
Hình ảnh của Tác giả
Một trong những lĩnh vực củng cố khoa học dữ liệu là học máy. Vì vậy, nếu bạn muốn tham gia vào lĩnh vực khoa học dữ liệu, hiểu về máy học là một trong những bước đầu tiên bạn cần thực hiện.
Nhưng bạn bắt đầu ở đâu? Bạn bắt đầu bằng cách tìm hiểu sự khác biệt giữa hai loại thuật toán học máy chính. Chỉ sau đó, chúng ta mới có thể nói về các thuật toán riêng lẻ nên nằm trong danh sách ưu tiên của bạn để học khi mới bắt đầu.
Sự khác biệt chính giữa các thuật toán dựa trên cách chúng học.

Hình ảnh của Tác giả
Các thuật toán học tập có giám sát được đào tạo về một tập dữ liệu được dán nhãn. Tập dữ liệu này đóng vai trò giám sát (do đó có tên) cho việc học vì một số dữ liệu trong đó đã được gắn nhãn là câu trả lời đúng. Dựa trên đầu vào này, thuật toán có thể tìm hiểu và áp dụng việc học đó cho phần còn lại của dữ liệu.
Mặt khác, thuật toán học không giám sát học trên một tập dữ liệu không được gắn nhãn, nghĩa là chúng tham gia vào việc tìm kiếm các mẫu trong dữ liệu mà không cần con người đưa ra hướng dẫn.
Bạn có thể đọc thêm chi tiết về thuật toán học máy và các loại hình học tập.
Ngoài ra còn có một số loại hình học máy khác nhưng không dành cho người mới bắt đầu.
Các thuật toán được sử dụng để giải quyết hai vấn đề chính riêng biệt trong từng loại máy học.
Một lần nữa, còn có một số nhiệm vụ nữa nhưng chúng không dành cho người mới bắt đầu.

Hình ảnh của Tác giả
Nhiệm vụ học tập có giám sát
Hồi quy là nhiệm vụ dự đoán một giá trị số, Được gọi là biến kết quả liên tục hoặc biến phụ thuộc. Dự đoán dựa trên (các) biến dự đoán hoặc (các) biến độc lập.
Hãy suy nghĩ về việc dự đoán giá dầu hoặc nhiệt độ không khí.
phân loại được sử dụng để dự đoán hạng (lớp) của dữ liệu đầu vào. Các biến kết quả đây là phân loại hoặc rời rạc.
Hãy suy nghĩ dự đoán xem thư đó có phải là thư rác hay không phải thư rác hay bệnh nhân có mắc một căn bệnh nào đó hay không.
Nhiệm vụ học tập không giám sát
Clustering có nghĩa chia dữ liệu thành các tập hợp con hoặc cụm. Mục tiêu là nhóm dữ liệu một cách tự nhiên nhất có thể. Điều này có nghĩa là các điểm dữ liệu trong cùng một cụm sẽ giống nhau hơn so với các điểm dữ liệu từ các cụm khác.
Giảm kích thước đề cập đến việc giảm số lượng biến đầu vào trong tập dữ liệu. Về cơ bản nó có nghĩa là giảm tập dữ liệu xuống rất ít biến trong khi vẫn nắm bắt được bản chất của nó.
Dưới đây là tổng quan về các thuật toán tôi sẽ đề cập.
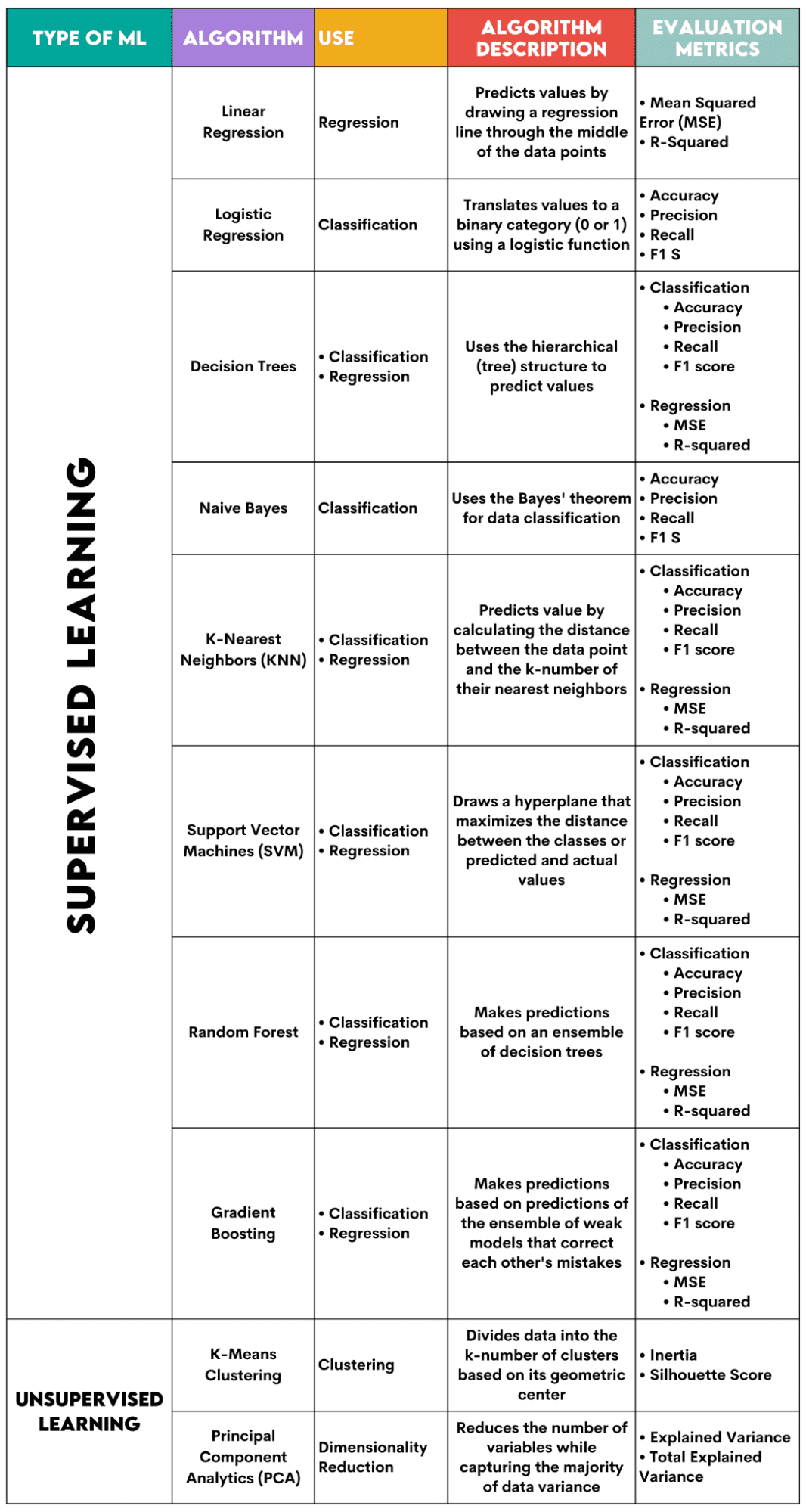
Hình ảnh của Tác giả
Thuật toán học có giám sát
Khi chọn thuật toán cho bài toán của bạn, điều quan trọng là phải biết thuật toán đó được sử dụng cho nhiệm vụ gì.
Là một nhà khoa học dữ liệu, bạn có thể sẽ áp dụng các thuật toán này bằng Python bằng cách sử dụng thư viện scikit-learning. Mặc dù nó thực hiện (gần như) mọi thứ cho bạn, nhưng ít nhất bạn nên biết các nguyên tắc chung về hoạt động bên trong của từng thuật toán.
Cuối cùng, sau khi thuật toán được huấn luyện, bạn nên đánh giá xem nó hoạt động tốt như thế nào. Vì vậy, mỗi thuật toán có một số số liệu tiêu chuẩn.
1. Hồi quy tuyến tính
Được dùng cho: Hồi quy
Sự miêu tả: Hồi quy tuyến tính vẽ một đường thẳng được gọi là đường hồi quy giữa các biến. Đường này đi gần đến giữa các điểm dữ liệu, do đó giảm thiểu sai số ước tính. Nó hiển thị giá trị dự đoán của biến phụ thuộc dựa trên giá trị của các biến độc lập.
Chỉ số đánh giá:
- Lỗi bình phương trung bình (MSE): Biểu thị mức trung bình của sai số bình phương, sai số là chênh lệch giữa giá trị thực tế và giá trị dự đoán. Giá trị càng thấp thì hiệu suất thuật toán càng tốt.
- R-Bình phương: Biểu thị tỷ lệ phần trăm phương sai của biến phụ thuộc mà biến độc lập có thể dự đoán được. Đối với thước đo này, bạn nên cố gắng đạt đến số 1 càng gần càng tốt.
2. Hồi quy logistic
Được dùng cho: phân loại
Sự miêu tả: Nó sử dụng một chức năng hậu cần để dịch các giá trị dữ liệu sang danh mục nhị phân, tức là 0 hoặc 1. Việc này được thực hiện bằng cách sử dụng ngưỡng, thường được đặt ở 0.5. Kết quả nhị phân làm cho thuật toán này trở nên hoàn hảo để dự đoán kết quả nhị phân, chẳng hạn như CÓ/KHÔNG, TRUE/FALSE hoặc 0/1.
Chỉ số đánh giá:
- Độ chính xác: Tỷ lệ giữa dự đoán đúng và tổng dự đoán. Càng gần 1 thì càng tốt.
- Độ chính xác: Thước đo độ chính xác của mô hình trong các dự đoán tích cực; được biểu thị bằng tỷ lệ giữa các dự đoán tích cực chính xác và tổng kết quả tích cực được mong đợi. Càng gần 1 thì càng tốt.
- Nhớ lại: Nó cũng đo lường độ chính xác của mô hình trong các dự đoán tích cực. Nó được biểu thị bằng tỷ lệ giữa các dự đoán tích cực chính xác và tổng số quan sát được thực hiện trong lớp. Đọc thêm về các số liệu này tại đây.
- Điểm F1: Giá trị trung bình hài hòa của độ thu hồi và độ chính xác của mô hình. Càng gần 1 thì càng tốt.
3. Cây quyết định
Được dùng cho: Hồi quy & Phân loại
Sự miêu tả: Cây quyết định là các thuật toán sử dụng cấu trúc phân cấp hoặc cây để dự đoán giá trị hoặc một lớp. Nút gốc đại diện cho toàn bộ tập dữ liệu, sau đó phân nhánh thành các nút quyết định, nhánh và lá dựa trên các giá trị biến.
Chỉ số đánh giá:
- Độ chính xác, độ chính xác, thu hồi và điểm F1 -> để phân loại
- MSE, R bình phương -> cho hồi quy
4. Bayes ngây thơ
Được dùng cho: phân loại
Sự miêu tả: Đây là một họ các thuật toán phân loại sử dụng Định lý Bayes, nghĩa là chúng thừa nhận sự độc lập giữa các tính năng trong một lớp.
Chỉ số đánh giá:
- tính chính xác
- Độ chính xác
- Nhớ lại
- Điểm F1
5. Hàng xóm gần nhất K (KNN)
Được dùng cho: Hồi quy & Phân loại
Sự miêu tả: Nó tính toán khoảng cách giữa dữ liệu thử nghiệm và k-số điểm dữ liệu gần nhất từ dữ liệu huấn luyện. Dữ liệu thử nghiệm thuộc về một lớp có số lượng 'hàng xóm' cao hơn. Về hồi quy, giá trị dự đoán là trung bình của k điểm đào tạo đã chọn.
Chỉ số đánh giá:
- Độ chính xác, độ chính xác, thu hồi và điểm F1 -> để phân loại
- MSE, R bình phương -> cho hồi quy
6. Hỗ trợ Máy Véc tơ (SVM)
Được dùng cho: Hồi quy & Phân loại
Sự miêu tả: Thuật toán này vẽ ra một siêu phẳng để phân biệt các lớp dữ liệu khác nhau. Nó được đặt ở khoảng cách lớn nhất so với các điểm gần nhất của mỗi lớp. Khoảng cách giữa điểm dữ liệu với siêu phẳng càng cao thì nó càng thuộc về lớp của nó. Đối với hồi quy, nguyên tắc tương tự: siêu phẳng tối đa hóa khoảng cách giữa giá trị dự đoán và giá trị thực tế.
Chỉ số đánh giá:
- Độ chính xác, độ chính xác, thu hồi và điểm F1 -> để phân loại
- MSE, R bình phương -> cho hồi quy
7. Rừng Ngẫu Nhiên
Được dùng cho: Hồi quy & Phân loại
Sự miêu tả: Thuật toán rừng ngẫu nhiên sử dụng một tập hợp các cây quyết định, sau đó tạo ra một rừng quyết định. Dự đoán của thuật toán dựa trên dự đoán của nhiều cây quyết định. Dữ liệu sẽ được gán cho lớp nhận được nhiều phiếu bầu nhất. Đối với hồi quy, giá trị dự đoán là giá trị trung bình của tất cả các giá trị dự đoán của cây.
Chỉ số đánh giá:
- Độ chính xác, độ chính xác, thu hồi và điểm F1 -> để phân loại
- MSE, R bình phương -> cho hồi quy
8. Tăng cường độ dốc
Được dùng cho: Hồi quy & Phân loại
Sự miêu tả: Các thuật toán này sử dụng một tập hợp các mô hình yếu, trong đó mỗi mô hình tiếp theo sẽ nhận ra và sửa các lỗi của mô hình trước đó. Quá trình này được lặp lại cho đến khi lỗi (hàm mất mát) được giảm thiểu.
Chỉ số đánh giá:
- Độ chính xác, độ chính xác, thu hồi và điểm F1 -> để phân loại
- MSE, R bình phương -> cho hồi quy
Thuật toán học tập không giám sát
9. Phân cụm K-Means
Được dùng cho: Clustering
Sự miêu tả: Thuật toán chia tập dữ liệu thành các cụm số k, mỗi cụm được biểu thị bằng trung tâm hoặc trung tâm hình học. Thông qua quá trình lặp đi lặp lại việc chia dữ liệu thành k cụm, mục tiêu là giảm thiểu khoảng cách giữa các điểm dữ liệu và tâm của cụm của chúng. Mặt khác, nó cũng cố gắng tối đa hóa khoảng cách giữa các điểm dữ liệu này với tâm của cụm khác. Nói một cách đơn giản, dữ liệu thuộc cùng một cụm phải giống nhau nhất có thể và càng khác biệt với dữ liệu từ các cụm khác.
Chỉ số đánh giá:
- Quán tính: Tổng bình phương khoảng cách của mỗi điểm dữ liệu tính từ tâm cụm gần nhất. Giá trị quán tính càng thấp thì cụm càng nhỏ gọn.
- Điểm Silhouette: Nó đo lường mức độ gắn kết (độ tương tự của dữ liệu trong cụm của chính nó) và sự tách biệt (sự khác biệt của dữ liệu với các cụm khác) của các cụm. Giá trị của điểm này dao động từ -1 đến +1. Giá trị càng cao thì dữ liệu càng được khớp tốt với cụm của nó và dữ liệu càng khớp kém với các cụm khác.
10. Phân tích thành phần chính (PCA)
Được dùng cho: Giảm kích thước
Sự miêu tả: Thuật toán giảm số lượng biến được sử dụng bằng cách xây dựng các biến mới (các thành phần chính) trong khi vẫn cố gắng tối đa hóa phương sai thu được của dữ liệu. Nói cách khác, nó giới hạn dữ liệu ở những thành phần phổ biến nhất trong khi không làm mất đi bản chất của dữ liệu.
Chỉ số đánh giá:
- Phương sai được giải thích: Tỷ lệ phần trăm của phương sai được bao phủ bởi từng thành phần chính.
- Tổng phương sai được giải thích: Tỷ lệ phần trăm của phương sai được bao phủ bởi tất cả các thành phần chính.
Học máy là một phần thiết yếu của khoa học dữ liệu. Với mười thuật toán này, bạn sẽ giải quyết được các tác vụ phổ biến nhất trong học máy. Tất nhiên, phần tổng quan này chỉ cung cấp cho bạn ý tưởng chung về cách hoạt động của từng thuật toán. Vì vậy, đây chỉ là một sự khởi đầu.
Bây giờ, bạn cần học cách triển khai các thuật toán này trong Python và giải quyết các vấn đề thực tế. Trong đó, tôi khuyên bạn nên sử dụng scikit-learn. Không chỉ vì đây là thư viện ML tương đối dễ sử dụng mà còn vì nó vật liệu phong phú về thuật toán ML.
Nate Rosidi là nhà khoa học dữ liệu và phụ trách chiến lược sản phẩm. Anh ấy cũng là giáo sư phụ trợ giảng dạy về phân tích và là người sáng lập StrataScratch, một nền tảng giúp các nhà khoa học dữ liệu chuẩn bị cho các cuộc phỏng vấn của họ bằng các câu hỏi phỏng vấn thực tế từ các công ty hàng đầu. Nate viết về các xu hướng mới nhất trong thị trường nghề nghiệp, đưa ra lời khuyên khi phỏng vấn, chia sẻ các dự án khoa học dữ liệu và đề cập đến mọi thứ về SQL.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/a-beginner-guide-to-the-top-10-machine-learning-algorithms?utm_source=rss&utm_medium=rss&utm_campaign=a-beginners-guide-to-the-top-10-machine-learning-algorithms

