
Người xưa có câu nói “Một ounce phòng bệnh đáng giá một pound chữa bệnh”, nhắc nhở chúng ta rằng việc ngăn chặn một điều gì đó xảy ra ngay từ đầu còn dễ hơn là sửa chữa những thiệt hại sau khi nó đã xảy ra.
Trong thời đại trí tuệ nhân tạo (AI), câu tục ngữ này nhấn mạnh tầm quan trọng của việc tránh những cạm bẫy tiềm ẩn, chẳng hạn như trang bị quá mức, thông qua các kỹ thuật như chính quy hóa.
Trong bài viết này, chúng ta sẽ khám phá tính chính quy hóa bằng cách bắt đầu với các nguyên tắc cơ bản cho ứng dụng của nó bằng cách sử dụng Sci-kit Learn(Machine Learning) và Tensorflow(Deep Learning) và chứng kiến sức mạnh biến đổi của nó với các bộ dữ liệu trong thế giới thực bằng cách so sánh các kết quả này. Hãy bắt đầu!
Chính quy hóa là một khái niệm quan trọng trong học máy và học sâu nhằm mục đích ngăn chặn các mô hình bị trang bị quá mức.
Quá khớp xảy ra khi một mô hình học dữ liệu huấn luyện quá tốt. Tình hình cho thấy mô hình của bạn quá tốt để có thể trở thành sự thật.
Chúng ta hãy xem trang bị quá mức trông như thế nào.
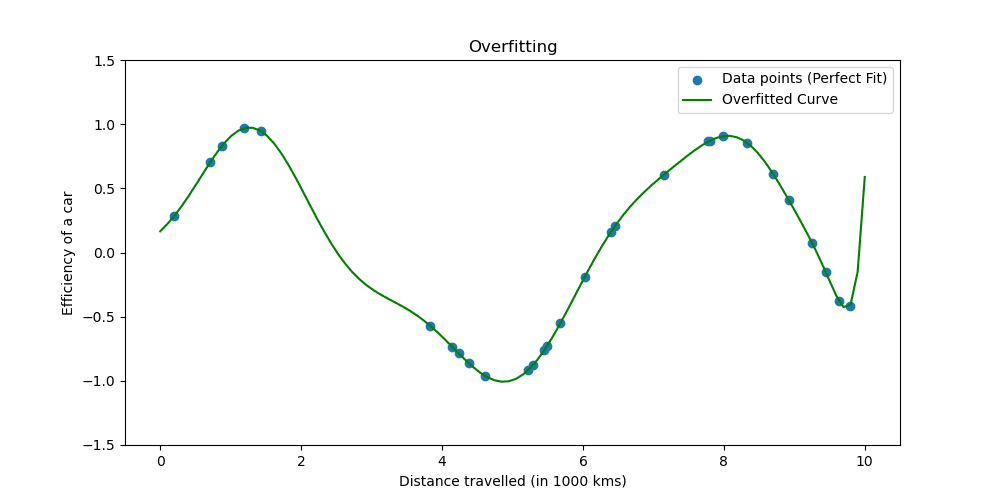
Các kỹ thuật chính quy hóa điều chỉnh quá trình học để đơn giản hóa mô hình, đảm bảo mô hình hoạt động tốt trên dữ liệu huấn luyện và khái quát hóa tốt cho dữ liệu mới. Chúng ta sẽ khám phá hai cách nổi tiếng để làm điều này.
Trong học máy, chính quy hóa thường được áp dụng cho các mô hình tuyến tính, chẳng hạn như hồi quy tuyến tính và logistic. Trong bối cảnh này, các hình thức chính quy hóa phổ biến nhất là:
- Chính quy hóa L1 (hồi quy Lasso)
- Chính quy hóa L2 (Hồi quy sườn)
Điều chỉnh Lasso khuyến khích mô hình chỉ sử dụng các tính năng cần thiết nhất bằng cách cho phép một số giá trị hệ số chính xác bằng 0, điều này có thể đặc biệt hữu ích cho việc lựa chọn tính năng.


Mặt khác, chính quy hóa sườn núi không khuyến khích các hệ số quan trọng bằng cách phạt bình phương các giá trị của chúng.

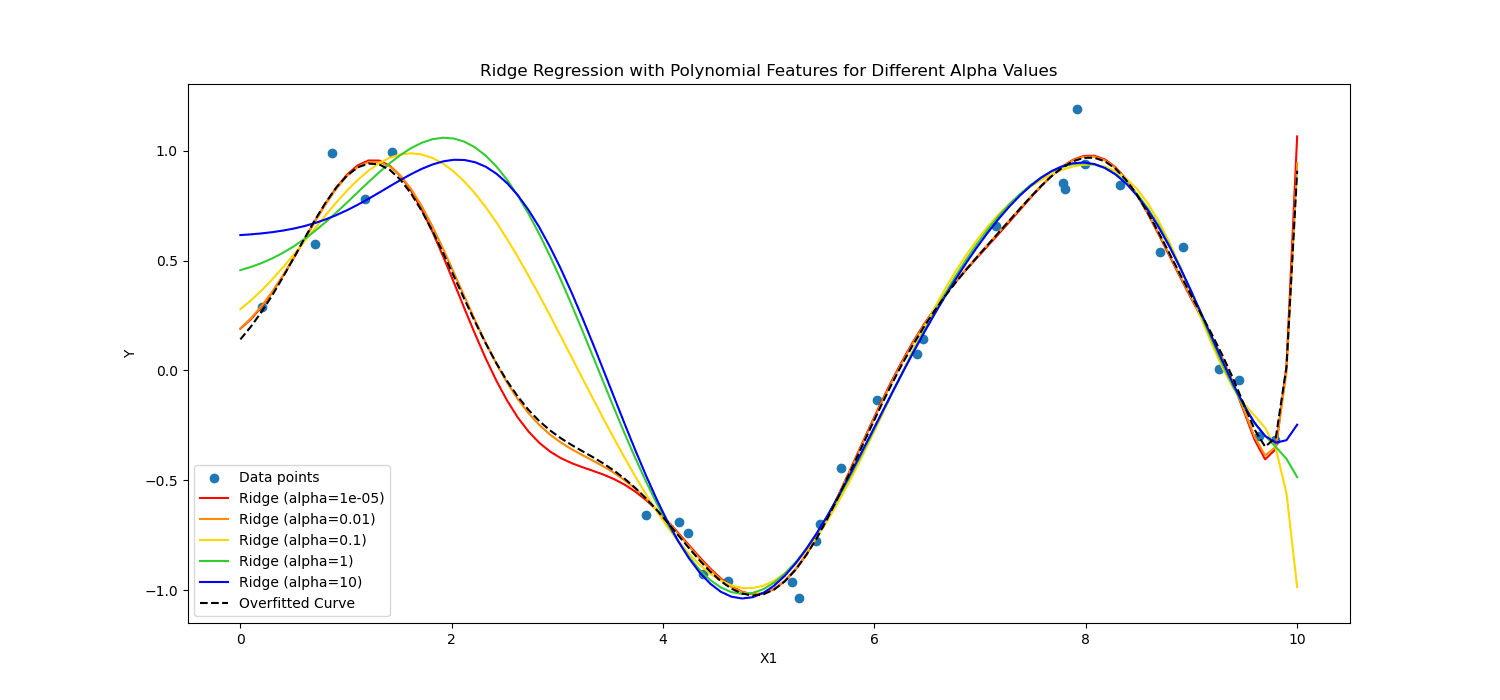
Nói tóm lại, họ tính toán khác nhau.
Hãy áp dụng những điều này vào dữ liệu bệnh nhân tim để thấy sức mạnh của nó trong học sâu và học máy.
Bây giờ, chúng ta sẽ áp dụng chính quy hóa để phân tích dữ liệu bệnh nhân tim mạch để thấy được sức mạnh của chính quy hóa. Bạn có thể tiếp cận tập dữ liệu từ tại đây.
Để áp dụng machine learning, chúng ta sẽ sử dụng Scikit-learn; để áp dụng deep learning, chúng ta sẽ sử dụng TensorFlow. Hãy bắt đầu!
Chính quy hóa trong học máy
Scikit-learn là một trong những phổ biến nhất Thư viện Python cho việc học máy cung cấp các công cụ mô hình hóa và phân tích dữ liệu đơn giản và hiệu quả.
Nó bao gồm việc triển khai các kỹ thuật chính quy hóa khác nhau, đặc biệt đối với các mô hình tuyến tính.
Ở đây, chúng ta sẽ khám phá cách áp dụng chính quy hóa L1 (Lasso) và L2 (Ridge).
Trong đoạn mã sau, chúng ta sẽ đào tạo hồi quy logistic bằng cách sử dụng kỹ thuật chính quy hóa Ridge(L2) và Lasso (L1). Cuối cùng, chúng ta sẽ thấy báo cáo chi tiết. Hãy xem mã.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Assuming heart_data is already loaded
X = heart_data.drop('target', axis=1)
y = heart_data['target']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define regularization values to explore
regularization_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over regularization values for L1 and L2
for C_value in regularization_values:
# Train and evaluate L1 model
log_reg_l1 = LogisticRegression(penalty='l1', C=C_value, solver='liblinear')
log_reg_l1.fit(X_train_scaled, y_train)
y_pred_l1 = log_reg_l1.predict(X_test_scaled)
accuracy_l1 = accuracy_score(y_test, y_pred_l1)
report_l1 = classification_report(y_test, y_pred_l1)
performance_metrics.append(('L1', C_value, accuracy_l1))
# Train and evaluate L2 model
log_reg_l2 = LogisticRegression(penalty='l2', C=C_value, solver='liblinear')
log_reg_l2.fit(X_train_scaled, y_train)
y_pred_l2 = log_reg_l2.predict(X_test_scaled)
accuracy_l2 = accuracy_score(y_test, y_pred_l2)
report_l2 = classification_report(y_test, y_pred_l2)
performance_metrics.append(('L2', C_value, accuracy_l2))
# Print the performance metrics for all models
print("Model Performance Evaluation:")
print("--------------------------------")
for metric in performance_metrics:
reg_type, C_value, accuracy = metric
print(f"Regularization: {reg_type}, C: {C_value}, Accuracy: {accuracy:.2f}")
Đây là kết quả đầu ra.
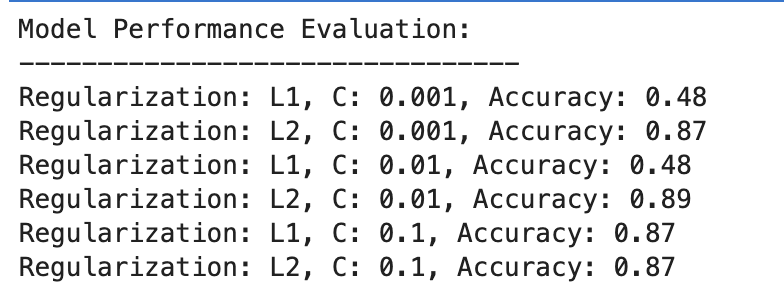
Hãy đánh giá kết quả.
L1 chính quy hóa
- Ở C=0.001, độ chính xác thấp đáng kể (48%). Điều này cho thấy mô hình chưa phù hợp. Nó cho thấy quá nhiều sự chính quy.
- Khi C tăng lên 0.01, độ chính xác không thay đổi đối với L1, cho thấy mô hình vẫn bị thiếu khớp hoặc độ chính quy hóa quá mạnh.
- Với C=0.1, độ chính xác cải thiện đáng kể lên 87%, cho thấy việc giảm cường độ chính quy hóa cho phép mô hình học hỏi tốt hơn từ dữ liệu.
L2 chính quy hóa
Nhìn chung, quá trình chính quy hóa L2 hoạt động tốt một cách nhất quán, với độ chính xác ở mức 87% đối với C=0.001 và cao hơn một chút ở mức 89% đối với C=0.01, sau đó ổn định ở mức 87% đối với C=0.1.
Điều này cho thấy rằng việc chính quy hóa L2 nhìn chung dễ tha thứ và hiệu quả hơn đối với tập dữ liệu này trong các mô hình hồi quy logistic, có thể là do bản chất của nó.
Chính quy hóa trong Deep Learning
Một số kỹ thuật chính quy hóa được sử dụng trong học sâu, bao gồm chính quy hóa L1 (Lasso) và L2 (Ridge), bỏ học và dừng sớm.
Trong phần này, để lặp lại những gì chúng ta đã làm trong ví dụ học máy trước đây, chúng ta sẽ áp dụng chính quy hóa L1 và L2. Lần này hãy xác định danh sách các giá trị chính quy L1 và L2.
Sau đó, đối với tất cả các giá trị này, chúng tôi sẽ đào tạo và đánh giá mô hình học sâu của mình và cuối cùng, chúng tôi sẽ đánh giá kết quả.
Hãy xem mã.
from tensorflow.keras.regularizers import l1_l2
import numpy as np
# Define a list/grid of L1 and L2 regularization values
l1_values = [0.001, 0.01, 0.1]
l2_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over all combinations of L1 and L2 values
for l1_val in l1_values:
for l2_val in l2_values:
# Define model with the current combination of L1 and L2
model = Sequential([
Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train_scaled, y_train, validation_split=0.2, epochs=100, batch_size=10, verbose=0)
# Evaluate the model
loss, accuracy = model.evaluate(X_test_scaled, y_test, verbose=0)
# Store the performance along with the regularization values
performance_metrics.append((l1_val, l2_val, accuracy))
# Find the best performing model
best_performance = max(performance_metrics, key=lambda x: x[2])
best_l1, best_l2, best_accuracy = best_performance
# After the loop, to print all performance metrics
print("All Model Performances:")
print("L1 Value | L2 Value | Accuracy")
for metrics in performance_metrics:
print(f"{metrics[0]:8} | {metrics[1]:8} | {metrics[2]:.3f}")
# After finding the best performance, to print the best model details
print("nBest Model Performance:")
print("----------------------------")
print(f"Best L1 value: {best_l1}")
print(f"Best L2 value: {best_l2}")
print(f"Best accuracy: {best_accuracy:.3f}")
Đây là kết quả đầu ra.
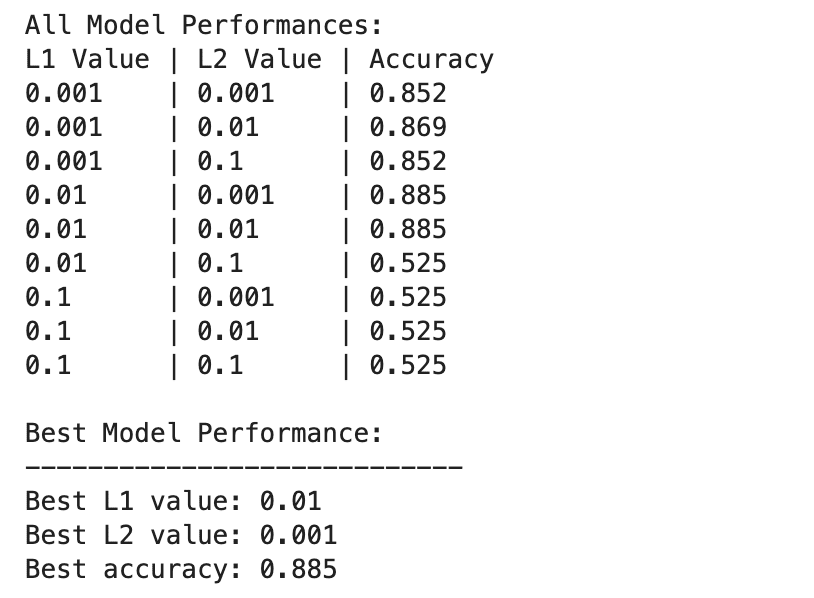
Hiệu suất của mô hình học sâu khác nhau nhiều hơn trên các kết hợp khác nhau của các giá trị chính quy L1 và L2.
Hiệu suất tốt nhất được quan sát thấy ở L1=0.01 và L2=0.001, với độ chính xác là 88.5%, cho thấy sự chính quy hóa cân bằng giúp ngăn ngừa tình trạng quá khớp trong khi cho phép mô hình nắm bắt các mẫu cơ bản trong dữ liệu.
Các giá trị chính quy hóa cao hơn, đặc biệt là ở L1=0.1 hoặc L2=0.1, làm giảm đáng kể độ chính xác của mô hình xuống 52.5%, cho thấy rằng việc chính quy hóa quá nhiều sẽ hạn chế nghiêm trọng khả năng học tập của mô hình.
Học máy & Học sâu trong chính quy hóa
Hãy so sánh kết quả giữa Machine Learning và Deep Learning.
Hiệu quả của việc chính quy hóa: Cả trong bối cảnh học máy và học sâu, việc chính quy hóa phù hợp sẽ giúp giảm thiểu tình trạng trang bị quá mức, nhưng việc chính quy hóa quá mức sẽ dẫn đến việc trang bị thiếu. Cường độ chính quy hóa tối ưu khác nhau, với các mô hình học sâu có khả năng yêu cầu sự cân bằng nhiều sắc thái hơn do độ phức tạp cao hơn của chúng.
Hiệu suất: Mô hình học máy hiệu suất tốt nhất (L2 với C=0.01, độ chính xác 89%) và mô hình học sâu hiệu suất tốt nhất (L1=0.01, L2=0.001, độ chính xác 88.5%) đạt được độ chính xác tương đương, chứng tỏ rằng cả hai phương pháp đều có thể hiệu quả được chính quy hóa để đạt được hiệu suất cao trên tập dữ liệu này.
Chiến lược chính quy hóa: Chính quy hóa L2 dường như hiệu quả hơn và ít nhạy cảm hơn với việc lựa chọn C trong các mô hình hồi quy logistic, trong khi sự kết hợp giữa chính quy hóa L1 và L2 mang lại kết quả tốt nhất trong học sâu, mang lại sự cân bằng giữa lựa chọn tính năng và hình phạt trọng số.
Sự lựa chọn và sức mạnh của việc chính quy hóa cần được điều chỉnh cẩn thận để cân bằng độ phức tạp trong học tập với nguy cơ trang bị quá mức hoặc không phù hợp.
Trong suốt quá trình khám phá này, chúng tôi đã làm sáng tỏ vấn đề chính quy hóa, thể hiện vai trò của nó trong việc ngăn chặn việc điều chỉnh quá mức và đảm bảo các mô hình của chúng tôi khái quát hóa tốt dữ liệu không nhìn thấy được.
Việc áp dụng các kỹ thuật chính quy hóa sẽ đưa bạn đến gần hơn với trình độ thành thạo về học máy và học sâu, củng cố bộ công cụ khoa học dữ liệu của bạn.
Đi sâu vào các dự án dữ liệu và thử điều chỉnh dữ liệu của bạn trong các tình huống khác nhau, chẳng hạn như Dự đoán thời gian giao hàng. Chúng tôi đã sử dụng cả mô hình Machine Learning và Deep Learning trong dự án dữ liệu này. Tuy nhiên, cuối cùng, chúng tôi cũng đề cập rằng có thể vẫn còn chỗ để cải thiện. Vậy tại sao bạn không thử quy tắc hóa ở đó và xem nó có giúp ích gì không?
Nate Rosidi là một nhà khoa học dữ liệu và trong chiến lược sản phẩm. Anh ấy cũng là một giáo sư trợ giảng dạy phân tích và là người sáng lập StrataScratch, một nền tảng giúp các nhà khoa học dữ liệu chuẩn bị cho cuộc phỏng vấn của họ với các câu hỏi phỏng vấn thực tế từ các công ty hàng đầu. Kết nối với anh ấy trên Twitter: StrataScratch or LinkedIn.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/wtf-is-regularization-and-what-is-it-for?utm_source=rss&utm_medium=rss&utm_campaign=wtf-is-regularization-and-what-is-it-for

