Các hồ dữ liệu do AWS cung cấp, được hỗ trợ bởi tính sẵn có chưa từng có của Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), có thể xử lý quy mô, tính linh hoạt và tính linh hoạt cần thiết để kết hợp các phương pháp phân tích và dữ liệu khác nhau. Khi các hồ dữ liệu tăng quy mô và hoàn thiện về mặt sử dụng, bạn có thể phải bỏ ra nhiều nỗ lực để giữ dữ liệu nhất quán với các sự kiện kinh doanh. Để đảm bảo các tệp được cập nhật theo cách nhất quán về mặt giao dịch, ngày càng nhiều khách hàng đang sử dụng các định dạng bảng giao dịch nguồn mở như tảng băng Apache, Apache Hudivà Quỹ Linux Hồ Delta giúp bạn lưu trữ dữ liệu với tốc độ nén cao, giao tiếp nguyên bản với các ứng dụng và khung của bạn, đồng thời đơn giản hóa quá trình xử lý dữ liệu gia tăng trong hồ dữ liệu được xây dựng trên Amazon S3. Các định dạng này cho phép các giao dịch ACID (tính nguyên tử, tính nhất quán, sự cô lập, độ bền), nâng cấp và xóa cũng như các tính năng nâng cao như du hành thời gian và ảnh chụp nhanh mà trước đây chỉ có trong kho dữ liệu. Mỗi định dạng lưu trữ triển khai chức năng này theo những cách hơi khác nhau; để so sánh, hãy tham khảo Chọn định dạng bảng mở cho hồ dữ liệu giao dịch của bạn trên AWS.
Trong 2023, AWS đã công bố tính khả dụng rộng rãi cho Apache Iceberg, Apache Hudi và Linux Foundation Delta Lake ở Amazon Athena cho Apache Spark, giúp loại bỏ nhu cầu cài đặt một trình kết nối riêng biệt hoặc các phần phụ thuộc liên quan cũng như quản lý các phiên bản, đồng thời đơn giản hóa các bước cấu hình cần thiết để sử dụng các khung này.
Trong bài đăng này, chúng tôi chỉ cho bạn cách sử dụng Spark SQL trong amazon Athena sổ ghi chép và làm việc với các định dạng bảng Iceberg, Hudi và Delta Lake. Chúng tôi trình bày các thao tác phổ biến như tạo cơ sở dữ liệu và bảng, chèn dữ liệu vào bảng, truy vấn dữ liệu và xem ảnh chụp nhanh của bảng trong Amazon S3 bằng Spark SQL trong Athena.
Điều kiện tiên quyết
Hoàn thành các điều kiện tiên quyết sau:
Tải xuống và nhập sổ tay mẫu từ Amazon S3
Để theo dõi, hãy tải xuống sổ ghi chép được thảo luận trong bài đăng này từ các vị trí sau:
Sau khi bạn tải sổ ghi chép xuống, hãy nhập chúng vào môi trường Athena Spark của bạn bằng cách làm theo Để nhập sổ ghi chép phần trong Quản lý tập tin sổ ghi chép.
Điều hướng đến phần Định dạng bảng mở cụ thể
Nếu bạn quan tâm đến định dạng bảng Iceberg, hãy điều hướng đến Làm việc với các bảng Apache Iceberg phần.
Nếu bạn quan tâm đến định dạng bảng Hudi, hãy điều hướng đến Làm việc với các bảng Apache Hudi phần.
Nếu bạn quan tâm đến định dạng bảng Delta Lake, hãy điều hướng đến Làm việc với các bảng Delta Lake trên nền tảng Linux phần.
Làm việc với các bảng Apache Iceberg
Khi sử dụng sổ ghi chép Spark trong Athena, bạn có thể chạy truy vấn SQL trực tiếp mà không cần phải sử dụng PySpark. Chúng tôi thực hiện điều này bằng cách sử dụng phép thuật ô, là các tiêu đề đặc biệt trong ô sổ ghi chép giúp thay đổi hành vi của ô. Đối với SQL, chúng ta có thể thêm %%sql magic, sẽ diễn giải toàn bộ nội dung ô dưới dạng câu lệnh SQL để chạy trên Athena.
Trong phần này, chúng tôi trình bày cách bạn có thể sử dụng SQL trên Apache Spark cho Athena để tạo, phân tích và quản lý các bảng Apache Iceberg.
Thiết lập phiên ghi chép
Để sử dụng Apache Iceberg trong Athena, trong khi tạo hoặc chỉnh sửa phiên, hãy chọn tảng băng Apache tùy chọn bằng cách mở rộng Thuộc tính Spark của Apache phần. Nó sẽ điền trước các thuộc tính như trong ảnh chụp màn hình sau.
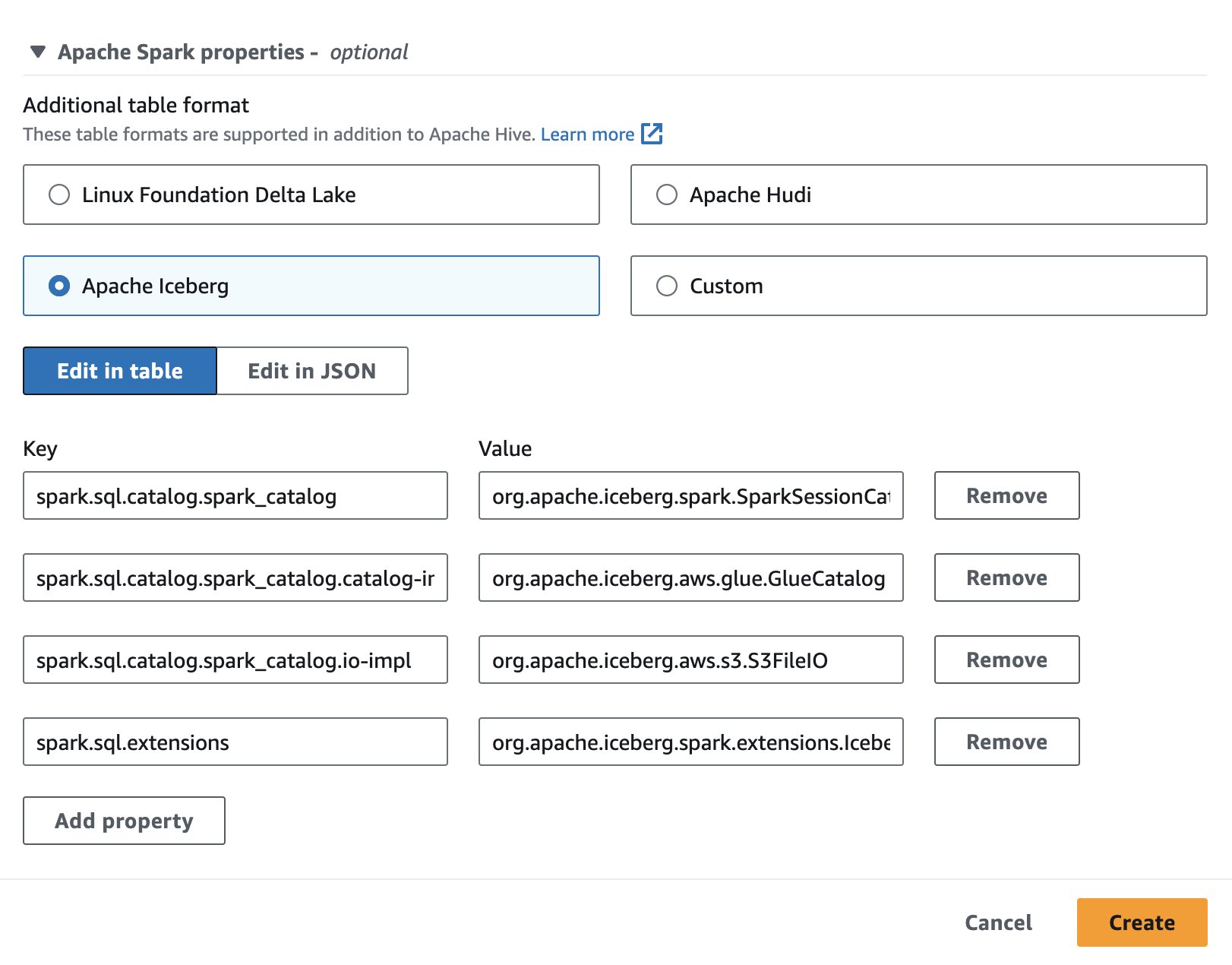
Để biết các bước, hãy xem Chỉnh sửa chi tiết phiên or Tạo sổ ghi chép của riêng bạn.
Mã được sử dụng trong phần này có sẵn trong SparkSQL_iceberg.ipynb tập tin để làm theo.
Tạo cơ sở dữ liệu và bảng Iceberg
Đầu tiên, chúng tôi tạo cơ sở dữ liệu trong Danh mục dữ liệu AWS Glue. Với câu lệnh SQL sau, chúng ta có thể tạo một cơ sở dữ liệu có tên icebergdb:
Tiếp theo, trong cơ sở dữ liệu icebergdb, chúng tôi tạo một bảng Iceberg có tên noaa_iceberg trỏ đến một vị trí trong Amazon S3 nơi chúng tôi sẽ tải dữ liệu. Chạy câu lệnh sau và thay thế vị trí s3://<your-S3-bucket>/<prefix>/ với nhóm S3 và tiền tố của bạn:
Chèn dữ liệu vào bảng
Để điền vào noaa_iceberg Bảng Iceberg, chúng tôi chèn dữ liệu từ bảng Parquet sparkblogdb.noaa_pq được tạo ra như một phần của điều kiện tiên quyết. Bạn có thể làm điều này bằng cách sử dụng một CHÈN VÀO tuyên bố trong Spark:
Ngoài ra, bạn có thể sử dụng TẠO BẢNG NHƯ CHỌN với mệnh đề USING Iceberg để tạo bảng Iceberg và chèn dữ liệu từ bảng nguồn trong một bước:
Truy vấn bảng Iceberg
Bây giờ dữ liệu đã được chèn vào bảng Iceberg, chúng ta có thể bắt đầu phân tích nó. Hãy chạy Spark SQL để tìm nhiệt độ tối thiểu được ghi lại theo năm cho 'SEATTLE TACOMA AIRPORT, WA US' vị trí:
Chúng tôi nhận được đầu ra sau đây.

Cập nhật dữ liệu vào bảng Iceberg
Hãy xem cách cập nhật dữ liệu trong bảng của chúng tôi. Chúng tôi muốn cập nhật tên trạm 'SEATTLE TACOMA AIRPORT, WA US' đến 'Sea-Tac'. Sử dụng Spark SQL, chúng ta có thể chạy một CẬP NHẬT tuyên bố chống lại bảng Iceberg:
Sau đó chúng ta có thể chạy truy vấn SELECT trước đó để tìm nhiệt độ tối thiểu được ghi lại cho 'Sea-Tac' vị trí:
Chúng tôi nhận được kết quả sau.

Tệp dữ liệu nhỏ gọn
Các định dạng bảng mở như Iceberg hoạt động bằng cách tạo các thay đổi delta trong bộ lưu trữ tệp và theo dõi phiên bản của các hàng thông qua tệp kê khai. Nhiều tệp dữ liệu hơn dẫn đến nhiều siêu dữ liệu được lưu trữ trong tệp kê khai hơn và các tệp dữ liệu nhỏ thường tạo ra lượng siêu dữ liệu không cần thiết, dẫn đến các truy vấn kém hiệu quả hơn và chi phí truy cập Amazon S3 cao hơn. Chạy tảng băng trôi rewrite_data_files quy trình trong Spark cho Athena sẽ thu gọn các tệp dữ liệu, kết hợp nhiều tệp thay đổi delta nhỏ thành một tập hợp nhỏ hơn các tệp Parquet được tối ưu hóa để đọc. Việc nén tệp sẽ tăng tốc thao tác đọc khi được truy vấn. Để chạy nén trên bảng của chúng tôi, hãy chạy Spark SQL sau:
rewrite_data_files cung cấp các tùy chọn để chỉ định chiến lược sắp xếp của bạn, điều này có thể giúp sắp xếp lại và thu gọn dữ liệu.
Liệt kê ảnh chụp nhanh bảng
Mỗi thao tác ghi, cập nhật, xóa, nâng cấp và nén trên bảng Iceberg sẽ tạo ra một ảnh chụp nhanh mới của bảng trong khi vẫn giữ dữ liệu và siêu dữ liệu cũ để cách ly ảnh chụp nhanh và du hành thời gian. Để liệt kê các ảnh chụp nhanh của bảng Iceberg, hãy chạy câu lệnh Spark SQL sau:
Ảnh chụp nhanh cũ hết hạn
Bạn nên thường xuyên sử dụng các ảnh chụp nhanh hết hạn để xóa các tệp dữ liệu không còn cần thiết nữa và để giữ kích thước của siêu dữ liệu bảng ở mức nhỏ. Nó sẽ không bao giờ xóa các tập tin vẫn được yêu cầu bởi một ảnh chụp nhanh chưa hết hạn. Trong Spark cho Athena, hãy chạy câu SQL sau để hết hạn ảnh chụp nhanh cho bảng icebergdb.noaa_iceberg cũ hơn một dấu thời gian cụ thể:
Lưu ý rằng giá trị dấu thời gian được chỉ định dưới dạng một chuỗi có định dạng yyyy-MM-dd HH:mm:ss.fff. Đầu ra sẽ đưa ra số lượng tệp dữ liệu và siêu dữ liệu đã bị xóa.
Bỏ bảng và cơ sở dữ liệu
Bạn có thể chạy Spark SQL sau để dọn sạch bảng Iceberg và dữ liệu liên quan trong Amazon S3 từ bài tập này:
Chạy Spark SQL sau để xóa cơ sở dữ liệu Icebergdb:
Để tìm hiểu thêm về tất cả các thao tác bạn có thể thực hiện trên bảng Iceberg bằng Spark cho Athena, hãy tham khảo Truy vấn Spark và Thủ tục Spark trong tài liệu Iceberg.
Làm việc với các bảng Apache Hudi
Tiếp theo, chúng tôi trình bày cách bạn có thể sử dụng SQL trên Spark cho Athena để tạo, phân tích và quản lý các bảng Apache Hudi.
Thiết lập phiên ghi chép
Để sử dụng Apache Hudi trong Athena, trong khi tạo hoặc chỉnh sửa phiên, hãy chọn Apache Hudi tùy chọn bằng cách mở rộng Thuộc tính Spark của Apache phần.
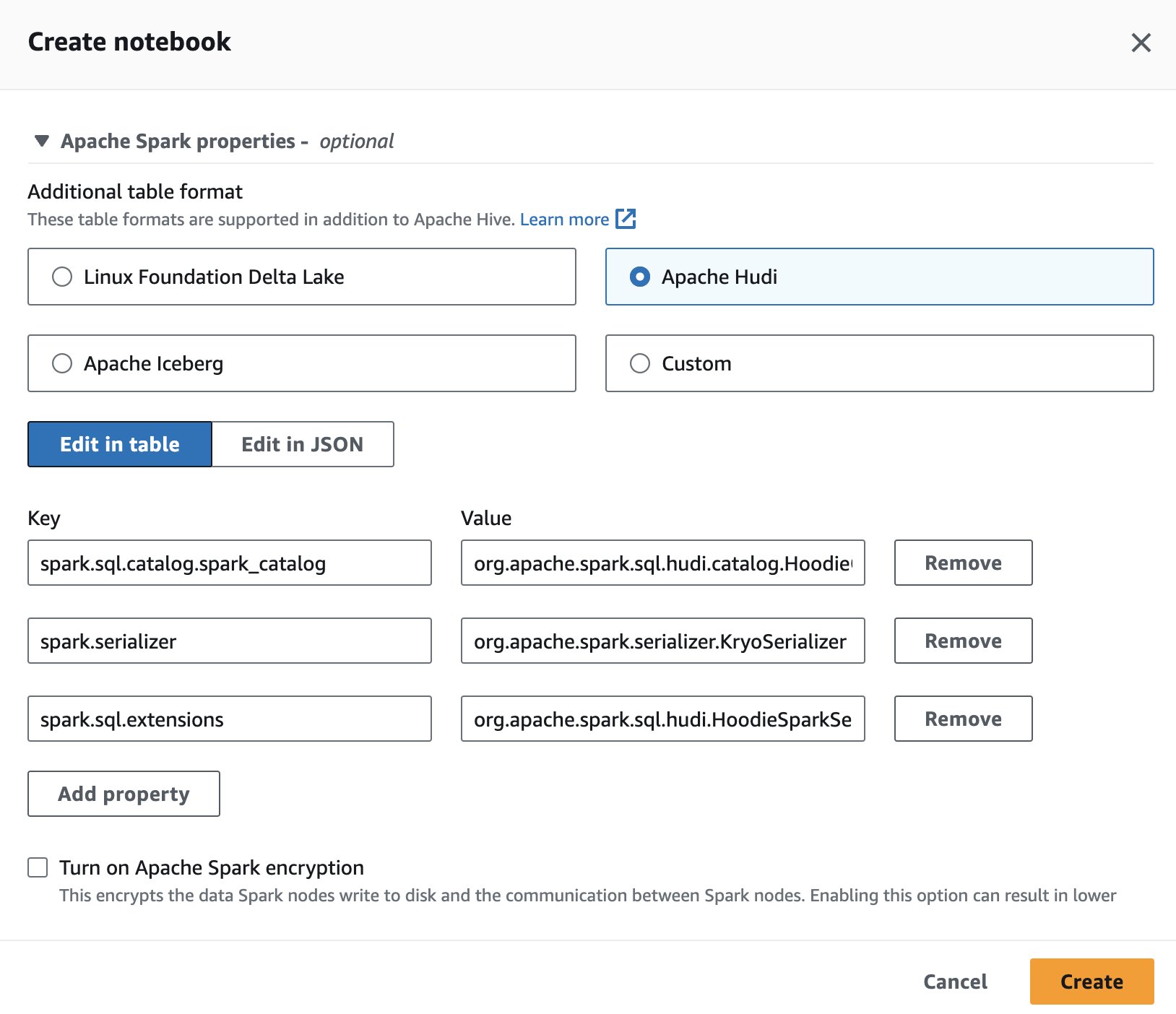
Để biết các bước, hãy xem Chỉnh sửa chi tiết phiên or Tạo sổ ghi chép của riêng bạn.
Mã được sử dụng trong phần này phải có sẵn trong SparkSQL_hudi.ipynb tập tin để làm theo.
Tạo cơ sở dữ liệu và bảng Hudi
Đầu tiên, chúng ta tạo một cơ sở dữ liệu có tên hudidb sẽ được lưu trữ trong Danh mục dữ liệu AWS Glue, sau đó tạo bảng Hudi:
Chúng tôi tạo bảng Hudi trỏ đến một vị trí trong Amazon S3 nơi chúng tôi sẽ tải dữ liệu. Lưu ý rằng bảng là của sao chép trên ghi kiểu. Nó được xác định bởi type= 'cow' trong bảng DDL. Chúng tôi đã xác định trạm và ngày là nhiều khóa chính và preCombinedField là năm. Ngoài ra, bảng được phân vùng theo năm. Chạy câu lệnh sau và thay thế vị trí s3://<your-S3-bucket>/<prefix>/ với nhóm S3 và tiền tố của bạn:
Chèn dữ liệu vào bảng
Giống như Iceberg, chúng tôi sử dụng CHÈN VÀO câu lệnh để điền vào bảng bằng cách đọc dữ liệu từ sparkblogdb.noaa_pq bảng đã tạo ở bài trước:
Truy vấn bảng Hudi
Bây giờ bảng đã được tạo, hãy chạy truy vấn để tìm nhiệt độ tối đa được ghi lại cho 'SEATTLE TACOMA AIRPORT, WA US' vị trí:
Cập nhật dữ liệu vào bảng Hudi
Hãy thay đổi tên trạm 'SEATTLE TACOMA AIRPORT, WA US' đến 'Sea–Tac'. Chúng tôi có thể chạy câu lệnh CẬP NHẬT trên Spark cho Athena để cập nhật các hồ sơ của noaa_hudi bàn:
Chúng tôi chạy truy vấn CHỌN trước đó để tìm nhiệt độ được ghi tối đa cho 'Sea-Tac' vị trí:
Chạy truy vấn du hành thời gian
Chúng ta có thể sử dụng truy vấn du hành thời gian trong SQL trên Athena để phân tích ảnh chụp nhanh dữ liệu trong quá khứ. Ví dụ:
Truy vấn này kiểm tra dữ liệu nhiệt độ của Sân bay Seattle tại một thời điểm cụ thể trong quá khứ. Mệnh đề dấu thời gian cho phép chúng ta quay trở lại mà không thay đổi dữ liệu hiện tại. Lưu ý rằng giá trị dấu thời gian được chỉ định dưới dạng một chuỗi có định dạng yyyy-MM-dd HH:mm:ss.fff.
Tối ưu hóa tốc độ truy vấn với phân cụm
Để cải thiện hiệu suất truy vấn, bạn có thể thực hiện tập hợp trên các bảng Hudi sử dụng SQL trong Spark cho Athena:
Bàn nhỏ gọn
Nén là một dịch vụ bảng được Hudi sử dụng cụ thể trong các bảng Hợp nhất khi đọc (MOR) để hợp nhất các bản cập nhật từ tệp nhật ký dựa trên hàng sang tệp cơ sở dựa trên cột tương ứng theo định kỳ để tạo ra phiên bản mới của tệp cơ sở. Việc nén không áp dụng được cho các bảng Copy On Write (COW) và chỉ áp dụng cho các bảng MOR. Bạn có thể chạy truy vấn sau trong Spark cho Athena để thực hiện nén trên các bảng MOR:
Bỏ bảng và cơ sở dữ liệu
Chạy Spark SQL sau để xóa bảng Hudi mà bạn đã tạo và dữ liệu liên kết khỏi vị trí Amazon S3:
Chạy Spark SQL sau để xóa cơ sở dữ liệu hudidb:
Để tìm hiểu về tất cả các thao tác bạn có thể thực hiện trên bảng Hudi bằng Spark cho Athena, hãy tham khảo SQL DDL và Thủ tục trong tài liệu Hudi.
Làm việc với các bảng Delta Lake trên nền tảng Linux
Tiếp theo, chúng tôi trình bày cách bạn có thể sử dụng SQL trên Spark cho Athena để tạo, phân tích và quản lý các bảng Delta Lake.
Thiết lập phiên ghi chép
Để sử dụng Delta Lake trong Spark cho Athena, trong khi tạo hoặc chỉnh sửa phiên, hãy chọn Quỹ Linux Hồ Delta bằng cách mở rộng Thuộc tính Spark của Apache phần.

Để biết các bước, hãy xem Chỉnh sửa chi tiết phiên or Tạo sổ ghi chép của riêng bạn.
Mã được sử dụng trong phần này phải có sẵn trong SparkSQL_delta.ipynb tập tin để làm theo.
Tạo cơ sở dữ liệu và bảng Delta Lake
Trong phần này, chúng ta tạo cơ sở dữ liệu trong Danh mục dữ liệu AWS Glue. Sử dụng SQL sau, chúng ta có thể tạo một cơ sở dữ liệu có tên deltalakedb:
Tiếp theo, trong cơ sở dữ liệu deltalakedb, chúng ta tạo một bảng Delta Lake có tên noaa_delta trỏ đến một vị trí trong Amazon S3 nơi chúng tôi sẽ tải dữ liệu. Chạy câu lệnh sau và thay thế vị trí s3://<your-S3-bucket>/<prefix>/ với nhóm S3 và tiền tố của bạn:
Chèn dữ liệu vào bảng
Chúng tôi sử dụng một CHÈN VÀO câu lệnh để điền vào bảng bằng cách đọc dữ liệu từ sparkblogdb.noaa_pq bảng đã tạo ở bài trước:
Bạn cũng có thể sử dụng CREATE TABLE AS SELECT để tạo bảng Delta Lake và chèn dữ liệu từ bảng nguồn vào một truy vấn.
Truy vấn bảng Delta Lake
Bây giờ dữ liệu đã được chèn vào bảng Delta Lake, chúng ta có thể bắt đầu phân tích dữ liệu đó. Hãy chạy Spark SQL để tìm nhiệt độ tối thiểu được ghi cho 'SEATTLE TACOMA AIRPORT, WA US' vị trí:
Cập nhật dữ liệu vào bảng Delta lake
Hãy thay đổi tên trạm 'SEATTLE TACOMA AIRPORT, WA US' đến 'Sea–Tac'. Chúng ta có thể chạy một CẬP NHẬT tuyên bố về Spark cho Athena để cập nhật hồ sơ của noaa_delta bàn:
Chúng ta có thể chạy truy vấn SELECT trước đó để tìm nhiệt độ tối thiểu được ghi lại cho 'Sea-Tac' location và kết quả sẽ giống như trước đó:
Tệp dữ liệu nhỏ gọn
Trong Spark cho Athena, bạn có thể chạy OPTIMIZE trên bảng Delta Lake, thao tác này sẽ nén các tệp nhỏ thành các tệp lớn hơn để các truy vấn không bị gánh nặng bởi chi phí tệp nhỏ. Để thực hiện thao tác nén, hãy chạy truy vấn sau:
Tham khảo Tối ưu hóa trong tài liệu của Delta Lake để biết các tùy chọn khác nhau có sẵn khi chạy OPTIMIZE.
Xóa các tệp không còn được tham chiếu bởi bảng Delta Lake
Bạn có thể xóa các tệp được lưu trữ trong Amazon S3 không còn được tham chiếu bởi bảng Delta Lake và cũ hơn ngưỡng lưu giữ bằng cách chạy lệnh VACCUM trên bảng bằng Spark cho Athena:
Tham khảo Xóa các tệp không còn được tham chiếu bởi bảng Delta trong tài liệu của Delta Lake để biết các tùy chọn có sẵn với VACUUM.
Bỏ bảng và cơ sở dữ liệu
Chạy Spark SQL sau để xóa bảng Delta Lake mà bạn đã tạo:
Chạy Spark SQL sau để xóa cơ sở dữ liệu deltalakedb:
Việc chạy DROP TABLE DDL trên bảng và cơ sở dữ liệu Delta Lake sẽ xóa siêu dữ liệu cho các đối tượng này nhưng không tự động xóa các tệp dữ liệu trong Amazon S3. Bạn có thể chạy mã Python sau trong ô của sổ ghi chép để xóa dữ liệu khỏi vị trí S3:
Để tìm hiểu thêm về các câu lệnh SQL mà bạn có thể chạy trên bảng Delta Lake bằng Spark cho Athena, hãy tham khảo phần quickstart trong tài liệu của Delta Lake.
Kết luận
Bài đăng này đã trình bày cách sử dụng Spark SQL trong sổ ghi chép Athena để tạo cơ sở dữ liệu và bảng, chèn và truy vấn dữ liệu cũng như thực hiện các thao tác phổ biến như cập nhật, nén và du hành thời gian trên các bảng Hudi, Delta Lake và Iceberg. Các định dạng bảng mở thêm các giao dịch ACID, cập nhật và xóa vào hồ dữ liệu, khắc phục các hạn chế về lưu trữ đối tượng thô. Bằng cách loại bỏ nhu cầu cài đặt các trình kết nối riêng biệt, tính năng tích hợp tích hợp của Spark trên Athena giúp giảm các bước cấu hình và chi phí quản lý khi sử dụng các khung phổ biến này để xây dựng các hồ dữ liệu đáng tin cậy trên Amazon S3. Để tìm hiểu thêm về cách chọn định dạng bảng mở cho khối lượng công việc hồ dữ liệu của bạn, hãy tham khảo Chọn định dạng bảng mở cho hồ dữ liệu giao dịch của bạn trên AWS.
Về các tác giả
![]() Pathik Shah là Kiến trúc sư phân tích cấp cao trên Amazon Athena. Anh gia nhập AWS vào năm 2015 và kể từ đó tập trung vào lĩnh vực phân tích dữ liệu lớn, giúp khách hàng xây dựng các giải pháp mạnh mẽ và có thể mở rộng bằng dịch vụ phân tích AWS.
Pathik Shah là Kiến trúc sư phân tích cấp cao trên Amazon Athena. Anh gia nhập AWS vào năm 2015 và kể từ đó tập trung vào lĩnh vực phân tích dữ liệu lớn, giúp khách hàng xây dựng các giải pháp mạnh mẽ và có thể mở rộng bằng dịch vụ phân tích AWS.
![]() Raj Devath là Giám đốc sản phẩm tại AWS trên Amazon Athena. Anh ấy đam mê xây dựng những sản phẩm được khách hàng yêu thích và giúp khách hàng khai thác giá trị từ dữ liệu của họ. Nền tảng của ông là cung cấp các giải pháp cho nhiều thị trường cuối cùng, chẳng hạn như tài chính, bán lẻ, tòa nhà thông minh, tự động hóa gia đình và hệ thống truyền thông dữ liệu.
Raj Devath là Giám đốc sản phẩm tại AWS trên Amazon Athena. Anh ấy đam mê xây dựng những sản phẩm được khách hàng yêu thích và giúp khách hàng khai thác giá trị từ dữ liệu của họ. Nền tảng của ông là cung cấp các giải pháp cho nhiều thị trường cuối cùng, chẳng hạn như tài chính, bán lẻ, tòa nhà thông minh, tự động hóa gia đình và hệ thống truyền thông dữ liệu.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/

