Veri gölleri, çeşitli kaynaklardan gelen büyük miktarda veriyi ölçeklenebilir ve uygun maliyetli bir şekilde depolamak için popülerlik kazanıyor. Veri tüketicilerinin sayısı arttıkça, veri gölü yöneticilerinin genellikle farklı kullanıcı profilleri için ayrıntılı erişim denetimleri uygulaması gerekir. Talepte bulunan kullanıcının türüne bağlı olarak belirli tablo veya sütunlara erişimi kısıtlamaları gerekebilir. Ayrıca işletmeler bazen verileri harici uygulamaların kullanımına sunmak ister ancak bunu güvenli bir şekilde nasıl yapacaklarından emin olamazlar. Bu zorlukların üstesinden gelmek için kuruluşlar GraphQL'e başvurabilir ve AWS Göl Oluşumu.
GraphQL Verileri sorgulamak ve almak için güçlü, güvenli ve esnek bir yol sağlar. AWS Uygulama Senkronizasyonu tek bir birleşik GraphQL uç noktasından birden fazla veritabanını, mikro hizmeti ve API'yi sorgulayabilen GraphQL API'leri oluşturmaya yönelik bir hizmettir.
Veri gölü yöneticileri, veri göllerine erişimi yönetmek için Lake Formation'ı kullanabilir. Lake Formation, kullanıcı ve grup izinlerini tablo, sütun ve hücre düzeyinde yönetmek için ayrıntılı erişim kontrolleri sunar. Bu nedenle veri güvenliğini ve uyumluluğunu sağlayabilir. Ayrıca bu Lake Formation, aşağıdakiler gibi diğer AWS hizmetleriyle de entegre olur: Amazon AtinaBu da onu API'ler aracılığıyla veri göllerini sorgulamak için ideal hale getiriyor.
Bu yazıda, bir GraphQL API aracılığıyla bir veri gölünden veri çıkarabilen ve sonuçları, kendi özel veri erişim ayrıcalıklarına göre farklı türdeki kullanıcılara sunabilen bir uygulamanın nasıl oluşturulacağını gösteriyoruz. Bu yazıda açıklanan örnek uygulama AWS Çözüm Ortağı tarafından oluşturulmuştur. NETSOL Teknolojileri.
Çözüme genel bakış
bizim çözüm kullanır Amazon Basit Depolama Hizmeti (Amazon S3) verileri depolamak için, AWS Tutkal Veri şemasını barındıran Data Catalog ve rol tabanlı erişim uygulayarak AWS Glue Data Catalog nesneleri üzerinde yönetim sağlamak için Lake Formation. Biz de kullanıyoruz Amazon EventBridge veri gölümüzdeki olayları yakalamak ve aşağı yönlü süreçleri başlatmak için. Çözüm mimarisi aşağıdaki şemada gösterilmektedir.
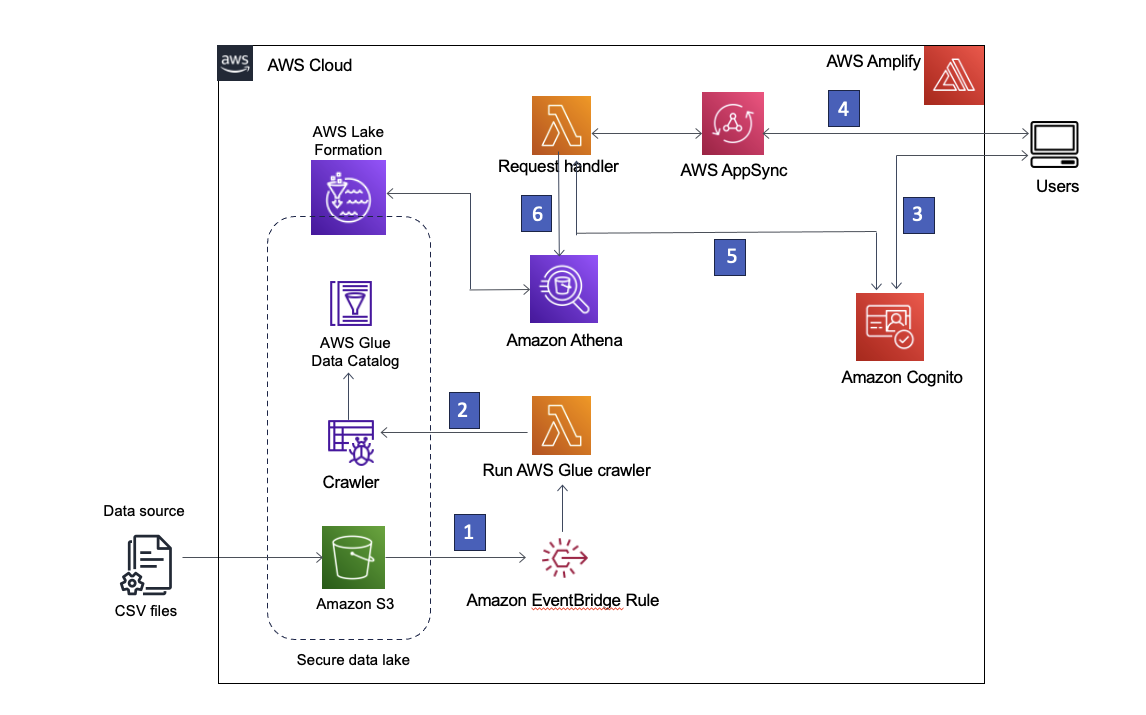
Şekil 1 – Çözüm mimarisi
Çözümün adım adım açıklaması aşağıdadır:
- Veri gölü, Lake Formation'a kayıtlı bir S3 klasöründe oluşturulur. Yeni veriler geldiğinde bir EventBridge kuralı çağrılır.
- EventBridge kuralı şunları çalıştırır: AWS Lambda En son verilerin sorgulanabilmesi için yeni verileri keşfetmek ve şema değişikliklerini güncellemek üzere bir AWS Glue tarayıcısını başlatma işlevi.
Not: AWS Glue tarayıcıları, burada açıklandığı gibi doğrudan Amazon S3 olaylarından da başlatılabilir. blog yazısı. - AWS Yükseltme kullanıcıların şunu kullanarak oturum açmasına olanak tanır: Amazon Cognito'su kimlik sağlayıcısı olarak Cognito, kullanıcının kimlik bilgilerini doğrular ve erişim belirteçlerini döndürür.
- Kimliği doğrulanmış kullanıcılar Amplify aracılığıyla bir AWS AppSync GraphQL API'sini çağırarak veri gölünden veri getirir. İsteği işlemek için bir Lambda işlevi çalıştırılır.
- Lambda işlevi kullanıcı ayrıntılarını Cognito'dan alır ve AWS Kimlik ve Erişim Yönetimi (IAM) istekte bulunan kullanıcının Cognito kullanıcı grubuyla ilişkili rol.
- Lambda işlevi daha sonra data lake tablolarına karşı bir Athena sorgusu çalıştırır ve sonuçları AWS AppSync'e döndürür, o da sonuçları kullanıcıya döndürür.
Önkoşullar
Bu çözümü dağıtmak için öncelikle aşağıdakileri yapmanız gerekir:
Göl Oluşumu izinlerini hazırlayın
Adresinde oturum açın LakeFormation konsolu ve kendinizi yönetici olarak ekleyin. Lake Formation'da ilk kez oturum açıyorsanız bunu Lake Formation'a Hoş Geldiniz ekranında Kendimi Ekle'yi seçip Şekil 2'de gösterildiği gibi Başlayın'ı seçerek yapabilirsiniz.

Şekil 2 – Kendinizi Göl Oluşumu yöneticisi olarak ekleyin
Aksi takdirde, sol gezinme çubuğunda Yönetici rolleri ve görevleri'ni seçip kendiniz eklemek için Yöneticileri Yönet'i seçebilirsiniz. İşlemi tamamladığınızda, Tam erişime sahip Veri gölü yöneticileri altında IAM kullanıcı adınızı görmelisiniz.
Sol gezinme çubuğunda Veri kataloğu ayarları'nı seçin ve Şekil 3'te gösterildiği gibi iki IAM erişim kontrol kutusunun seçili olmadığından emin olun. Yeni veritabanlarına erişimi IAM'in değil Lake Formation'ın kontrol etmesini istiyorsunuz.
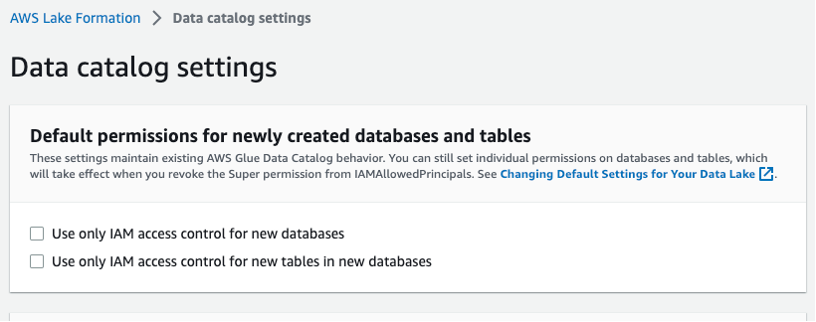
Şekil 3 – Göl Oluşumu veri kataloğu ayarları
Çözümü dağıtın
Çözümü AWS ortamınızda oluşturmak için aşağıdaki AWS CloudFormation yığınını başlatın: ![]()
Aşağıdaki kaynaklar CloudFormation şablonu aracılığıyla başlatılacaktır:
- Amazon VPC ve ağ bileşenleri (alt ağlar, güvenlik grupları ve NAT ağ geçidi)
- IAM rolleri
- S3 kovasını, AWS Glue tarayıcısını ve AWS Glue veritabanını kapsayan Lake Formation
- Lambda işlevleri
- Cognito kullanıcı havuzu
- AWS AppSync GraphQL API'si
- EventBridge kuralları
Gerekli kaynaklar CloudFormation yığınından dağıtıldıktan sonra iki Lambda işlevi oluşturmalı ve veri kümesini Amazon S3'e yüklemelisiniz. Lake Formation, S3 klasöründe depolanan veri gölünü yönetecektir.
Lambda işlevlerini oluşturma
Belirlenen S3 klasörüne yeni bir dosya yerleştirildiğinde, AWS Glue tarayıcısını başlatmak için bir Lambda işlevini başlatan bir EventBridge kuralı çağrılır. Tarayıcı, şemadaki değişiklikleri yansıtacak şekilde AWS Glue Data Catalog'u günceller.
Uygulama, GraphQL API aracılığıyla veri için bir sorgu yaptığında, sorguyu işlemek ve sonuçları döndürmek için bir istek işleyici Lambda işlevi çağrılır.
Bu iki Lambda fonksiyonunu oluşturmak için aşağıdaki şekilde ilerleyin.
- Lambda konsolunda oturum açın.
- Adlı istek işleyici Lambda işlevini seçin
dl-dev-crawlerLambdaFunction. - Tarayıcı Lambda işlev dosyasını
lambdas/crawler-lambdayerel makinenize kopyaladığınız git deposundaki klasör. - Bu dosyadaki kodu kopyalayıp, Kod bölümüne yapıştırın.
dl-dev-crawlerLambdaFunctionLambda konsolunuzda. Ardından işlevi dağıtmak için Dağıt'ı seçin.
Şekil 4 – Kodu kopyalayıp Lambda işlevine yapıştırın
- Adı verilen istek işleyici işlevi için 2'den 4'e kadar olan adımları tekrarlayın.
dl-dev-requestHandlerLambdaFunctioniçindeki kodu kullanaraklambdas/request-handler-lambda.
İstek işleyicisi Lambda için bir katman oluşturun
Artık istek işleyici Lambda işlevinin ihtiyaç duyduğu bazı ek kitaplık kodlarını yüklemelisiniz.
- seç Katmanlar soldaki menüden seçin ve Katman oluştur.
- gibi bir ad girin
appsync-lambda-layer. - Bu indirin paket katmanı ZIP dosyası yerel makinenize.
- ZIP dosyasını kullanarak yükleyin Foto Yükle düğmesini Katman oluştur gidin.
- Klinik Python 3.7 katmanın çalışma zamanı olarak.
- Klinik oluşturmak.
- seç fonksiyonlar soldaki menüden seçin ve
dl-dev-requestHandlerLambda işlevi. - Aşağı doğru kaydırın Katmanlar bölüm ve seç Katman ekle.
- seçmek Özel katmanlar seçeneğini seçin ve ardından yukarıda oluşturduğunuz katmanı seçin.
- Tıkla Ekle.
Verileri Amazon S3'e yükleyin
Klonlanmış git deposunun kök dizinine gidin ve örnek veri kümesini yüklemek için aşağıdaki komutları çalıştırın. Değiştir bucket_name CloudFormation şablonu kullanılarak sağlanan S3 paketine sahip yer tutucu. Paket adını CloudFormation konsolundan şuraya giderek alabilirsiniz: Çıkışlar tuşlu sekme datalakes3bucketName aşağıdaki resimde gösterildiği gibi.

Şekil 5 – CloudFormation Çıkışları sekmesinde gösterilen S3 grubu adı
Veri kümesini S3 klasörüne yüklemek için yerel makinenizdeki proje klasörünüze aşağıdaki komutları girin.
Şimdi konuşlandırılan eserlere bir göz atalım.
veri gölü
S3 klasörü iki varlık için örnek veriler içerir: şirketler ve ilgili sahipleri. Kova, Şekil 6'da gösterildiği gibi Lake Formation'a kayıtlıdır. Bu, Lake Formation'ın veri katalogları oluşturup yönetmesine ve verilerle ilgili izinleri yönetmesine olanak tanır.

Şekil 6 – Veri gölü konumunu gösteren Göl Oluşumu konsolu
Amazon S3'te bulunan verilerin şemasını tutacak bir veritabanı oluşturulur. S3 klasöründeki şemadaki herhangi bir değişikliği güncellemek için bir AWS Glue tarayıcısı kullanılır. Bu tarayıcıya Lake Formation'ı kullanarak veritabanındaki CREATE, ALTER ve DROP tablolarını kullanma izni verilmiştir.
Veri gölü erişim kontrollerini uygulama
İki IAM rolü oluşturulur, dl-us-east-1-developer ve dl-us-east-1-business-analysther biri farklı bir Cognito kullanıcı grubuna atanmıştır. Her role Lake Formasyonu aracılığıyla farklı yetkiler atanır. Geliştirici rolü, veri gölündeki her sütuna erişim kazanırken, İş Analisti rolüne yalnızca kişisel olarak tanımlanamayan bilgiler (PII) sütunlarına erişim izni verilir.
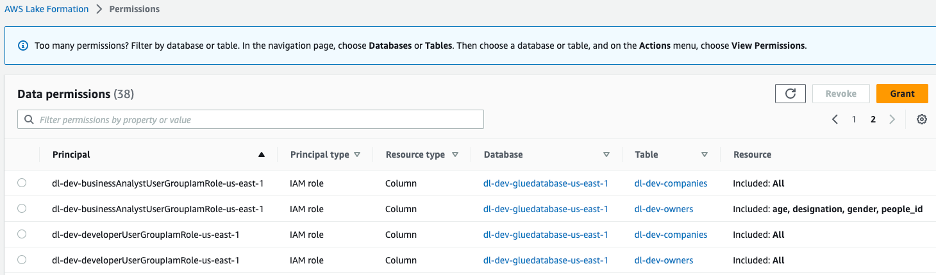
Şekil 7 – Grup rollerine atanan Lake Formation konsolu veri gölü izinleri
GraphQL şeması
GraphQL API, AWS AppSync konsolundan görüntülenebilir. Companies tür, şirketlerin sahiplerini tanımlayan çeşitli özellikleri içerir.
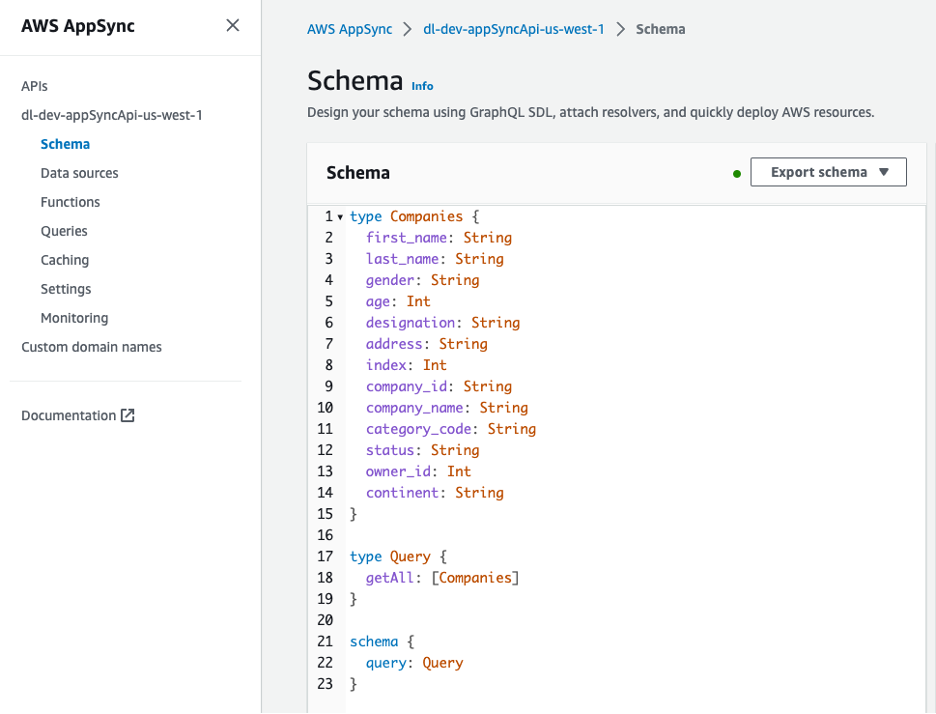
Şekil 8 – GraphQL API Şeması
GraphQL API'sinin veri kaynağı, istekleri işleyen bir Lambda işlevidir.
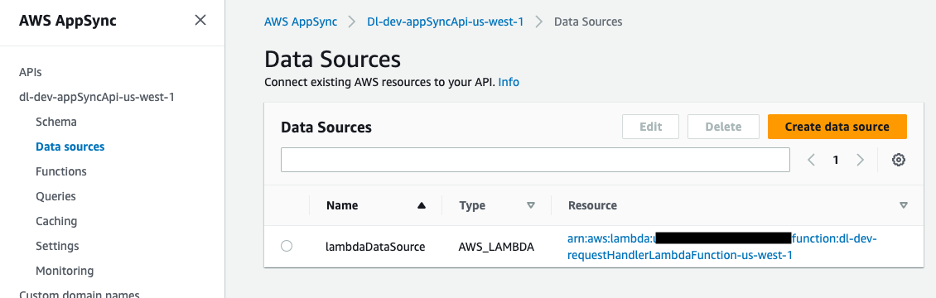
Şekil 9 – Lambda işleviyle eşlenen AWS AppSync veri kaynağı
GraphQL API isteklerini yönetme
GraphQL API istek işleyicisi Lambda işlevi, Cognito kullanıcı havuzu kimliğini ortam değişkenlerinden alır. Boto3 kütüphanesini kullanarak bir Cognito istemcisi yaratır ve get_group Cognito kullanıcı grubuyla ilişkili IAM rolünü elde etme yöntemi.
Rolü almak için Lambda işlevindeki bir yardımcı işlevi kullanırsınız.
Kullanma AWS Güvenlik Belirteci Hizmeti (AWS STS) boto3 istemcisi aracılığıyla IAM rolünü üstlenebilir ve Athena sorgusunu çalıştırmak için ihtiyaç duyduğunuz geçici kimlik bilgilerini alabilirsiniz.
Boto3 Amazon Athena istemcimizi oluştururken geçici kimlik bilgilerini parametre olarak aktarıyoruz.
athena_client = boto3.client('athena', aws_access_key_id=access_key, aws_secret_access_key=secret_key, aws_session_token=session_token)İstemci ve sorgu, sorguyu yürüten ve bir sorgu kimliği döndüren Athena sorgu yardımcı işlevimize aktarılır. Sorgu kimliğiyle S3'teki sonuçları okuyabilir ve yanıtta döndürülecek bir Python sözlüğü olarak paketleyebiliriz.
Veri gölüne istemci tarafı erişimi etkinleştirme
İstemci tarafında AWS Amplify, kimlik doğrulama için bir Amazon Cognito kullanıcı havuzuyla yapılandırılmıştır. Oluşturulan kullanıcı havuzunu ve grupları görüntülemek için Amazon Cognito konsoluna gideceğiz.
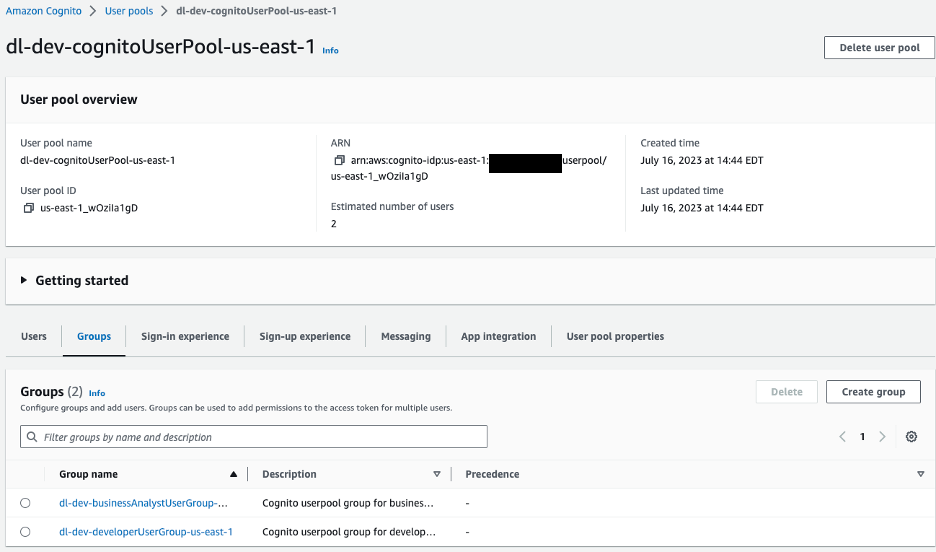
Şekil 10 – Amazon Cognito Kullanıcı havuzları
Örnek uygulamamız için kullanıcı havuzumuzda iki grubumuz var:
dl-dev-businessAnalystUserGroup– Sınırlı izinlere sahip iş analistleri.dl-dev-developerUserGroup– Tam izinlere sahip geliştiriciler.
Bu grupları incelerseniz her biriyle ilişkilendirilmiş bir IAM rolü görürsünüz. Bu, kimlik doğrulaması sırasında kullanıcıya atanan IAM rolüdür. Athena, veri gölünü sorgularken bu rolü üstlenir.
Bu IAM rolünün izinlerini görüntülerseniz tablo düzeyinin altındaki erişim kontrollerini içermediğini fark edeceksiniz. Ayrıntılı erişim kontrolü eklemek için Lake Formation tarafından sağlanan ek yönetim katmanına ihtiyacınız var.
Kullanıcının Cognito tarafından doğrulanması ve kimliği doğrulandıktan sonra Amplify, AWS AppSync GraphQL API'sini çağırmak ve verileri getirmek için erişim belirteçlerini kullanır. Kullanıcının grubuna bağlı olarak bir Lambda işlevi, karşılık gelen Cognito kullanıcı grubu rolünü üstlenir. Varsayılan rolü kullanarak bir Athena sorgusu çalıştırılır ve sonuç kullanıcıya döndürülür.
Test kullanıcıları oluşturun
Biri geliştirici, diğeri iş analisti için olmak üzere iki kullanıcı oluşturun ve bunları kullanıcı gruplarına ekleyin.
- Cognito'ya gidin ve kullanıcı havuzunu seçin,
dl-dev-cognitoUserPool, bu yaratıldı. - Klinik Kullanıcı oluştur ve yeni bir iş analisti kullanıcısı oluşturmak için ayrıntıları sağlayın. Kullanıcı adı olabilir iş analisti. E-posta adresini boş bırakın ve bir şifre girin.
- seçmek Kullanıcılar sekmesine gidin ve yeni oluşturduğunuz kullanıcıyı seçin.
- Bu kullanıcıyı iş analisti grubuna aşağıdakileri seçerek ekleyin: Gruba kullanıcı ekle düğmesine basın.
- Kullanıcı adı ile başka bir kullanıcı oluşturmak için aynı adımları izleyin geliştirici ve kullanıcıyı geliştiriciler grubuna ekleyin.
Çözümü test edin
Çözümünüzü test etmek için yerel makinenizde React uygulamasını başlatın.
- Klonlanmış proje dizininde şuraya gidin:
react-appdizin. - Proje bağımlılıklarını yükleyin.
- Amplify CLI'yi yükleyin:
- Adlı yeni bir dosya oluşturun
.envaşağıdaki komutları çalıştırarak. Daha sonra dosyadaki ortam değişkeni değerlerini güncellemek için bir metin düzenleyici kullanın.
Kullan Çıkışlar Anahtarlardan gerekli değerleri aşağıdaki gibi almak için CloudFormation konsol yığınınızın sekmesini kullanın:
REACT_APP_APPSYNC_URL |
appsyncApiEndpoint |
REACT_APP_CLIENT_ID |
cognitoUserPoolClientId |
REACT_APP_USER_POOL_ID |
cognitoUserPoolId |
- Önceki değişkenleri ortamınıza ekleyin.
- Kullanarak API ile etkileşim kurmak için gereken kodu oluşturun CodeGen'i güçlendirin. Cloudformation konsolunuzun Çıkışlar sekmesinde, AWS Appsync API kimliğinizi yanındaki
appsyncApiIdtuşuna basın.
Yukarıdaki komut için tüm varsayılan seçenekleri tuşuna basarak kabul edin. Keşfet her istemde.
- Uygulamayı başlatın.
adresini ziyaret ederek uygulamanın çalıştığını doğrulayabilirsiniz. http://localhost:3000 ve daha önce oluşturduğunuz geliştirici kullanıcısı olarak oturum açın.
Artık uygulamayı çalıştırdığınıza göre, her bir rolün sunucudan nasıl sunulduğuna bir göz atalım. companies uç nokta.
Birincisi, Sign, tüm alanlara erişimi olan ve şirketin uç noktasına API isteğinde bulunan geliştirici rolüdür. Hangi alanlara erişebildiğinizi not edin.
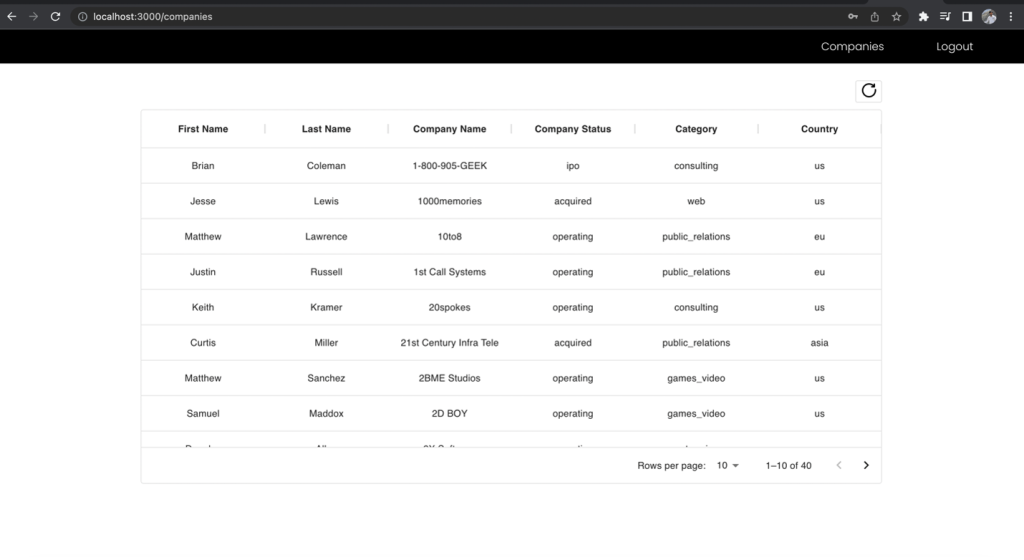
Şekil 11 – Geliştirici rolüne ilişkin sonuçlar
Şimdi iş analisti kullanıcısı olarak oturum açın ve aynı uç noktaya istekte bulunun ve dahil edilen alanları karşılaştırın.
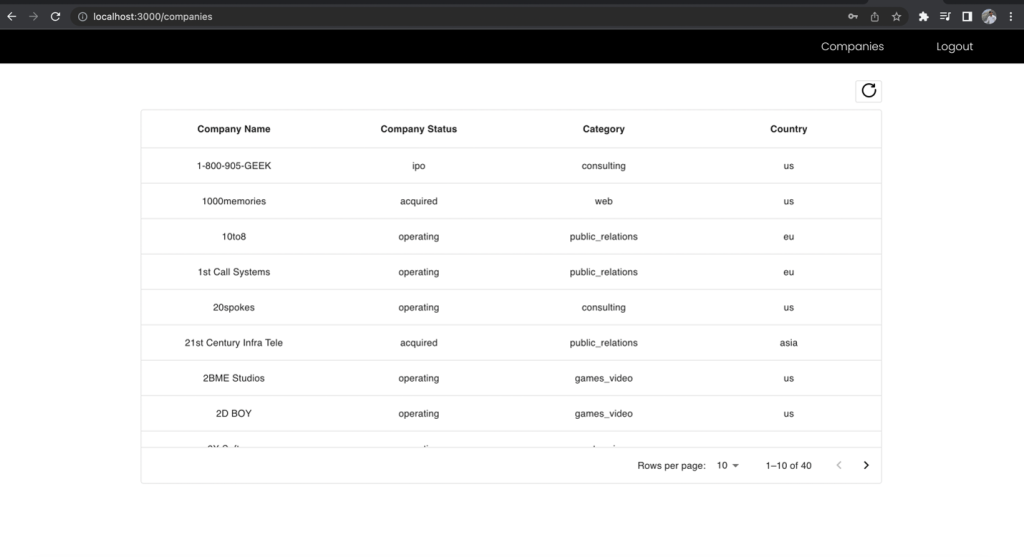
Şekil 12 – İş Analisti rolüne ilişkin sonuçlar
Aynı uç noktaya istekte bulunmuş olsanız bile, şirketler listesinin Ad ve Soyadı sütunları iş analisti görünümünde hariç tutulur. Bu, verilerinize rol tabanlı erişimi yönetmek için Lake Formation izinleriyle eşlenen birden fazla Cognito kullanıcı grubu IAM rolüyle birlikte tek bir birleşik GraphQL uç noktası kullanmanın gücünü gösterir.
Temizlemek
Çözümü test etmeyi tamamladıktan sonra, gelecekte ücret alınmasını önlemek için aşağıdaki kaynakları temizleyin:
- CloudFormation şablonu tarafından oluşturulan S3 paketlerini boşaltın.
- S3 paketlerini ve diğer kaynakları kaldırmak için CloudFormation yığınını silin.
Sonuç
Bu yazıda, bir veri gölündeki verileri, bir React uygulamasının kimliği doğrulanmış kullanıcılarına, rol tabanlı erişim ayrıcalıklarına dayalı olarak nasıl güvenli bir şekilde sunacağınızı gösterdik. Bunu başarmak için AWS AppSync'teki GraphQL API'lerini, Lake Formation'daki ayrıntılı erişim kontrollerini ve kullanıcıların kimliklerini gruba göre doğrulamak ve onları IAM rolleriyle eşlemek için Cognito'yu kullandınız. Ayrıca verileri sorgulamak için Athena'yı kullandınız.
Bu konuyla ilgili ilgili okumalar için bkz. AWS AppSync, Amazon Athena ve AWS Amplify ile büyük verileri görselleştirme ve AWS Lake Formation ve AWS Glue kullanarak bir veri ağı mimarisi tasarlayın.
Veri gölünüzden veri sunmak için bu yaklaşımı uygulayacak mısınız? Yorumlarda bize bildirin!
Yazarlar Hakkında
 Rana Dutt Amazon Web Services'te Baş Çözüm Mimarıdır. Finansal hizmetler, sağlık hizmetleri ve telekom şirketleri için ölçeklenebilir yazılım platformları tasarlama konusunda bir geçmişi var ve müşterilerin AWS üzerinde geliştirme yapmasına yardımcı olma konusunda tutkulu.
Rana Dutt Amazon Web Services'te Baş Çözüm Mimarıdır. Finansal hizmetler, sağlık hizmetleri ve telekom şirketleri için ölçeklenebilir yazılım platformları tasarlama konusunda bir geçmişi var ve müşterilerin AWS üzerinde geliştirme yapmasına yardımcı olma konusunda tutkulu.
 Ranjith Rayaprolu AWS'de Kuzeybatı Pasifik'teki müşterilerle çalışan Kıdemli Çözüm Mimarıdır. Müşterilerin AWS'de iş sorunlarını çözen ve AWS hizmetlerinin benimsenmesini hızlandıran Well-Architected çözümler tasarlamasına ve çalıştırmasına yardımcı oluyor. Farklı sektör sektörlerinde bulutta çözümler geliştirmek için AWS güvenliği ve ağ teknolojilerine odaklanıyor. Ranjith, Seattle bölgesinde yaşıyor ve açık hava etkinliklerini seviyor.
Ranjith Rayaprolu AWS'de Kuzeybatı Pasifik'teki müşterilerle çalışan Kıdemli Çözüm Mimarıdır. Müşterilerin AWS'de iş sorunlarını çözen ve AWS hizmetlerinin benimsenmesini hızlandıran Well-Architected çözümler tasarlamasına ve çalıştırmasına yardımcı oluyor. Farklı sektör sektörlerinde bulutta çözümler geliştirmek için AWS güvenliği ve ağ teknolojilerine odaklanıyor. Ranjith, Seattle bölgesinde yaşıyor ve açık hava etkinliklerini seviyor.
 Justin Leto Amazon Web Services'te veritabanları, büyük veri analitiği ve makine öğrenimi konularında uzmanlaşan Kıdemli Çözüm Mimarıdır. Onun tutkusu, müşterilerin bulutu daha iyi benimsemelerine yardımcı olmaktır. Boş zamanlarında açık denizde yelken açmaktan ve caz piyanosu çalmaktan hoşlanıyor. Eşi ve küçük kızıyla birlikte New York'ta yaşıyor.
Justin Leto Amazon Web Services'te veritabanları, büyük veri analitiği ve makine öğrenimi konularında uzmanlaşan Kıdemli Çözüm Mimarıdır. Onun tutkusu, müşterilerin bulutu daha iyi benimsemelerine yardımcı olmaktır. Boş zamanlarında açık denizde yelken açmaktan ve caz piyanosu çalmaktan hoşlanıyor. Eşi ve küçük kızıyla birlikte New York'ta yaşıyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/using-aws-appsync-and-aws-lake-formation-to-access-a-secure-data-lake-through-a-graphql-api/

