Dieser Beitrag wurde gemeinsam mit Chaoyang He, Al Nevarez und Salman Avestimehr von FedML verfasst.
Viele Unternehmen implementieren maschinelles Lernen (ML), um ihre Geschäftsentscheidungen durch Automatisierung und die Nutzung großer verteilter Datensätze zu verbessern. Durch den verbesserten Zugriff auf Daten hat ML das Potenzial, beispiellose Geschäftseinblicke und -möglichkeiten zu bieten. Der Austausch roher, nicht bereinigter sensibler Informationen über verschiedene Standorte hinweg birgt jedoch erhebliche Sicherheits- und Datenschutzrisiken, insbesondere in regulierten Branchen wie dem Gesundheitswesen.
Um dieses Problem anzugehen, ist Federated Learning (FL) eine dezentrale und kollaborative ML-Trainingstechnik, die Datenschutz bietet und gleichzeitig Genauigkeit und Wiedergabetreue gewährleistet. Im Gegensatz zum herkömmlichen ML-Training findet das FL-Training an einem isolierten Kundenstandort unter Verwendung einer unabhängigen sicheren Sitzung statt. Der Client teilt nur seine Ausgabemodellparameter mit einem zentralen Server, dem Trainingskoordinator oder Aggregationsserver, und nicht die tatsächlichen Daten, die zum Trainieren des Modells verwendet werden. Dieser Ansatz beseitigt viele Datenschutzbedenken und ermöglicht gleichzeitig eine effektive Zusammenarbeit beim Modelltraining.
Obwohl FL ein Schritt hin zu mehr Datenschutz und Sicherheit ist, ist es keine garantierte Lösung. Unsichere Netzwerke ohne Zugangskontrolle und Verschlüsselung können dennoch sensible Informationen für Angreifer preisgeben. Darüber hinaus können lokal trainierte Informationen private Daten preisgeben, wenn sie durch einen Inferenzangriff rekonstruiert werden. Um diese Risiken zu mindern, verwendet das FL-Modell personalisierte Trainingsalgorithmen sowie eine effektive Maskierung und Parametrisierung, bevor Informationen an den Trainingskoordinator weitergegeben werden. Starke Netzwerkkontrollen an lokalen und zentralen Standorten können das Risiko von Rückschlüssen und Exfiltration weiter reduzieren.
In diesem Beitrag teilen wir einen FL-Ansatz mit FedML, Amazon Elastic Kubernetes-Service (Amazon EKS) und Amazon Sage Maker Verbesserung der Patientenergebnisse bei gleichzeitiger Berücksichtigung von Datenschutz- und Sicherheitsbedenken.
Der Bedarf an föderiertem Lernen im Gesundheitswesen
Das Gesundheitswesen ist in hohem Maße auf verteilte Datenquellen angewiesen, um genaue Vorhersagen und Einschätzungen zur Patientenversorgung zu treffen. Die Einschränkung der verfügbaren Datenquellen zum Schutz der Privatsphäre wirkt sich negativ auf die Genauigkeit der Ergebnisse und letztendlich auf die Qualität der Patientenversorgung aus. Daher stellt ML Herausforderungen für AWS-Kunden dar, die Datenschutz und Sicherheit über verteilte Einheiten hinweg gewährleisten müssen, ohne die Patientenergebnisse zu beeinträchtigen.
Gesundheitsorganisationen müssen bei der Implementierung von FL-Lösungen strenge Compliance-Vorschriften wie den Health Insurance Portability and Accountability Act (HIPAA) in den Vereinigten Staaten einhalten. Die Gewährleistung von Datenschutz, Sicherheit und Compliance wird im Gesundheitswesen noch wichtiger und erfordert robuste Verschlüsselung, Zugriffskontrollen, Prüfmechanismen und sichere Kommunikationsprotokolle. Darüber hinaus enthalten Gesundheitsdatensätze oft komplexe und heterogene Datentypen, was die Datenstandardisierung und Interoperabilität in FL-Umgebungen zu einer Herausforderung macht.
Anwendungsfallübersicht
Der in diesem Beitrag beschriebene Anwendungsfall betrifft Daten zu Herzerkrankungen in verschiedenen Organisationen, auf denen ein ML-Modell Klassifizierungsalgorithmen ausführt, um Herzerkrankungen beim Patienten vorherzusagen. Da es sich bei diesen Daten um organisationsübergreifende Daten handelt, verwenden wir föderiertes Lernen, um die Ergebnisse zusammenzustellen.
Das Datensatz zu Herzerkrankungen vom Machine Learning Repository der University of California Irvine ist ein weit verbreiteter Datensatz für die kardiovaskuläre Forschung und prädiktive Modellierung. Es besteht aus 303 Proben, die jeweils einen Patienten repräsentieren, und enthält eine Kombination aus klinischen und demografischen Merkmalen sowie das Vorliegen oder Fehlen einer Herzerkrankung.
Dieser multivariate Datensatz enthält 76 Attribute in den Patienteninformationen, von denen 14 Attribute am häufigsten für die Entwicklung und Bewertung von ML-Algorithmen verwendet werden, um das Vorliegen einer Herzerkrankung auf der Grundlage der angegebenen Attribute vorherzusagen.
FedML-Framework
Es gibt eine große Auswahl an FL-Frameworks, wir haben uns jedoch für das entschieden FedML-Framework für diesen Anwendungsfall geeignet, da es Open Source ist und mehrere FL-Paradigmen unterstützt. FedML bietet eine beliebte Open-Source-Bibliothek, eine MLOps-Plattform und ein Anwendungsökosystem für FL. Diese erleichtern die Entwicklung und Bereitstellung von FL-Lösungen. Es bietet eine umfassende Suite von Tools, Bibliotheken und Algorithmen, die es Forschern und Praktikern ermöglichen, FL-Algorithmen in einer verteilten Umgebung zu implementieren und damit zu experimentieren. FedML geht auf die Herausforderungen des Datenschutzes, der Kommunikation und der Modellaggregation in Florida ein und bietet eine benutzerfreundliche Oberfläche und anpassbare Komponenten. Mit seinem Fokus auf Zusammenarbeit und Wissensaustausch möchte FedML die Einführung von FL beschleunigen und Innovationen in diesem aufstrebenden Bereich vorantreiben. Das FedML-Framework ist modellunabhängig, einschließlich der kürzlich hinzugefügten Unterstützung für große Sprachmodelle (LLMs). Weitere Informationen finden Sie unter Veröffentlichung von FedLLM: Erstellen Sie mithilfe der FedML-Plattform Ihre eigenen großen Sprachmodelle auf proprietären Daten.
FedML-Oktopus
Systemhierarchie und Heterogenität sind eine zentrale Herausforderung in realen FL-Anwendungsfällen, in denen unterschiedliche Datensilos über unterschiedliche Infrastrukturen mit CPU und GPUs verfügen können. In solchen Szenarien können Sie verwenden FedML-Oktopus.
FedML Octopus ist die industrietaugliche Plattform von Cross-Silo FL für organisations- und kontoübergreifendes Training. In Verbindung mit FedML MLOps ermöglicht es Entwicklern oder Organisationen, von überall und in jedem Umfang auf sichere Weise eine offene Zusammenarbeit durchzuführen. FedML Octopus führt in jedem Datensilo ein verteiltes Trainingsparadigma aus und verwendet synchrone oder asynchrone Trainings.
FedML MLOps
FedML MLOps ermöglicht die lokale Entwicklung von Code, der später mithilfe von FedML-Frameworks überall bereitgestellt werden kann. Bevor Sie mit der Schulung beginnen, müssen Sie ein FedML-Konto erstellen sowie die Server- und Client-Pakete in FedML Octopus erstellen und hochladen. Weitere Einzelheiten finden Sie unter Schritte und Einführung von FedML Octopus: Skalierung von föderiertem Lernen in die Produktion mit vereinfachten MLOps.
Lösungsüberblick
Wir stellen FedML in mehreren EKS-Clustern bereit, die zur Experimentverfolgung in SageMaker integriert sind. Wir gebrauchen Amazon EKS-Blueprints für Terraform die erforderliche Infrastruktur bereitzustellen. EKS Blueprints hilft beim Zusammenstellen vollständiger EKS-Cluster, die vollständig mit der Betriebssoftware ausgestattet sind, die zum Bereitstellen und Betreiben von Workloads erforderlich ist. Mit EKS Blueprints wird die Konfiguration für den gewünschten Zustand der EKS-Umgebung, wie z. B. die Steuerungsebene, Worker-Knoten und Kubernetes-Add-Ons, als Infrastructure-as-Code (IaC)-Blueprint beschrieben. Nachdem ein Blueprint konfiguriert wurde, kann er mithilfe der kontinuierlichen Bereitstellungsautomatisierung zum Erstellen konsistenter Umgebungen über mehrere AWS-Konten und -Regionen hinweg verwendet werden.
Die in diesem Beitrag geteilten Inhalte spiegeln reale Situationen und Erfahrungen wider, es ist jedoch wichtig zu beachten, dass die Umsetzung dieser Situationen an verschiedenen Orten unterschiedlich sein kann. Obwohl wir ein einziges AWS-Konto mit separaten VPCs verwenden, ist es wichtig zu verstehen, dass individuelle Umstände und Konfigurationen unterschiedlich sein können. Daher sollten die bereitgestellten Informationen als allgemeiner Leitfaden dienen und müssen möglicherweise je nach spezifischen Anforderungen und örtlichen Gegebenheiten angepasst werden.
Das folgende Diagramm zeigt unsere Lösungsarchitektur.
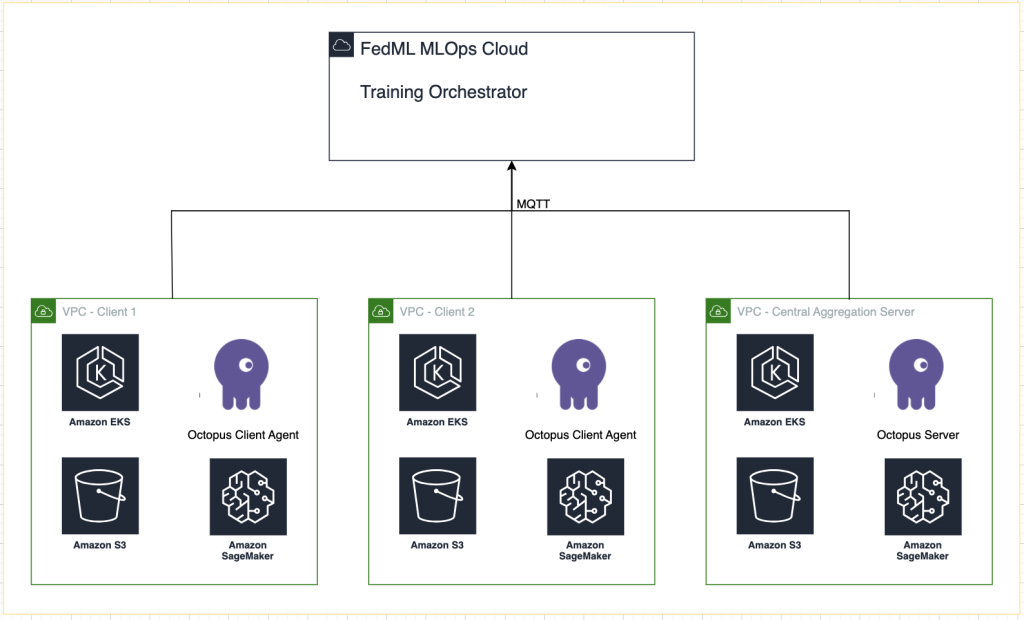
Zusätzlich zum von FedML bereitgestellten Tracking verwenden wir MLOps für jeden Trainingslauf Amazon SageMaker-Experimente um die Leistung jedes Client-Modells und des zentralisierten (Aggregator-)Modells zu verfolgen.
SageMaker Experiments ist eine Funktion von SageMaker, mit der Sie Ihre ML-Experimente erstellen, verwalten, analysieren und vergleichen können. Durch die Aufzeichnung von Experimentdetails, Parametern und Ergebnissen können Forscher ihre Arbeit genau reproduzieren und validieren. Es ermöglicht einen effektiven Vergleich und eine Analyse verschiedener Ansätze und führt zu einer fundierten Entscheidungsfindung. Darüber hinaus erleichtert die Verfolgung von Experimenten die iterative Verbesserung, indem sie Einblicke in den Fortschritt von Modellen liefert und es Forschern ermöglicht, aus früheren Iterationen zu lernen, was letztendlich die Entwicklung effektiverer Lösungen beschleunigt.
Für jeden Lauf senden wir Folgendes an SageMaker Experiments:
- Modellbewertungsmetriken – Trainingsverlust und Area Under the Curve (AUC)
- Hyperparameter – Epoche, Lernrate, Batchgröße, Optimierer und Gewichtsabfall
Voraussetzungen:
Um diesem Beitrag folgen zu können, sollten Sie die folgenden Voraussetzungen erfüllen:
Stellen Sie die Lösung bereit
Klonen Sie zunächst das Repository, das den Beispielcode lokal hostet:
Stellen Sie dann die Anwendungsfall-Infrastruktur mit den folgenden Befehlen bereit:
Die vollständige Bereitstellung der Terraform-Vorlage kann 20 bis 30 Minuten dauern. Befolgen Sie nach der Bereitstellung die Schritte in den nächsten Abschnitten, um die FL-Anwendung auszuführen.
Erstellen Sie ein MLOps-Bereitstellungspaket
Als Teil der FedML-Dokumentation müssen wir die Client- und Serverpakete erstellen, die die MLOps-Plattform an den Server und die Clients verteilt, um mit dem Training zu beginnen.
Um diese Pakete zu erstellen, führen Sie das folgende Skript aus, das sich im Stammverzeichnis befindet:
Dadurch werden die entsprechenden Pakete im folgenden Verzeichnis im Stammverzeichnis des Projekts erstellt:
Laden Sie die Pakete auf die FedML MLOps-Plattform hoch
Führen Sie die folgenden Schritte aus, um die Pakete hochzuladen:
- Wählen Sie auf der FedML-Benutzeroberfläche aus meine Anwendungen im Navigationsbereich.
- Auswählen
Neue Bewerbung.
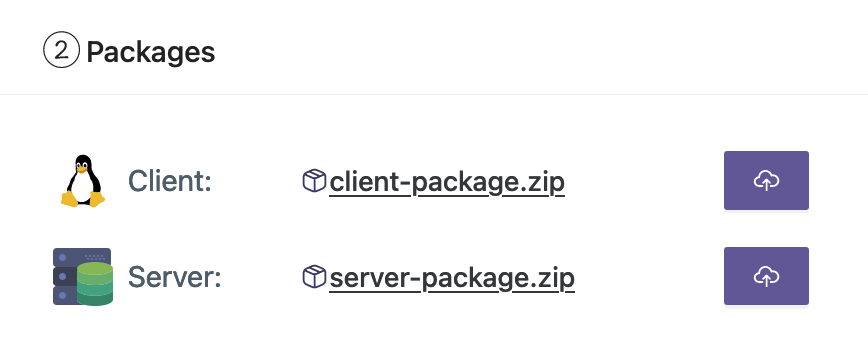
- Laden Sie die Client- und Serverpakete von Ihrer Workstation hoch.
- Sie können die Hyperparameter auch anpassen oder neue erstellen.

Lösen Sie ein Verbundtraining aus
Führen Sie die folgenden Schritte aus, um ein Verbundtraining auszuführen:
- Wählen Sie auf der FedML-Benutzeroberfläche aus Projektliste im Navigationsbereich.
- Auswählen Erstellen Sie ein neues Projekt.
- Geben Sie einen Gruppennamen und einen Projektnamen ein und wählen Sie dann OK.

- Wählen Sie das neu erstellte Projekt aus und wählen Sie Neuen Lauf erstellen um einen Trainingslauf auszulösen.
- Wählen Sie die Edge-Client-Geräte und den zentralen Aggregatorserver für diesen Trainingslauf aus.
- Wählen Sie die Anwendung aus, die Sie in den vorherigen Schritten erstellt haben.

- Aktualisieren Sie einen der Hyperparameter oder verwenden Sie die Standardeinstellungen.
- Auswählen
Startseite mit dem Training beginnen.

- Wähle die Trainingsstatus Klicken Sie auf die Registerkarte und warten Sie, bis der Trainingslauf abgeschlossen ist. Sie können auch zu den verfügbaren Registerkarten navigieren.
- Wenn das Training abgeschlossen ist, wählen Sie das aus System Klicken Sie auf die Registerkarte, um die Trainingsdauer auf Ihren Edge-Servern und Aggregationsereignissen anzuzeigen.
Ergebnisse und Experimentdetails anzeigen
Wenn das Training abgeschlossen ist, können Sie die Ergebnisse mit FedML und SageMaker anzeigen.
Auf der FedML-Benutzeroberfläche auf der Modelle Auf der Registerkarte können Sie das Aggregator- und Client-Modell sehen. Sie können diese Modelle auch von der Website herunterladen.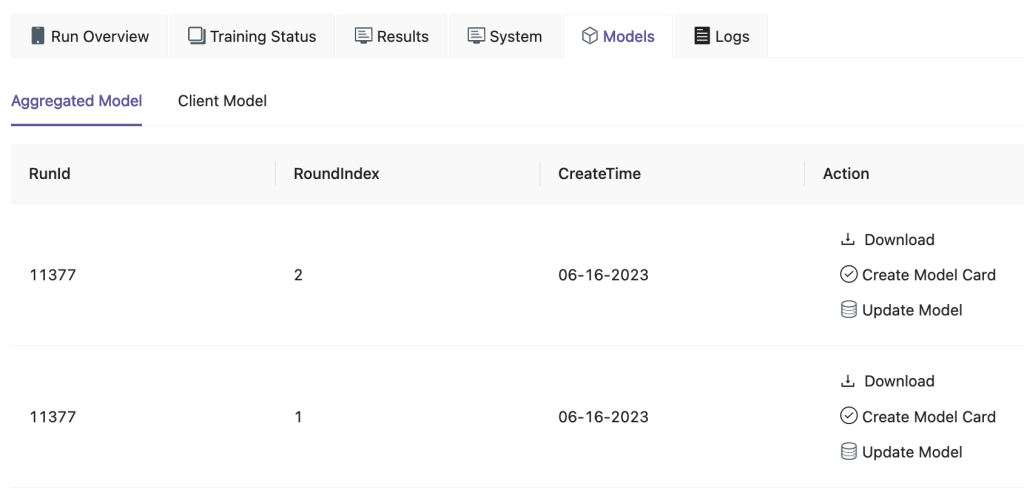
Sie können sich auch anmelden Amazon SageMaker-Studio und wählen Sie Experimente im Navigationsbereich.
Der folgende Screenshot zeigt die protokollierten Experimente.
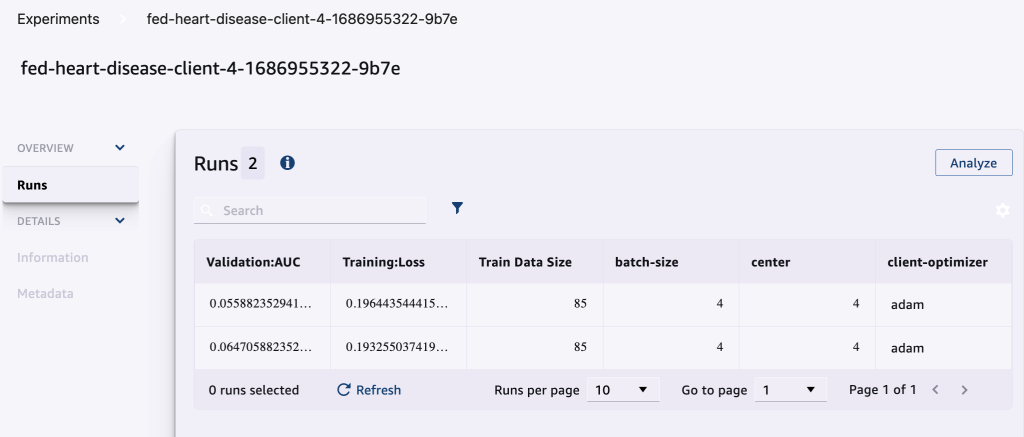
Experiment-Tracking-Code
In diesem Abschnitt untersuchen wir den Code, der die SageMaker-Experimentverfolgung mit dem FL-Framework-Training integriert.
Öffnen Sie in einem Editor Ihrer Wahl den folgenden Ordner, um die Änderungen am Code zum Einfügen des SageMaker-Experiment-Tracking-Codes als Teil der Schulung anzuzeigen:
Für die Nachverfolgung des Trainings haben wir Erstellen Sie ein SageMaker-Experiment mit Parametern und Metriken, die mit dem protokolliert werden log_parameter und log_metric Befehl wie im folgenden Codebeispiel beschrieben.
Ein Eintrag in der config/fedml_config.yaml Die Datei deklariert das Experimentpräfix, auf das im Code verwiesen wird, um eindeutige Experimentnamen zu erstellen: sm_experiment_name: "fed-heart-disease". Sie können dies auf einen beliebigen Wert Ihrer Wahl aktualisieren.
Sehen Sie sich beispielsweise den folgenden Code für an heart_disease_trainer.py, die von jedem Client verwendet wird, um das Modell anhand seines eigenen Datensatzes zu trainieren:
Für jeden Clientlauf werden die Experimentdetails mithilfe des folgenden Codes in heart_disease_trainer.py verfolgt:
Ebenso können Sie den Code in verwenden heart_disease_aggregator.py um nach der Aktualisierung der Modellgewichte einen Test für lokale Daten durchzuführen. Die Details werden nach jedem Kommunikationslauf mit den Clients protokolliert.
Aufräumen
Wenn Sie mit der Lösung fertig sind, achten Sie darauf, die verwendeten Ressourcen zu bereinigen, um eine effiziente Ressourcennutzung und Kostenverwaltung sicherzustellen und unnötige Kosten und Ressourcenverschwendung zu vermeiden. Aktives Aufräumen der Umgebung, wie das Löschen ungenutzter Instanzen, das Beenden unnötiger Dienste und das Entfernen temporärer Daten, trägt zu einer sauberen und organisierten Infrastruktur bei. Mit dem folgenden Code können Sie Ihre Ressourcen bereinigen:
Zusammenfassung
Durch die Verwendung von Amazon EKS als Infrastruktur und FedML als Framework für FL sind wir in der Lage, eine skalierbare und verwaltete Umgebung für das Training und die Bereitstellung gemeinsamer Modelle unter Wahrung des Datenschutzes bereitzustellen. Dank der dezentralen Natur von FL können Unternehmen sicher zusammenarbeiten, das Potenzial verteilter Daten nutzen und ML-Modelle verbessern, ohne den Datenschutz zu gefährden.
Wie immer freut sich AWS über Ihr Feedback. Bitte hinterlassen Sie Ihre Gedanken und Fragen im Kommentarbereich.
Über die Autoren
 Randy DeFauw ist Senior Principal Solutions Architect bei AWS. Er besitzt einen MSEE von der University of Michigan, wo er an Computer Vision für autonome Fahrzeuge arbeitete. Er verfügt außerdem über einen MBA der Colorado State University. Randy hatte verschiedene Positionen im Technologiebereich inne, von der Softwareentwicklung bis zum Produktmanagement. Er ist 2013 in den Big-Data-Bereich eingestiegen und erforscht diesen Bereich weiterhin. Er arbeitet aktiv an Projekten im ML-Bereich und hat auf zahlreichen Konferenzen, darunter Strata und GlueCon, Vorträge gehalten.
Randy DeFauw ist Senior Principal Solutions Architect bei AWS. Er besitzt einen MSEE von der University of Michigan, wo er an Computer Vision für autonome Fahrzeuge arbeitete. Er verfügt außerdem über einen MBA der Colorado State University. Randy hatte verschiedene Positionen im Technologiebereich inne, von der Softwareentwicklung bis zum Produktmanagement. Er ist 2013 in den Big-Data-Bereich eingestiegen und erforscht diesen Bereich weiterhin. Er arbeitet aktiv an Projekten im ML-Bereich und hat auf zahlreichen Konferenzen, darunter Strata und GlueCon, Vorträge gehalten.
 Arnab Sinha ist Senior Solutions Architect für AWS und fungiert als Field CTO, um Unternehmen beim Entwurf und Aufbau skalierbarer Lösungen zu unterstützen, die Geschäftsergebnisse bei Rechenzentrumsmigrationen, digitaler Transformation und Anwendungsmodernisierung, Big Data und maschinellem Lernen unterstützen. Er hat Kunden in einer Vielzahl von Branchen unterstützt, darunter Energie, Einzelhandel, Fertigung, Gesundheitswesen und Biowissenschaften. Arnab verfügt über alle AWS-Zertifizierungen, einschließlich der ML Specialty Certification. Bevor er zu AWS kam, war Arnab ein Technologieführer und hatte zuvor Führungspositionen als Architekt und Ingenieur inne.
Arnab Sinha ist Senior Solutions Architect für AWS und fungiert als Field CTO, um Unternehmen beim Entwurf und Aufbau skalierbarer Lösungen zu unterstützen, die Geschäftsergebnisse bei Rechenzentrumsmigrationen, digitaler Transformation und Anwendungsmodernisierung, Big Data und maschinellem Lernen unterstützen. Er hat Kunden in einer Vielzahl von Branchen unterstützt, darunter Energie, Einzelhandel, Fertigung, Gesundheitswesen und Biowissenschaften. Arnab verfügt über alle AWS-Zertifizierungen, einschließlich der ML Specialty Certification. Bevor er zu AWS kam, war Arnab ein Technologieführer und hatte zuvor Führungspositionen als Architekt und Ingenieur inne.
 Prachi Kulkarni ist Senior Solutions Architect bei AWS. Ihre Spezialisierung ist maschinelles Lernen und sie arbeitet aktiv an der Entwicklung von Lösungen unter Verwendung verschiedener AWS ML-, Big Data- und Analyseangebote. Prachi verfügt über Erfahrung in mehreren Bereichen, darunter Gesundheitswesen, Sozialleistungen, Einzelhandel und Bildung, und war in verschiedenen Positionen in den Bereichen Produktentwicklung und -architektur, Management und Kundenerfolg tätig.
Prachi Kulkarni ist Senior Solutions Architect bei AWS. Ihre Spezialisierung ist maschinelles Lernen und sie arbeitet aktiv an der Entwicklung von Lösungen unter Verwendung verschiedener AWS ML-, Big Data- und Analyseangebote. Prachi verfügt über Erfahrung in mehreren Bereichen, darunter Gesundheitswesen, Sozialleistungen, Einzelhandel und Bildung, und war in verschiedenen Positionen in den Bereichen Produktentwicklung und -architektur, Management und Kundenerfolg tätig.
 Tamer Sherif ist Principal Solutions Architect bei AWS und verfügt über einen vielfältigen Hintergrund im Bereich Technologie- und Unternehmensberatungsdienstleistungen, der über 17 Jahre als Lösungsarchitekt umfasst. Mit einem Schwerpunkt auf Infrastruktur deckt Tamers Fachwissen ein breites Spektrum an Branchen ab, darunter Handel, Gesundheitswesen, Automobil, öffentlicher Sektor, Fertigung, Öl und Gas, Mediendienste und mehr. Seine Kompetenz erstreckt sich auf verschiedene Bereiche wie Cloud-Architektur, Edge Computing, Netzwerk, Speicher, Virtualisierung, Unternehmensproduktivität und technische Führung.
Tamer Sherif ist Principal Solutions Architect bei AWS und verfügt über einen vielfältigen Hintergrund im Bereich Technologie- und Unternehmensberatungsdienstleistungen, der über 17 Jahre als Lösungsarchitekt umfasst. Mit einem Schwerpunkt auf Infrastruktur deckt Tamers Fachwissen ein breites Spektrum an Branchen ab, darunter Handel, Gesundheitswesen, Automobil, öffentlicher Sektor, Fertigung, Öl und Gas, Mediendienste und mehr. Seine Kompetenz erstreckt sich auf verschiedene Bereiche wie Cloud-Architektur, Edge Computing, Netzwerk, Speicher, Virtualisierung, Unternehmensproduktivität und technische Führung.
 Hans Nesbitt ist Senior Solutions Architect bei AWS mit Sitz in Südkalifornien. Er arbeitet mit Kunden im gesamten Westen der USA zusammen, um hoch skalierbare, flexible und belastbare Cloud-Architekturen zu entwickeln. In seiner Freizeit verbringt er gerne Zeit mit seiner Familie, kocht und spielt Gitarre.
Hans Nesbitt ist Senior Solutions Architect bei AWS mit Sitz in Südkalifornien. Er arbeitet mit Kunden im gesamten Westen der USA zusammen, um hoch skalierbare, flexible und belastbare Cloud-Architekturen zu entwickeln. In seiner Freizeit verbringt er gerne Zeit mit seiner Familie, kocht und spielt Gitarre.
 Chaoyang Er ist Mitbegründer und CTO von FedML, Inc., einem Startup, das sich für eine Community einsetzt, die von überall und in jeder Größenordnung offene und kollaborative KI aufbaut. Sein Forschungsschwerpunkt liegt auf verteilten und föderierten Algorithmen, Systemen und Anwendungen des maschinellen Lernens. Er erhielt seinen Doktortitel in Informatik von der University of Southern California.
Chaoyang Er ist Mitbegründer und CTO von FedML, Inc., einem Startup, das sich für eine Community einsetzt, die von überall und in jeder Größenordnung offene und kollaborative KI aufbaut. Sein Forschungsschwerpunkt liegt auf verteilten und föderierten Algorithmen, Systemen und Anwendungen des maschinellen Lernens. Er erhielt seinen Doktortitel in Informatik von der University of Southern California.
 Al Nevarez ist Direktor für Produktmanagement bei FedML. Vor FedML war er Gruppenproduktmanager bei Google und Senior Manager für Datenwissenschaft bei LinkedIn. Er verfügt über mehrere Patente im Zusammenhang mit Datenprodukten und hat Ingenieurwissenschaften an der Stanford University studiert.
Al Nevarez ist Direktor für Produktmanagement bei FedML. Vor FedML war er Gruppenproduktmanager bei Google und Senior Manager für Datenwissenschaft bei LinkedIn. Er verfügt über mehrere Patente im Zusammenhang mit Datenprodukten und hat Ingenieurwissenschaften an der Stanford University studiert.
 Salman Avestimehr ist Mitbegründer und CEO von FedML. Er war Dekanatsprofessor am USC, Direktor des USC-Amazon Center on Trustworthy AI und Amazon Scholar für Alexa AI. Er ist Experte für föderiertes und dezentrales maschinelles Lernen, Informationstheorie, Sicherheit und Datenschutz. Er ist Fellow des IEEE und promovierte in EECS an der UC Berkeley.
Salman Avestimehr ist Mitbegründer und CEO von FedML. Er war Dekanatsprofessor am USC, Direktor des USC-Amazon Center on Trustworthy AI und Amazon Scholar für Alexa AI. Er ist Experte für föderiertes und dezentrales maschinelles Lernen, Informationstheorie, Sicherheit und Datenschutz. Er ist Fellow des IEEE und promovierte in EECS an der UC Berkeley.
 Samir Lad ist ein versierter Unternehmenstechnologe bei AWS, der eng mit den C-Level-Führungskräften der Kunden zusammenarbeitet. Als ehemaliger C-Suite-Manager, der Transformationen in mehreren Fortune-100-Unternehmen vorangetrieben hat, teilt Samir seine unschätzbaren Erfahrungen, um seinen Kunden auf ihrem eigenen Transformationsweg zum Erfolg zu verhelfen.
Samir Lad ist ein versierter Unternehmenstechnologe bei AWS, der eng mit den C-Level-Führungskräften der Kunden zusammenarbeitet. Als ehemaliger C-Suite-Manager, der Transformationen in mehreren Fortune-100-Unternehmen vorangetrieben hat, teilt Samir seine unschätzbaren Erfahrungen, um seinen Kunden auf ihrem eigenen Transformationsweg zum Erfolg zu verhelfen.
 Stephen Kraemer ist Vorstands- und CxO-Berater und ehemalige Führungskraft bei AWS. Stephen plädiert für Kultur und Führung als Grundlagen des Erfolgs. Er bezeichnet Sicherheit und Innovation als Treiber der Cloud-Transformation, die äußerst wettbewerbsfähige, datengesteuerte Unternehmen ermöglicht.
Stephen Kraemer ist Vorstands- und CxO-Berater und ehemalige Führungskraft bei AWS. Stephen plädiert für Kultur und Führung als Grundlagen des Erfolgs. Er bezeichnet Sicherheit und Innovation als Treiber der Cloud-Transformation, die äußerst wettbewerbsfähige, datengesteuerte Unternehmen ermöglicht.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/federated-learning-on-aws-using-fedml-amazon-eks-and-amazon-sagemaker/

