Amazon RedShift ist ein schnelles Cloud-Data-Warehouse im Petabyte-Bereich, auf das sich Zehntausende Kunden verlassen, um ihre Analyse-Workloads zu betreiben. Tausende Kunden nutzen die Lesedatenfreigabe von Amazon Redshift, um sofortigen, granularen und schnellen Datenzugriff über von Redshift bereitgestellte Cluster und serverlose Arbeitsgruppen hinweg zu ermöglichen. Dadurch können Sie Ihre Lese-Workloads auf Tausende gleichzeitiger Benutzer skalieren, ohne die Daten verschieben oder kopieren zu müssen.
Jetzt kündigen wir bei Amazon Redshift Multi-Data-Warehouse-Schreibvorgänge durch Datenfreigabe in der öffentlichen Vorschau an. Dadurch können Sie eine bessere Leistung für ETL-Workloads (Extrahieren, Transformieren und Laden) erzielen, indem Sie basierend auf Ihren Workload-Anforderungen verschiedene Warehouses unterschiedlicher Art und Größe verwenden. Darüber hinaus können Sie Ihre ETL-Jobs auf einfache Weise vorhersehbarer ausführen, da Sie sie mit wenigen Klicks zwischen Lagern aufteilen, Kosten überwachen und kontrollieren können, da jedes Lager über eigene Überwachungs- und Kostenkontrollen verfügt, und die Zusammenarbeit fördern, da Sie verschiedene Teams einsetzen können mit nur wenigen Klicks in die Datenbanken eines anderen Teams schreiben.
Die Daten sind live und in allen Lagern verfügbar, sobald sie festgeschrieben werden, selbst wenn sie konto- oder regionsübergreifend geschrieben werden. Für die Vorschau können Sie eine Kombination aus ra3.4xl-Clustern, ra3.16xl-Clustern oder serverlosen Arbeitsgruppen verwenden.
In diesem Beitrag besprechen wir, wann Sie die Verwendung mehrerer Warehouses zum Schreiben in dieselben Datenbanken in Betracht ziehen sollten, erklären, wie Multi-Warehouse-Schreibvorgänge durch Datenfreigabe funktionieren, und führen Sie durch ein Beispiel, wie Sie mehrere Warehouses zum Schreiben in dieselbe Datenbank verwenden.
Gründe für die Verwendung mehrerer Warehouses zum Schreiben in dieselben Datenbanken
In diesem Abschnitt besprechen wir einige Gründe, warum Sie die Verwendung mehrerer Warehouses zum Schreiben in dieselbe Datenbank in Betracht ziehen sollten.
Bessere Leistung und Vorhersehbarkeit für gemischte Arbeitslasten
Kunden beginnen oft mit einem Lager, das so dimensioniert ist, dass es seinen anfänglichen Arbeitsanforderungen entspricht. Wenn Sie beispielsweise gelegentliche Benutzerabfragen und die nächtliche Aufnahme von 10 Millionen Zeilen mit Kaufdaten unterstützen müssen, ist eine 32-RPU-Arbeitsgruppe möglicherweise perfekt für Ihre Anforderungen geeignet. Das Hinzufügen einer neuen stündlichen Aufnahme von 400 Millionen Zeilen mit Website- und App-Interaktionen von Benutzern könnte jedoch die Reaktionszeiten bestehender Benutzer verlangsamen, da die neue Arbeitslast erhebliche Ressourcen verbraucht. Sie können die Größe auf eine größere Arbeitsgruppe anpassen, sodass Lese- und Schreibarbeitslasten schnell erledigt werden können, ohne sich um Ressourcen streiten zu müssen. Dies kann jedoch zu unnötigem Strom führen und Kosten für bestehende Arbeitslasten verursachen. Da sich Workloads die Rechenleistung teilen, kann sich ein Spitzenwert bei einem Workload außerdem auf die Fähigkeit anderer Workloads auswirken, ihre SLAs einzuhalten.
Das folgende Diagramm veranschaulicht eine Single-Warehouse-Architektur.
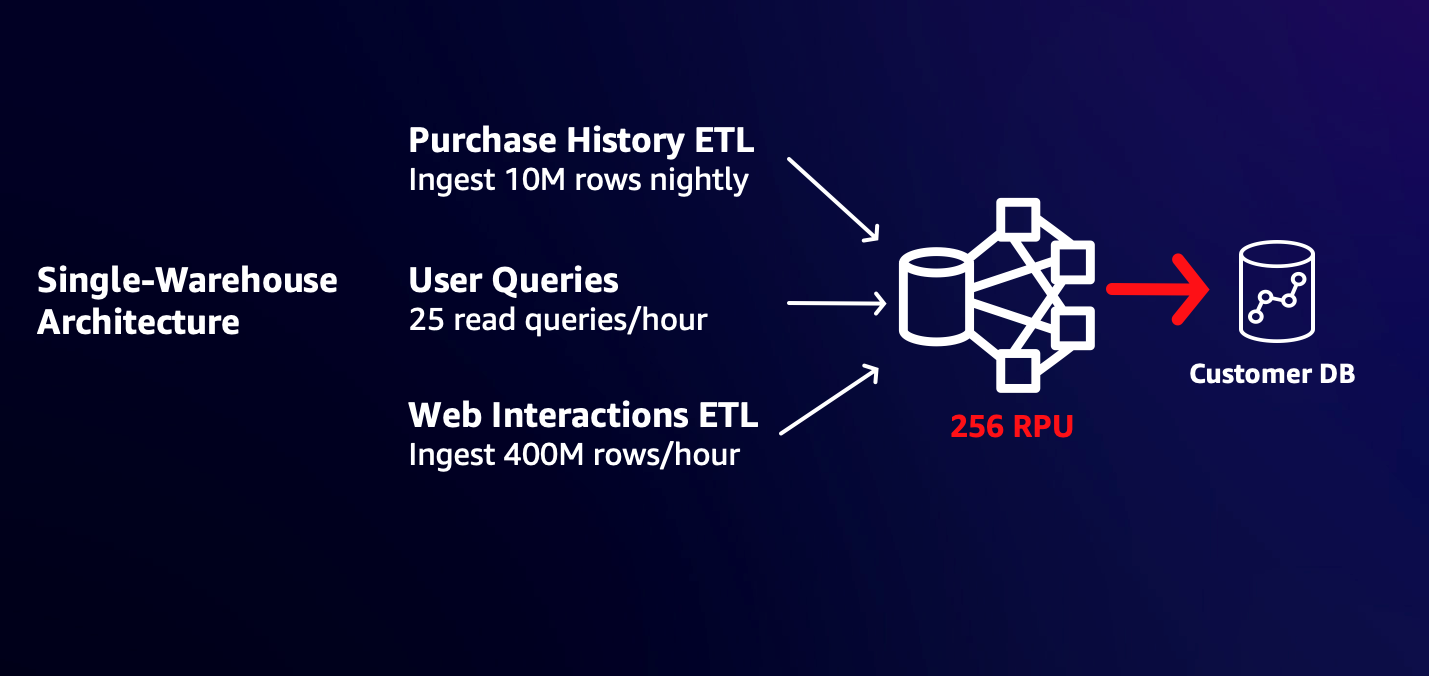
Mit der Möglichkeit, über Datenfreigaben zu schreiben, können Sie jetzt die ETL für neue Benutzerwebsites und App-Interaktionen in eine separate, größere Arbeitsgruppe aufteilen, sodass sie schnell und mit der von Ihnen benötigten Leistung abgeschlossen wird, ohne dass sich dies auf die Kosten oder die Fertigstellungszeit Ihrer vorhandenen Arbeitslasten auswirkt. Das folgende Diagramm veranschaulicht diese Multi-Warehouse-Architektur.

Die Multi-Warehouse-Architektur ermöglicht es Ihnen, alle Schreib-Workloads rechtzeitig mit weniger Rechenaufwand und damit geringeren Kosten abzuschließen als ein einzelnes Warehouse, das alle Workloads unterstützt.
Kosten kontrollieren und überwachen
Wenn Sie für alle Ihre ETL-Aufträge ein einziges Lager verwenden, kann es schwierig sein zu verstehen, welche Arbeitslasten zu Ihren Kosten beitragen. Beispielsweise kann es sein, dass ein Team einen ETL-Workload ausführt und Daten aus einem CRM-System aufnimmt, während ein anderes Team Daten aus internen Betriebssystemen aufnimmt. Es ist für Sie schwierig, die Kosten für die Workloads zu überwachen und zu kontrollieren, da Abfragen gemeinsam ausgeführt werden und dabei die gleiche Rechenleistung im Warehouse verwenden. Durch die Aufteilung der Schreib-Workloads in separate Warehouses können Sie die Kosten separat überwachen und steuern und gleichzeitig sicherstellen, dass die Workloads unabhängig voneinander und ohne Ressourcenkonflikte ablaufen können.
Arbeiten Sie problemlos an Live-Daten zusammen
Es gibt Zeiten, in denen zwei Teams aus Datenverwaltungs-, Rechenleistungs- oder Kostengründen unterschiedliche Warehouses verwenden, manchmal aber auch in dieselben gemeinsam genutzten Daten schreiben müssen. Beispielsweise verfügen Sie möglicherweise über eine Reihe von Customer 360-Tabellen, die live aktualisiert werden müssen, wenn Kunden mit Ihren Marketing-, Vertriebs- und Kundendienstteams interagieren. Wenn diese Teams unterschiedliche Warehouses verwenden, kann es schwierig sein, diese Daten aktuell zu halten, da Sie möglicherweise eine Multi-Service-ETL-Pipeline mit Tools wie erstellen müssen Amazon Simple Storage-Service (Amazon S3), Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue-Dienst (Amazon SQS), und AWS Lambda um Live-Änderungen in den Daten jedes Teams zu verfolgen und sie in einer einzigen Quelle aufzunehmen.
Mit der Möglichkeit, über Datenfreigaben zu schreiben, können Sie mit wenigen Klicks verschiedenen Teams, die unterschiedliche Warehouses verwenden, differenzierte Berechtigungen für Ihre Datenbankobjekte erteilen (z. B. SELECT für eine Tabelle und SELECT, INSERT und TRUNCATE für eine andere). Dies ermöglicht es Teams, mithilfe ihrer eigenen Warehouses mit dem Schreiben auf die gemeinsam genutzten Objekte zu beginnen. Die Daten sind live und für alle Lager verfügbar, sobald sie festgeschrieben werden. Dies funktioniert sogar, wenn die Lager unterschiedliche Konten und Regionen verwenden.
In den folgenden Abschnitten führen wir Sie durch die Verwendung mehrerer Warehouses, um über die Datenfreigabe in dieselben Datenbanken zu schreiben.
Lösungsüberblick
Wir verwenden in dieser Lösung die folgende Terminologie:
- Namespace – Ein logischer Container für Datenbankobjekte, Benutzer und Rollen, ihre Berechtigungen für Datenbankobjekte und Computing (serverlose Arbeitsgruppen und bereitgestellte Cluster).
- Datenfreigabe – Die Freigabeeinheit für die Datenfreigabe. Sie erteilen Berechtigungen für Objekte an Datenfreigaben.
- Produzent – Das Warehouse, das den Datashare erstellt, Berechtigungen für Objekte an Datashares erteilt und anderen Warehouses und Konten Zugriff auf den Datashare gewährt.
- Privatkunden – Das Warehouse, dem Zugriff auf den Datashare gewährt wird. Sie können sich Verbraucher als Datashare-Mieter vorstellen.
Bei diesem Anwendungsfall handelt es sich um einen Kunden mit zwei Warehouses: einem primären Warehouse, das für die meisten Lese- und Schreibabfragen an den primären Namespace angeschlossen wird, und einem sekundären Warehouse, das an einen sekundären Namespace angeschlossen ist und hauptsächlich zum Schreiben in den primären Namespace verwendet wird. Wir nutzen die öffentlich zugänglichen 10 GB TPCH-Datensatz von AWS Labs, gehostet in einem S3-Bucket. Sie können viele der Befehle kopieren und einfügen, um sie zu befolgen. Obwohl dieser Datensatz für ein Data Warehouse klein ist, ermöglicht er ein einfaches Funktionstesten dieser Funktion.
Das folgende Diagramm zeigt unsere Lösungsarchitektur.

Wir richten den primären Namespace ein, indem wir über sein Warehouse eine Verbindung zu ihm herstellen und darin eine Marketingdatenbank mit a erstellen prod und staging Schema und das Erstellen von drei Tabellen im prod Schema aufgerufen region, nation und af_customer. Anschließend laden wir Daten in die region und nation Tabellen über das Lager. Wir nehmen keine Daten in das auf af_customer Tabelle.
Anschließend erstellen wir einen Datashare im primären Namespace. Wir gewähren dem Datashare die Möglichkeit, Objekte im zu erstellen staging Schema und die Möglichkeit, Objekte im auszuwählen, einzufügen, zu aktualisieren und zu löschen prod Schema. Anschließend gewähren wir die Nutzung des Schemas einem anderen Namespace im Konto.
An diesem Punkt stellen wir eine Verbindung zum sekundären Lager her. Wir erstellen eine Datenbank aus einem Datashare in diesem Warehouse sowie einem neuen Benutzer. Anschließend erteilen wir dem neuen Benutzer Berechtigungen für das Datashare-Objekt. Anschließend verbinden wir uns als neuer Benutzer erneut mit dem sekundären Lager.
Anschließend erstellen wir eine Kundentabelle im Datashare staging Schema und kopieren Sie Daten aus dem TPCH 10-Kundendatensatz in die Staging-Tabelle. Wir fügen Staging-Kundentabellendaten in die Freigabe ein af_customer Produktionstabelle und kürzen Sie dann die Tabelle.
An diesem Punkt ist die ETL abgeschlossen und Sie können die Daten im primären Namespace, die vom sekundären ETL-Warehouse eingefügt wurden, sowohl aus dem primären Warehouse als auch aus dem sekundären ETL-Warehouse lesen.
Voraussetzungen:
Um diesem Beitrag folgen zu können, sollten Sie die folgenden Voraussetzungen erfüllen:
- Zwei Lagerhallen erstellt mit dem
PREVIEW_2023Schiene. Die Warehouses können eine Mischung aus serverlosen Arbeitsgruppen, ra3.4xl-Clustern und ra3.16xl-Clustern sein. - Zugang zu a Superuser in beiden Lagern.
- An AWS Identity and Access Management and (IAM)-Rolle, die Daten von Amazon Redshift in Amazon S3 aufnehmen kann (Amazon Redshift erstellt standardmäßig eine Rolle, wenn Sie einen Cluster oder eine serverlose Arbeitsgruppe erstellen).
- Nur für die kontoübergreifende Nutzung benötigen Sie Zugriff auf einen IAM-Benutzer oder eine IAM-Rolle, der bzw. die berechtigt ist, Datenfreigaben zu autorisieren. Informationen zur IAM-Richtlinie finden Sie unter Datenfreigaben teilen.
Beziehen auf Teilen von Lese- und Schreibdaten innerhalb eines AWS-Kontos oder zwischen Konten (Vorschau) Für die aktuellsten Informationen.
Richten Sie den primären Namespace (Produzent) ein.
In diesem Abschnitt zeigen wir, wie Sie den primären (Produzenten-)Namespace einrichten, den wir zum Speichern unserer Daten verwenden.
Mit dem Produzenten verbinden
Führen Sie die folgenden Schritte aus, um eine Verbindung zum Produzenten herzustellen:
- Wählen Sie in der Amazon Redshift-Konsole aus Abfrage-Editor v2 im Navigationsbereich.

Im Abfrageeditor v2 können Sie im linken Bereich alle Lager sehen, auf die Sie Zugriff haben. Sie können sie erweitern, um ihre Datenbanken anzuzeigen.
- Stellen Sie über einen Superuser eine Verbindung zu Ihrem primären Lager her.
- Führen Sie den folgenden Befehl aus, um die zu erstellen
marketingDatenbank:
Erstellen Sie die Datenbankobjekte, die Sie freigeben möchten
Führen Sie die folgenden Schritte aus, um Ihre Datenbankobjekte zur Freigabe zu erstellen:
- Nachdem Sie die erstellt haben
marketingDatenbank, wechseln Sie Ihre Datenbankverbindung zurmarketingDatenbank.
Möglicherweise müssen Sie Ihre Seite aktualisieren, um sie sehen zu können.
- Führen Sie die folgenden Befehle aus, um die beiden Schemata zu erstellen, die Sie teilen möchten:
- Erstellen Sie die Tabellen, die Sie mit dem folgenden Code teilen möchten. Dabei handelt es sich um Standard-DDL-Anweisungen, die aus der AWS Labs-DDL-Datei mit geänderten Tabellennamen stammen.
Kopieren Sie die Daten in die region und nation Tabellen
Führen Sie die folgenden Befehle aus, um Daten aus dem AWS Labs S3-Bucket in den zu kopieren region und nation Tische. Wenn Sie einen Cluster erstellt und dabei die standardmäßig erstellte IAM-Rolle beibehalten haben, können Sie die folgenden Befehle kopieren und einfügen, um Daten in Ihre Tabellen zu laden:
Erstellen Sie den Datenaustausch
Erstellen Sie den Datashare mit dem folgenden Befehl:
Das publicaccessible Die Einstellung gibt an, ob ein Datashare von Verbrauchern mit öffentlich zugänglichen bereitgestellten Clustern und serverlosen Arbeitsgruppen verwendet werden kann. Wenn Ihre Lager nicht öffentlich zugänglich sind, können Sie dieses Feld ignorieren.
Erteilen Sie dem Datashare Berechtigungen für Schemas
Um Objekte mit Berechtigungen zum Datashare hinzuzufügen, verwenden Sie die Grant-Syntax und geben Sie den Datashare an, dem Sie die Berechtigungen erteilen möchten:
Dadurch können die Datashare-Konsumenten Objekte verwenden, die dem hinzugefügt wurden prod Schema und verwenden und erstellen Sie hinzugefügte Objekte staging Schema. Um die Abwärtskompatibilität aufrechtzuerhalten, wenn Sie die verwenden alter datashare Wenn Sie den Befehl zum Hinzufügen eines Schemas verwenden, entspricht dies der Gewährung der Nutzung des Schemas.
Erteilen Sie dem Datashare Berechtigungen für Tabellen
Jetzt können Sie dem Datashare mithilfe der Grant-Syntax Zugriff auf Tabellen gewähren und dabei die Berechtigungen und das Datashare angeben. Der folgende Code gewährt alle Berechtigungen für af_customer Tabelle zum Datashare:
Um die Abwärtskompatibilität zu gewährleisten, entspricht die Verwendung des Befehls alter datashare zum Hinzufügen einer Tabelle der Gewährung einer Auswahl für die Tabelle.
Darüber hinaus haben wir bereichsbezogene Berechtigungen hinzugefügt, mit denen Sie allen aktuellen und zukünftigen Objekten innerhalb des Datashares dieselbe Berechtigung erteilen können. Wir fügen die bereichsbezogene Auswahlberechtigung hinzu Stoß Schematabellen zum Datashare:
Nach dieser Gewährung verfügt der Kunde über ausgewählte Berechtigungen für alle aktuellen und zukünftigen Tabellen im Produktschema. Dadurch erhalten sie ausgewählten Zugriff auf die region und nation Tabellen.
Berechtigungen anzeigen, die dem Datashare gewährt wurden
Sie können die dem Datashare gewährten Berechtigungen anzeigen, indem Sie den folgenden Befehl ausführen:
Erteilen Sie Berechtigungen für den sekundären ETL-Namespace
Sie können mithilfe der vorhandenen Syntax Berechtigungen für den sekundären ETL-Namespace erteilen. Dies erreichen Sie durch die Angabe der Namespace-ID. Sie finden den Namespace auf der Namespace-Detailseite, wenn Ihr sekundärer ETL-Namespace serverlos ist, als Teil der Namespace-ID auf der Cluster-Detailseite, wenn Ihr sekundärer ETL-Namespace bereitgestellt ist, oder indem Sie im Abfrageeditor v2 eine Verbindung zum sekundären ETL-Warehouse herstellen und läuft select current_namespace. Anschließend können Sie mit dem folgenden Befehl Zugriff auf den anderen Namespace gewähren (ändern Sie den Consumer-Namespace in die Namespace-UID Ihres eigenen sekundären ETL-Warehouses):
Richten Sie den sekundären ETL-Namespace (Consumer) ein.
An diesem Punkt können Sie Ihr sekundäres (Consumer-)ETL-Warehouse einrichten, um mit dem Schreiben in die freigegebenen Daten zu beginnen.
Erstellen Sie eine Datenbank aus dem Datashare
Führen Sie die folgenden Schritte aus, um Ihre Datenbank zu erstellen:
- Wechseln Sie im Abfrageeditor v2 zum sekundären ETL-Warehouse.
- Führen Sie den Befehl aus
show datasharesum den Marketing-Datashare sowie den Namespace des Datashare-Produzenten anzuzeigen. - Verwenden Sie diesen Namespace, um eine Datenbank aus dem Datashare zu erstellen, wie im folgenden Code gezeigt:
Angeben with permissions ermöglicht es Ihnen, einzelnen Datenbankbenutzern und -rollen detaillierte Berechtigungen zu erteilen. Ohne dies erhalten Benutzer und Rollen alle Berechtigungen für alle Objekte in der Datashare-Datenbank, wenn Sie Nutzungsberechtigungen für die Datashare-Datenbank erteilen.
Erstellen Sie einen Benutzer und erteilen Sie diesem Benutzer Berechtigungen
Erstellen Sie einen Benutzer mit dem BENUTZER ERSTELLEN Befehl:
Mit diesen Zuschüssen haben Sie dem Benutzer etwas gegeben data_engineer Alle Berechtigungen für alle Objekte im Datashare. Darüber hinaus haben Sie alle in den Schemas verfügbaren Berechtigungen als bereichsbezogene Berechtigungen für erteilt data_engineer. Alle Berechtigungen für alle zu diesen Schemas hinzugefügten Objekte werden automatisch erteilt data_engineer.
An diesem Punkt können Sie die Schritte entweder mit dem Administratorbenutzer, als dem Sie derzeit angemeldet sind, oder mit dem fortfahren data_engineer.
Optionen zum Schreiben in die Datashare-Datenbank
Sie können Daten auf drei Arten in die Datashare-Datenbank schreiben.
Verwenden Sie die dreiteilige Notation, während Sie mit einer lokalen Datenbank verbunden sind
Wie bei der Lesedatenfreigabe können Sie die dreiteilige Notation verwenden, um auf die Datashare-Datenbankobjekte zu verweisen. Zum Beispiel, insert into marketing_ds_db.prod.customer. Beachten Sie, dass Sie Transaktionen mit mehreren Anweisungen nicht verwenden können, um auf diese Weise in Objekte in der Datashare-Datenbank zu schreiben.
Stellen Sie eine direkte Verbindung zur Datashare-Datenbank her
Zusätzlich zur Amazon Redshift Data API (neu) können Sie über den Redshift JDBC-, ODBC- oder Python-Treiber eine direkte Verbindung zur Datashare-Datenbank herstellen. Um eine solche Verbindung herzustellen, geben Sie den Namen der Datashare-Datenbank in der Verbindungszeichenfolge an. Dadurch können Sie mit zweiteiliger Notation in die Datashare-Datenbank schreiben und Transaktionen mit mehreren Anweisungen verwenden, um in die Datashare-Datenbank zu schreiben. Beachten Sie, dass einige System- und Katalogtabellen auf diese Weise nicht verfügbar sind.
Führen Sie den Befehl use aus
Sie können nun mit dem Befehl angeben, dass Sie eine andere Datenbank verwenden möchten use <database_name>. Dadurch können Sie mit zweiteiliger Notation in die Datashare-Datenbank schreiben und Transaktionen mit mehreren Anweisungen verwenden, um in die Datashare-Datenbank zu schreiben. Beachten Sie, dass einige System- und Katalogtabellen auf diese Weise nicht verfügbar sind. Außerdem fragen Sie beim Abfragen von System- und Katalogtabellen die System- und Katalogtabellen der Datenbank ab, mit der Sie verbunden sind, und nicht die Datenbank, die Sie verwenden.
Um diese Methode auszuprobieren, führen Sie den folgenden Befehl aus:
Beginnen Sie mit dem Schreiben in die Datashare-Datenbank
In diesem Abschnitt zeigen wir, wie Sie mit der zweiten und dritten Option, die wir besprochen haben (direkte Verbindung oder Befehl verwenden), in die Datashare-Datenbank schreiben. Wir benutzen das AWS Labs stellte SQL bereit um in die Datashare-Datenbank zu schreiben.
Erstellen Sie eine Staging-Tabelle
Erstellen Sie eine Tabelle innerhalb des Staging-Schemas, da Ihnen Erstellungsberechtigungen gewährt wurden. Wir erstellen eine Tabelle innerhalb der Datenfreigabe staging Schema mit der folgenden DDL-Anweisung:
Sie können die zweiteilige Notation verwenden, da Sie den USE-Befehl verwendet oder eine direkte Verbindung zur Datashare-Datenbank hergestellt haben. Wenn nicht, müssen Sie auch die Namen der Datashare-Datenbanken angeben.
Kopieren Sie Daten in die Staging-Tabelle
Kopieren Sie die TPCH 10-Kundendaten aus dem öffentlichen S3-Bucket von AWS Labs mit dem folgenden Befehl in die Tabelle:
Dies erfordert wie zuvor, dass Sie beim Erstellen dieses Warehouses die Standard-IAM-Rolle eingerichtet haben.
Nehmen Sie afrikanische Kundendaten in die Tabelle auf prod.af_customer
Führen Sie den folgenden Befehl aus, um nur die afrikanischen Kundendaten in die Tabelle aufzunehmen prod.af_customer:
Dazu ist die Teilnahme an den Länder- und Regionstabellen erforderlich, für die Sie über die ausgewählte Berechtigung verfügen.
Staging-Tabelle kürzen
Sie können das abschneiden Aufführung Tabelle, sodass Sie darauf schreiben können, ohne sie in einem zukünftigen Job neu erstellen zu müssen. Die Truncate-Aktion wird transaktional ausgeführt und kann rückgängig gemacht werden, wenn Sie direkt mit der Datashare-Datenbank verbunden sind oder den Befehl use verwenden (auch wenn Sie keine Datashare-Datenbank verwenden). Verwenden Sie den folgenden Code:
Zu diesem Zeitpunkt haben Sie die Aufnahme der Daten in den primären Namespace abgeschlossen. Sie können die abfragen af_customer Tabelle sowohl aus dem primären Warehouse als auch aus dem sekundären ETL-Warehouse und sehen dieselben Daten.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie Sie mehrere Warehouses verwenden, um in dieselbe Datenbank zu schreiben. Diese Lösung bietet folgende Vorteile:
- Sie können bereitgestellte Cluster und serverlose Arbeitsgruppen unterschiedlicher Größe verwenden, um in dieselben Datenbanken zu schreiben
- Sie können über Konten und Regionen hinweg schreiben
- Die Daten sind live und für alle Lager verfügbar, sobald sie festgeschrieben werden
- Schreibvorgänge funktionieren auch dann, wenn das Producer-Warehouse (das Warehouse, das die Datenbank besitzt) angehalten ist
Weitere Informationen zu dieser Funktion finden Sie unter Teilen von Lese- und Schreibdaten innerhalb eines AWS-Kontos oder zwischen Konten (Vorschau). Wenn Sie außerdem Feedback haben, senden Sie uns bitte eine E-Mail an dsw-feedback@amazon.com.
Über die Autoren
 Ryan Waldorf ist Senior Product Manager bei Amazon Redshift. Ryan konzentriert sich auf Funktionen, die es Kunden ermöglichen, Rechenleistung zu definieren und zu skalieren, einschließlich Datenfreigabe und Parallelitätsskalierung.
Ryan Waldorf ist Senior Product Manager bei Amazon Redshift. Ryan konzentriert sich auf Funktionen, die es Kunden ermöglichen, Rechenleistung zu definieren und zu skalieren, einschließlich Datenfreigabe und Parallelitätsskalierung.
 Harshida Patel ist Analytics Specialist Principal Solutions Architect bei Amazon Web Services (AWS).
Harshida Patel ist Analytics Specialist Principal Solutions Architect bei Amazon Web Services (AWS).
 Sudito Das ist Senior Principal Engineer bei Amazon Web Services (AWS). Er leitet die technische Architektur und Strategie mehrerer Datenbank- und Analysedienste in AWS mit besonderem Schwerpunkt auf Amazon Redshift und Amazon Aurora.
Sudito Das ist Senior Principal Engineer bei Amazon Web Services (AWS). Er leitet die technische Architektur und Strategie mehrerer Datenbank- und Analysedienste in AWS mit besonderem Schwerpunkt auf Amazon Redshift und Amazon Aurora.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/improve-your-etl-performance-using-multiple-redshift-warehouses-for-writes/

