Wir leben im Zeitalter von Echtzeitdaten und Erkenntnissen, angetrieben durch Daten-Streaming-Anwendungen mit geringer Latenz. Heutzutage erwartet jeder ein personalisiertes Erlebnis in jeder Anwendung, und Unternehmen entwickeln ständig Innovationen, um ihre Geschäftsabläufe und Entscheidungsfindung zu beschleunigen. Die Menge der produzierten zeitkritischen Daten nimmt rapide zu, wobei in neuen Unternehmen und Kundenanwendungsfällen unterschiedliche Datenformate eingeführt werden. Daher ist es für Unternehmen von entscheidender Bedeutung, eine skalierbare und zuverlässige Daten-Streaming-Infrastruktur mit geringer Latenz zu nutzen, um Geschäftsanwendungen in Echtzeit und bessere Kundenerlebnisse bereitzustellen.
Dies ist der erste Beitrag einer Blog-Reihe, die gängige Architekturmuster für den Aufbau von Echtzeit-Daten-Streaming-Infrastrukturen mithilfe von Kinesis Data Streams für eine Vielzahl von Anwendungsfällen bietet. Ziel ist es, ein Framework zum Erstellen von Streaming-Anwendungen mit geringer Latenz in der AWS Cloud bereitzustellen Amazon Kinesis-Datenströme und Von AWS speziell entwickelte Datenanalysedienste.
In diesem Beitrag werden wir die gemeinsamen Architekturmuster von zwei Anwendungsfällen untersuchen: Zeitreihen-Datenanalyse und ereignisgesteuerte Microservices. Im folgenden Beitrag unserer Reihe werden wir die Architekturmuster beim Aufbau von Streaming-Pipelines für Echtzeit-BI-Dashboards, Contact-Center-Agenten, Hauptbuchdaten, personalisierte Echtzeitempfehlungen, Protokollanalysen, IoT-Daten, Change Data Capture und real untersuchen Zeitliche Marketingdaten. Alle diese Architekturmuster sind in Amazon Kinesis Data Streams integriert.
Echtzeit-Streaming mit Kinesis Data Streams
Amazon Kinesis Data Streams ist ein cloudnativer, serverloser Streaming-Datendienst, der die einfache Erfassung, Verarbeitung und Speicherung von Echtzeitdaten in jeder Größenordnung ermöglicht. Mit Kinesis Data Streams können Sie Hunderte Gigabyte an Daten pro Sekunde aus Hunderttausenden Quellen sammeln und verarbeiten und so problemlos Anwendungen schreiben, die Informationen in Echtzeit verarbeiten. Die gesammelten Daten stehen in Millisekunden zur Verfügung, um Anwendungsfälle für Echtzeitanalysen zu ermöglichen, z. B. Echtzeit-Dashboards, Echtzeit-Anomalieerkennung und dynamische Preisgestaltung. Standardmäßig werden die Daten im Kinesis Data Stream 24 Stunden lang gespeichert, mit der Option, die Datenaufbewahrung auf 365 Tage zu erhöhen. Wenn Kunden dieselben Daten in Echtzeit mit mehreren Anwendungen verarbeiten möchten, können sie die Funktion Enhanced Fan-Out (EFO) nutzen. Vor dieser Funktion teilte jede Anwendung, die Daten aus dem Stream konsumierte, die Ausgabe von 2 MB/Sekunde/Shard. Durch die Konfiguration von Stream-Konsumenten für die Verwendung von erweitertem Fan-Out erhält jeder Datenkonsument pro Shard eine dedizierte Pipe mit einem Lesedurchsatz von 2 MB/Sekunde, um die Latenz beim Datenabruf weiter zu reduzieren.
Für hohe Verfügbarkeit und Haltbarkeit erreicht Kinesis Data Streams eine hohe Haltbarkeit durch die synchrone Replikation der gestreamten Daten über drei Availability Zones in einer AWS-Region und bietet Ihnen die Möglichkeit, Daten bis zu 365 Tage lang aufzubewahren. Aus Sicherheitsgründen bieten Kinesis Data Streams eine serverseitige Verschlüsselung, sodass Sie strenge Datenverwaltungsanforderungen erfüllen können, indem Sie Ihre Daten im Ruhezustand und die Endpunkte der Amazon Virtual Private Cloud (VPC)-Schnittstelle verschlüsseln, um den Datenverkehr zwischen Ihrer Amazon VPC und Kinesis Data Streams privat zu halten.
Kinesis Data Streams verfügt über native Integrationen mit anderen AWS-Diensten wie z AWS-Kleber und Amazon EventBridge um Echtzeit-Streaming-Anwendungen auf AWS zu erstellen. Weitere Details finden Sie unter Amazon Kinesis Data Streams-Integrationen.
Moderne Daten-Streaming-Architektur mit Kinesis Data Streams
Eine moderne Streaming-Datenarchitektur mit Kinesis Data Streams kann als Stapel aus fünf logischen Schichten entworfen werden; Jede Schicht besteht aus mehreren speziell entwickelten Komponenten, die spezifische Anforderungen erfüllen, wie im folgenden Diagramm dargestellt:

Die Architektur besteht aus den folgenden Schlüsselkomponenten:
- Streaming-Quellen – Zu Ihrer Streaming-Datenquelle gehören Datenquellen wie Clickstream-Daten, Sensoren, soziale Medien, Geräte für das Internet der Dinge (IoT), Protokolldateien, die durch die Verwendung Ihrer Web- und Mobilanwendungen generiert werden, sowie Mobilgeräte, die halbstrukturierte und unstrukturierte Daten als kontinuierliche Streams generieren mit hoher Geschwindigkeit.
- Stream-Aufnahme – Die Stream-Ingestion-Schicht ist für die Datenaufnahme in die Stream-Speicherschicht verantwortlich. Es bietet die Möglichkeit, Daten aus Zehntausenden Datenquellen zu sammeln und in Echtzeit aufzunehmen. Du kannst den ... benutzen Kinesis SDK für die Aufnahme von Streaming-Daten über APIs, die Kinesis Producer-Bibliothek zum Aufbau leistungsstarker und langlebiger Streaming-Produzenten, oder a Kinesis-Agent zum Sammeln einer Reihe von Dateien und deren Aufnahme in Kinesis Data Streams. Darüber hinaus können Sie viele vorgefertigte Integrationen verwenden, z AWS Database Migration Service (AWS DMS), Amazon DynamoDB und AWS IoT-Kern um Daten ohne Code aufzunehmen. Sie können auch Daten von Drittanbieterplattformen wie Apache Spark und Apache Kafka Connect aufnehmen
- Stream-Speicher – Kinesis Data Streams bieten zwei Modi zur Unterstützung des Datendurchsatzes: On-Demand und Provisioned. Der On-Demand-Modus, jetzt die Standardauswahl, kann flexibel skaliert werden, um variable Durchsätze zu absorbieren, sodass sich Kunden keine Gedanken über die Kapazitätsverwaltung und die Bezahlung nach Datendurchsatz machen müssen. Der On-Demand-Modus skaliert automatisch die Stream-Kapazität um das Zweifache über die bisherige maximale Datenaufnahme hinaus, um ausreichend Kapazität für unerwartete Spitzen bei der Datenaufnahme bereitzustellen. Alternativ können Kunden, die eine detaillierte Kontrolle über Stream-Ressourcen wünschen, den bereitgestellten Modus verwenden und die Anzahl der Shards proaktiv nach oben oder unten skalieren, um ihren Durchsatzanforderungen gerecht zu werden. Darüber hinaus können Kinesis Data Streams Streaming-Daten standardmäßig bis zu 2 Stunden speichern, können sich aber je nach Anwendungsfall auf 24 Tage oder 7 Tage verlängern. Mehrere Anwendungen können denselben Stream nutzen.
- Stream-Verarbeitung – Die Stream-Verarbeitungsschicht ist dafür verantwortlich, Daten durch Datenvalidierung, -bereinigung, -normalisierung, -transformation und -anreicherung in einen verbrauchbaren Zustand umzuwandeln. Die Streaming-Datensätze werden in der Reihenfolge gelesen, in der sie erzeugt werden, was Echtzeitanalysen, die Erstellung ereignisgesteuerter Anwendungen oder das Streaming von ETL (Extrahieren, Transformieren und Laden) ermöglicht. Sie können verwenden Amazon Managed Service für Apache Flink für komplexe Stream-Datenverarbeitung, AWS Lambda für die zustandslose Stream-Datenverarbeitung und AWS-Kleber & Amazon EMR für Berechnungen nahezu in Echtzeit. Sie können damit auch benutzerdefinierte Verbraucheranwendungen erstellen Kinesis-Verbraucherbibliothek, das viele komplexe Aufgaben im Zusammenhang mit verteiltem Rechnen erledigt.
- Ziel - Die Zielebene ist je nach Anwendungsfall wie ein speziell erstelltes Ziel. Sie können Daten direkt dorthin streamen Amazon RedShift für Data Warehousing und Amazon EventBridge für die Erstellung ereignisgesteuerter Anwendungen. Sie können auch verwenden Amazon Kinesis Data Firehose für die Streaming-Integration, bei der Sie die Stream-Verarbeitung mit AWS Lambda vereinfachen und dann verarbeitetes Streaming an Ziele wie senden können Amazon S3 Data Lake, OpenSearch Service für Betriebsanalysen, ein Redshift Data Warehouse, No-SQL-Datenbanken wie Amazon DynamoDB und relationale Datenbanken wie Amazon RDS um Echtzeit-Streams in Geschäftsanwendungen zu nutzen. Das Ziel kann eine ereignisgesteuerte Anwendung für Echtzeit-Dashboards, automatische Entscheidungen auf der Grundlage verarbeiteter Streaming-Daten, Echtzeitänderungen und mehr sein.
Echtzeit-Analysearchitektur für Zeitreihen
Zeitreihendaten sind eine Folge von Datenpunkten, die über ein Zeitintervall aufgezeichnet werden, um Ereignisse zu messen, die sich im Laufe der Zeit ändern. Beispiele sind Aktienkurse im Zeitverlauf, Webseiten-Clickstreams und Geräteprotokolle im Zeitverlauf. Kunden können Zeitreihendaten verwenden, um Veränderungen im Laufe der Zeit zu überwachen, sodass sie Anomalien erkennen, Muster identifizieren und analysieren können, wie bestimmte Variablen im Laufe der Zeit beeinflusst werden. Zeitreihendaten werden in der Regel aus mehreren Quellen in großen Mengen generiert und müssen kostengünstig und nahezu in Echtzeit erfasst werden.
Typischerweise gibt es drei Hauptziele, die Kunden bei der Verarbeitung von Zeitreihendaten erreichen möchten:
- Erhalten Sie in Echtzeit Einblicke in die Systemleistung und erkennen Sie Anomalien
- Verstehen Sie das Verhalten der Endbenutzer, um Trends zu verfolgen und aus diesen Erkenntnissen Abfragen/Visualisierungen zu erstellen
- Verfügen Sie über eine dauerhafte Speicherlösung zur Aufnahme und Speicherung sowohl archivierter als auch häufig aufgerufener Daten.
Mit Kinesis Data Streams können Kunden kontinuierlich Terabytes an Zeitreihendaten aus Tausenden von Quellen zur Bereinigung, Anreicherung, Speicherung, Analyse und Visualisierung erfassen.
Das folgende Architekturmuster veranschaulicht, wie Echtzeitanalysen für Zeitreihendaten mit Kinesis Data Streams erreicht werden können:
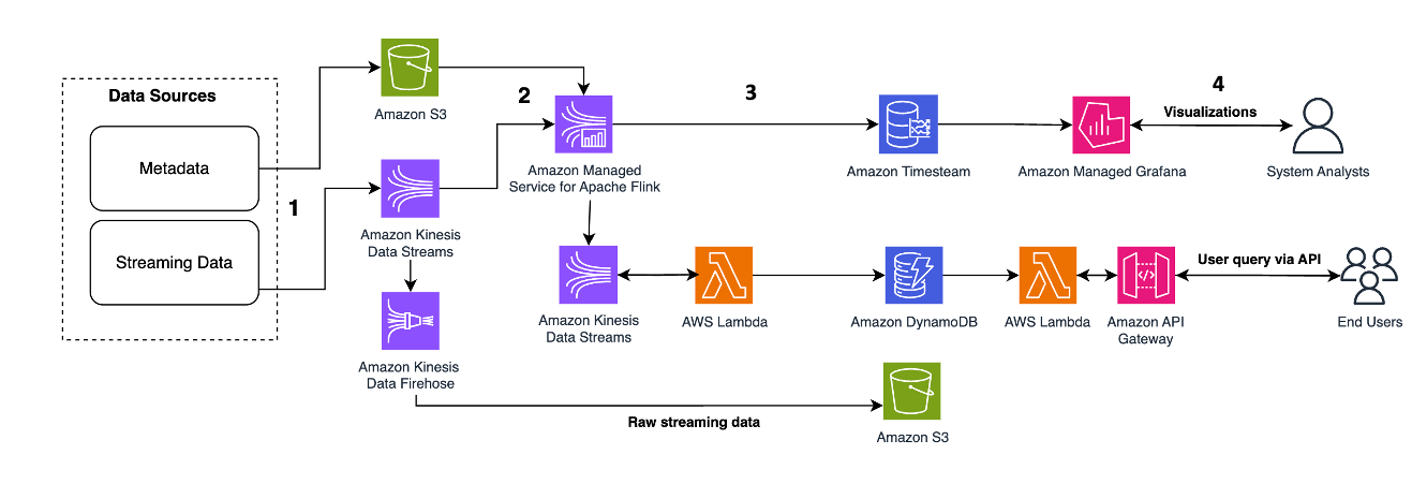
Die Arbeitsschritte sind wie folgt:
- Datenaufnahme und -speicherung – Kinesis Data Streams können kontinuierlich Terabytes an Daten aus Tausenden von Quellen erfassen und speichern.
- Stream-Verarbeitung – Eine Anwendung, die mit erstellt wurde Amazon Managed Service für Apache Flink kann die Datensätze aus dem Datenstrom lesen, um Fehler in den Zeitreihendaten zu erkennen und zu bereinigen und die Daten mit spezifischen Metadaten anzureichern, um die Betriebsanalyse zu optimieren. Die Verwendung eines Datenstroms in der Mitte bietet den Vorteil, dass die Zeitreihendaten gleichzeitig in anderen Prozessen und Lösungen verwendet werden können. Mit diesen Ereignissen wird dann eine Lambda-Funktion aufgerufen, die Zeitreihenberechnungen im Speicher durchführen kann.
- Reiseziele – Nach der Bereinigung und Anreicherung können die verarbeiteten Zeitreihendaten gestreamt werden Amazon-Timestream Datenbank für Echtzeit-Dashboarding und -Analyse oder in Datenbanken wie DynamoDB für Endbenutzerabfragen gespeichert. Die Rohdaten können zur Archivierung an Amazon S3 gestreamt werden.
- Visualisierung und Einblicke gewinnen – Kunden können mithilfe von Benachrichtigungen abfragen, visualisieren und erstellen Amazon Managed Service für Grafana. Grafana unterstützt Datenquellen, die Speicher-Backends für Zeitreihendaten sind. Um auf Ihre Daten von Timestream zuzugreifen, müssen Sie das Timestream-Plugin für Grafana installieren. Endbenutzer können mit Daten aus der DynamoDB-Tabelle abfragen Amazon API-Gateway als Stellvertreter fungieren.
Beziehen auf Verarbeitung nahezu in Echtzeit mit Amazon Kinesis, Amazon Timestream und Grafana Präsentation einer serverlosen Streaming-Pipeline zur Verarbeitung und Speicherung von Gerätetelemetrie-IoT-Daten in einem zeitreihenoptimierten Datenspeicher wie Amazon Timestream.
Anreicherung und Wiedergabe von Daten in Echtzeit für Event-Sourcing-Microservices
Microservices sind ein architektonischer und organisatorischer Ansatz für die Softwareentwicklung, bei dem Software aus kleinen unabhängigen Diensten besteht, die über genau definierte APIs kommunizieren. Beim Aufbau ereignisgesteuerter Microservices möchten Kunden 1. eine hohe Skalierbarkeit zur Bewältigung der Menge eingehender Ereignisse und 2. Zuverlässigkeit der Ereignisverarbeitung und Aufrechterhaltung der Systemfunktionalität auch bei Ausfällen erreichen.
Kunden nutzen Microservice-Architekturmuster, um Innovationen und die Markteinführung neuer Funktionen zu beschleunigen, da sich Anwendungen dadurch einfacher skalieren und schneller entwickeln lassen. Es ist jedoch eine Herausforderung, die Daten in einem Netzwerkaufruf an einen anderen Microservice anzureichern und wiederzugeben, da dies die Zuverlässigkeit der Anwendung beeinträchtigen und das Debuggen und Nachverfolgen von Fehlern erschweren kann. Um dieses Problem zu lösen, ist Event-Sourcing ein effektives Entwurfsmuster, das historische Aufzeichnungen aller Zustandsänderungen zur Anreicherung und Wiedergabe zentralisiert und Lese- von Schreib-Workloads entkoppelt. Kunden können Kinesis Data Streams als zentralisierten Ereignisspeicher für Event-Sourcing-Microservices verwenden, da KDS 1/Gigabyte Datendurchsatz pro Sekunde und Stream verarbeiten und die Daten in Millisekunden streamen kann, um die Anforderungen an hohe Skalierbarkeit und nahezu Echtzeit zu erfüllen Latenz, 2/ Integration mit Flink und S3 zur Datenanreicherung und -erzielung bei gleichzeitiger vollständiger Entkopplung von den Microservices und 3/ Ermöglichen von Wiederholungsversuchen und asynchronem Lesen zu einem späteren Zeitpunkt, da KDS den Datensatz standardmäßig für 24 Stunden und optional aufbewahrt bis zu 365 Tage.
Das folgende Architekturmuster ist eine generische Darstellung, wie Kinesis Data Streams für Event-Sourcing-Microservices verwendet werden können:
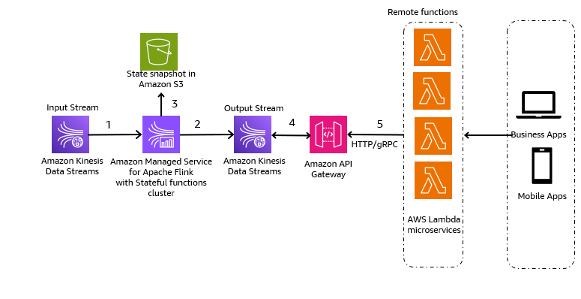
Die Schritte im Workflow sind wie folgt:
- Datenaufnahme und -speicherung – Sie können die Eingaben Ihrer Microservices zur Speicherung in Ihren Kinesis Data Streams aggregieren.
- Stream-Verarbeitung - Stateful-Funktionen von Apache Flink vereinfacht die Erstellung verteilter, zustandsbehafteter, ereignisgesteuerter Anwendungen. Es kann die Ereignisse von einem Kinesis-Eingabedatenstrom empfangen und den resultierenden Strom an einen Ausgabedatenstrom weiterleiten. Sie können mit Apache Flink einen Stateful-Functions-Cluster basierend auf der Geschäftslogik Ihrer Anwendung erstellen.
- Zustandsschnappschuss in Amazon S3 – Sie können den Status-Snapshot zur Nachverfolgung in Amazon S3 speichern.
- Ausgabeströme – Die Ausgabestreams können über Lambda-Remotefunktionen über das HTTP/gRPC-Protokoll über API Gateway genutzt werden.
- Lambda-Fernfunktionen – Lambda-Funktionen können als Microservices für verschiedene Anwendungs- und Geschäftslogiken fungieren, um Geschäftsanwendungen und mobile Apps bereitzustellen.
Um zu erfahren, wie andere Kunden ihre ereignisbasierten Microservices mit Kinesis Data Streams erstellt haben, lesen Sie Folgendes:
Wichtige Überlegungen und Best Practices
Im Folgenden finden Sie Überlegungen und Best Practices, die Sie beachten sollten:
- Die Datenerkennung sollte Ihr erster Schritt beim Aufbau moderner Daten-Streaming-Anwendungen sein. Sie müssen den Geschäftswert definieren und dann Ihre Streaming-Datenquellen und Benutzerpersönlichkeiten identifizieren, um die gewünschten Geschäftsergebnisse zu erzielen.
- Wählen Sie Ihr Streaming-Datenerfassungstool basierend auf Ihrer Streaming-Datenquelle. Sie können zum Beispiel die verwenden Kinesis SDK für die Aufnahme von Streaming-Daten über APIs, die Kinesis Producer-Bibliothek für den Aufbau leistungsstarker und langlebiger Streaming-Produzenten, a Kinesis-Agent zum Sammeln einer Reihe von Dateien und deren Aufnahme in Kinesis Data Streams, AWS-DMS für CDC-Streaming-Anwendungsfälle und AWS IoT-Kern zur Aufnahme von IoT-Gerätedaten in Kinesis Data Streams. Sie können Streaming-Daten direkt in Amazon Redshift aufnehmen, um Streaming-Anwendungen mit geringer Latenz zu erstellen. Sie können auch Bibliotheken von Drittanbietern wie Apache Spark und Apache Kafka verwenden, um Streaming-Daten in Kinesis Data Streams aufzunehmen.
- Sie müssen Ihre Streaming-Datenverarbeitungsdienste basierend auf Ihrem spezifischen Anwendungsfall und Ihren Geschäftsanforderungen auswählen. Beispielsweise können Sie Amazon Kinesis Managed Service für Apache Flink für erweiterte Streaming-Anwendungsfälle mit mehreren Streaming-Zielen und komplexer Stateful-Stream-Verarbeitung verwenden oder wenn Sie Geschäftsmetriken in Echtzeit (z. B. stündlich) überwachen möchten. Lambda eignet sich gut für die ereignisbasierte und zustandslose Verarbeitung. Sie können verwenden Amazon EMR für die Streaming-Datenverarbeitung, um Ihre bevorzugten Open-Source-Big-Data-Frameworks zu verwenden. AWS Glue eignet sich für die Streaming-Datenverarbeitung nahezu in Echtzeit für Anwendungsfälle wie Streaming-ETL.
- Der On-Demand-Modus von Kinesis Data Streams berechnet nach Nutzung und skaliert die Ressourcenkapazität automatisch hoch, sodass er sich gut für spitzenmäßige Streaming-Arbeitslasten und freihändige Wartung eignet. Der bereitgestellte Modus berechnet die Kosten nach Kapazität und erfordert eine proaktive Kapazitätsverwaltung. Er eignet sich daher gut für vorhersehbare Streaming-Arbeitslasten.
- Sie können die Verwendung Gemeinsamer Kinesis-Rechner um die Anzahl der für den bereitgestellten Modus erforderlichen Shards zu berechnen. Im On-Demand-Modus müssen Sie sich keine Sorgen um Shards machen.
- Beim Erteilen von Berechtigungen entscheiden Sie, wer welche Berechtigungen für welche Kinesis Data Streams-Ressourcen erhält. Sie aktivieren bestimmte Aktionen, die Sie für diese Ressourcen zulassen möchten. Daher sollten Sie nur die Berechtigungen erteilen, die zum Ausführen einer Aufgabe erforderlich sind. Sie können die Daten im Ruhezustand auch mithilfe eines vom KMS verwalteten Schlüssels (Customer Managed Key, CMK) verschlüsseln.
- Du kannst dich Aktualisieren Sie die Aufbewahrungsfrist über die Kinesis Data Streams-Konsole oder mithilfe von StreamRetentionPeriod erhöhen und dem StreamRetentionPeriod verringern Operationen basierend auf Ihren spezifischen Anwendungsfällen.
- Kinesis Data Streams unterstützt Neugestaltung. Die empfohlene API für diese Funktion ist UpdateShardCount, wodurch Sie die Anzahl der Shards in Ihrem Stream ändern können, um sie an Änderungen in der Datenflussrate durch den Stream anzupassen. Die Resharding-APIs (Split und Merge) werden normalerweise für die Verarbeitung von Hot Shards verwendet.
Zusammenfassung
In diesem Beitrag wurden verschiedene Architekturmuster zum Erstellen von Streaming-Anwendungen mit geringer Latenz mit Kinesis Data Streams demonstriert. Mithilfe der Informationen in diesem Beitrag können Sie mit Kinesis Data Streams Ihre eigenen Steaming-Anwendungen mit geringer Latenz erstellen.
Detaillierte Architekturmuster finden Sie in den folgenden Ressourcen:
Wenn Sie eine Datenvision und -strategie entwickeln möchten, schauen Sie sich die an AWS Data-Driven Everything (D2E)-Programm.
Über die Autoren
 Raghavarao Sodabathina ist Principal Solutions Architect bei AWS und konzentriert sich auf Datenanalyse, KI/ML und Cloud-Sicherheit. Er arbeitet mit Kunden zusammen, um innovative Lösungen zu entwickeln, die auf die Geschäftsprobleme der Kunden eingehen und die Einführung von AWS-Services beschleunigen. In seiner Freizeit verbringt Raghavarao gerne Zeit mit seiner Familie, liest Bücher und schaut sich Filme an.
Raghavarao Sodabathina ist Principal Solutions Architect bei AWS und konzentriert sich auf Datenanalyse, KI/ML und Cloud-Sicherheit. Er arbeitet mit Kunden zusammen, um innovative Lösungen zu entwickeln, die auf die Geschäftsprobleme der Kunden eingehen und die Einführung von AWS-Services beschleunigen. In seiner Freizeit verbringt Raghavarao gerne Zeit mit seiner Familie, liest Bücher und schaut sich Filme an.
 Hang Zuo ist Senior Product Manager im Amazon Kinesis Data Streams-Team bei Amazon Web Services. Seine Leidenschaft gilt der Entwicklung intuitiver Produkterlebnisse, die komplexe Kundenprobleme lösen und es Kunden ermöglichen, ihre Geschäftsziele zu erreichen.
Hang Zuo ist Senior Product Manager im Amazon Kinesis Data Streams-Team bei Amazon Web Services. Seine Leidenschaft gilt der Entwicklung intuitiver Produkterlebnisse, die komplexe Kundenprobleme lösen und es Kunden ermöglichen, ihre Geschäftsziele zu erreichen.
 Shwetha Radhakrishnan ist Lösungsarchitekt für AWS mit Schwerpunkt Datenanalyse. Sie hat Lösungen entwickelt, die die Cloud-Einführung vorantreiben und Organisationen dabei helfen, datengesteuerte Entscheidungen im öffentlichen Sektor zu treffen. Außerhalb der Arbeit tanzt sie gerne, verbringt Zeit mit Freunden und Familie und reist gerne.
Shwetha Radhakrishnan ist Lösungsarchitekt für AWS mit Schwerpunkt Datenanalyse. Sie hat Lösungen entwickelt, die die Cloud-Einführung vorantreiben und Organisationen dabei helfen, datengesteuerte Entscheidungen im öffentlichen Sektor zu treffen. Außerhalb der Arbeit tanzt sie gerne, verbringt Zeit mit Freunden und Familie und reist gerne.
 Brittany Ly ist Lösungsarchitekt bei AWS. Sie konzentriert sich darauf, Unternehmenskunden bei der Einführung und Modernisierung der Cloud zu unterstützen und interessiert sich für den Bereich Sicherheit und Analyse. Außerhalb der Arbeit verbringt sie gerne Zeit mit ihrem Hund und spielt Pickleball.
Brittany Ly ist Lösungsarchitekt bei AWS. Sie konzentriert sich darauf, Unternehmenskunden bei der Einführung und Modernisierung der Cloud zu unterstützen und interessiert sich für den Bereich Sicherheit und Analyse. Außerhalb der Arbeit verbringt sie gerne Zeit mit ihrem Hund und spielt Pickleball.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/

