Mục lục
Trong bài viết này, chúng ta sẽ tìm hiểu làm thế nào để phát hiện khuôn mặt trong thời gian thực bằng OpenCV. Sau khi phát hiện khuôn mặt từ luồng webcam, chúng tôi sẽ lưu các khung có chứa khuôn mặt. Sau đó, chúng tôi sẽ chuyển các khung (hình ảnh) này đến bộ phân loại máy dò khẩu trang để tìm hiểu xem người đó có đeo khẩu trang hay không.
Chúng ta cũng sẽ xem cách tạo bộ phát hiện mặt nạ tùy chỉnh bằng cách sử dụng Tensorflow và Keras nhưng bạn có thể bỏ qua phần đó vì tôi sẽ đính kèm tệp mô hình được đào tạo bên dưới mà bạn có thể tải xuống và sử dụng. Dưới đây là danh sách các chủ đề phụ mà chúng tôi sẽ đề cập:
- Nhận diện khuôn mặt là gì?
- Phương pháp nhận diện khuôn mặt
- Thuật toán nhận diện khuôn mặt
- Nhận dạng khuôn mặt
- Nhận diện khuôn mặt bằng Python
- Nhận diện khuôn mặt bằng OpenCV
- Tạo mô hình nhận diện khuôn mặt đeo khẩu trang (Tùy chọn)
- Cách thực hiện phát hiện Mặt nạ thời gian thực
Điều gì Nhận diện khuôn mặt là gì?
Mục tiêu của tính năng phát hiện khuôn mặt là xác định xem có bất kỳ khuôn mặt nào trong hình ảnh hoặc video hay không. Nếu có nhiều mặt, mỗi mặt được bao quanh bởi một hộp giới hạn và do đó chúng ta biết vị trí của các mặt
Mục tiêu chính của các thuật toán nhận diện khuôn mặt là xác định chính xác và hiệu quả sự hiện diện và vị trí của các khuôn mặt trong một hình ảnh hoặc video. Các thuật toán phân tích nội dung trực quan của dữ liệu, tìm kiếm các mẫu và đặc điểm tương ứng với các đặc điểm trên khuôn mặt. Bằng cách sử dụng nhiều kỹ thuật khác nhau, chẳng hạn như học máy, xử lý hình ảnh và nhận dạng mẫu, các thuật toán nhận diện khuôn mặt nhằm mục đích phân biệt khuôn mặt với các đối tượng hoặc thành phần nền khác trong dữ liệu hình ảnh.
Khuôn mặt người rất khó mô hình hóa vì có nhiều yếu tố có thể thay đổi, chẳng hạn như biểu cảm khuôn mặt, hướng, điều kiện ánh sáng và các vật che khuất một phần như kính râm, khăn quàng cổ, khẩu trang, v.v. Kết quả phát hiện đưa ra các tham số vị trí khuôn mặt và nó có thể được yêu cầu ở nhiều dạng khác nhau, ví dụ, một hình chữ nhật bao phủ phần trung tâm của khuôn mặt, trung tâm mắt hoặc các điểm mốc bao gồm mắt, mũi và khóe miệng, lông mày, lỗ mũi, v.v.
Phương pháp nhận diện khuôn mặt
Có hai cách tiếp cận chính để Nhận diện khuôn mặt:
- Phương pháp tiếp cận cơ sở tính năng
- Phương pháp tiếp cận cơ sở hình ảnh
Phương pháp tiếp cận cơ sở tính năng
Các đối tượng thường được nhận ra bởi các tính năng độc đáo của chúng. Có nhiều đặc điểm trên khuôn mặt người, có thể được nhận ra giữa một khuôn mặt và nhiều đối tượng khác. Nó định vị khuôn mặt bằng cách trích xuất các đặc điểm cấu trúc như mắt, mũi, miệng, v.v. rồi sử dụng chúng để phát hiện khuôn mặt. Thông thường, một số loại phân loại thống kê đủ điều kiện sau đó hữu ích để phân tách giữa các vùng trên khuôn mặt và không phải trên khuôn mặt. Ngoài ra, khuôn mặt người có kết cấu đặc biệt có thể được sử dụng để phân biệt giữa khuôn mặt và các đối tượng khác. Hơn nữa, các tính năng cạnh có thể giúp phát hiện các đối tượng từ khuôn mặt. Trong phần sắp tới, chúng tôi sẽ triển khai cách tiếp cận dựa trên tính năng bằng cách sử dụng Hướng dẫn OpenCV.
Phương pháp tiếp cận cơ sở hình ảnh
Nói chung, các phương pháp dựa trên hình ảnh dựa trên các kỹ thuật từ phân tích thống kê và học máy để tìm ra các đặc điểm liên quan của hình ảnh khuôn mặt và không phải khuôn mặt. Các đặc điểm đã học ở dạng mô hình phân phối hoặc hàm phân biệt được sử dụng để phát hiện khuôn mặt. Trong phương pháp này, chúng tôi sử dụng các thuật toán khác nhau như Mạng thần kinh, HMM, SVM, AdaTăng cường học tập. Trong phần tiếp theo, chúng ta sẽ xem cách chúng ta có thể phát hiện khuôn mặt bằng MTCNN hoặc Multi-Task Cascaded Convolutional Mạng thần kinh, đây là phương pháp nhận diện khuôn mặt dựa trên hình ảnh
Thuật toán nhận diện khuôn mặt
Một trong những thuật toán phổ biến sử dụng cách tiếp cận dựa trên tính năng là Thuật toán Viola-Jones và ở đây tôi sẽ thảo luận ngắn gọn về nó. Nếu bạn muốn biết chi tiết về nó, tôi khuyên bạn nên xem qua bài viết này, Nhận diện khuôn mặt bằng thuật toán Viola Jones.
Viola-Jones thuật toán được đặt theo tên của hai nhà nghiên cứu thị giác máy tính đã đề xuất phương pháp này vào năm 2001, Paul Cây tử la lan và Michael Jones trong bài báo của họ, “Phát hiện đối tượng nhanh chóng bằng cách sử dụng một loạt các tính năng đơn giản được tăng cường”. Mặc dù là một framework lỗi thời, nhưng Viola-Jones khá mạnh mẽ và ứng dụng của nó đã được chứng minh là đặc biệt đáng chú ý trong nhận diện khuôn mặt thời gian thực. Thuật toán này đào tạo rất chậm nhưng có thể phát hiện khuôn mặt trong thời gian thực với tốc độ ấn tượng.
Đưa ra một hình ảnh (thuật toán này hoạt động trên hình ảnh thang độ xám), thuật toán xem xét nhiều tiểu vùng nhỏ hơn và cố gắng tìm khuôn mặt bằng cách tìm kiếm các tính năng cụ thể trong từng tiểu vùng. Nó cần kiểm tra nhiều vị trí và tỷ lệ khác nhau vì một hình ảnh có thể chứa nhiều khuôn mặt với nhiều kích cỡ khác nhau. Viola và Jones đã sử dụng các tính năng giống như Haar để phát hiện khuôn mặt trong thuật toán này.
Nhận diện khuôn mặt
Nhận diện khuôn mặt và Nhận dạng khuôn mặt thường được sử dụng thay thế cho nhau nhưng chúng khá khác nhau. Trên thực tế, Nhận diện khuôn mặt chỉ là một phần của Nhận dạng khuôn mặt.
Nhận dạng khuôn mặt là một phương pháp xác định hoặc xác minh danh tính của một cá nhân bằng cách sử dụng khuôn mặt của họ. Có nhiều thuật toán khác nhau có thể thực hiện nhận dạng khuôn mặt nhưng độ chính xác của chúng có thể khác nhau. Ở đây tôi sẽ mô tả cách chúng tôi thực hiện nhận dạng khuôn mặt bằng cách sử dụng học sâu.
Trên thực tế, đây là một bài viết, Face Recognition Python trình bày cách triển khai Nhận dạng khuôn mặt.
Nhận diện khuôn mặt bằng Python
Như đã đề cập trước đó, ở đây chúng ta sẽ xem cách chúng ta có thể phát hiện khuôn mặt bằng cách sử dụng phương pháp dựa trên Hình ảnh. MTCNN hoặc Mạng thần kinh chuyển đổi theo tầng đa tác vụ chắc chắn là một trong những công cụ phát hiện khuôn mặt phổ biến nhất và chính xác nhất hoạt động theo nguyên tắc này. Như vậy, nó dựa trên một học kĩ càng kiến trúc, nó đặc biệt bao gồm 3 mạng thần kinh (P-Net, R-Net và O-Net) được kết nối theo tầng.
Vì vậy, hãy xem cách chúng ta có thể sử dụng thuật toán này trong Python để phát hiện khuôn mặt trong thời gian thực. Trước tiên, bạn cần cài đặt thư viện MTCNN chứa mô hình được đào tạo có thể phát hiện khuôn mặt.
pip install mtcnnBây giờ chúng ta hãy xem cách sử dụng MTCNN:
from mtcnn import MTCNN
import cv2
detector = MTCNN()
#Load a videopip TensorFlow
video_capture = cv2.VideoCapture(0) while (True): ret, frame = video_capture.read() frame = cv2.resize(frame, (600, 400)) boxes = detector.detect_faces(frame) if boxes: box = boxes[0]['box'] conf = boxes[0]['confidence'] x, y, w, h = box[0], box[1], box[2], box[3] if conf > 0.5: cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 255), 1) cv2.imshow("Frame", frame) if cv2.waitKey(25) & 0xFF == ord('q'): break video_capture.release()
cv2.destroyAllWindows()
Nhận diện khuôn mặt bằng OpenCV
Trong phần này, chúng ta sẽ thực hiện thời gian thực nhận diện khuôn mặt bằng OpenCV từ một luồng trực tiếp qua webcam của chúng tôi.
Như bạn đã biết, video về cơ bản được tạo thành từ các khung hình tĩnh. Chúng tôi thực hiện nhận diện khuôn mặt cho từng khung hình trong video. Vì vậy, khi phát hiện khuôn mặt trong ảnh tĩnh và phát hiện khuôn mặt trong luồng video thời gian thực, không có nhiều khác biệt giữa chúng.
Chúng tôi sẽ sử dụng thuật toán Haar Cascade, còn được gọi là thuật toán Voila-Jones để phát hiện khuôn mặt. Về cơ bản, nó là một thuật toán phát hiện đối tượng học máy được sử dụng để xác định các đối tượng trong hình ảnh hoặc video. Trong OpenCV, chúng tôi có một số mô hình Haar Cascade được đào tạo được lưu dưới dạng tệp XML. Thay vì tạo và đào tạo mô hình từ đầu, chúng tôi sử dụng tệp này. Chúng tôi sẽ sử dụng tệp “haarcascade_frontalface_alt2.xml” trong dự án này. Bây giờ chúng ta hãy bắt đầu viết mã này
Bước đầu tiên là tìm đường dẫn đến tệp “haarcascade_frontalface_alt2.xml”. Chúng tôi làm điều này bằng cách sử dụng mô-đun os của ngôn ngữ Python.
import os
cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"Bước tiếp theo là tải trình phân loại của chúng tôi. Đường dẫn đến tệp XML ở trên là đối số cho phương thức CascadeClassifier() của OpenCV.
faceCascade = cv2.CascadeClassifier(cascPath)Sau khi tải bộ phân loại, chúng ta hãy mở webcam bằng mã một lớp OpenCV đơn giản này
video_capture = cv2.VideoCapture(0)Tiếp theo, chúng ta cần lấy các khung hình từ luồng webcam, chúng ta thực hiện việc này bằng hàm read(). Chúng tôi sử dụng nó trong vòng lặp vô hạn để lấy tất cả các khung cho đến thời điểm chúng tôi muốn đóng luồng.
while True: # Capture frame-by-frame ret, frame = video_capture.read()Hàm read() trả về:
- Khung hình video thực tế đã đọc (một khung hình trên mỗi vòng lặp)
- Mã trả về
Mã trả về cho chúng tôi biết liệu chúng tôi có hết khung hay không, điều này sẽ xảy ra nếu chúng tôi đang đọc từ một tệp. Điều này không thành vấn đề khi đọc từ webcam vì chúng tôi có thể ghi mãi mãi, vì vậy chúng tôi sẽ bỏ qua nó.
Để trình phân loại cụ thể này hoạt động, chúng ta cần chuyển đổi khung thành thang độ xám.
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)Đối tượng faceCascade có một phương thức detectMultiScale(), phương thức này nhận một khung (hình ảnh) làm đối số và chạy xếp tầng trình phân loại trên hình ảnh. Thuật ngữ MultiScale chỉ ra rằng thuật toán xem xét các tiểu vùng của hình ảnh theo nhiều tỷ lệ, để phát hiện các khuôn mặt có kích thước khác nhau.
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE)Chúng ta hãy đi qua các đối số của chức năng này:
- scaleFactor – Tham số chỉ định kích thước hình ảnh được giảm bao nhiêu ở mỗi tỷ lệ hình ảnh. Bằng cách thay đổi kích thước hình ảnh đầu vào, bạn có thể thay đổi kích thước khuôn mặt lớn hơn thành khuôn mặt nhỏ hơn, giúp thuật toán có thể phát hiện khuôn mặt đó. 1.05 là một giá trị tốt có thể cho điều này, có nghĩa là bạn sử dụng một bước nhỏ để thay đổi kích thước, tức là giảm kích thước xuống 5%, bạn sẽ tăng cơ hội tìm thấy kích thước phù hợp với mô hình để phát hiện.
- minNeighbors – Tham số chỉ định số lượng hàng xóm mà mỗi hình chữ nhật ứng viên phải giữ lại. Tham số này sẽ ảnh hưởng đến chất lượng của các khuôn mặt được phát hiện. Giá trị cao hơn dẫn đến ít lần phát hiện hơn nhưng chất lượng cao hơn. 3 ~ 6 là một giá trị tốt cho nó.
- cờ –Chế độ hoạt động
- minSize – Kích thước đối tượng tối thiểu có thể. Các đối tượng nhỏ hơn sẽ bị bỏ qua.
Các mặt biến hiện chứa tất cả các phát hiện cho hình ảnh mục tiêu. Các phát hiện được lưu dưới dạng tọa độ pixel. Mỗi lần phát hiện được xác định bởi tọa độ góc trên cùng bên trái của nó cũng như chiều rộng và chiều cao của hình chữ nhật bao quanh khuôn mặt được phát hiện.
Để hiển thị khuôn mặt được phát hiện, chúng tôi sẽ vẽ một hình chữ nhật trên đó. Hình chữ nhật() của OpenCV vẽ hình chữ nhật trên hình ảnh và nó cần biết tọa độ pixel của các góc trên cùng bên trái và dưới cùng bên phải. Các tọa độ cho biết hàng và cột pixel trong ảnh. Chúng ta có thể dễ dàng lấy các tọa độ này từ mặt biến.
for (x,y,w,h) in faces: cv2.rectangle(frame, (x, y), (x + w, y + h),(0,255,0), 2)hình chữ nhật() chấp nhận các đối số sau:
- Ảnh gốc
- Các tọa độ của điểm trên cùng bên trái của phát hiện
- Các tọa độ của điểm dưới cùng bên phải của phát hiện
- Màu của hình chữ nhật (một bộ xác định lượng màu đỏ, xanh lá cây và xanh lam (0-255)). Trong trường hợp của chúng tôi, chúng tôi đặt thành màu xanh lá cây chỉ giữ thành phần màu xanh lá cây là 255 và phần còn lại là XNUMX.
- Độ dày của các đường hình chữ nhật
Tiếp theo, chúng tôi chỉ hiển thị khung kết quả và cũng đặt cách thoát khỏi vòng lặp vô tận này và đóng nguồn cấp dữ liệu video. Bằng cách nhấn phím 'q', chúng ta có thể thoát khỏi tập lệnh tại đây
cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): breakHai dòng tiếp theo chỉ để dọn dẹp và phát hành hình ảnh.
video_capture.release()
cv2.destroyAllWindows()Đây là mã đầy đủ và đầu ra.
import cv2
import os
cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE) for (x,y,w,h) in faces: cv2.rectangle(frame, (x, y), (x + w, y + h),(0,255,0), 2) # Display the resulting frame cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()
Đầu ra:
Tạo mô hình nhận diện khuôn mặt đeo khẩu trang
Trong phần này, chúng ta sẽ tạo một bộ phân loại có thể phân biệt khuôn mặt đeo mặt nạ và không đeo mặt nạ. Trong trường hợp bạn muốn bỏ qua phần này, đây là một Link để tải xuống mô hình được đào tạo trước. Lưu nó và chuyển sang phần tiếp theo để biết cách sử dụng nó để phát hiện mặt nạ bằng OpenCV. Kiểm tra bộ sưu tập của chúng tôi về các khóa học OpenCV để giúp bạn phát triển kỹ năng của bạn và hiểu rõ hơn.
Vì vậy, để tạo bộ phân loại này, chúng tôi cần dữ liệu ở dạng Hình ảnh. May mắn thay, chúng tôi có một bộ dữ liệu chứa hình ảnh các khuôn mặt đeo mặt nạ và không đeo mặt nạ. Vì những hình ảnh này có số lượng rất ít nên chúng ta không thể huấn luyện mạng thần kinh từ đầu. Thay vào đó, chúng tôi tinh chỉnh một mạng được đào tạo trước có tên là MobileNetV2 được đào tạo trên bộ dữ liệu Imagenet.
Trước tiên chúng ta hãy nhập tất cả các thư viện cần thiết mà chúng ta sẽ cần.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import osBước tiếp theo là đọc tất cả các hình ảnh và gán chúng vào một số danh sách. Ở đây chúng tôi lấy tất cả các đường dẫn được liên kết với những hình ảnh này và sau đó gắn nhãn cho chúng. Hãy nhớ rằng tập dữ liệu của chúng tôi được chứa trong hai thư mục viz- with_masks và without_masks. Vì vậy, chúng tôi có thể dễ dàng lấy nhãn bằng cách trích xuất tên thư mục từ đường dẫn. Ngoài ra, chúng tôi xử lý trước hình ảnh và thay đổi kích thước hình ảnh thành kích thước 224x 224.
imagePaths = list(paths.list_images('/content/drive/My Drive/dataset'))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths: # extract the class label from the filename label = imagePath.split(os.path.sep)[-2] # load the input image (224x224) and preprocess it image = load_img(imagePath, target_size=(224, 224)) image = img_to_array(image) image = preprocess_input(image) # update the data and labels lists, respectively data.append(image) labels.append(label)
# convert the data and labels to NumPy arrays
data = np.array(data, dtype="float32")
labels = np.array(labels)Bước tiếp theo là tải mô hình được đào tạo trước và tùy chỉnh nó theo vấn đề của chúng tôi. Vì vậy, chúng tôi chỉ cần xóa các lớp trên cùng của mô hình được đào tạo trước này và thêm một vài lớp của riêng chúng tôi. Như bạn có thể thấy lớp cuối cùng có hai nút vì chúng ta chỉ có hai đầu ra. Điều này được gọi là học chuyển giao.
baseModel = MobileNetV2(weights="imagenet", include_top=False, input_shape=(224, 224, 3))
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=(7, 7))(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(128, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(2, activation="softmax")(headModel) # place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the first training process
for layer in baseModel.layers: layer.trainable = FalseBây giờ chúng ta cần chuyển đổi các nhãn thành mã hóa một lần nóng. Sau đó, chúng tôi chia dữ liệu thành các tập huấn luyện và kiểm tra để đánh giá chúng. Ngoài ra, bước tiếp theo là tăng cường dữ liệu làm tăng đáng kể tính đa dạng của dữ liệu có sẵn cho các mô hình đào tạo mà không thực sự thu thập dữ liệu mới. Các kỹ thuật tăng cường dữ liệu như cắt xén, xoay, cắt và lật ngang thường được sử dụng để huấn luyện các mạng thần kinh lớn.
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
labels = to_categorical(labels)
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.20, stratify=labels, random_state=42)
# construct the training image generator for data augmentation
aug = ImageDataGenerator( rotation_range=20, zoom_range=0.15, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15, horizontal_flip=True, fill_mode="nearest")Bước tiếp theo là biên dịch mô hình và huấn luyện mô hình trên dữ liệu tăng cường.
INIT_LR = 1e-4
EPOCHS = 20
BS = 32
print("[INFO] compiling model...")
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"])
# train the head of the network
print("[INFO] training head...")
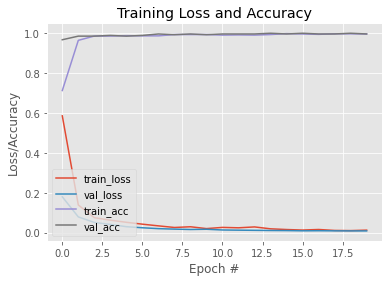
H = model.fit( aug.flow(trainX, trainY, batch_size=BS), steps_per_epoch=len(trainX) // BS, validation_data=(testX, testY), validation_steps=len(testX) // BS, epochs=EPOCHS)Bây giờ mô hình của chúng ta đã được đào tạo, chúng ta hãy vẽ biểu đồ để xem đường cong học tập của nó. Ngoài ra, chúng tôi lưu mô hình để sử dụng sau này. Đây là Link cho mô hình được đào tạo này.
N = EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")Đầu ra:
#To save the trained model
model.save('mask_recog_ver2.h5')Cách thực hiện phát hiện Mặt nạ thời gian thực
Trước khi chuyển sang phần tiếp theo, hãy đảm bảo tải xuống mô hình trên từ đây Link và đặt nó vào cùng thư mục với tập lệnh python mà bạn sẽ viết mã bên dưới.
Bây giờ mô hình của chúng tôi đã được đào tạo, chúng tôi có thể sửa đổi mã trong phần đầu tiên để nó có thể phát hiện khuôn mặt và cũng cho chúng tôi biết liệu người đó có đeo mặt nạ hay không.
Để mô hình phát hiện mặt nạ của chúng tôi hoạt động, nó cần có hình ảnh khuôn mặt. Đối với điều này, chúng tôi sẽ phát hiện các khung có khuôn mặt bằng cách sử dụng các phương pháp như được hiển thị trong phần đầu tiên và sau đó chuyển chúng vào mô hình của chúng tôi sau khi xử lý trước chúng. Vì vậy, trước tiên chúng ta hãy nhập tất cả các thư viện mà chúng ta cần.
import cv2
import os
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
import numpy as npMột vài dòng đầu tiên giống hệt như phần đầu tiên. Điều khác biệt duy nhất là chúng tôi đã chỉ định mô hình phát hiện mặt nạ được đào tạo trước của mình cho mô hình biến đổi.
ascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
model = load_model("mask_recog1.h5") video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE)Tiếp theo, chúng tôi xác định một số danh sách. faces_list chứa tất cả các khuôn mặt được phát hiện bởi mô hình faceCascade và danh sách dự đoán được sử dụng để lưu trữ các dự đoán do mô hình phát hiện mặt nạ đưa ra.
faces_list=[]
preds=[]Ngoài ra, vì biến khuôn mặt chứa tọa độ góc trên cùng bên trái, chiều cao và chiều rộng của hình chữ nhật bao quanh các khuôn mặt, nên chúng ta có thể sử dụng biến đó để lấy khung của khuôn mặt và sau đó xử lý trước khung đó để có thể đưa vào mô hình để dự đoán . Các bước tiền xử lý giống như các bước được tuân theo khi đào tạo mô hình trong phần thứ hai. Ví dụ: mô hình được đào tạo trên hình ảnh RGB nên chúng tôi chuyển đổi hình ảnh thành RGB tại đây
for (x, y, w, h) in faces: face_frame = frame[y:y+h,x:x+w] face_frame = cv2.cvtColor(face_frame, cv2.COLOR_BGR2RGB) face_frame = cv2.resize(face_frame, (224, 224)) face_frame = img_to_array(face_frame) face_frame = np.expand_dims(face_frame, axis=0) face_frame = preprocess_input(face_frame) faces_list.append(face_frame) if len(faces_list)>0: preds = model.predict(faces_list) for pred in preds: #mask contain probabily of wearing a mask and vice versa (mask, withoutMask) = pred Sau khi nhận được các dự đoán, chúng tôi vẽ một hình chữ nhật trên mặt và dán nhãn theo các dự đoán.
label = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255) label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) cv2.putText(frame, label, (x, y- 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (x, y), (x + w, y + h),color, 2)Các bước còn lại giống như phần đầu tiên.
cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()Đây là mã hoàn chỉnh và đầu ra:
import cv2
import os
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
import numpy as np cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
model = load_model("mask_recog1.h5") video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE) faces_list=[] preds=[] for (x, y, w, h) in faces: face_frame = frame[y:y+h,x:x+w] face_frame = cv2.cvtColor(face_frame, cv2.COLOR_BGR2RGB) face_frame = cv2.resize(face_frame, (224, 224)) face_frame = img_to_array(face_frame) face_frame = np.expand_dims(face_frame, axis=0) face_frame = preprocess_input(face_frame) faces_list.append(face_frame) if len(faces_list)>0: preds = model.predict(faces_list) for pred in preds: (mask, withoutMask) = pred label = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255) label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) cv2.putText(frame, label, (x, y- 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (x, y), (x + w, y + h),color, 2) # Display the resulting frame cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()
Đầu ra:
Điều này đưa chúng ta đến phần cuối của bài viết này, nơi chúng ta đã học cách phát hiện khuôn mặt trong thời gian thực và cũng thiết kế một mô hình có thể phát hiện khuôn mặt bằng mặt nạ. Sử dụng mô hình này, chúng tôi có thể sửa đổi máy dò khuôn mặt thành máy dò mặt nạ.
Cập nhật: Tôi đã đào tạo một người mẫu khác có thể phân loại hình ảnh thành đeo khẩu trang, không đeo khẩu trang và đeo khẩu trang không đúng cách. Đây là một liên kết của Sổ tay Kaggle của mô hình này. Bạn có thể sửa đổi nó và cũng có thể tải xuống mô hình từ đó và sử dụng nó thay vì mô hình mà chúng tôi đã đào tạo trong bài viết này. Mặc dù mô hình này không hiệu quả bằng mô hình mà chúng tôi đã đào tạo ở đây, nhưng nó có một tính năng bổ sung là phát hiện đeo khẩu trang không đúng cách.
Nếu bạn đang sử dụng mô hình này, bạn cần thực hiện một số thay đổi nhỏ đối với mã. Thay thế các dòng trước bằng các dòng này.
#Here are some minor changes in opencv code
for (box, pred) in zip(locs, preds): # unpack the bounding box and predictions (startX, startY, endX, endY) = box (mask, withoutMask,notproper) = pred # determine the class label and color we'll use to draw # the bounding box and text if (mask > withoutMask and mask>notproper): label = "Without Mask" elif ( withoutMask > notproper and withoutMask > mask): label = "Mask" else: label = "Wear Mask Properly" if label == "Mask": color = (0, 255, 0) elif label=="Without Mask": color = (0, 0, 255) else: color = (255, 140, 0) # include the probability in the label label = "{}: {:.2f}%".format(label, max(mask, withoutMask, notproper) * 100) # display the label and bounding box rectangle on the output # frame cv2.putText(frame, label, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2)Bạn cũng có thể nâng cao kỹ năng với Great Learning's Khóa học trí tuệ nhân tạo và máy học PGP. Khóa học cung cấp sự cố vấn từ các nhà lãnh đạo trong ngành và bạn cũng sẽ có cơ hội làm việc trong các dự án liên quan đến ngành theo thời gian thực.
Đọc thêm
- Phát hiện đối tượng thời gian thực bằng TensorFlow
- Phát hiện đối tượng YOLO bằng OpenCV
- Phát hiện đối tượng trong Pytorch | Phát hiện đối tượng là gì?
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- EVM tài chính. Giao diện hợp nhất cho tài chính phi tập trung. Truy cập Tại đây.
- Tập đoàn truyền thông lượng tử. Khuếch đại IR/PR. Truy cập Tại đây.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- nguồn: https://www.mygreatlearning.com/blog/real-time-face-detection/

