnen des Notizbuchs
Amazon SageMaker Notebook-Instances sind ML-Compute-Instances, die auf der Jupyter Notebook-App ausgeführt werden. Amazon SageMaker verwaltet die Erstellung von Instanzen und zugehörigen Ressourcen. Verwenden Sie Jupyter-Notebooks in Ihrer Notebook-Instance, um Daten vorzubereiten und zu verarbeiten, Code zum Trainieren von Modellen zu schreiben, Modelle auf dem Amazon SageMaker-Hosting bereitzustellen und Ihre Modelle zu testen oder zu validieren.
Befolgen Sie die nächsten Schritte, um auf die Amazon SageMaker Notebook-Umgebung zuzugreifen:
- Suchen Sie unter Dienste nach Amazon Sage Maker.
- Der NotizbuchWählen Notebook-Instanzen.

- Eine Notebook-Instanz sollte bereitgestellt werden. Wählen Sie Öffnen aus Jupyter-Labor, das sich auf der rechten Seite der vorab bereitgestellten Notebook-Instanz unter befindet Aktionen.

- Beim Laden der Seite sehen Sie ein Symbol wie dieses:

- Sie werden zu einem neuen Browser-Tab weitergeleitet, der wie im folgenden Diagramm aussieht:
- Sobald Sie sich in der Amazon SageMaker Notebook Instance Launcher-Benutzeroberfläche befinden. Wählen Sie in der linken Seitenleiste die aus Git Symbol wie im folgenden Diagramm gezeigt.
- Auswählen Klonen Sie ein Repository .
- Geben Sie die GitHub-URL ein (https://github.com/aws-samples/end-2-end-3d-ml) im Popup-Fenster und wählen Sie aus klonen.
- Auswählen Datei-Browser um den GitHub-Ordner anzuzeigen.
- Öffnen Sie das Notizbuch mit dem Titel
1_visualization.ipynb.
Bedienung des Notebooks
Über uns
Die ersten paar Zellen des Notizbuchs im Abschnitt mit dem Titel Heruntergeladene Dateien führt durch, wie Sie den Datensatz herunterladen und die darin enthaltenen Dateien untersuchen. Nachdem die Zellen ausgeführt wurden, dauert es einige Minuten, bis der Download der Daten abgeschlossen ist.
Nach dem Herunterladen können Sie die Dateistruktur von A2D2 überprüfen, bei der es sich um eine Liste von Szenen oder Laufwerken handelt. Eine Szene ist eine kurze Aufzeichnung von Sensordaten unseres Fahrzeugs. A2D2 stellt uns 18 dieser Szenen zum Trainieren zur Verfügung, die alle durch eindeutige Daten gekennzeichnet sind. Jede Szene enthält 2D-Kameradaten, 2D-Beschriftungen, 3D-Quader-Anmerkungen und 3D-Punktwolken.
Sie können die Dateistruktur für den A2D2-Datensatz wie folgt anzeigen:
A2D2-Sensor-Setup
Im nächsten Abschnitt werden einige dieser Punktwolkendaten gelesen, um sicherzustellen, dass wir sie richtig interpretieren und im Notebook visualisieren können, bevor wir versuchen, sie in ein Format zu konvertieren, das für die Datenbeschriftung bereit ist.
Für jede Art von autonomem Fahraufbau, bei dem wir 2D- und 3D-Sensordaten haben, ist die Erfassung von Sensorkalibrierungsdaten unerlässlich. Neben den Rohdaten haben wir auch heruntergeladen cams_lidar.json. Diese Datei enthält die Verschiebung und Ausrichtung jedes Sensors relativ zum Koordinatenrahmen des Fahrzeugs, was auch als Pose oder Position des Sensors im Raum bezeichnet werden kann. Dies ist wichtig, um Punkte aus dem Koordinatensystem eines Sensors in das Koordinatensystem des Fahrzeugs umzuwandeln. Mit anderen Worten, es ist wichtig, die 2D- und 3D-Sensoren während der Fahrt zu visualisieren. Der Koordinatenrahmen des Fahrzeugs ist als statischer Punkt in der Mitte des Fahrzeugs definiert, wobei die x-Achse in Richtung der Vorwärtsbewegung des Fahrzeugs verläuft, die y-Achse links und rechts bezeichnet, wobei links positiv ist, und die z-Achse Achse, die durch das Dach des Fahrzeugs zeigt. Ein Punkt (X,Y,Z) von (5,2,1) bedeutet, dass dieser Punkt 5 Meter vor unserem Fahrzeug, 2 Meter links und 1 Meter über unserem Fahrzeug liegt. Mit diesen Kalibrierungen können wir auch 3D-Punkte auf unser 2D-Bild projizieren, was besonders hilfreich für Punktwolken-Beschriftungsaufgaben ist.
Um die Sensoreinstellung am Fahrzeug zu sehen, überprüfen Sie das folgende Diagramm.
Die Punktwolkendaten, auf denen wir trainieren, sind speziell auf die nach vorne gerichtete Kamera oder die vordere Mitte der Kamera ausgerichtet: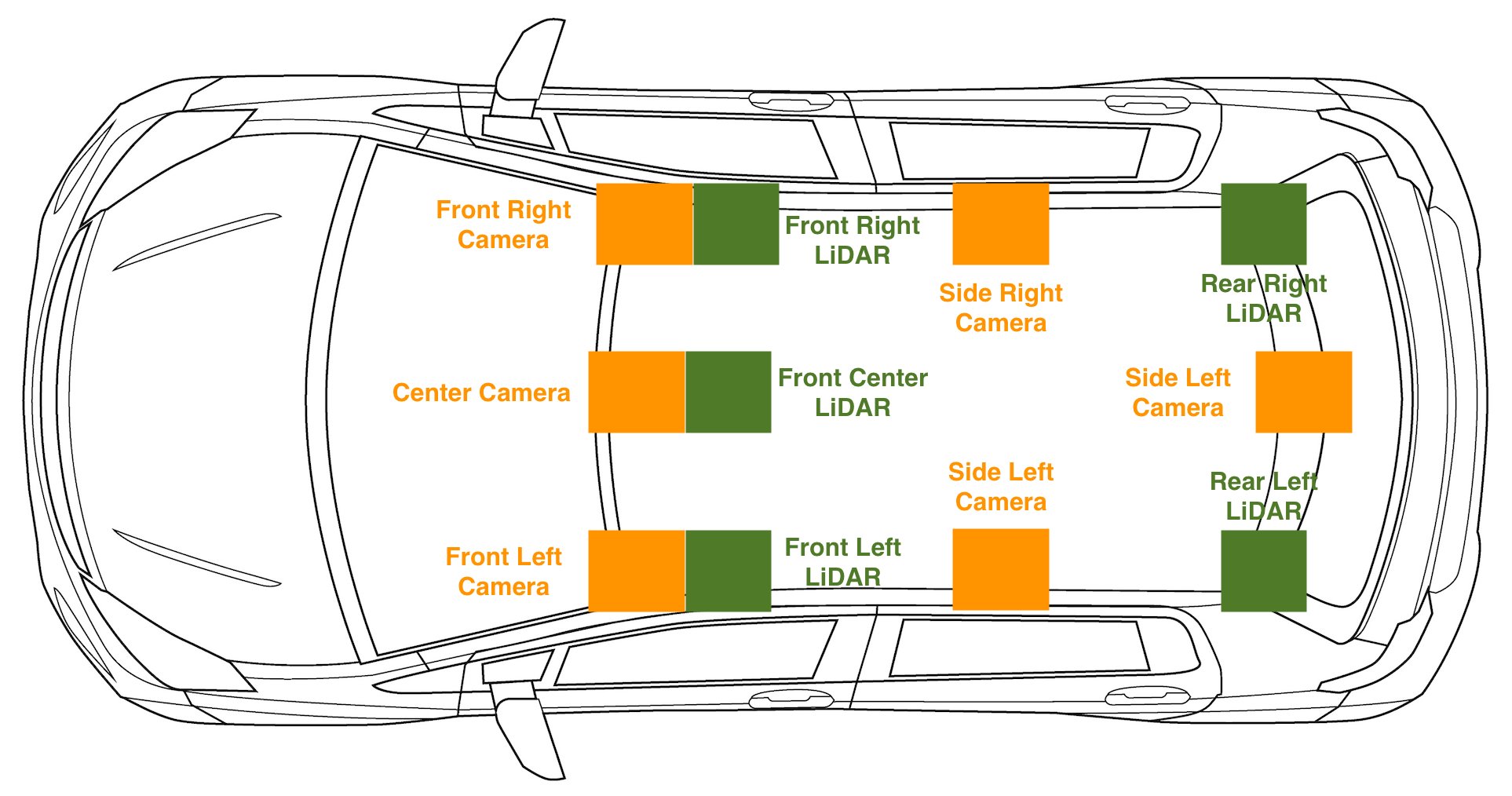
Dies entspricht unserer Visualisierung von Kamerasensoren in 3D: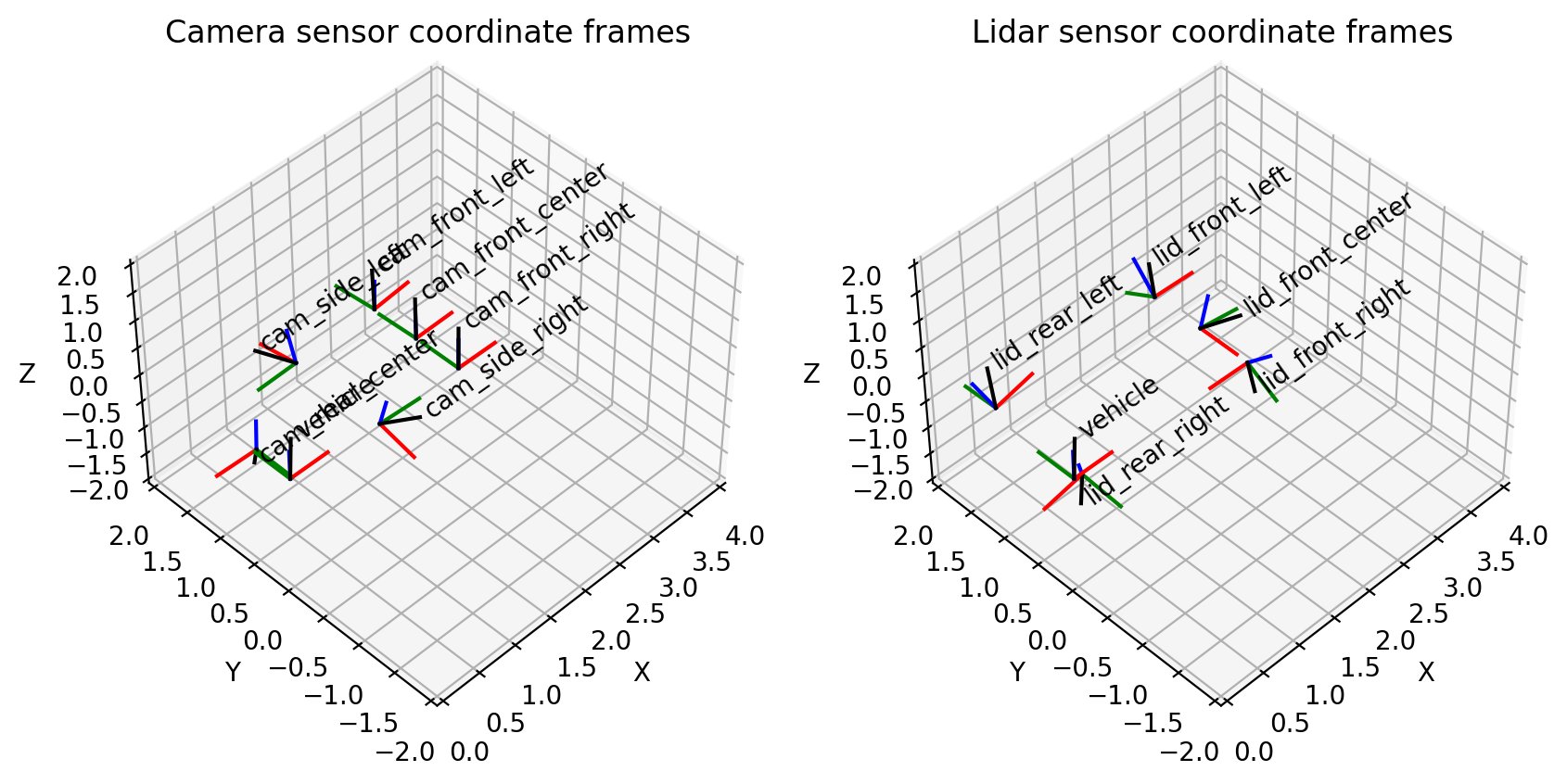
Dieser Teil des Notebooks führt durch die Validierung, dass der A2D2-Datensatz unseren Erwartungen bezüglich der Sensorpositionen entspricht und dass wir in der Lage sind, Daten von den Punktwolkensensoren am Kamerarahmen auszurichten. Fühlen Sie sich frei, alle Zellen durch die mit dem Titel zu führen Projektion von 3D auf 2D um Ihre Punktwolkendatenüberlagerung auf dem folgenden Kamerabild zu sehen.
Umstellung auf Amazon SageMaker Ground Truth

Nachdem wir unsere Daten in unserem Notebook visualisiert haben, können wir unsere Punktwolken getrost in Amazon umwandeln Das 3D-Format von SageMaker Ground Truth um unsere Etiketten zu überprüfen und anzupassen. Dieser Abschnitt führt Sie durch die Konvertierung vom Datenformat von A2D2 in ein Amazon SageMaker Ground Truth-Sequenzdatei, mit dem Eingabeformat, das von der Objektverfolgungsmodalität verwendet wird.
Das Sequenzdateiformat umfasst die Punktwolkenformate, die jeder Punktwolke zugeordneten Bilder und alle Sensorpositions- und -orientierungsdaten, die zum Ausrichten von Bildern mit Punktwolken erforderlich sind. Diese Konvertierungen werden unter Verwendung der aus dem vorherigen Abschnitt gelesenen Sensorinformationen durchgeführt. Das folgende Beispiel ist ein Sequenzdateiformat von Amazon SageMaker Ground Truth, das eine Sequenz mit nur einem einzigen Zeitschritt beschreibt.
Die Punktwolke für diesen Zeitschritt befindet sich bei s3://sagemaker-us-east-1-322552456788/a2d2_smgt/20180807_145028_out/20180807145028_lidar_frontcenter_000000091.txt und hat ein Format von <x coordinate> <y coordinate> <z coordinate>.
Der Punktwolke ist ein einzelnes Kamerabild zugeordnet, das sich bei befindet s3://sagemaker-us-east-1-322552456788/a2d2_smgt/20180807_145028_out/undistort_20180807145028_camera_frontcenter_000000091.png. Beachten Sie, dass wir die Sequenzdatei verwenden, die alle Kameraparameter definiert, um eine Projektion von der Punktwolke zur Kamera und zurück zu ermöglichen.
Die Konvertierung in dieses Eingabeformat erfordert, dass wir eine Konvertierung vom Datenformat von A2D2 in Datenformate schreiben, die von Amazon SageMaker Ground Truth unterstützt werden. Dies ist der gleiche Prozess, den jeder durchlaufen muss, wenn er seine eigenen Daten zur Etikettierung mitbringt. Wir erklären Schritt für Schritt, wie diese Konvertierung funktioniert. Wenn Sie dem Notizbuch folgen, sehen Sie sich die benannte Funktion an a2d2_scene_to_smgt_sequence_and_seq_label.
Konvertierung von Punktwolken
Der erste Schritt besteht darin, die Daten aus einer komprimierten Numpy-formatierten Datei (NPZ) zu konvertieren, die mit dem numpy.savez Methode, zu einem akzeptiertes 3D-Rohformat für Amazon SageMaker Ground Truth. Konkret generieren wir eine Datei mit einer Zeile pro Punkt. Jeder 3D-Punkt wird durch drei Fließkomma-X-, -Y- und -Z-Koordinaten definiert. Wenn wir unser Format in der Sequenzdatei angeben, verwenden wir die Zeichenfolge text/xyz um dieses Format darzustellen. Amazon SageMaker Ground Truth unterstützt auch das Hinzufügen von Intensitätswerten oder Rot-Grün-Blau-Punkten (RGB).
Die NPZ-Dateien von A2D2 enthalten mehrere Numpy-Arrays mit jeweils eigenem Namen. Um eine Konvertierung durchzuführen, laden wir die NPZ-Datei mit Numpy's Belastung -Methode auf das aufgerufene Array zugreifen Punkte (dh ein Nx3-Array, wobei N die Anzahl der Punkte in der Punktwolke ist) und unter Verwendung von Numpy als Text in einer neuen Datei speichern savetxt Methode.
Bildvorverarbeitung
Als nächstes bereiten wir unsere Bilddateien vor. A2D2 bietet PNG-Bilder und Amazon SageMaker Ground Truth unterstützt PNG-Bilder; diese Bilder sind jedoch verzerrt. Verzerrungen treten häufig auf, weil das Bildaufnahmeobjektiv nicht parallel zur Abbildungsebene ausgerichtet ist, wodurch einige Bereiche im Bild näher als erwartet erscheinen. Diese Verzerrung beschreibt den Unterschied zwischen einer physischen Kamera und einer idealisiertes Lochkameramodell. Wenn die Verzerrung nicht berücksichtigt wird, kann Amazon SageMaker Ground Truth unsere 3D-Punkte nicht über den Kameraansichten rendern, was die Durchführung der Beschriftung schwieriger macht. Ein Tutorial zur Kamerakalibrierung finden Sie in dieser Dokumentation von OpenCV.
Während Amazon SageMaker Ground Truth Verzerrungskoeffizienten in seiner Eingabedatei unterstützt, können Sie auch eine Vorverarbeitung vor dem Kennzeichnungsauftrag durchführen. Da A2D2 einen Hilfscode zum Entzerren bereitstellt, wenden wir ihn auf das Bild an und lassen die Felder, die sich auf die Verzerrung beziehen, aus unserer Sequenzdatei. Beachten Sie, dass die verzerrungsbezogenen Felder enthalten k1, k2, k3, k4, p1, p2 und Schräglage.
Kameraposition, Ausrichtung und Projektionsumwandlung
Neben den für die Beschriftung erforderlichen Rohdatendateien benötigt die Sequenzdatei auch Kamerapositions- und -orientierungsinformationen, um die Projektion von 3D-Punkten in die 2D-Kameraansichten durchzuführen. Wir müssen wissen, wohin die Kamera im 3D-Raum blickt, um herauszufinden, wie quaderförmige 3D-Etiketten und 3D-Punkte über unseren Bildern gerendert werden sollten.
Da wir unsere Sensorpositionen in einen gemeinsamen Transformationsmanager im Abschnitt A2D2-Sensoreinrichtung geladen haben, können wir den Transformationsmanager einfach nach den gewünschten Informationen abfragen. In unserem Fall behandeln wir die Fahrzeugposition in jedem Frame als (0, 0, 0), da wir keine Positionsinformationen des Sensors haben, die vom Objekterkennungsdatensatz von A2D2 bereitgestellt werden. Relativ zu unserem Fahrzeug wird also die Ausrichtung und Position der Kamera durch den folgenden Code beschrieben:
Nachdem Position und Ausrichtung konvertiert wurden, müssen wir auch Werte für fx, fy, cx und cy angeben, alles Parameter für jede Kamera im Sequenzdateiformat.
Diese Parameter beziehen sich auf Werte in der Kameramatrix. Während die Position und Ausrichtung beschreiben, in welche Richtung eine Kamera zeigt, beschreibt die Kameramatrix das Sichtfeld der Kamera und genau, wie ein 3D-Punkt relativ zur Kamera in einen 2D-Pixelort in einem Bild umgewandelt wird.
A2D2 bietet eine Kameramatrix. Im folgenden Code wird eine Referenzkameramatrix angezeigt, zusammen mit der Indizierung dieser Matrix durch unser Notebook, um die entsprechenden Felder abzurufen.
Nachdem alle Felder aus dem A2D2-Format geparst wurden, können wir die Sequenzdatei speichern und in einem Amazon verwenden SageMaker Ground Truth-Eingabemanifestdatei um einen Etikettierauftrag zu starten. Mit diesem Beschriftungsauftrag können wir Beschriftungen für 3D-Begrenzungsrahmen erstellen, die nachgelagert für das Training von 3D-Modellen verwendet werden können.
Führen Sie alle Zellen bis zum Ende des Notebooks aus und stellen Sie sicher, dass Sie die ersetzen workteam ARN mit Amazon SageMaker Ground Truth workteam ARN Sie haben eine Voraussetzung geschaffen. Nach etwa 10 Minuten Erstellungszeit für den Etikettierungsauftrag sollten Sie sich beim Worker-Portal anmelden und verwenden können Benutzeroberfläche beschriften um Ihre Szene zu visualisieren.
Aufräumen
Löschen Sie den von Ihnen bereitgestellten AWS CloudFormation-Stack mithilfe der Stack starten Schaltfläche benannt ThreeD in der AWS CloudFormation-Konsole, um alle in diesem Beitrag verwendeten Ressourcen zu entfernen, einschließlich aller laufenden Instances.
Voraussichtliche Kosten
Die ungefähren Kosten betragen $5 für 2 Stunden.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie man 3D-Daten nimmt und sie in eine Form umwandelt, die für die Beschriftung in Amazon SageMaker Ground Truth bereit ist. Mit diesen Schritten können Sie Ihre eigenen 3D-Daten zum Trainieren von Objekterkennungsmodellen kennzeichnen. Im nächsten Beitrag dieser Serie zeigen wir Ihnen, wie Sie A2D2 nehmen und ein Objektdetektormodell auf den bereits im Datensatz vorhandenen Etiketten trainieren.
Frohes Bauen!
Über die Autoren
 Isaak Privitera ist Senior Data Scientist an der Amazon Machine Learning Solutions Lab, wo er maßgeschneiderte maschinelle Lern- und Deep-Learning-Lösungen entwickelt, um die Geschäftsprobleme von Kunden anzugehen. Er arbeitet hauptsächlich im Bereich Computer Vision und konzentriert sich darauf, AWS-Kunden verteiltes Training und aktives Lernen zu ermöglichen.
Isaak Privitera ist Senior Data Scientist an der Amazon Machine Learning Solutions Lab, wo er maßgeschneiderte maschinelle Lern- und Deep-Learning-Lösungen entwickelt, um die Geschäftsprobleme von Kunden anzugehen. Er arbeitet hauptsächlich im Bereich Computer Vision und konzentriert sich darauf, AWS-Kunden verteiltes Training und aktives Lernen zu ermöglichen.
 Vidya Sagar Ravipati ist Geschäftsführer bei der Amazon Machine Learning Solutions LabHier nutzt er seine langjährige Erfahrung mit verteilten Großsystemen und seine Leidenschaft für maschinelles Lernen, um AWS-Kunden in verschiedenen Branchen dabei zu helfen, ihre KI- und Cloud-Akzeptanz zu beschleunigen. Zuvor war er ein Ingenieur für maschinelles Lernen in Connectivity Services bei Amazon, der beim Aufbau von Plattformen für Personalisierung und vorausschauende Wartung half.
Vidya Sagar Ravipati ist Geschäftsführer bei der Amazon Machine Learning Solutions LabHier nutzt er seine langjährige Erfahrung mit verteilten Großsystemen und seine Leidenschaft für maschinelles Lernen, um AWS-Kunden in verschiedenen Branchen dabei zu helfen, ihre KI- und Cloud-Akzeptanz zu beschleunigen. Zuvor war er ein Ingenieur für maschinelles Lernen in Connectivity Services bei Amazon, der beim Aufbau von Plattformen für Personalisierung und vorausschauende Wartung half.
 Jeremy Feltracco ist Softwareentwicklungsingenieur bei th Amazon Machine Learning Solutions Lab bei Amazon Webservices. Er nutzt seinen Hintergrund in Computer Vision, Robotik und maschinellem Lernen, um AWS-Kunden dabei zu helfen, ihre KI-Einführung zu beschleunigen.
Jeremy Feltracco ist Softwareentwicklungsingenieur bei th Amazon Machine Learning Solutions Lab bei Amazon Webservices. Er nutzt seinen Hintergrund in Computer Vision, Robotik und maschinellem Lernen, um AWS-Kunden dabei zu helfen, ihre KI-Einführung zu beschleunigen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/using-amazon-sagemaker-with-point-clouds-part-1-ground-truth-for-3d-labeling/

