Phần 1 của loạt bài gồm hai phần này đã mô tả cách xây dựng dịch vụ bút danh hóa để chuyển đổi các thuộc tính dữ liệu văn bản thuần túy thành bút danh hoặc ngược lại. Dịch vụ bút danh tập trung cung cấp một kiến trúc độc đáo và được công nhận rộng rãi để tạo bút danh. Do đó, một tổ chức có thể đạt được quy trình chuẩn để xử lý dữ liệu nhạy cảm trên tất cả các nền tảng. Ngoài ra, điều này giúp loại bỏ mọi sự phức tạp và kiến thức chuyên môn cần thiết để hiểu và triển khai các yêu cầu tuân thủ khác nhau từ nhóm phát triển và người dùng phân tích, cho phép họ tập trung vào kết quả kinh doanh của mình.
Áp dụng cách tiếp cận dựa trên dịch vụ tách rời có nghĩa là, với tư cách là một tổ chức, bạn không thiên vị trong việc sử dụng bất kỳ công nghệ cụ thể nào để giải quyết các vấn đề kinh doanh của mình. Bất kể các nhóm riêng lẻ ưa thích công nghệ nào, họ đều có thể gọi dịch vụ đặt bút danh để đặt bút danh cho dữ liệu nhạy cảm.
Trong bài đăng này, chúng tôi tập trung vào các mẫu tiêu thụ trích xuất, chuyển đổi và tải (ETL) phổ biến có thể sử dụng dịch vụ bút danh. Chúng tôi thảo luận về cách sử dụng dịch vụ bút danh trong công việc ETL của bạn trên Amazon EMR (sử dụng Amazon EMR trên EC2) cho các trường hợp sử dụng trực tuyến và hàng loạt. Ngoài ra, bạn có thể tìm thấy một amazon Athena và Keo AWS mô hình tiêu dùng dựa trên Repo GitHub của giải pháp.
Tổng quan về giải pháp
Sơ đồ sau đây mô tả kiến trúc giải pháp.

Tài khoản bên phải lưu trữ dịch vụ bút danh mà bạn có thể triển khai bằng cách sử dụng hướng dẫn được cung cấp trong Phần 1 của loạt bài này.
Tài khoản bên trái là tài khoản bạn thiết lập trong bài đăng này, đại diện cho nền tảng ETL dựa trên Amazon EMR bằng cách sử dụng dịch vụ bút danh.
Bạn có thể triển khai dịch vụ bút danh và nền tảng ETL trên cùng một tài khoản.
Amazon EMR hỗ trợ bạn tạo, vận hành và mở rộng quy mô các khung dữ liệu lớn như Apache Spark một cách nhanh chóng và tiết kiệm chi phí.
Trong giải pháp này, chúng tôi trình bày cách sử dụng dịch vụ bút danh trên Amazon EMR với Apache Spark cho các trường hợp sử dụng hàng loạt và phát trực tuyến. Ứng dụng hàng loạt đọc dữ liệu từ một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) và ứng dụng phát trực tuyến sử dụng các bản ghi từ Luồng dữ liệu Amazon Kinesis.
Mã PySpark được sử dụng trong các công việc hàng loạt và phát trực tuyến
Cả hai ứng dụng đều sử dụng một chức năng tiện ích chung để thực hiện các lệnh gọi HTTP POST dựa trên Cổng API được liên kết với bút danh AWS Lambda chức năng. Các lệnh gọi API REST được thực hiện trên mỗi phân vùng Spark bằng Spark RDD bản đồPhân vùng chức năng. Phần thân yêu cầu POST chứa danh sách các giá trị duy nhất cho một cột đầu vào nhất định. Phản hồi yêu cầu POST chứa các giá trị được đặt biệt danh tương ứng. Mã hoán đổi các giá trị nhạy cảm với các giá trị được đặt biệt danh cho một tập dữ liệu nhất định. Kết quả được lưu vào Amazon S3 và Keo AWS Danh mục dữ liệu, sử dụng Apache Iceberg định dạng bảng.
Iceberg là một định dạng bảng mở hỗ trợ các giao dịch ACID, tiến hóa lược đồ và truy vấn du hành thời gian. Bạn có thể sử dụng các tính năng này để triển khai Quyền được lãng quên (hoặc xóa dữ liệu) giải pháp sử dụng câu lệnh SQL hoặc giao diện lập trình. Iceberg được Amazon EMR hỗ trợ bắt đầu từ phiên bản 6.5.0, AWS Glue và Athena. Các mẫu phát trực tuyến và hàng loạt sử dụng Iceberg làm định dạng mục tiêu. Để biết tổng quan về cách xây dựng hồ dữ liệu tuân thủ ACID bằng Iceberg, hãy tham khảo Xây dựng hồ dữ liệu hiệu suất cao, tuân thủ ACID, đang phát triển bằng cách sử dụng Apache Iceberg trên Amazon EMR.
Điều kiện tiên quyết
Bạn phải có các điều kiện tiên quyết sau:
- An Tài khoản AWS.
- An Quản lý truy cập và nhận dạng AWS (IAM) có đặc quyền triển khai Hình thành đám mây AWS ngăn xếp và các tài nguyên liên quan.
- Sản phẩm Giao diện dòng lệnh AWS (AWS CLI) được cài đặt trên máy phát triển hoặc triển khai mà bạn sẽ sử dụng để chạy các tập lệnh được cung cấp.
- Vùng lưu trữ S3 trong cùng một tài khoản và Khu vực AWS nơi giải pháp sẽ được triển khai.
- Con trăn3 được cài đặt trong máy cục bộ nơi các lệnh được chạy.
- PyYAML cài đặt bằng cách sử dụng đánh rớt.
- Một thiết bị đầu cuối bash để chạy các tập lệnh bash triển khai ngăn xếp CloudFormation.
- Một nhóm S3 bổ sung chứa tập dữ liệu đầu vào trong tệp Parquet (chỉ dành cho các ứng dụng hàng loạt). Sao chép tập dữ liệu mẫu vào nhóm S3.
- Một bản sao của kho mã mới nhất trong máy cục bộ bằng cách sử dụng
git clonehoặc tùy chọn tải xuống.
Mở một thiết bị đầu cuối bash mới và điều hướng đến thư mục gốc của kho lưu trữ nhân bản.
Mã nguồn của các mẫu được đề xuất có thể được tìm thấy trong kho lưu trữ nhân bản. Nó sử dụng các tham số sau:
- ARTEFACT_S3_BUCKET – Vùng lưu trữ S3 nơi mã cơ sở hạ tầng sẽ được lưu trữ. Nhóm phải được tạo trong cùng một tài khoản và Khu vực nơi giải pháp tồn tại.
- AWS_REGION – Khu vực nơi giải pháp sẽ được triển khai.
- AWS_PROFILE – Hồ sơ được đặt tên sẽ được áp dụng cho Lệnh AWS CLI. Điều này phải chứa thông tin xác thực dành cho người đứng đầu IAM có đặc quyền để triển khai nhóm tài nguyên liên quan của CloudFormation.
- SUBNET_ID – ID mạng con nơi cụm EMR sẽ được tách ra. Mạng con này đã tồn tại từ trước và nhằm mục đích minh họa, chúng tôi sử dụng ID mạng con mặc định của VPC mặc định.
- EP_URL – URL điểm cuối của dịch vụ bút danh. Lấy thông tin này từ giải pháp được triển khai dưới dạng Phần 1 của loạt bài này.
- API_SECRET - An Cổng API Amazon chính nó sẽ được lưu trữ trong Quản lý bí mật AWS. Khóa API được tạo từ quá trình triển khai được mô tả trong Phần 1 của loạt bài này.
- S3_INPUT_PATH – URI S3 trỏ đến thư mục chứa tập dữ liệu đầu vào dưới dạng tệp Parquet.
- KINESIS_DATA_STREAM_NAME – Tên luồng dữ liệu Kinesis được triển khai cùng với ngăn xếp CloudFormation.
- BATCH_SIZE – Số lượng bản ghi được đẩy vào luồng dữ liệu mỗi đợt.
- THREADS_NUM – Số lượng luồng song song được sử dụng trong máy cục bộ để tải dữ liệu lên luồng dữ liệu. Nhiều chủ đề hơn tương ứng với số lượng tin nhắn cao hơn.
- EMR_CLUSTER_ID – ID cụm EMR nơi mã sẽ được chạy (cụm EMR được tạo bởi ngăn xếp CloudFormation).
- STACK_NAME – Tên của ngăn xếp CloudFormation được gán trong tập lệnh triển khai.
Các bước triển khai hàng loạt
Như được mô tả trong điều kiện tiên quyết, trước khi bạn triển khai giải pháp, hãy tải tệp Parquet của tập dữ liệu thử nghiệm tới Amazon S3. Sau đó cung cấp đường dẫn S3 của thư mục chứa các tệp làm tham số <S3_INPUT_PATH>.
Chúng tôi tạo tài nguyên giải pháp thông qua AWS CloudFormation. Bạn có thể triển khai giải pháp bằng cách chạy triển khai_1.sh tập lệnh nằm bên trong deployment_scripts thư mục.
Sau khi đã thỏa mãn các điều kiện tiên quyết khi triển khai, hãy nhập lệnh sau để triển khai giải pháp:
sh ./deployment_scripts/deploy_1.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>
-i <S3_INPUT_PATH>Đầu ra sẽ trông giống như ảnh chụp màn hình sau.

Các tham số cần thiết cho lệnh dọn dẹp được in ra khi kết thúc quá trình chạy chương trình. deploy_1.sh kịch bản. Hãy chắc chắn ghi lại những giá trị này.
Kiểm tra giải pháp hàng loạt
Trong mẫu CloudFormation được triển khai bằng cách sử dụng deploy_1.sh tập lệnh, bước EMR chứa Ứng dụng hàng loạt Spark được thêm vào cuối quá trình thiết lập cụm EMR.
Để xác minh kết quả, hãy kiểm tra nhóm S3 được xác định trong kết quả đầu ra của ngăn xếp CloudFormation bằng biến SparkOutputLocation.

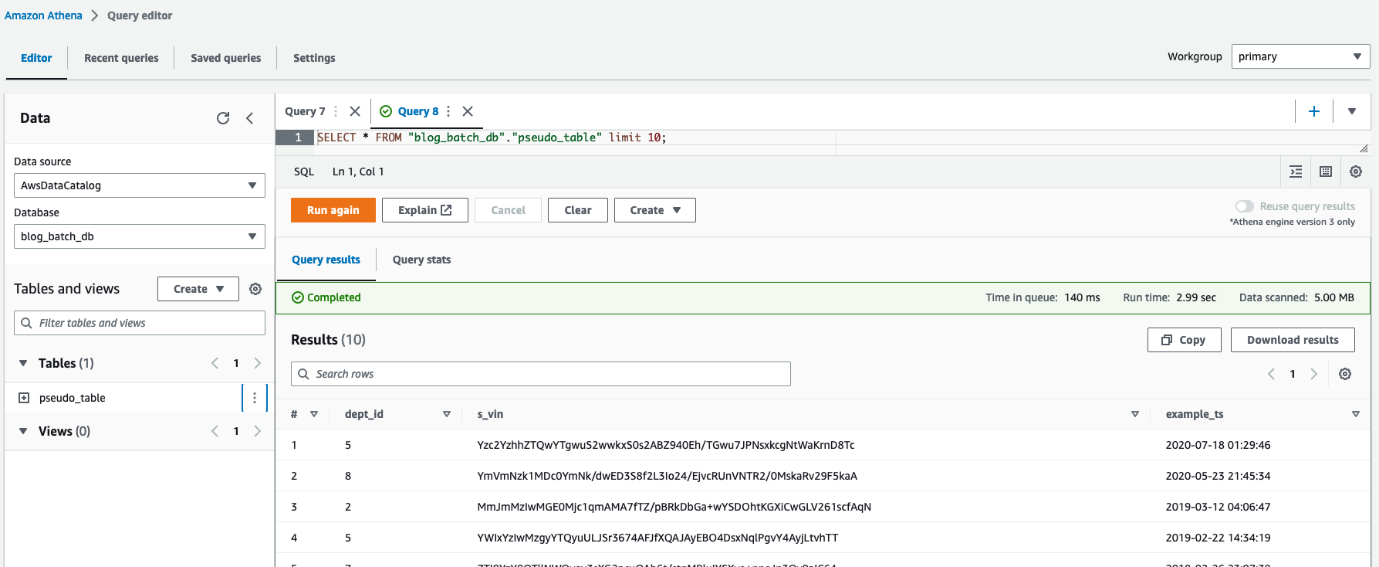
Bạn cũng có thể sử dụng Athena để truy vấn bảng pseudo_table trong cơ sở dữ liệu blog_batch_db.
Dọn dẹp tài nguyên hàng loạt
Để tiêu hủy các tài nguyên được tạo ra như một phần của bài tập này,
trong thiết bị đầu cuối bash, điều hướng đến thư mục gốc của kho lưu trữ nhân bản. Nhập lệnh dọn dẹp được hiển thị dưới dạng đầu ra của lần chạy trước đó triển khai_1.sh kịch bản:
sh ./deployment_scripts/cleanup_1.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>Đầu ra sẽ trông giống như ảnh chụp màn hình sau.

Truyền phát các bước triển khai
Chúng tôi tạo tài nguyên giải pháp thông qua AWS CloudFormation. Bạn có thể triển khai giải pháp bằng cách chạy triển khai_2.sh tập lệnh nằm bên trong deployment_scripts thư mục. Mẫu ngăn xếp CloudFormation cho mẫu này có sẵn trong Repo GitHub.
Sau khi đã thỏa mãn các điều kiện tiên quyết khi triển khai, hãy nhập lệnh sau để triển khai giải pháp:
sh deployment_scripts/deploy_2.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>Đầu ra sẽ trông giống như ảnh chụp màn hình sau.
Các tham số cần thiết cho lệnh dọn dẹp được in ra ở cuối đầu ra của lệnh dọn dẹp. triển khai_2.sh kịch bản. Đảm bảo lưu các giá trị này để sử dụng sau.
Kiểm tra giải pháp phát trực tuyến
Trong mẫu CloudFormation được triển khai bằng cách sử dụng deploy_2.sh tập lệnh, bước EMR chứa Ứng dụng phát trực tuyến Spark được thêm vào cuối quá trình thiết lập cụm EMR. Để kiểm tra quy trình từ đầu đến cuối, bạn cần đẩy các bản ghi vào luồng dữ liệu Kinesis đã triển khai. Với các lệnh sau trong bash terminal, bạn có thể kích hoạt trình tạo Kinesis sẽ liên tục đưa các bản ghi vào luồng cho đến khi quá trình này bị dừng theo cách thủ công. Bạn có thể kiểm soát âm lượng tin nhắn của nhà sản xuất bằng cách sửa đổi BATCH_SIZE và THREADS_NUM biến.


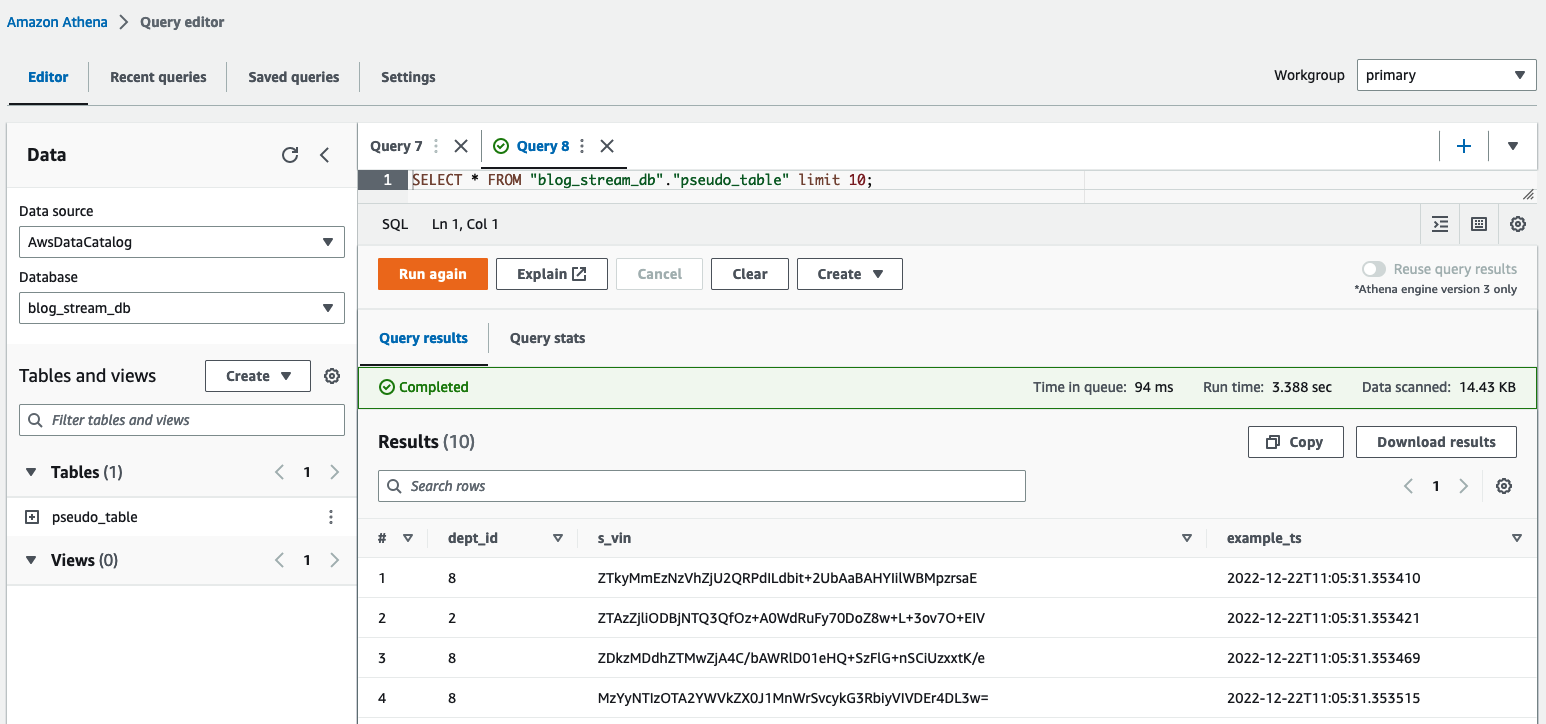
Trong trình soạn thảo truy vấn Athena, kiểm tra kết quả bằng cách truy vấn table pseudo_table trong cơ sở dữ liệu blog_stream_db.
Dọn dẹp tài nguyên phát trực tuyến
Để hủy các tài nguyên được tạo như một phần của bài tập này, hãy hoàn thành các bước sau:
- Dừng trình tạo Python Kinesis đã được khởi chạy trong thiết bị đầu cuối bash ở phần trước.
- Nhập lệnh sau:
sh ./deployment_scripts/cleanup_2.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>Đầu ra sẽ trông giống như ảnh chụp màn hình sau.

Chi tiết hiệu suất
Các trường hợp sử dụng có thể khác nhau về các yêu cầu liên quan đến kích thước dữ liệu, khả năng tính toán và chi phí. Chúng tôi đã cung cấp một số điểm chuẩn và các yếu tố có thể ảnh hưởng đến hiệu suất; tuy nhiên, chúng tôi thực sự khuyên bạn nên xác thực giải pháp trong môi trường thấp hơn để xem liệu giải pháp đó có đáp ứng các yêu cầu cụ thể của bạn hay không.
Bạn có thể tác động đến hiệu suất của giải pháp được đề xuất (nhằm mục đích đặt biệt danh cho tập dữ liệu bằng Amazon EMR) bằng số lượng cuộc gọi song song tối đa đến dịch vụ đặt biệt danh và kích thước tải trọng cho mỗi cuộc gọi. Đối với các cuộc gọi song song, các yếu tố cần xem xét là Giới hạn cuộc gọi GetSecretValue từ Trình quản lý bí mật (10.000 mỗi giây, giới hạn cứng) và song song mặc định Lambda (1,000 theo mặc định; có thể tăng theo yêu cầu hạn mức). Bạn có thể kiểm soát tính song song tối đa bằng cách điều chỉnh số lượng người thực thi, số lượng phân vùng tạo tập dữ liệu và cấu hình cụm (số lượng và loại nút). Về kích thước tải trọng cho mỗi cuộc gọi, các yếu tố cần xem xét là Kích thước tải trọng tối đa của API Gateway (6 MB) và thời gian chạy tối đa của hàm Lambda (15 phút). Bạn có thể kiểm soát kích thước tải trọng và thời gian chạy hàm Lambda bằng cách điều chỉnh giá trị kích thước lô. Đây là một tham số của tập lệnh PySpark xác định số lượng mục sẽ được đặt biệt danh cho mỗi lệnh gọi API. Để nắm bắt được mức độ ảnh hưởng của tất cả các yếu tố này và đánh giá hiệu quả của các mô hình tiêu dùng bằng Amazon EMR, chúng tôi đã thiết kế và giám sát các tình huống sau.
Hiệu suất mô hình tiêu thụ hàng loạt
Để đánh giá hiệu suất cho mô hình tiêu thụ hàng loạt, chúng tôi đã chạy ứng dụng bút danh với ba tập dữ liệu đầu vào bao gồm 1, 10 và 100 tệp Parquet, mỗi tệp có dung lượng 97.7 MB. Chúng tôi đã tạo các tệp đầu vào bằng cách sử dụng tập dữ liệu_generator.py kịch bản.
Các nút công suất cụm là 1 nút chính (m5.4xlarge) và 15 lõi (m5d.8xlarge). Cấu hình cụm này vẫn giữ nguyên cho cả ba trường hợp và cho phép ứng dụng Spark sử dụng tới 100 trình thực thi. Các batch_size, cũng giống nhau trong ba trường hợp, được đặt thành 900 VIN cho mỗi lệnh gọi API và kích thước VIN tối đa là 5 byte.
Bảng sau đây ghi lại thông tin của ba kịch bản.
| ID thực thi | Phân chia lại | Kích thước tập dữ liệu | Số người thực hiện | Số lõi trên mỗi người thực thi | Bộ nhớ thực thi | Runtime |
| A | 800 | 9.53 GB | 100 | 4 | 4 GiB | 11 phút, 10 giây |
| B | 80 | 0.95 GB | 10 | 4 | 4 GiB | 8 phút, 36 giây |
| C | 8 | 0.09 GB | 1 | 4 | 4 GiB | 7 phút, 56 giây |
Như chúng ta có thể thấy, việc song song hóa chính xác các lệnh gọi đến dịch vụ bút danh hóa của chúng tôi cho phép chúng tôi kiểm soát thời gian chạy tổng thể.
Trong các ví dụ sau, chúng tôi phân tích ba số liệu Lambda quan trọng cho dịch vụ bút danh: Invocations, ConcurrentExecutionsvà Duration.
Biểu đồ sau đây mô tả Invocations số liệu, với số liệu thống kê SUM màu cam và RUNNING SUM màu xanh lam.

Bằng cách tính toán sự khác biệt giữa điểm bắt đầu và điểm kết thúc của các lệnh gọi tích lũy, chúng ta có thể trích xuất số lượng lệnh gọi được thực hiện trong mỗi lần chạy.
| Chạy ID | Kích thước tập dữ liệu | Tổng số lời gọi |
| A | 9.53 GB | 1.467.000 - 0 = 1.467.000 |
| B | 0.95 GB | 1.467.000 - 1.616.500 = 149.500 |
| C | 0.09 GB | 1.616.500 - 1.631.000 = 14.500 |
Đúng như mong đợi, số lượng lệnh gọi tăng tỷ lệ thuận với 10 với kích thước tập dữ liệu.
Biểu đồ sau đây mô tả tổng ConcurrentExecutions số liệu, với số liệu thống kê MAX màu xanh lam.
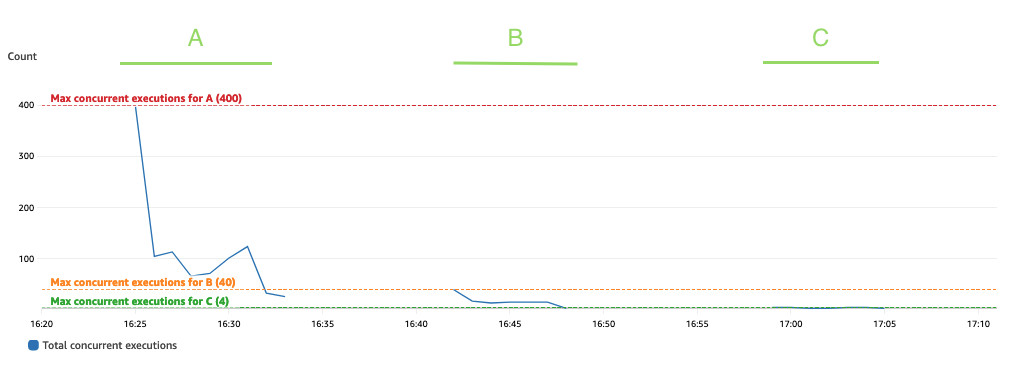
Ứng dụng này được thiết kế sao cho số lần chạy hàm Lambda đồng thời tối đa được xác định bằng số lượng tác vụ Spark (phân vùng tập dữ liệu Spark), có thể được xử lý song song. Con số này có thể được tính như MIN (người thi hành x executor_cores, Phân vùng tập dữ liệu Spark).
Trong thử nghiệm, hãy chạy A đã xử lý 800 phân vùng, sử dụng 100 trình thực thi với mỗi lõi bốn lõi. Điều này khiến 400 tác vụ được xử lý song song nên số lần chạy đồng thời của hàm Lambda không thể vượt quá 400. Logic tương tự được áp dụng cho các lần chạy B và C. Chúng ta có thể thấy điều này được phản ánh trong biểu đồ trước đó, trong đó số lần chạy đồng thời không bao giờ vượt quá giá trị 400, 40 và 4.
Để tránh điều tiết, hãy đảm bảo rằng số lượng tác vụ Spark có thể được xử lý song song không vượt quá giới hạn đồng thời của hàm Lambda. Nếu đúng như vậy, bạn nên tăng giới hạn đồng thời của hàm Lambda (nếu muốn duy trì hiệu suất) hoặc giảm số lượng phân vùng hoặc số lượng trình thực thi có sẵn (ảnh hưởng đến hiệu suất ứng dụng).
Biểu đồ sau đây mô tả Lambda Duration số liệu, với số liệu thống kê AVG màu cam và MAX màu xanh lá cây.
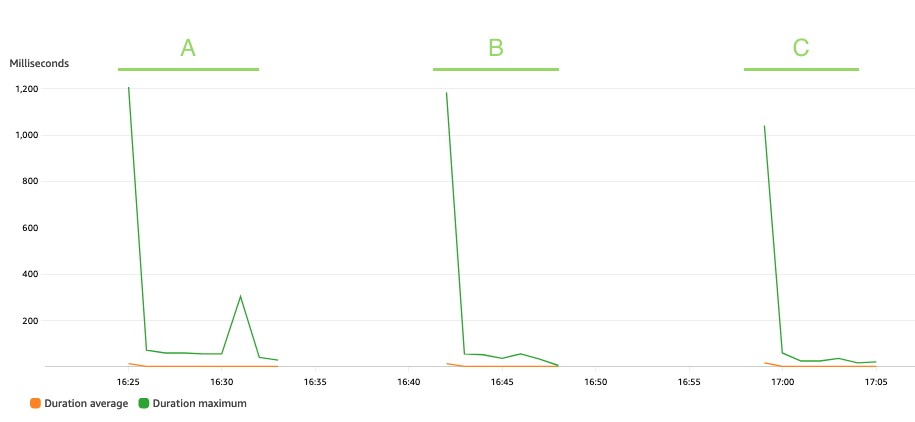
Đúng như mong đợi, kích thước của tập dữ liệu không ảnh hưởng đến thời lượng chạy hàm ẩn danh, ngoài một số lệnh gọi ban đầu gặp phải tình trạng khởi động nguội, vẫn không đổi ở mức trung bình 3 mili giây trong suốt ba kịch bản. Điều này là do số lượng bản ghi tối đa có trong mỗi lệnh gọi bút danh là không đổi (batch_size giá trị).
Lambda được tính phí dựa trên số lần gọi và thời gian để mã của bạn chạy (thời lượng). Bạn có thể sử dụng số liệu thời lượng trung bình và số lần gọi để ước tính chi phí của dịch vụ bút danh.
Truyền phát hiệu suất mô hình tiêu thụ
Để đánh giá hiệu suất cho mô hình sử dụng phát trực tuyến, chúng tôi đã chạy nhà sản xuất.py tập lệnh xác định trình tạo dữ liệu Kinesis để đẩy các bản ghi theo đợt vào luồng dữ liệu Kinesis.
Ứng dụng phát trực tuyến đã chạy trong 15 phút và được định cấu hình bằng một batch_interval trong 1 phút, là khoảng thời gian mà dữ liệu phát trực tuyến sẽ được chia thành các đợt. Bảng dưới đây tóm tắt các yếu tố liên quan.
| Phân chia lại | Nút công suất cụm | Số người thực hiện | Ký ức của người thực thi | Cửa sổ hàng loạt | Kích thước lô | Kích thước VIN |
| 17 |
1 Chính (m5.xlarge), 3 lõi (m5.2xlarge) |
6 | 9 GiB | 60 giây | 900 VIN/cuộc gọi API. | 5 byte / VIN |
Các biểu đồ sau đây mô tả số liệu của Kinesis Data Streams PutRecords (màu xanh) và GetRecords (màu cam) được tổng hợp trong khoảng thời gian 1 phút và sử dụng số liệu thống kê SUM. Biểu đồ đầu tiên hiển thị số liệu tính bằng byte, đạt mức cao nhất là 6.8 MB mỗi phút. Biểu đồ thứ hai hiển thị số liệu về số lượng bản ghi đạt mức cao nhất là 85,000 bản ghi mỗi phút.
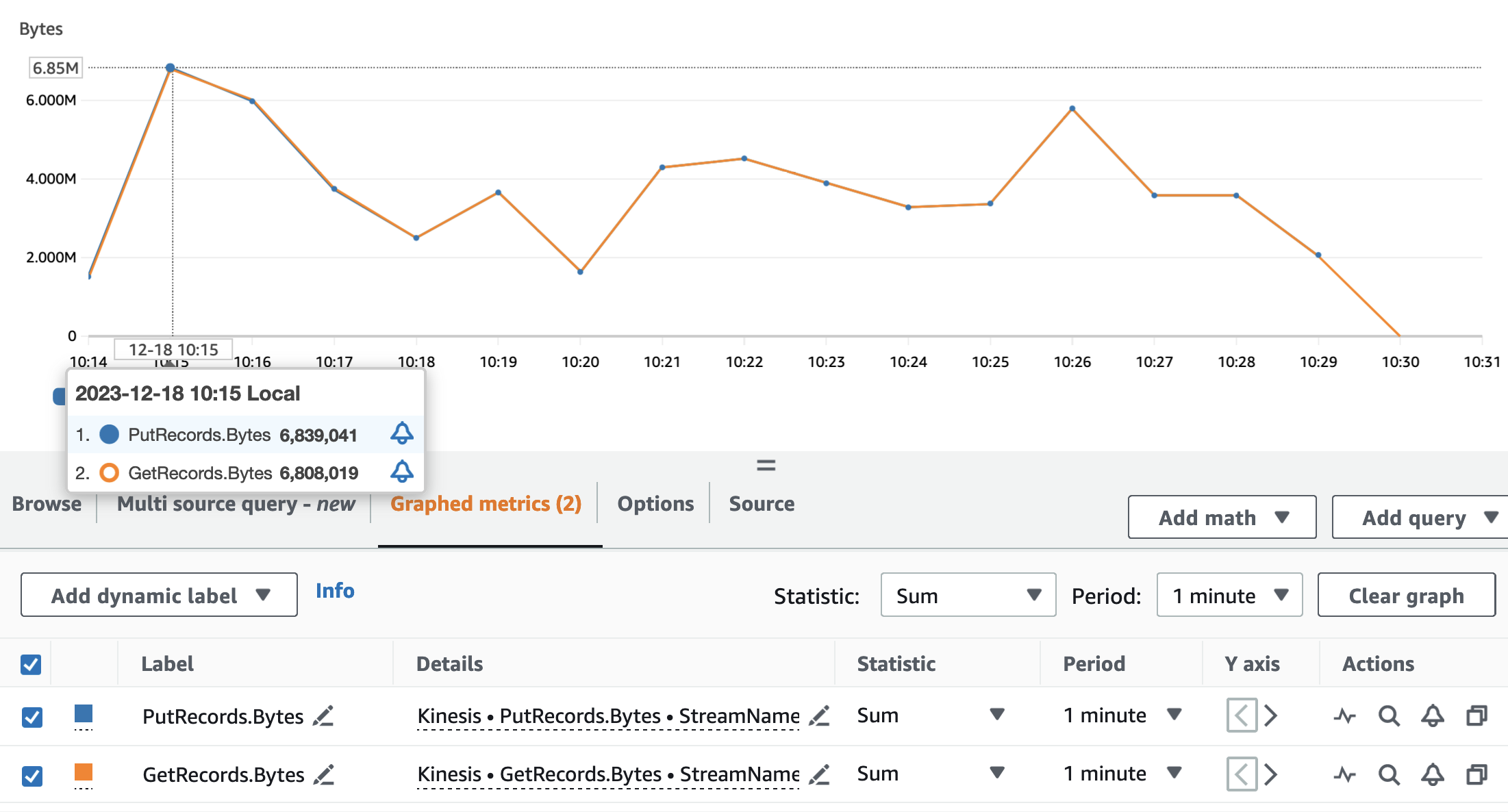

Chúng ta có thể thấy rằng các chỉ số GetRecords và PutRecords có các giá trị chồng chéo trong gần như toàn bộ quá trình chạy của ứng dụng. Điều này có nghĩa là ứng dụng phát trực tuyến có thể theo kịp tải của luồng.
Tiếp theo, chúng tôi phân tích các số liệu Lambda có liên quan cho dịch vụ bút danh: Invocations, ConcurrentExecutionsvà Duration.
Biểu đồ sau đây mô tả Invocations số liệu, với số liệu thống kê SUM (màu cam) và RUNNING SUM màu xanh lam.
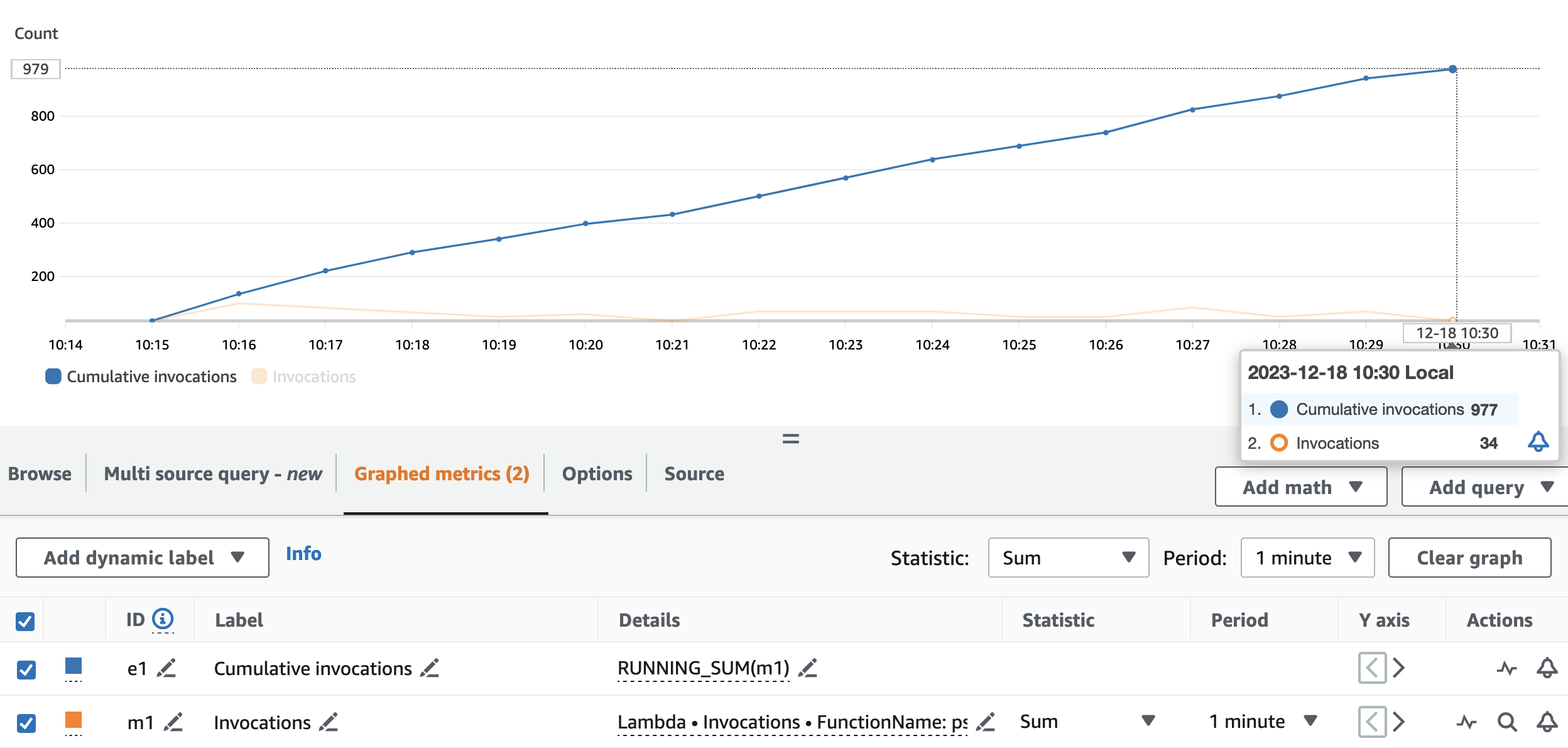
Bằng cách tính toán sự khác biệt giữa điểm bắt đầu và điểm kết thúc của các lệnh gọi tích lũy, chúng ta có thể trích xuất số lượng lệnh gọi đã được thực hiện trong quá trình chạy. Cụ thể, trong 15 phút, ứng dụng phát trực tuyến đã gọi API bút danh 977 lần, tức là khoảng 65 lệnh gọi mỗi phút.
Biểu đồ sau đây mô tả tổng ConcurrentExecutions số liệu, với số liệu thống kê MAX màu xanh lam.
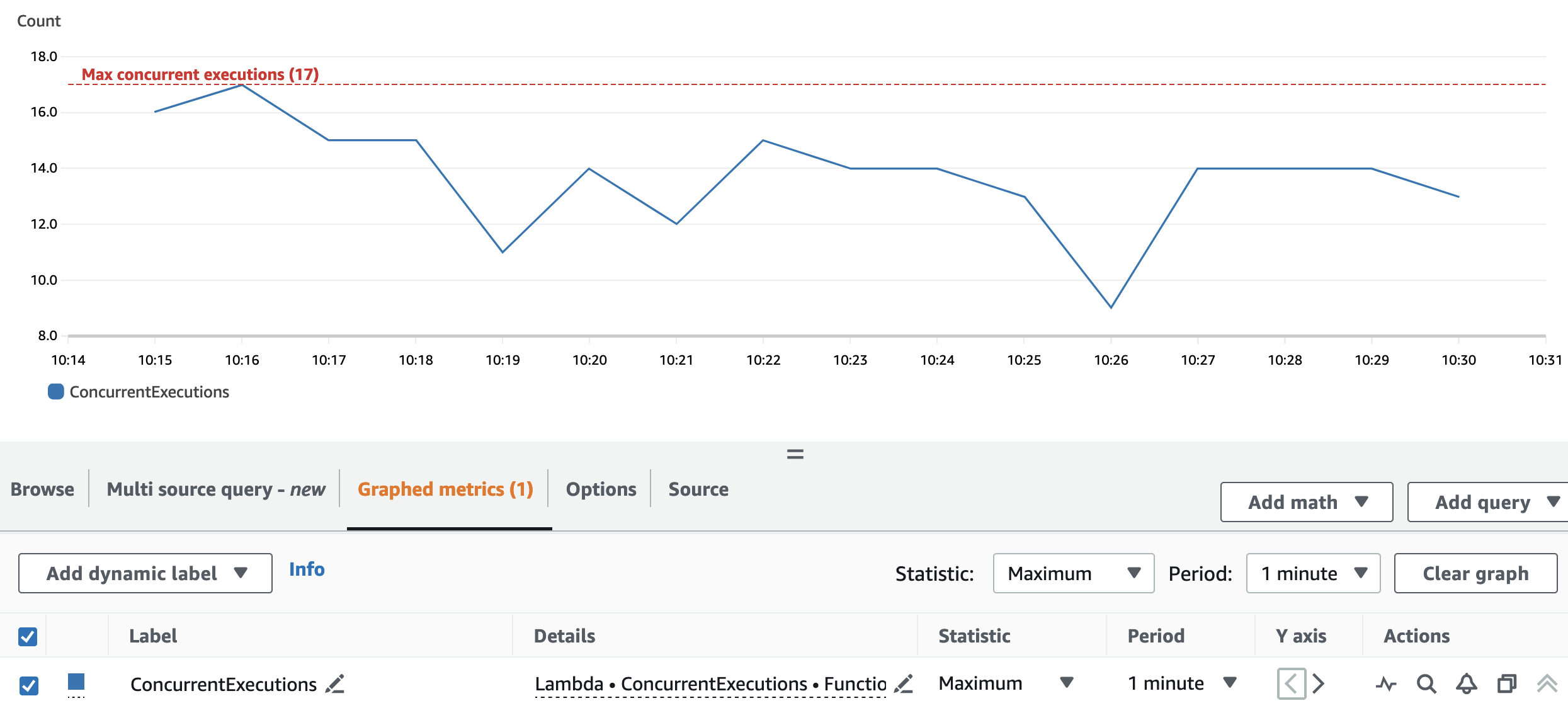
Cấu hình phân vùng lại và cụm cho phép ứng dụng xử lý song song tất cả các phân vùng Spark RDD. Kết quả là số lần chạy đồng thời của hàm Lambda luôn bằng hoặc thấp hơn số phân vùng là 17.
Để tránh điều tiết, hãy đảm bảo rằng số lượng tác vụ Spark có thể được xử lý song song không vượt quá giới hạn đồng thời của hàm Lambda. Đối với khía cạnh này, các đề xuất tương tự như đối với trường hợp sử dụng hàng loạt đều hợp lệ.
Biểu đồ sau đây mô tả Lambda Duration số liệu, với số liệu thống kê AVG màu xanh lam và MAX trong màu cam.
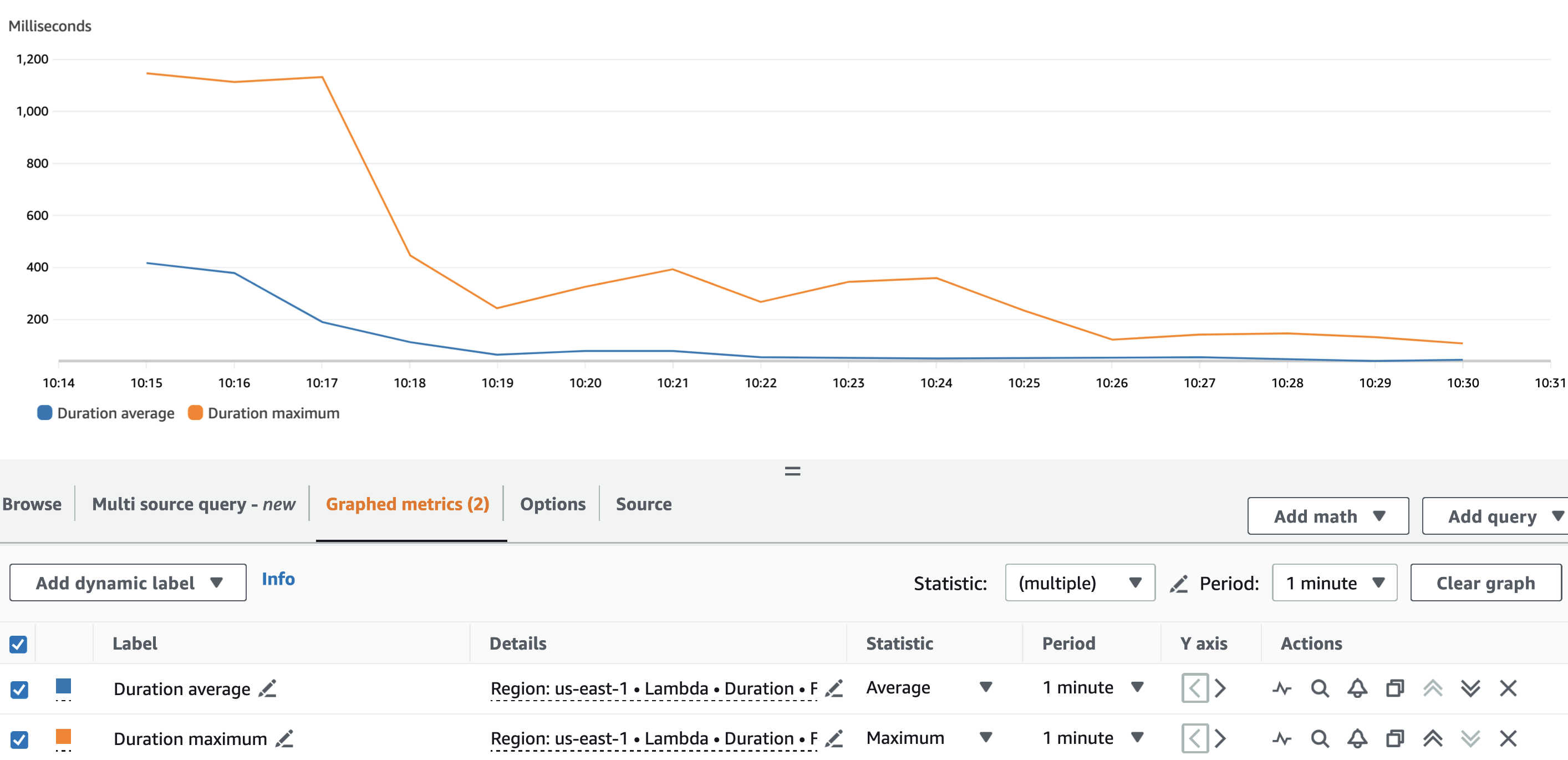
Đúng như dự đoán, ngoài thời gian khởi động nguội của hàm Lambda, thời lượng trung bình của hàm ẩn danh gần như không đổi trong suốt quá trình chạy. Điều này bởi vì batch_size giá trị xác định số lượng VIN cần đặt bút danh cho mỗi cuộc gọi, được đặt thành và không đổi ở mức 900.
Tốc độ truyền tải luồng dữ liệu Kinesis và tốc độ tiêu thụ ứng dụng phát trực tuyến của chúng tôi là những yếu tố ảnh hưởng đến số lượng lệnh gọi API được thực hiện đối với dịch vụ bút danh và do đó ảnh hưởng đến chi phí liên quan.
Biểu đồ sau đây mô tả Lambda Invocations số liệu, với số liệu thống kê SUM màu cam và Luồng dữ liệu Kinesis GetRecords.Records số liệu, với số liệu thống kê SUM màu xanh lam. Chúng ta có thể thấy rằng có mối tương quan giữa số lượng bản ghi được truy xuất từ luồng mỗi phút và số lượng lệnh gọi hàm Lambda, do đó ảnh hưởng đến chi phí của quá trình truyền phát.

Ngoài các batch_interval, chúng ta có thể kiểm soát tốc độ tiêu thụ của ứng dụng phát trực tuyến bằng cách sử dụng Thuộc tính phát trực tuyến Spark Lượt thích spark.streaming.receiver.maxRate và spark.streaming.blockInterval. Để biết thêm chi tiết, hãy tham khảo Tích hợp Spark Streaming + Kinesis và Hướng dẫn lập trình Spark Streaming.
Kết luận
Việc duyệt qua các quy tắc và quy định của luật bảo mật dữ liệu có thể khó khăn. Việc đặt bút danh cho các thuộc tính PII là một trong nhiều điểm cần cân nhắc khi xử lý dữ liệu nhạy cảm.
Trong loạt bài gồm hai phần này, chúng tôi đã khám phá cách bạn có thể xây dựng và sử dụng dịch vụ bút danh bằng nhiều dịch vụ AWS khác nhau với các tính năng hỗ trợ bạn xây dựng nền tảng dữ liệu mạnh mẽ. TRONG Phần 1, chúng tôi đã xây dựng nền tảng bằng cách chỉ ra cách xây dựng dịch vụ bút danh. Trong bài đăng này, chúng tôi đã giới thiệu các mẫu khác nhau để sử dụng dịch vụ bút danh theo cách hiệu quả và tiết kiệm chi phí. Kiểm tra GitHub kho lưu trữ cho các mô hình tiêu dùng bổ sung.
Về các tác giả
 Edvin Hallvaxhiu là Kiến trúc sư Bảo mật Toàn cầu Cấp cao với Dịch vụ Chuyên nghiệp của AWS và rất đam mê về an ninh mạng và tự động hóa. Anh ấy giúp khách hàng xây dựng các giải pháp an toàn và tuân thủ trên đám mây. Ngoài công việc, anh ấy thích đi du lịch và thể thao.
Edvin Hallvaxhiu là Kiến trúc sư Bảo mật Toàn cầu Cấp cao với Dịch vụ Chuyên nghiệp của AWS và rất đam mê về an ninh mạng và tự động hóa. Anh ấy giúp khách hàng xây dựng các giải pháp an toàn và tuân thủ trên đám mây. Ngoài công việc, anh ấy thích đi du lịch và thể thao.
 Rahul Shaurya là Kiến trúc sư dữ liệu lớn chính với Dịch vụ chuyên nghiệp của AWS. Anh giúp đỡ và hợp tác chặt chẽ với khách hàng trong việc xây dựng nền tảng dữ liệu và ứng dụng phân tích trên AWS. Ngoài giờ làm việc, Rahul thích đi dạo đường dài cùng chú chó Barney của mình.
Rahul Shaurya là Kiến trúc sư dữ liệu lớn chính với Dịch vụ chuyên nghiệp của AWS. Anh giúp đỡ và hợp tác chặt chẽ với khách hàng trong việc xây dựng nền tảng dữ liệu và ứng dụng phân tích trên AWS. Ngoài giờ làm việc, Rahul thích đi dạo đường dài cùng chú chó Barney của mình.
 Andrea Montanari là Kiến trúc sư dữ liệu lớn cấp cao với Dịch vụ chuyên nghiệp của AWS. Anh tích cực hỗ trợ khách hàng và đối tác trong việc xây dựng các giải pháp phân tích trên quy mô lớn trên AWS.
Andrea Montanari là Kiến trúc sư dữ liệu lớn cấp cao với Dịch vụ chuyên nghiệp của AWS. Anh tích cực hỗ trợ khách hàng và đối tác trong việc xây dựng các giải pháp phân tích trên quy mô lớn trên AWS.
 María Guerra là một Kiến trúc sư Dữ liệu lớn với Dịch vụ Chuyên nghiệp của AWS. Maria có kiến thức nền tảng về phân tích dữ liệu và kỹ thuật cơ khí. Cô ấy giúp khách hàng lập kiến trúc và phát triển khối lượng công việc liên quan đến dữ liệu trên đám mây.
María Guerra là một Kiến trúc sư Dữ liệu lớn với Dịch vụ Chuyên nghiệp của AWS. Maria có kiến thức nền tảng về phân tích dữ liệu và kỹ thuật cơ khí. Cô ấy giúp khách hàng lập kiến trúc và phát triển khối lượng công việc liên quan đến dữ liệu trên đám mây.
 Pushpraj Singh là Kiến trúc sư dữ liệu cấp cao với Dịch vụ chuyên nghiệp của AWS. Anh ấy đam mê kỹ thuật Dữ liệu và DevOps. Anh ấy giúp khách hàng xây dựng các ứng dụng dựa trên dữ liệu trên quy mô lớn.
Pushpraj Singh là Kiến trúc sư dữ liệu cấp cao với Dịch vụ chuyên nghiệp của AWS. Anh ấy đam mê kỹ thuật Dữ liệu và DevOps. Anh ấy giúp khách hàng xây dựng các ứng dụng dựa trên dữ liệu trên quy mô lớn.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/build-a-pseudonymization-service-on-aws-to-protect-sensitive-data-part-2/

