Amazon EMR không có máy chủ cung cấp môi trường thời gian chạy không có máy chủ giúp đơn giản hóa hoạt động của các ứng dụng phân tích sử dụng các khung nguồn mở mới nhất, chẳng hạn như Apache Spark và Apache Hive. Với EMR Serverless, bạn không phải định cấu hình, tối ưu hóa, bảo mật hoặc vận hành các cụm để chạy ứng dụng với các khung này. Bạn có thể chạy khối lượng công việc phân tích ở bất kỳ quy mô nào với tính năng tự động điều chỉnh quy mô giúp thay đổi kích thước tài nguyên trong vài giây để đáp ứng các yêu cầu xử lý và khối lượng dữ liệu luôn thay đổi. EMR Serverless tự động tăng giảm quy mô tài nguyên để cung cấp lượng dung lượng phù hợp cho ứng dụng của bạn và bạn chỉ trả tiền cho những gì mình sử dụng.
Chức năng bước AWS là một dịch vụ điều phối phi máy chủ cho phép các nhà phát triển xây dựng quy trình làm việc trực quan cho các ứng dụng dưới dạng một loạt các bước theo sự kiện. Step Functions đảm bảo rằng các bước trong quy trình làm việc không có máy chủ được tuân thủ một cách đáng tin cậy, thông tin được truyền giữa các giai đoạn và lỗi được xử lý tự động.
Việc tích hợp giữa AWS Step Functions và Amazon EMR Serverless giúp quản lý và điều phối quy trình công việc dữ liệu lớn dễ dàng hơn. Trước khi tích hợp này, bạn phải thăm dò thủ công các trạng thái công việc hoặc triển khai cơ chế chờ thông qua lệnh gọi API. Giờ đây, với sự hỗ trợ tích hợp “Chạy công việc (.sync)”, bạn có thể quản lý các công việc EMR Serverless của mình hiệu quả hơn. Việc sử dụng .sync cho phép quy trình làm việc Step Functions của bạn chờ công việc EMR Serverless hoàn thành trước khi chuyển sang bước tiếp theo, biến việc thực thi công việc thành một phần của máy trạng thái một cách hiệu quả. Tương tự, mẫu “Phản hồi yêu cầu” có thể hữu ích để kích hoạt công việc và ngay lập tức nhận được phản hồi, tất cả đều nằm trong giới hạn của quy trình làm việc Step Functions của bạn. Sự tích hợp này giúp đơn giản hóa kiến trúc của bạn bằng cách loại bỏ nhu cầu thực hiện các bước bổ sung để theo dõi trạng thái công việc, giúp toàn bộ hệ thống hiệu quả hơn và dễ quản lý hơn.
Trong bài đăng này, chúng tôi giải thích cách bạn có thể sắp xếp ứng dụng PySpark bằng cách sử dụng Amazon EMR không có máy chủ và Chức năng bước AWS. Chúng tôi chạy một công việc Spark trên EMR Serverless để xử lý Tập dữ liệu Citi Bike dữ liệu trong một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) và lưu trữ kết quả tổng hợp trong Amazon S3.
Tổng quan về giải pháp
Chúng tôi chứng minh giải pháp này bằng một ví dụ sử dụng Tập dữ liệu Citi Bike. Tập dữ liệu này bao gồm nhiều thông số như loại Có thể đi được, trạm Xuất phát, Xuất phát tại, Trạm kết thúc, Kết thúc tại và nhiều yếu tố khác về hành trình của Citi Bikers. Mục tiêu của chúng tôi là tìm thời lượng chuyến đi xe đạp tối thiểu, tối đa và trung bình trong một tháng nhất định.
Trong giải pháp này, dữ liệu đầu vào được đọc từ đường dẫn đầu vào S3, các phép biến đổi và tổng hợp được áp dụng với mã PySpark và đầu ra tóm tắt được ghi vào đường dẫn đầu ra S3 s3://<bucket-name>/serverlessout/.
Giải pháp được thực hiện như sau:
- Tạo ứng dụng EMR Serverless với thời gian chạy Spark. Sau khi ứng dụng được tạo, bạn có thể gửi các công việc xử lý dữ liệu đến ứng dụng đó. Bước API này chờ quá trình tạo Ứng dụng hoàn tất.
- Gửi công việc PySpark và chờ hoàn thành với
StartJobRun(.sync) API. Điều này cho phép bạn gửi công việc tới ứng dụng Amazon EMR Serverless và đợi cho đến khi công việc hoàn thành. - Sau khi công việc PySpark hoàn thành, kết quả tóm tắt sẽ có trong thư mục đầu ra S3.
- Nếu công việc gặp lỗi, quy trình làm việc của máy trạng thái sẽ báo lỗi. Bạn có thể kiểm tra lỗi cụ thể trong máy trạng thái. Để phân tích chi tiết hơn, bạn cũng có thể kiểm tra nhật ký lỗi công việc EMR trong bảng điều khiển studio EMR.
Điều kiện tiên quyết
Trước khi bắt đầu, hãy đảm bảo bạn có các điều kiện tiên quyết sau:
- An Tài khoản AWS
- Người dùng IAM có quyền truy cập quản trị viên
- Một thùng S3
giải pháp xây dựng
Để tự động hóa toàn bộ quy trình, chúng tôi sử dụng kiến trúc sau, tích hợp Step Functions để điều phối và Amazon EMR Serverless để chuyển đổi dữ liệu. Sau đó, đầu ra tóm tắt sẽ được ghi vào bộ chứa Amazon S3.
Sơ đồ sau minh họa kiến trúc cho trường hợp sử dụng này

Các bước triển khai
Trước khi bắt đầu hướng dẫn này, hãy đảm bảo rằng vai trò đang được sử dụng để triển khai có tất cả các quyền liên quan để tạo các tài nguyên cần thiết như một phần của giải pháp. Các vai trò có quyền thích hợp sẽ được tạo thông qua mẫu CloudFormation bằng các bước sau.
Bước 1: Tạo máy trạng thái Step Functions
Bạn có thể tạo quy trình làm việc của Step Functions State Machine theo hai cách— trực tiếp qua mã hoặc thông qua giao diện đồ họa của Step Functions studio. Để tạo máy trạng thái, bạn có thể làm theo các bước từ tùy chọn 1 hoặc tùy chọn 2 bên dưới.
Cách 1: Tạo máy trạng thái thông qua code trực tiếp
Để tạo máy trạng thái Step Functions cùng với các vai trò IAM cần thiết, hãy hoàn thành các bước sau:
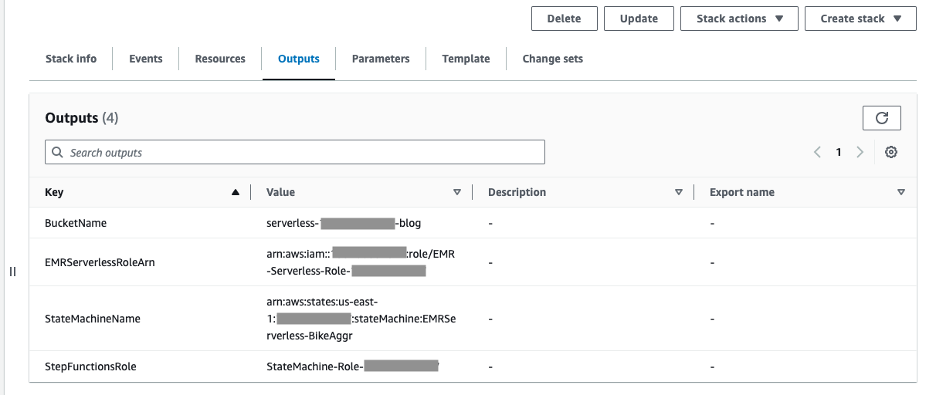
- Khởi chạy ngăn xếp CloudFormation bằng cách sử dụng cái này Link. Trên bảng điều khiển Cloud Formation, cung cấp tên ngăn xếp và chấp nhận các giá trị mặc định để tạo ngăn xếp. Một khi Sự hình thành mây quá trình triển khai hoàn tất, các tài nguyên sau sẽ được tạo, ngoài ra Vai trò liên kết dịch vụ EMR sẽ được ngăn xếp CloudFormation này tự động tạo để truy cập EMR Serverless:
- S3 để tải tập lệnh PySpark lên và ghi dữ liệu đầu ra từ công việc EMR Serverless. Chúng tôi khuyên bạn nên bật mã hóa mặc định trên bộ chứa S3 của mình để mã hóa các đối tượng mới, cũng như bật tính năng ghi nhật ký truy cập để ghi lại tất cả các yêu cầu được thực hiện cho bộ chứa. Việc làm theo những đề xuất này sẽ cải thiện tính bảo mật và cung cấp khả năng hiển thị quyền truy cập vào nhóm.
- Vai trò EMR Serverless Runtime cung cấp các quyền chi tiết cho các tài nguyên cụ thể được yêu cầu khi các công việc EMR Serverless chạy.
- Vai trò Step Functions để cấp quyền cho AWS Step Functions truy cập vào các tài nguyên AWS sẽ được sử dụng bởi các máy trạng thái của nó.
- Máy trạng thái với các bước EMR Serverless.
- Để chuẩn bị nhóm S3 có tập lệnh PySpark, hãy mở Đám mây AWS từ thanh công cụ ở góc trên bên phải của bảng điều khiển AWS và chạy lệnh AWS CLI sau trong CloudShell (đảm bảo thay thế < > bằng ID tài khoản AWS của bạn):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/bikeaggregator.py s3://serverless-<<ACCOUNT-ID>>-blog/scripts/
![]()

- Để chuẩn bị vùng lưu trữ S3 với Dữ liệu đầu vào, hãy chạy lệnh AWS CLI sau trong CloudShell (đảm bảo thay thế < > bằng ID tài khoản AWS của bạn):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/201306-citibike-tripdata.csv s3://serverless-<<ACCOUNT-ID>>-blog/data/ --copy-props none

Tùy chọn 2: Tạo máy trạng thái Step Functions thông qua Workflow Studio
Điều kiện tiên quyết
Trước khi tạo Máy trạng thái thông qua Workshop Studio, vui lòng đảm bảo rằng tất cả các vai trò và tài nguyên liên quan đều được tạo như một phần của giải pháp.
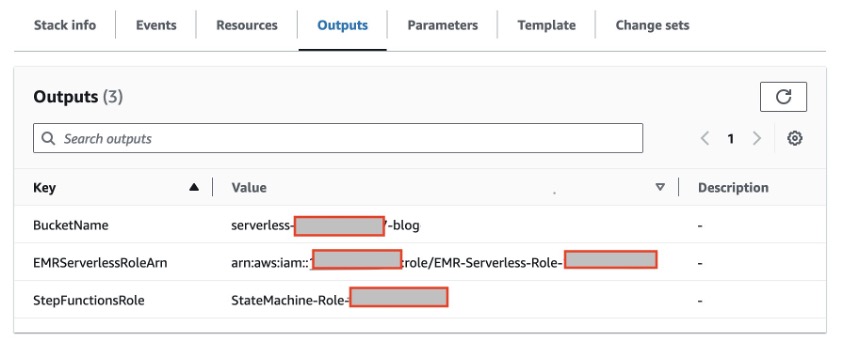
- Để triển khai các vai trò IAM và nhóm S3 cần thiết vào tài khoản AWS của bạn, hãy khởi chạy ngăn xếp CloudFormation bằng cách sử dụng Link. Một khi Sự hình thành mây quá trình triển khai hoàn tất, các tài nguyên sau sẽ được tạo:
- Nhóm S3 để tải lên tập lệnh PySpark và ghi dữ liệu đầu ra. Chúng tôi khuyên bạn nên bật mã hóa mặc định trên bộ chứa S3 của mình để mã hóa các đối tượng mới, cũng như bật tính năng ghi nhật ký truy cập để ghi lại tất cả các yêu cầu được thực hiện cho bộ chứa. Việc làm theo những đề xuất này sẽ cải thiện tính bảo mật và cung cấp khả năng hiển thị quyền truy cập vào nhóm.
- Vai trò EMR Serverless Runtime cung cấp các quyền chi tiết cho các tài nguyên cụ thể được yêu cầu khi các công việc EMR Serverless chạy.
- Vai trò Step Functions để cấp quyền cho AWS Step Functions truy cập vào các tài nguyên AWS sẽ được sử dụng bởi các máy trạng thái của nó.
- Để chuẩn bị nhóm S3 có tập lệnh PySpark, hãy mở Đám mây AWS từ thanh công cụ ở trên cùng bên phải của bảng điều khiển AWS và chạy lệnh AWS CLI sau trong CloudShell (đảm bảo thay thế < > bằng ID tài khoản AWS của bạn):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/bikeaggregator.py s3://serverless-<<ACCOUNT-ID>>-blog/scripts/
![]()

- Để chuẩn bị vùng lưu trữ S3 với Dữ liệu đầu vào, hãy chạy lệnh AWS CLI sau trong CloudShell (đảm bảo thay thế < > bằng ID tài khoản AWS của bạn):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/201306-citibike-tripdata.csv s3://serverless-<<ACCOUNT-ID>>-blog/data/ --copy-props none

Để tạo máy trạng thái Step Functions, hãy hoàn thành các bước sau:
- trên Bảng điều khiển chức năng bước, chọn Tạo máy trạng thái.
- Giữ Chỗ trống mẫu đã chọn và nhấp vào Chọn.
- Trong tạp chí Menu hành động ở bên trái, Step Functions cung cấp danh sách API dịch vụ AWS mà bạn có thể kéo và thả vào biểu đồ quy trình làm việc của mình trong khung thiết kế. Kiểu EMR Không có máy chủ trong Tìm kiếm và kéo Ứng dụng tạo không có máy chủ của Amazon EMR trạng thái vào biểu đồ quy trình làm việc:
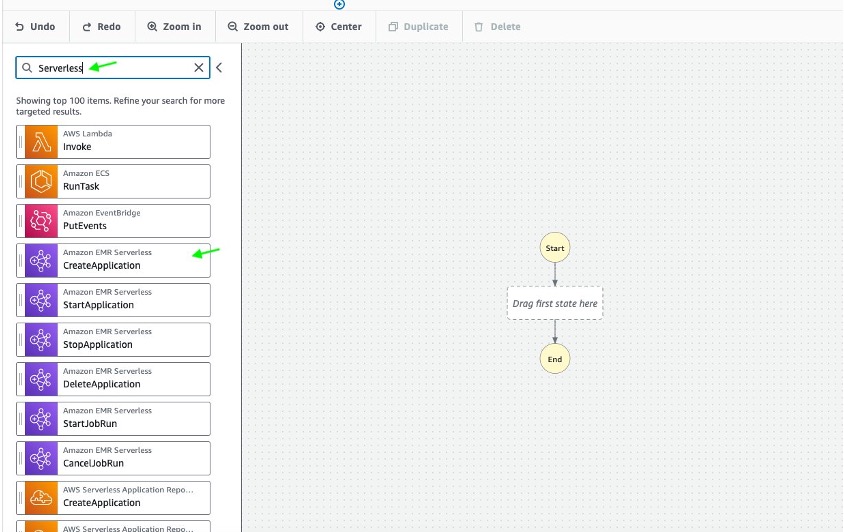
- Trong canvas, chọn Ứng dụng tạo không có máy chủ của Amazon EMR state để cấu hình các thuộc tính của nó. Các Viên thanh tra bảng bên phải hiển thị các tùy chọn cấu hình. Cung cấp các giá trị cấu hình sau:
- Thay đổi Tên nhà nước đến Tạo ứng dụng EMR Serverless
- Cung cấp các giá trị sau cho Tham số API. Điều này tạo ra một Ứng dụng EMR Serverless với Apache Spark dựa trên bản phát hành Amazon EMR 6.12.0 bằng cách sử dụng cài đặt cấu hình mặc định.
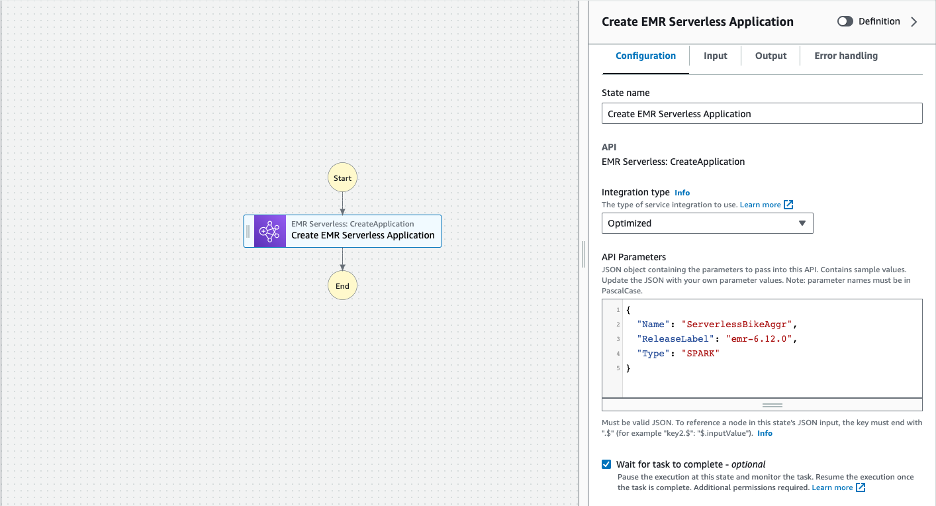
- Nhấn vào Đợi nhiệm vụ hoàn thành - tùy chọn hộp kiểm để đợi trạng thái tạo Ứng dụng phi máy chủ EMR hoàn tất trước khi thực thi trạng thái tiếp theo.
- Theo Trạng thái tiếp theo, chọn Thêm trạng thái mới tùy chọn từ trình đơn thả xuống.
- Kéo EMR StartJobRun không có máy chủ trạng thái từ trình duyệt bên trái sang trạng thái tiếp theo trong quy trình làm việc.
- Đổi tên Tên nhà nước đến Gửi công việc PySpark
- Cung cấp các giá trị sau trong tham số API và nhấp Đợi nhiệm vụ hoàn thành - tùy chọn (đảm bảo thay thế < > bằng ID tài khoản AWS của bạn).
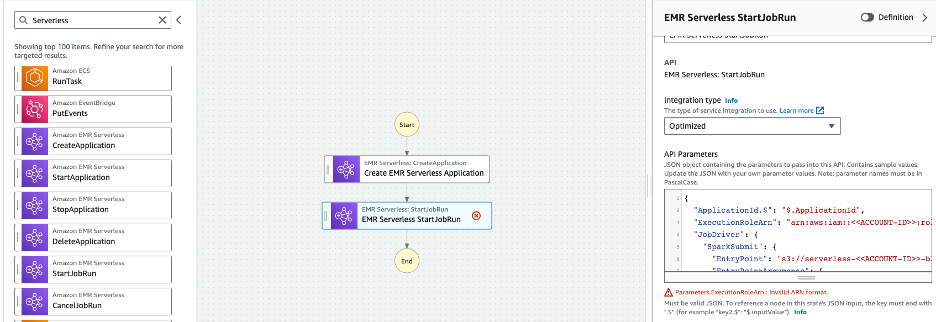
- Chọn hình ba gạch Config tab cho máy trạng thái từ trên xuống và thay đổi các cấu hình sau:
- Thay đổi Tên máy trạng thái đến EMRless-BikeAggr được tìm thấy trong Chi tiết.
- Trong phần Quyền, chọn StateMachine-Role-< > từ danh sách thả xuống cho Vai trò thực thi. (Hãy chắc chắn rằng bạn thay thế < > bằng ID tài khoản AWS của bạn).
- Tiếp tục thêm các bước cho Kiểm tra thành công công việc từ studio như thể hiện trong sơ đồ sau.
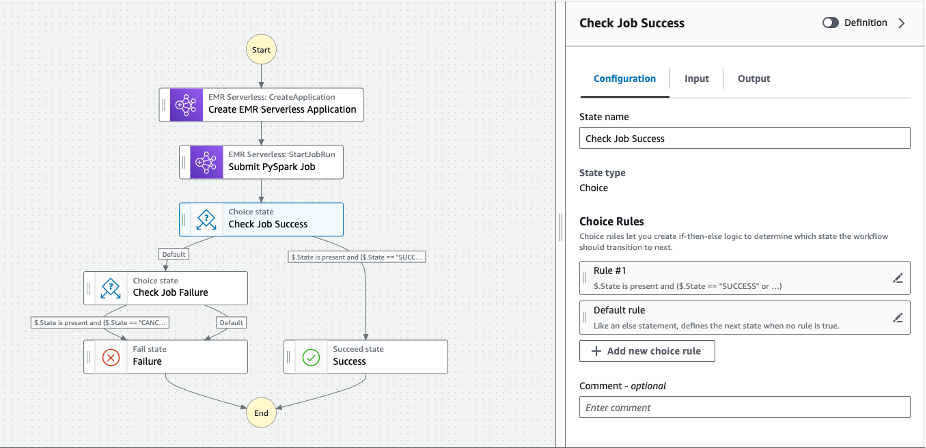
- Nhấp chuột Tạo để tạo Máy trạng thái chức năng bước để điều phối các công việc EMR Serverless.
Bước 2: Gọi các hàm bước
Bây giờ Step Function đã được tạo, chúng ta có thể gọi nó bằng cách nhấp vào Bắt đầu thực hiện nút:
Khi hàm bước đang được gọi, nó sẽ hiển thị luồng chạy của nó như trong ảnh chụp màn hình sau. Bởi vì chúng tôi đã chọn Đợi nhiệm vụ hoàn thành config (.sync API) cho bước này, bước tiếp theo sẽ không bắt đầu cho đến khi Ứng dụng EMR Serverless được tạo (màu xanh biểu thị Ứng dụng Amazon EMR Serverless đang được tạo).

Sau khi tạo thành công Ứng dụng EMR Serverless, chúng tôi gửi Công việc PySpark tới Ứng dụng đó.
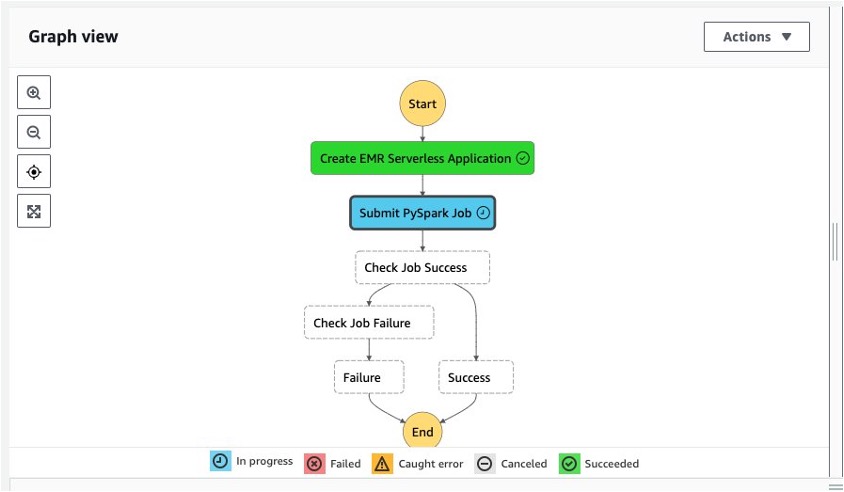
Khi công việc EMR Serverless hoàn thành, Gửi PySpark Việc làm bước chuyển sang màu xanh lá cây. Điều này là do chúng tôi đã chọn Đợi nhiệm vụ hoàn thành cấu hình (sử dụng API .sync) cho bước này.

ID ứng dụng không có máy chủ EMR cũng như Id chạy công việc PySpark từ Đầu ra tab cho Gửi công việc PySpark bậc thang.
Bước 3: Xác thực
Để xác nhận hoàn thành công việc thành công, hãy điều hướng đến Bảng điều khiển không có máy chủ EMR và tìm Id ứng dụng không có máy chủ EMR. Nhấp vào Id ứng dụng để tìm chi tiết thực thi cho lần chạy Công việc PySpark được gửi từ Step Functions.

Để xác minh đầu ra của quá trình thực thi công việc, bạn có thể kiểm tra nhóm S3 nơi đầu ra sẽ được lưu trữ trong tệp .csv như minh họa trong đồ họa sau.
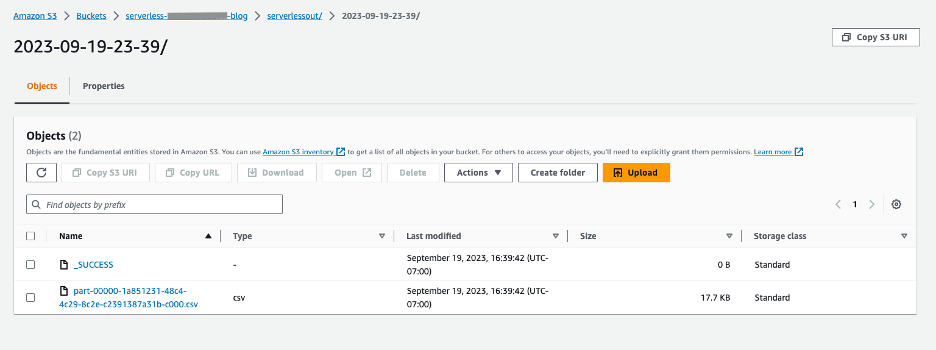
Dọn dẹp
Đăng nhập vào Bảng điều khiển quản lý AWS và xóa mọi nhóm S3 được tạo bởi quá trình triển khai này để tránh các khoản phí không mong muốn đối với tài khoản AWS của bạn. Ví dụ: s3://serverless-<<ACCOUNT-ID>>-blog/
Sau đó, hãy dọn dẹp môi trường của bạn, xóa mẫu CloudFormation mà bạn đã tạo ở các bước cấu hình Giải pháp.
Chức năng Xóa Bước bạn đã tạo như một phần của giải pháp này.
Kết luận
Trong bài đăng này, chúng tôi đã giải thích cách khởi chạy tác vụ Amazon EMR Serverless Spark với Step Functions bằng cách sử dụng Workflow Studio để triển khai quy trình ETL đơn giản nhằm tạo đầu ra tổng hợp từ tập dữ liệu Citi Bike và tạo báo cáo.
Chúng tôi hy vọng điều này mang lại cho bạn một điểm khởi đầu tuyệt vời để sử dụng giải pháp này với tập dữ liệu của bạn và áp dụng các quy tắc công việc phức tạp hơn để giải quyết các trường hợp sử dụng cụm tạm thời của bạn.
Bạn có câu hỏi hoặc phản hồi tiếp theo không? Để lại một bình luận. Chúng tôi muốn nghe những suy nghĩ và đề xuất của bạn.
dự án
Về các tác giả
 Naveen Balaraman là Kiến trúc sư ứng dụng đám mây cấp cao tại Amazon Web Services. Anh ấy đam mê Container, Serverless, Kiến trúc vi dịch vụ và giúp khách hàng tận dụng sức mạnh của đám mây AWS.
Naveen Balaraman là Kiến trúc sư ứng dụng đám mây cấp cao tại Amazon Web Services. Anh ấy đam mê Container, Serverless, Kiến trúc vi dịch vụ và giúp khách hàng tận dụng sức mạnh của đám mây AWS.
 Karthik Prabhakar là Kiến trúc sư giải pháp dữ liệu lớn cấp cao cho Amazon EMR tại AWS. Anh ấy là một kỹ sư phân tích giàu kinh nghiệm làm việc với các khách hàng của AWS để cung cấp các phương pháp hay nhất và tư vấn kỹ thuật nhằm hỗ trợ thành công của họ trong hành trình dữ liệu.
Karthik Prabhakar là Kiến trúc sư giải pháp dữ liệu lớn cấp cao cho Amazon EMR tại AWS. Anh ấy là một kỹ sư phân tích giàu kinh nghiệm làm việc với các khách hàng của AWS để cung cấp các phương pháp hay nhất và tư vấn kỹ thuật nhằm hỗ trợ thành công của họ trong hành trình dữ liệu.
 Parul Saxena là Kiến trúc sư giải pháp chuyên gia dữ liệu lớn tại Amazon Web Services, tập trung vào Amazon EMR, Amazon Athena, AWS Glue và AWS Lake Formation, nơi cô cung cấp hướng dẫn kiến trúc cho khách hàng để chạy khối lượng công việc dữ liệu lớn phức tạp trên nền tảng AWS. Khi rảnh rỗi, cô thích đi du lịch và dành thời gian cho gia đình và bạn bè.
Parul Saxena là Kiến trúc sư giải pháp chuyên gia dữ liệu lớn tại Amazon Web Services, tập trung vào Amazon EMR, Amazon Athena, AWS Glue và AWS Lake Formation, nơi cô cung cấp hướng dẫn kiến trúc cho khách hàng để chạy khối lượng công việc dữ liệu lớn phức tạp trên nền tảng AWS. Khi rảnh rỗi, cô thích đi du lịch và dành thời gian cho gia đình và bạn bè.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/orchestrate-amazon-emr-serverless-jobs-with-aws-step-functions/

