Wir freuen uns, heute die Möglichkeit bekannt zu geben, Code-Llama-Modelle mithilfe von Meta zu optimieren Amazon SageMaker-JumpStart. Die Code Llama-Familie großer Sprachmodelle (LLMs) ist eine Sammlung vorab trainierter und fein abgestimmter Codegenerierungsmodelle mit einer Größenordnung von 7 bis 70 Milliarden Parametern. Feinabgestimmte Code-Llama-Modelle bieten eine bessere Genauigkeit und Erklärbarkeit im Vergleich zu den Basis-Code-Llama-Modellen, wie ihre Tests zeigen HumanEval und MBPP-Datensätze. Mit SageMaker JumpStart können Sie Code-Llama-Modelle optimieren und bereitstellen Amazon SageMaker-Studio Benutzeroberfläche mit wenigen Klicks oder mit dem SageMaker Python SDK. Die Feinabstimmung der Llama-Modelle basiert auf den im bereitgestellten Skripten Lama-Rezepte GitHub-Repo von Meta unter Verwendung der Quantisierungstechniken PyTorch FSDP, PEFT/LoRA und Int8.
In diesem Beitrag erfahren Sie, wie Sie vorab trainierte Code Llama-Modelle über SageMaker JumpStart mithilfe einer Ein-Klick-Benutzeroberfläche und einem SDK optimieren, die im Folgenden verfügbar sind GitHub-Repository.
Was ist SageMaker JumpStart?
Mit SageMaker JumpStart können Praktiker des maschinellen Lernens (ML) aus einer breiten Auswahl öffentlich verfügbarer Basismodelle wählen. ML-Praktiker können Basismodelle für dedizierte Personen bereitstellen Amazon Sage Maker Erstellen Sie Instanzen aus einer netzwerkisolierten Umgebung und passen Sie Modelle mithilfe von SageMaker für die Modellschulung und -bereitstellung an.
Was ist Code Lama?
Code Llama ist eine auf Code spezialisierte Version von Lama 2 Dies wurde durch weiteres Training von Llama 2 mit seinen codespezifischen Datensätzen und durch das Abtasten weiterer Daten aus demselben Datensatz über einen längeren Zeitraum erstellt. Code Llama bietet erweiterte Codierungsfunktionen. Es kann Code und natürliche Sprache über Code generieren, sowohl aus Code- als auch aus Eingabeaufforderungen in natürlicher Sprache (z. B. „Schreiben Sie mir eine Funktion, die die Fibonacci-Folge ausgibt“). Sie können es auch zur Codevervollständigung und zum Debuggen verwenden. Es unterstützt viele der heute am häufigsten verwendeten Programmiersprachen, darunter Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash und mehr.
Warum Code-Llama-Modelle verfeinern?
Meta veröffentlichte Code Llama-Leistungsbenchmarks am HumanEval und MBPP für gängige Programmiersprachen wie Python, Java und JavaScript. Die Leistung von Code Llama-Python-Modellen auf HumanEval zeigte eine unterschiedliche Leistung über verschiedene Programmiersprachen und Aufgaben hinweg, die von 38 % beim 7B-Python-Modell bis zu 57 % bei 70B-Python-Modellen reichte. Darüber hinaus haben fein abgestimmte Code-Llama-Modelle für die Programmiersprache SQL bessere Ergebnisse gezeigt, wie in SQL-Bewertungsbenchmarks deutlich wird. Diese veröffentlichten Benchmarks verdeutlichen die potenziellen Vorteile der Feinabstimmung von Code-Llama-Modellen und ermöglichen eine bessere Leistung, Anpassung und Anpassung an bestimmte Codierungsdomänen und -aufgaben.
Feinabstimmung ohne Code über die Benutzeroberfläche von SageMaker Studio
Um mit der Feinabstimmung Ihrer Llama-Modelle mit SageMaker Studio zu beginnen, führen Sie die folgenden Schritte aus:
- Wählen Sie auf der SageMaker Studio-Konsole Starthilfe im Navigationsbereich.
Sie finden Auflistungen von über 350 Modellen, von Open-Source-Modellen bis hin zu proprietären Modellen.
- Suchen Sie nach Code Llama-Modellen.

Wenn Sie keine Code-Llama-Modelle sehen, können Sie Ihre SageMaker Studio-Version aktualisieren, indem Sie sie herunterfahren und neu starten. Weitere Informationen zu Versionsaktualisierungen finden Sie unter Fahren Sie Studio Apps herunter und aktualisieren Sie sie. Weitere Modellvarianten finden Sie auch unter der Auswahl Entdecken Sie alle Codegenerierungsmodelle oder suchen Sie im Suchfeld nach „Code Lama“.
SageMaker JumpStart unterstützt derzeit die Feinabstimmung von Anweisungen für Code-Llama-Modelle. Der folgende Screenshot zeigt die Feinabstimmungsseite für das Modell Code Llama 2 70B.
- Aussichten für Speicherort des Trainingsdatensatzes, Sie können auf die zeigen Amazon Simple Storage-Service (Amazon S3)-Bucket, der die Trainings- und Validierungsdatensätze zur Feinabstimmung enthält.
- Legen Sie Ihre Bereitstellungskonfiguration, Hyperparameter und Sicherheitseinstellungen zur Feinabstimmung fest.
- Auswählen
Training um den Feinabstimmungsjob auf einer SageMaker ML-Instanz zu starten.
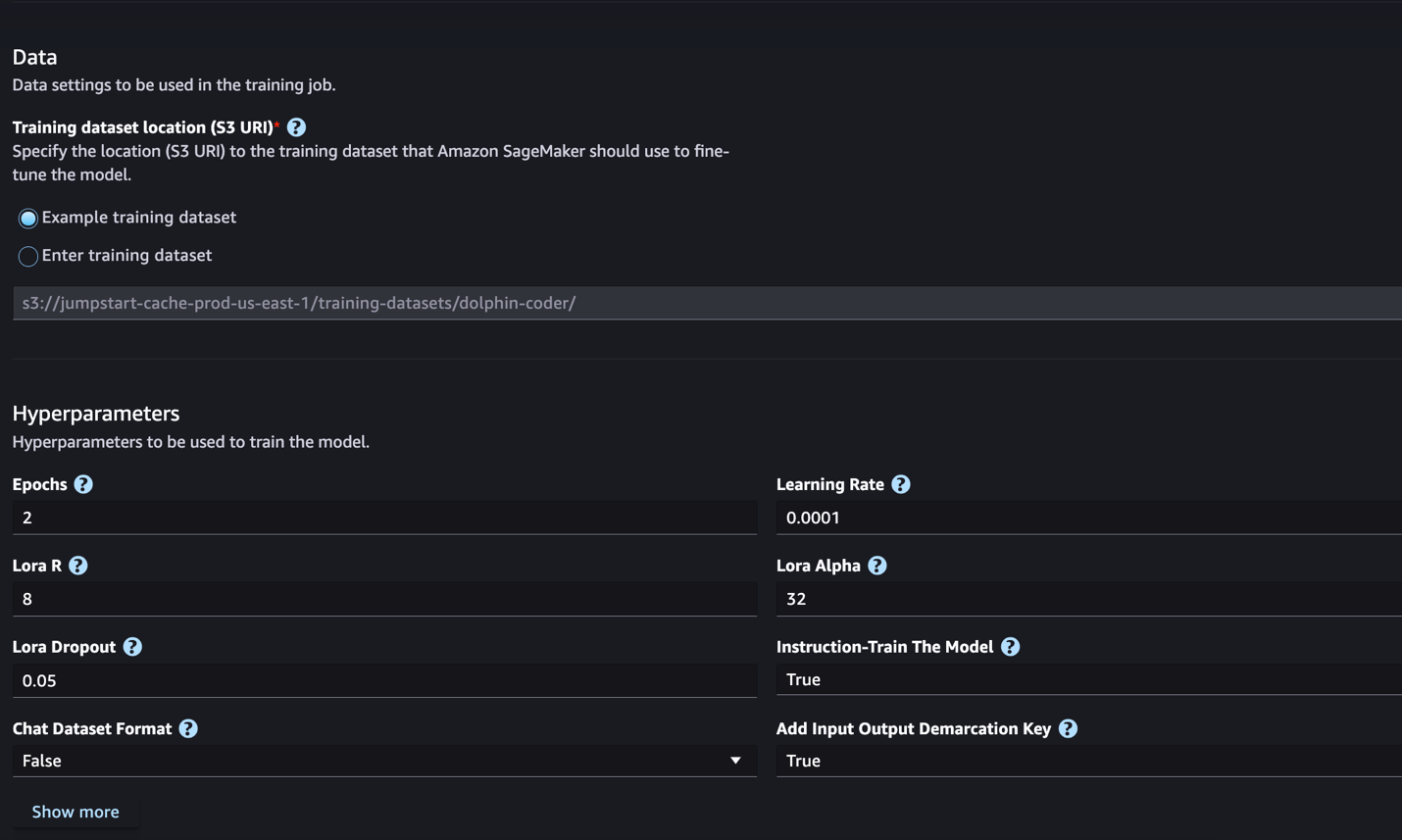
Im nächsten Abschnitt besprechen wir das Datensatzformat, das Sie für die Feinabstimmung der Anweisungen vorbereiten müssen.
- Nachdem das Modell fein abgestimmt wurde, können Sie es über die Modellseite in SageMaker JumpStart bereitstellen.
Die Option zum Bereitstellen des feinabgestimmten Modells wird angezeigt, wenn die Feinabstimmung abgeschlossen ist, wie im folgenden Screenshot gezeigt.

Feinabstimmung über das SageMaker Python SDK
In diesem Abschnitt zeigen wir, wie Sie Code-LIama-Modelle mithilfe des SageMaker Python SDK an einem befehlsformatierten Datensatz optimieren. Insbesondere ist das Modell auf eine Reihe von NLP-Aufgaben (Natural Language Processing) abgestimmt, die mithilfe von Anweisungen beschrieben werden. Dies trägt dazu bei, die Leistung des Modells für unsichtbare Aufgaben mit Zero-Shot-Eingabeaufforderungen zu verbessern.
Führen Sie die folgenden Schritte aus, um Ihre Feinabstimmungsaufgabe abzuschließen. Den gesamten Feinabstimmungscode erhalten Sie unter GitHub-Repository.
Schauen wir uns zunächst das Datensatzformat an, das für die Feinabstimmung der Anweisungen erforderlich ist. Die Trainingsdaten sollten im JSON-Zeilenformat (.jsonl) formatiert sein, wobei jede Zeile ein Wörterbuch ist, das eine Datenprobe darstellt. Alle Trainingsdaten müssen in einem einzigen Ordner liegen. Es kann jedoch in mehreren .jsonl-Dateien gespeichert werden. Das Folgende ist ein Beispiel im JSON-Zeilenformat:
Der Schulungsordner kann Folgendes enthalten: template.json Datei, die die Eingabe- und Ausgabeformate beschreibt. Das Folgende ist eine Beispielvorlage:
Um mit der Vorlage übereinzustimmen, muss jedes Beispiel in den JSON-Zeilendateien enthalten system_prompt, question und response Felder. In dieser Demonstration verwenden wir die Dolphin Coder-Datensatz von Hugging Face.
Nachdem Sie den Datensatz vorbereitet und in den S3-Bucket hochgeladen haben, können Sie mit der Feinabstimmung mithilfe des folgenden Codes beginnen:
Sie können das fein abgestimmte Modell direkt aus dem Schätzer bereitstellen, wie im folgenden Code gezeigt. Einzelheiten finden Sie im Notizbuch im GitHub-Repository.
Feinabstimmungstechniken
Sprachmodelle wie Llama sind mehr als 10 GB oder sogar 100 GB groß. Die Feinabstimmung solch großer Modelle erfordert Instanzen mit deutlich hohem CUDA-Speicher. Darüber hinaus kann das Training dieser Modelle aufgrund der Größe des Modells sehr langsam sein. Für eine effiziente Feinabstimmung nutzen wir daher folgende Optimierungen:
- Low-Rank-Anpassung (LoRA) – Hierbei handelt es sich um eine Art der Parametereffizienten Feinabstimmung (PEFT) zur effizienten Feinabstimmung großer Modelle. Bei dieser Methode frieren Sie das gesamte Modell ein und fügen dem Modell nur einen kleinen Satz anpassbarer Parameter oder Ebenen hinzu. Anstatt beispielsweise alle 7 Milliarden Parameter für Llama 2 7B zu trainieren, können Sie weniger als 1 % der Parameter feinabstimmen. Dies trägt zu einer erheblichen Reduzierung des Speicherbedarfs bei, da Sie nur für 1 % der Parameter Farbverläufe, Optimierungszustände und andere trainingsbezogene Informationen speichern müssen. Darüber hinaus trägt dies zur Reduzierung der Schulungszeit und der Kosten bei. Weitere Einzelheiten zu dieser Methode finden Sie unter LoRA: Low-Rank-Anpassung großer Sprachmodelle.
- Int8-Quantisierung – Selbst mit Optimierungen wie LoRA sind Modelle wie Llama 70B immer noch zu groß zum Trainieren. Um den Speicherbedarf während des Trainings zu verringern, können Sie während des Trainings die Int8-Quantisierung verwenden. Die Quantisierung verringert typischerweise die Präzision von Gleitkomma-Datentypen. Dadurch wird zwar der zum Speichern von Modellgewichten erforderliche Speicher verringert, jedoch wird die Leistung aufgrund von Informationsverlusten beeinträchtigt. Die Int8-Quantisierung verwendet nur eine viertel Genauigkeit, führt jedoch nicht zu Leistungseinbußen, da die Bits nicht einfach gelöscht werden. Es rundet die Daten von einem Typ zum anderen. Weitere Informationen zur Int8-Quantisierung finden Sie unter LLM.int8(): 8-Bit-Matrixmultiplikation für Transformers at Scale.
- Vollständig geteilte Datenparallelität (FSDP) – Dies ist eine Art datenparalleler Trainingsalgorithmus, der die Parameter des Modells auf datenparallele Worker aufteilt und optional einen Teil der Trainingsberechnung auf die CPUs verlagern kann. Obwohl die Parameter auf verschiedene GPUs verteilt sind, erfolgt die Berechnung jedes Mikrobatchs lokal für den GPU-Worker. Es teilt Parameter gleichmäßiger auf und erzielt eine optimierte Leistung durch Überlappung von Kommunikation und Berechnungen während des Trainings.
Die folgende Tabelle fasst die Details jedes Modells mit unterschiedlichen Einstellungen zusammen.
| Modell | Voreinstellung | LORA + FSDP | LORA + Kein FSDP | Int8-Quantisierung + LORA + Kein FSDP |
| Code Lama 2 7B | LORA + FSDP | Ja | Ja | Ja |
| Code Lama 2 13B | LORA + FSDP | Ja | Ja | Ja |
| Code Lama 2 34B | INT8 + LORA + KEIN FSDP | Nein | Nein | Ja |
| Code Lama 2 70B | INT8 + LORA + KEIN FSDP | Nein | Nein | Ja |
Die Feinabstimmung von Llama-Modellen basiert auf den von den folgenden bereitgestellten Skripten GitHub Repo.
Unterstützte Hyperparameter für das Training
Die Feinabstimmung von Code Llama 2 unterstützt eine Reihe von Hyperparametern, von denen sich jeder auf den Speicherbedarf, die Trainingsgeschwindigkeit und die Leistung des feinabgestimmten Modells auswirken kann:
- Epoche – Die Anzahl der Durchgänge, die der Feinabstimmungsalgorithmus durch den Trainingsdatensatz durchführt. Muss eine ganze Zahl größer als 1 sein. Der Standardwert ist 5.
- Lernrate – Die Rate, mit der die Modellgewichte nach dem Durcharbeiten jedes Stapels von Trainingsbeispielen aktualisiert werden. Muss ein positiver Gleitkommawert größer als 0 sein. Der Standardwert ist 1e-4.
- Anweisung_tuned – Ob das Modell einer Schulung unterzogen werden soll oder nicht. Muss sein
TrueorFalse. Standard istFalse. - pro_device_train_batch_size – Die Batchgröße pro GPU-Kern/CPU für das Training. Muss eine positive ganze Zahl sein. Der Standardwert ist 4.
- pro_device_eval_batch_size – Die Batchgröße pro GPU-Kern/CPU zur Auswertung. Muss eine positive ganze Zahl sein. Der Standardwert ist 1.
- max_train_samples – Für Debugging-Zwecke oder schnelleres Training kürzen Sie die Anzahl der Trainingsbeispiele auf diesen Wert. Der Wert -1 bedeutet, dass alle Trainingsbeispiele verwendet werden. Muss eine positive Ganzzahl oder -1 sein. Der Standardwert ist -1.
- max_val_samples – Für Debugging-Zwecke oder eine schnellere Schulung kürzen Sie die Anzahl der Validierungsbeispiele auf diesen Wert. Der Wert -1 bedeutet, dass alle Validierungsproben verwendet werden. Muss eine positive Ganzzahl oder -1 sein. Der Standardwert ist -1.
- max_input_length – Maximale Gesamtlänge der Eingabesequenz nach der Tokenisierung. Längere Sequenzen werden abgeschnitten. Wenn -1,
max_input_lengthwird auf das Minimum von 1024 und die maximale Modelllänge festgelegt, die vom Tokenizer definiert wird. Wenn auf einen positiven Wert eingestellt,max_input_lengthwird auf das Minimum des angegebenen Werts gesetzt und dermodel_max_lengthvom Tokenizer definiert. Muss eine positive Ganzzahl oder -1 sein. Der Standardwert ist -1. - validation_split_ratio – Wenn der Validierungskanal vorhanden ist
none, muss das Verhältnis der Zugvalidierungsaufteilung aus den Zugdaten zwischen 0 und 1 liegen. Der Standardwert ist 0.2. - train_data_split_seed – Wenn keine Validierungsdaten vorhanden sind, wird dadurch die zufällige Aufteilung der eingegebenen Trainingsdaten in Trainings- und Validierungsdaten behoben, die vom Algorithmus verwendet werden. Muss eine ganze Zahl sein. Der Standardwert ist 0.
- preprocessing_num_workers – Die Anzahl der Prozesse, die für die Vorverarbeitung verwendet werden sollen. Wenn
None, der Hauptprozess dient der Vorverarbeitung. Standard istNone. - lora_r – Lora R. Muss eine positive ganze Zahl sein. Der Standardwert ist 8.
- lora_alpha – Lora Alpha. Muss eine positive ganze Zahl sein. Der Standardwert ist 32
- lora_dropout – Lora Dropout. muss ein positiver Gleitkommawert zwischen 0 und 1 sein. Der Standardwert ist 0.05.
- int8_quantisierung - Falls
True, wird das Modell für das Training mit 8-Bit-Präzision geladen. Die Standardeinstellung für 7B und 13B istFalse. Der Standardwert für 70B istTrue. - enable_fsdp – Wenn True, verwendet das Training FSDP. Der Standardwert für 7B und 13B ist True. Der Standardwert für 70B ist False. Beachten Sie, dass
int8_quantizationwird mit FSDP nicht unterstützt.
Berücksichtigen Sie bei der Auswahl der Hyperparameter Folgendes:
- Rahmen
int8_quantization=Trueverringert den Gedächtnisbedarf und führt zu einem schnelleren Training. - Abnehmend
per_device_train_batch_sizeundmax_input_lengthreduziert den Speicherbedarf und kann daher auf kleineren Instanzen ausgeführt werden. Allerdings kann die Einstellung sehr niedriger Werte die Trainingszeit verlängern. - Wenn Sie die Int8-Quantisierung nicht verwenden (
int8_quantization=False), verwenden Sie FSDP (enable_fsdp=True) für schnelleres und effizienteres Training.
Unterstützte Instanztypen für das Training
Die folgende Tabelle fasst die unterstützten Instanztypen für das Training verschiedener Modelle zusammen.
| Modell | Standardinstanztyp | Unterstützte Instanztypen |
| Code Lama 2 7B | ml.g5.12xgroß |
ml.g5.12xgroß, ml.g5.24xgroß, ml.g5.48xgroß, ml.p3dn.24xlarge, ml.g4dn.12xgroß |
| Code Lama 2 13B | ml.g5.12xgroß |
ml.g5.24xgroß, ml.g5.48xgroß, ml.p3dn.24xlarge, ml.g4dn.12xgroß |
| Code Lama 2 70B | ml.g5.48xgroß |
ml.g5.48xgroß ml.p4d.24xgroß |
Berücksichtigen Sie bei der Auswahl des Instanztyps Folgendes:
- G5-Instanzen bieten das effizienteste Training unter den unterstützten Instanztypen. Wenn Sie also G5-Instanzen zur Verfügung haben, sollten Sie diese verwenden.
- Die Trainingszeit hängt weitgehend von der Anzahl der GPUs und dem verfügbaren CUDA-Speicher ab. Daher ist das Training auf Instanzen mit der gleichen Anzahl an GPUs (z. B. ml.g5.2xlarge und ml.g5.4xlarge) ungefähr gleich. Daher können Sie für das Training die günstigere Instanz verwenden (ml.g5.2xlarge).
- Bei Verwendung von p3-Instanzen erfolgt das Training mit 32-Bit-Präzision, da bfloat16 auf diesen Instanzen nicht unterstützt wird. Daher verbraucht der Trainingsjob beim Training auf p3-Instanzen doppelt so viel CUDA-Speicher wie auf g5-Instanzen.
Informationen zu den Schulungskosten pro Instanz finden Sie unter Amazon EC2 G5-Instanzen.
Evaluierung
Die Evaluierung ist ein wichtiger Schritt zur Beurteilung der Leistung fein abgestimmter Modelle. Wir präsentieren sowohl qualitative als auch quantitative Bewertungen, um die Verbesserung fein abgestimmter Modelle gegenüber nicht fein abgestimmten Modellen aufzuzeigen. In der qualitativen Auswertung zeigen wir eine Beispielantwort sowohl von fein abgestimmten als auch von nicht fein abgestimmten Modellen. Bei der quantitativen Auswertung verwenden wir HumanEval, eine von OpenAI entwickelte Testsuite zur Generierung von Python-Code, um die Fähigkeit zu testen, korrekte und genaue Ergebnisse zu erzielen. Das HumanEval-Repository steht unter MIT-Lizenz. Wir haben die Python-Varianten aller Code LIama-Modelle in verschiedenen Größen optimiert (Code LIama Python 7B, 13B, 34B und 70B). Dolphin Coder-Datensatz) und präsentieren die Auswertungsergebnisse in den folgenden Abschnitten.
Qualitativ bewerten
Sobald Ihr fein abgestimmtes Modell bereitgestellt ist, können Sie damit beginnen, den Endpunkt zum Generieren von Code zu verwenden. Im folgenden Beispiel präsentieren wir Antworten sowohl von Basis- als auch von fein abgestimmten Code LIama 34B-Python-Varianten auf ein Testbeispiel im Dolphin Coder-Datensatz:
Das fein abgestimmte Code-Lama-Modell liefert nicht nur den Code für die vorherige Abfrage, sondern generiert auch eine detaillierte Erklärung des Ansatzes und einen Pseudocode.
Code Llama 34b Python Nicht fein abgestimmte Antwort:
Code Llama 34B Python Feinabgestimmte Antwort
Grundwahrheit
Interessanterweise bietet unsere optimierte Version von Code Llama 34B Python eine auf dynamischer Programmierung basierende Lösung für den längsten palindromischen Teilstring, die sich von der in der Grundwahrheit des ausgewählten Testbeispiels bereitgestellten Lösung unterscheidet. Unser fein abgestimmtes Modell begründet und erklärt die auf dynamischer Programmierung basierende Lösung im Detail. Andererseits halluziniert das nicht fein abgestimmte Modell potenzielle Ausgaben direkt nach dem print Anweisung (in der linken Zelle angezeigt) als Ausgabe axyzzyx ist nicht das längste Palindrom in der angegebenen Zeichenfolge. In Bezug auf die zeitliche Komplexität ist die dynamische Programmierlösung im Allgemeinen besser als der ursprüngliche Ansatz. Die dynamische Programmierlösung hat eine Zeitkomplexität von O(n^2), wobei n die Länge der Eingabezeichenfolge ist. Dies ist effizienter als die ursprüngliche Lösung des nicht fein abgestimmten Modells, das ebenfalls eine quadratische Zeitkomplexität von O(n^2) hatte, jedoch einen weniger optimierten Ansatz hatte.
Das sieht vielversprechend aus! Denken Sie daran, dass wir die Code-LIama-Python-Variante nur mit 10 % verfeinert haben Dolphin Coder-Datensatz. Es gibt noch viel mehr zu entdecken!
Trotz ausführlicher Anweisungen in der Antwort müssen wir noch die Richtigkeit des in der Lösung bereitgestellten Python-Codes prüfen. Als nächstes verwenden wir ein Bewertungsframework namens Menschliche Bewertung um Integrationstests für die generierte Antwort von Code LIama durchzuführen, um deren Qualität systematisch zu überprüfen.
Quantitative Auswertung mit HumanEval
HumanEval ist ein Evaluierungstool zur Bewertung der Problemlösungsfähigkeiten eines LLM bei Python-basierten Codierungsproblemen, wie im Artikel beschrieben Evaluierung großer Sprachmodelle, die auf Code trainiert wurden. Konkret besteht es aus 164 ursprünglichen Python-basierten Programmierproblemen, die die Fähigkeit eines Sprachmodells bewerten, Code basierend auf bereitgestellten Informationen wie Funktionssignatur, Dokumentzeichenfolge, Hauptteil und Komponententests zu generieren.
Für jede Python-basierte Programmierfrage senden wir sie an ein Code LIama-Modell, das auf einem SageMaker-Endpunkt bereitgestellt wird, um k Antworten zu erhalten. Als Nächstes führen wir jede der k Antworten auf die Integrationstests im HumanEval-Repository aus. Wenn eine der k Antworten die Integrationstests besteht, zählen wir diesen Testfall als erfolgreich. andernfalls fehlgeschlagen. Dann wiederholen wir den Vorgang, um das Verhältnis erfolgreicher Fälle als endgültige Bewertungspunktzahl zu berechnen pass@k. Gemäß der Standardpraxis setzen wir k in unserer Bewertung auf 1, um nur eine Antwort pro Frage zu generieren und zu testen, ob sie den Integrationstest besteht.
Im Folgenden finden Sie einen Beispielcode zur Verwendung des HumanEval-Repositorys. Sie können über einen SageMaker-Endpunkt auf den Datensatz zugreifen und eine einzelne Antwort generieren. Einzelheiten finden Sie im Notizbuch im GitHub-Repository.
Die folgende Tabelle zeigt die Verbesserungen der fein abgestimmten Code LIama Python-Modelle gegenüber den nicht fein abgestimmten Modellen in verschiedenen Modellgrößen. Um die Korrektheit sicherzustellen, stellen wir auch die nicht fein abgestimmten Code-LIama-Modelle in SageMaker-Endpunkten bereit und führen Human-Eval-Bewertungen durch. Der pass@1 Zahlen (die erste Zeile in der folgenden Tabelle) stimmen mit den gemeldeten Zahlen im überein Code-Lama-Forschungspapier. Die Inferenzparameter werden konsistent als festgelegt "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
Wie wir aus den Ergebnissen ersehen können, zeigen alle fein abgestimmten Code-LIama-Python-Varianten eine deutliche Verbesserung gegenüber den nicht fein abgestimmten Modellen. Insbesondere Code LIama Python 70B übertrifft das nicht fein abgestimmte Modell um etwa 12 %.
| . | 7B Python | 13B Python | 34 Mrd | 34B Python | 70B Python |
| Leistung des vorab trainierten Modells (bestanden@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| Feinabstimmung der Modellleistung (durchlauf@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
Jetzt können Sie versuchen, Code LIama-Modelle an Ihrem eigenen Datensatz zu optimieren.
Aufräumen
Wenn Sie entscheiden, dass Sie den SageMaker-Endpunkt nicht mehr laufen lassen möchten, können Sie ihn mit löschen AWS SDK für Python (Boto3), AWS-Befehlszeilenschnittstelle (AWS CLI) oder SageMaker-Konsole. Weitere Informationen finden Sie unter Endpunkte und Ressourcen löschen. Darüber hinaus können Sie Fahren Sie die SageMaker Studio-Ressourcen herunter die nicht mehr benötigt werden.
Zusammenfassung
In diesem Beitrag haben wir die Feinabstimmung der Code Llama 2-Modelle von Meta mit SageMaker JumpStart besprochen. Wir haben gezeigt, dass Sie die SageMaker JumpStart-Konsole in SageMaker Studio oder das SageMaker Python SDK verwenden können, um diese Modelle zu optimieren und bereitzustellen. Wir haben auch die Feinabstimmungstechnik, Instanztypen und unterstützte Hyperparameter besprochen. Darüber hinaus haben wir anhand verschiedener von uns durchgeführter Tests Empfehlungen für ein optimiertes Training gegeben. Wie wir aus diesen Ergebnissen der Feinabstimmung von drei Modellen über zwei Datensätze sehen können, verbessert die Feinabstimmung die Zusammenfassung im Vergleich zu nicht feinabgestimmten Modellen. Als nächsten Schritt können Sie versuchen, diese Modelle mithilfe des im GitHub-Repository bereitgestellten Codes an Ihrem eigenen Datensatz zu optimieren, um die Ergebnisse für Ihre Anwendungsfälle zu testen und zu vergleichen.
Über die Autoren
 Xin Huang ist Senior Applied Scientist für Amazon SageMaker JumpStart und die integrierten Algorithmen von Amazon SageMaker. Er konzentriert sich auf die Entwicklung skalierbarer Algorithmen für maschinelles Lernen. Seine Forschungsinteressen liegen im Bereich der Verarbeitung natürlicher Sprache, erklärbares Deep Learning auf tabellarischen Daten und robuste Analyse von nichtparametrischem Raum-Zeit-Clustering. Er hat viele Artikel auf ACL-, ICDM-, KDD-Konferenzen und der Royal Statistical Society: Series A veröffentlicht.
Xin Huang ist Senior Applied Scientist für Amazon SageMaker JumpStart und die integrierten Algorithmen von Amazon SageMaker. Er konzentriert sich auf die Entwicklung skalierbarer Algorithmen für maschinelles Lernen. Seine Forschungsinteressen liegen im Bereich der Verarbeitung natürlicher Sprache, erklärbares Deep Learning auf tabellarischen Daten und robuste Analyse von nichtparametrischem Raum-Zeit-Clustering. Er hat viele Artikel auf ACL-, ICDM-, KDD-Konferenzen und der Royal Statistical Society: Series A veröffentlicht.
 Vishaal Yalamanchali ist ein Startup-Lösungsarchitekt, der mit generativen KI-, Robotik- und autonomen Fahrzeugunternehmen im Frühstadium arbeitet. Vishaal arbeitet mit seinen Kunden zusammen, um hochmoderne ML-Lösungen bereitzustellen, und interessiert sich persönlich für Reinforcement Learning, LLM-Bewertung und Codegenerierung. Vor seiner Zeit bei AWS war Vishaal Student an der UCI mit Schwerpunkt auf Bioinformatik und intelligenten Systemen.
Vishaal Yalamanchali ist ein Startup-Lösungsarchitekt, der mit generativen KI-, Robotik- und autonomen Fahrzeugunternehmen im Frühstadium arbeitet. Vishaal arbeitet mit seinen Kunden zusammen, um hochmoderne ML-Lösungen bereitzustellen, und interessiert sich persönlich für Reinforcement Learning, LLM-Bewertung und Codegenerierung. Vor seiner Zeit bei AWS war Vishaal Student an der UCI mit Schwerpunkt auf Bioinformatik und intelligenten Systemen.
 Meenakshisundaram Thandavarayan arbeitet für AWS als KI/ML-Spezialist. Seine Leidenschaft ist es, menschenzentrierte Daten- und Analyseerlebnisse zu entwerfen, zu erstellen und zu fördern. Meena konzentriert sich auf die Entwicklung nachhaltiger Systeme, die messbare Wettbewerbsvorteile für strategische Kunden von AWS bieten. Meena ist eine Connector- und Design-Denkerin und strebt danach, Unternehmen durch Innovation, Inkubation und Demokratisierung zu neuen Arbeitsweisen zu bewegen.
Meenakshisundaram Thandavarayan arbeitet für AWS als KI/ML-Spezialist. Seine Leidenschaft ist es, menschenzentrierte Daten- und Analyseerlebnisse zu entwerfen, zu erstellen und zu fördern. Meena konzentriert sich auf die Entwicklung nachhaltiger Systeme, die messbare Wettbewerbsvorteile für strategische Kunden von AWS bieten. Meena ist eine Connector- und Design-Denkerin und strebt danach, Unternehmen durch Innovation, Inkubation und Demokratisierung zu neuen Arbeitsweisen zu bewegen.
 Dr. Ashish Khetan ist Senior Applied Scientist mit integrierten Amazon SageMaker-Algorithmen und hilft bei der Entwicklung von Algorithmen für maschinelles Lernen. Er promovierte an der University of Illinois Urbana-Champaign. Er ist ein aktiver Forscher auf dem Gebiet des maschinellen Lernens und der statistischen Inferenz und hat viele Artikel auf den Konferenzen NeurIPS, ICML, ICLR, JMLR, ACL und EMNLP veröffentlicht.
Dr. Ashish Khetan ist Senior Applied Scientist mit integrierten Amazon SageMaker-Algorithmen und hilft bei der Entwicklung von Algorithmen für maschinelles Lernen. Er promovierte an der University of Illinois Urbana-Champaign. Er ist ein aktiver Forscher auf dem Gebiet des maschinellen Lernens und der statistischen Inferenz und hat viele Artikel auf den Konferenzen NeurIPS, ICML, ICLR, JMLR, ACL und EMNLP veröffentlicht.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

