Maschinelles Lernen (ML) revolutioniert branchenübergreifend Lösungen und fördert neue Formen von Erkenntnissen und Intelligenz aus Daten. Viele ML-Algorithmen trainieren große Datensätze, verallgemeinern Muster, die sie in den Daten finden, und leiten Ergebnisse aus diesen Mustern ab, wenn neue, unsichtbare Datensätze verarbeitet werden. Wenn der Datensatz oder das Modell zu groß ist, um auf einer einzelnen Instanz trainiert zu werden, verteiltes Training ermöglicht die Verwendung mehrerer Instanzen innerhalb eines Clusters und die Verteilung von Daten oder Modellpartitionen auf diese Instanzen während des Trainingsprozesses. Native Unterstützung für verteilte Schulungen wird über angeboten Amazon Sage Maker SDK, zusammen mit Beispiel Notizbücher in gängigen Frameworks.
Aufgrund von Sicherheits- und Datenschutzbestimmungen innerhalb oder zwischen Organisationen werden die Daten jedoch manchmal dezentral über mehrere Konten oder in verschiedenen Regionen verteilt und können nicht in einem Konto oder über mehrere Regionen hinweg zentralisiert werden. In diesem Fall sollte föderiertes Lernen (FL) in Betracht gezogen werden, um ein verallgemeinertes Modell für die gesamten Daten zu erhalten.
In diesem Beitrag diskutieren wir, wie man föderiertes Lernen auf Amazon SageMaker implementiert, um ML mit dezentralen Trainingsdaten auszuführen.
Was ist föderiertes Lernen?
Federated Learning ist ein ML-Ansatz, der es ermöglicht, mehrere separate Trainingssitzungen parallel laufen zu lassen, um über große Grenzen hinweg, beispielsweise geografisch, zu laufen und die Ergebnisse zu aggregieren, um dabei ein verallgemeinertes Modell (globales Modell) zu erstellen. Genauer gesagt verwendet jede Trainingssitzung ihren eigenen Datensatz und erhält ihr eigenes lokales Modell. Lokale Modelle in verschiedenen Trainingssitzungen werden während des Trainingsprozesses zu einem globalen Modell aggregiert (z. B. Modellgewichtungsaggregation). Dieser Ansatz steht im Gegensatz zu zentralisierten ML-Techniken, bei denen Datensätze für eine Trainingssitzung zusammengeführt werden.
Föderiertes Lernen vs. verteiltes Training in der Cloud
Wenn diese beiden Ansätze in der Cloud ausgeführt werden, erfolgt das verteilte Training in einer Region auf einem Konto und die Trainingsdaten beginnen mit einer zentralisierten Trainingssitzung oder einem zentralen Job. Während des verteilten Trainingsprozesses wird der Datensatz in kleinere Teilmengen aufgeteilt und je nach Strategie (Datenparallelität oder Modellparallelität) werden Teilmengen an verschiedene Trainingsknoten gesendet oder durchlaufen Knoten in einem Trainingscluster, was bedeutet, dass einzelne Daten dies nicht unbedingt tun müssen Bleiben Sie in einem Knoten des Clusters.
Im Gegensatz dazu erfolgt die Schulung beim föderierten Lernen normalerweise in mehreren separaten Konten oder über mehrere Regionen hinweg. Jedes Konto oder jede Region verfügt über eigene Trainingsinstanzen. Die Trainingsdaten werden von Anfang bis Ende dezentral über Konten oder Regionen verteilt, und einzelne Daten werden während des föderierten Lernprozesses nur von der jeweiligen Trainingssitzung oder dem jeweiligen Job zwischen verschiedenen Konten oder Regionen gelesen.
Blumen-Lernrahmen
Für föderiertes Lernen stehen mehrere Open-Source-Frameworks zur Verfügung, z FATE, BLÜTEN, PySyft, OpenFL, FedML, NVFlare und Tensorflow Federated. Bei der Auswahl eines FL-Frameworks berücksichtigen wir normalerweise dessen Unterstützung für Modellkategorie, ML-Framework und Gerät oder Betriebssystem. Wir müssen auch die Erweiterbarkeit und Paketgröße des FL-Frameworks berücksichtigen, um es effizient in der Cloud ausführen zu können. In diesem Beitrag wählen wir ein leicht erweiterbares, anpassbares und leichtes Framework, Flower, für die FL-Implementierung mit SageMaker.
Flower ist ein umfassendes FL-Framework, das sich von bestehenden Frameworks dadurch unterscheidet, dass es neue Möglichkeiten zur Durchführung groß angelegter FL-Experimente bietet und äußerst heterogene FL-Geräteszenarien ermöglicht. FL löst Herausforderungen im Zusammenhang mit Datenschutz und Skalierbarkeit in Szenarien, in denen der Datenaustausch nicht möglich ist.
Gestaltungsprinzipien und Umsetzung von Flower FL
Flower FL ist vom Design her sprachunabhängig und ML-Framework-unabhängig, ist vollständig erweiterbar und kann neue Algorithmen, Trainingsstrategien und Kommunikationsprotokolle integrieren. Flower ist Open-Source unter der Apache 2.0-Lizenz.
Die konzeptionelle Architektur der FL-Implementierung wird im Papier beschrieben Flower: Ein freundliches Federated Learning Framework und ist in der folgenden Abbildung hervorgehoben.

In dieser Architektur leben Edge-Clients auf echten Edge-Geräten und kommunizieren über RPC mit dem Server. Virtuelle Clients hingegen verbrauchen im inaktiven Zustand nahezu keine Ressourcen und laden Modelle und Daten nur dann in den Speicher, wenn der Client für Training oder Evaluierung ausgewählt wird.
Der Flower-Server erstellt die Strategie und Konfigurationen, die an die Flower-Clients gesendet werden. Es serialisiert diese Konfigurationswörterbücher (bzw config dict (kurz) in ihre ProtoBuf-Darstellung, transportiert sie mithilfe von gRPC zum Client und deserialisiert sie dann zurück in Python-Wörterbücher.
Flower FL-Strategien
Flower ermöglicht die Anpassung des Lernprozesses durch Strategieabstraktion. Die Strategie definiert den gesamten Verbundprozess und gibt die Parameterinitialisierung (unabhängig davon, ob es sich um eine Server- oder Client-Initialisierung handelt), die Mindestanzahl verfügbarer Clients, die für die Initialisierung eines Laufs erforderlich sind, die Gewichtung der Client-Beiträge sowie Trainings- und Bewertungsdetails an.
Flower verfügt über eine umfassende Implementierung von FL-Mittelungsalgorithmen und einen robusten Kommunikationsstapel. Eine Liste der implementierten Mittelungsalgorithmen und zugehörigen Forschungsarbeiten finden Sie in der folgenden Tabelle von Flower: Ein freundliches Federated Learning Framework.

Föderiertes Lernen mit SageMaker: Lösungsarchitektur
Eine föderierte Lernarchitektur unter Verwendung von SageMaker mit dem Flower-Framework wird auf der Grundlage bidirektionaler gRPC-Streams (Foundation) implementiert. gRPC definiert die Arten der ausgetauschten Nachrichten und verwendet Compiler, um dann eine effiziente Implementierung für Python zu generieren, kann aber auch die Implementierung für andere Sprachen wie Java oder C++ generieren.
Die Flower-Clients erhalten Anweisungen (Nachrichten) als Rohbyte-Arrays über das Netzwerk. Anschließend deserialisieren die Clients die Anweisung und führen sie aus (Training für lokale Daten). Die Ergebnisse (Modellparameter und Gewichte) werden dann serialisiert und an den Server zurückkommuniziert.
Die Server-/Client-Architektur für Flower FL wird in SageMaker mithilfe von Notebook-Instanzen in verschiedenen Konten in derselben Region wie der Flower-Server und der Flower-Client definiert. Auf dem Server werden die Trainings- und Evaluierungsstrategien sowie die globalen Parameter definiert, dann wird die Konfiguration serialisiert und über VPC-Peering an den Client gesendet.
Der Notebook-Instanz-Client startet einen SageMaker-Trainingsjob, der ein benutzerdefiniertes Skript ausführt, um die Instanziierung des Flower-Clients auszulösen, der die Serverkonfiguration deserialisiert und liest, den Trainingsjob auslöst und die Parameterantwort sendet.
Der letzte Schritt erfolgt auf dem Server, wenn die Auswertung der neu aggregierten Parameter nach Abschluss der in der Serverstrategie festgelegten Anzahl an Läufen und Clients ausgelöst wird. Die Auswertung erfolgt anhand eines Testdatensatzes, der nur auf dem Server vorhanden ist, und die neuen verbesserten Genauigkeitsmetriken werden erstellt.
Das folgende Diagramm veranschaulicht die Architektur des FL-Setups auf SageMaker mit dem Flower-Paket.
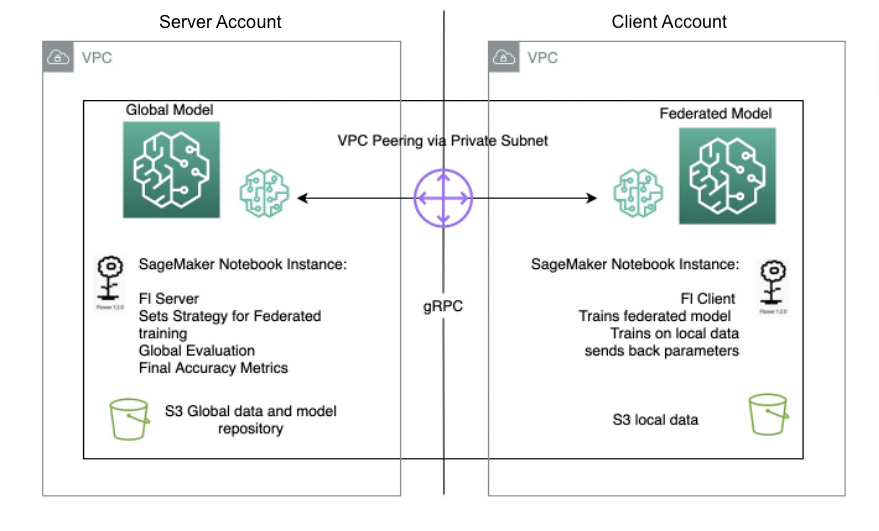
Implementieren Sie föderiertes Lernen mit SageMaker
SageMaker ist ein vollständig verwalteter ML-Dienst. Mit SageMaker können Datenwissenschaftler und Entwickler schnell ML-Modelle erstellen und trainieren und sie dann in einer produktionsbereiten gehosteten Umgebung bereitstellen.
In diesem Beitrag zeigen wir, wie Sie die verwaltete ML-Plattform verwenden, um mithilfe von SageMaker-Trainingsjobs eine Notebook-Erlebnisumgebung bereitzustellen und föderiertes Lernen über AWS-Konten hinweg durchzuführen. Die rohen Trainingsdaten verlassen niemals das Konto, dem die Daten gehören, und nur die abgeleiteten Gewichtungen werden über die Peer-Verbindung gesendet.
In diesem Beitrag heben wir die folgenden Kernkomponenten hervor:
- Networking – SageMaker ermöglicht die schnelle Einrichtung der Standard-Netzwerkkonfiguration und ermöglicht Ihnen gleichzeitig die vollständige Anpassung des Netzwerks an die Anforderungen Ihres Unternehmens. Wir benutzen ein VPC-Peering-Konfiguration in diesem Beispiel innerhalb der Region.
- Einstellungen für den kontoübergreifenden Zugriff – Um einem Benutzer im Serverkonto zu ermöglichen, einen Modelltrainingsjob im Clientkonto zu starten, haben wir Delegieren Sie den Zugriff über Konten hinweg Verwendung von AWS Identity and Access Management and (IAM)-Rollen. Auf diese Weise muss sich ein Benutzer im Serverkonto nicht vom Konto abmelden und sich beim Clientkonto anmelden, um Aktionen auf SageMaker durchzuführen. Diese Einstellung dient nur zum Starten von SageMaker-Schulungsjobs und beinhaltet keine kontoübergreifende Datenzugriffsberechtigung oder -freigabe.
- Implementieren des Verbundlern-Clientcodes im Clientkonto und des Servercodes im Serverkonto – Wir implementieren den Client-Code für föderiertes Lernen im Kundenkonto, indem wir das Flower-Paket und das von SageMaker verwaltete Training verwenden. In der Zwischenzeit implementieren wir Servercode im Serverkonto mithilfe des Flower-Pakets.
VPC-Peering einrichten
Eine VPC-Peering-Verbindung ist eine Netzwerkverbindung zwischen zwei VPCs, die es Ihnen ermöglicht, Datenverkehr zwischen ihnen über private IPv4-Adressen oder IPv6-Adressen weiterzuleiten. Instanzen in beiden VPCs können miteinander kommunizieren, als ob sie sich im selben Netzwerk befänden.
Um eine VPC-Peering-Verbindung einzurichten, erstellen Sie zunächst eine Peer-Anfrage mit einer anderen VPC. Sie können eine VPC-Peering-Verbindung mit einer anderen VPC im selben Konto anfordern oder in unserem Anwendungsfall eine Verbindung mit einer VPC in einem anderen AWS-Konto herstellen. Um die Anfrage zu aktivieren, muss der Eigentümer der VPC die Anfrage akzeptieren. Weitere Informationen zum VPC-Peering finden Sie unter Erstellen Sie eine VPC-Peering-Verbindung.
Starten Sie SageMaker-Notebook-Instanzen in VPCs
Eine SageMaker-Notebook-Instanz stellt eine Jupyter-Notebook-App über ein vollständig verwaltetes ML bereit Amazon Elastic Compute-Cloud (Amazon EC2) Instanz. SageMaker Jupyter-Notebooks werden verwendet, um erweiterte Datenexplorationen durchzuführen, Trainingsjobs zu erstellen, Modelle auf dem SageMaker-Hosting bereitzustellen und Ihre Modelle zu testen oder zu validieren.
Der Notebook-Instanz stehen verschiedene Netzwerkkonfigurationen zur Verfügung. In diesem Setup wird die Notebook-Instanz in einem privaten Subnetz der VPC ausgeführt und hat keinen direkten Internetzugang.

Konfigurieren Sie die Einstellungen für den kontoübergreifenden Zugriff
Zu den kontoübergreifenden Zugriffseinstellungen gehören zwei Schritte zum Delegieren des Zugriffs vom Serverkonto zum Clientkonto mithilfe von IAM-Rollen:
- Erstellen Sie eine IAM-Rolle im Kundenkonto.
- Gewähren Sie Zugriff auf die Rolle im Serverkonto.
Ausführliche Schritte zum Einrichten eines ähnlichen Szenarios finden Sie unter Delegieren Sie den Zugriff über AWS-Konten hinweg mithilfe von IAM-Rollen.
Im Kundenkonto erstellen wir eine IAM-Rolle namens FL-kickoff-client-job mit der Politik FL-sagemaker-actions an die Rolle gebunden. Der FL-sagemaker-actions Die Richtlinie hat den folgenden JSON-Inhalt:
Anschließend ändern wir die Vertrauensrichtlinie in den Vertrauensbeziehungen des FL-kickoff-client-job Rolle:
Im Serverkonto werden einem vorhandenen Benutzer Berechtigungen hinzugefügt (z. B. developer), um den Wechsel zu ermöglichen FL-kickoff-client-job Rolle im Kundenkonto. Dazu erstellen wir eine Inline-Richtlinie namens FL-allow-kickoff-client-job und hängen Sie es an den Benutzer an. Das Folgende ist der JSON-Inhalt der Richtlinie:
Beispieldatensatz und Datenaufbereitung
In diesem Beitrag verwenden wir a kuratierter Datensatz zur Betrugserkennung in den von der veröffentlichten Daten von Medicare-Anbietern Zentren für Medicare & Medicaid Services (CMS). Die Daten werden in einen Trainingsdatensatz und einen Testdatensatz aufgeteilt. Da es sich bei den meisten Daten nicht um Betrug handelt, wenden wir uns an SMOTEN um den Trainingsdatensatz auszugleichen und den Trainingsdatensatz weiter in Trainings- und Validierungsteile aufzuteilen. Sowohl die Trainings- als auch die Validierungsdaten werden in eine hochgeladen Amazon Simple Storage-Service (Amazon S3)-Bucket für das Modelltraining im Clientkonto, und der Testdatensatz wird im Serverkonto nur zu Testzwecken verwendet. Einzelheiten zum Datenvorbereitungscode finden Sie im Folgenden Notizbuch.
Mit dem SageMaker vorgefertigte Docker-Images für das Scikit-Learn-Framework und dem von SageMaker verwalteten Trainingsprozess trainieren wir mithilfe von föderiertem Lernen ein logistisches Regressionsmodell für diesen Datensatz.
Implementieren Sie einen Verbundlern-Client im Kundenkonto
In der SageMaker-Notebook-Instanz des Kundenkontos bereiten wir eine vor client.py Skript und ein utils.py Skript. Die client.py Die Datei enthält Code für den Client und die utils.py Die Datei enthält Code für einige der Dienstprogrammfunktionen, die für unser Training benötigt werden. Wir verwenden das scikit-learn-Paket, um das logistische Regressionsmodell zu erstellen.
In client.py, definieren wir einen Flower-Client. Der Client wird von der Klasse abgeleitet fl.client.NumPyClient. Es müssen die folgenden drei Methoden definiert werden:
- get_parameters – Es gibt die aktuellen lokalen Modellparameter zurück. Die Utility-Funktion
get_model_parameterswerde das tun. - passen – Es definiert die Schritte zum Trainieren des Modells anhand der Trainingsdaten im Kundenkonto. Außerdem erhält es globale Modellparameter und andere Konfigurationsinformationen vom Server. Wir aktualisieren die Parameter des lokalen Modells mithilfe der empfangenen globalen Parameter und trainieren es weiterhin anhand des Datensatzes im Kundenkonto. Diese Methode sendet außerdem die Parameter des lokalen Modells nach dem Training, die Größe des Trainingssatzes und ein Wörterbuch, das beliebige Werte an den Server zurückmeldet.
- bewerten – Es wertet die bereitgestellten Parameter anhand der Validierungsdaten im Kundenkonto aus. Es gibt den Verlust zusammen mit anderen Details wie der Größe des Validierungssatzes und der Genauigkeit an den Server zurück.
Das Folgende ist ein Codeausschnitt für die Flower-Client-Definition:
Wir verwenden dann SageMaker Skriptmodus um den Rest vorzubereiten client.py Datei. Dazu gehört das Definieren von Parametern, die an das SageMaker-Training übergeben werden, das Laden von Trainings- und Validierungsdaten, das Initialisieren und Trainieren des Modells auf dem Client, das Einrichten des Flower-Clients für die Kommunikation mit dem Server und schließlich das Speichern des trainierten Modells.
utils.py enthält einige Dienstfunktionen, die aufgerufen werden client.py:
- get_model_parameters – Es gibt das scikit-learn zurück Logistische Regression Modellparameter.
- set_model_params – Es legt die Parameter des Modells fest.
- set_initial_params – Es initialisiert die Parameter des Modells als Nullen. Dies ist erforderlich, da der Server beim Start erste Modellparameter vom Client anfordert. Im Scikit-Learn-Framework gilt jedoch
LogisticRegressionModellparameter werden erst initialisiertmodel.fit()wird genannt. - lade Daten – Es lädt die Trainings- und Testdaten.
- save_model – Es speichert das Modell als
.joblibDatei.
Weil Flower kein Paket ist, das im installiert ist Von SageMaker vorgefertigter Scikit-Learn-Docker-Container, wir listen auf flwr==1.3.0 in einem requirements.txt Datei.
Wir haben alle drei Dateien abgelegt (client.py, utils.py und requirements.txt) in einen Ordner und tar-komprimieren Sie es. Die .tar.gz-Datei (benannt source.tar.gz in diesem Beitrag) wird dann in einen S3-Bucket im Kundenkonto hochgeladen.
Implementieren Sie einen Verbundlernserver im Serverkonto
Im Serverkonto bereiten wir Code auf einem Jupyter-Notebook vor. Dies umfasst zwei Teile: Der Server übernimmt zunächst die Rolle, einen Trainingsjob im Client-Konto zu starten, dann verbindet der Server das Modell mithilfe von Flower.
Übernehmen Sie eine Rolle zum Ausführen des Trainingsjobs im Kundenkonto
Wir nutzen die Boto3-Python-SDK ein AWS-Sicherheitstoken-Service (AWS STS)-Client, um das zu übernehmen FL-kickoff-client-job Rolle und richten Sie einen SageMaker-Client ein, um mithilfe des von SageMaker verwalteten Trainingsprozesses einen Trainingsjob im Client-Konto auszuführen:
Mithilfe der angenommenen Rolle erstellen wir einen SageMaker-Schulungsauftrag im Kundenkonto. Der Trainingsjob nutzt das in SageMaker integrierte Scikit-Learn-Framework. Beachten Sie, dass sich alle S3-Buckets und die SageMaker IAM-Rolle im folgenden Codeausschnitt auf das Kundenkonto beziehen:
Aggregieren Sie lokale Modelle mithilfe von Flower zu einem globalen Modell
Wir bereiten Code vor, um das Modell auf dem Server zu föderieren. Dazu gehört die Definition der Strategie für den Verbund und seiner Initialisierungsparameter. Wir verwenden Utility-Funktionen in der utils.py Das zuvor beschriebene Skript dient zum Initialisieren und Festlegen von Modellparametern. Mit Flower können Sie Ihre eigenen Rückruffunktionen definieren, um eine bestehende Strategie anzupassen. Wir benutzen das FedDurchschn Strategie mit benutzerdefinierten Rückrufen zur Bewertung und Anpassungskonfiguration. Siehe den folgenden Code:
Die folgenden zwei Funktionen werden im vorherigen Codeausschnitt erwähnt:
- fit_round – Es wird verwendet, um die runde Zahl an den Client zu senden. Wir übergeben diesen Rückruf als
on_fit_config_fnParameter der Strategie. Wir tun dies lediglich, um die Verwendung von zu demonstrierenon_fit_config_fnParameters. - get_evaluate_fn – Es wird zur Modellbewertung auf dem Server verwendet.
Für Demozwecke verwenden wir den Testdatensatz, den wir bei der Datenvorbereitung reserviert haben, um das aus dem Konto des Kunden föderierte Modell zu bewerten und das Ergebnis an den Kunden zurückzumelden. Es ist jedoch zu beachten, dass in fast allen realen Anwendungsfällen die im Serverkonto verwendeten Daten nicht von dem im Clientkonto verwendeten Datensatz getrennt werden.
Nachdem der föderierte Lernprozess abgeschlossen ist, a model.tar.gz Die Datei wird von SageMaker als Modellartefakt in einem S3-Bucket im Kundenkonto gespeichert. Mittlerweile a model.joblib Die Datei wird auf der SageMaker Notebook-Instanz im Serverkonto gespeichert. Zuletzt verwenden wir den Testdatensatz, um das endgültige Modell zu testen (model.joblib) auf dem Server. Die Testausgabe des endgültigen Modells lautet wie folgt:
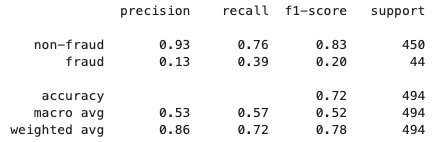
Aufräumen
Wenn Sie fertig sind, bereinigen Sie die Ressourcen sowohl im Serverkonto als auch im Clientkonto, um zusätzliche Kosten zu vermeiden:
- Stoppen Sie die SageMaker-Notebook-Instanzen.
- Löschen Sie VPC-Peering-Verbindungen und entsprechende VPCs.
- Leeren und löschen Sie den S3-Bucket, den Sie für die Datenspeicherung erstellt haben.
Zusammenfassung
In diesem Beitrag haben wir erläutert, wie Sie mit dem Flower-Paket föderiertes Lernen auf SageMaker implementieren. Wir haben gezeigt, wie man VPC-Peering konfiguriert, den kontoübergreifenden Zugriff einrichtet und den FL-Client und -Server implementiert. Dieser Beitrag ist nützlich für diejenigen, die ML-Modelle auf SageMaker unter Verwendung dezentraler Daten über Konten hinweg mit eingeschränkter Datenfreigabe trainieren müssen. Da die FL in diesem Beitrag mit SageMaker implementiert wird, ist es erwähnenswert, dass noch viel mehr Funktionen in SageMaker in den Prozess einbezogen werden können.
Durch die Implementierung von föderiertem Lernen auf SageMaker können Sie alle erweiterten Funktionen nutzen, die SageMaker im Laufe des ML-Lebenszyklus bietet. Es gibt andere Möglichkeiten, föderiertes Lernen in der AWS Cloud zu erreichen oder anzuwenden, beispielsweise durch die Verwendung von EC2-Instanzen oder am Edge. Einzelheiten zu diesen alternativen Ansätzen finden Sie unter Federated Learning auf AWS mit FedML und Anwendung von Federated Learning für ML am Edge.
Über die Autoren
 Sherry Ding ist ein leitender KI/ML-Spezialist für Lösungsarchitekten bei Amazon Web Services (AWS). Sie verfügt über umfangreiche Erfahrung im maschinellen Lernen und hat einen Doktortitel in Informatik. Sie arbeitet hauptsächlich mit Kunden aus dem öffentlichen Sektor an verschiedenen geschäftlichen Herausforderungen im Zusammenhang mit KI/ML und hilft ihnen, ihre Reise zum maschinellen Lernen in der AWS Cloud zu beschleunigen. Wenn sie nicht gerade Kunden betreut, genießt sie Outdoor-Aktivitäten.
Sherry Ding ist ein leitender KI/ML-Spezialist für Lösungsarchitekten bei Amazon Web Services (AWS). Sie verfügt über umfangreiche Erfahrung im maschinellen Lernen und hat einen Doktortitel in Informatik. Sie arbeitet hauptsächlich mit Kunden aus dem öffentlichen Sektor an verschiedenen geschäftlichen Herausforderungen im Zusammenhang mit KI/ML und hilft ihnen, ihre Reise zum maschinellen Lernen in der AWS Cloud zu beschleunigen. Wenn sie nicht gerade Kunden betreut, genießt sie Outdoor-Aktivitäten.
 Lorea Arrizabalaga ist eine auf den britischen öffentlichen Sektor ausgerichtete Lösungsarchitektin, wo sie Kunden bei der Entwicklung von ML-Lösungen mit Amazon SageMaker unterstützt. Sie ist auch Teil der Technical Field Community, die sich der Hardwarebeschleunigung widmet, und hilft beim Testen und Benchmarking von AWS Inferentia- und AWS Trainium-Workloads.
Lorea Arrizabalaga ist eine auf den britischen öffentlichen Sektor ausgerichtete Lösungsarchitektin, wo sie Kunden bei der Entwicklung von ML-Lösungen mit Amazon SageMaker unterstützt. Sie ist auch Teil der Technical Field Community, die sich der Hardwarebeschleunigung widmet, und hilft beim Testen und Benchmarking von AWS Inferentia- und AWS Trainium-Workloads.
 Ben Snively ist ein AWS Public Sector Senior Principal Specialist Solutions Architect. Er arbeitet mit Regierungs-, Non-Profit- und Bildungskunden an Big-Data-, Analyse- und KI/ML-Projekten zusammen und hilft ihnen bei der Entwicklung von Lösungen mit AWS.
Ben Snively ist ein AWS Public Sector Senior Principal Specialist Solutions Architect. Er arbeitet mit Regierungs-, Non-Profit- und Bildungskunden an Big-Data-, Analyse- und KI/ML-Projekten zusammen und hilft ihnen bei der Entwicklung von Lösungen mit AWS.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Automobil / Elektrofahrzeuge, Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- ChartPrime. Verbessern Sie Ihr Handelsspiel mit ChartPrime. Hier zugreifen.
- BlockOffsets. Modernisierung des Eigentums an Umweltkompensationen. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/machine-learning-with-decentralized-training-data-using-federated-learning-on-amazon-sagemaker/

