Verilerin katlanarak büyümesiyle birlikte şirketler, kişisel olarak tanımlanabilir bilgiler (PII) de dahil olmak üzere büyük hacimli ve çok çeşitli verileri yönetiyor. PII, tek bir kişiyi tanımlayabilen, iletişim kurabilen veya yerini tespit edebilen bilgilere ilişkin yasal bir terimdir. Hassas verilerin geniş ölçekte belirlenmesi ve korunması giderek daha karmaşık, pahalı ve zaman alıcı hale geldi. Kuruluşların veri gizliliği, uyumluluk ve aşağıdaki gibi düzenleyici gereksinimlere uyması gerekir: KVKK ve CCPAUyumluluğu sürdürmek için PII'yi tanımlamak ve korumak önemlidir. Ad, Sosyal Güvenlik Numarası (SSN), adres, e-posta, sürücü belgesi ve daha fazlası gibi kişisel bilgiler de dahil olmak üzere hassas verileri tanımlamanız gerekir. Tanımlamadan sonra bile hassas verilerin geniş ölçekte düzenlenmesi, maskelenmesi veya şifrelenmesi zahmetlidir.
Birçok şirket PII'yi manuel, zaman alıcı ve hataya açık yöntemlerle tanımlayıp etiketliyor yorumlar veritabanlarını, veri ambarlarını ve veri göllerini yok ederek hassas verilerini korumasız ve düzenleyici cezalara ve ihlal olaylarına karşı savunmasız hale getiriyor.
Bu yazıda, PII verilerini tespit etmek için otomatik bir çözüm sunuyoruz. Amazon Kırmızıya Kaydırma kullanma AWS Tutkal.
Çözüme genel bakış
Bu çözümle Redshift veri ambarımızdaki verilerde PII tespit ederek verileri alıp koruyoruz. Aşağıdaki hizmetleri kullanıyoruz:
- Amazon Kırmızıya Kaydırma her ölçekte en iyi fiyatı/performansı sunmak için AWS tasarımlı donanım ve makine öğrenimini (ML) kullanarak veri ambarları, operasyonel veritabanları ve veri gölleri genelinde yapılandırılmış ve yarı yapılandırılmış verileri analiz etmek için SQL kullanan bir bulut veri ambarı hizmetidir. Çözümümüz için verileri depolamak amacıyla Amazon Redshift'i kullanıyoruz.
- AWS Tutkal analiz, makine öğrenimi ve uygulama geliştirme için verileri keşfetmeyi, hazırlamayı ve birleştirmeyi kolaylaştıran sunucusuz bir veri entegrasyon hizmetidir. Amazon Redshift'te depolanan PII verilerini keşfetmek için AWS Glue'yu kullanıyoruz.
- Amazon Basit Depolama Hizmetleri (Amazon S3), sektör lideri ölçeklenebilirlik, veri kullanılabilirliği, güvenlik ve performans sunan bir depolama hizmetidir.
Aşağıdaki şema çözüm mimarimizi göstermektedir.
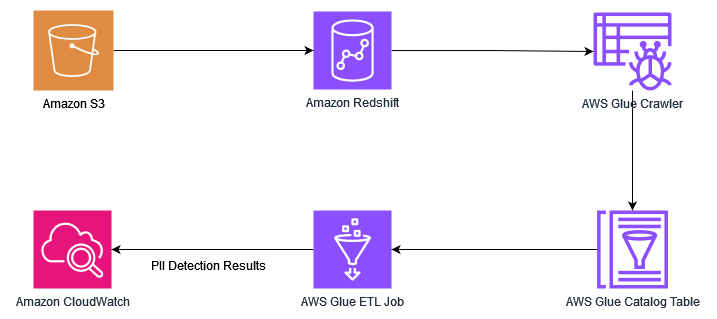
Çözüm, aşağıdaki üst düzey adımları içerir:
- Altyapıyı kullanarak bir AWS CloudFormation şablonu.
- Verileri Amazon S3'ten Redshift veri ambarına yükleyin.
- AWS Glue Veri Katalogunu tablolarla doldurmak için bir AWS Glue tarayıcısı çalıştırın.
- PII verilerini tespit etmek için bir AWS Glue işi çalıştırın.
- Çıktıyı kullanarak analiz edin Amazon Bulut İzleme.
Önkoşullar
Bu gönderide oluşturulan kaynaklar, özel bir alt ağ ve her iki tanımlayıcıyla birlikte bir VPC'nin mevcut olduğunu varsayar. Bu, VPC ve alt ağ yapılandırmasını önemli ölçüde değiştirmememizi sağlar. Bu nedenle, VPC uç noktalarımızı, onu kullanıma sunmayı seçtiğimiz VPC ve alt ağa göre ayarlamak istiyoruz.
Başlamadan önce önkoşul olarak aşağıdaki kaynakları oluşturun:
- Mevcut bir VPC
- Söz konusu VPC'deki özel bir alt ağ
- VPC ağ geçidi S3 uç noktası
- Bir VPC STS ağ geçidi uç noktası
AWS CloudFormation ile altyapıyı kurun
CloudFormation şablonuyla altyapınızı oluşturmak için aşağıdaki adımları tamamlayın:
- AWS hesabınızda AWS CloudFormation konsolunu açın.
- Klinik Yığını Başlat:

- Klinik Sonraki.
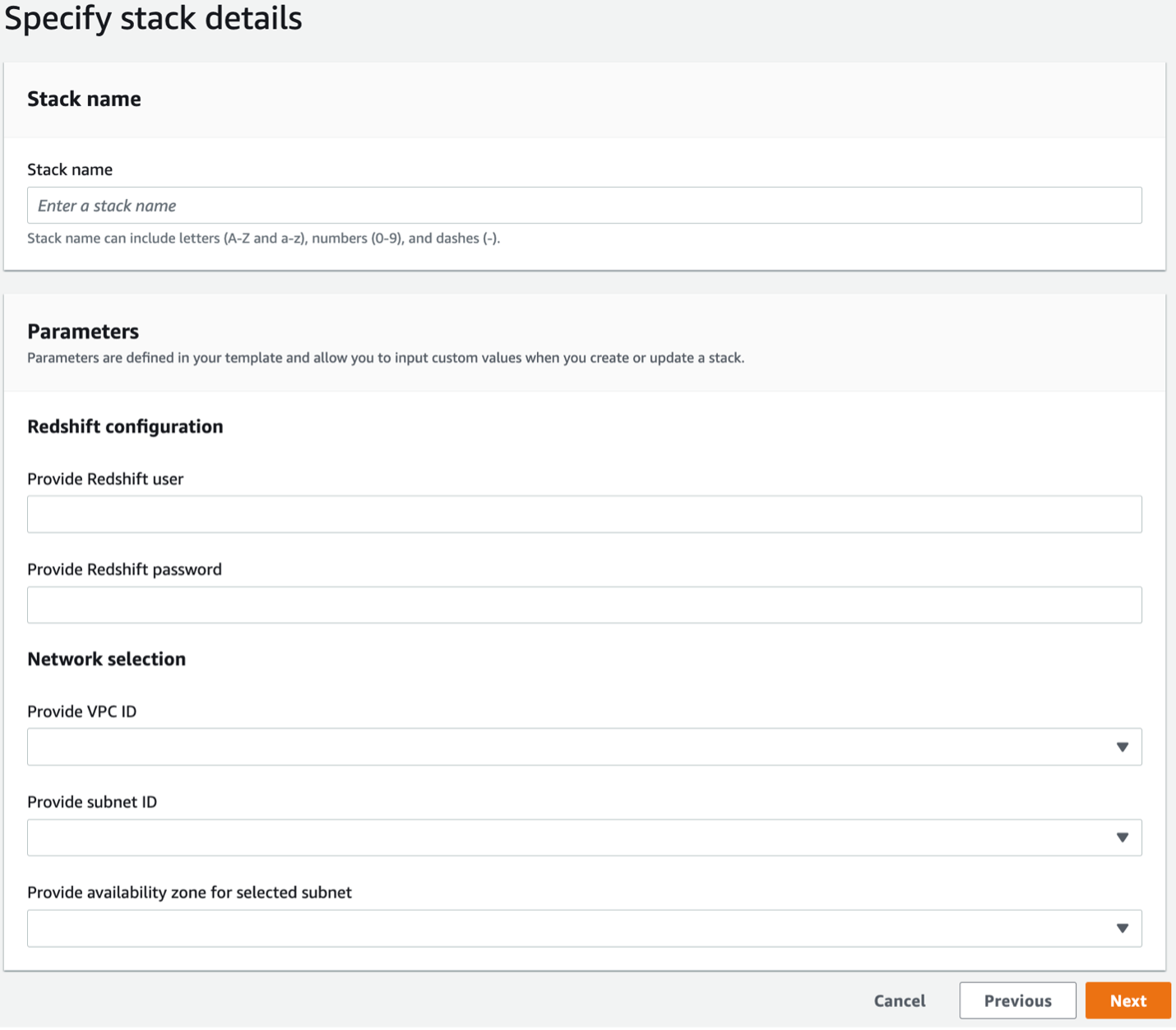
- Aşağıdaki bilgileri sağlayın:
- Yığın adı
- Amazon Redshift kullanıcı adı
- Amazon Redshift şifresi
- VPC kimliği
- Alt ağ kimliği
- Alt ağ kimliği için Erişilebilirlik Alanları
- Klinik Sonraki.
- Bir sonraki sayfada, seçin Sonraki.
- Ayrıntıları gözden geçirin ve seçin AWS CloudFormation'ın IAM kaynakları oluşturabileceğini kabul ediyorum.
- Klinik Yığın oluştur.
- için değerleri not edin
S3BucketNameveRedshiftRoleArnyığının üzerinde Çıkışlar sekmesi.
Amazon S3'ten Redshift Veri ambarına veri yükleme
İle KOPYALA komutu, bir veya daha fazla S3 klasöründe bulunan dosyalardan veri yükleyebiliriz. COPY komutunun Amazon S3'teki dosyaları nasıl konumlandırdığını belirtmek için FROM yan tümcesini kullanırız. FROM yan tümcesinin bir parçası olarak veri dosyalarına nesne yolunu sağlayabilir veya S3 nesne yollarının listesini içeren bir bildirim dosyasının konumunu sağlayabilirsiniz. Amazon S3'ten COPY bir HTTPS bağlantısı kullanır.
Bu yazı için örnek bir kişisel sağlık örneği kullanıyoruz veri kümesi. Verileri aşağıdaki adımlarla yükleyin:
- Amazon S3 konsolunda CloudFormation şablonundan oluşturulan S3 klasörüne gidin ve veri kümesini kontrol edin.
- kullanarak Redshift veri ambarına bağlanın. Sorgu Düzenleyicisi v2 Kullanıcı adı ve şifreyle birlikte CloudFormation yığınını kullanarak oluşturduğunuz veritabanıyla bağlantı kurarak.
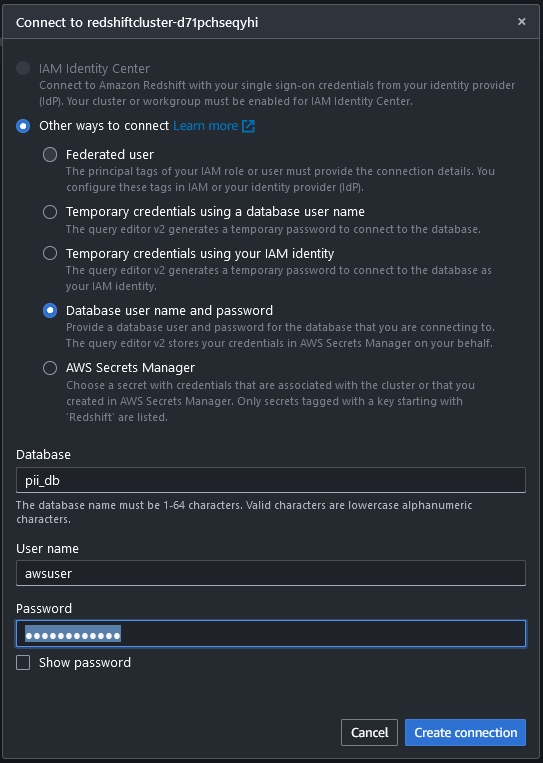
Bağlandıktan sonra Redshift veri ambarında tablo oluşturmak ve verileri kopyalamak için aşağıdaki komutları kullanabilirsiniz.
- Aşağıdaki sorguyla bir tablo oluşturun:
- Verileri S3 klasöründen yükleyin:
Aşağıdaki yer tutucular için değerleri sağlayın:
- Kırmızıya KaymaRolArn – ARN'yi CloudFormation yığınında bulun Çıkışlar çıkıntı
- S3BucketAdı – CloudFormation yığınındaki paket adıyla değiştirin
- aws bölgesi – CloudFormation şablonunu dağıttığınız Bölgeye geçin
- Verilerin yüklendiğini doğrulamak için aşağıdaki komutu çalıştırın:

Veri Kataloğu'nu tablolarla doldurmak için bir AWS Glue tarayıcısı çalıştırın
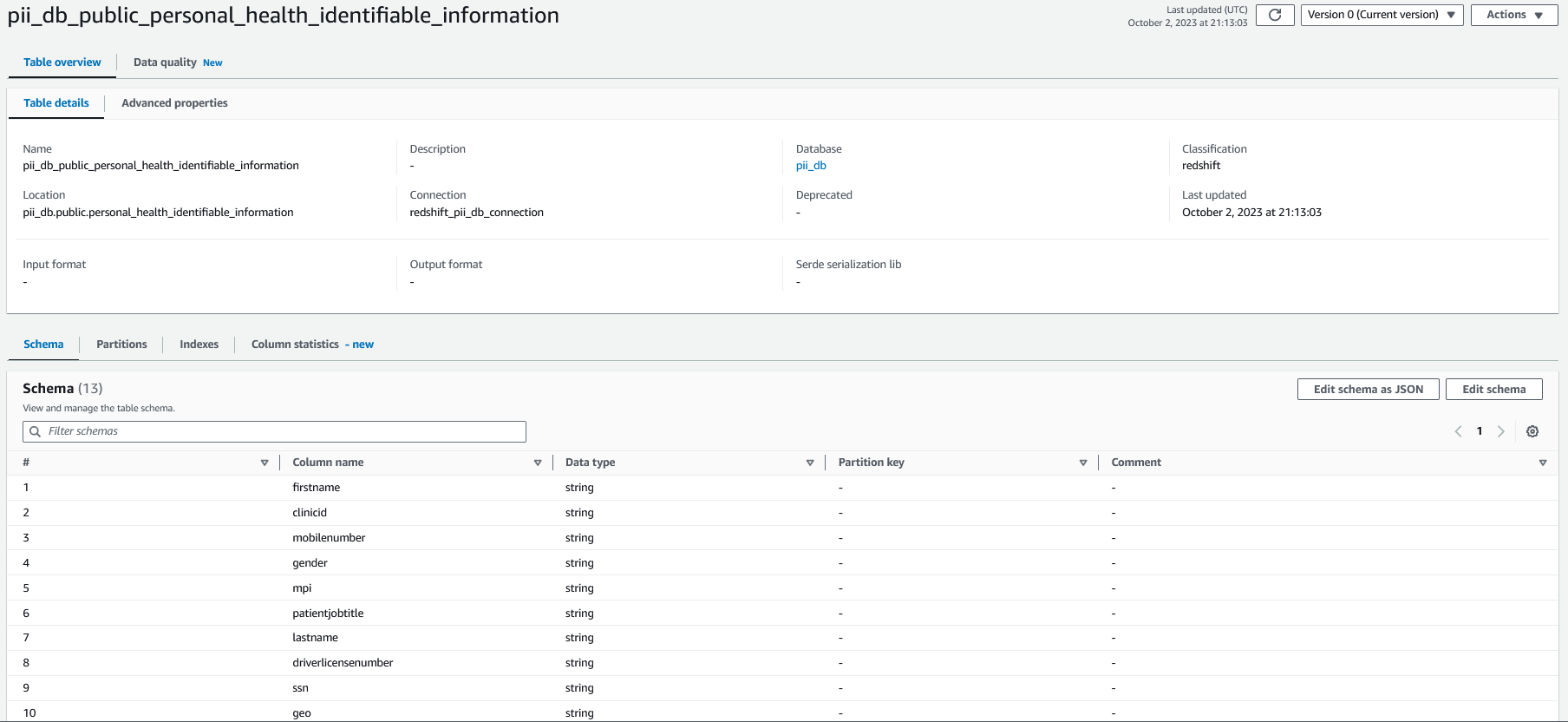
AWS Glue konsolunda CloudFormation yığınının parçası olarak dağıttığınız tarayıcıyı şu adla seçin: crawler_pii_db, Daha sonra seçmek Tarayıcıyı çalıştırın.

Tarayıcı tamamlandığında veritabanındaki tablolar bu isimle pii_db AWS Glue Veri Kataloğu'nda doldurulur ve tablo şeması aşağıdaki ekran görüntüsüne benzer.
Amazon Redshift'te PII verilerini tespit etmek ve ilgili sütunları maskelemek için bir AWS Glue işi çalıştırın
AWS Glue konsolunda seçin ETL İşleri Gezinti bölmesinde ve yapılandırmasını anlamak için pii-veri tespit etme işini bulun. Temel ve gelişmiş özellikler CloudFormation şablonu kullanılarak yapılandırılır.
Temel özellikler aşağıdaki gibidir:
- Tip - Kıvılcım
- Tutkal versiyonu – Tutkal 4.0
- Dil - Python
Gösterim amacıyla, otomatik ölçeklendirme özelliğiyle birlikte iş yer imleri seçeneği de devre dışı bırakılır.

Bağlantılar ve iş parametreleriyle ilgili gelişmiş özellikleri de yapılandırıyoruz.
Amazon Redshift'te bulunan verilere erişmek için JDBC bağlantısını kullanan bir AWS Glue bağlantısı oluşturduk.
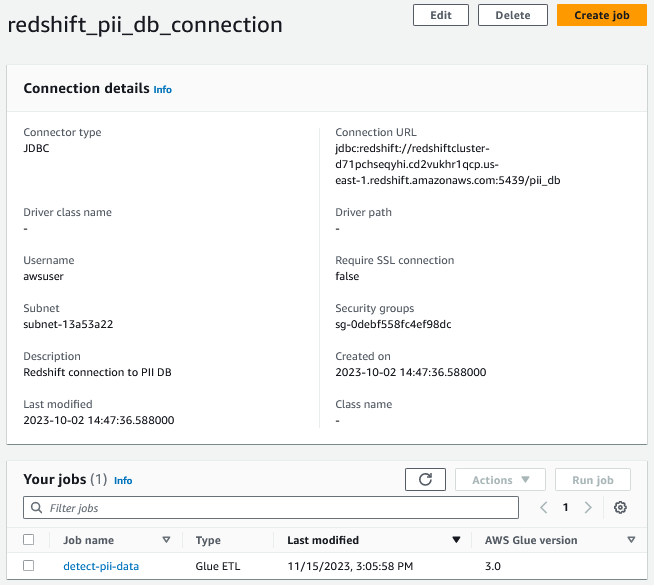
Ayrıca özel parametreleri anahtar/değer çiftleri olarak da sağlıyoruz. Bu yazı için PII'yi beş farklı tespit kategorisine ayırıyoruz:
- evrensel -
PERSON_NAME,EMAIL,CREDIT_CARD - hipaa -
PERSON_NAME,PHONE_NUMBER,USA_SSN,USA_ITIN,BANK_ACCOUNT,USA_DRIVING_LICENSE,USA_HCPCS_CODE,USA_NATIONAL_DRUG_CODE,USA_NATIONAL_PROVIDER_IDENTIFIER,USA_DEA_NUMBER,USA_HEALTH_INSURANCE_CLAIM_NUMBER,USA_MEDICARE_BENEFICIARY_IDENTIFIER - ağ -
IP_ADDRESS,MAC_ADDRESS - Amerika Birleşik Devletleri -
PHONE_NUMBER,USA_PASSPORT_NUMBER,USA_SSN,USA_ITIN,BANK_ACCOUNT - görenek – Koordinatlar
Bu çözümü başka ülkelerden deniyorsanız, bu çözüm ABD bölgeleri temel alınarak oluşturulduğundan, özel kategoriyi kullanarak özel PII alanlarını belirtebilirsiniz.
Gösterim amacıyla tek bir tablo kullanıyoruz ve bunu aşağıdaki parametre olarak aktarıyoruz:
--table_name: table_nameBu yazı için tabloya bir ad veriyoruz personal_health_identifiable_information.

Bu parametreleri bireysel iş kullanım durumuna göre özelleştirebilirsiniz.
İşi çalıştırın ve bekleyin Success durumu.
İşin iki hedefi var. İlk hedef, Redshift tablosundaki PII verileriyle ilgili sütunları belirlemek ve bu sütun adlarının bir listesini oluşturmaktır. İkinci amaç ise hedef tablonun belirli sütunlarındaki verilerin gizlenmesidir. İkinci hedefin bir parçası olarak tablo verilerini okur, bu belirli sütunlara kullanıcı tanımlı bir maskeleme işlevi uygular ve Redshift aşama tablosunu kullanarak hedef tablodaki verileri günceller (stage_personal_health_identifiable_information) yükselişler için.
Alternatif olarak dinamik veri maskelemeyi de kullanabilirsiniz (DDM) veri ambarınızdaki hassas verileri korumak için Amazon Redshift'te.
CloudWatch'u kullanarak çıktıyı analiz edin
İş tamamlandığında AWS Glue işinin nasıl çalıştığını anlamak için CloudWatch günlüklerini inceleyelim. CloudWatch günlüklerine aşağıdakileri seçerek gidebiliriz: Çıktı günlükleri AWS Glue konsolundaki iş ayrıntıları sayfasında.

İş, AWS Glue işine duyarlı veri algılama alanları kullanılarak iletilen özel alanlar da dahil olmak üzere PII verilerini içeren her sütunu tanımladı.

Temizlemek
Altyapıyı temizlemek ve ek ücretlerden kaçınmak için aşağıdaki adımları tamamlayın:
- S3 kaplarını boşaltın.
- Oluşturduğunuz uç noktaları silin.
- Kalan kaynakları silmek için CloudFormation yığınını AWS CloudFormation konsolu aracılığıyla silin.

Sonuç
Bu çözüm sayesinde Redshift kümelerinde bulunan verileri bir AWS Glue işi kullanarak otomatik olarak tarayabilir, PII'yi tanımlayabilir ve gerekli eylemleri gerçekleştirebilirsiniz. Bu, kuruluşunuza veri güvenliği ve veri yönetimine katkıda bulunan güvenlik, uyumluluk, yönetim ve veri koruma özellikleri konusunda yardımcı olabilir.
Yazarlar Hakkında
 Manikanta Gona AWS Profesyonel Hizmetler'de Veri ve Makine Öğrenimi Mühendisidir. AWS'ye 2021'de BT alanında 6 yılı aşkın deneyimle katıldı. AWS'de Data Lake uygulamalarına ve Amazon OpenSearch Service'i kullanarak Arama, Analitik iş yüklerine odaklanıyor. Boş zamanlarında bahçeyle uğraşmayı, kocasıyla yürüyüşe çıkmayı ve bisiklete binmeyi sever.
Manikanta Gona AWS Profesyonel Hizmetler'de Veri ve Makine Öğrenimi Mühendisidir. AWS'ye 2021'de BT alanında 6 yılı aşkın deneyimle katıldı. AWS'de Data Lake uygulamalarına ve Amazon OpenSearch Service'i kullanarak Arama, Analitik iş yüklerine odaklanıyor. Boş zamanlarında bahçeyle uğraşmayı, kocasıyla yürüyüşe çıkmayı ve bisiklete binmeyi sever.
 Denys Novikov Amazon Web Services'te Profesyonel Hizmetler ekibinde Kıdemli Veri Gölü Mimarıdır. Kurumsal müşteriler için Analitik, Veri Yönetimi ve Büyük Veri sistemlerinin tasarımı ve uygulanması konusunda uzmanlaşmıştır.
Denys Novikov Amazon Web Services'te Profesyonel Hizmetler ekibinde Kıdemli Veri Gölü Mimarıdır. Kurumsal müşteriler için Analitik, Veri Yönetimi ve Büyük Veri sistemlerinin tasarımı ve uygulanması konusunda uzmanlaşmıştır.
 Anjan Mukherjee AWS'de büyük veri ve analiz çözümlerinde uzmanlaşmış bir Veri Gölü Mimarıdır. Müşterilerin AWS platformunda ölçeklenebilir, güvenilir, güvenli ve yüksek performanslı uygulamalar oluşturmasına yardımcı oluyor.
Anjan Mukherjee AWS'de büyük veri ve analiz çözümlerinde uzmanlaşmış bir Veri Gölü Mimarıdır. Müşterilerin AWS platformunda ölçeklenebilir, güvenilir, güvenli ve yüksek performanslı uygulamalar oluşturmasına yardımcı oluyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/automatically-detect-personally-identifiable-information-in-amazon-redshift-using-aws-glue/

