Dịch vụ Tìm kiếm Mở của Amazon gần đây đã giới thiệu dòng Phiên bản được tối ưu hóa cho OpenSearch (OR1), giúp cải thiện hiệu suất về giá lên tới 30% so với các phiên bản được tối ưu hóa bộ nhớ hiện có trong các điểm chuẩn nội bộ và sử dụng Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) để cung cấp độ bền 11 giây. Với dòng phiên bản mới này, Dịch vụ OpenSearch sử dụng công nghệ AWS và cải tiến OpenSearch để hình dung lại cách dữ liệu được lập chỉ mục và lưu trữ trên đám mây.
Ngày nay, khách hàng sử dụng rộng rãi Dịch vụ OpenSearch để phân tích hoạt động vì khả năng thu thập khối lượng dữ liệu lớn đồng thời cung cấp các phân tích tương tác và phong phú. Để cung cấp những lợi ích này, OpenSearch được thiết kế như một hệ thống phân tán quy mô cao với nhiều phiên bản độc lập lập chỉ mục dữ liệu và xử lý các yêu cầu. Khi tốc độ và khối lượng dữ liệu phân tích hoạt động của bạn tăng lên, các điểm nghẽn có thể xuất hiện. Để hỗ trợ bền vững khối lượng lập chỉ mục cao và mang lại độ bền, chúng tôi đã xây dựng dòng phiên bản OR1.
Trong bài đăng này, chúng tôi thảo luận về cách hoạt động của luồng dữ liệu được mô phỏng lại với các phiên bản OR1 cũng như cách nó có thể cung cấp thông lượng lập chỉ mục và độ bền cao bằng cách sử dụng giao thức sao chép vật lý mới. Chúng tôi cũng đi sâu vào một số thách thức mà chúng tôi đã giải quyết để duy trì tính chính xác và tính toàn vẹn của dữ liệu.
Thiết kế cho thông lượng cao với độ bền 11 9 giây
Dịch vụ OpenSearch quản lý hàng chục nghìn cụm OpenSearch. Chúng tôi đã hiểu rõ hơn về cấu hình cụm điển hình mà khách hàng sử dụng để đáp ứng các mục tiêu về thông lượng và độ bền cao. Để đạt được thông lượng cao hơn, khách hàng thường chọn thả các bản sao để tiết kiệm độ trễ khi sao chép; tuy nhiên, cấu hình này làm mất đi tính khả dụng và độ bền. Các khách hàng khác yêu cầu độ bền cao và do đó cần phải duy trì nhiều bản sao, dẫn đến chi phí vận hành của họ cao hơn.
Dòng phiên bản tối ưu hóa OpenSearch mang lại độ bền cao hơn đồng thời duy trì chi phí ở mức thấp hơn bằng cách lưu trữ bản sao dữ liệu trên Amazon S3. Với phiên bản OR1, bạn có thể đặt cấu hình nhiều bản sao để có khả năng đọc cao trong khi vẫn duy trì thông lượng lập chỉ mục.
Sơ đồ sau minh họa luồng lập chỉ mục liên quan đến cập nhật siêu dữ liệu trong OR1
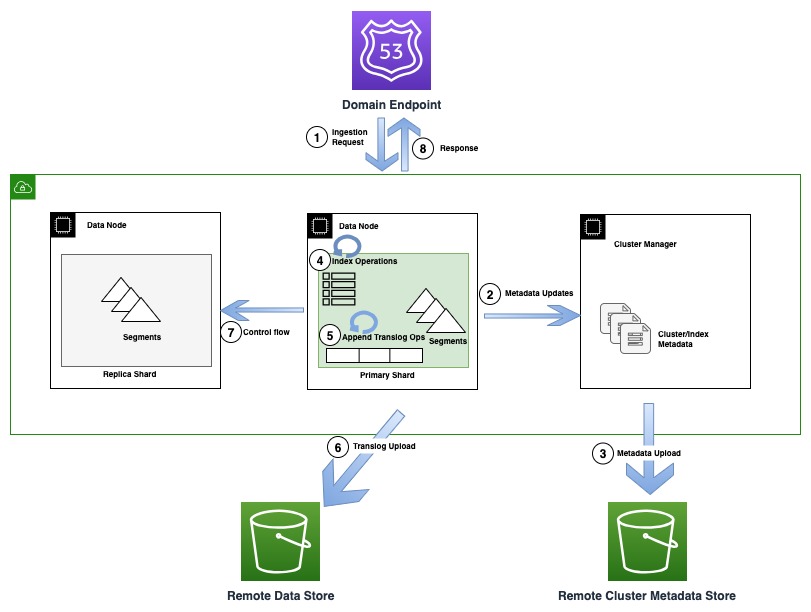
Trong quá trình lập chỉ mục, các tài liệu riêng lẻ được lập chỉ mục vào Lucene và cũng được thêm vào nhật ký viết trước còn được gọi là translog. Trước khi gửi lại xác nhận cho khách hàng, tất cả các hoạt động chuyển nhật ký sẽ được lưu vào kho dữ liệu từ xa được hỗ trợ bởi Amazon S3. Nếu bất kỳ bản sao nào được định cấu hình, bản sao chính sẽ thực hiện kiểm tra để phát hiện khả năng có nhiều người ghi (luồng điều khiển) trên tất cả các bản sao vì lý do chính xác.
Sơ đồ sau minh họa luồng tạo và sao chép phân đoạn trong các phiên bản OR1
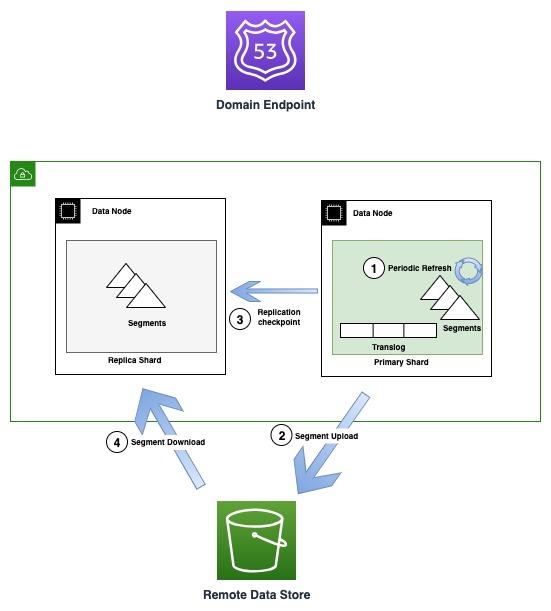
Định kỳ, khi các tệp phân đoạn mới được tạo, OR1 sẽ sao chép các phân đoạn đó sang Amazon S3. Khi quá trình truyền hoàn tất, hệ thống chính sẽ xuất bản các điểm kiểm tra mới cho tất cả các bản sao, thông báo cho chúng về phân đoạn mới có sẵn để tải xuống. Các bản sao sau đó tải xuống các phân đoạn mới hơn và làm cho chúng có thể tìm kiếm được. Mô hình này tách riêng luồng dữ liệu xảy ra khi sử dụng Amazon S3 và luồng điều khiển (xuất bản điểm kiểm tra và xác thực thuật ngữ) xảy ra qua giao tiếp truyền tải giữa các nút.
Sơ đồ sau minh họa quy trình khôi phục trong các phiên bản OR1
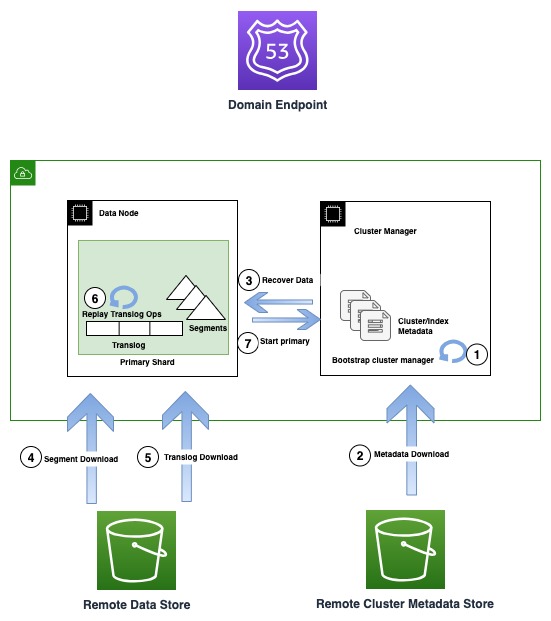
Phiên bản OR1 không chỉ duy trì dữ liệu mà còn cả siêu dữ liệu cụm như ánh xạ chỉ mục, mẫu và cài đặt trong Amazon S3. Điều này đảm bảo rằng trong trường hợp mất số đại biểu trình quản lý cụm, một dạng lỗi thường gặp trong các thiết lập trình quản lý cụm không chuyên dụng, OpenSearch có thể khôi phục siêu dữ liệu được xác nhận cuối cùng một cách đáng tin cậy.
Trong trường hợp cơ sở hạ tầng bị lỗi, miền OpenSearch có thể bị mất một hoặc nhiều nút. Trong trường hợp như vậy, họ phiên bản mới đảm bảo khôi phục cả siêu dữ liệu cụm và dữ liệu chỉ mục cho đến hoạt động được xác nhận mới nhất. Khi các nút thay thế mới tham gia vào cụm, cơ chế khôi phục cụm bên trong sẽ khởi động tập hợp nút mới và sau đó khôi phục siêu dữ liệu cụm mới nhất từ kho lưu trữ siêu dữ liệu của cụm từ xa. Sau khi siêu dữ liệu cụm được khôi phục, cơ chế khôi phục bắt đầu hydrat hóa dữ liệu phân đoạn bị thiếu và chuyển nhật ký từ Amazon S3. Sau đó, tất cả các hoạt động chuyển đổi không được cam kết, tính đến hoạt động được xác nhận cuối cùng, sẽ được phát lại để khôi phục bản sao bị mất.
Thiết kế mới không sửa đổi cách hoạt động của tìm kiếm. Các truy vấn được xử lý bình thường bằng phân đoạn chính hoặc phân đoạn sao chép cho mỗi phân đoạn trong chỉ mục. Bạn có thể thấy độ trễ dài hơn (trong khoảng 10 giây) trước khi tất cả các bản sao đều nhất quán ở một thời điểm cụ thể vì quá trình sao chép dữ liệu đang sử dụng Amazon S3.
Ưu điểm chính của kiến trúc này là nó đóng vai trò như một khối xây dựng nền tảng cho những đổi mới trong tương lai, như tách biệt người đọc và người viết, đồng thời giúp tách biệt các lớp điện toán và lưu trữ.
Cách xác định lại chiến lược sao chép sẽ tăng thông lượng lập chỉ mục
OpenSearch hỗ trợ hai chiến lược sao chép: sao chép logic (tài liệu) và vật lý (phân đoạn). Trong trường hợp sao chép logic, dữ liệu được lập chỉ mục trên tất cả các bản sao một cách độc lập, dẫn đến tính toán dư thừa trên cụm. Các phiên bản OR1 sử dụng cái mới sao chép vật lý mô hình, trong đó dữ liệu chỉ được lập chỉ mục trên bản sao chính và các bản sao bổ sung được tạo bằng cách sao chép dữ liệu từ bản chính. Với số lượng bản sao cao, nút lưu trữ bản sao chính yêu cầu băng thông mạng đáng kể để sao chép phân đoạn thành tất cả các bản sao. Các phiên bản OR1 mới giải quyết vấn đề này bằng cách duy trì lâu dài phân khúc tới Amazon S3, được định cấu hình như một lưu trữ từ xa lựa chọn. Chúng cũng giúp mở rộng quy mô bản sao mà không gây tắc nghẽn trên bản chính.
Sau khi các phân đoạn được tải lên Amazon S3, phân đoạn chính sẽ gửi yêu cầu điểm kiểm tra, thông báo cho tất cả các bản sao tải xuống các phân đoạn mới. Sau đó, các bản sao cần tải xuống các phân đoạn tăng dần. Bởi vì quá trình này giải phóng tài nguyên điện toán trên các bản sao, vốn được yêu cầu để lập chỉ mục dữ liệu một cách dư thừa và chi phí mạng phát sinh trên các bản gốc để sao chép dữ liệu, nên cụm có thể tạo ra nhiều thông lượng hơn. Trong trường hợp các bản sao không thể xử lý các phân đoạn mới được tạo do quá tải hoặc đường dẫn mạng chậm, thì các bản sao vượt quá một điểm sẽ được đánh dấu là không thành công để ngăn chúng trả về kết quả cũ.
Vì sao độ bền cao là ý tưởng hay nhưng khó làm tốt
Mặc dù tất cả các phân đoạn đã cam kết đều được duy trì lâu dài trên Amazon S3 bất cứ khi nào chúng được tạo, một trong những thách thức chính để đạt được độ bền cao là ghi đồng bộ tất cả các hoạt động không được cam kết vào nhật ký ghi trước trên Amazon S3, trước khi xác nhận lại yêu cầu cho khách hàng mà không phải hy sinh thông lượng. Ngữ nghĩa mới giới thiệu độ trễ mạng bổ sung cho các yêu cầu riêng lẻ, nhưng cách chúng tôi đảm bảo không có tác động đến thông lượng là phân nhóm và loại bỏ các yêu cầu trên một luồng trong một khoảng thời gian nhất định, đồng thời đảm bảo các luồng khác tiếp tục lập chỉ mục yêu cầu. Kết quả là, bạn có thể tăng thông lượng cao hơn với nhiều kết nối máy khách đồng thời hơn bằng cách phân khối khối lượng lớn một cách tối ưu.
Những thách thức khác trong việc thiết kế một hệ thống có độ bền cao bao gồm việc thực thi tính toàn vẹn và chính xác của dữ liệu mọi lúc. Mặc dù một số sự kiện như phân vùng mạng rất hiếm xảy ra nhưng chúng có thể phá vỡ tính đúng đắn của hệ thống và do đó hệ thống cần được chuẩn bị để đối phó với các chế độ lỗi này. Do đó, trong khi chuyển sang giao thức sao chép phân đoạn mới, chúng tôi cũng đưa ra một số thay đổi về giao thức khác, như phát hiện nhiều người ghi trên mỗi bản sao. Giao thức đảm bảo rằng một người viết bị cô lập không thể xác nhận yêu cầu ghi, trong khi một người viết chính mới được thăng cấp khác, dựa trên số đại biểu của người quản lý cụm, đang đồng thời chấp nhận những lần viết mới hơn.
Dòng phiên bản mới tự động phát hiện việc mất phân đoạn chính trong khi khôi phục dữ liệu và thực hiện kiểm tra kỹ lưỡng về khả năng tiếp cận mạng trước khi dữ liệu có thể được cung cấp lại từ Amazon S3 và cụm được đưa trở lại trạng thái hoạt động bình thường.
Để đảm bảo tính toàn vẹn của dữ liệu, tất cả các tệp đều được kiểm tra tổng hợp rộng rãi để đảm bảo chúng tôi có thể phát hiện và ngăn chặn lỗi mạng hoặc hệ thống tệp có thể khiến dữ liệu không thể đọc được. Hơn nữa, tất cả các tệp bao gồm siêu dữ liệu đều được thiết kế để không thể thay đổi, mang lại sự an toàn bổ sung chống lại lỗi và được lập phiên bản để ngăn chặn các thay đổi đột biến do vô tình.
Hình dung lại cách truyền dữ liệu
Phiên bản OR1 hydrat sao chép trực tiếp từ Amazon S3 để thực hiện khôi phục các phân đoạn bị mất khi cơ sở hạ tầng bị lỗi. Bằng cách sử dụng Amazon S3, chúng tôi có thể giải phóng băng thông mạng, thông lượng ổ đĩa và điện toán của nút chính, từ đó cung cấp trải nghiệm triển khai xanh/xanh và mở rộng quy mô tại chỗ liền mạch hơn bằng cách điều phối toàn bộ quy trình với sự phối hợp nút chính ở mức tối thiểu.
Dịch vụ OpenSearch cung cấp sao lưu dữ liệu tự động được gọi là snapshots theo các khoảng thời gian hàng giờ, có nghĩa là trong trường hợp vô tình sửa đổi dữ liệu, bạn có tùy chọn quay lại trạng thái thời điểm trước đó. Tuy nhiên, với dòng phiên bản OpenSearch mới, chúng tôi đã thảo luận rằng dữ liệu đã được lưu giữ lâu dài trên Amazon S3. Vậy ảnh chụp nhanh hoạt động như thế nào khi chúng tôi đã có sẵn dữ liệu trên Amazon S3?
Với dòng phiên bản mới, ảnh chụp nhanh đóng vai trò là điểm kiểm tra, tham chiếu đến dữ liệu phân đoạn đã có sẵn tại một thời điểm. Điều này làm cho ảnh chụp nhanh nhẹ hơn và nhanh hơn vì chúng không cần tải lên lại bất kỳ dữ liệu bổ sung nào. Thay vào đó, họ tải lên các tệp siêu dữ liệu ghi lại chế độ xem các phân đoạn tại thời điểm đó mà chúng tôi gọi là ảnh chụp nhanh nông. Lợi ích của ảnh chụp nhanh nông mở rộng đến tất cả các hoạt động, cụ thể là tạo, xóa và sao chép ảnh chụp nhanh. Bạn vẫn có tùy chọn chụp nhanh một bản sao độc lập với ảnh chụp nhanh thủ công cho các hoạt động hành chính khác.
Tổng kết
OpenSearch là một phần mềm nguồn mở, hướng tới cộng đồng. Hầu hết các thay đổi cơ bản bao gồm mô hình sao chép, lưu trữ được hỗ trợ từ xa và siêu dữ liệu cụm từ xa đã được đóng góp cho nguồn mở; trên thực tế, chúng tôi tuân theo mô hình phát triển nguồn mở đầu tiên.
Những nỗ lực nhằm cải thiện thông lượng và độ tin cậy là một chu kỳ không bao giờ kết thúc khi chúng tôi tiếp tục học hỏi và cải tiến. Các phiên bản được tối ưu hóa OpenSearch mới đóng vai trò là khối xây dựng nền tảng, mở đường cho những cải tiến trong tương lai. Chúng tôi rất vui mừng được tiếp tục nỗ lực cải thiện độ tin cậy và hiệu suất, đồng thời xem những người xây dựng giải pháp mới và hiện có có thể tạo ra những giải pháp nào bằng cách sử dụng Dịch vụ OpenSearch. Chúng tôi hy vọng điều này sẽ giúp bạn hiểu sâu hơn về dòng phiên bản OpenSearch mới, cách sản phẩm này đạt được độ bền cao và thông lượng tốt hơn cũng như cách nó có thể giúp bạn đặt cấu hình cụm dựa trên nhu cầu của doanh nghiệp bạn.
Nếu bạn hào hứng đóng góp cho OpenSearch, hãy mở một Sự cố GitHub và cho chúng tôi biết suy nghĩ của bạn. Chúng tôi cũng muốn nghe về những câu chuyện thành công của bạn khi đạt được thông lượng và độ bền cao trên Dịch vụ OpenSearch. Nếu bạn có câu hỏi khác, xin vui lòng để lại nhận xét.
Về các tác giả
 Bukhtawar Khan là Kỹ sư chính làm việc trên Dịch vụ tìm kiếm mở của Amazon. Ông quan tâm đến việc xây dựng các hệ thống phân tán và tự trị. Anh ấy là người duy trì và đóng góp tích cực cho OpenSearch.
Bukhtawar Khan là Kỹ sư chính làm việc trên Dịch vụ tìm kiếm mở của Amazon. Ông quan tâm đến việc xây dựng các hệ thống phân tán và tự trị. Anh ấy là người duy trì và đóng góp tích cực cho OpenSearch.
 Gaurav Bafna là một Kỹ sư phần mềm cao cấp làm việc trên OpenSearch tại Amazon Web Services. Anh ấy say mê giải quyết các vấn đề trong các hệ thống phân tán. Anh ấy là người duy trì và đóng góp tích cực cho OpenSearch.
Gaurav Bafna là một Kỹ sư phần mềm cao cấp làm việc trên OpenSearch tại Amazon Web Services. Anh ấy say mê giải quyết các vấn đề trong các hệ thống phân tán. Anh ấy là người duy trì và đóng góp tích cực cho OpenSearch.
 Cải Sachin là kỹ sư phát triển phần mềm cao cấp tại AWS làm việc về OpenSearch.
Cải Sachin là kỹ sư phát triển phần mềm cao cấp tại AWS làm việc về OpenSearch.
 Rohin Bhargava là Giám đốc Sản phẩm của Sr. với nhóm Dịch vụ Tìm kiếm Mở của Amazon. Niềm đam mê của anh ấy tại AWS là giúp khách hàng tìm thấy sự kết hợp chính xác của các dịch vụ AWS để đạt được thành công cho các mục tiêu kinh doanh của họ.
Rohin Bhargava là Giám đốc Sản phẩm của Sr. với nhóm Dịch vụ Tìm kiếm Mở của Amazon. Niềm đam mê của anh ấy tại AWS là giúp khách hàng tìm thấy sự kết hợp chính xác của các dịch vụ AWS để đạt được thành công cho các mục tiêu kinh doanh của họ.
 Ranjith Ramachandra là Giám đốc Kỹ thuật Cấp cao làm việc trên Dịch vụ Tìm kiếm Mở của Amazon. Anh ấy đam mê các hệ thống phân tán có khả năng mở rộng cao, hiệu suất cao và hệ thống linh hoạt.
Ranjith Ramachandra là Giám đốc Kỹ thuật Cấp cao làm việc trên Dịch vụ Tìm kiếm Mở của Amazon. Anh ấy đam mê các hệ thống phân tán có khả năng mở rộng cao, hiệu suất cao và hệ thống linh hoạt.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-under-the-hood-opensearch-optimized-instancesor1/

