Kunden jeder Größe und Branche entwickeln auf AWS Innovationen, indem sie maschinelles Lernen (ML) in ihre Produkte und Dienstleistungen integrieren. Jüngste Entwicklungen bei generativen KI-Modellen haben den Bedarf an ML-Einführung in allen Branchen weiter beschleunigt. Die Implementierung von Sicherheits-, Datenschutz- und Governance-Kontrollen stellt jedoch immer noch die größten Herausforderungen für Kunden dar, wenn sie ML-Workloads in großem Maßstab implementieren. Die Bewältigung dieser Herausforderungen schafft den Rahmen und die Grundlagen für die Risikominderung und den verantwortungsvollen Einsatz von ML-gesteuerten Produkten. Obwohl für die generative KI möglicherweise zusätzliche Kontrollen erforderlich sind, wie etwa die Beseitigung von Toxizität und die Verhinderung von Jailbreaking und Halluzinationen, weist sie dieselben grundlegenden Komponenten für Sicherheit und Governance auf wie herkömmliche ML.
Wir hören von Kunden, dass sie für den Aufbau ihrer maßgeschneiderten Lösung Fachwissen und eine Investition von bis zu 12 Monaten benötigen Amazon Sage Maker Implementierung der ML-Plattform, um skalierbare, zuverlässige, sichere und kontrollierte ML-Umgebungen für ihre Geschäftsbereiche (LOBs) oder ML-Teams sicherzustellen. Wenn Ihnen ein Framework für die Steuerung des ML-Lebenszyklus im großen Maßstab fehlt, können Sie auf Herausforderungen stoßen, wie z. B. die Isolation von Ressourcen auf Teamebene, die Skalierung von Experimentierressourcen, die Operationalisierung von ML-Workflows, die Skalierung der Modell-Governance sowie die Verwaltung der Sicherheit und Compliance von ML-Workloads.
Die Steuerung des ML-Lebenszyklus im großen Maßstab ist ein Rahmenwerk, das Sie beim Aufbau einer ML-Plattform mit eingebetteten Sicherheits- und Governance-Kontrollen unterstützt, die auf branchenüblichen Best Practices und Unternehmensstandards basieren. Dieses Rahmenwerk begegnet Herausforderungen, indem es präskriptive Leitlinien durch einen modularen Rahmenansatz bietet, der eine erweitert AWS-Kontrollturm AWS-Umgebung mit mehreren Konten und der im Beitrag besprochene Ansatz Einrichten sicherer, gut verwalteter Umgebungen für maschinelles Lernen auf AWS.
Es bietet präskriptive Anleitungen für die folgenden ML-Plattformfunktionen:
- Multi-Account-, Sicherheits- und Netzwerkgrundlagen – Diese Funktion nutzt AWS Control Tower und gut durchdachte Prinzipien zum Einrichten und Betreiben von Multi-Account-Umgebungen, Sicherheits- und Netzwerkdiensten.
- Daten- und Governance-Grundlagen – Diese Funktion verwendet a Datenmaschenarchitektur für die Einrichtung und den Betrieb des Data Lake, des zentralen Feature Stores und der Daten-Governance-Grundlagen, um einen differenzierten Datenzugriff zu ermöglichen.
- Gemeinsame und Governance-Dienste der ML-Plattform – Diese Funktion ermöglicht die Einrichtung und den Betrieb allgemeiner Dienste wie CI/CD, AWS-Servicekatalog für die Bereitstellung von Umgebungen und eine zentrale Modellregistrierung für Modellförderung und -herkunft.
- ML-Teamumgebungen – Diese Funktion ermöglicht die Einrichtung und den Betrieb von Umgebungen für ML-Teams für die Modellentwicklung, das Testen und die Bereitstellung ihrer Anwendungsfälle zur Einbettung von Sicherheits- und Governance-Kontrollen.
- Beobachtbarkeit der ML-Plattform – Diese Funktion hilft bei der Fehlerbehebung und der Identifizierung der Grundursache für Probleme in ML-Modellen durch die Zentralisierung von Protokollen und die Bereitstellung von Tools zur Visualisierung der Protokollanalyse. Es bietet außerdem Anleitungen zum Erstellen von Kosten- und Nutzungsberichten für ML-Anwendungsfälle.
Obwohl dieses Framework allen Kunden Vorteile bieten kann, ist es am vorteilhaftesten für große, reife, regulierte oder globale Unternehmenskunden, die ihre ML-Strategien in einem kontrollierten, konformen und koordinierten Ansatz im gesamten Unternehmen skalieren möchten. Es trägt dazu bei, die Einführung von ML zu ermöglichen und gleichzeitig Risiken zu mindern. Dieses Framework ist für folgende Kunden nützlich:
- Große Unternehmenskunden mit vielen Branchen oder Abteilungen, die an der Nutzung von ML interessiert sind. Dieses Framework ermöglicht es verschiedenen Teams, ML-Modelle unabhängig voneinander zu erstellen und bereitzustellen und gleichzeitig eine zentrale Governance bereitzustellen.
- Unternehmenskunden mit einem mittleren bis hohen Reifegrad in ML. Sie haben bereits einige erste ML-Modelle implementiert und möchten ihre ML-Bemühungen skalieren. Dieses Framework kann dazu beitragen, die ML-Einführung im gesamten Unternehmen zu beschleunigen. Diese Unternehmen erkennen auch die Notwendigkeit einer Governance zur Verwaltung von Dingen wie Zugriffskontrolle, Datennutzung, Modellleistung und unfairer Voreingenommenheit.
- Unternehmen in regulierten Branchen wie Finanzdienstleistungen, Gesundheitswesen, Chemie und Privatsektor. Diese Unternehmen benötigen eine starke Governance und Nachvollziehbarkeit für alle ML-Modelle, die in ihren Geschäftsprozessen verwendet werden. Die Übernahme dieses Rahmenwerks kann dazu beitragen, die Einhaltung von Vorschriften zu erleichtern und gleichzeitig die Entwicklung lokaler Modelle zu ermöglichen.
- Globale Organisationen, die ein Gleichgewicht zwischen zentraler und lokaler Kontrolle herstellen müssen. Der föderierte Ansatz dieses Frameworks ermöglicht es dem zentralen Plattform-Engineering-Team, einige Richtlinien und Standards auf hoher Ebene festzulegen, gibt den LOB-Teams aber auch die Flexibilität, sich an lokale Bedürfnisse anzupassen.
Im ersten Teil dieser Serie gehen wir die Referenzarchitektur zum Aufbau der ML-Plattform durch. In einem späteren Beitrag werden wir präskriptive Anleitungen für die Implementierung der verschiedenen Module in der Referenzarchitektur in Ihrer Organisation bereitstellen.
Die Funktionen der ML-Plattform sind in vier Kategorien eingeteilt, wie in der folgenden Abbildung dargestellt. Diese Fähigkeiten bilden die Grundlage der Referenzarchitektur, die später in diesem Beitrag besprochen wird:
- Erstellen Sie ML-Grundlagen
- Skalieren Sie ML-Operationen
- Beobachtbares ML
- Sicheres ML
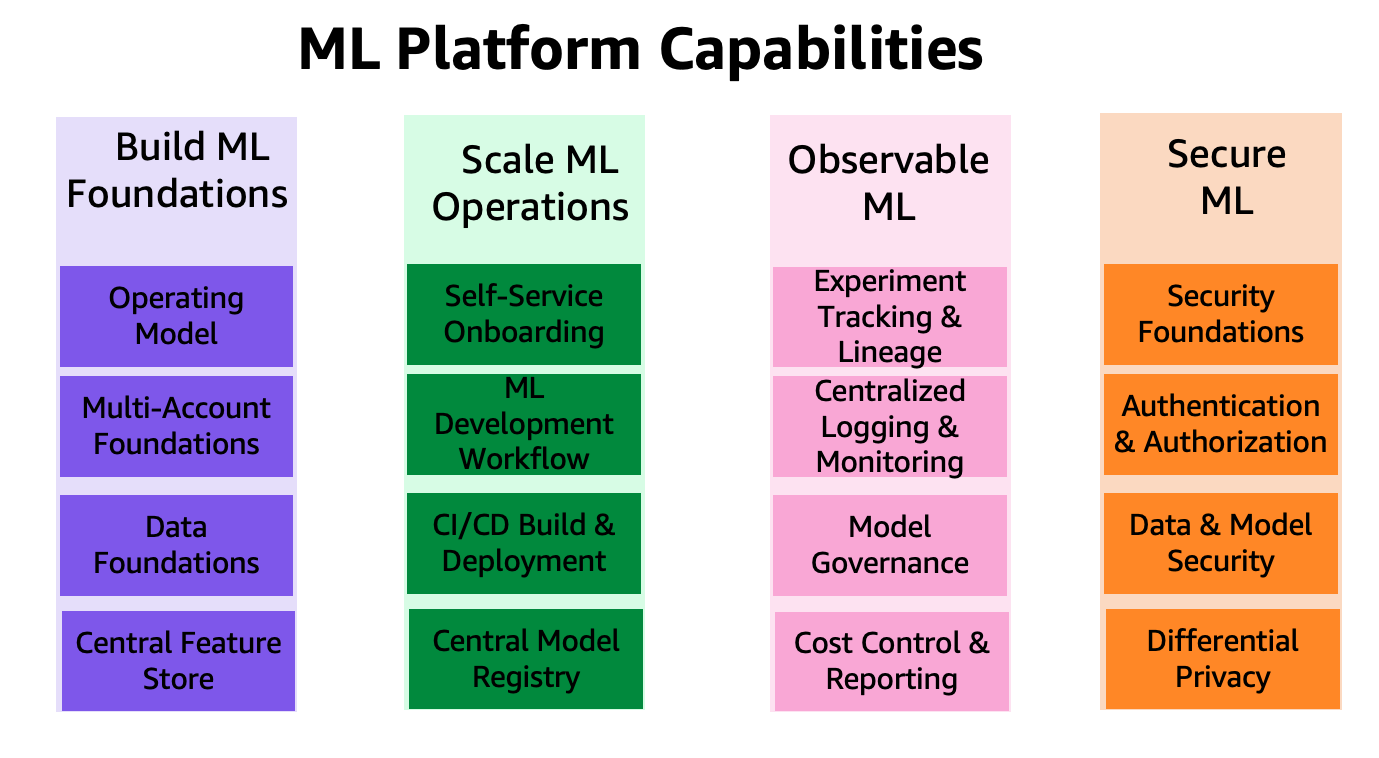
Lösungsüberblick
Das Framework zur Steuerung des ML-Lebenszyklus im großen Maßstab ermöglicht es Unternehmen, Sicherheits- und Governance-Kontrollen im gesamten ML-Lebenszyklus einzubetten, was wiederum dazu beiträgt, dass Unternehmen Risiken reduzieren und die Integration von ML in ihre Produkte und Dienstleistungen beschleunigen. Das Framework trägt dazu bei, die Einrichtung und Steuerung sicherer, skalierbarer und zuverlässiger ML-Umgebungen zu optimieren, die skaliert werden können, um eine zunehmende Anzahl von Modellen und Projekten zu unterstützen. Das Framework ermöglicht die folgenden Funktionen:
- Konto- und Infrastrukturbereitstellung mit organisationsrichtlinienkonformen Infrastrukturressourcen
- Self-Service-Bereitstellung von Data-Science-Umgebungen und End-to-End-ML-Operations-(MLOps)-Vorlagen für ML-Anwendungsfälle
- Isolierung von Ressourcen auf LOB- oder Teamebene zur Einhaltung von Sicherheits- und Datenschutzbestimmungen
- Geregelter Zugriff auf Daten in Produktionsqualität für Experimente und produktionsbereite Arbeitsabläufe
- Verwaltung und Governance für Code-Repositorys, Code-Pipelines, bereitgestellte Modelle und Datenfunktionen
- Eine Modellregistrierung und ein Feature-Store (lokale und zentrale Komponenten) zur Verbesserung der Governance
- Sicherheits- und Governance-Kontrollen für den End-to-End-Modellentwicklungs- und Bereitstellungsprozess
In diesem Abschnitt geben wir einen Überblick über präskriptive Anleitungen, die Ihnen beim Aufbau dieser ML-Plattform auf AWS mit eingebetteten Sicherheits- und Governance-Kontrollen helfen.
Die mit der ML-Plattform verbundene funktionale Architektur ist im folgenden Diagramm dargestellt. Die Architektur bildet die verschiedenen Funktionen der ML-Plattform auf AWS-Konten ab.
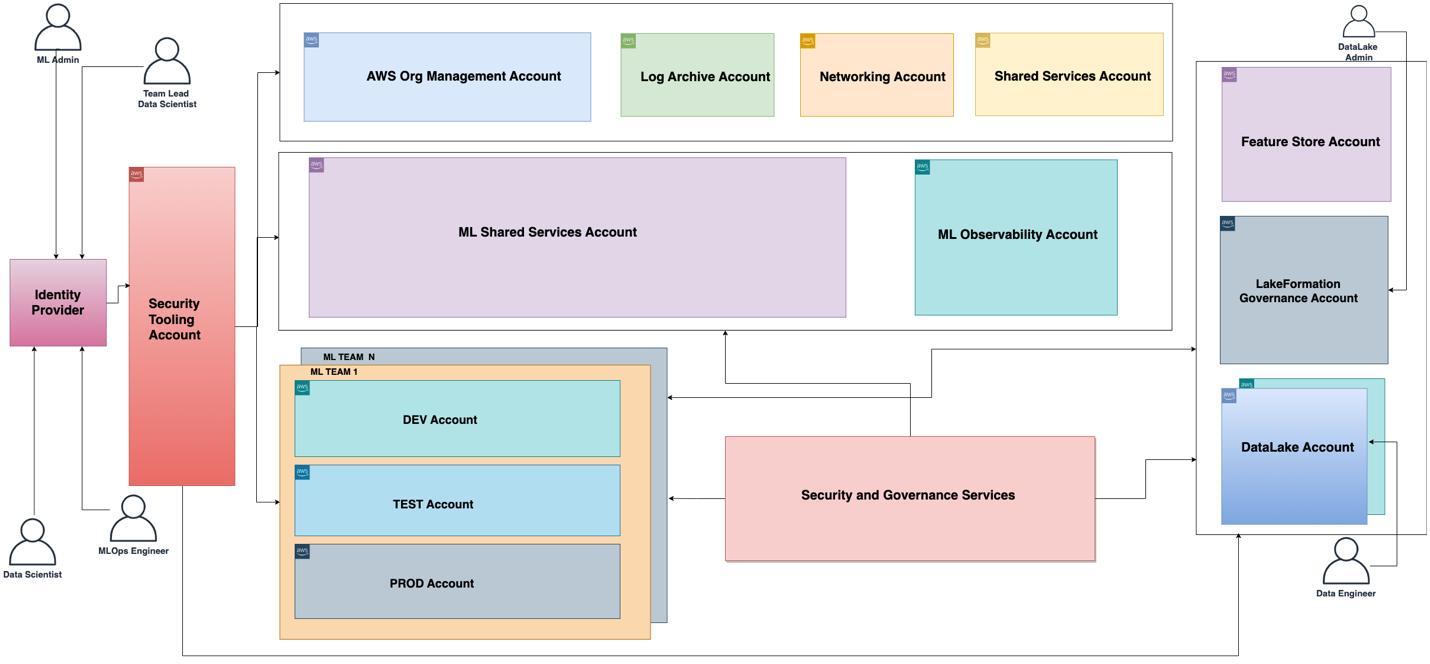
Die funktionale Architektur mit unterschiedlichen Funktionen wird mithilfe einer Reihe von AWS-Diensten implementiert, darunter AWS-Organisationen, SageMaker, AWS DevOps-Services und ein Data Lake. Die Referenzarchitektur für die ML-Plattform mit verschiedenen AWS-Diensten ist im folgenden Diagramm dargestellt.
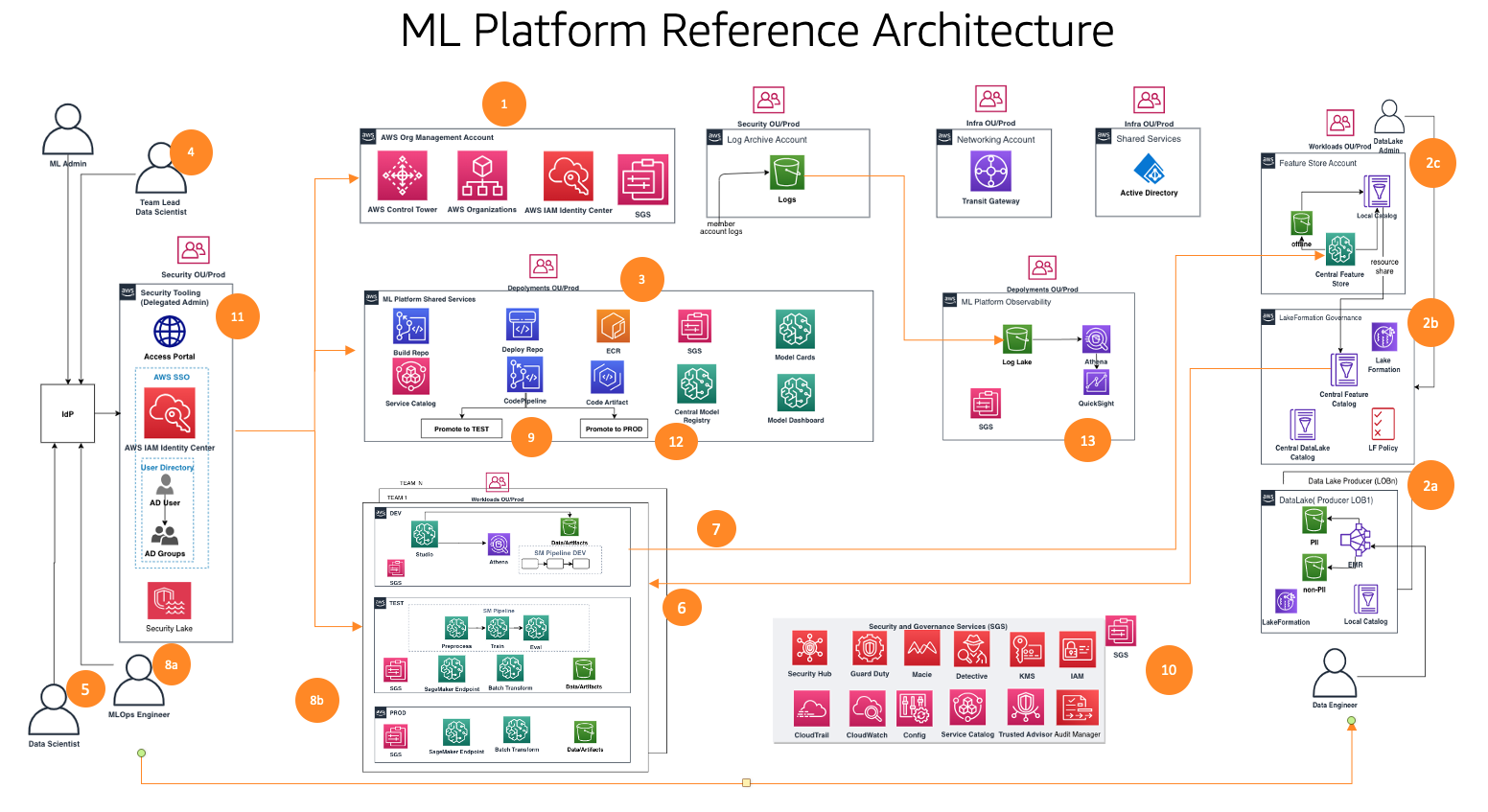
Dieses Framework berücksichtigt mehrere Personas und Dienste, um den ML-Lebenszyklus im großen Maßstab zu steuern. Wir empfehlen die folgenden Schritte zur Organisation Ihrer Teams und Dienste:
- Mithilfe von AWS Control Tower und Automatisierungstools richtet Ihr Cloud-Administrator die Multi-Account-Grundlagen wie Organisationen und ein AWS IAM Identity Center (Nachfolger von AWS Single Sign-On) und Sicherheits- und Governance-Services wie AWS-Schlüsselverwaltungsservice (AWS KMS) und Servicekatalog. Darüber hinaus richtet der Administrator verschiedene Organisationseinheiten (OUs) und Anfangskonten ein, um Ihre ML- und Analyse-Workflows zu unterstützen.
- Data-Lake-Administratoren richten Ihren Data-Lake und Datenkatalog ein und richten den zentralen Feature-Store in Zusammenarbeit mit dem ML-Plattform-Administrator ein.
- Der ML-Plattformadministrator stellt gemeinsam genutzte ML-Dienste bereit, z AWS-CodeCommit, AWS CodePipeline, Amazon Elastic Container-Registrierung (Amazon ECR), ein zentrales Modellregister, SageMaker-Modellkarten, SageMaker-Modell-Dashboardund Servicekatalogprodukte für ML-Teams.
- Der ML-Teamleiter verbindet sich über das IAM Identity Center, nutzt Service Catalog-Produkte und stellt Ressourcen in der Entwicklungsumgebung des ML-Teams bereit.
- Datenwissenschaftler aus ML-Teams verschiedener Geschäftsbereiche schließen sich in der Entwicklungsumgebung ihres Teams zusammen, um die Modellpipeline aufzubauen.
- Datenwissenschaftler suchen und beziehen Features aus dem zentralen Feature-Store-Katalog, erstellen Modelle durch Experimente und wählen das beste Modell für die Werbung aus.
- Datenwissenschaftler erstellen und teilen neue Features im zentralen Feature-Store-Katalog zur Wiederverwendung.
- Ein ML-Ingenieur stellt die Modellpipeline mithilfe eines Shared Services CI/CD-Prozesses in der Testumgebung des ML-Teams bereit.
- Nach der Stakeholder-Validierung wird das ML-Modell in der Produktionsumgebung des Teams bereitgestellt.
- Sicherheits- und Governance-Kontrollen sind mithilfe von Diensten wie z. B. in jede Schicht dieser Architektur eingebettet AWS-Sicherheits-Hub, Amazon-Wachdienst, Amazon MacieUnd vieles mehr.
- Sicherheitskontrollen werden zentral über das Sicherheitstool-Konto mithilfe von Security Hub verwaltet.
- Governance-Funktionen der ML-Plattform wie SageMaker Model Cards und SageMaker Model Dashboard werden zentral über das Governance-Services-Konto verwaltet.
- Amazon CloudWatch und AWS CloudTrail Protokolle von jedem Mitgliedskonto werden mithilfe nativer AWS-Dienste zentral über ein Observability-Konto zugänglich gemacht.
Als nächstes tauchen wir tief in die Module der Referenzarchitektur für dieses Framework ein.
Referenzarchitekturmodule
Die Referenzarchitektur besteht aus acht Modulen, die jeweils zur Lösung einer spezifischen Problemgruppe konzipiert sind. Zusammengenommen befassen sich diese Module mit der Governance in verschiedenen Dimensionen wie Infrastruktur, Daten, Modell und Kosten. Jedes Modul bietet einen eigenen Funktionsumfang und interoperiert mit anderen Modulen, um eine integrierte End-to-End-ML-Plattform mit eingebetteten Sicherheits- und Governance-Kontrollen bereitzustellen. In diesem Abschnitt präsentieren wir eine kurze Zusammenfassung der Funktionen jedes Moduls.
Stiftungen mit mehreren Konten
Dieses Modul hilft Cloud-Administratoren beim Erstellen einer Landezone des AWS Control Tower als Grundgerüst. Dazu gehören der Aufbau einer Struktur mit mehreren Konten, Authentifizierung und Autorisierung über das IAM Identity Center, ein Netzwerk-Hub-and-Spoke-Design, zentralisierte Protokollierungsdienste und neue AWS-Mitgliedskonten mit standardisierten Sicherheits- und Governance-Grundsätzen.
Darüber hinaus bietet dieses Modul Best-Practice-Anleitungen zu Organisationseinheits- und Kontostrukturen, die zur Unterstützung Ihrer ML- und Analyse-Workflows geeignet sind. Cloud-Administratoren verstehen den Zweck der erforderlichen Konten und Organisationseinheiten, wissen, wie sie bereitgestellt werden und welche wichtigen Sicherheits- und Compliance-Dienste sie zur zentralen Steuerung ihrer ML- und Analyse-Workloads nutzen sollten.
Es wird auch ein Rahmenwerk für den Verkauf neuer Konten behandelt, das die Automatisierung für die Baseline-Einstellung neuer Konten bei deren Bereitstellung nutzt. Durch die Einrichtung eines automatisierten Kontobereitstellungsprozesses können Cloud-Administratoren ML- und Analyseteams schneller die Konten bereitstellen, die sie für ihre Arbeit benötigen, ohne auf eine solide Grundlage für die Governance zu verzichten.
Data-Lake-Grundlagen
Dieses Modul hilft Data Lake-Administratoren beim Einrichten eines Data Lake, um Daten aufzunehmen, Datensätze zu kuratieren und zu verwenden AWS Lake-Formation Governance-Modell zur Verwaltung des fein abgestuften Datenzugriffs über Konten und Benutzer hinweg mithilfe eines zentralen Datenkatalogs, Datenzugriffsrichtlinien und tagbasierten Zugriffskontrollen. Sie können klein anfangen mit einem Konto für Ihre Datenplattform-Grundlagen für einen Proof of Concept oder ein paar kleine Workloads. Für die Implementierung mittlerer bis großer Produktions-Workloads empfehlen wir die Einführung einer Multi-Account-Strategie. In einer solchen Umgebung können LOBs die Rolle von Datenproduzenten und Datenkonsumenten übernehmen, indem sie unterschiedliche AWS-Konten verwenden, und die Data-Lake-Governance wird von einem zentralen, gemeinsam genutzten AWS-Konto aus betrieben. Der Datenproduzent sammelt, verarbeitet und speichert Daten aus seinem Datenbereich und überwacht und stellt die Qualität seiner Datenbestände sicher. Datenkonsumenten konsumieren die Daten vom Datenproduzenten, nachdem der zentralisierte Katalog sie über Lake Formation freigegeben hat. Der zentrale Katalog speichert und verwaltet den gemeinsamen Datenkatalog für die Datenerzeugerkonten.
ML-Plattformdienste
Dieses Modul hilft dem ML-Plattform-Engineering-Team bei der Einrichtung gemeinsamer Dienste, die von den Data-Science-Teams auf ihren Teamkonten verwendet werden. Zu den Dienstleistungen gehört ein Servicekatalog-Portfolio mit Produkten für SageMaker-Domäne Einsatz, Benutzerprofil der SageMaker-Domäne Bereitstellung, Data-Science-Modellvorlagen für die Modellerstellung und -bereitstellung. Dieses Modul verfügt über Funktionen für eine zentralisierte Modellregistrierung, Modellkarten, ein Modell-Dashboard und die CI/CD-Pipelines, die zur Orchestrierung und Automatisierung von Modellentwicklungs- und Bereitstellungsworkflows verwendet werden.
Darüber hinaus beschreibt dieses Modul, wie die erforderlichen Kontrollen und Governance implementiert werden, um personenbezogene Self-Service-Funktionen zu ermöglichen, sodass Data-Science-Teams ihre erforderliche Cloud-Infrastruktur und ML-Vorlagen unabhängig bereitstellen können.
Entwicklung von ML-Anwendungsfällen
Dieses Modul hilft LOBs und Datenwissenschaftlern, in einer Entwicklungsumgebung auf die SageMaker-Domäne ihres Teams zuzugreifen und eine Modellerstellungsvorlage zu instanziieren, um ihre Modelle zu entwickeln. In diesem Modul arbeiten Datenwissenschaftler an einer Entwicklerkontoinstanz der Vorlage, um mit den im zentralen Data Lake verfügbaren Daten zu interagieren, Features aus einem zentralen Feature-Store wiederzuverwenden und zu teilen, ML-Experimente zu erstellen und auszuführen, ihre ML-Workflows zu erstellen und zu testen, und registrieren ihre Modelle in einer Entwicklungskonto-Modellregistrierung in ihren Entwicklungsumgebungen.
Funktionen wie Experimentverfolgung, Modellerklärbarkeitsberichte, Daten- und Modellverzerrungsüberwachung und Modellregistrierung sind ebenfalls in den Vorlagen implementiert, was eine schnelle Anpassung der Lösungen an die von den Datenwissenschaftlern entwickelten Modelle ermöglicht.
ML-Operationen
Dieses Modul hilft LOBs und ML-Ingenieuren bei der Arbeit an ihren Entwicklungsinstanzen der Modellbereitstellungsvorlage. Nachdem das Kandidatenmodell registriert und genehmigt wurde, richten sie CI/CD-Pipelines ein und führen ML-Workflows in der Testumgebung des Teams aus, die das Modell in der zentralen Modellregistrierung registriert, die in einem Plattform-Shared-Services-Konto ausgeführt wird. Wenn ein Modell in der zentralen Modellregistrierung genehmigt wird, löst dies eine CI/CD-Pipeline aus, um das Modell in der Produktionsumgebung des Teams bereitzustellen.
Zentraler Feature-Store
Nachdem die ersten Modelle in der Produktion bereitgestellt wurden und mehrere Anwendungsfälle beginnen, Features zu teilen, die aus denselben Daten erstellt wurden, wird ein Feature Store unerlässlich, um die Zusammenarbeit über Anwendungsfälle hinweg sicherzustellen und doppelte Arbeit zu reduzieren. Dieses Modul hilft dem ML-Plattform-Engineering-Team beim Einrichten eines zentralen Feature-Stores, um Speicher und Governance für ML-Features bereitzustellen, die durch die ML-Anwendungsfälle erstellt wurden, und ermöglicht so die projektübergreifende Wiederverwendung von Features.
Protokollierung und Beobachtbarkeit
Dieses Modul hilft LOBs und ML-Anwendern, durch die Zentralisierung von Protokollaktivitäten wie CloudTrail, CloudWatch, VPC-Flussprotokollen und ML-Arbeitslastprotokollen Einblick in den Status von ML-Workloads in ML-Umgebungen zu erhalten. Teams können Protokolle zur Analyse filtern, abfragen und visualisieren, was auch zur Verbesserung der Sicherheitslage beitragen kann.
Kosten und Berichterstattung
Dieses Modul unterstützt verschiedene Stakeholder (Cloud-Administrator, Plattform-Administrator, Cloud-Geschäftsbüro) bei der Erstellung von Berichten und Dashboards, um die Kosten auf ML-Benutzer-, ML-Team- und ML-Produktebene aufzuschlüsseln und die Nutzung wie Anzahl der Benutzer, Instanztypen usw. zu verfolgen Endpunkte.
Kunden haben uns gebeten, Ratschläge dazu zu geben, wie viele Konten erstellt werden müssen und wie diese Konten strukturiert werden sollen. Im nächsten Abschnitt stellen wir Ihnen eine Anleitung zu dieser Kontostruktur als Referenz zur Verfügung, die Sie je nach Ihren Unternehmens-Governance-Anforderungen an Ihre Bedürfnisse anpassen können.
In diesem Abschnitt besprechen wir unsere Empfehlung zur Organisation Ihrer Kontostruktur. Wir teilen eine grundlegende Referenzkontostruktur; Wir empfehlen jedoch, dass ML- und Datenadministratoren eng mit ihrem Cloud-Administrator zusammenarbeiten, um diese Kontostruktur basierend auf den Kontrollen ihrer Organisation anzupassen.

Wir empfehlen, Konten nach Organisationseinheiten für Sicherheit, Infrastruktur, Arbeitslasten und Bereitstellungen zu organisieren. Organisieren Sie außerdem innerhalb jeder Organisationseinheit nach Nicht-Produktions- und Produktions-Organisationseinheit, da die unter ihnen bereitgestellten Konten und Arbeitslasten unterschiedliche Kontrollen haben. Als nächstes besprechen wir kurz diese Organisationseinheiten.
Sicherheits-OU
Die Konten in dieser Organisationseinheit werden vom Cloud-Administrator oder Sicherheitsteam der Organisation verwaltet, um Sicherheitsereignisse zu überwachen, zu identifizieren, zu schützen, zu erkennen und darauf zu reagieren.
Infrastruktur-OU
Die Konten in dieser Organisationseinheit werden vom Cloud-Administrator oder Netzwerkteam der Organisation verwaltet, um gemeinsam genutzte Ressourcen und Netzwerke der Infrastruktur auf Unternehmensebene zu verwalten.
Wir empfehlen die folgenden Konten unter der Infrastruktur-OU:
- Netzwerk – Richten Sie eine zentrale Netzwerkinfrastruktur ein, z AWS Transit-Gateway
- Geteilte Dienstleistungen – Richten Sie zentralisierte AD-Dienste und VPC-Endpunkte ein
Workloads-OU
Die Konten in dieser Organisationseinheit werden von den Plattformteamadministratoren der Organisation verwaltet. Wenn Sie für jedes Plattformteam unterschiedliche Kontrollen implementieren müssen, können Sie zu diesem Zweck andere OU-Ebenen verschachteln, z. B. eine OU für ML-Workloads, eine OU für Daten-Workloads usw.
Wir empfehlen die folgenden Konten unter der Arbeitslast-Organisationseinheit:
- ML-Entwicklungs-, Test- und Produktionskonten auf Teamebene – Richten Sie dies basierend auf Ihren Anforderungen an die Workload-Isolation ein
- Data-Lake-Konten – Partitionieren Sie Konten nach Ihrer Datendomäne
- Zentrales Data-Governance-Konto – Zentralisieren Sie Ihre Datenzugriffsrichtlinien
- Zentrales Feature-Store-Konto – Zentralisieren Sie Funktionen für die gemeinsame Nutzung zwischen Teams
Bereitstellungen OU
Die Konten in dieser Organisationseinheit werden von den Plattformteamadministratoren der Organisation für die Bereitstellung von Arbeitslasten und die Beobachtbarkeit verwaltet.
Wir empfehlen die folgenden Konten unter der Bereitstellungs-OU, da das ML-Plattform-Team auf dieser OU-Ebene verschiedene Kontrollsätze einrichten kann, um Bereitstellungen zu verwalten und zu steuern:
- ML-Shared-Services-Konten für Test und Produktion – Hostet Plattform-Shared-Services (CI/CD) und Modellregistrierung
- ML-Beobachtbarkeitskonten für Test und Produktion – Hostet CloudWatch-Protokolle, CloudTrail-Protokolle und andere Protokolle nach Bedarf
Als Nächstes gehen wir kurz auf Organisationskontrollen ein, die bei der Einbettung in Mitgliedskonten zur Überwachung der Infrastrukturressourcen berücksichtigt werden müssen.
AWS-Umgebungskontrollen
Eine Kontrolle ist eine Regel auf hoher Ebene, die eine fortlaufende Steuerung Ihrer gesamten AWS-Umgebung ermöglicht. Es ist in einfacher Sprache ausgedrückt. In diesem Framework verwenden wir AWS Control Tower, um die folgenden Kontrollen zu implementieren, die Ihnen bei der Verwaltung Ihrer Ressourcen und der Überwachung der Compliance über Gruppen von AWS-Konten hinweg helfen:
- Vorbeugende Kontrollen – Eine vorbeugende Kontrolle stellt sicher, dass Ihre Konten die Compliance wahren, da sie Aktionen unterbindet, die zu Richtlinienverstößen führen und mithilfe einer Service Control Policy (SCP) implementiert werden. Sie können beispielsweise eine präventive Kontrolle festlegen, die sicherstellt, dass CloudTrail in AWS-Konten oder -Regionen nicht gelöscht oder gestoppt wird.
- Detektivkontrollen – Eine detektivische Kontrolle erkennt die Nichteinhaltung von Ressourcen in Ihren Konten, wie z. B. Richtlinienverstöße, stellt über das Dashboard Warnungen bereit und wird mithilfe von implementiert AWS-Konfiguration Regeln. Sie können beispielsweise ein Detektivsteuerelement erstellen, um zu erkennen, ob öffentlicher Lesezugriff auf die aktiviert ist Amazon Simple Storage-Service (Amazon S3)-Buckets im freigegebenen Protokollarchivkonto.
- Proaktive Kontrollen – Eine proaktive Kontrolle scannt Ihre Ressourcen, bevor sie bereitgestellt werden, und stellt sicher, dass die Ressourcen dieser Kontrolle entsprechen und implementiert werden AWS CloudFormation Haken. Nicht konforme Ressourcen werden nicht bereitgestellt. Sie können beispielsweise eine proaktive Kontrolle festlegen, die prüft, ob für eine SageMaker-Notebook-Instanz kein direkter Internetzugriff zulässig ist.
Interaktionen zwischen ML-Plattformdiensten, ML-Anwendungsfällen und ML-Operationen
Verschiedene Personen wie der Leiter der Datenwissenschaft (leitender Datenwissenschaftler), der Datenwissenschaftler und der ML-Ingenieur bedienen die Module 2–6, wie im folgenden Diagramm für verschiedene Phasen der ML-Plattformdienste, der ML-Anwendungsfallentwicklung und des ML-Betriebs dargestellt zusammen mit Data-Lake-Grundlagen und dem zentralen Feature-Store.

Die folgende Tabelle fasst die Schritte der Operations-Flow-Aktivität und des Setup-Flows für verschiedene Personas zusammen. Sobald eine Persona eine ML-Aktivität als Teil des Betriebsablaufs initiiert, werden die Dienste wie in den Schritten zum Einrichtungsablauf beschrieben ausgeführt.
| Persona | Ops Flow-Aktivität – Anzahl | Ops Flow-Aktivität – Beschreibung | Setup-Flow-Schritt – Nummer | Setup-Ablaufschritt – Beschreibung |
| Leitender Data Science- oder ML-Teamleiter |
1 |
Verwendet Service Catalog im ML-Plattform-Services-Konto und stellt Folgendes bereit:
|
1-A |
|
|
1-B |
|
|||
| Daten Scientist |
2 |
Führt und verfolgt ML-Experimente in SageMaker-Notizbüchern |
2-A |
|
|
3 |
Automatisiert erfolgreiche ML-Experimente mit SageMaker-Projekten und -Pipelines |
3-A |
|
|
|
3-B |
Nachdem die SageMaker-Pipelines ausgeführt wurden, wird das Modell in der lokalen (dev) Modellregistrierung gespeichert | |||
| Leitender Datenwissenschaftler oder ML-Teamleiter |
4 |
Genehmigt das Modell in der lokalen (Dev)-Modellregistrierung |
4-A |
Modellmetadaten und Modellpaketschreibvorgänge aus der lokalen (Dev-)Modellregistrierung in die zentrale Modellregistrierung |
|
5 |
Genehmigt das Modell im zentralen Modellregister |
5-A |
Initiiert den Bereitstellungs-CI/CD-Prozess, um SageMaker-Endpunkte in der Testumgebung zu erstellen | |
|
5-B |
Schreibt die Modellinformationen und Metadaten vom lokalen (dev)-Konto in das ML-Governance-Modul (Modellkarte, Modell-Dashboard) im ML-Plattformdienstkonto | |||
| ML Ingenieur |
6 |
Testet und überwacht den SageMaker-Endpunkt in der Testumgebung nach CI/CD | . | |
|
7 |
Genehmigt die Bereitstellung für SageMaker-Endpunkte in der Produktionsumgebung |
7-A |
Initiiert den Bereitstellungs-CI/CD-Prozess, um SageMaker-Endpunkte in der Produktionsumgebung zu erstellen | |
|
8 |
Testet und überwacht den SageMaker-Endpunkt in der Testumgebung nach CI/CD | . | ||
Personas und Interaktionen mit verschiedenen Modulen der ML-Plattform
Jedes Modul richtet sich an bestimmte Zielpersonen innerhalb bestimmter Abteilungen, die das Modul am häufigsten nutzen, und gewährt ihnen primären Zugriff. Der sekundäre Zugriff ist dann anderen Abteilungen gestattet, die eine gelegentliche Nutzung der Module erfordern. Die Module sind auf die Bedürfnisse bestimmter Jobrollen oder Personas zugeschnitten, um die Funktionalität zu optimieren.
Wir besprechen folgende Teams:
- Zentrales Cloud-Engineering – Dieses Team arbeitet auf der Unternehmens-Cloud-Ebene über alle Arbeitslasten hinweg, um allgemeine Cloud-Infrastrukturdienste einzurichten, wie z. B. die Einrichtung von Netzwerken, Identitäten, Berechtigungen und Kontoverwaltung auf Unternehmensebene
- Datenplattform-Engineering – Dieses Team verwaltet Enterprise Data Lakes, Datenerfassung, Datenkuration und Datenverwaltung
- ML-Plattform-Engineering – Dieses Team ist branchenübergreifend auf der ML-Plattformebene tätig, um gemeinsame ML-Infrastrukturdienste wie die Bereitstellung der ML-Infrastruktur, die Verfolgung von Experimenten, die Modellverwaltung, die Bereitstellung und die Beobachtbarkeit bereitzustellen
In der folgenden Tabelle wird aufgeführt, welche Abteilungen gemäß den Zielpersonen des Moduls primären und sekundären Zugriff auf jedes Modul haben.
| Modulnummer | Module | Primärer Zugriff | Sekundärer Zugriff | Zielpersonas | Anzahl der Konten |
|
1 |
Stiftungen mit mehreren Konten | Zentrales Cloud-Engineering | Einzelne LOBs |
|
Wenige |
|
2 |
Data-Lake-Grundlagen | Zentrales Cloud- oder Datenplattform-Engineering | Einzelne LOBs |
|
Mehrere |
|
3 |
ML-Plattformdienste | Zentrales Cloud- oder ML-Plattform-Engineering | Einzelne LOBs |
|
Eins |
|
4 |
Entwicklung von ML-Anwendungsfällen | Einzelne LOBs | Zentrales Cloud- oder ML-Plattform-Engineering |
|
Mehrere |
|
5 |
ML-Operationen | Zentrales Cloud- oder ML-Engineering | Einzelne LOBs |
|
Mehrere |
|
6 |
Zentraler Feature-Store | Zentrale Cloud oder Datentechnik | Einzelne LOBs |
|
Eins |
|
7 |
Protokollierung und Beobachtbarkeit | Zentrales Cloud-Engineering | Einzelne LOBs |
|
Eins |
|
8 |
Kosten und Berichterstattung | Einzelne LOBs | Zentrales Plattform-Engineering |
|
Eins |
Zusammenfassung
In diesem Beitrag haben wir ein Framework für die Steuerung des ML-Lebenszyklus im großen Maßstab vorgestellt, das Sie bei der Implementierung gut strukturierter ML-Workloads mit eingebetteten Sicherheits- und Governance-Kontrollen unterstützt. Wir haben diskutiert, wie dieses Framework einen ganzheitlichen Ansatz für den Aufbau einer ML-Plattform unter Berücksichtigung von Daten-Governance, Modell-Governance und Kontrollen auf Unternehmensebene verfolgt. Wir ermutigen Sie, mit dem in diesem Beitrag vorgestellten Framework und den Konzepten zu experimentieren und Ihr Feedback zu teilen.
Über die Autoren
 Widder Vittal ist Principal ML Solutions Architect bei AWS. Er verfügt über mehr als drei Jahrzehnte Erfahrung in der Architektur und Entwicklung verteilter, Hybrid- und Cloud-Anwendungen. Seine Leidenschaft gilt der Entwicklung sicherer, skalierbarer und zuverlässiger KI/ML- und Big-Data-Lösungen, um Unternehmenskunden bei der Einführung und Optimierung der Cloud zu unterstützen und so ihre Geschäftsergebnisse zu verbessern. In seiner Freizeit fährt er Motorrad und geht mit seinem dreijährigen Schäfchen spazieren!
Widder Vittal ist Principal ML Solutions Architect bei AWS. Er verfügt über mehr als drei Jahrzehnte Erfahrung in der Architektur und Entwicklung verteilter, Hybrid- und Cloud-Anwendungen. Seine Leidenschaft gilt der Entwicklung sicherer, skalierbarer und zuverlässiger KI/ML- und Big-Data-Lösungen, um Unternehmenskunden bei der Einführung und Optimierung der Cloud zu unterstützen und so ihre Geschäftsergebnisse zu verbessern. In seiner Freizeit fährt er Motorrad und geht mit seinem dreijährigen Schäfchen spazieren!
 Sovik Kumar Nath ist ein KI/ML-Lösungsarchitekt bei AWS. Er verfügt über umfangreiche Erfahrung in der Entwicklung von End-to-End-Lösungen für maschinelles Lernen und Geschäftsanalysen in den Bereichen Finanzen, Betrieb, Marketing, Gesundheitswesen, Lieferkettenmanagement und IoT. Sovik hat Artikel veröffentlicht und hält ein Patent zur ML-Modellüberwachung. Er verfügt über einen Doppel-Master-Abschluss der University of South Florida, Universität Freiburg, Schweiz, und einen Bachelor-Abschluss des Indian Institute of Technology, Kharagpur. Außerhalb der Arbeit reist Sovik gerne, unternimmt Fährfahrten und schaut sich Filme an.
Sovik Kumar Nath ist ein KI/ML-Lösungsarchitekt bei AWS. Er verfügt über umfangreiche Erfahrung in der Entwicklung von End-to-End-Lösungen für maschinelles Lernen und Geschäftsanalysen in den Bereichen Finanzen, Betrieb, Marketing, Gesundheitswesen, Lieferkettenmanagement und IoT. Sovik hat Artikel veröffentlicht und hält ein Patent zur ML-Modellüberwachung. Er verfügt über einen Doppel-Master-Abschluss der University of South Florida, Universität Freiburg, Schweiz, und einen Bachelor-Abschluss des Indian Institute of Technology, Kharagpur. Außerhalb der Arbeit reist Sovik gerne, unternimmt Fährfahrten und schaut sich Filme an.
 Maira Ladeira Tanke ist Senior Data Specialist bei AWS. Als technische Leiterin hilft sie Kunden dabei, durch neue Technologien und innovative Lösungen schneller einen Geschäftswert zu erzielen. Maira ist seit Januar 2020 bei AWS. Zuvor war sie als Datenwissenschaftlerin in verschiedenen Branchen tätig und konzentrierte sich darauf, aus Daten einen Geschäftswert zu erzielen. In ihrer Freizeit reist Maira gerne und verbringt Zeit mit ihrer Familie an einem warmen Ort.
Maira Ladeira Tanke ist Senior Data Specialist bei AWS. Als technische Leiterin hilft sie Kunden dabei, durch neue Technologien und innovative Lösungen schneller einen Geschäftswert zu erzielen. Maira ist seit Januar 2020 bei AWS. Zuvor war sie als Datenwissenschaftlerin in verschiedenen Branchen tätig und konzentrierte sich darauf, aus Daten einen Geschäftswert zu erzielen. In ihrer Freizeit reist Maira gerne und verbringt Zeit mit ihrer Familie an einem warmen Ort.
 Ryan Lempka ist Senior Solutions Architect bei Amazon Web Services, wo er seinen Kunden hilft, ausgehend von den Geschäftszielen rückwärts zu arbeiten und Lösungen auf AWS zu entwickeln. Er verfügt über umfassende Erfahrung in den Bereichen Geschäftsstrategie, IT-Systemmanagement und Datenwissenschaft. Ryan ist bestrebt, lebenslang zu lernen und genießt es, sich jeden Tag selbst herauszufordern, etwas Neues zu lernen.
Ryan Lempka ist Senior Solutions Architect bei Amazon Web Services, wo er seinen Kunden hilft, ausgehend von den Geschäftszielen rückwärts zu arbeiten und Lösungen auf AWS zu entwickeln. Er verfügt über umfassende Erfahrung in den Bereichen Geschäftsstrategie, IT-Systemmanagement und Datenwissenschaft. Ryan ist bestrebt, lebenslang zu lernen und genießt es, sich jeden Tag selbst herauszufordern, etwas Neues zu lernen.
 Sriharsh Adari ist Senior Solutions Architect bei Amazon Web Services (AWS), wo er Kunden hilft, ausgehend von Geschäftsergebnissen rückwärts zu arbeiten, um innovative Lösungen auf AWS zu entwickeln. Im Laufe der Jahre hat er mehreren Kunden bei der Transformation von Datenplattformen in allen Branchen geholfen. Zu seinen Kernkompetenzen gehören Technologiestrategie, Datenanalyse und Datenwissenschaft. In seiner Freizeit treibt er gerne Sport, schaut sich Serien an und spielt Tabla.
Sriharsh Adari ist Senior Solutions Architect bei Amazon Web Services (AWS), wo er Kunden hilft, ausgehend von Geschäftsergebnissen rückwärts zu arbeiten, um innovative Lösungen auf AWS zu entwickeln. Im Laufe der Jahre hat er mehreren Kunden bei der Transformation von Datenplattformen in allen Branchen geholfen. Zu seinen Kernkompetenzen gehören Technologiestrategie, Datenanalyse und Datenwissenschaft. In seiner Freizeit treibt er gerne Sport, schaut sich Serien an und spielt Tabla.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/governing-the-ml-lifecycle-at-scale-part-1-a-framework-for-architecting-ml-workloads-using-amazon-sagemaker/

