Hình ảnh của Tác giả
Đi sâu vào thế giới khoa học dữ liệu và học máy, một trong những kỹ năng cơ bản bạn sẽ gặp phải là nghệ thuật đọc dữ liệu. Nếu bạn đã có một số kinh nghiệm về nó, có thể bạn đã quen với JSON (Ký hiệu đối tượng JavaScript) – một định dạng phổ biến cho cả việc lưu trữ và trao đổi dữ liệu.
Hãy nghĩ xem các cơ sở dữ liệu NoSQL như MongoDB thích lưu trữ dữ liệu dưới dạng JSON như thế nào hoặc các API REST thường phản hồi theo cùng một định dạng như thế nào.
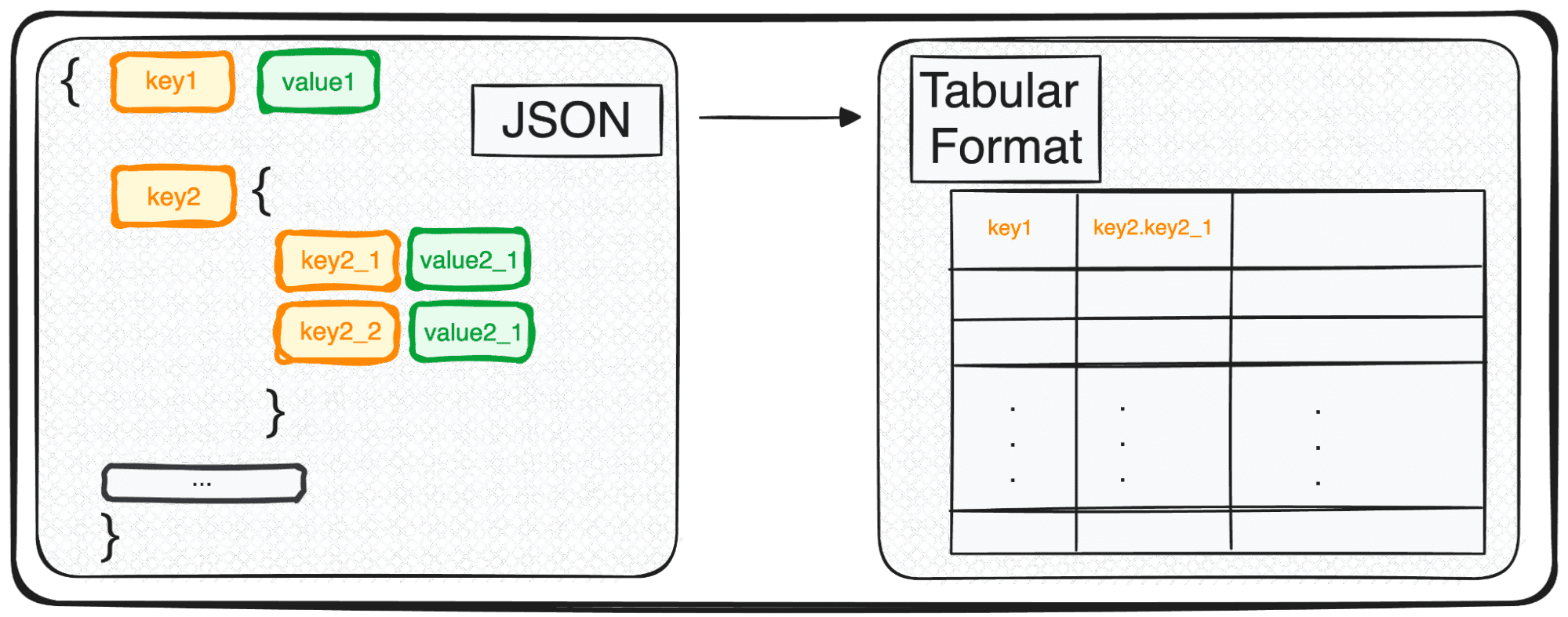
Tuy nhiên, JSON, mặc dù hoàn hảo cho việc lưu trữ và trao đổi, nhưng vẫn chưa sẵn sàng để phân tích chuyên sâu ở dạng thô. Đây là nơi chúng tôi chuyển nó thành thứ gì đó thân thiện hơn về mặt phân tích – định dạng bảng.
Vì vậy, cho dù bạn đang xử lý một đối tượng JSON đơn lẻ hay một mảng thú vị trong số chúng, theo thuật ngữ của Python, về cơ bản bạn đang xử lý một lệnh hoặc một danh sách các lệnh.
Chúng ta hãy cùng nhau khám phá quá trình chuyển đổi này diễn ra như thế nào, khiến dữ liệu của chúng ta chín muồi để phân tích ????
Hôm nay tôi sẽ giải thích một lệnh kỳ diệu cho phép chúng ta dễ dàng phân tích cú pháp bất kỳ JSON nào thành định dạng bảng trong vài giây.
Và nó là… pd.json_normalize()
Vì vậy, hãy xem nó hoạt động như thế nào với các loại JSON khác nhau.
Loại JSON đầu tiên mà chúng ta có thể làm việc là JSON cấp đơn với một vài khóa và giá trị. Chúng tôi xác định các JSON đơn giản đầu tiên của mình như sau:
Mã của tác giả
Vì vậy, hãy mô phỏng nhu cầu làm việc với các JSON này. Tất cả chúng ta đều biết không có nhiều việc phải làm ở định dạng JSON của họ. Chúng ta cần chuyển đổi các JSON này thành một số định dạng có thể đọc được và có thể sửa đổi… có nghĩa là Pandas DataFrames!
1.1 Xử lý các cấu trúc JSON đơn giản
Đầu tiên, chúng ta cần nhập thư viện pandas và sau đó chúng ta có thể sử dụng lệnh pd.json_normalize(), như sau:
import pandas as pd
pd.json_normalize(json_string)
Bằng cách áp dụng lệnh này cho JSON với một bản ghi duy nhất, chúng ta sẽ có được bảng cơ bản nhất. Tuy nhiên, khi dữ liệu của chúng tôi phức tạp hơn một chút và trình bày danh sách JSON, chúng tôi vẫn có thể sử dụng cùng một lệnh mà không gặp phải vấn đề gì thêm và đầu ra sẽ tương ứng với một bảng có nhiều bản ghi.

Hình ảnh của Tác giả
Dễ dàng… phải không?
Câu hỏi tự nhiên tiếp theo là điều gì sẽ xảy ra khi thiếu một số giá trị.
1.2 Xử lý giá trị null
Hãy tưởng tượng một số giá trị không được thông báo, chẳng hạn như bản ghi Thu nhập của David bị thiếu. Khi chuyển JSON của chúng ta thành khung dữ liệu gấu trúc đơn giản, giá trị tương ứng sẽ xuất hiện dưới dạng NaN.

Hình ảnh của Tác giả
Và nếu tôi chỉ muốn lấy một số cánh đồng thì sao?
1.3 Chỉ chọn những cột quan tâm
Trong trường hợp chúng ta chỉ muốn chuyển đổi một số trường cụ thể thành DataFrame dạng bảng, lệnh json_normalize() không cho phép chúng ta chọn trường nào cần chuyển đổi.
Do đó, nên thực hiện một quá trình tiền xử lý nhỏ JSON trong đó chúng tôi chỉ lọc các cột quan tâm đó.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Vì vậy, hãy chuyển sang một số cấu trúc JSON nâng cao hơn.
Khi xử lý các JSON nhiều cấp độ, chúng ta thấy mình có các JSON lồng nhau ở các cấp độ khác nhau. Quy trình vẫn giống như trước, nhưng trong trường hợp này, chúng ta có thể chọn số lượng cấp độ mà chúng ta muốn chuyển đổi. Theo mặc định, lệnh sẽ luôn mở rộng tất cả các cấp độ và tạo các cột mới chứa tên nối của tất cả các cấp độ lồng nhau.
Vì vậy, nếu chúng ta bình thường hóa các JSON sau đây.
Mã của tác giả
Chúng ta sẽ nhận được bảng sau với 3 cột thuộc lĩnh vực kỹ năng:
- kỹ năng.python
- kỹ năng.SQL
- kỹ năng.GCP
và 4 cột theo vai trò trường
- người quản lý vai trò.project
- kỹ sư role.data
- nhà khoa học vai trò.data
- nhà phân tích vai trò.data

Hình ảnh của Tác giả
Tuy nhiên, hãy tưởng tượng chúng ta chỉ muốn thay đổi cấp độ cao nhất của mình. Chúng ta có thể làm như vậy bằng cách xác định cụ thể tham số max_level thành 0 (max_level mà chúng ta muốn mở rộng).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
Các giá trị đang chờ xử lý sẽ được duy trì trong JSON trong DataFrame của gấu trúc của chúng tôi.

Hình ảnh của Tác giả
Trường hợp cuối cùng mà chúng ta có thể tìm thấy là có Danh sách lồng nhau trong trường JSON. Vì vậy, trước tiên chúng tôi xác định JSON của mình để sử dụng.
Mã của tác giả
Chúng tôi có thể quản lý dữ liệu này một cách hiệu quả bằng cách sử dụng Pandas trong Python. Hàm pd.json_normalize() đặc biệt hữu ích trong ngữ cảnh này. Nó có thể làm phẳng dữ liệu JSON, bao gồm cả danh sách lồng nhau, thành định dạng có cấu trúc phù hợp để phân tích. Khi hàm này được áp dụng cho dữ liệu JSON của chúng tôi, nó sẽ tạo ra một bảng chuẩn hóa kết hợp danh sách lồng nhau như một phần của các trường của nó.
Hơn nữa, Pandas còn cung cấp khả năng tinh chỉnh thêm quy trình này. Bằng cách sử dụng tham số record_path trong pd.json_normalize(), chúng ta có thể chỉ đạo hàm chuẩn hóa cụ thể danh sách lồng nhau.
Hành động này dẫn đến một bảng dành riêng cho nội dung của danh sách. Theo mặc định, quá trình này sẽ chỉ mở ra các phần tử trong danh sách. Tuy nhiên, để làm phong phú bảng này bằng ngữ cảnh bổ sung, chẳng hạn như giữ lại ID liên kết cho mỗi bản ghi, chúng ta có thể sử dụng tham số meta.

Hình ảnh của Tác giả
Tóm lại, việc chuyển đổi dữ liệu JSON thành tệp CSV bằng thư viện Pandas của Python rất dễ dàng và hiệu quả.
JSON vẫn là định dạng phổ biến nhất trong lưu trữ và trao đổi dữ liệu hiện đại, đặc biệt là trong cơ sở dữ liệu NoSQL và API REST. Tuy nhiên, nó đưa ra một số thách thức phân tích quan trọng khi xử lý dữ liệu ở định dạng thô.
Vai trò then chốt của pd.json_normalize() của Pandas nổi lên như một cách tuyệt vời để xử lý các định dạng như vậy và chuyển đổi dữ liệu của chúng ta thành DataFrame của gấu trúc.
Tôi hy vọng hướng dẫn này hữu ích và lần tới khi xử lý JSON, bạn có thể thực hiện nó theo cách hiệu quả hơn.
Bạn có thể kiểm tra Notebook Jupyter tương ứng trong theo dõi GitHub repo.
Josep Ferrer là một kỹ sư phân tích từ Barcelona. Anh tốt nghiệp kỹ sư vật lý và hiện đang làm việc trong lĩnh vực Khoa học dữ liệu ứng dụng cho khả năng di chuyển của con người. Anh ấy là người sáng tạo nội dung bán thời gian tập trung vào khoa học dữ liệu và công nghệ. Bạn có thể liên hệ với anh ấy trên LinkedIn, Twitter or Trung bình.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way

