Bạn có thể nhập và tích hợp dữ liệu từ nhiều cảm biến Internet of Things (IoT) để hiểu rõ hơn. Tuy nhiên, bạn có thể phải tích hợp dữ liệu từ nhiều thiết bị cảm biến IoT để lấy các phân tích như thông tin về tình trạng thiết bị từ tất cả các cảm biến dựa trên các thành phần dữ liệu chung. Mỗi thiết bị cảm biến này có thể truyền dữ liệu với các lược đồ duy nhất và các thuộc tính khác nhau.
Bạn có thể nhập dữ liệu từ tất cả các cảm biến IoT của mình vào một vị trí trung tâm trên Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3). Lược đồ tiến hóa là một tính năng trong đó lược đồ của bảng cơ sở dữ liệu có thể phát triển để phù hợp với những thay đổi về thuộc tính của tệp được nhập. Với chức năng tiến hóa lược đồ có sẵn trong Keo AWS, Quang phổ dịch chuyển đỏ Amazon có thể tự động xử lý các thay đổi trong lược đồ khi các thuộc tính mới được thêm vào hoặc các thuộc tính hiện có bị loại bỏ. Điều này đạt được nhờ trình thu thập thông tin AWS Glue bằng cách đọc các thay đổi lược đồ dựa trên cấu trúc tệp S3. Trình thu thập thông tin tạo một lược đồ kết hợp hoạt động với cả tập dữ liệu cũ và mới. Bạn có thể đọc từ tất cả các tệp dữ liệu được nhập vào tại một vị trí Amazon S3 được chỉ định với các lược đồ khác nhau thông qua một Quang phổ dịch chuyển đỏ Amazon bảng bằng cách tham khảo danh mục siêu dữ liệu AWS Glue.
Trong bài đăng này, chúng tôi trình bày cách sử dụng tính năng phát triển lược đồ AWS Glue để đọc từ nhiều tệp có định dạng JSON với nhiều lược đồ khác nhau được lưu trữ ở một vị trí Amazon S3 duy nhất. Chúng tôi cũng trình bày cách truy vấn dữ liệu này trong Amazon S3 bằng Redshift Spectrum mà không cần xác định lại lược đồ hoặc tải dữ liệu vào bảng Redshift.
Tổng quan về giải pháp
Giải pháp bao gồm các bước sau:
- tạo một Firehose dữ liệu của Amazon luồng phân phối với Amazon S3 là đích đến.
- Tạo dữ liệu luồng mẫu từ Trình tạo dữ liệu Amazon Kinesis (KDG) với luồng phân phối Firehose là đích.
- Tải các tệp dữ liệu ban đầu lên vị trí Amazon S3.
- Tạo và chạy trình thu thập thông tin AWS Glue để điền vào Danh mục dữ liệu với định nghĩa bảng bên ngoài bằng cách đọc các tệp dữ liệu từ Amazon S3.
- Tạo lược đồ bên ngoài được gọi là
iotdb_exttrong Amazon Redshift và truy vấn bảng Danh mục dữ liệu. - Truy vấn bảng bên ngoài từ Redshift Spectrum để đọc dữ liệu từ lược đồ ban đầu.
- Thêm các thành phần dữ liệu bổ sung vào mẫu KDG và gửi dữ liệu đến luồng phân phối Firehose.
- Xác thực rằng các tệp dữ liệu bổ sung được tải lên Amazon S3 bằng các thành phần dữ liệu bổ sung.
- Chạy trình thu thập thông tin AWS Glue để cập nhật các định nghĩa bảng bên ngoài.
- Truy vấn lại bảng bên ngoài từ Redshift Spectrum để đọc tập dữ liệu kết hợp từ hai lược đồ khác nhau.
- Xóa phần tử dữ liệu khỏi mẫu và gửi dữ liệu đến luồng phân phối Firehose.
- Xác thực rằng các tệp dữ liệu bổ sung được tải lên Amazon S3 với ít phần tử dữ liệu hơn.
- Chạy trình thu thập thông tin AWS Glue để cập nhật các định nghĩa bảng bên ngoài.
- Truy vấn bảng bên ngoài từ Redshift Spectrum để đọc tập dữ liệu kết hợp từ ba lược đồ khác nhau.
Giải pháp này được mô tả trong sơ đồ kiến trúc sau.

Điều kiện tiên quyết
Giải pháp này yêu cầu các điều kiện tiên quyết sau:
Thực hiện giải pháp
Hoàn thành các bước sau để xây dựng giải pháp:
- Trên bảng điều khiển Kinesis, tạo luồng phân phối Firehose với các thông số sau:
- Trong nguồn, chọn PUT trực tiếp.
- Trong Nơi đến, chọn Amazon S3.
- Trong Xô S3, hãy nhập nhóm S3 của bạn.
- Trong phân vùng động, lựa chọn Kích hoạt.

-
- Thêm các khóa phân vùng động sau:
- Năm quan trọng với biểu thức
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%Y") - Tháng quan trọng với biểu thức
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%m") - Ngày quan trọng với biểu hiện
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%d") - Giờ chính với biểu hiện
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%H")
- Năm quan trọng với biểu thức
- Thêm các khóa phân vùng động sau:
-
- Trong Tiền tố thùng S3, đi vào
year=!{partitionKeyFromQuery:year}/month=!{partitionKeyFromQuery:month}/day=!{partitionKeyFromQuery:day}/hour=!{partitionKeyFromQuery:hour}/
- Trong Tiền tố thùng S3, đi vào

Bạn có thể xem lại chi tiết luồng phân phối của mình trên bảng điều khiển Kinesis Data Firehose.
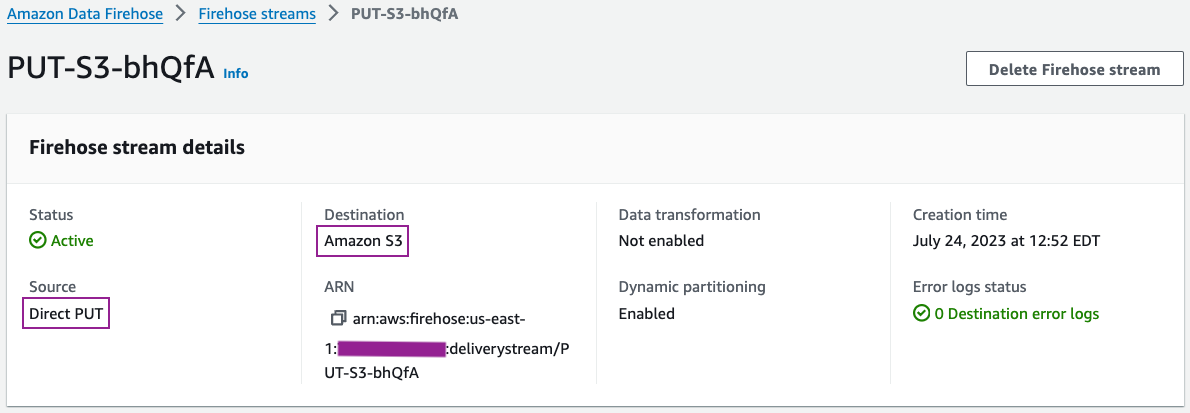
Chi tiết cấu hình luồng phân phối của bạn phải giống với ảnh chụp màn hình sau.

- Tạo dữ liệu luồng mẫu từ KDG với luồng phân phối Firehose làm đích với mẫu sau:

- Trên bảng điều khiển Amazon S3, xác thực rằng tập hợp tệp ban đầu đã được tải vào vùng lưu trữ S3.
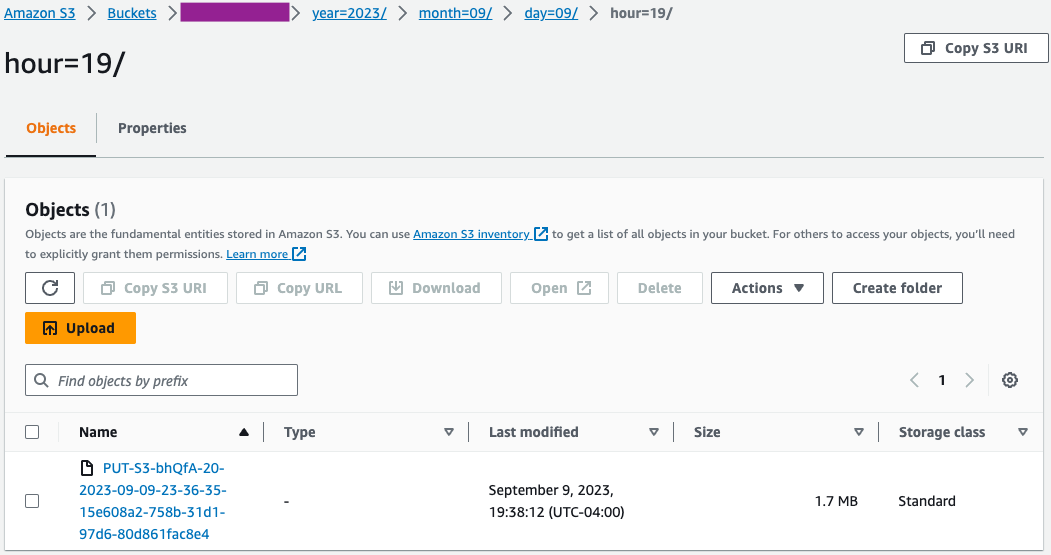
- Trên bảng điều khiển AWS Glue, tạo và chạy Trình thu thập keo AWS với nguồn dữ liệu là vùng lưu trữ S3 mà bạn đã sử dụng ở bước trước đó.
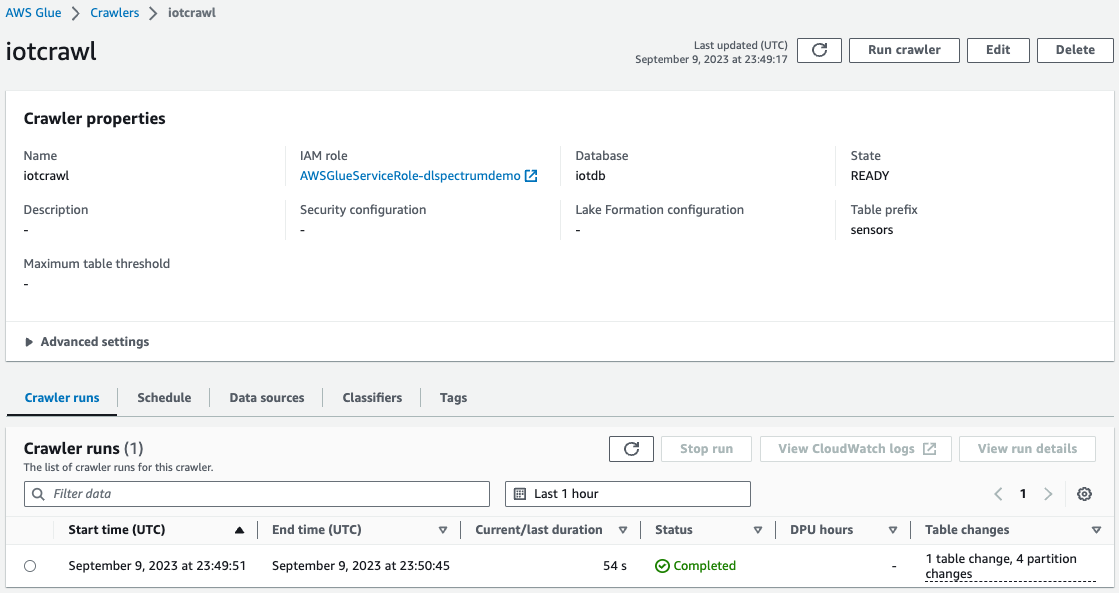
Khi trình thu thập thông tin hoàn tất, bạn có thể xác thực rằng bảng đã được tạo trên bảng điều khiển AWS Glue.

Xử lý sự cố
Nếu dữ liệu không được tải vào Amazon S3 sau khi gửi dữ liệu từ mẫu KDG đến luồng phân phối Firehose, hãy làm mới và đảm bảo rằng bạn đã đăng nhập vào KDG.
Làm sạch
Bạn có thể muốn xóa dữ liệu S3 và cụm Redshift nếu không định sử dụng thêm dữ liệu đó để tránh chi phí không cần thiết cho tài khoản AWS của mình.
Kết luận
Với sự xuất hiện của các yêu cầu về phân tích dự đoán và phân tích theo quy định dựa trên dữ liệu lớn, nhu cầu ngày càng tăng về các giải pháp dữ liệu tích hợp dữ liệu từ nhiều mô hình dữ liệu không đồng nhất với nỗ lực tối thiểu. Trong bài đăng này, chúng tôi đã giới thiệu cách bạn có thể lấy số liệu từ các phần tử dữ liệu nguyên tử phổ biến từ các nguồn dữ liệu khác nhau bằng các lược đồ duy nhất. Bạn có thể lưu trữ dữ liệu từ tất cả các nguồn dữ liệu ở một vị trí S3 chung, trong cùng một thư mục hoặc nhiều thư mục con theo từng nguồn dữ liệu. Bạn có thể xác định và lên lịch để trình thu thập thông tin AWS Glue chạy ở cùng tần suất với yêu cầu làm mới dữ liệu đối với mức tiêu thụ dữ liệu của bạn. Với giải pháp này, bạn có thể tạo bảng Redshift Spectrum để đọc từ vị trí S3 với các cấu trúc tệp khác nhau bằng cách sử dụng Danh mục dữ liệu AWS Glue và chức năng tiến hóa lược đồ.
Nếu bạn có bất kỳ câu hỏi hoặc đề xuất nào, vui lòng để lại phản hồi của bạn trong phần bình luận. Nếu bạn cần hỗ trợ thêm trong việc xây dựng các giải pháp phân tích với dữ liệu từ nhiều cảm biến IoT khác nhau, vui lòng liên hệ với nhóm tài khoản AWS của bạn.
Về các tác giả
 Swapna Bandla là Kiến trúc sư giải pháp cấp cao trong Nhóm SA Chuyên gia phân tích AWS. Swapna có niềm đam mê tìm hiểu nhu cầu phân tích và dữ liệu của khách hàng, đồng thời trao quyền cho họ phát triển các giải pháp có kiến trúc tốt dựa trên đám mây. Ngoài công việc, cô thích dành thời gian cho gia đình.
Swapna Bandla là Kiến trúc sư giải pháp cấp cao trong Nhóm SA Chuyên gia phân tích AWS. Swapna có niềm đam mê tìm hiểu nhu cầu phân tích và dữ liệu của khách hàng, đồng thời trao quyền cho họ phát triển các giải pháp có kiến trúc tốt dựa trên đám mây. Ngoài công việc, cô thích dành thời gian cho gia đình.
 Indira Balakrish Nam là Kiến trúc sư giải pháp chính trong Nhóm SA chuyên gia AWS Analytics. Cô ấy đam mê giúp khách hàng xây dựng các giải pháp phân tích dựa trên đám mây để giải quyết các vấn đề kinh doanh của họ bằng cách sử dụng các quyết định dựa trên dữ liệu. Ngoài công việc, cô tình nguyện tham gia các hoạt động của con cái và dành thời gian cho gia đình.
Indira Balakrish Nam là Kiến trúc sư giải pháp chính trong Nhóm SA chuyên gia AWS Analytics. Cô ấy đam mê giúp khách hàng xây dựng các giải pháp phân tích dựa trên đám mây để giải quyết các vấn đề kinh doanh của họ bằng cách sử dụng các quyết định dựa trên dữ liệu. Ngoài công việc, cô tình nguyện tham gia các hoạt động của con cái và dành thời gian cho gia đình.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/build-an-analytics-pipeline-that-is-resilient-to-schema-changes-using-amazon-redshift-spectrum/

