
Bài viết này ban đầu được xuất bản trên của tác giả Blog của chúng tôi. và được xuất bản lại lên TOPBOTS với sự cho phép của tác giả.
Các mô hình ngôn ngữ lớn như ChatGPT xử lý và tạo chuỗi văn bản bằng cách trước tiên chia văn bản thành các đơn vị nhỏ hơn được gọi là thẻ. Trong hình ảnh bên dưới, mỗi khối màu đại diện cho một mã thông báo duy nhất. Những từ ngắn hoặc phổ biến như “bạn”, “nói”, “to” và “luôn luôn” là dấu hiệu riêng của nó, trong khi những từ dài hơn hoặc ít phổ biến hơn như “tàn bạo”, “sớm phát triển” và “siêu năng lực kinh nghiệm” được chia thành từ phụ nhỏ hơn.
Quá trình này của mã thông báo không đồng nhất giữa các ngôn ngữ, dẫn đến sự chênh lệch về số lượng mã thông báo được tạo cho các biểu thức tương đương trong các ngôn ngữ khác nhau. Ví dụ, một câu bằng tiếng Miến Điện hoặc tiếng Amharic có thể yêu cầu nhiều hơn 10 lần mã thông báo so với một thông điệp tương tự bằng tiếng Anh.

Một ví dụ về cùng một thông báo được dịch sang năm ngôn ngữ và số lượng mã thông báo tương ứng cần thiết để mã hóa thông báo đó (sử dụng mã thông báo của OpenAI). Các văn bản đến từ Bộ dữ liệu MASSIVE của Amazon.
Trong bài viết này, tôi khám phá quy trình token hóa và cách quy trình này khác nhau giữa các ngôn ngữ khác nhau:
- Phân tích phân phối mã thông báo trong bộ dữ liệu song song gồm các tin nhắn ngắn đã được dịch sang 52 ngôn ngữ khác nhau
- Một số ngôn ngữ, chẳng hạn như tiếng Armenia hoặc tiếng Miến Điện, yêu cầu gấp 9 đến 10 lần so với tiếng Anh để mã hóa các tin nhắn có thể so sánh
- Tác động của sự khác biệt ngôn ngữ này
- Hiện tượng này không mới đối với AI — điều này phù hợp với những gì chúng tôi quan sát được trong mã Morse và phông chữ máy tính
Hãy thử nó cho mình!
Hãy dùng thử bảng điều khiển khám phá mà tôi đã tạo, có sẵn trên các không gian HuggingFace. Tại đây, bạn có thể so sánh độ dài mã thông báo cho các ngôn ngữ khác nhau và cho các trình mã thông báo khác nhau (điều này chưa được khám phá trong bài viết này, nhưng tôi khám phá người đọc để tự mình thực hiện).
TO LỚN là một tập dữ liệu song song được giới thiệu bởi amazon bao gồm 1 triệu văn bản ngắn song song, thực tế được dịch qua 52 ngôn ngữ và 18 miền. tôi đã sử dụng dev phân chia tập dữ liệu, bao gồm 2033 văn bản được dịch sang từng ngôn ngữ. tập dữ liệu là có sẵn trên HuggingFace và được cấp phép theo Giấy phép CC BY 4.0.
Trong khi tồn tại nhiều mã thông báo mô hình ngôn ngữ khác, bài viết này chủ yếu tập trung vào Mã thông báo mã hóa cặp byte (BPE) của OpenAI (được sử dụng bởi ChatGPT và GPT-4) vì ba lý do chính:
- Đầu tiên, Bài viết của Denys Linkov đã so sánh một số trình tạo mã thông báo và nhận thấy rằng trình tạo mã thông báo của GPT-2 có độ dài mã thông báo chênh lệch cao nhất giữa các ngôn ngữ khác nhau. Điều này thôi thúc tôi tập trung vào các mô hình OpenAI, bao gồm GPT-2 và những người kế nhiệm của nó.
- Thứ hai, vì chúng tôi thiếu thông tin chi tiết về tập dữ liệu đào tạo đầy đủ của ChatGPT, việc điều tra các mô hình hộp đen và mã thông báo của OpenAI giúp hiểu rõ hơn về hành vi và kết quả đầu ra của chúng.
- Cuối cùng, việc áp dụng rộng rãi ChatGPT trong các ứng dụng khác nhau (từ các nền tảng học ngôn ngữ như Duolingo đến các ứng dụng truyền thông xã hội như Snapchat) nêu bật tầm quan trọng của việc hiểu các sắc thái mã hóa để đảm bảo xử lý ngôn ngữ công bằng giữa các cộng đồng ngôn ngữ khác nhau.
Để tính số lượng mã thông báo chứa trong văn bản, tôi sử dụng cl100k_base mã thông báo có sẵn trên tikitoken, là mã thông báo BPE được sử dụng bởi các mô hình ChatGPT của OpenAI (`gpt-3.5-turbo` và `gpt-4`).
Một số ngôn ngữ liên tục mã hóa với độ dài dài hơn
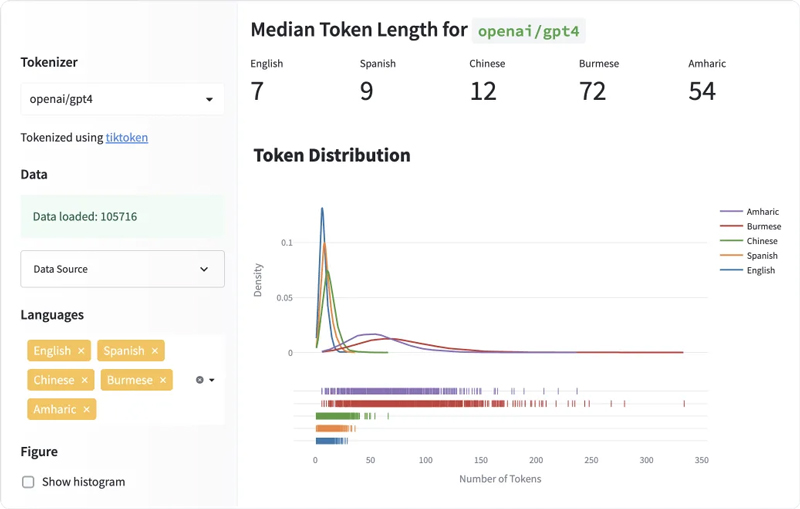
Biểu đồ phân phối sau đây so sánh việc phân phối độ dài mã thông báo cho năm ngôn ngữ. Đường cong cho tiếng Anh cao và hẹp, có nghĩa là các văn bản tiếng Anh luôn được mã hóa thành một số lượng mã thông báo nhỏ hơn. Mặt khác, đường cong cho các ngôn ngữ như tiếng Hindi và tiếng Miến Điện ngắn và rộng, nghĩa là các ngôn ngữ này mã hóa văn bản thành nhiều mã thông báo hơn.
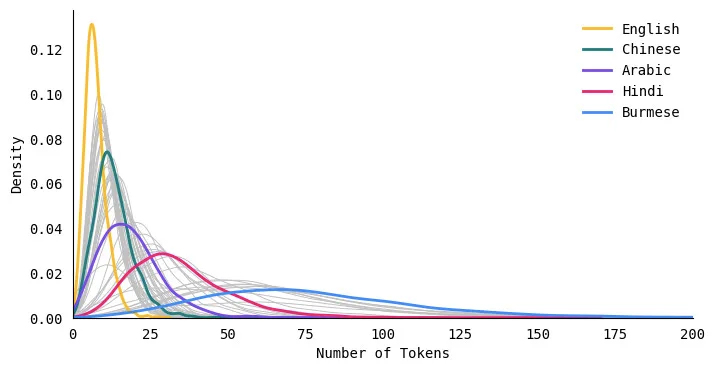
Tiếng Anh có độ dài mã thông báo trung bình ngắn nhất
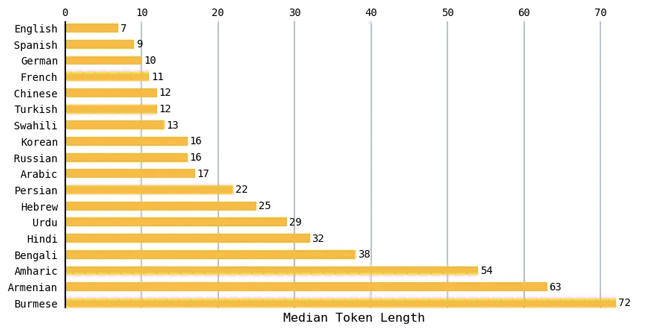
Đối với mỗi ngôn ngữ, tôi đã tính độ dài mã thông báo trung bình cho tất cả các văn bản trong tập dữ liệu. Biểu đồ sau đây so sánh một tập hợp con của các ngôn ngữ. Văn bản tiếng Anh có độ dài trung bình nhỏ nhất là 7 thẻ và văn bản tiếng Miến Điện có độ dài trung bình lớn nhất là 72 thẻ. Các ngôn ngữ lãng mạn như tiếng Tây Ban Nha, tiếng Pháp và tiếng Bồ Đào Nha có xu hướng dẫn đến số lượng mã thông báo tương tự như tiếng Anh.
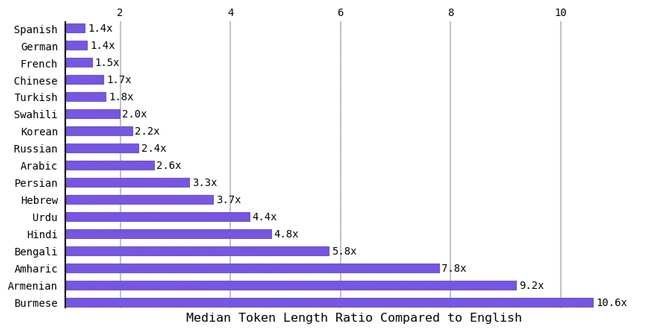
Vì tiếng Anh có độ dài mã thông báo trung bình ngắn nhất nên tôi đã tính tỷ lệ độ dài mã thông báo trung bình của các ngôn ngữ khác so với tiếng Anh. Các ngôn ngữ như tiếng Hindi và tiếng Bengali (hơn 800 triệu người nói một trong hai ngôn ngữ này) dẫn đến độ dài mã thông báo trung bình gấp khoảng 5 lần so với tiếng Anh. Tỷ lệ này gấp 9 lần so với tiếng Anh đối với người Armenia và hơn 10 lần so với tiếng Anh đối với người Miến Điện. Nói cách khác, để thể hiện cùng một cảm xúc, một số ngôn ngữ yêu cầu mã thông báo nhiều hơn tới 10 lần.
Ý nghĩa của sự chênh lệch ngôn ngữ mã thông báo
Nhìn chung, yêu cầu nhiều mã thông báo hơn (để mã hóa cùng một thông báo bằng một ngôn ngữ khác) có nghĩa là:
- Bạn bị giới hạn bởi lượng thông tin bạn có thể đưa vào lời nhắc (vì cửa sổ ngữ cảnh đã được cố định). Kể từ tháng 2023 năm 3, GPT-4 có thể cần tới 4K mã thông báo và GPT-8 có thể cần tới 32K hoặc XNUMXK mã thông báo trong đầu vào [1]
- Nó tốn nhiều tiền hơn
- Mất nhiều thời gian hơn để chạy
Các mô hình của OpenAI đang ngày càng được sử dụng ở các quốc gia mà tiếng Anh không phải là ngôn ngữ chính. Theo SimilarWeb.com, Hoa Kỳ chỉ chiếm 10% lưu lượng truy cập được gửi đến ChatGPT từ tháng 2023 đến tháng XNUMX năm XNUMX.
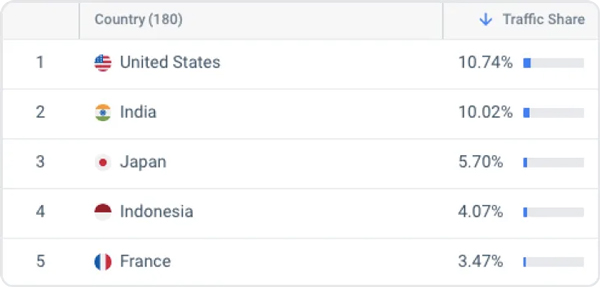
Ngoài ra, ChatGPT đã được sử dụng ở Pakistan để cấp bảo lãnh trong một vụ bắt cóc trẻ vị thành niên và tại Nhật Bản cho các công việc hành chính. Khi ChatGPT và các mô hình tương tự ngày càng được tích hợp vào các sản phẩm và dịch vụ trên toàn thế giới, điều quan trọng là phải hiểu và giải quyết những bất bình đẳng như vậy.
Chênh lệch ngôn ngữ trong xử lý ngôn ngữ tự nhiên
Sự phân chia kỹ thuật số này trong xử lý ngôn ngữ tự nhiên (NLP) là một lĩnh vực nghiên cứu tích cực. 70% tài liệu nghiên cứu được xuất bản trong một hội nghị ngôn ngữ học máy tính chỉ đánh giá tiếng Anh.[2] Các mô hình đa ngôn ngữ hoạt động kém hơn đối với một số tác vụ NLP trên các ngôn ngữ có ít tài nguyên hơn so với các ngôn ngữ có nhiều tài nguyên như tiếng Anh.[3] Theo W3Techs (World Wide Web Technology Surveys), tiếng Anh thống trị hơn một nửa (55.6%) nội dung trên Internet.[4]
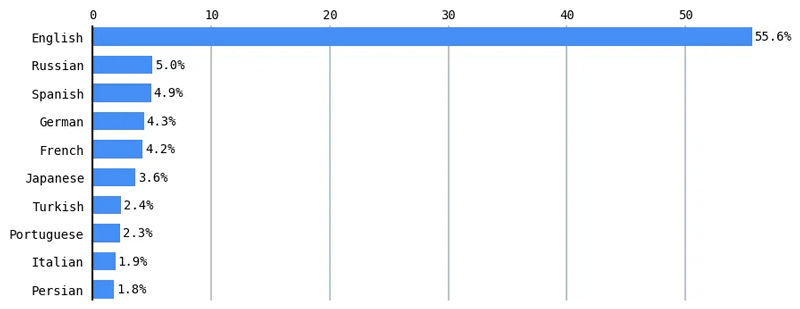
Tương tự như vậy, tiếng Anh chiếm hơn 46% kho văn bản Thu thập thông tin chung (hàng tỷ trang web từ Internet bò trong hơn một thập kỷ), các phiên bản của chúng đã được sử dụng để đào tạo nhiều ngôn ngữ lớn như T5 của Google và GPT-3 của OpenAI (và có thể là ChatGPT và GPT-4). Thu thập thông tin thông thường chiếm 60% dữ liệu đào tạo GPT-3.[5]
Giải quyết khoảng cách kỹ thuật số trong NLP là rất quan trọng để đảm bảo hiệu suất và biểu diễn ngôn ngữ công bằng trong các công nghệ do AI điều khiển. Thu hẹp khoảng cách này đòi hỏi nỗ lực phối hợp từ các nhà nghiên cứu, nhà phát triển và nhà ngôn ngữ học để ưu tiên và đầu tư vào việc phát triển các ngôn ngữ sử dụng ít tài nguyên, thúc đẩy một bối cảnh ngôn ngữ toàn diện và đa dạng hơn trong lĩnh vực xử lý ngôn ngữ tự nhiên.
Ví dụ lịch sử: Thể hiện kiểu chữ Trung Quốc bằng mã Morse
Sự chênh lệch về chi phí công nghệ cho các ngôn ngữ khác nhau như vậy không phải là mới đối với AI hay thậm chí là điện toán.
Hơn một trăm năm trước, điện báo, một công nghệ mang tính cách mạng vào thời bấy giờ (“internet của thời đại nó”), đã phải đối mặt với sự bất bình đẳng về ngôn ngữ tương tự như những gì chúng ta thấy trong các mô hình ngôn ngữ lớn ngày nay. Bất chấp những hứa hẹn về trao đổi và hợp tác cởi mở, điện báo thể hiện sự khác biệt về tốc độ và chi phí giữa các ngôn ngữ. Chẳng hạn, việc mã hóa và truyền một tin nhắn bằng tiếng Trung Quốc (so với một tin nhắn tương đương bằng tiếng Anh) là
- đắt gấp 2 lần
- Lâu hơn 15–20 lần
Nghe có vẻ quen?
Điện tín được “thiết kế đầu tiên và quan trọng nhất đối với các ngôn ngữ chữ cái phương Tây, trên hết là tiếng Anh.”[6] Mã Morse đã gán độ dài và chi phí khác nhau cho dấu chấm và dấu gạch ngang, dẫn đến một hệ thống tiết kiệm chi phí cho tiếng Anh. Tuy nhiên, ngôn ngữ Trung Quốc, vốn dựa vào chữ tượng hình, đã phải đối mặt với những thách thức trong điện báo. Một người Pháp tên là Viguier đã nghĩ ra một hệ thống ánh xạ các ký tự Trung Quốc sang mã Morse.
Về cơ bản, mỗi chữ tượng hình của Trung Quốc được ánh xạ tới một mã gồm bốn chữ số, mã này sau đó phải được dịch sang mã Morse. Việc này mất nhiều thời gian để tra cứu các mã trong sổ mã (thiếu các mối tương quan có ý nghĩa) và tốn kém hơn khi truyền (vì mỗi ký tự được biểu thị bằng bốn chữ số và truyền một chữ số đắt hơn một chữ cái). Thực tế này khiến tiếng Trung Quốc gặp bất lợi so với các ngôn ngữ khác về tốc độ và chi phí điện báo.
Một ví dụ khác: Sự không công bằng trong việc thể hiện phông chữ
Ban đầu, tôi cố gắng hình dung tất cả 52 ngôn ngữ trong một đám mây từ duy nhất. Tôi đã kết thúc với một cái gì đó như thế này, trong đó phần lớn các ngôn ngữ không được hiển thị chính xác.

Điều này khiến tôi gặp khó khăn khi cố gắng tìm một phông chữ có thể hiển thị tất cả các tập lệnh ngôn ngữ. Tôi đã truy cập Google Fonts để tìm phông chữ hoàn hảo này và thấy rằng không có phông chữ nào tồn tại. Dưới đây là ảnh chụp màn hình cho thấy cách 52 ngôn ngữ này hiển thị bằng 3 phông chữ khác nhau từ Google Fonts.

Để tạo đám mây từ ở đầu bài viết này, tôi (ehm) đã tải xuống thủ công 17 tệp phông chữ cần thiết để hiển thị tất cả các tập lệnh ngôn ngữ và từng từ được hiển thị cùng một lúc. Mặc dù tôi đã đạt được hiệu quả mong muốn, nhưng nó còn hiệu quả hơn rất nhiều so với, chẳng hạn như nếu tất cả các ngôn ngữ của tôi sử dụng cùng một hệ thống chữ viết (chẳng hạn như bảng chữ cái Latinh).
Trong bài viết này, tôi đã khám phá sự khác biệt về ngôn ngữ trong các mô hình ngôn ngữ bằng cách xem cách chúng xử lý văn bản thông qua mã thông báo.
- Sử dụng bộ dữ liệu gồm các văn bản song song được dịch sang 52 ngôn ngữ, tôi đã chỉ ra rằng một số ngôn ngữ yêu cầu số lượng mã thông báo nhiều hơn tới 10 lần để diễn đạt cùng một thông điệp bằng tiếng Anh
- tôi đã chia sẻ một bảng điều khiển nơi bạn có thể khám phá các ngôn ngữ và mã thông báo khác nhau
- Tôi đã thảo luận về tác động của sự chênh lệch này đối với một số ngôn ngữ về hiệu suất, chi phí tiền tệ và thời gian
- Tôi đã chỉ ra rằng mô hình chênh lệch công nghệ ngôn ngữ này không phải là mới, so sánh hiện tượng này với trường hợp lịch sử của mã Morse và điện báo của Trung Quốc
Sự khác biệt về ngôn ngữ trong mã thông báo NLP cho thấy một vấn đề cấp bách trong AI: tính công bằng và tính toàn diện. Vì các mô hình như ChatGPT chủ yếu được đào tạo bằng tiếng Anh nên các ngôn ngữ chữ viết không thuộc ngôn ngữ Ấn-Âu và không phải tiếng Latinh phải đối mặt với các rào cản do chi phí mã thông báo bị cấm. Giải quyết những khác biệt này là điều cần thiết để đảm bảo một tương lai toàn diện và dễ tiếp cận hơn cho trí tuệ nhân tạo, cuối cùng mang lại lợi ích cho các cộng đồng ngôn ngữ đa dạng trên toàn thế giới.
Phụ lục
Token mã hóa cặp byte
Trong lĩnh vực xử lý ngôn ngữ tự nhiên, mã thông báo đóng một vai trò quan trọng trong việc cho phép các mô hình ngôn ngữ xử lý và hiểu văn bản. Các mô hình khác nhau sử dụng các phương pháp khác nhau để mã hóa một câu, chẳng hạn như tách câu đó thành các từ, thành các ký tự hoặc thành các phần của từ (còn được gọi là từ phụ; ví dụ: tách “constantly” thành “constant” và “ly”).
Một mã thông báo phổ biến được gọi là Mã hóa cặp byte (BPE). Đây là mã hóa được OpenAI sử dụng cho các mô hình ChatGPT của họ. BPE có nghĩa là phân tách các từ hiếm thành các từ phụ có ý nghĩa trong khi vẫn giữ nguyên các từ được sử dụng thường xuyên. Có thể tìm thấy lời giải thích toàn diện về thuật toán BPE trên Khóa học HuggingFace Transformers.
Tìm hiểu sâu hơn về phân phối mã thông báo cho các ngôn ngữ
Tôi đã tăng cường tập dữ liệu MASSIVE của Amazon bằng cách sử dụng thông tin về từng ngôn ngữ trong số 52 ngôn ngữ bằng cách sử dụng phần hộp thông tin trên trang Wikipedia của ngôn ngữ đó, thu thập thông tin như chữ viết (ví dụ: bảng chữ cái Latinh, Ả Rập) và khu vực địa lý chính mà ngôn ngữ đó chiếm ưu thế (nếu có liên quan) . Tôi cũng sử dụng siêu dữ liệu từ Bản đồ thế giới về cấu trúc ngôn ngữ để lấy thông tin như gia đình ngôn ngữ (ví dụ: Ấn-Âu, Trung-Tạng).[7]
Lưu ý rằng các phân tích sau đây trong bài viết này ủng hộ các giả định của Wikipedia, The World Atlas of Language Structures và bởi bộ dữ liệu MASSIVE của Amazon. Vì tôi không phải là một chuyên gia ngôn ngữ học, nên tôi phải giả định rằng bất cứ điều gì trên Wikipedia và World Atlas đều được chấp nhận theo quy tắc là chính xác liên quan đến khu vực địa lý hoặc họ ngôn ngữ chiếm ưu thế.
Ngoài ra, có những cuộc tranh luận về những gì tạo nên một ngôn ngữ so với một phương ngữ. Ví dụ, trong khi các ngôn ngữ như tiếng Trung Quốc và tiếng Ả Rập có các hình thức khác nhau mà mọi người có thể không hiểu, chúng vẫn được gọi là ngôn ngữ đơn lẻ. Mặt khác, tiếng Hindi và tiếng Urdu rất giống nhau và đôi khi được nhóm lại thành một ngôn ngữ gọi là tiếng Hindustani. Vì những thách thức này, chúng ta cần phải cẩn thận khi quyết định điều gì được coi là ngôn ngữ hoặc phương ngữ.
Phân tích theo ngôn ngữ. Tôi đã chọn 12 ngôn ngữ được nói nhiều nhất (sự kết hợp của cả người nói ngôn ngữ thứ nhất và ngôn ngữ thứ hai).
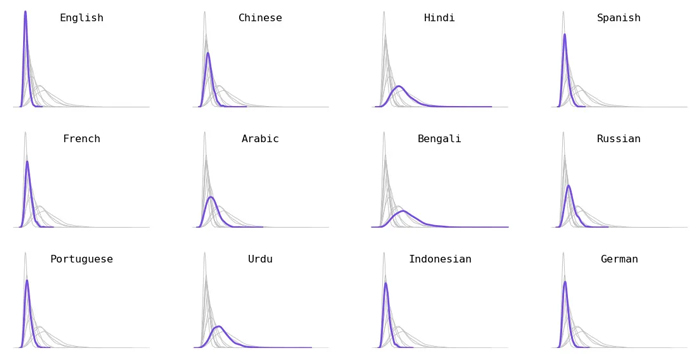
Phân loại theo họ ngôn ngữ. Ngôn ngữ Ấn-Âu (ví dụ: tiếng Thụy Điển, tiếng Pháp), ngôn ngữ Nam Đảo (ví dụ: tiếng Indonesia, tiếng Tagalog) và ngôn ngữ Uralic (ví dụ: tiếng Hungary, tiếng Phần Lan) dẫn đến các mã thông báo ngắn hơn. Các ngôn ngữ Dravidian (ví dụ như tiếng Tamil, tiếng Kannada) có xu hướng có các mã thông báo dài hơn.

Phân tích theo khu vực địa lý chính. Không phải tất cả các ngôn ngữ đều dành riêng cho một khu vực địa lý (chẳng hạn như tiếng Ả Rập, tiếng Anh và tiếng Tây Ban Nha, trải rộng trên nhiều khu vực) — những ngôn ngữ này đã bị xóa khỏi phần này. Các ngôn ngữ được nói chủ yếu ở châu Âu có xu hướng ngắn hơn về độ dài mã thông báo, trong khi các ngôn ngữ được nói chủ yếu ở Trung Đông, Trung Á và Sừng châu Phi có xu hướng dài hơn về độ dài mã thông báo.

Sự cố bằng cách viết kịch bản. Ngoài bảng chữ cái Latinh, Ả Rập và Cyrillic, tất cả các ngôn ngữ khác đều sử dụng hệ thống chữ viết độc đáo của riêng chúng. Mặc dù cái sau kết hợp nhiều chữ viết độc đáo rất khác nhau (chẳng hạn như chữ viết tiếng Hàn, tiếng Do Thái và tiếng Gruzia), những chữ viết duy nhất này chắc chắn mã hóa thành các giá trị dài hơn. So với các tập lệnh dựa trên tiếng Latinh, vốn mã hóa thành các giá trị ngắn hơn.

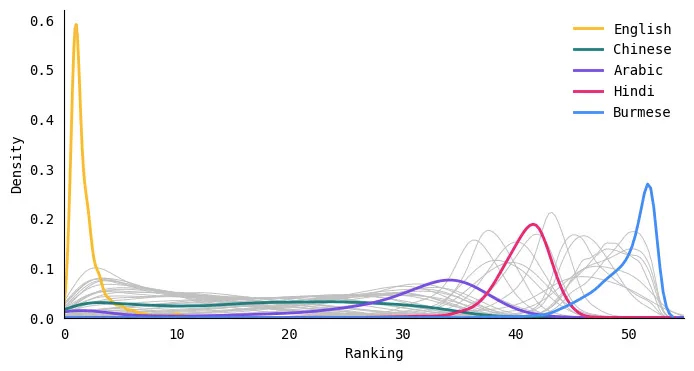
Tiếng Anh hầu như luôn đứng số 1
Đối với mỗi văn bản trong tập dữ liệu, tôi đã xếp hạng tất cả các ngôn ngữ dựa trên số lượng mã thông báo — ngôn ngữ có ít mã thông báo nhất được xếp hạng #1 và ngôn ngữ có nhiều mã thông báo nhất được xếp hạng #52. Sau đó, tôi vẽ biểu đồ phân phối của từng ngôn ngữ xếp hạng. Về cơ bản, điều này sẽ cho thấy độ dài mã thông báo của mỗi ngôn ngữ so với các ngôn ngữ khác trong bộ dữ liệu này như thế nào. Trong hình bên dưới, tôi đã gắn nhãn một số ngôn ngữ (các ngôn ngữ khác hiển thị dưới dạng các đường màu xám ở nền).
Mặc dù có một số trường hợp mã thông báo của một số ngôn ngữ ít hơn tiếng Anh (chẳng hạn như một số ví dụ bằng tiếng Indonesia hoặc tiếng Na Uy), tiếng Anh hầu như luôn xếp hạng nhất. Điều này có gây ngạc nhiên cho bất kỳ ai không? Điều làm tôi ngạc nhiên nhất là không có #2 hay #3 rõ ràng. Các văn bản tiếng Anh luôn tạo ra các mã thông báo ngắn nhất và xếp hạng dao động nhiều hơn một chút đối với các ngôn ngữ khác.
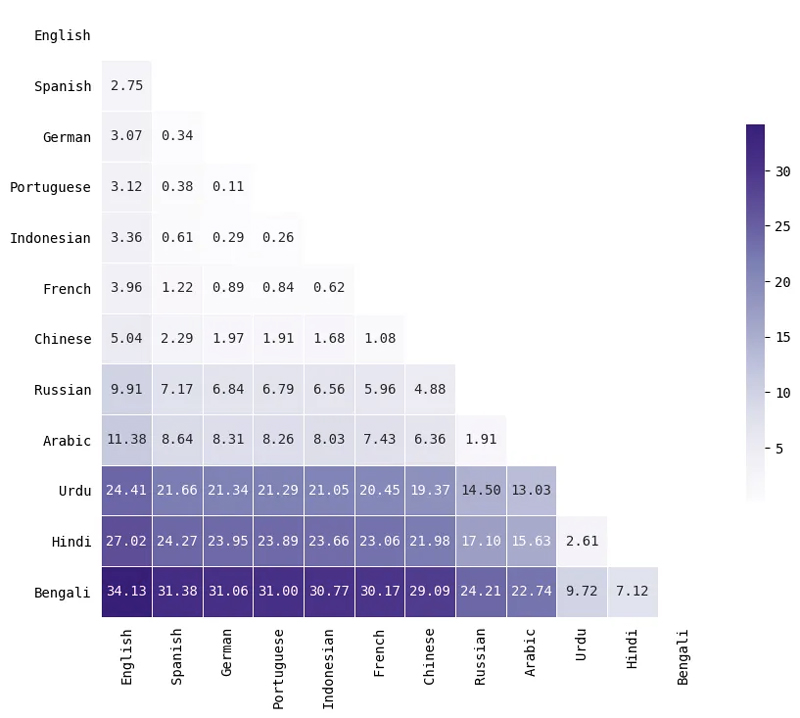
Định lượng sự khác biệt về phân phối mã thông báo bằng Khoảng cách của Earth Mover
Để định lượng mức độ khác nhau của phân phối độ dài mã thông báo giữa hai ngôn ngữ, tôi đã tính khoảng cách của máy bay trái đất (còn được gọi là khoảng cách Wasserstein) giữa hai bản phân phối. Về cơ bản, số liệu này tính toán lượng “công việc” tối thiểu cần thiết để chuyển đổi một bản phân phối này sang một bản phân phối khác. Các giá trị lớn hơn có nghĩa là các bản phân phối cách xa nhau hơn (khác nhau hơn) trong khi các giá trị nhỏ hơn có nghĩa là các bản phân phối khá giống nhau.
Đây là một tập hợp con nhỏ của các ngôn ngữ. Lưu ý rằng khoảng cách không nói lên điều gì về độ dài của mã thông báo, chỉ là mức độ phân phối độ dài mã thông báo giống nhau như thế nào đối với hai ngôn ngữ. Ví dụ, tiếng Ả Rập và tiếng Nga có sự phân bố tương tự mặc dù bản thân các ngôn ngữ này không giống nhau về mặt ngôn ngữ học.
1. MởAI. “Người mẫu”. API OpenAI. Lưu trữ từ bản gốc ngày 17 tháng 2023 năm 18. Truy cập ngày 2023 tháng XNUMX năm XNUMX.
2. Sebastian Ruder, Ivan Vulić và Anders Søgaard. 2022. Xu hướng Square One trong NLP: Hướng tới khám phá đa chiều của đa dạng nghiên cứu. Trong Kết quả của Hiệp hội Ngôn ngữ học Máy tính: ACL 2022, trang 2340–2354, Dublin, Ireland. Hiệp hội Ngôn ngữ học tính toán.
3. Shijie Wu và Mark Dredze. 2020. Tất cả các ngôn ngữ có được tạo ra bình đẳng trong BERT đa ngôn ngữ không?. Trong Kỷ yếu Hội thảo lần thứ 5 về Học đại diện cho NLP, trang 120–130, Trực tuyến. Hiệp hội Ngôn ngữ học tính toán.
4. Thống kê sử dụng ngôn ngữ nội dung cho các trang web”. Lưu trữ từ bản gốc vào ngày 30 tháng 2023 năm XNUMX.
5. Brown, Tom, et al. “Các mô hình ngôn ngữ là những người học vài lần.” Những tiến bộ trong hệ thống xử lý thông tin thần kinh 33 (2020): 1877 tầm 1901.
6. Kim Tử. Vương quốc nhân vật: Cuộc cách mạng ngôn ngữ đã làm cho Trung Quốc hiện đại. New York: Riverhead Books, 2022 (trang 124).
7. Máy sấy, Matthew S. & Haspelmath, Martin (eds.) 2013. WALS Online (v2020.3) [Tập dữ liệu]. Zenodo. https://doi.org/10.5281/zenodo.7385533. Có sẵn trực tuyến tại https://wals.info, Truy cập vào ngày 2023–04–30.
Thưởng thức bài viết này? Đăng ký để cập nhật thêm nghiên cứu AI.
Chúng tôi sẽ cho bạn biết khi chúng tôi phát hành thêm các bài viết tóm tắt như thế này.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- EVM tài chính. Giao diện hợp nhất cho tài chính phi tập trung. Truy cập Tại đây.
- Tập đoàn truyền thông lượng tử. Khuếch đại IR/PR. Truy cập Tại đây.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- nguồn: https://www.topbots.com/all-languages-are-not-tokenized-equal/

