Heutzutage nutzen Kunden aller Branchen – sei es Finanzdienstleistungen, Gesundheitswesen und Biowissenschaften, Reisen und Gastgewerbe, Medien und Unterhaltung, Telekommunikation, Software as a Service (SaaS) und sogar Anbieter proprietärer Modelle – große Sprachmodelle (LLMs), um Erstellen Sie Anwendungen wie Frage- und Antwort-Chatbots (QnA), Suchmaschinen und Wissensdatenbanken. Diese generative KI Anwendungen werden nicht nur zur Automatisierung bestehender Geschäftsprozesse verwendet, sondern haben auch die Möglichkeit, das Erlebnis für Kunden, die diese Anwendungen nutzen, zu verändern. Mit den Fortschritten, die mit LLMs wie dem gemacht werden Mixtral-8x7B Anleitung, Ableitung von Architekturen wie der Expertenmischung (MoE)Kunden suchen ständig nach Möglichkeiten, die Leistung und Genauigkeit generativer KI-Anwendungen zu verbessern und ihnen gleichzeitig die effektive Nutzung einer größeren Auswahl an Closed- und Open-Source-Modellen zu ermöglichen.
Typischerweise werden eine Reihe von Techniken verwendet, um die Genauigkeit und Leistung der Ausgabe eines LLM zu verbessern, beispielsweise die Feinabstimmung mit Parametereffiziente Feinabstimmung (PEFT), Reinforcement Learning aus menschlichem Feedback (RLHF), und durchführen Wissensdestillation. Beim Erstellen generativer KI-Anwendungen können Sie jedoch eine alternative Lösung verwenden, die die dynamische Einbindung von externem Wissen ermöglicht und es Ihnen ermöglicht, die für die Generierung verwendeten Informationen zu steuern, ohne Ihr bestehendes Basismodell verfeinern zu müssen. Hier kommt Retrieval Augmented Generation (RAG) ins Spiel, insbesondere für generative KI-Anwendungen im Gegensatz zu den teureren und robusteren Feinabstimmungsalternativen, die wir besprochen haben. Wenn Sie komplexe RAG-Anwendungen in Ihre täglichen Aufgaben integrieren, kann es sein, dass Sie mit Ihren RAG-Systemen auf häufige Herausforderungen stoßen, z. B. ungenaues Abrufen, zunehmende Größe und Komplexität von Dokumenten sowie ein Überfluss an Kontext, was sich erheblich auf die Qualität und Zuverlässigkeit der generierten Antworten auswirken kann .
In diesem Beitrag werden RAG-Muster zur Verbesserung der Antwortgenauigkeit mithilfe von LangChain und Tools wie dem Parent Document Retriever sowie Techniken wie kontextbezogener Komprimierung erläutert, um Entwicklern die Verbesserung bestehender generativer KI-Anwendungen zu ermöglichen.
Lösungsüberblick
In diesem Beitrag demonstrieren wir die Verwendung der Mixtral-8x7B Instruct-Textgenerierung in Kombination mit dem BGE Large En-Einbettungsmodell, um mithilfe des Parent Document Retriever-Tools und der kontextbezogenen Komprimierungstechnik effizient ein RAG-QnA-System auf einem Amazon SageMaker-Notebook zu erstellen. Das folgende Diagramm veranschaulicht die Architektur dieser Lösung.
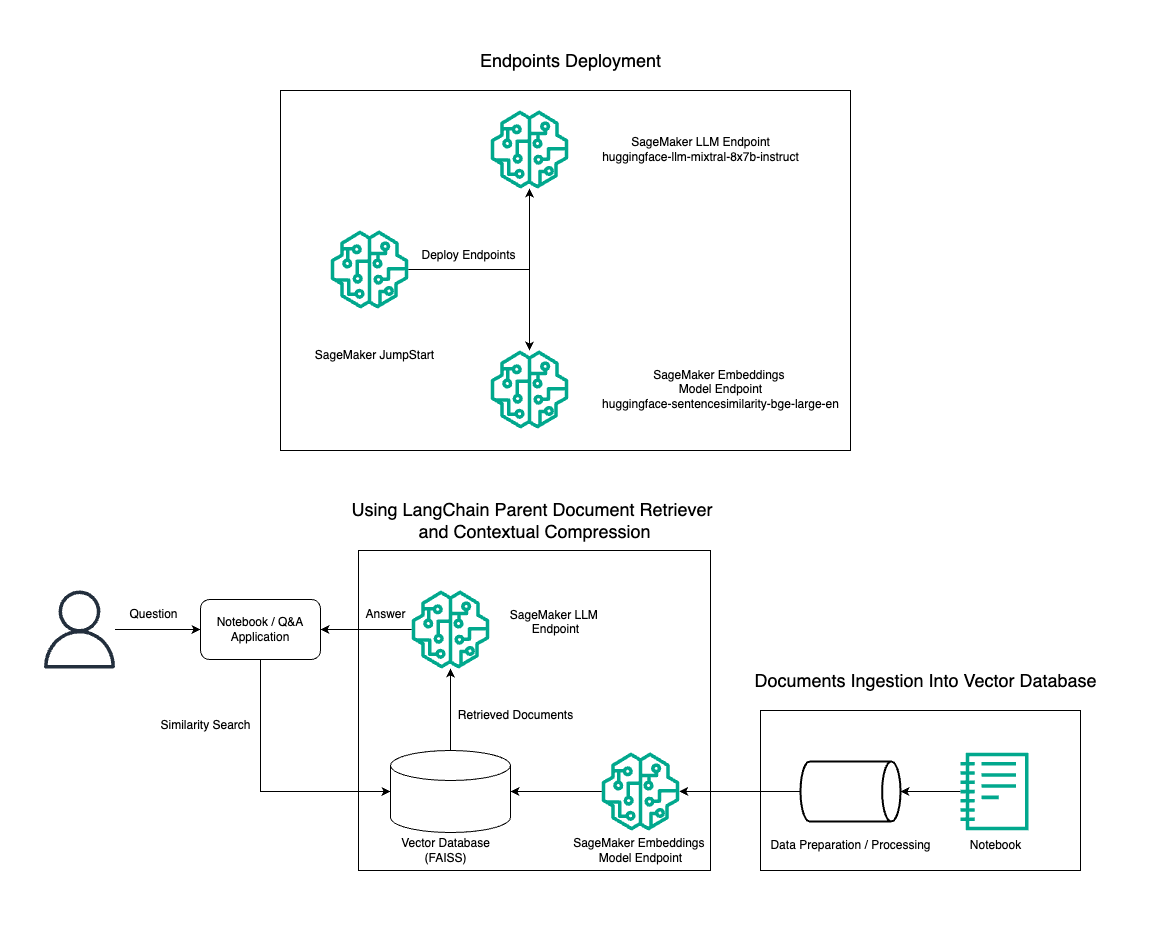
Sie können diese Lösung mit nur wenigen Klicks bereitstellen Amazon SageMaker-JumpStart, eine vollständig verwaltete Plattform, die hochmoderne Grundmodelle für verschiedene Anwendungsfälle wie das Schreiben von Inhalten, die Generierung von Code, die Beantwortung von Fragen, das Verfassen von Texten, die Zusammenfassung, die Klassifizierung und das Abrufen von Informationen bietet. Es bietet eine Sammlung vorab trainierter Modelle, die Sie schnell und einfach bereitstellen können, um die Entwicklung und Bereitstellung von Anwendungen für maschinelles Lernen (ML) zu beschleunigen. Eine der Schlüsselkomponenten von SageMaker JumpStart ist der Model Hub, der einen umfangreichen Katalog vorab trainierter Modelle wie den Mixtral-8x7B für eine Vielzahl von Aufgaben bietet.
Mixtral-8x7B verwendet eine MoE-Architektur. Diese Architektur ermöglicht es verschiedenen Teilen eines neuronalen Netzwerks, sich auf unterschiedliche Aufgaben zu spezialisieren und so die Arbeitslast effektiv auf mehrere Experten aufzuteilen. Dieser Ansatz ermöglicht im Vergleich zu herkömmlichen Architekturen das effiziente Training und den Einsatz größerer Modelle.
Einer der Hauptvorteile der MoE-Architektur ist ihre Skalierbarkeit. Durch die Verteilung der Arbeitslast auf mehrere Experten können MoE-Modelle auf größeren Datensätzen trainiert werden und eine bessere Leistung erzielen als herkömmliche Modelle derselben Größe. Darüber hinaus können MoE-Modelle bei der Inferenz effizienter sein, da für eine bestimmte Eingabe nur eine Teilmenge von Experten aktiviert werden muss.
Weitere Informationen zu Mixtral-8x7B Instruct auf AWS finden Sie unter Mixtral-8x7B ist jetzt in Amazon SageMaker JumpStart verfügbar. Das Mixtral-8x7B-Modell wird unter der freizügigen Apache 2.0-Lizenz zur uneingeschränkten Nutzung zur Verfügung gestellt.
In diesem Beitrag besprechen wir, wie Sie es verwenden können LangChain um effektive und effizientere RAG-Anwendungen zu erstellen. LangChain ist eine Open-Source-Python-Bibliothek zum Erstellen von Anwendungen mit LLMs. Es bietet ein modulares und flexibles Framework für die Kombination von LLMs mit anderen Komponenten wie Wissensdatenbanken, Abrufsystemen und anderen KI-Tools, um leistungsstarke und anpassbare Anwendungen zu erstellen.
Wir führen den Aufbau einer RAG-Pipeline auf SageMaker mit Mixtral-8x7B durch. Wir verwenden das Mixtral-8x7B Instruct-Textgenerierungsmodell mit dem BGE Large En-Einbettungsmodell, um ein effizientes QnA-System mithilfe von RAG auf einem SageMaker-Notebook zu erstellen. Wir verwenden eine ml.t3.medium-Instanz, um die Bereitstellung von LLMs über SageMaker JumpStart zu demonstrieren, auf das über einen von SageMaker generierten API-Endpunkt zugegriffen werden kann. Dieser Aufbau ermöglicht die Erforschung, Experimentierung und Optimierung fortgeschrittener RAG-Techniken mit LangChain. Wir veranschaulichen auch die Integration des FAISS-Einbettungsspeichers in den RAG-Workflow und heben seine Rolle beim Speichern und Abrufen von Einbettungen hervor, um die Leistung des Systems zu verbessern.
Wir führen einen kurzen Rundgang durch das SageMaker-Notizbuch durch. Ausführlichere und schrittweise Anleitungen finden Sie im Erweiterte RAG-Muster mit Mixtral im SageMaker Jumpstart GitHub-Repo.
Der Bedarf an fortgeschrittenen RAG-Mustern
Fortgeschrittene RAG-Muster sind unerlässlich, um die aktuellen Fähigkeiten von LLMs beim Verarbeiten, Verstehen und Generieren von menschenähnlichem Text zu verbessern. Da die Größe und Komplexität von Dokumenten zunimmt, kann die Darstellung mehrerer Facetten des Dokuments in einer einzigen Einbettung zu einem Verlust an Spezifität führen. Obwohl es wichtig ist, das allgemeine Wesen eines Dokuments zu erfassen, ist es ebenso wichtig, die verschiedenen Unterkontexte darin zu erkennen und darzustellen. Dies ist eine Herausforderung, vor der Sie häufig stehen, wenn Sie mit größeren Dokumenten arbeiten. Eine weitere Herausforderung bei RAG besteht darin, dass Sie beim Abrufen nicht wissen, welche spezifischen Abfragen Ihr Dokumentenspeichersystem bei der Aufnahme bearbeiten wird. Dies könnte dazu führen, dass Informationen, die für eine Abfrage am relevantesten sind, unter dem Text verborgen bleiben (Kontextüberlauf). Um Fehler zu minimieren und die bestehende RAG-Architektur zu verbessern, können Sie erweiterte RAG-Muster (Abruf von übergeordneten Dokumenten und kontextbezogene Komprimierung) verwenden, um Abruffehler zu reduzieren, die Antwortqualität zu verbessern und die Bearbeitung komplexer Fragen zu ermöglichen.
Mit den in diesem Beitrag besprochenen Techniken können Sie wichtige Herausforderungen im Zusammenhang mit der externen Wissensabfrage und -integration bewältigen und Ihrer Anwendung ermöglichen, präzisere und kontextbezogenere Antworten zu liefern.
In den folgenden Abschnitten untersuchen wir, wie Retriever für übergeordnete Dokumente und kontextbezogene Komprimierung kann Ihnen bei der Bewältigung einiger der von uns besprochenen Probleme helfen.
Retriever für übergeordnete Dokumente
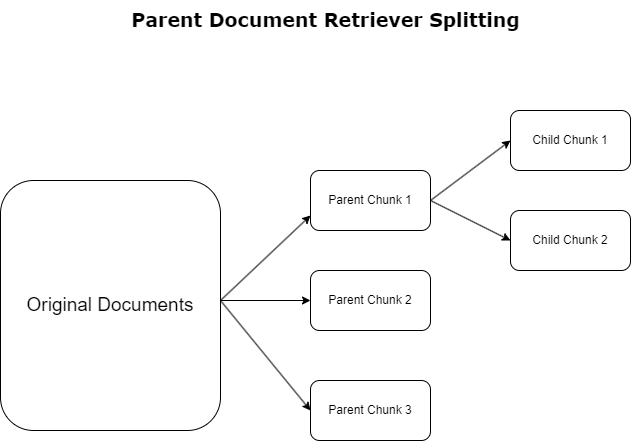
Im vorherigen Abschnitt haben wir die Herausforderungen hervorgehoben, denen RAG-Anwendungen beim Umgang mit umfangreichen Dokumenten gegenüberstehen. Um diese Herausforderungen anzugehen, Retriever für übergeordnete Dokumente Eingehende Dokumente kategorisieren und kennzeichnen als übergeordnete Dokumente. Diese Dokumente sind für ihren umfassenden Charakter bekannt, werden jedoch nicht direkt in ihrer ursprünglichen Form für Einbettungen verwendet. Anstatt ein gesamtes Dokument in eine einzige Einbettung zu komprimieren, zerlegen übergeordnete Dokument-Retriever diese übergeordneten Dokumente in Kinderdokumente. Jedes untergeordnete Dokument erfasst unterschiedliche Aspekte oder Themen aus dem umfassenderen übergeordneten Dokument. Nach der Identifizierung dieser untergeordneten Segmente werden ihnen individuelle Einbettungen zugewiesen, die ihre spezifische thematische Essenz erfassen (siehe folgende Abbildung). Beim Abruf wird das übergeordnete Dokument aufgerufen. Diese Technik bietet gezielte und dennoch weitreichende Suchmöglichkeiten und verschafft dem LLM eine breitere Perspektive. Retriever für übergeordnete Dokumente bieten LLMs einen doppelten Vorteil: die Spezifität der Einbettung von untergeordneten Dokumenten für den präzisen und relevanten Informationsabruf, gepaart mit dem Aufruf von übergeordneten Dokumenten zur Antwortgenerierung, wodurch die Ausgaben des LLM um einen vielschichtigen und umfassenden Kontext bereichert werden.
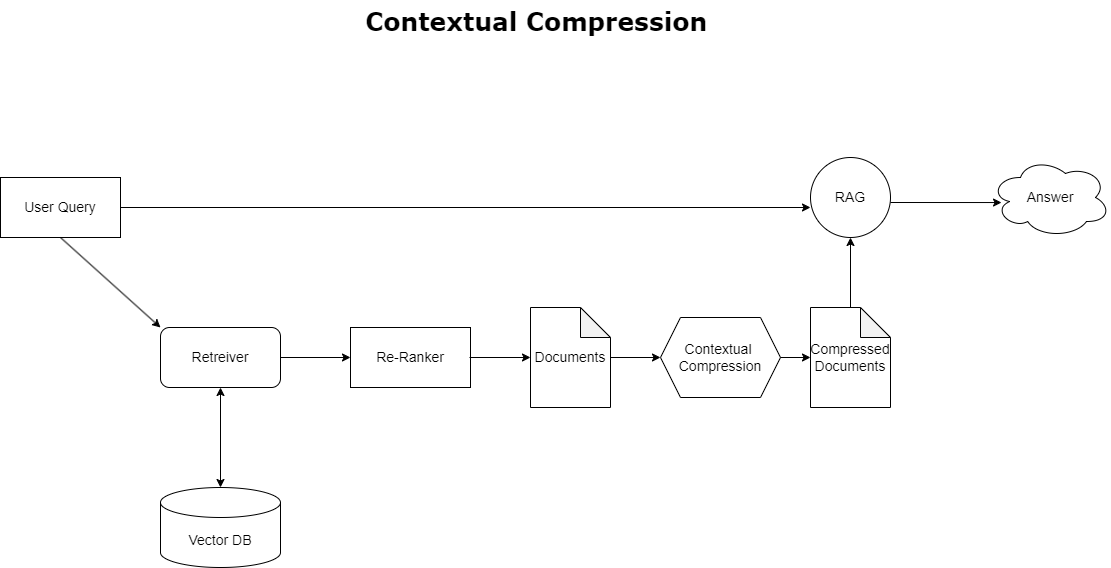
Kontextbezogene Komprimierung
Um das zuvor besprochene Problem des Kontextüberlaufs zu beheben, können Sie Folgendes verwenden: kontextbezogene Komprimierung um die abgerufenen Dokumente entsprechend dem Kontext der Abfrage zu komprimieren und zu filtern, sodass nur relevante Informationen gespeichert und verarbeitet werden. Dies wird durch eine Kombination aus einem Basis-Retriever zum anfänglichen Abrufen von Dokumenten und einem Dokumentenkompressor zum Verfeinern dieser Dokumente erreicht, indem ihr Inhalt reduziert oder sie basierend auf ihrer Relevanz vollständig ausgeschlossen werden, wie im folgenden Diagramm dargestellt. Dieser optimierte Ansatz, der durch den kontextbezogenen Komprimierungs-Retriever ermöglicht wird, steigert die Effizienz der RAG-Anwendung erheblich, indem er eine Methode bereitstellt, mit der nur das Wesentliche aus einer Informationsmenge extrahiert und genutzt werden kann. Es geht das Problem der Informationsüberflutung und der Verarbeitung irrelevanter Daten direkt an und führt zu einer verbesserten Antwortqualität, kostengünstigeren LLM-Operationen und einem reibungsloseren Gesamtabrufprozess. Im Wesentlichen handelt es sich um einen Filter, der die Informationen an die jeweilige Abfrage anpasst, was ihn zu einem dringend benötigten Werkzeug für Entwickler macht, die ihre RAG-Anwendungen für eine bessere Leistung und Benutzerzufriedenheit optimieren möchten.
Voraussetzungen:
Wenn Sie neu bei SageMaker sind, lesen Sie die Amazon SageMaker-Entwicklungshandbuch.
Bevor Sie mit der Lösung beginnen, Erstellen Sie ein AWS-Konto. Wenn Sie ein AWS-Konto erstellen, erhalten Sie eine Single-Sign-On-Identität (SSO), die vollständigen Zugriff auf alle AWS-Dienste und -Ressourcen im Konto hat. Diese Identität wird als AWS-Konto bezeichnet Root-Benutzer.
Anmeldung bei AWS-Managementkonsole Wenn Sie die E-Mail-Adresse und das Passwort verwenden, die Sie zum Erstellen des Kontos verwendet haben, erhalten Sie vollständigen Zugriff auf alle AWS-Ressourcen in Ihrem Konto. Wir empfehlen dringend, dass Sie den Root-Benutzer nicht für alltägliche Aufgaben verwenden, auch nicht für administrative.
Halten Sie sich stattdessen an die Best Practices für die Sicherheit in AWS Identity and Access Management and (Ich bin und Erstellen Sie einen Administratorbenutzer und eine Administratorgruppe. Sperren Sie dann die Anmeldeinformationen des Root-Benutzers sicher und verwenden Sie sie, um nur einige wenige Konto- und Dienstverwaltungsaufgaben auszuführen.
Das Mixtral-8x7b-Modell erfordert eine ml.g5.48xlarge-Instanz. SageMaker JumpStart bietet eine vereinfachte Möglichkeit, auf über 100 verschiedene Open-Source- und Drittanbieter-Grundlagenmodelle zuzugreifen und diese bereitzustellen. Um zu Starten Sie einen Endpunkt zum Hosten von Mixtral-8x7B über SageMaker JumpStart, müssen Sie möglicherweise eine Erhöhung des Dienstkontingents anfordern, um auf eine ml.g5.48xlarge-Instanz für die Endpunktnutzung zuzugreifen. Du kannst Anforderungsservice-Kontingent erhöht sich über die Konsole, AWS-Befehlszeilenschnittstelle (AWS CLI) oder API, um den Zugriff auf diese zusätzlichen Ressourcen zu ermöglichen.
Richten Sie eine SageMaker-Notebook-Instanz ein und installieren Sie Abhängigkeiten
Erstellen Sie zunächst eine SageMaker-Notebook-Instanz und installieren Sie die erforderlichen Abhängigkeiten. Siehe die GitHub Repo um eine erfolgreiche Einrichtung zu gewährleisten. Nachdem Sie die Notebook-Instanz eingerichtet haben, können Sie das Modell bereitstellen.
Sie können das Notebook auch lokal in Ihrer bevorzugten integrierten Entwicklungsumgebung (IDE) ausführen. Stellen Sie sicher, dass Sie das Jupyter Notebook Lab installiert haben.
Stellen Sie das Modell bereit
Stellen Sie das Mixtral-8X7B Instruct LLM-Modell auf SageMaker JumpStart bereit:
Stellen Sie das BGE Large En-Einbettungsmodell auf SageMaker JumpStart bereit:
Richten Sie LangChain ein
Nachdem Sie alle erforderlichen Bibliotheken importiert und das Mixtral-8x7B-Modell und das BGE Large En-Einbettungsmodell bereitgestellt haben, können Sie nun LangChain einrichten. Eine Schritt-für-Schritt-Anleitung finden Sie im GitHub Repo.
Datenaufbereitung
In diesem Beitrag verwenden wir die Briefe an die Aktionäre von Amazon aus mehreren Jahren als Textkorpus für die Frage-und-Antwort-Analyse. Ausführlichere Schritte zur Vorbereitung der Daten finden Sie im GitHub Repo.
Frage beantworten
Sobald die Daten vorbereitet sind, können Sie den von LangChain bereitgestellten Wrapper verwenden, der den Vektorspeicher umschließt und Eingaben für das LLM entgegennimmt. Dieser Wrapper führt die folgenden Schritte aus:
- Nehmen Sie die Eingabefrage.
- Erstellen Sie eine Frageneinbettung.
- Holen Sie sich relevante Dokumente.
- Integrieren Sie die Dokumente und die Frage in eine Eingabeaufforderung.
- Rufen Sie das Modell mit der Eingabeaufforderung auf und generieren Sie die Antwort auf lesbare Weise.
Da der Vektorspeicher nun eingerichtet ist, können Sie beginnen, Fragen zu stellen:
Reguläre Retrieverkette
Im vorherigen Szenario haben wir untersucht, wie Sie schnell und unkompliziert eine kontextbezogene Antwort auf Ihre Frage erhalten. Schauen wir uns nun eine anpassbarere Option mit Hilfe von RetrievalQA an, bei der Sie mithilfe des Parameters „chain_type“ anpassen können, wie die abgerufenen Dokumente zur Eingabeaufforderung hinzugefügt werden sollen. Um zu steuern, wie viele relevante Dokumente abgerufen werden sollen, können Sie außerdem den k-Parameter im folgenden Code ändern, um unterschiedliche Ausgaben anzuzeigen. In vielen Szenarien möchten Sie möglicherweise wissen, welche Quelldokumente das LLM zum Generieren der Antwort verwendet hat. Sie können diese Dokumente in der Ausgabe abrufen mit return_source_documents, das die Dokumente zurückgibt, die dem Kontext der LLM-Eingabeaufforderung hinzugefügt werden. Mit RetrievalQA können Sie auch eine benutzerdefinierte Eingabeaufforderungsvorlage bereitstellen, die spezifisch für das Modell sein kann.
Stellen wir eine Frage:
Abrufkette für übergeordnete Dokumente
Schauen wir uns mithilfe von eine erweiterte RAG-Option an ParentDocumentRetriever. Wenn Sie mit dem Abrufen von Dokumenten arbeiten, müssen Sie möglicherweise einen Kompromiss zwischen der Speicherung kleiner Teile eines Dokuments für genaue Einbettungen und größerer Dokumente zur Beibehaltung von mehr Kontext eingehen. Der Parent Document Retriever schafft dieses Gleichgewicht, indem er kleine Datenblöcke aufteilt und speichert.
Wir benutzen ein parent_splitter um die Originaldokumente in größere Teile zu unterteilen, die als übergeordnete Dokumente bezeichnet werden, und a child_splitter So erstellen Sie kleinere untergeordnete Dokumente aus den Originaldokumenten:
Die untergeordneten Dokumente werden dann mithilfe von Einbettungen in einem Vektorspeicher indiziert. Dies ermöglicht ein effizientes Abrufen relevanter untergeordneter Dokumente basierend auf Ähnlichkeit. Um relevante Informationen abzurufen, ruft der Retriever für übergeordnete Dokumente zunächst die untergeordneten Dokumente aus dem Vektorspeicher ab. Anschließend sucht es nach den übergeordneten IDs dieser untergeordneten Dokumente und gibt die entsprechenden größeren übergeordneten Dokumente zurück.
Stellen wir eine Frage:
Kontextuelle Komprimierungskette
Schauen wir uns eine weitere erweiterte RAG-Option namens an kontextbezogene Komprimierung. Eine Herausforderung beim Abrufen besteht darin, dass wir normalerweise nicht wissen, mit welchen spezifischen Abfragen Ihr Dokumentenspeichersystem konfrontiert wird, wenn Sie Daten in das System aufnehmen. Dies bedeutet, dass die für eine Abfrage relevantesten Informationen möglicherweise in einem Dokument mit viel irrelevantem Text verborgen sind. Die Weitergabe des vollständigen Dokuments durch Ihre Bewerbung kann zu teureren LLM-Anrufen und schlechteren Antworten führen.
Der kontextbezogene Komprimierungs-Retriever löst die Herausforderung, relevante Informationen aus einem Dokumentenspeichersystem abzurufen, in dem die relevanten Daten möglicherweise in Dokumenten mit viel Text verborgen sind. Durch Komprimieren und Filtern der abgerufenen Dokumente basierend auf dem gegebenen Abfragekontext werden nur die relevantesten Informationen zurückgegeben.
Um den kontextuellen Komprimierungs-Retriever zu verwenden, benötigen Sie:
- Ein Base-Retriever – Dies ist der erste Retriever, der basierend auf der Abfrage Dokumente aus dem Speichersystem abruft
- Ein Dokumentenkompressor – Diese Komponente nimmt die ursprünglich abgerufenen Dokumente und kürzt sie, indem sie den Inhalt einzelner Dokumente reduziert oder irrelevante Dokumente ganz löscht, wobei der Abfragekontext zur Bestimmung der Relevanz verwendet wird
Hinzufügen einer kontextbezogenen Komprimierung mit einem LLM-Kettenextraktor
Wickeln Sie zunächst Ihren Base Retriever mit einem ContextualCompressionRetriever. Sie fügen eine hinzu LLMChainExtractor, das die ursprünglich zurückgegebenen Dokumente durchläuft und aus jedem nur den Inhalt extrahiert, der für die Abfrage relevant ist.
Initialisieren Sie die Kette mit ContextualCompressionRetriever sowie einem LLMChainExtractor und übergeben Sie die Eingabeaufforderung über die chain_type_kwargs Argument.
Stellen wir eine Frage:
Filtern Sie Dokumente mit einem LLM-Kettenfilter
Das LLMChainFilter ist ein etwas einfacherer, aber robusterer Kompressor, der mithilfe einer LLM-Kette entscheidet, welche der ursprünglich abgerufenen Dokumente herausgefiltert und welche zurückgegeben werden sollen, ohne den Dokumentinhalt zu manipulieren:
Initialisieren Sie die Kette mit ContextualCompressionRetriever sowie einem LLMChainFilter und übergeben Sie die Eingabeaufforderung über die chain_type_kwargs Argument.
Stellen wir eine Frage:
Ergebnisse vergleichen
In der folgenden Tabelle werden die Ergebnisse verschiedener Abfragen je nach Technik verglichen.
| Technik | Abfrage 1 | Abfrage 2 | Vergleich |
| Wie hat sich AWS entwickelt? | Warum ist Amazon erfolgreich? | ||
| Reguläre Retriever-Kettenausgabe | AWS (Amazon Web Services) entwickelte sich von einer anfänglich unrentablen Investition zu einem Run-Rate-Unternehmen mit einem Jahresumsatz von 85 Milliarden US-Dollar und hoher Rentabilität, das ein breites Spektrum an Diensten und Funktionen anbot und zu einem bedeutenden Teil des Amazon-Portfolios wurde. Trotz Skepsis und kurzfristigem Gegenwind setzte AWS seine Innovationen fort, zog neue Kunden an und migrierte aktive Kunden und bot Vorteile wie Agilität, Innovation, Kosteneffizienz und Sicherheit. AWS hat außerdem seine langfristigen Investitionen, einschließlich der Chipentwicklung, ausgeweitet, um neue Funktionen bereitzustellen und die Möglichkeiten für seine Kunden zu verändern. | Amazon ist aufgrund seiner kontinuierlichen Innovation und Expansion in neue Bereiche wie Technologie-Infrastrukturdienste, digitale Lesegeräte, sprachgesteuerte persönliche Assistenten und neue Geschäftsmodelle wie der Drittanbieter-Marktplatz erfolgreich. Auch die Fähigkeit des Unternehmens, den Betrieb schnell zu skalieren, was sich in der raschen Ausweitung seiner Fulfillment- und Transportnetzwerke zeigt, trägt zum Erfolg bei. Darüber hinaus hat Amazons Fokus auf Optimierung und Effizienzsteigerung seiner Prozesse zu Produktivitätsverbesserungen und Kostensenkungen geführt. Das Beispiel Amazon Business unterstreicht die Fähigkeit des Unternehmens, seine E-Commerce- und Logistikstärken in verschiedenen Sektoren zu nutzen. | Basierend auf den Antworten der regulären Retriever-Kette stellen wir fest, dass sie zwar lange Antworten liefert, aber unter einem Kontextüberlauf leidet und keine wesentlichen Details aus dem Korpus in Bezug auf die Beantwortung der gestellten Anfrage erwähnt. Die reguläre Abrufkette ist nicht in der Lage, die Nuancen mit Tiefe oder kontextbezogenem Einblick zu erfassen, wodurch möglicherweise kritische Aspekte des Dokuments übersehen werden. |
| Ausgabe des übergeordneten Dokument-Retrievers | AWS (Amazon Web Services) begann mit einem funktionsarmen ersten Start des Elastic Compute Cloud (EC2)-Dienstes im Jahr 2006, der nur eine Instanzgröße in einem Rechenzentrum in einer Region der Welt mit ausschließlich Linux-Betriebssysteminstanzen bereitstellte und ohne viele wichtige Funktionen wie Überwachung, Lastausgleich, automatische Skalierung oder dauerhaften Speicher. Der Erfolg von AWS ermöglichte es ihnen jedoch, die fehlenden Funktionen schnell zu iterieren und hinzuzufügen und schließlich zu erweitern, um verschiedene Varianten, Größen und Optimierungen von Rechenleistung, Speicher und Netzwerk anzubieten sowie eigene Chips (Graviton) zu entwickeln, um Preis und Leistung weiter zu steigern . Der iterative Innovationsprozess von AWS erforderte über einen Zeitraum von 20 Jahren erhebliche Investitionen in finanzielle und personelle Ressourcen, oft lange vor dem Zeitpunkt der Auszahlung, um die Kundenbedürfnisse zu erfüllen und die Kundenerfahrung, Loyalität und Rendite für die Aktionäre langfristig zu verbessern. | Amazon ist aufgrund seiner Fähigkeit, ständig Innovationen zu entwickeln, sich an veränderte Marktbedingungen anzupassen und Kundenbedürfnisse in verschiedenen Marktsegmenten zu erfüllen, erfolgreich. Dies zeigt sich am Erfolg von Amazon Business, das durch die Bereitstellung von Auswahl, Wert und Komfort für Geschäftskunden einen jährlichen Bruttoumsatz von rund 35 Milliarden US-Dollar erzielt hat. Die Investitionen von Amazon in E-Commerce- und Logistikkapazitäten haben auch die Entwicklung von Diensten wie „Buy with Prime“ ermöglicht, die Händlern mit Direct-to-Consumer-Websites dabei helfen, die Umwandlung von Ansichten in Käufe zu steigern. | Der Parent Document Retriever befasst sich eingehender mit den Besonderheiten der Wachstumsstrategie von AWS, einschließlich des iterativen Prozesses des Hinzufügens neuer Funktionen auf der Grundlage von Kundenfeedback und der detaillierten Reise von einer funktionsarmen Ersteinführung zu einer dominanten Marktposition, und bietet gleichzeitig eine kontextreiche Antwort . Die Antworten decken ein breites Spektrum an Aspekten ab, von technischen Innovationen und Marktstrategie bis hin zu organisatorischer Effizienz und Kundenorientierung, und bieten einen ganzheitlichen Blick auf die Erfolgsfaktoren sowie Beispiele. Dies ist auf die gezielten und dennoch umfassenden Suchfunktionen des Parent Document Retrievers zurückzuführen. |
| LLM Chain Extractor: Kontextbezogene Komprimierungsausgabe | AWS entwickelte sich, indem es als kleines Projekt innerhalb von Amazon begann, erhebliche Kapitalinvestitionen erforderte und sowohl innerhalb als auch außerhalb des Unternehmens auf Skepsis stieß. AWS hatte jedoch einen Vorsprung gegenüber potenziellen Konkurrenten und glaubte an den Mehrwert, den es für Kunden und Amazon bringen könnte. AWS hat sich langfristig dazu verpflichtet, weiter zu investieren, was zur Einführung von über 3,300 neuen Funktionen und Diensten im Jahr 2022 führte. AWS hat die Art und Weise, wie Kunden ihre Technologieinfrastruktur verwalten, verändert und ist zu einem Unternehmen mit einem Jahresumsatz von 85 Milliarden US-Dollar und hoher Rentabilität geworden. Darüber hinaus hat AWS seine Angebote kontinuierlich verbessert, beispielsweise durch die Erweiterung von EC2 nach seiner ersten Einführung um zusätzliche Funktionen und Dienste. | Basierend auf dem gegebenen Kontext kann der Erfolg von Amazon auf die strategische Expansion von einer Buchhandelsplattform zu einem globalen Marktplatz mit einem dynamischen Drittanbieter-Ökosystem, frühen Investitionen in AWS, Innovationen bei der Einführung von Kindle und Alexa und erheblichem Wachstum zurückgeführt werden im Jahresumsatz von 2019 bis 2022. Dieses Wachstum führte zur Erweiterung der Logistikzentrumsfläche, zur Schaffung eines Last-Mile-Transportnetzwerks und zum Aufbau eines neuen Sortierzentrumsnetzwerks, die auf Produktivität und Kostensenkung optimiert wurden. | Der LLM-Kettenextraktor hält die Balance zwischen der umfassenden Abdeckung wichtiger Punkte und der Vermeidung unnötiger Tiefe. Es passt sich dynamisch an den Kontext der Abfrage an, sodass die Ausgabe direkt relevant und umfassend ist. |
| LLM-Kettenfilter: Kontextbezogene Komprimierungsausgabe | AWS (Amazon Web Services) entwickelte sich dadurch weiter, dass es anfänglich nur wenige Funktionen hatte, dann aber auf der Grundlage des Kundenfeedbacks schnell iterierte, um die notwendigen Funktionen hinzuzufügen. Dieser Ansatz ermöglichte es AWS, EC2 im Jahr 2006 mit eingeschränkten Funktionen zu starten und dann kontinuierlich neue Funktionalitäten hinzuzufügen, wie z. B. zusätzliche Instanzgrößen, Rechenzentren, Regionen, Betriebssystemoptionen, Überwachungstools, Lastausgleich, automatische Skalierung und persistenten Speicher. Im Laufe der Zeit wandelte sich AWS von einem funktionsarmen Dienst zu einem Multimilliarden-Dollar-Unternehmen, indem es sich auf Kundenbedürfnisse, Agilität, Innovation, Kosteneffizienz und Sicherheit konzentrierte. AWS hat mittlerweile einen Jahresumsatz von 85 Milliarden US-Dollar und bietet jedes Jahr über 3,300 neue Funktionen und Dienste und richtet sich an ein breites Kundenspektrum, von Start-ups bis hin zu multinationalen Unternehmen und Organisationen des öffentlichen Sektors. | Amazon ist aufgrund seiner innovativen Geschäftsmodelle, kontinuierlichen technologischen Fortschritte und strategischen organisatorischen Veränderungen erfolgreich. Das Unternehmen hat durch die Einführung neuer Ideen, wie einer E-Commerce-Plattform für verschiedene Produkte und Dienstleistungen, einem Drittanbieter-Marktplatz, Cloud-Infrastrukturdiensten (AWS), dem Kindle-E-Reader und dem sprachgesteuerten persönlichen Assistenten Alexa immer wieder traditionelle Industrien auf den Kopf gestellt . Darüber hinaus hat Amazon strukturelle Änderungen vorgenommen, um seine Effizienz zu verbessern, wie z. B. die Neuorganisation seines US-amerikanischen Fulfillment-Netzwerks, um Kosten und Lieferzeiten zu senken, was weiter zu seinem Erfolg beiträgt. | Ähnlich wie der LLM-Kettenextraktor stellt der LLM-Kettenfilter sicher, dass die wichtigsten Punkte zwar abgedeckt werden, die Ausgabe jedoch effizient für Kunden ist, die nach prägnanten und kontextbezogenen Antworten suchen. |
Wenn wir diese verschiedenen Techniken vergleichen, können wir erkennen, dass in Kontexten wie der detaillierten Beschreibung des Übergangs von AWS von einem einfachen Dienst zu einem komplexen, mehrere Milliarden Dollar schweren Unternehmen oder der Erklärung der strategischen Erfolge von Amazon der regulären Retriever-Kette die Präzision fehlt, die anspruchsvollere Techniken bieten. Dies führt zu weniger gezielten Informationen. Obwohl zwischen den besprochenen fortgeschrittenen Techniken nur sehr wenige Unterschiede sichtbar sind, sind sie weitaus informativer als herkömmliche Retrieverketten.
Für Kunden in Branchen wie Gesundheitswesen, Telekommunikation und Finanzdienstleistungen, die RAG in ihren Anwendungen implementieren möchten, ist die reguläre Retriever-Kette aufgrund ihrer Einschränkungen bei der Bereitstellung von Präzision, der Vermeidung von Redundanz und der effektiven Komprimierung von Informationen weniger geeignet, diese Anforderungen zu erfüllen zu den fortgeschritteneren Techniken zum Abrufen übergeordneter Dokumente und zur kontextbezogenen Komprimierung. Diese Techniken sind in der Lage, große Informationsmengen in konzentrierte, aussagekräftige Erkenntnisse umzuwandeln, die Sie benötigen, und tragen gleichzeitig zur Verbesserung des Preis-Leistungs-Verhältnisses bei.
Aufräumen
Wenn Sie mit der Ausführung des Notebooks fertig sind, löschen Sie die von Ihnen erstellten Ressourcen, um zu vermeiden, dass Gebühren für die verwendeten Ressourcen anfallen:
Zusammenfassung
In diesem Beitrag haben wir eine Lösung vorgestellt, mit der Sie den Parent Document Retriever und kontextbezogene Komprimierungskettentechniken implementieren können, um die Fähigkeit von LLMs, Informationen zu verarbeiten und zu generieren, zu verbessern. Wir haben diese fortgeschrittenen RAG-Techniken mit den Modellen Mixtral-8x7B Instruct und BGE Large En getestet, die mit SageMaker JumpStart verfügbar sind. Wir haben auch die Verwendung von persistentem Speicher für Einbettungen und Dokumentblöcke sowie die Integration in Unternehmensdatenspeicher untersucht.
Die von uns durchgeführten Techniken verfeinern nicht nur die Art und Weise, wie LLM-Modelle auf externes Wissen zugreifen und es integrieren, sondern verbessern auch erheblich die Qualität, Relevanz und Effizienz ihrer Ergebnisse. Durch die Kombination des Abrufs aus großen Textkorpora mit Funktionen zur Sprachgenerierung ermöglichen diese fortschrittlichen RAG-Techniken LLMs, sachlichere, kohärentere und kontextgerechtere Antworten zu erzeugen und so ihre Leistung bei verschiedenen Aufgaben der Verarbeitung natürlicher Sprache zu verbessern.
Im Mittelpunkt dieser Lösung steht SageMaker JumpStart. Mit SageMaker JumpStart erhalten Sie Zugriff auf eine umfangreiche Auswahl an Open- und Closed-Source-Modellen, was den Einstieg in ML rationalisiert und ein schnelles Experimentieren und Bereitstellen ermöglicht. Um mit der Bereitstellung dieser Lösung zu beginnen, navigieren Sie zum Notizbuch im GitHub Repo.
Über die Autoren
 Niithiyn Vijeaswaran ist Lösungsarchitekt bei AWS. Sein Schwerpunkt liegt auf generativer KI und AWS AI Accelerators. Er hat einen Bachelor-Abschluss in Informatik und Bioinformatik. Niithiyn arbeitet eng mit dem Generative AI GTM-Team zusammen, um AWS-Kunden an mehreren Fronten zu unterstützen und ihre Einführung generativer KI zu beschleunigen. Er ist ein begeisterter Fan der Dallas Mavericks und sammelt gerne Turnschuhe.
Niithiyn Vijeaswaran ist Lösungsarchitekt bei AWS. Sein Schwerpunkt liegt auf generativer KI und AWS AI Accelerators. Er hat einen Bachelor-Abschluss in Informatik und Bioinformatik. Niithiyn arbeitet eng mit dem Generative AI GTM-Team zusammen, um AWS-Kunden an mehreren Fronten zu unterstützen und ihre Einführung generativer KI zu beschleunigen. Er ist ein begeisterter Fan der Dallas Mavericks und sammelt gerne Turnschuhe.
 Sebastian Bustillo ist Lösungsarchitekt bei AWS. Er konzentriert sich auf KI/ML-Technologien mit einer großen Leidenschaft für generative KI und Rechenbeschleuniger. Bei AWS hilft er Kunden, durch generative KI Geschäftswerte zu erschließen. Wenn er nicht bei der Arbeit ist, genießt er es, eine perfekte Tasse Kaffeespezialität zuzubereiten und mit seiner Frau die Welt zu erkunden.
Sebastian Bustillo ist Lösungsarchitekt bei AWS. Er konzentriert sich auf KI/ML-Technologien mit einer großen Leidenschaft für generative KI und Rechenbeschleuniger. Bei AWS hilft er Kunden, durch generative KI Geschäftswerte zu erschließen. Wenn er nicht bei der Arbeit ist, genießt er es, eine perfekte Tasse Kaffeespezialität zuzubereiten und mit seiner Frau die Welt zu erkunden.
 Armando Diaz ist Lösungsarchitekt bei AWS. Sein Fokus liegt auf generativer KI, KI/ML und Datenanalyse. Bei AWS unterstützt Armando Kunden bei der Integration modernster generativer KI-Funktionen in ihre Systeme und fördert so Innovationen und Wettbewerbsvorteile. Wenn er nicht bei der Arbeit ist, verbringt er gerne Zeit mit seiner Frau und seiner Familie, wandert und bereist die Welt.
Armando Diaz ist Lösungsarchitekt bei AWS. Sein Fokus liegt auf generativer KI, KI/ML und Datenanalyse. Bei AWS unterstützt Armando Kunden bei der Integration modernster generativer KI-Funktionen in ihre Systeme und fördert so Innovationen und Wettbewerbsvorteile. Wenn er nicht bei der Arbeit ist, verbringt er gerne Zeit mit seiner Frau und seiner Familie, wandert und bereist die Welt.
 Dr. Farooq Sabir ist ein leitender Lösungsarchitekt für künstliche Intelligenz und maschinelles Lernen bei AWS. Er hat einen PhD- und MS-Abschluss in Elektrotechnik von der University of Texas at Austin und einen MS in Informatik vom Georgia Institute of Technology. Er hat über 15 Jahre Berufserfahrung und unterrichtet und betreut auch gerne College-Studenten. Bei AWS hilft er Kunden bei der Formulierung und Lösung ihrer Geschäftsprobleme in den Bereichen Datenwissenschaft, maschinelles Lernen, Computer Vision, künstliche Intelligenz, numerische Optimierung und verwandte Bereiche. Er lebt in Dallas, Texas, und seine Familie liebt es zu reisen und lange Autofahrten zu unternehmen.
Dr. Farooq Sabir ist ein leitender Lösungsarchitekt für künstliche Intelligenz und maschinelles Lernen bei AWS. Er hat einen PhD- und MS-Abschluss in Elektrotechnik von der University of Texas at Austin und einen MS in Informatik vom Georgia Institute of Technology. Er hat über 15 Jahre Berufserfahrung und unterrichtet und betreut auch gerne College-Studenten. Bei AWS hilft er Kunden bei der Formulierung und Lösung ihrer Geschäftsprobleme in den Bereichen Datenwissenschaft, maschinelles Lernen, Computer Vision, künstliche Intelligenz, numerische Optimierung und verwandte Bereiche. Er lebt in Dallas, Texas, und seine Familie liebt es zu reisen und lange Autofahrten zu unternehmen.
 Marco Punio ist ein Lösungsarchitekt, der sich auf generative KI-Strategien, angewandte KI-Lösungen und die Durchführung von Forschungen konzentriert, um Kunden bei der Hyperskalierung auf AWS zu unterstützen. Marco ist ein digital nativer Cloud-Berater mit Erfahrung in den Bereichen FinTech, Gesundheitswesen und Biowissenschaften, Software-as-a-Service und zuletzt in der Telekommunikationsbranche. Er ist ein qualifizierter Technologe mit einer Leidenschaft für maschinelles Lernen, künstliche Intelligenz sowie Fusionen und Übernahmen. Marco lebt in Seattle, WA und schreibt, liest, trainiert und erstellt in seiner Freizeit gerne Anwendungen.
Marco Punio ist ein Lösungsarchitekt, der sich auf generative KI-Strategien, angewandte KI-Lösungen und die Durchführung von Forschungen konzentriert, um Kunden bei der Hyperskalierung auf AWS zu unterstützen. Marco ist ein digital nativer Cloud-Berater mit Erfahrung in den Bereichen FinTech, Gesundheitswesen und Biowissenschaften, Software-as-a-Service und zuletzt in der Telekommunikationsbranche. Er ist ein qualifizierter Technologe mit einer Leidenschaft für maschinelles Lernen, künstliche Intelligenz sowie Fusionen und Übernahmen. Marco lebt in Seattle, WA und schreibt, liest, trainiert und erstellt in seiner Freizeit gerne Anwendungen.
 AJ Dhimine ist Lösungsarchitekt bei AWS. Er ist spezialisiert auf generative KI, Serverless Computing und Datenanalyse. Er ist aktives Mitglied/Mentor in der Machine Learning Technical Field Community und hat mehrere wissenschaftliche Arbeiten zu verschiedenen KI/ML-Themen veröffentlicht. Er arbeitet mit Kunden, von Start-ups bis hin zu Unternehmen, zusammen, um einige generative KI-Lösungen zu entwickeln. Seine besondere Leidenschaft gilt der Nutzung großer Sprachmodelle für erweiterte Datenanalysen und der Erforschung praktischer Anwendungen, die reale Herausforderungen angehen. Außerhalb der Arbeit reist AJ gerne und ist derzeit in 53 Ländern unterwegs, mit dem Ziel, jedes Land der Welt zu besuchen.
AJ Dhimine ist Lösungsarchitekt bei AWS. Er ist spezialisiert auf generative KI, Serverless Computing und Datenanalyse. Er ist aktives Mitglied/Mentor in der Machine Learning Technical Field Community und hat mehrere wissenschaftliche Arbeiten zu verschiedenen KI/ML-Themen veröffentlicht. Er arbeitet mit Kunden, von Start-ups bis hin zu Unternehmen, zusammen, um einige generative KI-Lösungen zu entwickeln. Seine besondere Leidenschaft gilt der Nutzung großer Sprachmodelle für erweiterte Datenanalysen und der Erforschung praktischer Anwendungen, die reale Herausforderungen angehen. Außerhalb der Arbeit reist AJ gerne und ist derzeit in 53 Ländern unterwegs, mit dem Ziel, jedes Land der Welt zu besuchen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

