Dieser Beitrag wurde geschrieben in Zusammenarbeit mit Ankur Goyal und Karthikeyan Chokappa vom Cloud & Digital-Geschäft von PwC Australia.
Künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden zu einem integralen Bestandteil von Systemen und Prozessen, ermöglichen Entscheidungen in Echtzeit und sorgen so für Umsatz- und Gewinnverbesserungen im gesamten Unternehmen. Allerdings ist die maßstabsgetreue Umsetzung eines ML-Modells in die Produktion eine Herausforderung und erfordert eine Reihe von Best Practices. Viele Unternehmen verfügen bereits über Datenwissenschaftler und ML-Ingenieure, die hochmoderne Modelle erstellen können, aber die Modelle in die Produktion zu bringen und sie im Maßstab zu halten, bleibt eine Herausforderung. Manuelle Arbeitsabläufe schränken ML-Lebenszyklusvorgänge ein, verlangsamen den Entwicklungsprozess, erhöhen die Kosten und beeinträchtigen die Qualität des Endprodukts.
Machine Learning Operations (MLOps) wendet DevOps-Prinzipien auf ML-Systeme an. So wie DevOps Entwicklung und Betrieb für Software-Engineering kombiniert, kombiniert MLOps ML-Engineering und IT-Betrieb. Angesichts des schnellen Wachstums bei ML-Systemen und im Kontext des ML-Engineerings bietet MLOps Funktionen, die erforderlich sind, um die einzigartige Komplexität der praktischen Anwendung von ML-Systemen zu bewältigen. Insgesamt erfordern ML-Anwendungsfälle eine leicht verfügbare integrierte Lösung zur Industrialisierung und Rationalisierung des Prozesses, der ein ML-Modell von der Entwicklung bis zur skalierten Produktionsbereitstellung mithilfe von MLOps führt.
Um diesen Kundenherausforderungen zu begegnen, hat PwC Australia den Machine Learning Ops Accelerator als eine Reihe standardisierter Prozess- und Technologiefunktionen entwickelt, um die Operationalisierung von KI/ML-Modellen zu verbessern, die eine funktionsübergreifende Zusammenarbeit zwischen Teams im gesamten ML-Lebenszyklusbetrieb ermöglichen. PwC Machine Learning Ops Accelerator basiert auf den nativen AWS-Services und bietet eine zweckdienliche Lösung, die sich problemlos in die ML-Anwendungsfälle integrieren lässt und Kunden aus allen Branchen problemlos unterstützt. In diesem Beitrag konzentrieren wir uns auf die Erstellung und Bereitstellung eines ML-Anwendungsfalls, der verschiedene Lebenszykluskomponenten eines ML-Modells integriert und so kontinuierliche Integration (CI), kontinuierliche Bereitstellung (CD), kontinuierliches Training (CT) und kontinuierliche Überwachung (CM) ermöglicht.
Lösungsüberblick
Bei MLOps umfasst ein erfolgreicher Weg von Daten über ML-Modelle bis hin zu Empfehlungen und Vorhersagen in Geschäftssystemen und -prozessen mehrere entscheidende Schritte. Dabei geht es darum, das Ergebnis eines Experiments oder Prototyps in ein Produktionssystem mit Standardkontrollen, Qualitäts- und Feedbackschleifen umzuwandeln. Es ist viel mehr als nur Automatisierung. Es geht darum, Organisationspraktiken zu verbessern und Ergebnisse zu liefern, die in großem Maßstab wiederholbar und reproduzierbar sind.
Nur ein kleiner Teil eines realen ML-Anwendungsfalls besteht aus dem Modell selbst. Die verschiedenen Komponenten, die zum Aufbau einer integrierten erweiterten ML-Funktion und zum kontinuierlichen Betrieb in großem Maßstab erforderlich sind, sind in Abbildung 1 dargestellt. Wie im folgenden Diagramm dargestellt, umfasst PwC MLOps Accelerator sieben wichtige integrierte Funktionen und iterative Schritte, die CI, CD, CT usw. ermöglichen CM eines ML-Anwendungsfalls. Die Lösung nutzt die Vorteile nativer AWS-Funktionen von Amazon Sage Makerund baut darauf ein flexibles und erweiterbares Framework auf.
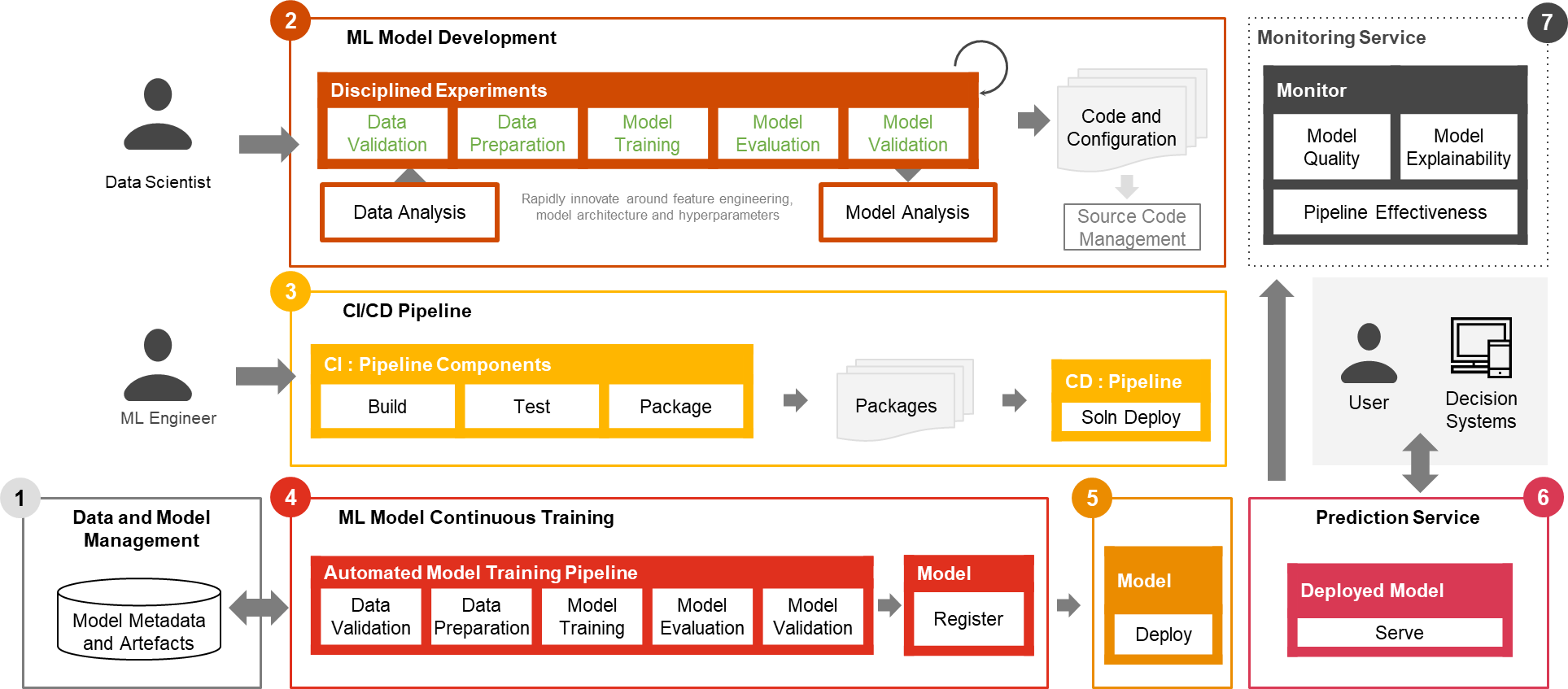
Abbildung 1 – Funktionen des PwC Machine Learning Ops Accelerator
In einem realen Unternehmensszenario können zusätzliche Testschritte und -phasen vorhanden sein, um eine strenge Validierung und Bereitstellung von Modellen in verschiedenen Umgebungen sicherzustellen.
- Daten- und Modellmanagement Bereitstellung einer zentralen Funktion, die ML-Artefakte während ihres gesamten Lebenszyklus steuert. Es ermöglicht Prüfbarkeit, Rückverfolgbarkeit und Compliance. Es fördert auch die gemeinsame Nutzung, Wiederverwendbarkeit und Auffindbarkeit von ML-Assets.
- ML-Modellentwicklung ermöglicht es verschiedenen Personas, eine robuste und reproduzierbare Modelltrainingspipeline zu entwickeln, die eine Abfolge von Schritten umfasst, von der Datenvalidierung und -transformation bis hin zum Modelltraining und der Modellbewertung.
- Kontinuierliche Integration/Lieferung erleichtert das automatisierte Erstellen, Testen und Packen der Modelltrainingspipeline sowie deren Bereitstellung in der Zielausführungsumgebung. Integrationen mit CI/CD-Workflows und Datenversionierung fördern MLOps-Best Practices wie Governance und Überwachung für iterative Entwicklung und Datenversionierung.
- Kontinuierliches Training des ML-Modells Die Fähigkeit führt die Trainingspipeline basierend auf Umschulungsauslösern aus. Das heißt, wenn neue Daten verfügbar werden oder die Modellleistung unter einen voreingestellten Schwellenwert sinkt. Es registriert das trainierte Modell, wenn es sich als erfolgreicher Modellkandidat qualifiziert, und speichert die Trainingsartefakte und zugehörigen Metadaten.
- Modellbereitstellung Ermöglicht den Zugriff auf das registrierte trainierte Modell zur Überprüfung und Genehmigung für die Produktionsfreigabe und ermöglicht das Packen, Testen und Bereitstellen des Modells in der Vorhersagedienstumgebung für die Produktionsbereitstellung.
- Vorhersagedienst Die Fähigkeit startet das bereitgestellte Modell, um Vorhersagen über Online-, Batch- oder Streaming-Muster bereitzustellen. Serving Runtime erfasst außerdem Modellbereitstellungsprotokolle zur kontinuierlichen Überwachung und Verbesserung.
- Kontinuierliche Überwachung Überwacht das Modell auf prädiktive Wirksamkeit, um Modellverfall und Serviceeffektivität (Latenz, Pipeline-Durchgängigkeit und Ausführungsfehler) zu erkennen.
PwC Machine Learning Ops Accelerator-Architektur
Die Lösung basiert auf AWS-nativen Diensten unter Verwendung von Amazon SageMaker und serverloser Technologie, um die Leistung und Skalierbarkeit hoch und die Betriebskosten niedrig zu halten.
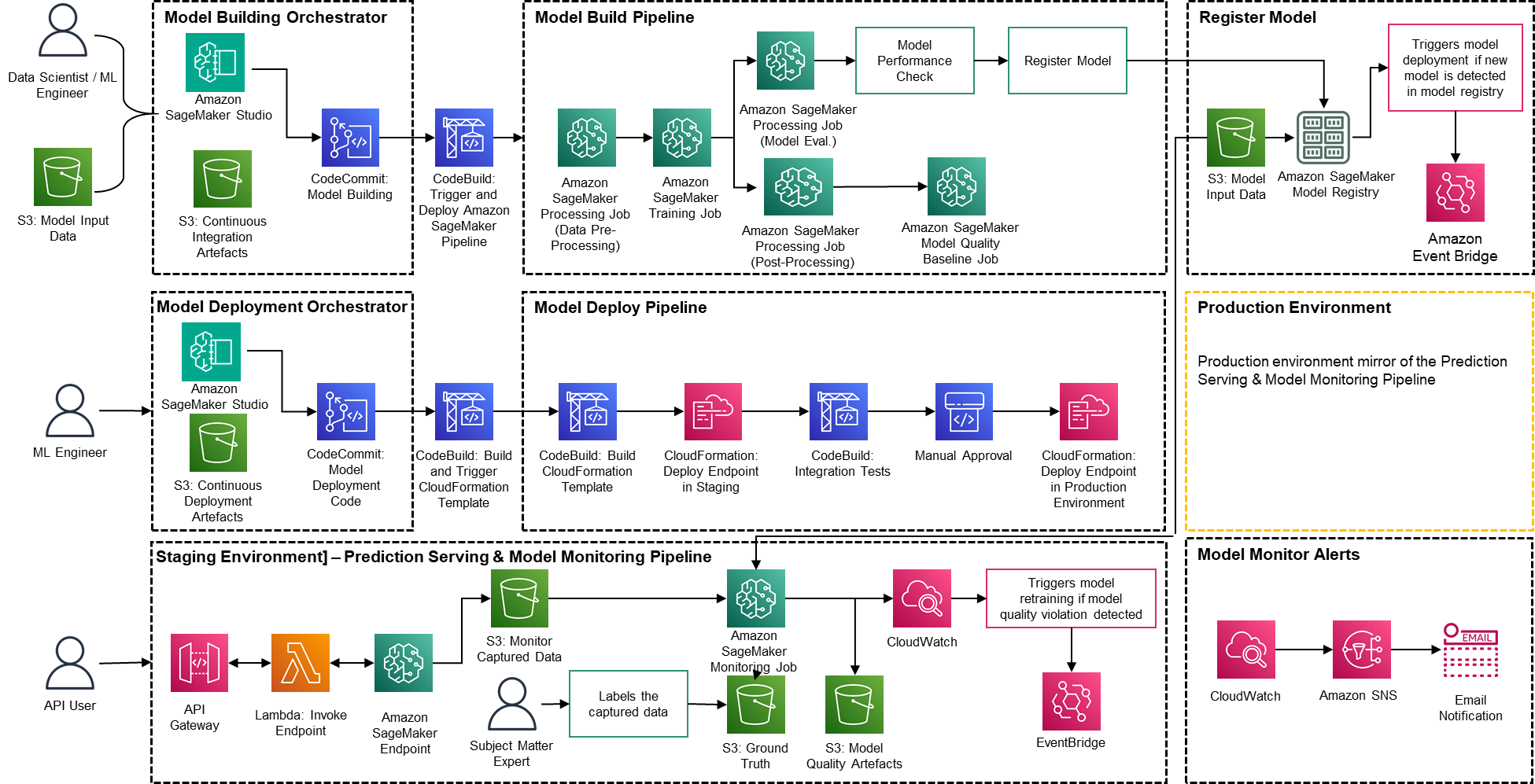
Abbildung 2 – PwC Machine Learning Ops Accelerator-Architektur
- PwC Machine Learning Ops Accelerator bietet eine personengesteuerte Zugriffsberechtigung für Aufbau, Nutzung und Betrieb, die es ML-Ingenieuren und Datenwissenschaftlern ermöglicht, die Bereitstellung von Pipelines (Schulung und Bereitstellung) zu automatisieren und schnell auf Änderungen der Modellqualität zu reagieren. Amazon SageMaker-Rollenmanager wird verwendet, um rollenbasierte ML-Aktivitäten zu implementieren, und Amazon S3 wird zum Speichern von Eingabedaten und Artefakten verwendet.
- Die Lösung nutzt vorhandene Modellerstellungsressourcen des Kunden und baut darauf mithilfe nativer AWS-Dienste ein flexibles und erweiterbares Framework auf. Es wurden Integrationen zwischen Amazon S3, Git und AWS CodeCommit erstellt, die eine Datensatzversionierung mit minimalem zukünftigem Verwaltungsaufwand ermöglichen.
- Die AWS CloudFormation-Vorlage wird mit generiert AWS Cloud Development Kit (AWS CDK). AWS CDK bietet die Möglichkeit, Änderungen für die gesamte Lösung zu verwalten. Die automatisierte Pipeline umfasst Schritte für die sofort einsatzbereite Modellspeicherung und Metrikverfolgung.
- PwC MLOps Accelerator ist modular konzipiert und wird als Infrastructure-as-Code (IaC) bereitgestellt, um automatische Bereitstellungen zu ermöglichen. Der Bereitstellungsprozess verwendet AWS-CodeCommit, AWS CodeBuild, AWS CodePipelineund AWS CloudFormation-Vorlage. Eine vollständige End-to-End-Lösung zur Operationalisierung eines ML-Modells ist als bereitstellbarer Code verfügbar.
- Über eine Reihe von IaC-Vorlagen werden drei unterschiedliche Komponenten bereitgestellt: Modellerstellung, Modellbereitstellung sowie Modellüberwachung und -vorhersagebereitstellung Amazon SageMaker-Pipelines
- Die Model Build Pipeline automatisiert den Modellschulungs- und Bewertungsprozess und ermöglicht die Genehmigung und Registrierung des trainierten Modells.
- Die Model-Deployment-Pipeline stellt die notwendige Infrastruktur bereit, um das ML-Modell für Batch- und Echtzeit-Inferenz bereitzustellen.
- Die Modellüberwachungs- und Vorhersagebereitstellungspipeline stellt die erforderliche Infrastruktur bereit, um Vorhersagen bereitzustellen und die Modellleistung zu überwachen.
- PwC MLOps Accelerator ist so konzipiert, dass es unabhängig von ML-Modellen, ML-Frameworks und Laufzeitumgebungen ist. Die Lösung ermöglicht die vertraute Verwendung von Programmiersprachen wie Python und R, Entwicklungstools wie Jupyter Notebook und ML-Frameworks über eine Konfigurationsdatei. Diese Flexibilität macht es Datenwissenschaftlern leicht, Modelle kontinuierlich zu verfeinern und sie in ihrer bevorzugten Sprache und Umgebung bereitzustellen.
- Die Lösung verfügt über integrierte Integrationen, um entweder vorgefertigte oder benutzerdefinierte Tools zum Zuweisen der Etikettierungsaufgaben zu verwenden Amazon Sagemaker Ground Truth für Trainingsdatensätze, um kontinuierliches Training und Überwachung bereitzustellen.
- Die End-to-End-ML-Pipeline ist mit nativen SageMaker-Funktionen aufgebaut (Amazon SageMaker-Studio , Amazon SageMaker-Modellerstellungspipelines, Amazon SageMaker-Experimente und Amazon SageMaker-Endpunkte).
- Die Lösung nutzt die integrierten Amazon SageMaker-Funktionen für Modellversionierung, Modellherkunftsverfolgung, Modellfreigabe und serverlose Inferenz mit Amazon SageMaker-Modellregistrierung.
- Sobald das Modell in Produktion ist, überwacht die Lösung kontinuierlich die Qualität der ML-Modelle in Echtzeit. Amazon SageMaker-Modellmonitor dient der kontinuierlichen Überwachung von Modellen in der Produktion. Amazon CloudWatch Logs wird verwendet, um Protokolldateien zu sammeln, die den Modellstatus überwachen, und Benachrichtigungen werden über Amazon SNS gesendet, wenn die Qualität des Modells bestimmte Schwellenwerte erreicht. Native Logger wie (boto3) werden zur Erfassung des Ausführungsstatus verwendet, um die Fehlerbehebung zu beschleunigen.
Lösungsweg
Die folgende exemplarische Vorgehensweise befasst sich mit den Standardschritten zum Erstellen des MLOps-Prozesses für ein Modell mit PwC MLOps Accelerator. Diese exemplarische Vorgehensweise beschreibt einen Anwendungsfall eines MLOps-Ingenieurs, der die Pipeline für ein kürzlich entwickeltes ML-Modell mithilfe einer einfachen, intuitiven Definitions-/Konfigurationsdatei bereitstellen möchte.
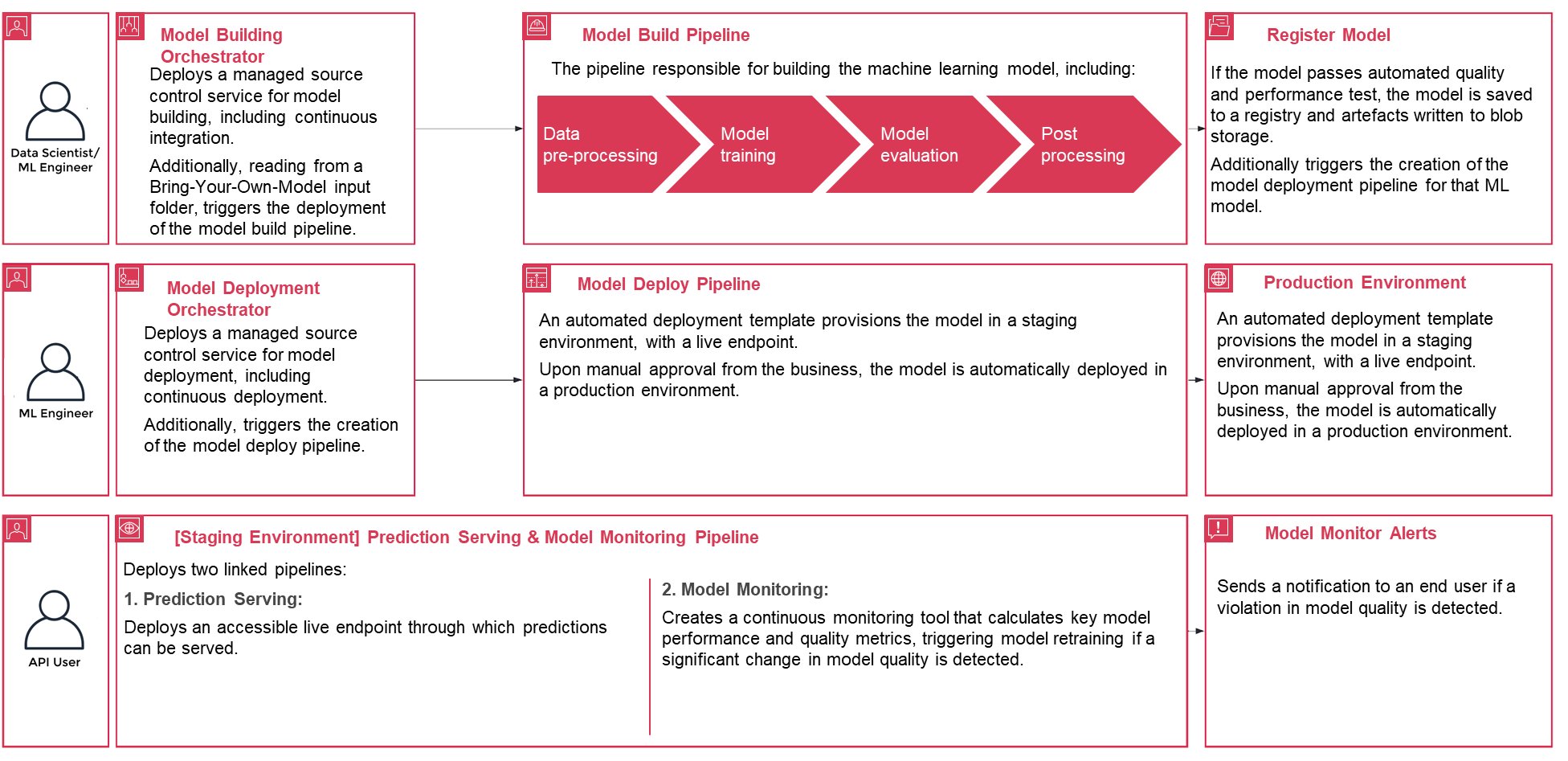
Abbildung 3 – Lebenszyklus des PwC Machine Learning Ops Accelerator-Prozesses
- Melden Sie sich zunächst an PwC MLOps Accelerator um Zugriff auf Lösungsartefakte zu erhalten. Die gesamte Lösung wird von einer einzigen Konfigurations-YAML-Datei gesteuert (
config.yaml) pro Modell. Alle zum Ausführen der Lösung erforderlichen Details sind in dieser Konfigurationsdatei enthalten und werden zusammen mit dem Modell in einem Git-Repository gespeichert. Die Konfigurationsdatei dient als Eingabe zur Automatisierung von Workflow-Schritten durch die Externalisierung wichtiger Parameter und Einstellungen außerhalb des Codes. - Der ML-Ingenieur muss Daten ausfüllen
config.yamlDatei und lösen Sie die MLOps-Pipeline aus. Kunden können ein AWS-Konto, das Repository, das Modell, die verwendeten Daten, den Pipeline-Namen, das Trainings-Framework, die Anzahl der für das Training zu verwendenden Instanzen, das Inferenz-Framework sowie alle Vor- und Nachverarbeitungsschritte und vieles mehr konfigurieren Konfigurationen zur Überprüfung der Modellqualität, Verzerrung und Erklärbarkeit.

Abbildung 4 – Konfiguration des Machine Learning Ops Accelerator (YAML).
- Eine einfache YAML-Datei wird verwendet, um die Trainings-, Bereitstellungs-, Überwachungs- und Laufzeitanforderungen jedes Modells zu konfigurieren. Sobald die
config.yamlWenn das Modell entsprechend konfiguriert und zusammen mit dem Modell in seinem eigenen Git-Repository gespeichert ist, wird der Modellbildungs-Orchestrator aufgerufen. Es kann auch aus einem Bring-Your-Own-Model lesen, das über YAML konfiguriert werden kann, um die Bereitstellung der Modellerstellungspipeline auszulösen. - Alles nach diesem Punkt wird durch die Lösung automatisiert und erfordert weder die Beteiligung des ML-Ingenieurs noch des Datenwissenschaftlers. Die für den Aufbau des ML-Modells verantwortliche Pipeline umfasst Datenvorverarbeitung, Modelltraining, Modellbewertung und Ostverarbeitung. Wenn das Modell automatisierte Qualitäts- und Leistungstests besteht, wird das Modell in einer Registrierung gespeichert und Artefakte werden gemäß den Definitionen in den YAML-Dateien in den Amazon S3-Speicher geschrieben. Dies löst die Erstellung der Modellbereitstellungspipeline für dieses ML-Modell aus.
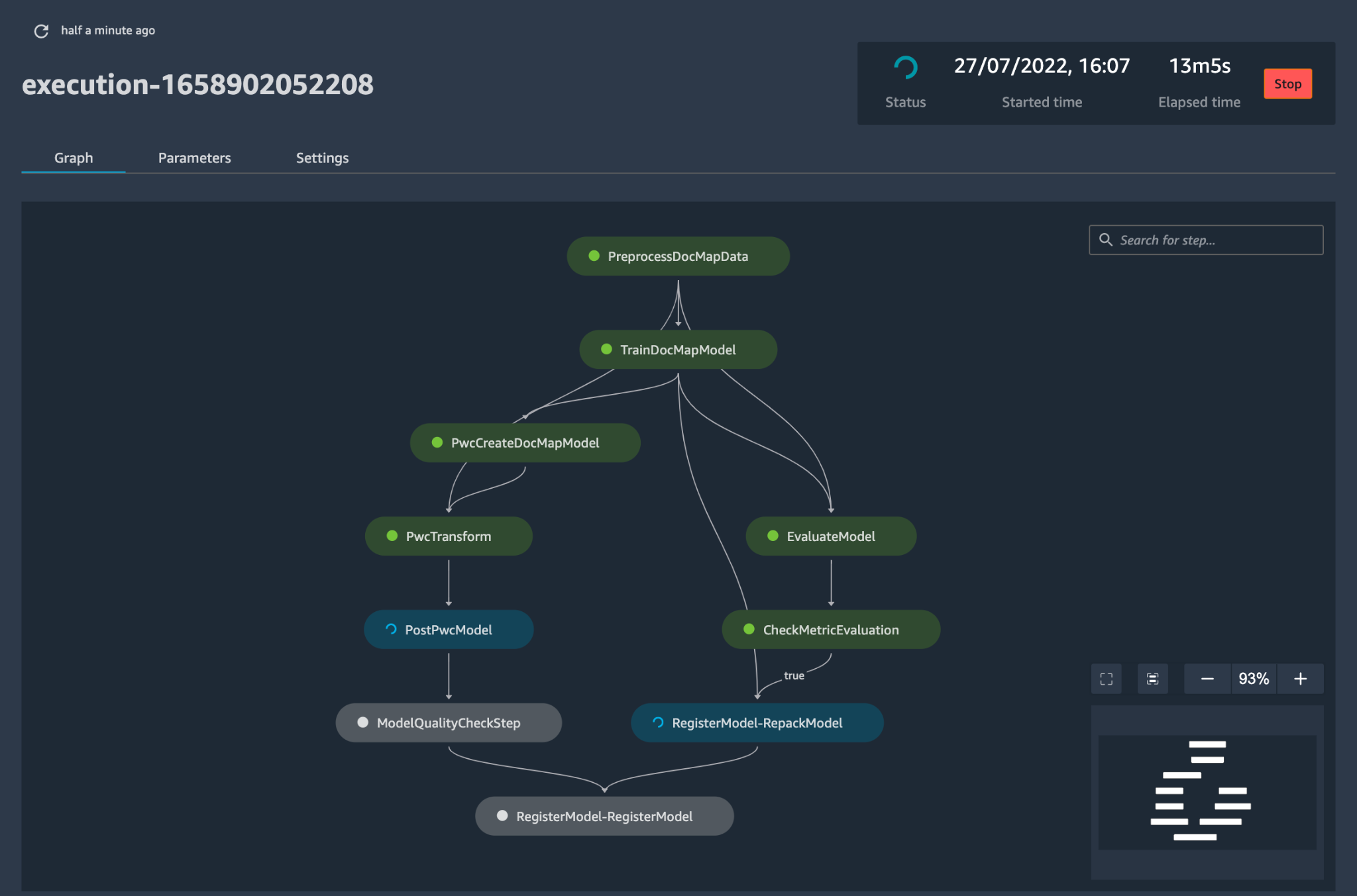
Abbildung 5 – Beispiel-Workflow für die Modellbereitstellung
- Anschließend stellt eine automatisierte Bereitstellungsvorlage das Modell in einer Staging-Umgebung mit einem Live-Endpunkt bereit. Nach der Genehmigung wird das Modell automatisch in der Produktionsumgebung bereitgestellt.
- Die Lösung stellt zwei verknüpfte Pipelines bereit. Die Vorhersagebereitstellung stellt einen zugänglichen Live-Endpunkt bereit, über den Vorhersagen bereitgestellt werden können. Durch die Modellüberwachung wird ein kontinuierliches Überwachungstool erstellt, das wichtige Leistungs- und Qualitätsmetriken des Modells berechnet und eine Neuschulung des Modells auslöst, wenn eine signifikante Änderung der Modellqualität festgestellt wird.
- Nachdem Sie nun die Erstellung und Erstbereitstellung abgeschlossen haben, kann der MLOps-Ingenieur Fehlerwarnungen konfigurieren, um bei Problemen benachrichtigt zu werden, beispielsweise wenn eine Pipeline ihre beabsichtigte Aufgabe nicht erfüllt.
- Bei MLOps geht es nicht mehr um das Packen, Testen und Bereitstellen von Cloud-Service-Komponenten, ähnlich wie bei einer herkömmlichen CI/CD-Bereitstellung; Es handelt sich um ein System, das automatisch einen anderen Dienst bereitstellen sollte. Beispielsweise stellt die Modelltrainingspipeline automatisch die Modellbereitstellungspipeline bereit, um den Vorhersagedienst zu aktivieren, der wiederum den Modellüberwachungsdienst aktiviert.
Zusammenfassung
Zusammenfassend lässt sich sagen, dass MLOps für jedes Unternehmen, das ML-Modelle in großem Maßstab in Produktionssystemen bereitstellen möchte, von entscheidender Bedeutung ist. PwC hat einen Beschleuniger entwickelt, um die Erstellung, Bereitstellung und Wartung von ML-Modellen durch die Integration von DevOps-Tools in den Modellentwicklungsprozess zu automatisieren.
In diesem Beitrag haben wir untersucht, wie die PwC-Lösung auf den nativen ML-Diensten von AWS basiert und dabei hilft, MLOps-Praktiken einzuführen, damit Unternehmen ihre KI-Reise beschleunigen und mehr Wert aus ihren ML-Modellen ziehen können. Wir gingen die Schritte durch, die ein Benutzer unternehmen würde, um auf den PwC Machine Learning Ops Accelerator zuzugreifen, die Pipelines auszuführen und einen ML-Anwendungsfall bereitzustellen, der verschiedene Lebenszykluskomponenten eines ML-Modells integriert.
Melden Sie sich an, um Ihre MLOps-Reise in der AWS Cloud in großem Maßstab zu beginnen und Ihre ML-Produktions-Workloads auszuführen PwC Machine Learning-Operationen.
Über die Autoren
 Kiran Kumar Ballari ist Principal Solutions Architect bei Amazon Web Services (AWS). Er ist ein Evangelist, der es liebt, Kunden dabei zu helfen, neue Technologien zu nutzen und wiederholbare Branchenlösungen zur Lösung ihrer Probleme zu entwickeln. Seine besondere Leidenschaft gilt dem Software-Engineering, der generativen KI und der Unterstützung von Unternehmen bei der KI/ML-Produktentwicklung.
Kiran Kumar Ballari ist Principal Solutions Architect bei Amazon Web Services (AWS). Er ist ein Evangelist, der es liebt, Kunden dabei zu helfen, neue Technologien zu nutzen und wiederholbare Branchenlösungen zur Lösung ihrer Probleme zu entwickeln. Seine besondere Leidenschaft gilt dem Software-Engineering, der generativen KI und der Unterstützung von Unternehmen bei der KI/ML-Produktentwicklung.
 Ankur Goyal ist Direktor in der Cloud- und Digital-Praxis von PwC Australia mit Schwerpunkt auf Daten, Analysen und KI. Ankur verfügt über umfangreiche Erfahrung in der Unterstützung von Organisationen des öffentlichen und privaten Sektors bei der Förderung technologischer Transformationen und der Entwicklung innovativer Lösungen durch die Nutzung von Datenbeständen und Technologien.
Ankur Goyal ist Direktor in der Cloud- und Digital-Praxis von PwC Australia mit Schwerpunkt auf Daten, Analysen und KI. Ankur verfügt über umfangreiche Erfahrung in der Unterstützung von Organisationen des öffentlichen und privaten Sektors bei der Förderung technologischer Transformationen und der Entwicklung innovativer Lösungen durch die Nutzung von Datenbeständen und Technologien.
 Karthikeyan Chokappa (KC) ist Manager im Cloud- und Digitalbereich von PwC Australien mit Schwerpunkt auf Daten, Analysen und KI. KC widmet sich mit Leidenschaft dem Entwurf, der Entwicklung und dem Einsatz von End-to-End-Analyselösungen, die Daten in wertvolle Entscheidungsressourcen umwandeln, um Leistung und Nutzung zu verbessern und die Gesamtbetriebskosten für vernetzte und intelligente Dinge zu senken.
Karthikeyan Chokappa (KC) ist Manager im Cloud- und Digitalbereich von PwC Australien mit Schwerpunkt auf Daten, Analysen und KI. KC widmet sich mit Leidenschaft dem Entwurf, der Entwicklung und dem Einsatz von End-to-End-Analyselösungen, die Daten in wertvolle Entscheidungsressourcen umwandeln, um Leistung und Nutzung zu verbessern und die Gesamtbetriebskosten für vernetzte und intelligente Dinge zu senken.
 Rama Lankalapalli ist Sr. Partner Solutions Architect bei AWS und arbeitet mit PwC zusammen, um die Migrationen und Modernisierungen ihrer Kunden in AWS zu beschleunigen. Er arbeitet in verschiedenen Branchen daran, die Einführung von AWS Cloud zu beschleunigen. Seine Expertise liegt in der Entwicklung effizienter und skalierbarer Cloud-Lösungen, der Förderung von Innovationen und der Modernisierung von Kundenanwendungen durch die Nutzung von AWS-Services und der Etablierung belastbarer Cloud-Grundlagen.
Rama Lankalapalli ist Sr. Partner Solutions Architect bei AWS und arbeitet mit PwC zusammen, um die Migrationen und Modernisierungen ihrer Kunden in AWS zu beschleunigen. Er arbeitet in verschiedenen Branchen daran, die Einführung von AWS Cloud zu beschleunigen. Seine Expertise liegt in der Entwicklung effizienter und skalierbarer Cloud-Lösungen, der Förderung von Innovationen und der Modernisierung von Kundenanwendungen durch die Nutzung von AWS-Services und der Etablierung belastbarer Cloud-Grundlagen.
 Jeejee Unwalla ist Senior Solutions Architect bei AWS und hat Freude daran, Kunden bei der Lösung von Herausforderungen und beim strategischen Denken zu unterstützen. Seine Leidenschaft gilt der Technologie und den Daten sowie der Ermöglichung von Innovationen.
Jeejee Unwalla ist Senior Solutions Architect bei AWS und hat Freude daran, Kunden bei der Lösung von Herausforderungen und beim strategischen Denken zu unterstützen. Seine Leidenschaft gilt der Technologie und den Daten sowie der Ermöglichung von Innovationen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/driving-advanced-analytics-outcomes-at-scale-using-amazon-sagemaker-powered-pwcs-machine-learning-ops-accelerator/

