In diesem Beitrag zeigen wir, wie man mithilfe der auf der neuronalen Architektursuche (NAS) basierenden Strukturbereinigung ein fein abgestimmtes BERT-Modell komprimiert, um die Modellleistung zu verbessern und die Inferenzzeiten zu verkürzen. Vorab trainierte Sprachmodelle (PLMs) werden in den Bereichen Produktivitätstools, Kundenservice, Suche und Empfehlungen, Geschäftsprozessautomatisierung und Inhaltserstellung schnell kommerziell und unternehmensweit übernommen. Der Einsatz von PLM-Inferenzendpunkten ist aufgrund der Rechenanforderungen in der Regel mit höherer Latenz und höheren Infrastrukturkosten sowie aufgrund der großen Anzahl von Parametern mit einer verringerten Recheneffizienz verbunden. Das Bereinigen eines PLM reduziert die Größe und Komplexität des Modells, während seine Vorhersagefähigkeiten erhalten bleiben. Bereinigte PLMs erzielen einen geringeren Speicherbedarf und eine geringere Latenz. Wir zeigen, dass wir durch die Bereinigung eines PLM und den Kompromiss zwischen Parameteranzahl und Validierungsfehlern für eine bestimmte Zielaufgabe schnellere Reaktionszeiten im Vergleich zum Basis-PLM-Modell erzielen können.
Bei der Optimierung mit mehreren Zielen handelt es sich um einen Bereich der Entscheidungsfindung, der mehr als eine Zielfunktion optimiert, beispielsweise den Speicherverbrauch, die Trainingszeit und die Rechenressourcen, die gleichzeitig optimiert werden sollen. Strukturelles Bereinigen ist eine Technik zur Reduzierung der Größe und des Rechenaufwands von PLM durch Beschneiden von Schichten oder Neuronen/Knoten unter gleichzeitiger Wahrung der Modellgenauigkeit. Durch das Entfernen von Schichten werden durch Strukturbereinigung höhere Komprimierungsraten erreicht, was zu einer hardwarefreundlichen strukturierten Sparsität führt, die Laufzeiten und Antwortzeiten reduziert. Die Anwendung einer Strukturbereinigungstechnik auf ein PLM-Modell führt zu einem leichteren Modell mit einem geringeren Speicherbedarf, das, wenn es als Inferenzendpunkt in SageMaker gehostet wird, im Vergleich zum ursprünglich fein abgestimmten PLM eine verbesserte Ressourceneffizienz und geringere Kosten bietet.
Die in diesem Beitrag dargestellten Konzepte können auf Anwendungen angewendet werden, die PLM-Funktionen verwenden, wie z. B. Empfehlungssysteme, Stimmungsanalysen und Suchmaschinen. Sie können diesen Ansatz insbesondere dann verwenden, wenn Sie über dedizierte Teams für maschinelles Lernen (ML) und Datenwissenschaft verfügen, die ihre eigenen PLM-Modelle mithilfe domänenspezifischer Datensätze verfeinern und eine große Anzahl von Inferenzendpunkten bereitstellen Amazon Sage Maker. Ein Beispiel ist ein Online-Händler, der eine große Anzahl von Inferenzendpunkten für die Textzusammenfassung, Produktkatalogklassifizierung und Produktfeedback-Stimmungsklassifizierung einsetzt. Ein weiteres Beispiel könnte ein Gesundheitsdienstleister sein, der PLM-Inferenzendpunkte für die Klassifizierung klinischer Dokumente, die Erkennung benannter Entitäten aus medizinischen Berichten, medizinische Chatbots und die Risikostratifizierung von Patienten verwendet.
Lösungsüberblick
In diesem Abschnitt stellen wir den gesamten Arbeitsablauf vor und erläutern die Vorgehensweise. Zuerst verwenden wir eine Amazon SageMaker-Studio Notizbuch um ein vorab trainiertes BERT-Modell anhand eines domänenspezifischen Datensatzes auf eine Zielaufgabe abzustimmen. BERT (Bidirektionale Encoder-Repräsentationen von Transformers) ist ein vorab trainiertes Sprachmodell, das auf dem basiert Transformator-Architektur Wird für NLP-Aufgaben (Natural Language Processing) verwendet. Neural Architecture Search (NAS) ist ein Ansatz zur Automatisierung des Entwurfs künstlicher neuronaler Netze und steht in engem Zusammenhang mit der Hyperparameteroptimierung, einem weit verbreiteten Ansatz im Bereich des maschinellen Lernens. Das Ziel von NAS besteht darin, die optimale Architektur für ein bestimmtes Problem zu finden, indem eine große Menge möglicher Architekturen mithilfe von Techniken wie der farbverlaufsfreien Optimierung oder der Optimierung der gewünschten Metriken durchsucht wird. Die Leistung der Architektur wird typischerweise anhand von Metriken wie dem Validierungsverlust gemessen. Automatisches SageMaker-Modelltuning (AMT) automatisiert den mühsamen und komplexen Prozess, die optimalen Kombinationen von Hyperparametern des ML-Modells zu finden, die die beste Modellleistung erzielen. AMT verwendet intelligente Suchalgorithmen und iterative Auswertungen unter Verwendung einer Reihe von Hyperparametern, die Sie angeben. Es wählt die Hyperparameterwerte aus, die ein Modell mit der besten Leistung erstellen, gemessen an Leistungsmetriken wie Genauigkeit und F-1-Score.
Der in diesem Beitrag beschriebene Feinabstimmungsansatz ist generisch und kann auf jeden textbasierten Datensatz angewendet werden. Die dem BERT PLM zugewiesene Aufgabe kann eine textbasierte Aufgabe wie Stimmungsanalyse, Textklassifizierung oder Fragen und Antworten sein. In dieser Demo ist die Zielaufgabe ein binäres Klassifizierungsproblem, bei dem BERT verwendet wird, um anhand eines Datensatzes, der aus einer Sammlung von Paaren von Textfragmenten besteht, zu ermitteln, ob die Bedeutung eines Textfragments aus dem anderen Fragment abgeleitet werden kann. Wir benutzen das Erkennen des Textual Entailment-Datensatzes aus der GLUE-Benchmarking-Suite. Wir führen eine Suche mit mehreren Zielen mit SageMaker AMT durch, um die Subnetzwerke zu identifizieren, die optimale Kompromisse zwischen Parameteranzahl und Vorhersagegenauigkeit für die Zielaufgabe bieten. Wenn wir eine Suche mit mehreren Zielen durchführen, definieren wir zunächst die Genauigkeit und Parameteranzahl als Ziele, die wir optimieren möchten.
Innerhalb des BERT PLM-Netzwerks kann es modulare, in sich geschlossene Teilnetzwerke geben, die es dem Modell ermöglichen, über spezielle Fähigkeiten wie Sprachverständnis und Wissensrepräsentation zu verfügen. BERT PLM verwendet ein mehrköpfiges Selbstaufmerksamkeits-Subnetzwerk und ein Feed-Forward-Subnetzwerk. Eine mehrköpfige Selbstaufmerksamkeitsschicht ermöglicht es BERT, verschiedene Positionen einer einzelnen Sequenz in Beziehung zu setzen, um eine Darstellung der Sequenz zu berechnen, indem es mehreren Köpfen ermöglicht, mehrere Kontextsignale zu berücksichtigen. Die Eingabe wird in mehrere Unterräume aufgeteilt und die Selbstaufmerksamkeit wird auf jeden der Unterräume separat angewendet. Mehrere Köpfe in einem Transformer-PLM ermöglichen es dem Modell, sich gemeinsam um Informationen aus verschiedenen Darstellungsunterräumen zu kümmern. Ein Feed-Forward-Subnetzwerk ist ein einfaches neuronales Netzwerk, das die Ausgabe des mehrköpfigen Selbstaufmerksamkeits-Subnetzwerks entgegennimmt, die Daten verarbeitet und die endgültigen Encoderdarstellungen zurückgibt.
Das Ziel der zufälligen Teilnetzwerkstichprobe besteht darin, kleinere BERT-Modelle zu trainieren, die bei Zielaufgaben eine ausreichende Leistung erbringen können. Wir nehmen Stichproben aus 100 zufälligen Subnetzwerken aus dem fein abgestimmten BERT-Basismodell und bewerten 10 Netzwerke gleichzeitig. Die trainierten Teilnetzwerke werden hinsichtlich der objektiven Metriken bewertet und das endgültige Modell wird auf der Grundlage der zwischen den objektiven Metriken gefundenen Kompromisse ausgewählt. Wir visualisieren das Pareto-Front für die abgetasteten Teilnetzwerke, das das bereinigte Modell enthält, das den optimalen Kompromiss zwischen Modellgenauigkeit und Modellgröße bietet. Wir wählen das Kandidaten-Subnetzwerk (NAS-bereinigtes BERT-Modell) basierend auf der Modellgröße und Modellgenauigkeit aus, die wir in Kauf nehmen möchten. Als Nächstes hosten wir die Endpunkte, das vorab trainierte BERT-Basismodell und das NAS-bereinigte BERT-Modell mit SageMaker. Um Lasttests durchzuführen, verwenden wir Heuschrecke, ein Open-Source-Auslastungstesttool, das Sie mit Python implementieren können. Wir führen Lasttests auf beiden Endpunkten mit Locust durch und visualisieren die Ergebnisse mithilfe der Pareto-Front, um den Kompromiss zwischen Reaktionszeiten und Genauigkeit für beide Modelle zu veranschaulichen. Das folgende Diagramm bietet einen Überblick über den in diesem Beitrag erläuterten Workflow.
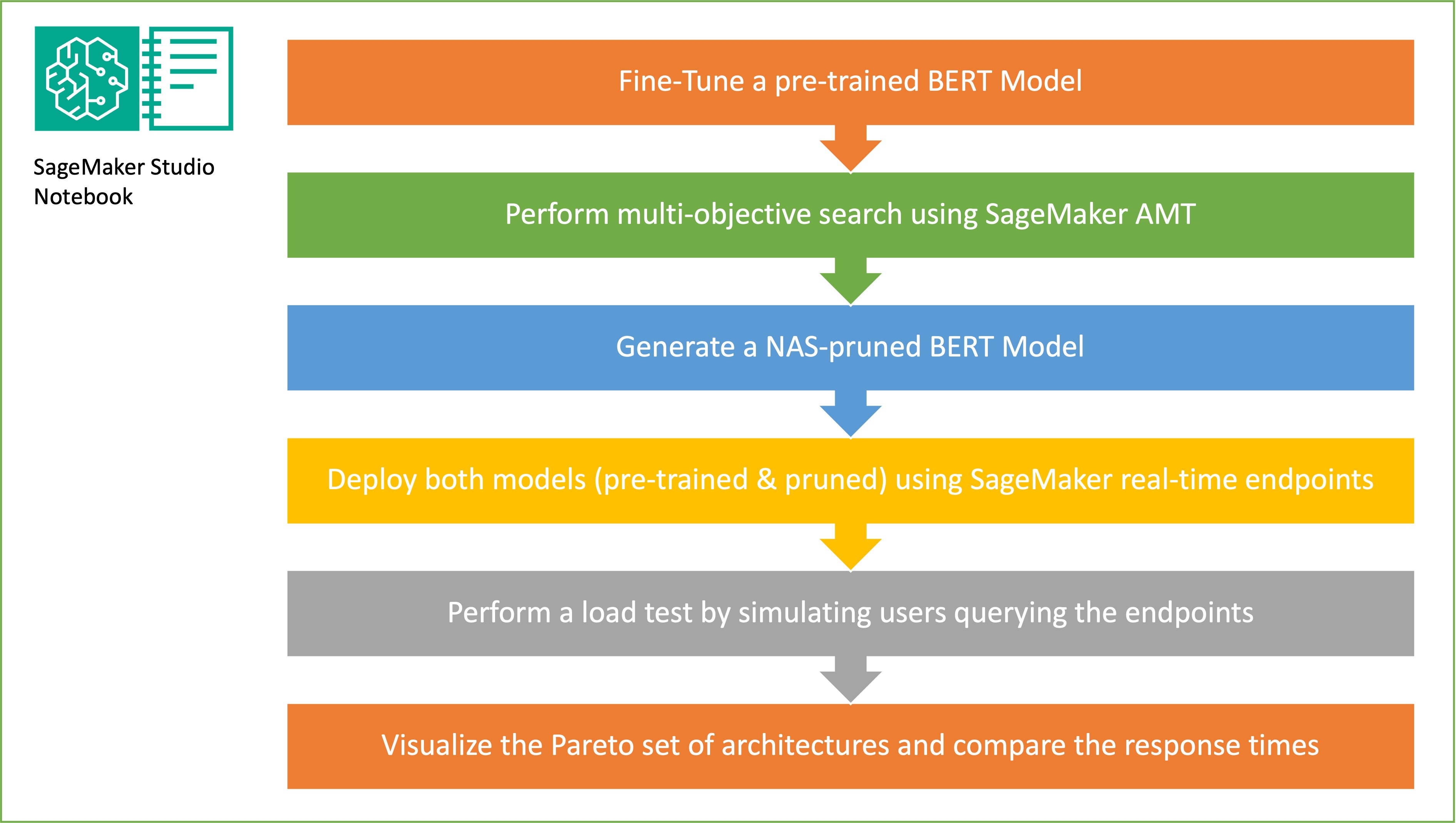
Voraussetzungen:
Für diese Stelle sind folgende Voraussetzungen erforderlich:
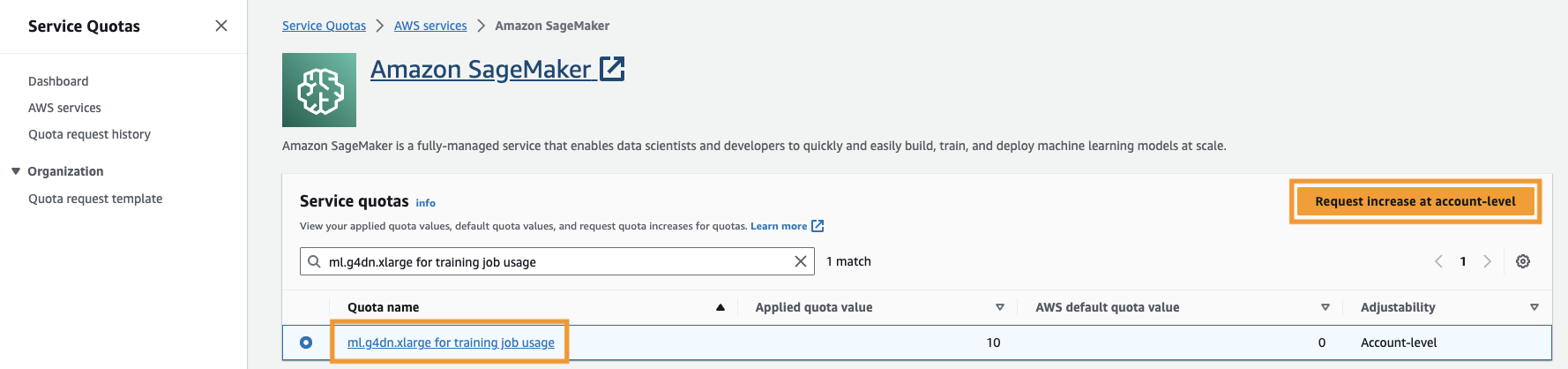
Sie müssen auch die erhöhen Servicekontingent um auf mindestens drei Instanzen von ml.g4dn.xlarge-Instanzen in SageMaker zuzugreifen. Der Instanztyp ml.g4dn.xlarge ist die kosteneffiziente GPU-Instanz, die es Ihnen ermöglicht, PyTorch nativ auszuführen. Um das Servicekontingent zu erhöhen, führen Sie die folgenden Schritte aus:
- Navigieren Sie in der Konsole zu Servicekontingente.
- Aussichten für Kontingente verwalten, wählen Amazon Sage Maker, Dann wählen Kontingente anzeigen.

- Suchen Sie nach „ml-g4dn.xlarge für die Nutzung von Schulungsjobs“ und wählen Sie das Kontingentelement aus.
- Auswählen Fordern Sie eine Erhöhung auf Kontoebene an.
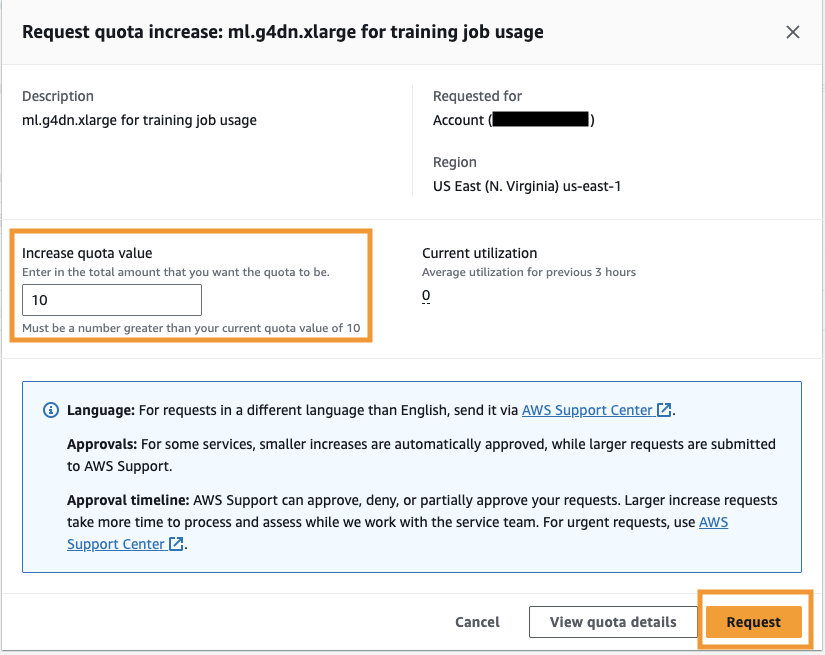
- Aussichten für Kontingentwert erhöhenGeben Sie einen Wert von 5 oder höher ein.
- Auswählen PREISANFRAGE (Request).
Abhängig von den Kontoberechtigungen kann es einige Zeit dauern, bis die angeforderte Kontingentgenehmigung abgeschlossen ist.
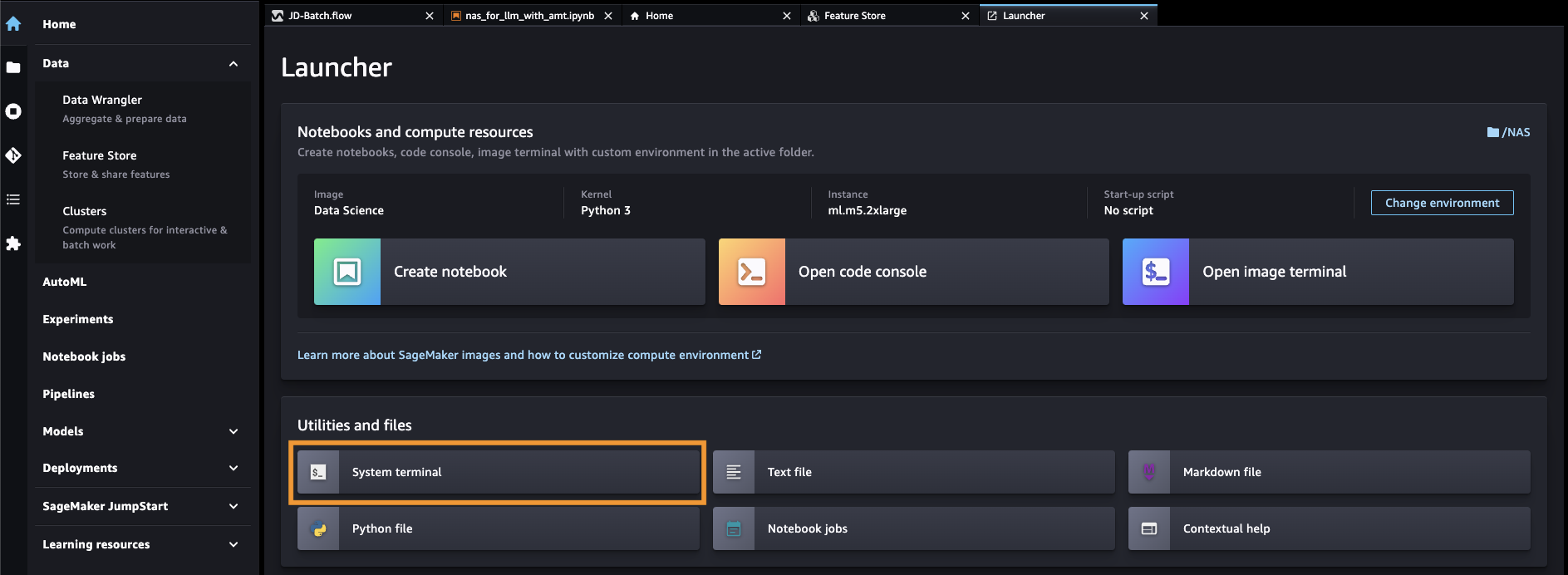
- Öffnen Sie SageMaker Studio über die SageMaker-Konsole.

- Auswählen Systemendgerät für Dienstprogramme und Dateien.
- Führen Sie den folgenden Befehl aus, um das zu klonen GitHub Repo zur SageMaker Studio-Instanz:
- Navigieren
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Öffnen Sie die Datei
nas_for_llm_with_amt.ipynb. - Richten Sie die Umgebung mit einem ein
ml.g4dn.xlargeInstanz und wählen Sie Auswählen.
Richten Sie das vorab trainierte BERT-Modell ein
In diesem Abschnitt importieren wir den Datensatz „Recognizing Textual Entailment“ aus der Datensatzbibliothek und teilen den Datensatz in Trainings- und Validierungssätze auf. Dieser Datensatz besteht aus Satzpaaren. Die Aufgabe des BERT PLM besteht darin, anhand zweier Textfragmente zu erkennen, ob die Bedeutung des einen Textfragments aus dem anderen Fragment abgeleitet werden kann. Im folgenden Beispiel können wir aus der zweiten Phrase auf die Bedeutung der ersten Phrase schließen:
Wir laden den Texterkennungsdatensatz aus dem KLEBER Benchmarking-Suite über die Datensatzbibliothek von Hugging Face in unserem Trainingsskript (./training.py). Wir haben den ursprünglichen Trainingsdatensatz von GLUE in einen Trainings- und Validierungssatz aufgeteilt. In unserem Ansatz verfeinern wir das BERT-Basismodell mithilfe des Trainingsdatensatzes und führen dann eine Suche mit mehreren Zielen durch, um den Satz von Subnetzwerken zu identifizieren, die ein optimales Gleichgewicht zwischen den objektiven Metriken bieten. Wir verwenden den Trainingsdatensatz ausschließlich zur Feinabstimmung des BERT-Modells. Wir verwenden jedoch Validierungsdaten für die Suche mit mehreren Zielen, indem wir die Genauigkeit des Holdout-Validierungsdatensatzes messen.
Optimieren Sie das BERT PLM mithilfe eines domänenspezifischen Datensatzes
Zu den typischen Anwendungsfällen für ein rohes BERT-Modell gehören die Vorhersage des nächsten Satzes oder die Modellierung maskierter Sprache. Um das Basis-BERT-Modell für nachgelagerte Aufgaben wie die Texterkennung zu verwenden, müssen wir das Modell mithilfe eines domänenspezifischen Datensatzes weiter verfeinern. Sie können ein fein abgestimmtes BERT-Modell für Aufgaben wie Sequenzklassifizierung, Fragebeantwortung und Tokenklassifizierung verwenden. Für die Zwecke dieser Demo verwenden wir jedoch das fein abgestimmte Modell für die binäre Klassifizierung. Wir optimieren das vorab trainierte BERT-Modell mit dem zuvor vorbereiteten Trainingsdatensatz und verwenden dabei die folgenden Hyperparameter:
Wir speichern den Checkpoint des Modelltrainings in einem Amazon Simple Storage-Service (Amazon S3)-Bucket, damit das Modell während der NAS-basierten Mehrzielsuche geladen werden kann. Bevor wir das Modell trainieren, definieren wir die Metriken wie Epoche, Trainingsverlust, Anzahl der Parameter und Validierungsfehler:
Nachdem der Feinabstimmungsprozess begonnen hat, dauert der Trainingsvorgang etwa 15 Minuten.
Führen Sie eine Suche mit mehreren Zielen durch, um Subnetzwerke auszuwählen und die Ergebnisse zu visualisieren
Im nächsten Schritt führen wir eine Suche mit mehreren Zielen auf dem fein abgestimmten Basis-BERT-Modell durch, indem wir mit SageMaker AMT Stichproben aus zufälligen Teilnetzwerken ziehen. Um auf ein Subnetzwerk innerhalb des Supernetzwerks (das fein abgestimmte BERT-Modell) zuzugreifen, maskieren wir alle Komponenten des PLM, die nicht Teil des Subnetzwerks sind. Das Maskieren eines Supernetzwerks zum Auffinden von Subnetzwerken in einem PLM ist eine Technik, mit der Verhaltensmuster des Modells isoliert und identifiziert werden. Beachten Sie, dass bei Hugging Face-Transformatoren die verborgene Größe ein Vielfaches der Anzahl der Köpfe betragen muss. Die verborgene Größe in einem Transformer-PLM steuert die Größe des verborgenen Zustandsvektorraums, was sich auf die Fähigkeit des Modells auswirkt, komplexe Darstellungen und Muster in den Daten zu lernen. In einem BERT-PLM hat der verborgene Zustandsvektor eine feste Größe (768). Wir können die verborgene Größe nicht ändern und daher muss die Anzahl der Köpfe in [1, 3, 6, 12] liegen.
Im Gegensatz zur Einzelzieloptimierung verfügen wir bei der Mehrzieloptimierung normalerweise nicht über eine einzige Lösung, die alle Ziele gleichzeitig optimiert. Stattdessen wollen wir eine Reihe von Lösungen sammeln, die alle anderen Lösungen in mindestens einem Ziel (z. B. Validierungsfehler) dominieren. Jetzt können wir die Suche mit mehreren Zielen über AMT starten, indem wir die Metriken festlegen, die wir reduzieren möchten (Validierungsfehler und Anzahl der Parameter). Die zufälligen Subnetzwerke werden durch den Parameter definiert max_jobs und die Anzahl der gleichzeitigen Jobs wird durch den Parameter definiert max_parallel_jobs. Der Code zum Laden des Modellprüfpunkts und zur Auswertung des Subnetzwerks ist im verfügbar evaluate_subnetwork.py Skripte.
Die Ausführung des AMT-Tuning-Auftrags dauert etwa 2 Stunden und 20 Minuten. Nachdem der AMT-Tuning-Job erfolgreich ausgeführt wurde, analysieren wir den Verlauf des Jobs und erfassen die Konfigurationen des Subnetzwerks, wie z. B. die Anzahl der Köpfe, die Anzahl der Schichten, die Anzahl der Einheiten und die entsprechenden Metriken wie Validierungsfehler und Anzahl der Parameter. Der folgende Screenshot zeigt die Zusammenfassung eines erfolgreichen AMT-Tuner-Auftrags.
Als nächstes visualisieren wir die Ergebnisse mithilfe eines Pareto-Sets (auch bekannt als Pareto-Grenze oder Pareto-Optimum-Set), das uns hilft, optimale Sets von Subnetzwerken zu identifizieren, die alle anderen Subnetzwerke in der Zielmetrik dominieren (Validierungsfehler):
Zunächst sammeln wir die Daten aus dem AMT-Tuning-Auftrag. Dann zeichnen wir die Pareto-Menge mit auf matplotlob.pyplot mit Anzahl der Parameter auf der x-Achse und Validierungsfehler auf der y-Achse. Dies impliziert, dass wir beim Wechsel von einem Teilnetzwerk des Pareto-Sets zu einem anderen entweder Einbußen bei der Leistung oder der Modellgröße hinnehmen müssen, dafür aber das andere verbessern müssen. Letztendlich bietet uns das Pareto-Set die Flexibilität, das Subnetzwerk auszuwählen, das unseren Vorlieben am besten entspricht. Wir können entscheiden, wie stark wir die Größe unseres Netzwerks reduzieren möchten und wie viel Leistung wir bereit sind zu opfern.

Stellen Sie das fein abgestimmte BERT-Modell und das NAS-optimierte Subnetzwerkmodell mit SageMaker bereit
Als nächstes setzen wir das größte Modell in unserem Pareto-Set ein, das zu der geringsten Leistungseinbuße bei a führt SageMaker-Endpunkt. Das beste Modell ist dasjenige, das einen optimalen Kompromiss zwischen dem Validierungsfehler und der Anzahl der Parameter für unseren Anwendungsfall bietet.
Modellvergleich
Wir haben ein vorab trainiertes BERT-Basismodell genommen, es mithilfe eines domänenspezifischen Datensatzes verfeinert, eine NAS-Suche durchgeführt, um anhand der objektiven Metriken dominante Subnetzwerke zu identifizieren, und das bereinigte Modell auf einem SageMaker-Endpunkt bereitgestellt. Darüber hinaus haben wir das vorab trainierte BERT-Basismodell genommen und das Basismodell auf einem zweiten SageMaker-Endpunkt bereitgestellt. Als nächstes rannten wir Belastungstest Wir haben Locust auf beiden Inferenzendpunkten verwendet und die Leistung im Hinblick auf die Antwortzeit bewertet.
Zuerst importieren wir die notwendigen Locust- und Boto3-Bibliotheken. Anschließend erstellen wir Anforderungsmetadaten und zeichnen die Startzeit auf, die für den Lasttest verwendet werden soll. Anschließend wird die Nutzlast über den BotoClient an die SageMaker-Endpunkt-Aufruf-API übergeben, um echte Benutzeranfragen zu simulieren. Wir verwenden Locust, um mehrere virtuelle Benutzer zu erzeugen, um Anfragen parallel zu senden und die Endpunktleistung unter Last zu messen. Tests werden durchgeführt, indem die Anzahl der Benutzer für jeden der beiden Endpunkte erhöht wird. Nachdem die Tests abgeschlossen sind, gibt Locust eine CSV-Datei mit Anforderungsstatistiken für jedes der bereitgestellten Modelle aus.
Als Nächstes generieren wir die Antwortzeitdiagramme aus den CSV-Dateien, die wir nach der Durchführung der Tests mit Locust heruntergeladen haben. Der Zweck der Darstellung der Antwortzeit gegenüber der Anzahl der Benutzer besteht darin, die Ergebnisse des Lasttests zu analysieren, indem die Auswirkungen der Antwortzeit der Modellendpunkte visualisiert werden. Im folgenden Diagramm sehen wir, dass der NAS-bereinigte Modellendpunkt im Vergleich zum Basis-BERT-Modellendpunkt eine kürzere Antwortzeit erreicht.
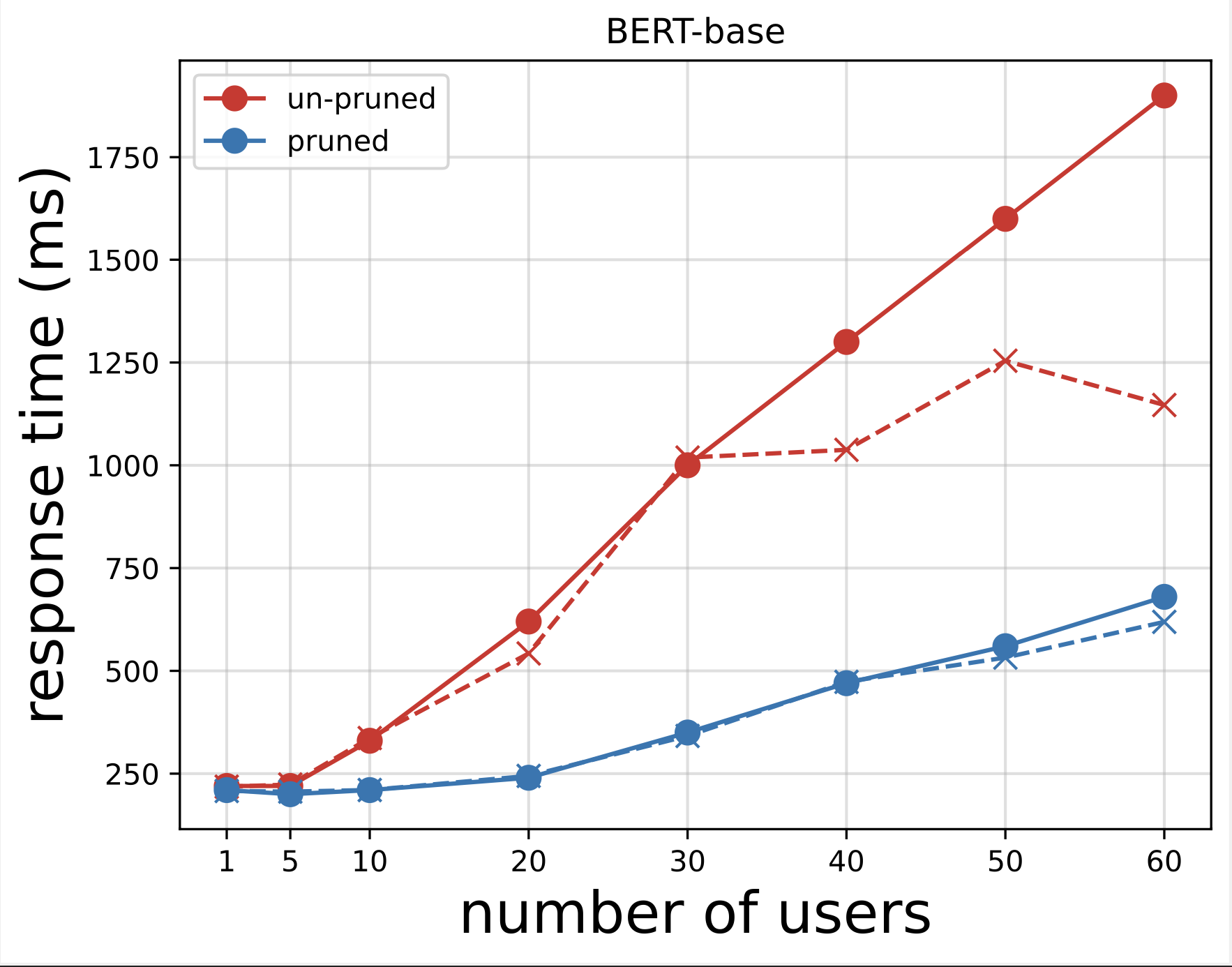
Im zweiten Diagramm, das eine Erweiterung des ersten Diagramms ist, beobachten wir, dass SageMaker nach etwa 70 Benutzern beginnt, den Endpunkt des Basis-BERT-Modells zu drosseln und eine Ausnahme auslöst. Beim NAS-beschnittenen Endpunktmodell erfolgt die Drosselung jedoch zwischen 90 und 100 Benutzern und mit einer kürzeren Reaktionszeit.

Anhand der beiden Diagramme erkennen wir, dass das beschnittene Modell im Vergleich zum unbeschnittenen Modell eine schnellere Reaktionszeit aufweist und besser skaliert. Wenn wir die Anzahl der Inferenzendpunkte skalieren, wie es bei Benutzern der Fall ist, die eine große Anzahl von Inferenzendpunkten für ihre PLM-Anwendungen bereitstellen, beginnen die Kostenvorteile und die Leistungsverbesserung recht erheblich zu werden.
Aufräumen
Um die SageMaker-Endpunkte für das fein abgestimmte BERT-Basismodell und das NAS-bereinigte Modell zu löschen, führen Sie die folgenden Schritte aus:
- Wählen Sie in der SageMaker-Konsole Inferenz und Endpunkte im Navigationsbereich.
- Wählen Sie den Endpunkt aus und löschen Sie ihn.
Alternativ können Sie im SageMaker Studio-Notizbuch die folgenden Befehle ausführen und dabei die Endpunktnamen angeben:
Zusammenfassung
In diesem Beitrag haben wir besprochen, wie man mit NAS ein fein abgestimmtes BERT-Modell bereinigt. Wir haben zunächst ein Basis-BERT-Modell mithilfe domänenspezifischer Daten trainiert und es auf einem SageMaker-Endpunkt bereitgestellt. Wir haben mit SageMaker AMT für eine Zielaufgabe eine Suche mit mehreren Zielen auf dem fein abgestimmten BERT-Basismodell durchgeführt. Wir haben die Pareto-Front visualisiert, das Pareto-optimale NAS-bereinigte BERT-Modell ausgewählt und das Modell auf einem zweiten SageMaker-Endpunkt bereitgestellt. Wir haben Lasttests mit Locust durchgeführt, um zu simulieren, dass Benutzer beide Endpunkte abfragen, und die Antwortzeiten gemessen und in einer CSV-Datei aufgezeichnet. Wir haben die Reaktionszeit im Vergleich zur Anzahl der Benutzer für beide Modelle aufgetragen.
Wir haben festgestellt, dass das beschnittene BERT-Modell sowohl hinsichtlich der Reaktionszeit als auch des Instanz-Drosselungsschwellenwerts eine deutlich bessere Leistung erbringt. Wir kamen zu dem Schluss, dass das NAS-beschnittene Modell widerstandsfähiger gegenüber einer erhöhten Belastung des Endpunkts war und im Vergleich zum BERT-Basismodell eine kürzere Reaktionszeit beibehielt, selbst wenn mehr Benutzer das System belasteten. Sie können die in diesem Beitrag beschriebene NAS-Technik auf jedes große Sprachmodell anwenden, um ein bereinigtes Modell zu finden, das die Zielaufgabe mit deutlich kürzerer Antwortzeit ausführen kann. Sie können den Ansatz weiter optimieren, indem Sie neben dem Validierungsverlust auch die Latenz als Parameter verwenden.
Obwohl wir in diesem Beitrag NAS verwenden, ist Quantisierung ein weiterer gängiger Ansatz zur Optimierung und Komprimierung von PLM-Modellen. Die Quantisierung reduziert die Präzision der Gewichte und Aktivierungen in einem trainierten Netzwerk von 32-Bit-Gleitkommazahlen auf niedrigere Bitbreiten wie 8-Bit- oder 16-Bit-Ganzzahlen, was zu einem komprimierten Modell führt, das schnellere Inferenzen generiert. Durch die Quantisierung wird die Anzahl der Parameter nicht reduziert; Stattdessen wird die Präzision der vorhandenen Parameter verringert, um ein komprimiertes Modell zu erhalten. Durch die NAS-Bereinigung werden redundante Netzwerke in einem PLM entfernt, wodurch ein spärliches Modell mit weniger Parametern entsteht. Typischerweise werden NAS-Pruning und Quantisierung zusammen verwendet, um große PLMs zu komprimieren, um die Modellgenauigkeit aufrechtzuerhalten, Validierungsverluste zu reduzieren und gleichzeitig die Leistung zu verbessern und die Modellgröße zu reduzieren. Zu den anderen häufig verwendeten Techniken zur Reduzierung der Größe von PLMs gehören: Wissensdestillation, Matrixfaktorisierung und Destillationskaskaden.
Der im Blogpost vorgeschlagene Ansatz eignet sich für Teams, die SageMaker verwenden, um die Modelle mithilfe domänenspezifischer Daten zu trainieren und zu verfeinern und die Endpunkte zur Generierung von Inferenzen bereitzustellen. Wenn Sie nach einem vollständig verwalteten Dienst suchen, der eine Auswahl an leistungsstarken Basismodellen bietet, die zum Erstellen generativer KI-Anwendungen erforderlich sind, sollten Sie die Verwendung in Betracht ziehen Amazonas Grundgestein. Wenn Sie nach vorab trainierten Open-Source-Modellen für eine Vielzahl von Geschäftsanwendungsfällen suchen und auf Lösungsvorlagen und Beispielnotizbücher zugreifen möchten, sollten Sie die Verwendung in Betracht ziehen Amazon SageMaker-JumpStart. Eine vorab trainierte Version des Hugging Face BERT-Basismodells mit Gehäuse, das wir in diesem Beitrag verwendet haben, ist auch bei SageMaker JumpStart erhältlich.
Über die Autoren
 Aparajithan Vaidyanathan ist Principal Enterprise Solutions Architect bei AWS. Er ist ein Cloud-Architekt mit mehr als 24 Jahren Erfahrung in der Gestaltung und Entwicklung von Unternehmens-, Groß- und verteilten Softwaresystemen. Er ist spezialisiert auf generative KI und maschinelles Lernen im Data Engineering. Er ist ein aufstrebender Marathonläufer und zu seinen Hobbys zählen Wandern, Radfahren und Zeit mit seiner Frau und seinen beiden Söhnen verbringen.
Aparajithan Vaidyanathan ist Principal Enterprise Solutions Architect bei AWS. Er ist ein Cloud-Architekt mit mehr als 24 Jahren Erfahrung in der Gestaltung und Entwicklung von Unternehmens-, Groß- und verteilten Softwaresystemen. Er ist spezialisiert auf generative KI und maschinelles Lernen im Data Engineering. Er ist ein aufstrebender Marathonläufer und zu seinen Hobbys zählen Wandern, Radfahren und Zeit mit seiner Frau und seinen beiden Söhnen verbringen.
 Aaron Klein ist Senior Applied Scientist bei AWS und arbeitet an automatisierten maschinellen Lernmethoden für tiefe neuronale Netze.
Aaron Klein ist Senior Applied Scientist bei AWS und arbeitet an automatisierten maschinellen Lernmethoden für tiefe neuronale Netze.
 Jacek Golebiowski ist Senior Applied Scientist bei AWS.
Jacek Golebiowski ist Senior Applied Scientist bei AWS.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/

