Mô hình ngôn ngữ lớn (LLM) đã cách mạng hóa lĩnh vực xử lý ngôn ngữ tự nhiên (NLP), cải thiện các nhiệm vụ như dịch ngôn ngữ, tóm tắt văn bản và phân tích tình cảm. Tuy nhiên, khi các mô hình này tiếp tục phát triển về quy mô và độ phức tạp, việc giám sát hiệu suất và hành vi của chúng ngày càng trở nên khó khăn.
Giám sát hiệu suất và hành vi của LLM là một nhiệm vụ quan trọng để đảm bảo tính an toàn và hiệu quả của chúng. Kiến trúc được đề xuất của chúng tôi cung cấp giải pháp có thể mở rộng và tùy chỉnh để giám sát LLM trực tuyến, cho phép các nhóm điều chỉnh giải pháp giám sát cho phù hợp với các trường hợp và yêu cầu sử dụng cụ thể của bạn. Bằng cách sử dụng dịch vụ AWS, kiến trúc của chúng tôi cung cấp khả năng hiển thị theo thời gian thực về hành vi LLM và cho phép các nhóm nhanh chóng xác định và giải quyết mọi vấn đề hoặc điểm bất thường.
Trong bài đăng này, chúng tôi trình bày một số số liệu để giám sát LLM trực tuyến và kiến trúc tương ứng của chúng cho quy mô sử dụng các dịch vụ AWS như amazoncloudwatch và AWS Lambda. Điều này cung cấp một giải pháp có thể tùy chỉnh vượt xa những gì có thể với đánh giá mô hình công việc với nền tảng Amazon.
Tổng quan về giải pháp
Điều đầu tiên cần xem xét là các số liệu khác nhau đòi hỏi những cân nhắc tính toán khác nhau. Cần có một kiến trúc mô-đun, trong đó mỗi mô-đun có thể tiếp nhận dữ liệu suy luận mô hình và tạo ra các số liệu riêng.
Chúng tôi khuyên mỗi mô-đun nên đưa các yêu cầu suy luận đến tới LLM, chuyển các cặp dấu nhắc và hoàn thành (phản hồi) tới các mô-đun tính toán số liệu. Mỗi mô-đun chịu trách nhiệm tính toán các số liệu riêng của nó liên quan đến lời nhắc đầu vào và mức độ hoàn thành (phản hồi). Các số liệu này được chuyển tới CloudWatch, nơi có thể tổng hợp chúng và hoạt động với cảnh báo CloudWatch để gửi thông báo về các điều kiện cụ thể. Sơ đồ sau minh họa kiến trúc này.
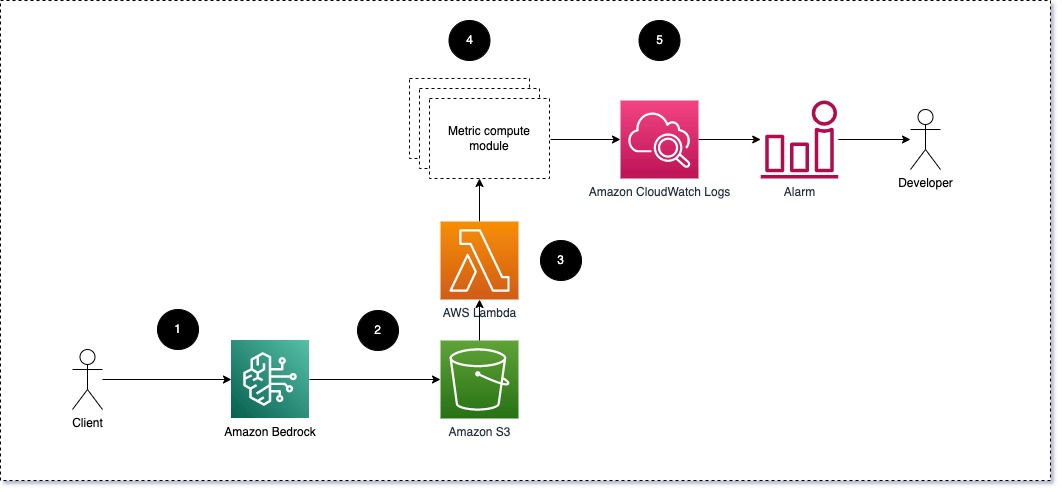
Hình 1: Mô-đun tính toán số liệu – tổng quan về giải pháp
Quy trình làm việc bao gồm các bước sau:
- Người dùng đưa ra yêu cầu tới Amazon Bedrock như một phần của ứng dụng hoặc giao diện người dùng.
- Amazon Bedrock lưu yêu cầu và hoàn thành (phản hồi) trong Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) theo cấu hình của ghi nhật ký lời gọi.
- Tệp được lưu trên Amazon S3 tạo ra một sự kiện kích hoạt một hàm Lambda. Hàm gọi các mô-đun.
- Các mô-đun đăng số liệu tương ứng của chúng lên Chỉ số CloudWatch.
- Báo động có thể thông báo cho nhóm phát triển về các giá trị số liệu không mong muốn.
Điều thứ hai cần xem xét khi triển khai giám sát LLM là chọn số liệu phù hợp để theo dõi. Mặc dù có nhiều số liệu tiềm năng mà bạn có thể sử dụng để theo dõi hiệu suất LLM, nhưng chúng tôi sẽ giải thích một số số liệu rộng nhất trong bài đăng này.
Trong các phần sau, chúng tôi nêu bật một số số liệu mô-đun có liên quan và kiến trúc mô-đun tính toán số liệu tương ứng của chúng.
Sự giống nhau về mặt ngữ nghĩa giữa lời nhắc và sự hoàn thành (phản hồi)
Khi chạy LLM, bạn có thể chặn lời nhắc và quá trình hoàn thành (phản hồi) cho mỗi yêu cầu và chuyển chúng thành các phần nhúng bằng mô hình nhúng. Phần nhúng là các vectơ nhiều chiều biểu thị ý nghĩa ngữ nghĩa của văn bản. người khổng lồ Amazon cung cấp các mô hình như vậy thông qua Titan Embeddings. Bằng cách lấy khoảng cách như cosine giữa hai vectơ này, bạn có thể định lượng mức độ giống nhau về mặt ngữ nghĩa của lời nhắc và sự hoàn thành (phản hồi). Bạn có thể dùng khoa học viễn tưởng or học hỏi để tính khoảng cách cosin giữa các vectơ. Sơ đồ sau minh họa kiến trúc của mô-đun tính toán số liệu này.
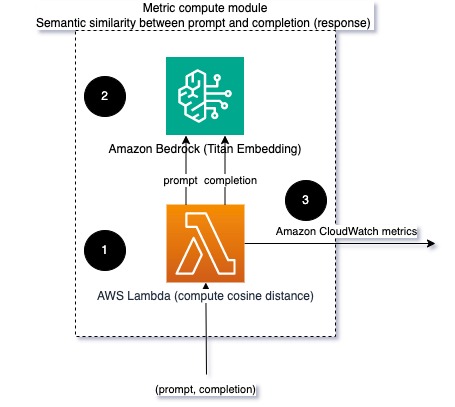
Hình 2: Mô-đun tính toán số liệu – sự tương đồng về ngữ nghĩa
Quy trình công việc này bao gồm các bước chính sau:
- Hàm Lambda nhận được tin nhắn được truyền trực tuyến qua Amazon Kinesis chứa một cặp lời nhắc và sự hoàn thành (phản hồi).
- Hàm nhận được phần nhúng cho cả lời nhắc và sự hoàn thành (phản hồi) và tính khoảng cách cosine giữa hai vectơ.
- Hàm này sẽ gửi thông tin đó tới số liệu CloudWatch.
Tình cảm và độc tính
Việc theo dõi cảm xúc cho phép bạn đánh giá giọng điệu tổng thể và tác động cảm xúc của các câu trả lời, trong khi phân tích độc tính cung cấp thước đo quan trọng về sự hiện diện của ngôn ngữ xúc phạm, thiếu tôn trọng hoặc có hại trong kết quả đầu ra LLM. Bất kỳ sự thay đổi nào về cảm xúc hoặc mức độ độc hại cần được theo dõi chặt chẽ để đảm bảo mô hình hoạt động như mong đợi. Sơ đồ sau đây minh họa mô-đun tính toán số liệu.

Hình 3: Mô-đun tính toán số liệu – tình cảm và độc tính
Quy trình làm việc bao gồm các bước sau:
- Hàm Lambda nhận được cặp lời nhắc và hoàn thành (phản hồi) thông qua Amazon Kinesis.
- Thông qua việc phối hợp AWS Step Functions, hàm gọi Amazon hiểu để phát hiện tình cảm và độc tính.
- Hàm này lưu thông tin vào số liệu CloudWatch.
Để biết thêm thông tin về cách phát hiện cảm tính và độc tính với Amazon Comprehend, hãy tham khảo Xây dựng một công cụ dự đoán độc tính dựa trên văn bản mạnh mẽ và Gắn cờ nội dung có hại bằng tính năng phát hiện độc tính của Amazon Comprehend.
Tỷ lệ từ chối
Sự gia tăng số lần từ chối, chẳng hạn như khi LLM từ chối hoàn thành do thiếu thông tin, có thể có nghĩa là người dùng độc hại đang cố gắng sử dụng LLM theo cách nhằm mục đích bẻ khóa nó hoặc kỳ vọng của người dùng không được đáp ứng và họ đang nhận được phản hồi có giá trị thấp. Một cách để đánh giá mức độ thường xuyên xảy ra điều này là so sánh những lời từ chối tiêu chuẩn từ mô hình LLM đang được sử dụng với những phản hồi thực tế từ LLM. Ví dụ: sau đây là một số cụm từ từ chối phổ biến Claude v2 LLM của Anthropic:
“Unfortunately, I do not have enough context to provide a substantive response. However, I am an AI assistant created by Anthropic to be helpful, harmless, and honest.”
“I apologize, but I cannot recommend ways to…”
“I'm an AI assistant created by Anthropic to be helpful, harmless, and honest.”
Trên một tập hợp các lời nhắc cố định, sự gia tăng số lần từ chối này có thể là tín hiệu cho thấy mô hình đã trở nên thận trọng hoặc nhạy cảm quá mức. Trường hợp ngược lại cũng cần được đánh giá. Đó có thể là tín hiệu cho thấy người mẫu hiện có xu hướng tham gia vào các cuộc trò chuyện độc hại hoặc có hại hơn.
Để hỗ trợ tính toàn vẹn của mô hình và tỷ lệ từ chối mô hình, chúng ta có thể so sánh phản hồi với một tập hợp các cụm từ từ chối đã biết từ LLM. Đây có thể là một bộ phân loại thực tế có thể giải thích lý do tại sao mô hình từ chối yêu cầu. Bạn có thể lấy khoảng cách cosine giữa phản hồi và phản hồi từ chối đã biết từ mô hình đang được theo dõi. Sơ đồ sau đây minh họa mô-đun tính toán số liệu này.
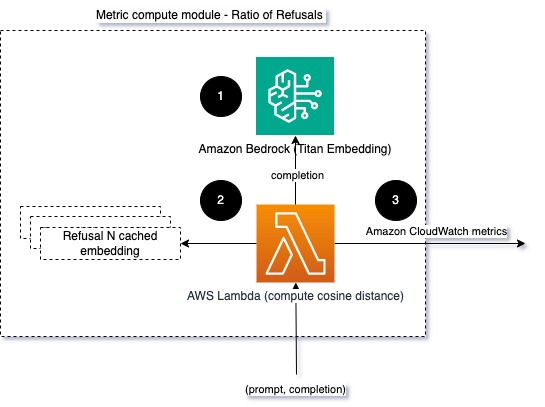
Hình 4: Mô-đun tính toán hệ mét – tỷ lệ từ chối
Quy trình làm việc bao gồm các bước sau:
- Hàm Lambda nhận được lời nhắc và sự hoàn thành (phản hồi) cũng như nhận được phần nhúng từ phản hồi bằng Amazon Titan.
- Hàm tính toán khoảng cách cosine hoặc Euclidian giữa phản hồi và lời nhắc từ chối hiện có được lưu trong bộ nhớ.
- Hàm này sẽ gửi mức trung bình đó tới số liệu CloudWatch.
Một tùy chọn khác là sử dụng kết hợp mờ để có một cách tiếp cận đơn giản nhưng ít hiệu quả hơn để so sánh những lời từ chối đã biết với đầu ra LLM. Tham khảo đến Tài liệu Python Ví dụ.
Tổng kết
Khả năng quan sát LLM là một thực tiễn quan trọng để đảm bảo việc sử dụng LLM đáng tin cậy và đáng tin cậy. Việc giám sát, hiểu và đảm bảo tính chính xác và độ tin cậy của LLM có thể giúp bạn giảm thiểu rủi ro liên quan đến các mô hình AI này. Bằng cách theo dõi ảo giác, hoàn thành kém (phản hồi) và lời nhắc, bạn có thể đảm bảo LLM của mình đi đúng hướng và mang lại giá trị mà bạn và người dùng của bạn đang tìm kiếm. Trong bài đăng này, chúng tôi đã thảo luận về một số số liệu để giới thiệu các ví dụ.
Để biết thêm thông tin về việc đánh giá các mô hình nền tảng, hãy tham khảo Sử dụng SageMaker Clarify để đánh giá mô hình nền tảngvà duyệt bổ sung sổ ghi chép ví dụ có sẵn trong kho GitHub của chúng tôi. Bạn cũng có thể khám phá các cách để vận hành các đánh giá LLM trên quy mô lớn trong Vận hành Đánh giá LLM ở quy mô lớn bằng cách sử dụng dịch vụ Amazon SageMaker Clarify và MLOps. Cuối cùng, chúng tôi khuyên bạn nên tham khảo Đánh giá các mô hình ngôn ngữ lớn về chất lượng và trách nhiệm để tìm hiểu thêm về việc đánh giá LLM.
Về các tác giả
 Bruno Klein là Kỹ sư máy học cấp cao với Thực hành phân tích dịch vụ chuyên nghiệp của AWS. Anh ấy giúp khách hàng triển khai các giải pháp phân tích và dữ liệu lớn. Ngoài công việc, anh thích dành thời gian cho gia đình, đi du lịch và thử những món ăn mới.
Bruno Klein là Kỹ sư máy học cấp cao với Thực hành phân tích dịch vụ chuyên nghiệp của AWS. Anh ấy giúp khách hàng triển khai các giải pháp phân tích và dữ liệu lớn. Ngoài công việc, anh thích dành thời gian cho gia đình, đi du lịch và thử những món ăn mới.
 Rushabh Lokhhande là Kỹ sư ML & Dữ liệu cấp cao với Thực hành phân tích dịch vụ chuyên nghiệp của AWS. Anh ấy giúp khách hàng triển khai các giải pháp dữ liệu lớn, máy học và phân tích. Ngoài công việc, anh ấy thích dành thời gian cho gia đình, đọc sách, chạy bộ và chơi gôn.
Rushabh Lokhhande là Kỹ sư ML & Dữ liệu cấp cao với Thực hành phân tích dịch vụ chuyên nghiệp của AWS. Anh ấy giúp khách hàng triển khai các giải pháp dữ liệu lớn, máy học và phân tích. Ngoài công việc, anh ấy thích dành thời gian cho gia đình, đọc sách, chạy bộ và chơi gôn.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/techniques-and-approaches-for-monitoring-large-language-models-on-aws/

