Çok miktarda metinden doğru ve anlayışlı yanıtların kilidini açmak, büyük dil modellerinin (LLM'ler) sağladığı heyecan verici bir yetenektir. LLM uygulamaları oluştururken, modele ilgili bağlamı sağlamak için genellikle harici veri kaynaklarına bağlanmak ve bunları sorgulamak gerekir. Popüler yaklaşımlardan biri, karmaşık bilgileri kavrayan ve sorgulara doğal yanıtlar sağlayan Soru-Cevap sistemleri oluşturmak için Alma Artırılmış Üretimi (RAG) kullanmaktır. RAG, modellerin geniş bilgi tabanlarından yararlanmasına ve sohbet robotları ve kurumsal arama asistanları gibi uygulamalar için insan benzeri diyaloglar sunmasına olanak tanır.
Bu yazıda gücün nasıl kullanılacağını araştırıyoruz. LamaIndex, Lama 2-70B-Sohbet, ve Dil Zinciri Güçlü Soru-Cevap uygulamaları oluşturmak için. Bu en son teknolojilerle metin bütünlerini alabilir, kritik bilgileri indeksleyebilir ve kullanıcıların sorularını kesin ve net bir şekilde yanıtlayan metinler oluşturabilirsiniz.
Lama 2-70B-Sohbet
Llama 2-70B-Chat, önde gelen modellerle rekabet eden güçlü bir LLM'dir. İki trilyon metin belirteci üzerinde önceden eğitilmiştir ve Meta tarafından kullanıcılara sohbet yardımı sağlamak için kullanılması amaçlanmıştır. Eğitim öncesi veriler, kamuya açık verilerden alınmıştır ve Eylül 2022 itibarıyla sona ermektedir; ince ayar verileri ise Temmuz 2023'te sona ermektedir. Modelin eğitim süreci, güvenlikle ilgili hususlar, öğrenilenler ve kullanım amaçları hakkında daha fazla ayrıntı için makaleye bakın. Llama 2: Açık Temel ve İnce Ayarlı Sohbet Modelleri. Llama 2 modelleri şu adreste mevcuttur: Amazon SageMaker Hızlı Başlangıç hızlı ve basit bir dağıtım için.
LamaIndex
LamaIndex LLM uygulamaları oluşturmaya olanak sağlayan bir veri çerçevesidir. Mevcut verilerinizi çeşitli kaynaklar ve formatlarla (PDF'ler, belgeler, API'ler, SQL ve daha fazlası) almak için veri bağlayıcılar sunan araçlar sağlar. İster veritabanlarında ister PDF'lerde depolanan verileriniz olsun, LlamaIndex bu verileri Yüksek Lisans için kullanıma getirmeyi kolaylaştırır. Bu yazıda gösterdiğimiz gibi, LlamaIndex API'leri verilere erişimi zahmetsiz hale getirir ve güçlü özel LLM uygulamaları ve iş akışları oluşturmanıza olanak tanır.
Yüksek Lisans'ları deneyiyor ve geliştiriyorsanız, yüksek lisans destekli uygulamaların geliştirilmesini ve dağıtımını basitleştiren sağlam bir çerçeve sunan LangChain'e muhtemelen aşinasınızdır. LangChain'e benzer şekilde LlamaIndex, veri bağlayıcılar, veri indeksleri, motorlar ve veri aracılarının yanı sıra araçlar ve gözlemlenebilirlik, izleme ve değerlendirme gibi uygulama entegrasyonları da dahil olmak üzere bir dizi araç sunar. LlamaIndex, veriler ile güçlü LLM'ler arasındaki boşluğu doldurmaya ve veri görevlerini kullanıcı dostu özelliklerle kolaylaştırmaya odaklanır. LlamaIndex, LLM'leri sorgulamak ve ilgili belgeleri almak için basit bir arayüz sağladığından RAG gibi arama ve erişim uygulamaları oluşturmak için özel olarak tasarlanmış ve optimize edilmiştir.
Çözüme genel bakış
Bu yazıda, LlamaIndex ve LLM kullanarak RAG tabanlı bir uygulamanın nasıl oluşturulacağını gösteriyoruz. Aşağıdaki şema, aşağıdaki bölümlerde özetlenen bu çözümün adım adım mimarisini göstermektedir.
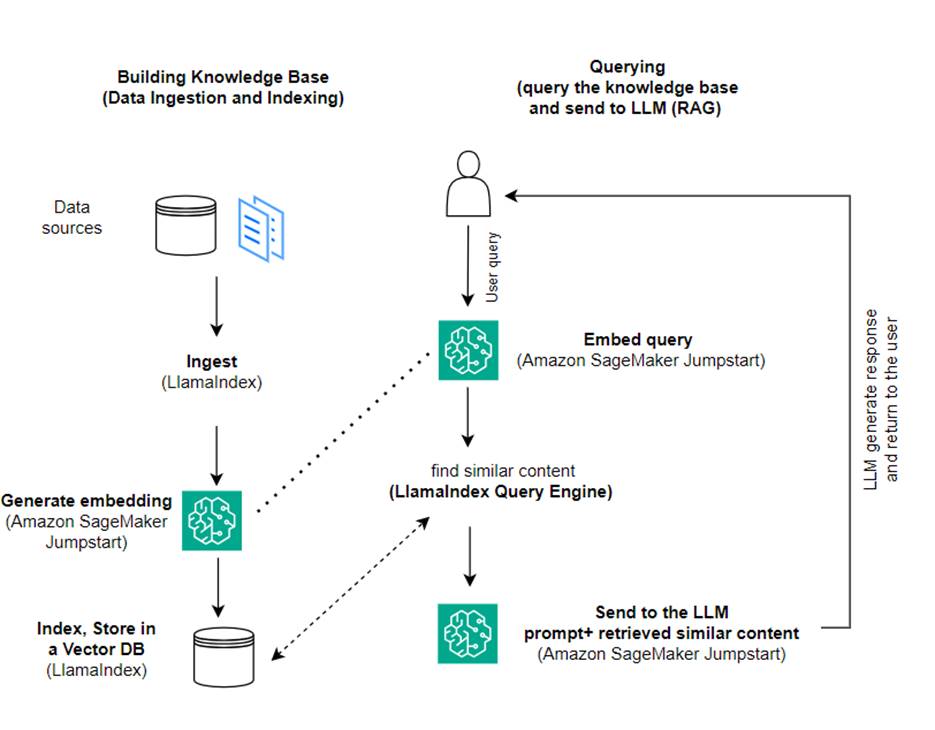
RAG, daha anlayışlı yanıtlar üretmek için bilgi erişimini doğal dil oluşturmayla birleştirir. İstendiğinde, RAG ilk olarak girdiyle en alakalı örnekleri almak için metin bütünlerini arar. Yanıt oluşturma sırasında model, yeteneklerini artırmak için bu örnekleri dikkate alır. İlgili alınan pasajların dahil edilmesiyle RAG yanıtları, temel üretken modellere kıyasla daha gerçekçi, tutarlı ve bağlamla tutarlı olma eğilimindedir. Bu geri alma-oluşturma çerçevesi, hem almanın hem de oluşturmanın güçlü yanlarından yararlanarak, saf otoregresif konuşma modellerinden kaynaklanabilecek tekrarlama ve bağlam eksikliği gibi sorunların giderilmesine yardımcı olur. RAG, bağlamsallaştırılmış, yüksek kaliteli yanıtlara sahip konuşma aracıları ve yapay zeka asistanları oluşturmaya yönelik etkili bir yaklaşım sunar.
Çözümün oluşturulması aşağıdaki adımlardan oluşur:
- Kurmak Amazon SageMaker Stüdyosu geliştirme ortamı olarak kullanın ve gerekli bağımlılıkları yükleyin.
- Amazon SageMaker JumpStart merkezinden bir yerleştirme modeli dağıtın.
- Harici bilgi tabanımız olarak kullanmak için basın bültenlerini indirin.
- Sorgulayabilmek ve bilgi istemine ek bağlam olarak ekleyebilmek için basın bültenlerinden bir dizin oluşturun.
- Bilgi tabanını sorgulayın.
- LlamaIndex ve LangChain aracılarını kullanarak bir Soru-Cevap uygulaması oluşturun.
Bu yazıdaki tüm kodlar şu adreste mevcuttur: GitHub repo.
Önkoşullar
Bu örnek için, SageMaker etki alanına sahip ve uygun bir AWS hesabına ihtiyacınız var. AWS Kimlik ve Erişim Yönetimi (IAM) izinleri. Hesap kurulumu talimatları için bkz. Bir AWS Hesabı Oluşturun. Henüz bir SageMaker alan adınız yoksa, bkz. Amazon SageMaker alanı bir tane oluşturmak için genel bakış. Bu yazıda, şunu kullanıyoruz: AmazonSageMakerTam Erişim rol. Bu kimlik bilgisini üretim ortamında kullanmanız önerilmez. Bunun yerine, en az ayrıcalıklı izinlere sahip bir rol oluşturmalı ve kullanmalısınız. Ayrıca nasıl kullanabileceğinizi de keşfedebilirsiniz. Amazon SageMaker Rol Yöneticisi Ortak makine öğrenimi ihtiyaçları için doğrudan SageMaker konsolu aracılığıyla kişi tabanlı IAM rolleri oluşturmak ve yönetmek.
Ayrıca minimum aşağıdaki bulut sunucusu boyutlarına erişmeniz gerekir:
- ml.g5.2xlarge dağıtırken uç nokta kullanımı için Sarılma Yüzü GPT-J metin yerleştirme modeli
- ml.g5.48xlarge Llama 2-Chat modeli uç noktasını dağıtırken uç nokta kullanımı için
Kotanızı artırmak için bkz. Kota artışı talep etme.
SageMaker JumpStart'ı kullanarak bir GPT-J yerleştirme modeli dağıtın
Bu bölüm SageMaker JumpStart modellerini dağıtırken size iki seçenek sunar. Sağlanan kodu kullanarak kod tabanlı bir dağıtım kullanabilir veya SageMaker JumpStart kullanıcı arayüzünü (UI) kullanabilirsiniz.
SageMaker Python SDK'sıyla dağıtın
LLM'leri dağıtmak için SageMaker Python SDK'sını aşağıdaki şekilde gösterildiği gibi kullanabilirsiniz: kod deposunda mevcuttur. Aşağıdaki adımları tamamlayın:
- Yerleştirme modelinin dağıtımı için kullanılacak örnek boyutunu şunu kullanarak ayarlayın:
instance_type = "ml.g5.2xlarge" - Yerleştirmeler için kullanılacak modelin kimliğini bulun. SageMaker JumpStart'ta şu şekilde tanımlanır:
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - Önceden eğitilmiş model kapsayıcısını alın ve çıkarım için dağıtın.
SageMaker, yerleştirme modeli başarıyla dağıtıldığında model uç noktasının adını ve aşağıdaki mesajı döndürecektir:
SageMaker Studio'da SageMaker JumpStart ile dağıtın
Modeli Studio'da SageMaker JumpStart'ı kullanarak dağıtmak için aşağıdaki adımları tamamlayın:
- SageMaker Studio konsolunda gezinme bölmesinde JumpStart'ı seçin.

- GPT-J 6B Yerleştirme FP16 modelini arayın ve seçin.
- Dağıt'ı seçin ve dağıtım yapılandırmasını özelleştirin.

- Bu örnek için, SageMaker JumpStart tarafından önerilen varsayılan örnek olan ml.g5.2xlarge örneğine ihtiyacımız var.
- Uç noktayı oluşturmak için tekrar Dağıt'ı seçin.
Uç noktanın hizmete girmesi yaklaşık 5-10 dakika sürecektir.

Gömme modelini dağıttıktan sonra, LangChain entegrasyonunu SageMaker API'leriyle kullanmak için, girişleri (ham metin) işleyecek bir işlev oluşturmanız ve modeli kullanarak bunları yerleştirmelere dönüştürmeniz gerekir. Bunu, adında bir sınıf oluşturarak yaparsınız. ContentHandler, bir JSON giriş verisi alır ve bir JSON metin yerleştirmesi döndürür: class ContentHandler(EmbeddingsContentHandler).
Model uç noktası adını ContentHandler metni dönüştürme ve yerleştirmeleri döndürme işlevi:
Uç nokta adını SDK çıktısında veya SageMaker JumpStart Kullanıcı Arayüzündeki dağıtım ayrıntılarında bulabilirsiniz.
Bunu test edebilirsiniz ContentHandler işlev ve uç nokta, bazı ham metinlerin girilmesi ve çalıştırılmasıyla beklendiği gibi çalışıyor embeddings.embed_query(text) işlev. Verilen örneği kullanabilirsiniz text = "Hi! It's time for the beach" veya kendi metninizi deneyin.
SageMaker JumpStart'ı kullanarak Llama 2-Chat'i dağıtın ve test edin
Artık kullanıcılarınızla etkileşimli görüşmeler yapabilen modeli devreye alabilirsiniz. Bu örnekte, aracılığıyla tanımlanan Lama 2 sohbet modellerinden birini seçiyoruz.
Modelin gerçek zamanlı bir uç noktaya dağıtılması gerekiyor. predictor = my_model.deploy(). SageMaker, modelin uç nokta adını döndürecektir. endpoint_name Daha sonra başvurulacak değişken.
Bir tanımla print_dialogue sohbet modeline girdi gönderme ve çıktı yanıtını alma işlevi. Yük, aşağıdakiler de dahil olmak üzere modele yönelik hiperparametreler içerir:
- max_new_tokens – Modelin çıktılarında üretebileceği maksimum token sayısını ifade eder.
- top_p – Modelin çıktılarını oluştururken tutabileceği tokenlerin kümülatif olasılığını ifade eder
- sıcaklık – Model tarafından üretilen çıktıların rastgeleliğini ifade eder. 0'dan büyük veya 1'e eşit bir sıcaklık rastgelelik düzeyini artırırken, 0'lık bir sıcaklık en olası belirteçleri üretecektir.
Hiperparametrelerinizi kullanım durumunuza göre seçmeli ve bunları uygun şekilde test etmelisiniz. Llama ailesi gibi modeller, Son Kullanıcı Lisans Sözleşmesini (EULA) okuyup kabul ettiğinizi gösteren ek bir parametre eklemenizi gerektirir:
Modeli test etmek için giriş yükünün içerik bölümünü değiştirin: "content": "what is the recipe of mayonnaise?". Kendi metin değerlerinizi kullanabilir ve hiperparametreleri daha iyi anlamak için güncelleyebilirsiniz.
Gömme modelinin dağıtımına benzer şekilde, SageMaker JumpStart Kullanıcı Arayüzünü kullanarak Llama-70B-Chat'i dağıtabilirsiniz:
- SageMaker Studio konsolunda seçin HızlıBaşlangıç gezinti bölmesinde
- Arayın ve seçin
Llama-2-70b-Chat model - EULA'yı kabul edin ve seçin Sürüş, varsayılan örneği tekrar kullanarak
Gömme modeline benzer şekilde, sohbet modelinizin giriş ve çıkışları için bir içerik işleyici şablonu oluşturarak LangChain entegrasyonunu kullanabilirsiniz. Bu durumda, girdileri bir kullanıcıdan gelenler olarak tanımlarsınız ve bunların system prompt. system prompt Belirli bir kullanım durumu için kullanıcıya yardımcı olma rolü hakkında modeli bilgilendirir.
Bu içerik işleyici daha sonra yukarıda belirtilen hiper parametrelere ve özel niteliklere (EULA kabulü) ek olarak model çağrılırken iletilir. Tüm bu nitelikleri aşağıdaki kodu kullanarak ayrıştırırsınız:
Uç nokta kullanılabilir olduğunda beklendiği gibi çalışıp çalışmadığını test edebilirsiniz. Güncelleyebilirsiniz llm("what is amazon sagemaker?") kendi metninizle. Ayrıca spesifik olarak tanımlamanız gerekir. ContentHandler gösterildiği gibi LangChain kullanarak LLM'yi çağırmak için kod ve aşağıdaki kod parçacığını:
RAG'ı oluşturmak için LlamaIndex'i kullanın
Devam etmek için RAG uygulamasını oluşturmak üzere LlamaIndex'i yükleyin. LlamaIndex'i pip kullanarak kurabilirsiniz: pip install llama_index
İndeksleme için öncelikle verilerinizi (bilgi tabanını) LlamaIndex'e yüklemeniz gerekir. Bu birkaç adımı içerir:
- Bir veri yükleyici seçin:
LlamaIndex, üzerinde mevcut olan bir dizi veri konektörü sağlar LlamaHub JSON, CSV ve metin dosyaları gibi yaygın veri türlerinin yanı sıra diğer veri kaynakları için çeşitli veri kümelerini almanıza olanak tanır. Bu yazıda şunu kullanıyoruz: SimpleDirectoryReader kodda gösterildiği gibi birkaç PDF dosyasını almak için. Veri örneğimiz, PDF sürümündeki iki Amazon basın bültenidir. basın bültenleri kod depomuzdaki klasör. PDF'leri yükledikten sonra bunların 11 öğeden oluşan bir listeye dönüştürüldüğünü görebilirsiniz.
Belgeleri doğrudan yüklemek yerine, belgeleri de kapatabilirsiniz. Document itiraz etmek Node nesneleri dizine göndermeden önce. Tamamını göndermek arasındaki seçim Document dizine itiraz etme veya Belgeyi dönüştürme Node Nesnelerin indekslenmeden önce nasıl seçileceği, özel kullanım durumunuza ve verilerinizin yapısına bağlıdır. Düğümler yaklaşımı genellikle, belgenin tamamı yerine belgenin belirli bölümlerini parçalayıp geri almak istediğiniz uzun belgeler için iyi bir seçimdir. Daha fazla bilgi için bkz. Belgeler / Düğümler.
- Yükleyiciyi oluşturun ve belgeleri yükleyin:
Bu adım, yükleyici sınıfını ve gizli dosyaların göz ardı edilip edilmeyeceği gibi gerekli tüm yapılandırmaları başlatır. Daha fazla ayrıntı için bkz. SimpleDirectoryReader.
- Yükleyiciyi arayın
load_dataKaynak dosyalarınızı ve verilerinizi ayrıştırıp bunları indekslemeye ve sorgulamaya hazır LlamaIndex Document nesnelerine dönüştürme yöntemi. LlamaIndex'in indeksleme ve alma yeteneklerini kullanarak veri alımını ve tam metin arama hazırlığını tamamlamak için aşağıdaki kodu kullanabilirsiniz:
- Dizini oluşturun:
LlamaIndex'in temel özelliği, belgeler veya düğümler olarak temsil edilen veriler üzerinde düzenli dizinler oluşturma yeteneğidir. İndeksleme, veriler üzerinde etkili sorgulamayı kolaylaştırır. Dizinimizi varsayılan bellek içi vektör deposuyla ve tanımlı ayar konfigürasyonumuzla oluşturuyoruz. LlamaIndex Ayarlar bir LlamaIndex uygulamasında indeksleme ve sorgulama işlemleri için yaygın olarak kullanılan kaynakları ve ayarları sağlayan bir yapılandırma nesnesidir. Tekil bir nesne gibi davranır, böylece genel konfigürasyonları ayarlamanıza olanak tanırken aynı zamanda belirli bileşenleri doğrudan onları kullanan arayüzlere (LLM'ler, yerleştirme modelleri gibi) geçirerek yerel olarak geçersiz kılmanıza da olanak tanır. Belirli bir bileşen açıkça sağlanmadığında, LlamaIndex çerçevesi, Settings nesneyi genel bir varsayılan olarak kullanın. Gömme ve LLM modellerimizi LangChain ile kullanmak ve yapılandırmak için Settings yüklememiz gerekiyor llama_index.embeddings.langchain ve llama_index.llms.langchain. yapılandırabiliriz Settings aşağıdaki koddaki gibi nesne:
Varsayılan olarak, VectorStoreIndex bir bellek içi kullanır SimpleVectorStore bu, varsayılan depolama bağlamının bir parçası olarak başlatılır. Gerçek hayattaki kullanım örneklerinde sıklıkla harici vektör depolarına bağlanmanız gerekir: Amazon Açık Arama Hizmeti. Daha fazla ayrıntı için bkz. Amazon OpenSearch Sunucusuz için Vektör Motoru.
Artık belgeleriniz üzerinde soru-cevap işlemlerini aşağıdakileri kullanarak gerçekleştirebilirsiniz: query_engine LlamaIndex'ten. Bunun için daha önce oluşturduğunuz dizini sorgulara aktarın ve sorunuzu sorun. Sorgu motoru, verileri sorgulamak için kullanılan genel bir arayüzdür. Giriş olarak doğal dil sorgusunu alır ve zengin bir yanıt döndürür. Sorgu motoru genellikle bir veya daha fazlasının üzerine kuruludur. indeksler kullanma alıcılar.
RAG çözümünün sağlanan belgelerden doğru cevabı alabildiğini görebilirsiniz:
LangChain araçlarını ve aracılarını kullanın
Loader sınıf. Yükleyici, verileri LlamaIndex'e veya daha sonra bir araç olarak yüklemek üzere tasarlanmıştır. LangChain temsilcisi. Bu, uygulamanızın bir parçası olarak bunu kullanmanız için size daha fazla güç ve esneklik sağlar. Tanımlayarak başlarsınız araç LangChain ajan sınıfından. Aracınıza aktardığınız işlev, LlamaIndex'i kullanarak belgelerinizin üzerine oluşturduğunuz dizini sorgular.
Daha sonra RAG uygulamanız için kullanmak istediğiniz doğru aracı türünü seçersiniz. Bu durumda, şunu kullanırsınız: chat-zero-shot-react-description ajan. Bu aracı ile LLM, yanıtı sağlamak için mevcut aracı (bu senaryoda, bilgi tabanı üzerindeki RAG) kullanacaktır. Daha sonra aracınızı, LLM'nizi ve aracı türünüzü ileterek aracıyı başlatırsınız:
Temsilcinin içinden geçtiğini görebilirsiniz thoughts, actions, ve observation , aracı kullanın (bu senaryoda, dizine eklenen belgelerinizi sorgulamak); ve bir sonuç döndürün:
Uçtan uca uygulama kodunu ekte bulabilirsiniz. GitHub repo.
Temizlemek
Gereksiz maliyetlerden kaçınmak için aşağıdaki kod parçacıkları veya Amazon JumpStart kullanıcı arayüzü aracılığıyla kaynaklarınızı temizleyebilirsiniz.
Boto3 SDK'yı kullanmak için, metin ekleme modeli uç noktasını ve metin oluşturma modeli uç noktasını ve uç nokta yapılandırmalarını silmek için aşağıdaki kodu kullanın:
SageMaker konsolunu kullanmak için aşağıdaki adımları tamamlayın:
- SageMaker konsolunda, gezinme bölmesindeki Çıkarım altında Uç Noktalar'ı seçin
- Gömme ve metin oluşturma uç noktalarını arayın.
- Uç nokta ayrıntıları sayfasında Sil'i seçin.
- Onaylamak için tekrar Sil'i seçin.
Sonuç
LlamaIndex, arama ve erişime odaklanan kullanım durumları için esnek yetenekler sağlar. LLM'ler için indeksleme ve erişim konusunda üstündür ve bu da onu verilerin derinlemesine araştırılması için güçlü bir araç haline getirir. LlamaIndex, organize veri dizinleri oluşturmanıza, çeşitli LLM'ler kullanmanıza, daha iyi LLM performansı için verileri artırmanıza ve verileri doğal dille sorgulamanıza olanak tanır.
Bu gönderi bazı önemli LlamaIndex kavramlarını ve yeteneklerini gösterdi. Yerleştirme için GPT-J'yi ve RAG uygulaması oluşturmak için LLM olarak Llama 2-Chat'i kullandık, ancak bunun yerine uygun herhangi bir modeli kullanabilirsiniz. SageMaker JumpStart'ta mevcut olan kapsamlı model yelpazesini keşfedebilirsiniz.
Ayrıca LlamaIndex'in verileri LangChain gibi diğer çerçevelere bağlamak, indekslemek, almak ve entegre etmek için nasıl güçlü, esnek araçlar sağlayabildiğini gösterdik. LlamaIndex entegrasyonları ve LangChain ile daha güçlü, çok yönlü ve anlayışlı LLM uygulamaları oluşturabilirsiniz.
Yazarlar Hakkında
 Dr. Romina Sharifpour Amazon Web Services'te (AWS) Kıdemli Makine Öğrenimi ve Yapay Zeka Çözümleri Mimarıdır. Makine öğrenimi ve yapay zeka alanındaki gelişmelerin mümkün kıldığı yenilikçi uçtan uca çözümlerin tasarımına ve uygulanmasına liderlik etmek için 10 yıldan fazla zaman harcadı. Romina'nın ilgi alanları doğal dil işleme, büyük dil modelleri ve MLOps'tur.
Dr. Romina Sharifpour Amazon Web Services'te (AWS) Kıdemli Makine Öğrenimi ve Yapay Zeka Çözümleri Mimarıdır. Makine öğrenimi ve yapay zeka alanındaki gelişmelerin mümkün kıldığı yenilikçi uçtan uca çözümlerin tasarımına ve uygulanmasına liderlik etmek için 10 yıldan fazla zaman harcadı. Romina'nın ilgi alanları doğal dil işleme, büyük dil modelleri ve MLOps'tur.
 Nicole Pinto Sidney, Avustralya merkezli bir AI/ML Uzman Çözüm Mimarıdır. Sağlık hizmetleri ve finansal hizmetlerdeki geçmişi ona müşteri sorunlarının çözümünde benzersiz bir bakış açısı kazandırıyor. Makine öğrenimi yoluyla müşterilere olanak sağlama ve STEM alanında yeni nesil kadınları güçlendirme konusunda tutkulu.
Nicole Pinto Sidney, Avustralya merkezli bir AI/ML Uzman Çözüm Mimarıdır. Sağlık hizmetleri ve finansal hizmetlerdeki geçmişi ona müşteri sorunlarının çözümünde benzersiz bir bakış açısı kazandırıyor. Makine öğrenimi yoluyla müşterilere olanak sağlama ve STEM alanında yeni nesil kadınları güçlendirme konusunda tutkulu.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

