Für die Erstellung generativer KI-Anwendungen ist die Anreicherung der großen Sprachmodelle (LLMs) mit neuen Daten unerlässlich. Hier kommt die Retrieval Augmented Generation (RAG)-Technik ins Spiel. RAG ist eine Architektur für maschinelles Lernen (ML), die externe Dokumente (wie Wikipedia) nutzt, um ihr Wissen zu erweitern und hochmoderne Ergebnisse bei wissensintensiven Aufgaben zu erzielen . Für die Aufnahme dieser externen Datenquellen wurden Vektordatenbanken entwickelt, die Vektoreinbettungen der Datenquelle speichern und Ähnlichkeitssuchen ermöglichen können.
In diesem Beitrag zeigen wir, wie man eine RAG-Einspeisungspipeline zum Extrahieren, Transformieren und Laden (ETL) erstellt, um große Datenmengen in eine aufzunehmen Amazon OpenSearch-Dienst Cluster und Nutzung Amazon Relational Database Service (Amazon RDS) für PostgreSQL mit der Erweiterung pgvector als Vektordatenspeicher. Jeder Dienst implementiert k-nearest neighbor (k-NN) oder approximative next neighbour (ANN)-Algorithmen und Distanzmetriken, um die Ähnlichkeit zu berechnen. Wir führen die Integration von ein Strahl in den RAG-Mechanismus zum Abrufen kontextueller Dokumente integriert. Ray ist eine Open-Source-Python-Bibliothek für verteiltes Rechnen für allgemeine Zwecke. Es ermöglicht die verteilte Datenverarbeitung zum Generieren und Speichern von Einbettungen für große Datenmengen und die Parallelisierung über mehrere GPUs hinweg. Wir verwenden einen Ray-Cluster mit diesen GPUs, um für jeden Dienst parallele Aufnahme und Abfrage auszuführen.
In diesem Experiment versuchen wir, die folgenden Aspekte für OpenSearch Service und die pgvector-Erweiterung auf Amazon RDS zu analysieren:
- Als Vektorspeicher bietet RAG die Möglichkeit, einen großen Datensatz mit mehreren zehn Millionen Datensätzen zu skalieren und zu verarbeiten
- Mögliche Engpässe in der Ingest-Pipeline für RAG
- So erreichen Sie eine optimale Leistung bei den Aufnahme- und Abfrageabrufzeiten für OpenSearch Service und Amazon RDS
Weitere Informationen zu Vektordatenspeichern und ihrer Rolle bei der Erstellung generativer KI-Anwendungen finden Sie unter Die Rolle von Vektordatenspeichern in generativen KI-Anwendungen.
Übersicht über den OpenSearch-Dienst
OpenSearch Service ist ein verwalteter Dienst für die sichere Analyse, Suche und Indizierung von Geschäfts- und Betriebsdaten. Der OpenSearch-Dienst unterstützt Daten im Petabyte-Bereich mit der Möglichkeit, mehrere Indizes für Text- und Vektordaten zu erstellen. Bei optimierter Konfiguration wird eine hohe Erinnerung an die Abfragen angestrebt. Der OpenSearch-Dienst unterstützt sowohl ANN als auch die exakte k-NN-Suche. OpenSearch Service unterstützt eine Auswahl von Algorithmen aus dem NMSLIB, FAISS und Lucene Bibliotheken zur Unterstützung der k-NN-Suche. Wir haben den ANN-Index für OpenSearch mit dem Hierarchical Navigable Small World (HNSW)-Algorithmus erstellt, da dieser als bessere Suchmethode für große Datensätze gilt. Weitere Informationen zur Auswahl des Indexalgorithmus finden Sie unter Wählen Sie mit OpenSearch den k-NN-Algorithmus für Ihren milliardenschweren Anwendungsfall.
Übersicht über Amazon RDS für PostgreSQL mit pgvector
Die pgvector-Erweiterung fügt PostgreSQL eine Open-Source-Vektorähnlichkeitssuche hinzu. Durch die Verwendung der pgvector-Erweiterung kann PostgreSQL Ähnlichkeitssuchen für Vektoreinbettungen durchführen und bietet Unternehmen so eine schnelle und kompetente Lösung. pgvector bietet zwei Arten von Vektorähnlichkeitssuchen: „Exakter nächster Nachbar“, der mit 100 % Rückruf ergibt, und „Annähernder nächster Nachbar“ (ANN), der eine bessere Leistung als die exakte Suche mit einem Kompromiss beim Rückruf bietet. Bei Suchvorgängen über einen Index können Sie auswählen, wie viele Zentren bei der Suche verwendet werden sollen, wobei mehr Zentren eine bessere Erinnerung bei einem Kompromiss bei der Leistung bieten.
Lösungsüberblick
Das folgende Diagramm zeigt die Lösungsarchitektur.

Schauen wir uns die Schlüsselkomponenten genauer an.
Datensatz
Wir verwenden OSCAR-Daten als Korpus und den SQUAD-Datensatz, um Beispielfragen bereitzustellen. Diese Datensätze werden zunächst in Parquet-Dateien konvertiert. Dann verwenden wir einen Ray-Cluster, um die Parquet-Daten in Einbettungen umzuwandeln. Die erstellten Einbettungen werden mit pgvector in OpenSearch Service und Amazon RDS aufgenommen.
OSCAR (Open Super-large Crawled Aggregated Corpus) ist ein riesiger mehrsprachiger Korpus, der durch Sprachklassifizierung und Filterung der gewonnen wird Allgemeines Crawlen Korpus unter Verwendung der unhöflich die Architektur. Die Daten werden je nach Sprache sowohl im Original als auch in deduplizierter Form verteilt. Der Oscar Corpus-Datensatz umfasst etwa 609 Millionen Datensätze und nimmt als JSONL-Rohdateien etwa 4.5 TB ein. Anschließend werden die JSONL-Dateien in das Parquet-Format konvertiert, wodurch die Gesamtgröße auf 1.8 TB minimiert wird. Wir haben den Datensatz weiter auf 25 Millionen Datensätze verkleinert, um bei der Aufnahme Zeit zu sparen.
SQuAD (Stanford Question Answering Dataset) ist ein Datensatz zum Leseverständnis, der aus Fragen besteht, die Crowdworker zu einer Reihe von Wikipedia-Artikeln gestellt haben, wobei die Antwort auf jede Frage ein Textsegment ist Spannweite, aus der entsprechenden Lesepassage, sonst könnte die Frage unbeantwortbar sein. Wir gebrauchen KADER, lizenziert als CC-BY-SA 4.0, um Beispielfragen bereitzustellen. Es enthält etwa 100,000 Fragen, davon über 50,000 unbeantwortbare Fragen, die von Crowdworkern so geschrieben wurden, dass sie den beantwortbaren Fragen ähneln.
Ray-Cluster zur Aufnahme und Erstellung von Vektoreinbettungen
Bei unseren Tests haben wir festgestellt, dass die GPUs beim Erstellen der Einbettungen den größten Einfluss auf die Leistung haben. Aus diesem Grund haben wir uns entschieden, einen Ray-Cluster zu verwenden, um unseren Rohtext zu konvertieren und die Einbettungen zu erstellen. Strahl ist ein einheitliches Open-Source-Computing-Framework, das es ML-Ingenieuren und Python-Entwicklern ermöglicht, Python-Anwendungen zu skalieren und ML-Workloads zu beschleunigen. Unser Cluster bestand aus 5 g4dn.12xlarge Amazon Elastic Compute-Cloud (Amazon EC2) Instanzen. Jede Instanz wurde mit 4 NVIDIA T4 Tensor Core GPUs, 48 vCPU und 192 GiB Arbeitsspeicher konfiguriert. Für unsere Textdatensätze haben wir letztendlich jeden in 1,000 Teile mit einer Überlappung von 100 Teilen aufgeteilt. Dies sind etwa 200 pro Datensatz. Für das Modell, das zum Erstellen von Einbettungen verwendet wird, haben wir uns entschieden all-mpnet-base-v2 um einen 768-dimensionalen Vektorraum zu erstellen.
Einrichtung der Infrastruktur
Wir haben die folgenden RDS-Instanztypen und OpenSearch-Service-Cluster-Konfigurationen verwendet, um unsere Infrastruktur einzurichten.
Im Folgenden sind die Eigenschaften unseres RDS-Instanztyps aufgeführt:
- Instanztyp: db.r7g.12xlarge
- Zugewiesener Speicher: 20 TB
- Multi-AZ: Stimmt
- Speicher verschlüsselt: True
- Leistungseinblicke aktivieren: True
- Aufbewahrung von Performance Insight: 7 Tage
- Speichertyp: GP3
- Bereitgestellte IOPS: 64,000
- Indextyp: IVF
- Anzahl der Listen: 5,000
- Distanzfunktion: L2
Im Folgenden sind die Eigenschaften unseres OpenSearch Service-Clusters aufgeführt:
- Version: 2.5
- Datenknoten: 10
- Datenknoten-Instanztyp: r6g.4xlarge
- Primärknoten: 3
- Typ der primären Knoteninstanz: r6g.xlarge
- Index: HNSW-Motor:
nmslib - Aktualisierungsintervall: 30 Sekunden
ef_construction: 256- m: 16
- Distanzfunktion: L2
Wir haben große Konfigurationen sowohl für den OpenSearch Service-Cluster als auch für die RDS-Instanzen verwendet, um Leistungsengpässe zu vermeiden.
Wir stellen die Lösung mit einem bereit AWS Cloud-Entwicklungskit (AWS-CDK) Stapel, wie im folgenden Abschnitt beschrieben.
Stellen Sie den AWS CDK-Stack bereit
Der AWS CDK-Stack ermöglicht es uns, OpenSearch Service oder Amazon RDS für die Datenaufnahme zu wählen.
Voraussetzungen
Bevor Sie mit der Installation fortfahren, ändern Sie unter cdk, bin, src.tc die booleschen Werte für Amazon RDS und OpenSearch Service je nach Wunsch entweder in „true“ oder „false“.
Sie benötigen außerdem einen Service-Link AWS Identity and Access Management and (IAM)-Rolle für die OpenSearch Service-Domäne. Weitere Einzelheiten finden Sie unter Amazon OpenSearch Service-Konstruktbibliothek. Sie können auch den folgenden Befehl ausführen, um die Rolle zu erstellen:
Dieser AWS CDK-Stack stellt die folgende Infrastruktur bereit:
- Eine VPC
- Ein Jump-Host (innerhalb der VPC)
- Ein OpenSearch-Service-Cluster (bei Verwendung des OpenSearch-Service für die Aufnahme)
- Eine RDS-Instanz (bei Verwendung von Amazon RDS für die Aufnahme)
- An AWS-Systemmanager Dokument zur Bereitstellung des Ray-Clusters
- An Amazon Simple Storage-Service (Amazon S3) Eimer
- An AWS-Kleber Job zum Konvertieren der JSONL-Dateien des OSCAR-Datensatzes in Parquet-Dateien
- Amazon CloudWatch Dashboards
Laden Sie die Daten herunter
Führen Sie die folgenden Befehle vom Jump-Host aus:
Stellen Sie vor dem Klonen des Git-Repos sicher, dass Sie über ein Hugging Face-Profil und Zugriff auf den OSCAR-Datenkorpus verfügen. Zum Klonen der OSCAR-Daten müssen Sie den Benutzernamen und das Passwort verwenden:
Konvertieren Sie JSONL-Dateien in Parquet
Der AWS CDK-Stack hat den AWS Glue ETL-Job erstellt oscar-jsonl-parquet um die OSCAR-Daten vom JSONL- in das Parquet-Format zu konvertieren.
Nachdem Sie die oscar-jsonl-parquet Job sollten die Dateien im Parquet-Format im Parquet-Ordner im S3-Bucket verfügbar sein.
Laden Sie die Fragen herunter
Laden Sie die Fragendaten von Ihrem Jump-Host herunter und laden Sie sie in Ihren S3-Bucket hoch:
Richten Sie den Ray-Cluster ein
Im Rahmen der AWS CDK-Stack-Bereitstellung haben wir ein Systems Manager-Dokument mit dem Namen erstellt CreateRayCluster.
Um das Dokument auszuführen, führen Sie die folgenden Schritte aus:
- Auf der Systems Manager-Konsole unter Dokumente Wählen Sie im Navigationsbereich Gehört mir.
- Öffnen Sie den Microsoft Store auf Ihrem Windows-PC.
CreateRayClusterDokument. - Auswählen Führen Sie.
Auf der Ausführungsbefehlsseite werden die Standardwerte für den Cluster ausgefüllt.
Die Standardkonfiguration erfordert 5 g4dn.12xlarge. Stellen Sie sicher, dass Ihr Konto über Grenzen verfügt, die dies unterstützen. Das relevante Servicelimit ist das Ausführen von On-Demand-G- und VT-Instanzen. Der Standardwert hierfür ist 64, diese Konfiguration erfordert jedoch 240 CPUS.
- Nachdem Sie die Clusterkonfiguration überprüft haben, wählen Sie den Jump-Host als Ziel für den Ausführungsbefehl aus.
Dieser Befehl führt die folgenden Schritte aus:
- Kopieren Sie die Ray-Cluster-Dateien
- Richten Sie den Ray-Cluster ein
- Richten Sie die OpenSearch Service-Indizes ein
- Richten Sie die RDS-Tabellen ein
Sie können die Ausgabe der Befehle auf der Systems Manager-Konsole überwachen. Dieser Vorgang dauert beim ersten Start 10–15 Minuten.
Führen Sie die Aufnahme aus
Stellen Sie vom Jump-Host aus eine Verbindung zum Ray-Cluster her:
Wenn Sie zum ersten Mal eine Verbindung zum Host herstellen, installieren Sie die Anforderungen. Diese Dateien sollten bereits auf dem Hauptknoten vorhanden sein.
Wenn Sie bei einer der Aufnahmemethoden eine Fehlermeldung wie die folgende erhalten, hängt dies mit abgelaufenen Anmeldeinformationen zusammen. Die aktuelle Problemumgehung (zum Zeitpunkt dieses Schreibens) besteht darin, Anmeldeinformationsdateien im Ray-Hauptknoten zu platzieren. Um Sicherheitsrisiken zu vermeiden, verwenden Sie keine IAM-Benutzer zur Authentifizierung, wenn Sie speziell entwickelte Software entwickeln oder mit echten Daten arbeiten. Verwenden Sie stattdessen die Föderation mit einem Identitätsanbieter wie z AWS IAM Identity Center (Nachfolger von AWS Single Sign-On).
Normalerweise werden die Anmeldeinformationen in der Datei gespeichert ~/.aws/credentials auf Linux- und macOS-Systemen und %USERPROFILE%.awscredentials unter Windows, es handelt sich hierbei jedoch um kurzfristige Anmeldeinformationen mit einem Sitzungstoken. Sie können die Standard-Anmeldeinformationsdatei auch nicht überschreiben und müssen daher langfristige Anmeldeinformationen ohne Sitzungstoken mit einem neuen IAM-Benutzer erstellen.
Um langfristige Anmeldeinformationen zu erstellen, müssen Sie einen AWS-Zugriffsschlüssel und einen geheimen AWS-Zugriffsschlüssel generieren. Sie können dies über die IAM-Konsole tun. Anweisungen finden Sie unter Authentifizieren Sie sich mit IAM-Benutzeranmeldeinformationen.
Nachdem Sie die Schlüssel erstellt haben, stellen Sie über eine Verbindung zum Jump-Host her Session Manager, eine Funktion von Systems Manager, und führen Sie den folgenden Befehl aus:
Jetzt können Sie die Aufnahmeschritte erneut ausführen.
Nehmen Sie Daten in den OpenSearch-Dienst auf
Wenn Sie den OpenSearch-Dienst verwenden, führen Sie das folgende Skript aus, um die Dateien aufzunehmen:
Wenn der Vorgang abgeschlossen ist, führen Sie das Skript aus, das simulierte Abfragen ausführt:
Nehmen Sie Daten in Amazon RDS auf
Wenn Sie Amazon RDS verwenden, führen Sie das folgende Skript aus, um die Dateien aufzunehmen:
Wenn der Vorgang abgeschlossen ist, stellen Sie sicher, dass auf der RDS-Instanz ein vollständiges Vakuum ausgeführt wird.
Führen Sie dann das folgende Skript aus, um simulierte Abfragen auszuführen:
Richten Sie das Ray-Dashboard ein
Bevor Sie das Ray-Dashboard einrichten, sollten Sie das installieren AWS-Befehlszeilenschnittstelle (AWS CLI) auf Ihrem lokalen Computer. Anweisungen finden Sie unter Installieren oder aktualisieren Sie die neueste Version der AWS CLI.
Führen Sie die folgenden Schritte aus, um das Dashboard einzurichten:
- Installieren Sie das Session Manager-Plugin für die AWS CLI.
- Kopieren Sie im Isengard-Konto die temporären Anmeldeinformationen für bash/zsh und führen Sie sie in Ihrem lokalen Terminal aus.
- Erstellen Sie eine session.sh-Datei auf Ihrem Computer und kopieren Sie den folgenden Inhalt in die Datei:
- Ändern Sie das Verzeichnis, in dem diese session.sh-Datei gespeichert ist.
- Führen Sie den Befehl aus
Chmod +xum der Datei die Ausführungsberechtigung zu erteilen. - Führen Sie den folgenden Befehl aus:
Beispielsweise:
Sie sehen eine Meldung wie die folgende:
Öffnen Sie einen neuen Tab in Ihrem Browser und geben Sie localhost:8265 ein.
Sie sehen das Ray-Dashboard und Statistiken zu den ausgeführten Jobs und Clustern. Von hier aus können Sie Metriken verfolgen.
Sie können beispielsweise das Ray-Dashboard verwenden, um die Auslastung des Clusters zu beobachten. Wie im folgenden Screenshot gezeigt, sind die GPUs während der Aufnahme nahezu zu 100 % ausgelastet.
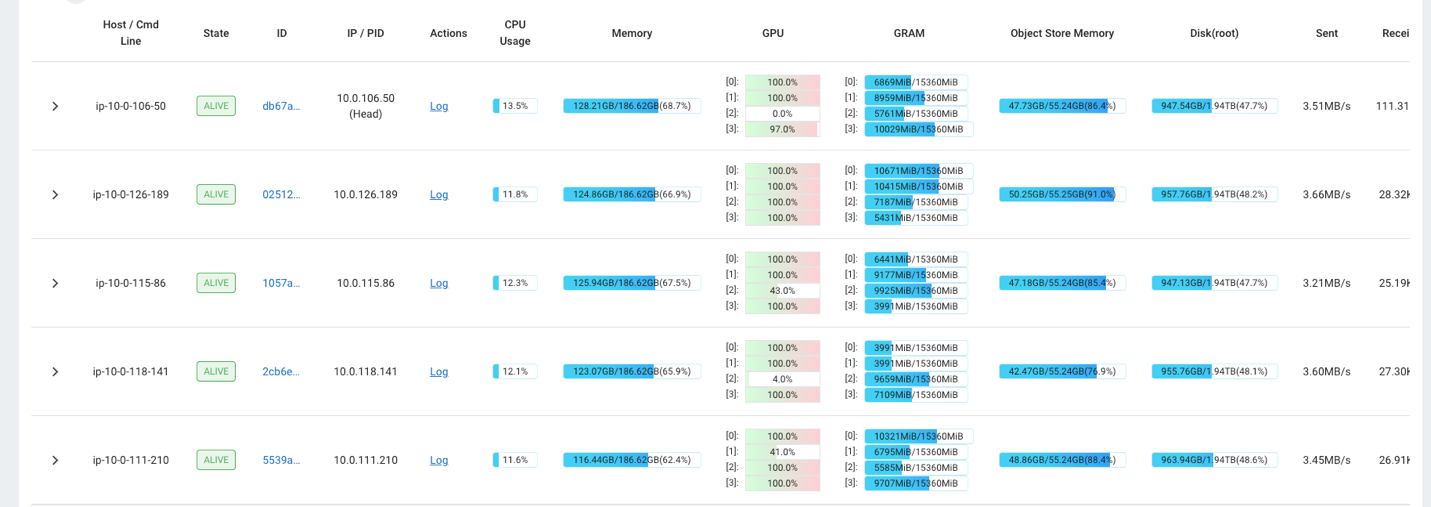
Sie können auch die Tasten RAG_Benchmarks CloudWatch-Dashboard, um die Aufnahmerate und die Antwortzeiten der Abfragen anzuzeigen.
Erweiterbarkeit der Lösung
Sie können diese Lösung erweitern, um andere AWS- oder Drittanbieter-Vektorspeicher einzubinden. Für jeden neuen Vektorspeicher müssen Sie Skripte zum Konfigurieren des Datenspeichers und zum Erfassen von Daten erstellen. Der Rest der Pipeline kann bei Bedarf wiederverwendet werden.
Zusammenfassung
In diesem Beitrag haben wir eine ETL-Pipeline geteilt, mit der Sie vektorisierte RAG-Daten sowohl in OpenSearch Service als auch in Amazon RDS mit der pgvector-Erweiterung als Vektordatenspeicher ablegen können. Die Lösung nutzte einen Ray-Cluster, um die notwendige Parallelität für die Aufnahme eines großen Datenkorpus bereitzustellen. Mit dieser Methode können Sie jede beliebige Vektordatenbank Ihrer Wahl integrieren, um RAG-Pipelines zu erstellen.
Über die Autoren
 Randy DeFauw ist Senior Principal Solutions Architect bei AWS. Er besitzt einen MSEE von der University of Michigan, wo er an Computer Vision für autonome Fahrzeuge arbeitete. Er verfügt außerdem über einen MBA der Colorado State University. Randy hatte verschiedene Positionen im Technologiebereich inne, von der Softwareentwicklung bis zum Produktmanagement. Er ist 2013 in den Big-Data-Bereich eingestiegen und erforscht diesen Bereich weiterhin. Er arbeitet aktiv an Projekten im ML-Bereich und hat auf zahlreichen Konferenzen, darunter Strata und GlueCon, Vorträge gehalten.
Randy DeFauw ist Senior Principal Solutions Architect bei AWS. Er besitzt einen MSEE von der University of Michigan, wo er an Computer Vision für autonome Fahrzeuge arbeitete. Er verfügt außerdem über einen MBA der Colorado State University. Randy hatte verschiedene Positionen im Technologiebereich inne, von der Softwareentwicklung bis zum Produktmanagement. Er ist 2013 in den Big-Data-Bereich eingestiegen und erforscht diesen Bereich weiterhin. Er arbeitet aktiv an Projekten im ML-Bereich und hat auf zahlreichen Konferenzen, darunter Strata und GlueCon, Vorträge gehalten.
 David Christian ist ein Principal Solutions Architect mit Sitz in Südkalifornien. Er hat einen Bachelor-Abschluss in Informationssicherheit und eine Leidenschaft für Automatisierung. Seine Schwerpunkte sind DevOps-Kultur und -Transformation, Infrastruktur als Code und Ausfallsicherheit. Bevor er zu AWS kam, war er in den Bereichen Sicherheit, DevOps und Systemtechnik tätig und verwaltete große private und öffentliche Cloud-Umgebungen.
David Christian ist ein Principal Solutions Architect mit Sitz in Südkalifornien. Er hat einen Bachelor-Abschluss in Informationssicherheit und eine Leidenschaft für Automatisierung. Seine Schwerpunkte sind DevOps-Kultur und -Transformation, Infrastruktur als Code und Ausfallsicherheit. Bevor er zu AWS kam, war er in den Bereichen Sicherheit, DevOps und Systemtechnik tätig und verwaltete große private und öffentliche Cloud-Umgebungen.
 Prachi Kulkarni ist Senior Solutions Architect bei AWS. Ihre Spezialisierung ist maschinelles Lernen und sie arbeitet aktiv an der Entwicklung von Lösungen unter Verwendung verschiedener AWS ML-, Big Data- und Analyseangebote. Prachi verfügt über Erfahrung in mehreren Bereichen, darunter Gesundheitswesen, Sozialleistungen, Einzelhandel und Bildung, und war in verschiedenen Positionen in den Bereichen Produktentwicklung und -architektur, Management und Kundenerfolg tätig.
Prachi Kulkarni ist Senior Solutions Architect bei AWS. Ihre Spezialisierung ist maschinelles Lernen und sie arbeitet aktiv an der Entwicklung von Lösungen unter Verwendung verschiedener AWS ML-, Big Data- und Analyseangebote. Prachi verfügt über Erfahrung in mehreren Bereichen, darunter Gesundheitswesen, Sozialleistungen, Einzelhandel und Bildung, und war in verschiedenen Positionen in den Bereichen Produktentwicklung und -architektur, Management und Kundenerfolg tätig.
 Richa Gupta ist Lösungsarchitekt bei AWS. Ihre Leidenschaft liegt in der Entwicklung von End-to-End-Lösungen für Kunden. Ihr Spezialgebiet ist maschinelles Lernen und wie es zur Entwicklung neuer Lösungen genutzt werden kann, die zu operativer Exzellenz führen und den Geschäftsumsatz steigern. Bevor sie zu AWS kam, arbeitete sie als Software-Ingenieurin und Lösungsarchitektin und entwickelte Lösungen für große Telekommunikationsbetreiber. Außerhalb der Arbeit erkundet sie gerne neue Orte und liebt abenteuerliche Aktivitäten.
Richa Gupta ist Lösungsarchitekt bei AWS. Ihre Leidenschaft liegt in der Entwicklung von End-to-End-Lösungen für Kunden. Ihr Spezialgebiet ist maschinelles Lernen und wie es zur Entwicklung neuer Lösungen genutzt werden kann, die zu operativer Exzellenz führen und den Geschäftsumsatz steigern. Bevor sie zu AWS kam, arbeitete sie als Software-Ingenieurin und Lösungsarchitektin und entwickelte Lösungen für große Telekommunikationsbetreiber. Außerhalb der Arbeit erkundet sie gerne neue Orte und liebt abenteuerliche Aktivitäten.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

