Đây là bài đăng của khách được đồng sáng tác với nhóm PyTorch của Meta và là sự tiếp nối của Phần 1 của loạt bài này, nơi chúng tôi chứng minh hiệu suất và sự dễ dàng khi chạy PyTorch 2.0 trên AWS.
Nghiên cứu về máy học (ML) đã chứng minh rằng các mô hình ngôn ngữ lớn (LLM) được đào tạo với bộ dữ liệu lớn đáng kể sẽ mang lại chất lượng mô hình tốt hơn. Trong vài năm gần đây, quy mô của các mô hình thế hệ hiện tại đã tăng lên đáng kể và chúng đòi hỏi các công cụ và cơ sở hạ tầng hiện đại để được đào tạo một cách hiệu quả và trên quy mô lớn. Tính song song dữ liệu phân tán PyTorch (DDP) giúp xử lý dữ liệu trên quy mô lớn một cách đơn giản và mạnh mẽ, nhưng nó yêu cầu mô hình phải vừa với một GPU. Thư viện PyTorch Full Sharded Data Parallel (FSDP) phá vỡ rào cản này bằng cách cho phép phân chia mô hình để đào tạo các mô hình lớn trên các trình xử lý song song dữ liệu.
Đào tạo mô hình phân tán yêu cầu một cụm nút công nhân có thể mở rộng quy mô. Dịch vụ Kubernetes đàn hồi của Amazon (Amazon EKS) là một dịch vụ tuân thủ Kubernetes phổ biến giúp đơn giản hóa đáng kể quy trình chạy khối lượng công việc AI/ML, giúp dễ quản lý hơn và tốn ít thời gian hơn.
Trong bài đăng trên blog này, AWS cộng tác với nhóm PyTorch của Meta để thảo luận cách sử dụng thư viện PyTorch FSDP nhằm đạt được quy mô tuyến tính của các mô hình deep learning trên AWS một cách liền mạch bằng cách sử dụng Amazon EKS và AWS Deep Learning Container (DLC). Chúng tôi chứng minh điều này thông qua việc triển khai từng bước các mô hình đào tạo 7B, 13B và 70B Llama2 bằng Amazon EKS với 16 Đám mây điện toán đàn hồi Amazon (Amazon EC2) p4de.24xlarge phiên bản (mỗi GPU có 8 GPU NVIDIA A100 Tensor Core và mỗi GPU có bộ nhớ HBM80e 2 GB) hoặc 16 EC2 p5.48xlund (mỗi phiên bản có 8 GPU NVIDIA H100 Tensor Core và mỗi GPU có bộ nhớ HBM80 3 GB), đạt được thông lượng có quy mô gần như tuyến tính và cuối cùng là cho phép thời gian đào tạo nhanh hơn.
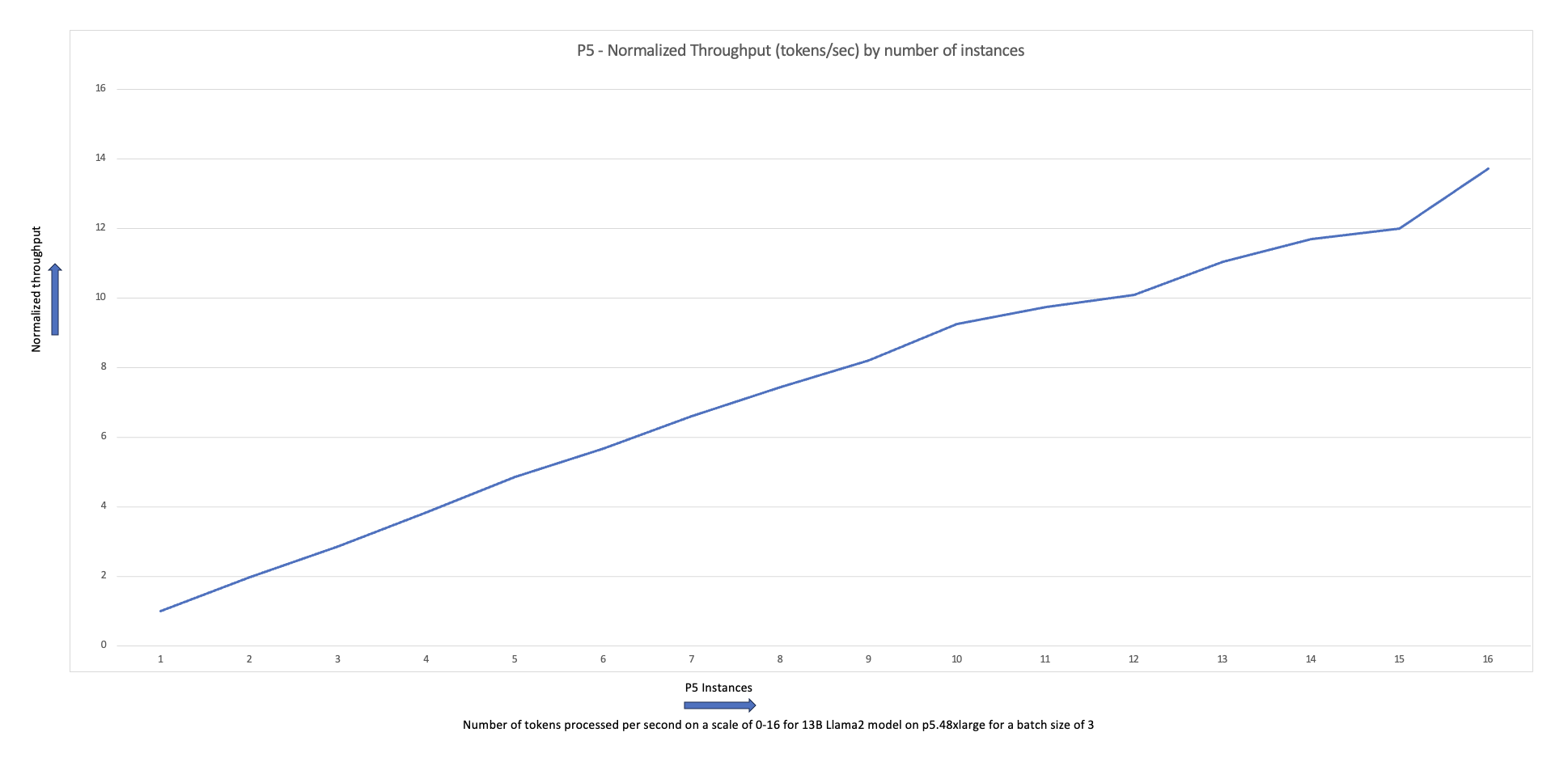
Biểu đồ chia tỷ lệ sau đây cho thấy các phiên bản p5.48xlarge mang lại hiệu suất mở rộng 87% nhờ tính năng tinh chỉnh FSDP Llama2 trong cấu hình cụm 16 nút.
Những thách thức của việc đào tạo LLM
Các doanh nghiệp đang ngày càng áp dụng LLM cho nhiều nhiệm vụ, bao gồm trợ lý ảo, dịch thuật, tạo nội dung và thị giác máy tính, để nâng cao hiệu quả và độ chính xác trong nhiều ứng dụng.
Tuy nhiên, việc đào tạo hoặc tinh chỉnh các mô hình lớn này cho trường hợp sử dụng tùy chỉnh đòi hỏi một lượng lớn dữ liệu và sức mạnh tính toán, điều này làm tăng thêm độ phức tạp kỹ thuật tổng thể của ngăn xếp ML. Điều này cũng là do bộ nhớ khả dụng trên một GPU có hạn, điều này hạn chế kích thước của mô hình có thể được đào tạo và cũng giới hạn kích thước lô trên mỗi GPU được sử dụng trong quá trình đào tạo.
Để giải quyết thách thức này, nhiều kỹ thuật mô hình song song khác nhau như DeepSpeed Zero và PyTorch FSDP được tạo ra để cho phép bạn vượt qua rào cản về bộ nhớ GPU hạn chế này. Điều này được thực hiện bằng cách áp dụng kỹ thuật song song dữ liệu được phân chia, trong đó mỗi bộ tăng tốc chỉ giữ một lát (một mảnh vỡ) của bản sao mô hình thay vì toàn bộ bản sao mô hình, điều này làm giảm đáng kể dung lượng bộ nhớ của công việc đào tạo.
Bài đăng này trình bày cách bạn có thể sử dụng PyTorch FSDP để tinh chỉnh mô hình Llama2 bằng Amazon EKS. Chúng tôi đạt được điều này bằng cách mở rộng quy mô công suất tính toán và GPU để giải quyết các yêu cầu của mô hình.
Tổng quan về FSDP
Trong đào tạo PyTorch DDP, mỗi GPU (được gọi là công nhân trong ngữ cảnh của PyTorch) giữ một bản sao hoàn chỉnh của mô hình, bao gồm trọng số mô hình, độ dốc và trạng thái tối ưu hóa. Mỗi công nhân xử lý một loạt dữ liệu và khi kết thúc quá trình lùi, sử dụng một giảm toàn bộ hoạt động để đồng bộ hóa độ dốc giữa các công nhân khác nhau.
Việc có một bản sao của mô hình trên mỗi GPU sẽ hạn chế kích thước của mô hình có thể được cung cấp trong quy trình làm việc DDP. FSDP giúp khắc phục hạn chế này bằng cách phân chia các tham số mô hình, trạng thái tối ưu hóa và độ dốc trên các trình xử lý song song dữ liệu trong khi vẫn duy trì tính đơn giản của song song dữ liệu.
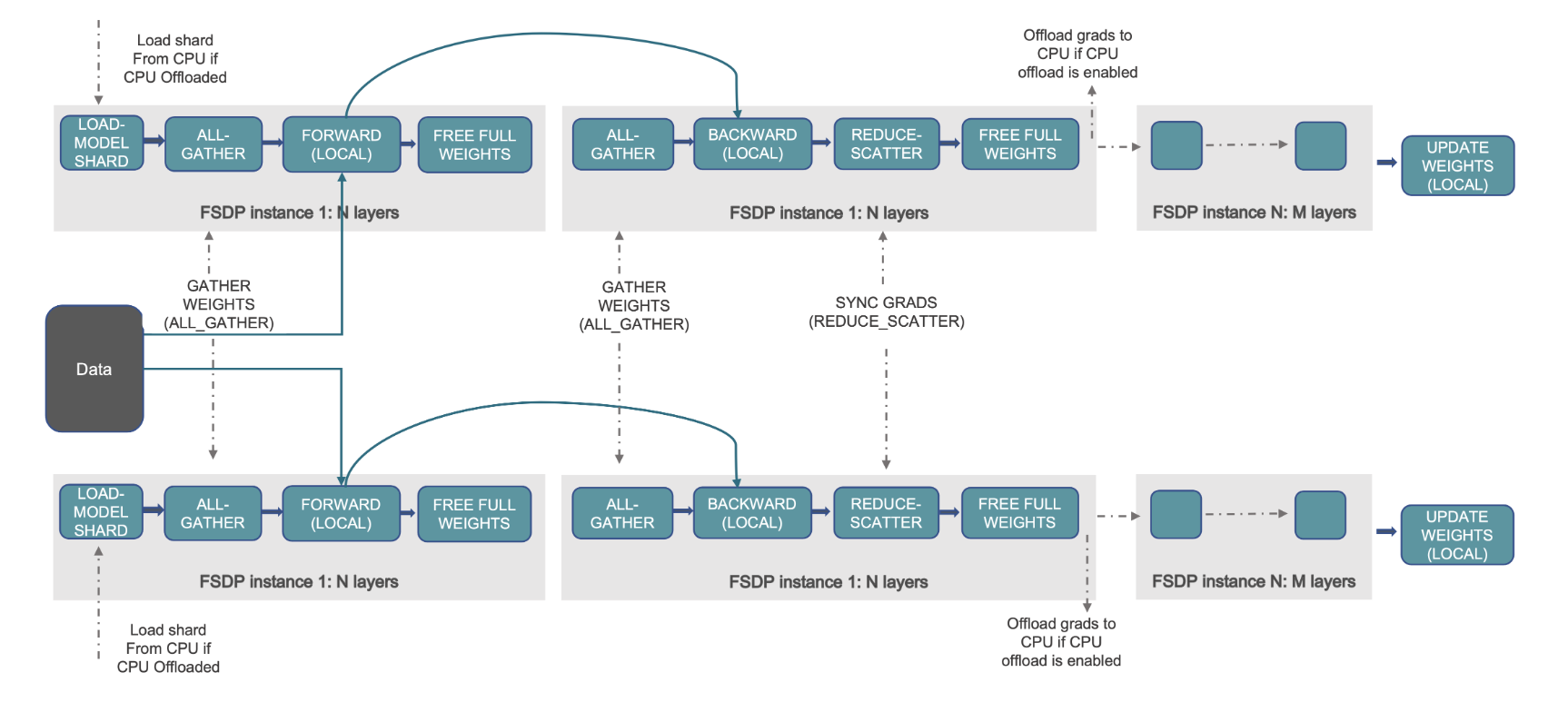
Điều này được thể hiện trong sơ đồ sau, trong trường hợp DDP, mỗi GPU giữ một bản sao hoàn chỉnh của trạng thái mô hình, bao gồm trạng thái tối ưu hóa (OS), độ dốc (G) và tham số (P): M(OS + G +P). Trong FSDP, mỗi GPU chỉ giữ một phần trạng thái mô hình, bao gồm trạng thái tối ưu hóa (OS), độ dốc (G) và tham số (P): M (HĐH + G + P). Việc sử dụng FSDP dẫn đến sử dụng bộ nhớ GPU nhỏ hơn đáng kể so với DDP trên tất cả nhân viên, cho phép đào tạo các mô hình rất lớn hoặc sử dụng kích thước lô lớn hơn cho công việc đào tạo.

Tuy nhiên, điều này phải trả giá bằng chi phí liên lạc tăng lên, được giảm thiểu thông qua tối ưu hóa FSDP, chẳng hạn như các quy trình tính toán và liên lạc chồng chéo với các tính năng như tìm nạp trước. Để biết thêm thông tin chi tiết, hãy tham khảo Bắt đầu với song song dữ liệu được phân chia hoàn toàn (FSDP).
FSDP cung cấp nhiều thông số khác nhau cho phép bạn điều chỉnh hiệu suất và hiệu quả của công việc đào tạo của mình. Một số tính năng và khả năng chính của FSDP bao gồm:
- Chính sách gói máy biến áp
- Độ chính xác hỗn hợp linh hoạt
- Kiểm tra kích hoạt
- Các chiến lược phân chia khác nhau để phù hợp với tốc độ mạng và cấu trúc liên kết cụm khác nhau:
- ĐẦY ĐỦ_SHARD – Tham số mô hình phân đoạn, độ dốc và trạng thái tối ưu hóa
- HYBRID_SHARD – Phân đoạn đầy đủ trong một nút DDP trên các nút; hỗ trợ nhóm sharding linh hoạt để có bản sao đầy đủ của mô hình (HSDP)
- SHARD_GRAD_OP – Phân đoạn chỉ độ dốc và trạng thái tối ưu hóa
- KHÔNG_SHARD – Tương tự như DDP
Để biết thêm thông tin về FSDP, hãy tham khảo Đào tạo quy mô lớn hiệu quả với Pytorch FSDP và AWS.
Hình dưới đây cho thấy cách FSDP hoạt động đối với hai quy trình song song dữ liệu.
Tổng quan về giải pháp
Trong bài đăng này, chúng tôi đã thiết lập một cụm điện toán bằng Amazon EKS, một dịch vụ được quản lý để chạy Kubernetes trên Đám mây AWS và các trung tâm dữ liệu tại chỗ. Nhiều khách hàng đang sử dụng Amazon EKS để chạy khối lượng công việc AI/ML dựa trên Kubernetes, tận dụng hiệu suất, khả năng mở rộng, độ tin cậy và tính khả dụng cũng như khả năng tích hợp của nó với mạng AWS, bảo mật và các dịch vụ khác.
Đối với trường hợp sử dụng FSDP của chúng tôi, chúng tôi sử dụng Nhà điều hành đào tạo Kubeflow trên Amazon EKS, một dự án dựa trên Kubernetes nhằm tạo điều kiện đào tạo tinh chỉnh và phân tán có thể mở rộng cho các mô hình ML. Nó hỗ trợ nhiều khung ML khác nhau, bao gồm PyTorch, mà bạn có thể sử dụng để triển khai và quản lý các công việc đào tạo PyTorch trên quy mô lớn.
Bằng cách sử dụng tài nguyên tùy chỉnh PyTorchJob của Kubeflow Training Operator, chúng tôi chạy các công việc đào tạo trên Kubernetes với số lượng bản sao nhân viên có thể định cấu hình cho phép chúng tôi tối ưu hóa việc sử dụng tài nguyên.
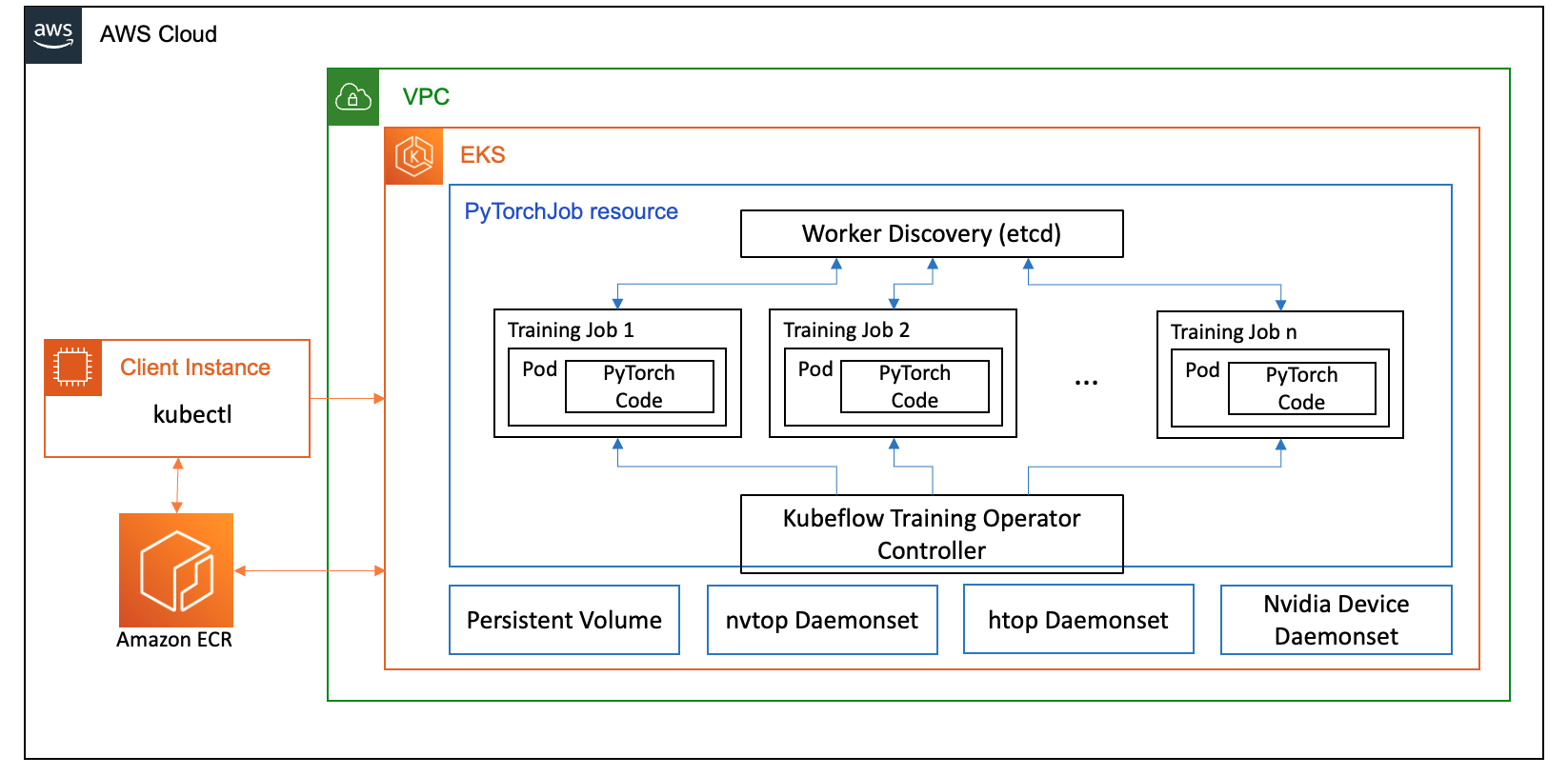
Sau đây là một số thành phần của toán tử đào tạo đóng vai trò trong trường hợp sử dụng tinh chỉnh Llama2 của chúng tôi:
- Bộ điều khiển Kubernetes tập trung điều phối các công việc đào tạo phân tán cho PyTorch.
- PyTorchJob, tài nguyên tùy chỉnh Kubernetes dành cho PyTorch, do Nhà điều hành đào tạo Kubeflow cung cấp, để xác định và triển khai các công việc đào tạo Llama2 trên Kubernetes.
- etcd, liên quan đến việc triển khai cơ chế điểm hẹn để điều phối đào tạo phân tán của các mô hình PyTorch. Cái này
etcdmáy chủ, như một phần của quy trình điểm hẹn, tạo điều kiện thuận lợi cho sự phối hợp và đồng bộ hóa của các công nhân tham gia trong quá trình đào tạo phân tán.
Sơ đồ sau minh họa kiến trúc giải pháp.
Hầu hết các chi tiết sẽ được tóm tắt bằng các tập lệnh tự động hóa mà chúng tôi sử dụng để chạy ví dụ Llama2.
Chúng tôi sử dụng các tham chiếu mã sau trong trường hợp sử dụng này:
Llama2 là gì?
Llama2 là một LLM được đào tạo trước trên 2 nghìn tỷ mã thông báo văn bản và mã. Đây là một trong những LLM lớn nhất và mạnh nhất hiện nay. Bạn có thể sử dụng Llama2 cho nhiều tác vụ khác nhau, bao gồm xử lý ngôn ngữ tự nhiên (NLP), tạo văn bản và dịch thuật. Để biết thêm thông tin, hãy tham khảo Bắt đầu với Llama.
Llama2 có sẵn ở ba kích cỡ mô hình khác nhau:
- Llama2-70b – Đây là mô hình Llama2 lớn nhất, với 70 tỷ tham số. Đây là mô hình Llama2 mạnh mẽ nhất và có thể được sử dụng cho những tác vụ đòi hỏi khắt khe nhất.
- Llama2-13b – Đây là model Llama2 cỡ trung bình, có 13 tỷ thông số. Đó là sự cân bằng tốt giữa hiệu suất và hiệu quả, đồng thời có thể được sử dụng cho nhiều nhiệm vụ khác nhau.
- Llama2-7b – Đây là model Llama2 nhỏ nhất, có 7 tỷ tham số. Đây là mô hình Llama2 hiệu quả nhất và có thể được sử dụng cho các tác vụ không yêu cầu mức hiệu suất cao nhất.
Bài đăng này cho phép bạn tinh chỉnh tất cả các mô hình này trên Amazon EKS. Để cung cấp trải nghiệm đơn giản và có thể tái tạo trong việc tạo cụm EKS và chạy các công việc FSDP trên đó, chúng tôi sử dụng ôi-ôi-ôi dự án. Ví dụ này cũng sẽ hoạt động với cụm EKS có sẵn.
Hướng dẫn theo kịch bản có sẵn trên GitHub để có trải nghiệm vượt trội. Trong các phần sau, chúng tôi sẽ giải thích quy trình từ đầu đến cuối chi tiết hơn.
Cung cấp hạ tầng giải pháp
Đối với các thử nghiệm được mô tả trong bài đăng này, chúng tôi sử dụng các cụm có nút p4de (GPU A100) và p5 (GPU H100).
Cụm với các nút p4de.24xlarge
Đối với cụm của chúng tôi có các nút p4de, chúng tôi sử dụng như sau eks-gpu-p4de-odcr.yaml kịch bản:
Sử dụng eksctl và bảng kê khai cụm trước đó, chúng tôi tạo một cụm có các nút p4de:
Cụm có các nút p5.48xlarge
Mẫu địa hình cho cụm EKS với các nút P5 được đặt ở phần sau Repo GitHub.
Bạn có thể tùy chỉnh cụm thông qua biến.tf file và sau đó tạo nó thông qua Terraform CLI:
Bạn có thể xác minh tính khả dụng của cụm bằng cách chạy lệnh kubectl đơn giản:
Cụm hoạt động tốt nếu đầu ra của lệnh này hiển thị số lượng nút dự kiến ở trạng thái Sẵn sàng.
Triển khai các điều kiện tiên quyết
Để chạy FSDP trên Amazon EKS, chúng tôi sử dụng PyTorchCông Việc tài nguyên tùy chỉnh. Nó yêu cầu vvd và Nhà điều hành đào tạo Kubeflow như những điều kiện tiên quyết.
Triển khai etcd với đoạn mã sau:
Triển khai Toán tử đào tạo Kubeflow với mã sau:
Xây dựng và đẩy hình ảnh vùng chứa FSDP lên Amazon ECR
Sử dụng đoạn mã sau để xây dựng hình ảnh vùng chứa FSDP và đẩy nó vào Đăng ký container đàn hồi Amazon (ECR của Amazon):
Tạo bảng kê khai FSDP PyTorchJob
Chèn của bạn Mã thông báo ôm mặt trong đoạn mã sau trước khi chạy nó:
Định cấu hình PyTorchJob của bạn với .NS file hoặc trực tiếp trong các biến môi trường của bạn như sau:
Tạo bảng kê khai PyTorchJob bằng cách sử dụng mẫu fsdp và tạo.sh tập lệnh hoặc tạo trực tiếp bằng tập lệnh bên dưới:
Chạy PyTorchJob
Chạy PyTorchJob với mã sau:
Bạn sẽ thấy số lượng nhóm công nhân FDSP được chỉ định đã được tạo và sau khi kéo hình ảnh, chúng sẽ chuyển sang trạng thái Đang chạy.
Để xem trạng thái của PyTorchJob, hãy sử dụng mã sau:
Để dừng PyTorchJob, hãy sử dụng mã sau:
Sau khi một công việc hoàn thành, nó cần được xóa trước khi bắt đầu một công việc mới. Chúng tôi cũng nhận thấy rằng việc xóaetcdpod và để nó khởi động lại trước khi bắt đầu một công việc mới sẽ giúp tránh được RendezvousClosedError.
Chia tỷ lệ cụm
Bạn có thể lặp lại các bước tạo và chạy công việc trước đó trong khi thay đổi số lượng và loại phiên bản của nút công việc trong cụm. Điều này cho phép bạn tạo biểu đồ tỷ lệ giống như biểu đồ được hiển thị trước đó. Nói chung, bạn sẽ thấy dung lượng bộ nhớ GPU giảm, thời gian epoch giảm và thông lượng tăng khi có nhiều nút hơn được thêm vào cụm. Biểu đồ trước đó được tạo ra bằng cách tiến hành một số thử nghiệm sử dụng nhóm nút p5 có kích thước khác nhau từ 1–16 nút.
Tuân thủ khối lượng đào tạo của FSDP
Khả năng quan sát khối lượng công việc trí tuệ nhân tạo tổng hợp là rất quan trọng để cho phép hiển thị các công việc đang chạy của bạn cũng như hỗ trợ tối đa hóa việc sử dụng tài nguyên máy tính của bạn. Trong bài đăng này, chúng tôi sử dụng một số công cụ quan sát nguồn mở và gốc của Kubernetes cho mục đích này. Những công cụ này cho phép bạn theo dõi lỗi, số liệu thống kê và hành vi của mô hình, khiến khả năng quan sát của AI trở thành một phần quan trọng trong mọi trường hợp sử dụng kinh doanh. Trong phần này, chúng tôi trình bày các cách tiếp cận khác nhau để quan sát các công việc đào tạo của FSDP.
Nhật ký nhóm công nhân
Ở cấp độ cơ bản nhất, bạn cần có khả năng xem nhật ký của nhóm đào tạo của mình. Điều này có thể dễ dàng được thực hiện bằng cách sử dụng các lệnh gốc Kubernetes.
Đầu tiên, truy xuất danh sách các nhóm và tìm tên của nhóm mà bạn muốn xem nhật ký:
Sau đó xem nhật ký cho nhóm đã chọn:

Chỉ có một nhật ký nhóm của công nhân (người lãnh đạo được bầu) sẽ liệt kê số liệu thống kê công việc tổng thể. Tên của nhóm lãnh đạo được bầu có sẵn ở đầu mỗi nhật ký nhóm công nhân, được xác định bằng khóa master_addr=.
Sử dụng CPU
Khối lượng công việc đào tạo phân tán yêu cầu cả tài nguyên CPU và GPU. Để tối ưu hóa những khối lượng công việc này, điều quan trọng là phải hiểu cách sử dụng các tài nguyên này. May mắn thay, hiện có sẵn một số tiện ích nguồn mở tuyệt vời giúp trực quan hóa việc sử dụng CPU và GPU. Để xem việc sử dụng CPU, bạn có thể sử dụnghtop. Nếu nhóm công nhân của bạn chứa tiện ích này, bạn có thể sử dụng lệnh bên dưới để mở shell vào nhóm rồi chạyhtop.
Ngoài ra, bạn có thể triển khai htopdaemonsetgiống như cái được cung cấp sau đây Repo GitHub.
Sản phẩmdaemonsetsẽ chạy một nhóm htop nhẹ trên mỗi nút. Bạn có thể thực thi vào bất kỳ nhóm nào trong số này và chạyhtopchỉ huy:
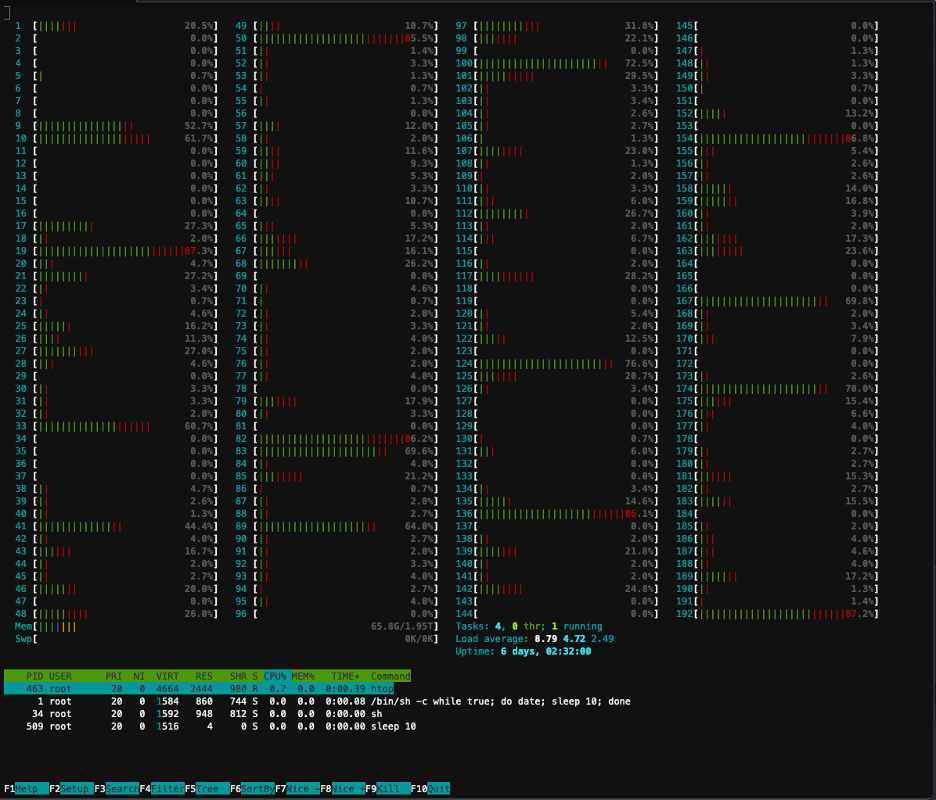
Ảnh chụp màn hình sau đây hiển thị mức sử dụng CPU trên một trong các nút trong cụm. Trong trường hợp này, chúng tôi đang xem xét một phiên bản P5.48xlarge có 192 vCPU. Các lõi bộ xử lý không hoạt động trong khi trọng lượng mô hình được tải xuống và chúng tôi thấy mức sử dụng tăng lên trong khi trọng số mô hình đang được tải vào bộ nhớ GPU.
Sử dụng GPU
Nếunvtoptiện ích có sẵn trong nhóm của bạn, bạn có thể thực thi nó bằng cách sử dụng bên dưới rồi chạynvtop.
Ngoài ra, bạn có thể triển khai nvtopdaemonsetgiống như cái được cung cấp sau đây Repo GitHub.
Điều này sẽ chạy mộtnvtoppod trên mỗi nút. Bạn có thể thực thi vào bất kỳ nhóm nào trong số đó và chạynvtop:
Ảnh chụp màn hình sau đây hiển thị việc sử dụng GPU trên một trong các nút trong cụm đào tạo. Trong trường hợp này, chúng tôi đang xem xét một phiên bản P5.48xlarge có 8 GPU NVIDIA H100. GPU không hoạt động trong khi trọng lượng mô hình được tải xuống, sau đó mức sử dụng bộ nhớ GPU tăng lên khi trọng lượng mô hình được tải lên GPU và mức sử dụng GPU tăng vọt lên 100% trong khi quá trình lặp lại huấn luyện đang được tiến hành.

Trang tổng quan Grafana
Bây giờ bạn đã hiểu cách hệ thống của mình hoạt động ở cấp độ nhóm và nút, điều quan trọng là phải xem xét các số liệu ở cấp độ cụm. Các số liệu sử dụng tổng hợp có thể được NVIDIA DCGM Importer và Prometheus thu thập và hiển thị trong Grafana.
Một ví dụ về triển khai Prometheus-Grafana có sẵn sau đây Repo GitHub.
Một ví dụ về triển khai nhà xuất khẩu DCGM có sẵn sau đây Repo GitHub.
Bảng điều khiển Grafana đơn giản được hiển thị trong ảnh chụp màn hình sau. Nó được xây dựng bằng cách chọn các số liệu DCGM sau: DCGM_FI_DEV_GPU_UTIL, DCGM_FI_MEM_COPY_UTIL, DCGM_FI_DEV_XID_ERRORS, DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_GPU_TEMPvà DCGM_FI_DEV_POWER_USAGE. Bảng điều khiển có thể được nhập vào Prometheus từ GitHub.
Bảng thông tin sau đây hiển thị một lần chạy công việc đào tạo kỷ nguyên đơn Llama2 7b. Các biểu đồ cho thấy rằng khi xung nhịp của bộ xử lý phát trực tuyến (SM) tăng lên, mức tiêu thụ điện năng và nhiệt độ của GPU cũng tăng theo, cùng với việc sử dụng GPU và bộ nhớ. Bạn cũng có thể thấy rằng không có lỗi XID nào và GPU vẫn hoạt động tốt trong quá trình chạy này.
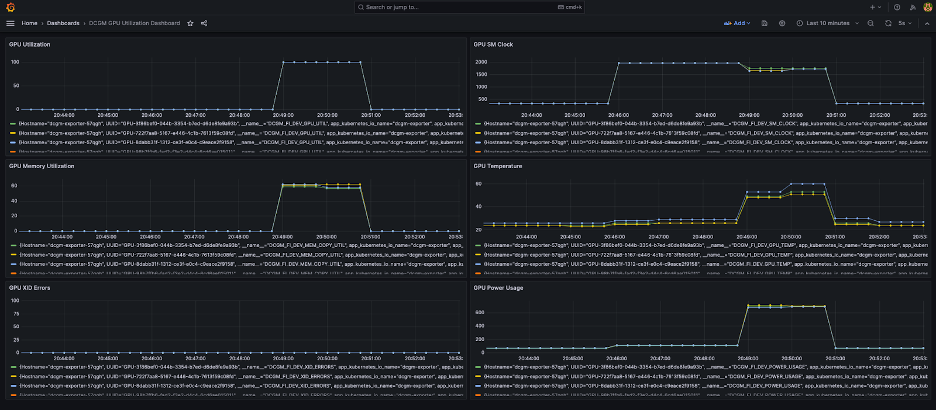
Kể từ tháng 2024 năm XNUMX, khả năng quan sát GPU cho EKS được hỗ trợ nguyên bản trong Thông tin chi tiết về vùng chứa CloudWatch. Để kích hoạt chức năng này, chỉ cần triển khai Tiện ích bổ sung khả năng quan sát CloudWatch trong cụm EKS của bạn. Sau đó, bạn sẽ có thể duyệt qua các số liệu ở cấp độ nhóm, nút và cụm thông qua các trang tổng quan có thể tùy chỉnh và định cấu hình sẵn trong Thông tin chi tiết về vùng chứa.
Làm sạch
Nếu bạn đã tạo cụm bằng cách sử dụng các ví dụ được cung cấp trong blog này thì bạn có thể thực thi đoạn mã sau để xóa cụm và mọi tài nguyên được liên kết với nó, bao gồm cả VPC:
Đối với eksctl:
Đối với địa hình:
Tính năng sắp tới
FSDP dự kiến sẽ bao gồm tính năng phân chia theo từng tham số, nhằm mục đích cải thiện hơn nữa dung lượng bộ nhớ trên mỗi GPU. Ngoài ra, sự phát triển liên tục của hỗ trợ FP8 nhằm mục đích cải thiện hiệu suất FSDP trên GPU H100. Cuối cùng, khi FSDP được tích hợp vớitorch.compile, chúng tôi hy vọng sẽ thấy những cải tiến bổ sung về hiệu suất và hỗ trợ các tính năng như điểm kiểm tra kích hoạt có chọn lọc.
Kết luận
Trong bài đăng này, chúng tôi đã thảo luận về cách FSDP giảm dung lượng bộ nhớ trên mỗi GPU, cho phép đào tạo các mô hình lớn hơn hiệu quả hơn và đạt được quy mô thông lượng gần như tuyến tính. Chúng tôi đã chứng minh điều này thông qua việc triển khai từng bước quá trình đào tạo mô hình Llama2 bằng Amazon EKS trên các phiên bản P4de và P5, đồng thời sử dụng các công cụ có khả năng quan sát như kubectl, htop, nvtop và dcgm để giám sát nhật ký cũng như việc sử dụng CPU và GPU.
Chúng tôi khuyến khích bạn tận dụng PyTorch FSDP cho công việc đào tạo LLM của riêng bạn. Bắt đầu tại aws-do-fsdp.
Về các tác giả
 Kanwaljit Khurmi là Kiến trúc sư giải pháp AI/ML chính tại Amazon Web Services. Anh làm việc với khách hàng của AWS để cung cấp hướng dẫn và hỗ trợ kỹ thuật, giúp họ cải thiện giá trị của các giải pháp machine learning trên AWS. Kanwaljit chuyên hỗ trợ khách hàng về các ứng dụng điện toán phân tán, được đóng gói và học sâu.
Kanwaljit Khurmi là Kiến trúc sư giải pháp AI/ML chính tại Amazon Web Services. Anh làm việc với khách hàng của AWS để cung cấp hướng dẫn và hỗ trợ kỹ thuật, giúp họ cải thiện giá trị của các giải pháp machine learning trên AWS. Kanwaljit chuyên hỗ trợ khách hàng về các ứng dụng điện toán phân tán, được đóng gói và học sâu.
 Alex Iankoulski là Kiến trúc sư giải pháp chính, Máy học tự quản lý tại AWS. Anh ấy là một kỹ sư cơ sở hạ tầng và phần mềm toàn diện, thích làm những công việc thực tế và sâu sắc. Trong vai trò của mình, anh tập trung vào việc hỗ trợ khách hàng sắp xếp và điều phối khối lượng công việc ML và AI trên các dịch vụ AWS chạy bằng container. Ông cũng là tác giả của nguồn mở làm khuôn khổ và một thuyền trưởng Docker yêu thích ứng dụng công nghệ container để đẩy nhanh tốc độ đổi mới đồng thời giải quyết những thách thức lớn nhất của thế giới.
Alex Iankoulski là Kiến trúc sư giải pháp chính, Máy học tự quản lý tại AWS. Anh ấy là một kỹ sư cơ sở hạ tầng và phần mềm toàn diện, thích làm những công việc thực tế và sâu sắc. Trong vai trò của mình, anh tập trung vào việc hỗ trợ khách hàng sắp xếp và điều phối khối lượng công việc ML và AI trên các dịch vụ AWS chạy bằng container. Ông cũng là tác giả của nguồn mở làm khuôn khổ và một thuyền trưởng Docker yêu thích ứng dụng công nghệ container để đẩy nhanh tốc độ đổi mới đồng thời giải quyết những thách thức lớn nhất của thế giới.
 Ana Simoes là Chuyên gia chính về học máy, ML Frameworks tại AWS. Cô hỗ trợ khách hàng triển khai AI, ML và AI tổng quát ở quy mô lớn trên cơ sở hạ tầng HPC trên đám mây. Ana tập trung vào việc hỗ trợ khách hàng đạt được hiệu quả về giá cho khối lượng công việc mới và các trường hợp sử dụng cho AI tổng hợp và học máy.
Ana Simoes là Chuyên gia chính về học máy, ML Frameworks tại AWS. Cô hỗ trợ khách hàng triển khai AI, ML và AI tổng quát ở quy mô lớn trên cơ sở hạ tầng HPC trên đám mây. Ana tập trung vào việc hỗ trợ khách hàng đạt được hiệu quả về giá cho khối lượng công việc mới và các trường hợp sử dụng cho AI tổng hợp và học máy.
 Hamid Shojanazeri là Kỹ sư đối tác tại PyTorch làm việc về mã nguồn mở, tối ưu hóa mô hình hiệu suất cao, đào tạo phân tán (FSDP) và suy luận. Ông là người đồng sáng tạo công thức llama và người đóng góp cho ngọn đuốcphục vụ. Mối quan tâm chính của ông là cải thiện hiệu quả chi phí, giúp AI dễ tiếp cận hơn với cộng đồng rộng lớn hơn.
Hamid Shojanazeri là Kỹ sư đối tác tại PyTorch làm việc về mã nguồn mở, tối ưu hóa mô hình hiệu suất cao, đào tạo phân tán (FSDP) và suy luận. Ông là người đồng sáng tạo công thức llama và người đóng góp cho ngọn đuốcphục vụ. Mối quan tâm chính của ông là cải thiện hiệu quả chi phí, giúp AI dễ tiếp cận hơn với cộng đồng rộng lớn hơn.
 Ít Wright hơn là Kỹ sư AI/Đối tác tại PyTorch. Anh ấy làm việc trên hạt nhân Triton/CUDA (Tăng tốc Dequant với phân tách công việc SplitK); trình tối ưu hóa phân trang, phát trực tuyến và lượng tử hóa; và phân phối PyTorch (PyTorch FSDP).
Ít Wright hơn là Kỹ sư AI/Đối tác tại PyTorch. Anh ấy làm việc trên hạt nhân Triton/CUDA (Tăng tốc Dequant với phân tách công việc SplitK); trình tối ưu hóa phân trang, phát trực tuyến và lượng tử hóa; và phân phối PyTorch (PyTorch FSDP).
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/scale-llms-with-pytorch-2-0-fsdp-on-amazon-eks-part-2/

