Amazon Kırmızıya Kaydırma yaygın olarak kullanılan, tam olarak yönetilen, petabayt ölçeğinde bir bulut veri ambarıdır. On binlerce müşteri, analitik iş yüklerini güçlendirmek için her gün exabaytlarca veriyi işlemek için Amazon Redshift'i kullanıyor. Müşteriler, hizmet fiyatı-performans, kullanım kolaylığı, güvenlik ve güvenilirlik avantajlarından yararlanmak için Google BigQuery gibi diğer veri ambarlarından Amazon Redshift'e geçişi kolaylaştıran araçlar arıyor.
Bu gönderide, Google BigQuery'den Amazon Redshift'e geçişinizi hızlandırmak için AWS yerel hizmetlerini nasıl kullanacağınızı gösteriyoruz. Kullanırız AWS Tutkal, tamamen yönetilen, sunucusuz bir ETL (ayıklama, dönüştürme ve yükleme) hizmeti ve AWS Glue için Google BigQuery Bağlayıcısı (daha fazla bilgi için bkz. AWS Glue özel bağlayıcılarını kullanarak verileri Google BigQuery'den Amazon S3'e taşıma). Ayrıca, birden çok tablonun Amazon Redshift'e geçişini kolaylaştırmak için otomasyon ve esneklik de ekledik. Özel Otomatik Yükleyici Çerçevesi.
Çözüme genel bakış
Çözüm, verileri Google BigQuery'den Google BigQuery'ye taşımak için ölçeklenebilir ve yönetilen bir veri taşıma iş akışı sağlar. Amazon Basit Depolama Hizmeti (Amazon S3) ve ardından Amazon S3'ten Amazon Redshift'e. Bu önceden oluşturulmuş çözüm, giriş parametrelerini kullanarak verileri paralel olarak yüklemek için ölçeklendirir.
Aşağıdaki mimari diyagram, çözümün nasıl çalıştığını göstermektedir. Google BigQuery'ye bağlanmak için taşıma yapılandırmasının ayarlanmasıyla başlar, ardından veritabanı şemalarını dönüştürür ve son olarak verileri Amazon Redshift'e taşır.
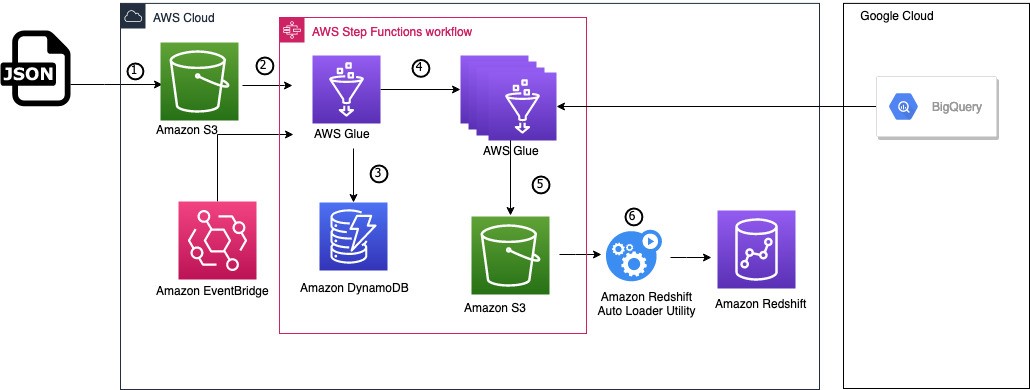
İş akışı aşağıdaki adımları içerir:
- Bu çözüm için seçtiğiniz bir S3 klasörüne bir yapılandırma dosyası yüklenir. Bu JSON dosyası, taşıma meta verilerini, yani aşağıdakileri içerir:
- Google BigQuery projelerinin ve veri kümelerinin listesi.
- Her proje ve veri kümesi çifti için geçirilecek tüm tabloların listesi.
- An Amazon EventBridge kural tetikler AWS Basamak İşlevleri tabloları taşımaya başlamak için durum makinesi.
- Step Functions durum makinesi, taşınacak tabloları yineler ve meta verileri Google BigQuery'den çıkarmak ve bir AWS Glue Python kabuk işi çalıştırır. Amazon DinamoDB tabloların geçiş durumunu izlemek için kullanılan tablo.
- Durum makinesi, maksimum geçiş işi sayısına bağlı olarak tablo geçişini paralel olarak çalıştırmak için bu DynamoDB tablosundaki meta verileri yineler. Google BigQuery'deki sınırlar veya kotalar. Aşağıdaki adımları gerçekleştirir:
- AWS Glue geçiş işini her tablo için paralel olarak çalıştırır.
- DynamoDB tablosundaki çalıştırma durumunu izler.
- Tablolar taşındıktan sonra, hataları kontrol eder ve çıkar.
- Google BigQuery'den dışa aktarılan veriler Amazon S3'e kaydedilir. Amazon S3'ü (AWS Glue işleri doğrudan Amazon Redshift tablolarına yazabilse de) birkaç özel nedenden dolayı kullanıyoruz:
- Veri taşıma ve veri yükleme adımlarını birbirinden ayırabiliriz.
- Verileri yeniden yükleme veya işlemi duraklatma özelliğiyle yükleme adımlarında daha fazla kontrol sunar.
- Amazon Redshift yük durumunun ayrıntılı bir şekilde izlenmesini sağlar.
- The Özel Otomatik Yükleyici Çerçevesi hedef veritabanında otomatik olarak şemalar ve tablolar oluşturur ve verileri sürekli olarak Amazon S3'ten Amazon Redshift'e yükler.
Dikkate alınması gereken birkaç ek nokta:
- Hedef şemayı ve tabloları Amazon Redshift veritabanında zaten oluşturduysanız Özel Otomatik Yükleyici Çerçevesini şemayı otomatik olarak algılayıp dönüştürmeyecek şekilde yapılandırabilirsiniz.
- Google BigQuery şemasını dönüştürme konusunda daha fazla kontrol istiyorsanız, AWS Şema Dönüştürme Aracı (AWS ÖTV). Daha fazla bilgi için bkz. AWS Schema Conversion aracını (SCT) kullanarak Google BigQuery'yi Amazon Redshift'e taşıyın.
- Bu yazı itibariyle, ne AWS SCT ne de Özel Otomatik Yükleyici Çerçevesi iç içe geçmiş veri türlerinin (kayıt, dizi ve yapı) dönüştürülmesini desteklememektedir. Amazon Redshift, Super veri türünü kullanan yarı yapılandırılmış verileri destekler, dolayısıyla tablonuz bu tür karmaşık veri türlerini kullanıyorsa hedef tabloları manuel olarak oluşturmanız gerekir.
Çözümü dağıtmak için iki ana adım vardır:
- Çözüm yığınını kullanarak dağıtın AWS CloudFormation.
- Amazon S3'ten Amazon Redshift'e dosya yüklemek için Özel Otomatik Yükleyici Çerçevesini dağıtın ve yapılandırın.
Önkoşullar
Başlamadan önce, aşağıdakilere sahip olduğunuzdan emin olun:
- Google Cloud'da bir hesap, özellikle Google BigQuery izinlerine sahip bir hizmet hesabı.
- ile bir AWS hesabı AWS Kimlik ve Erişim Yönetimi yapılandırmak için bir erişim anahtarına ve gizli anahtara sahip (IAM) kullanıcısı AWS Komut Satırı Arayüzü (AWS CLI). IAM kullanıcısının ayrıca bir IAM rolü ve politikaları oluşturmak için izinlere ihtiyacı vardır.
- Bir Amazon Redshift kümesi veya Amazon Redshift Sunucusuz çalışma grubu. Eğer sahip değilseniz, bkz. Amazon Redshift Sunucusuz.
- Bir S3 kepçesi. Mevcut paketlerinizden birini kullanmak istemiyorsanız, yeni bir tane oluştur. Daha sonra CloudFormation yığınına giriş parametresi olarak ilettiğinizde kullanılacak paketin adını not edin.
- Taşınacak tabloların listesini içeren bir yapılandırma dosyası. Bu dosya aşağıdaki yapıya sahip olmalıdır:
Alternatif olarak, yapabilirsiniz demo dosyasını indir, Medicare & Medicaid Services Merkezleri tarafından oluşturulan açık veri kümesi.
Bu örnekte, dosyayı adlandırdık bq-mig-config.json
-
- Google hesabınızı yapılandırın.
- AWS Glue için bir IAM rolü oluşturun (ve IAM rolünün adını not edin).
- AWS Glue için Google BigQuery Connector'a abone olun ve etkinleştirin.
Çözümü AWS CloudFormation kullanarak dağıtın
AWS CloudFormation kullanarak çözüm yığınını dağıtmak için aşağıdaki adımları tamamlayın:
- Klinik Yığını Başlat:
![]()
Bu şablon, AWS kaynaklarını us-east-1 Bölge. Farklı bir Bölgeye dağıtım yapmak istiyorsanız şablonu indirin bigquery-cft.yaml ve manuel olarak başlatın: AWS CloudFormation konsolunda Yeni kaynaklarla yığın oluştur'u seçin ve indirdiğiniz şablon dosyasını yükleyin.
Tedarik edilen kaynakların listesi aşağıdaki gibidir:
-
- Yapılandırma dosyasının karşıya yüklenmesi sırasında Step Functions durum makinesini başlatmak için bir EventBridge kuralı.
- Taşıma mantığını çalıştıran bir Step Functions durum makinesi. Aşağıdaki diyagram durum makinesini göstermektedir.
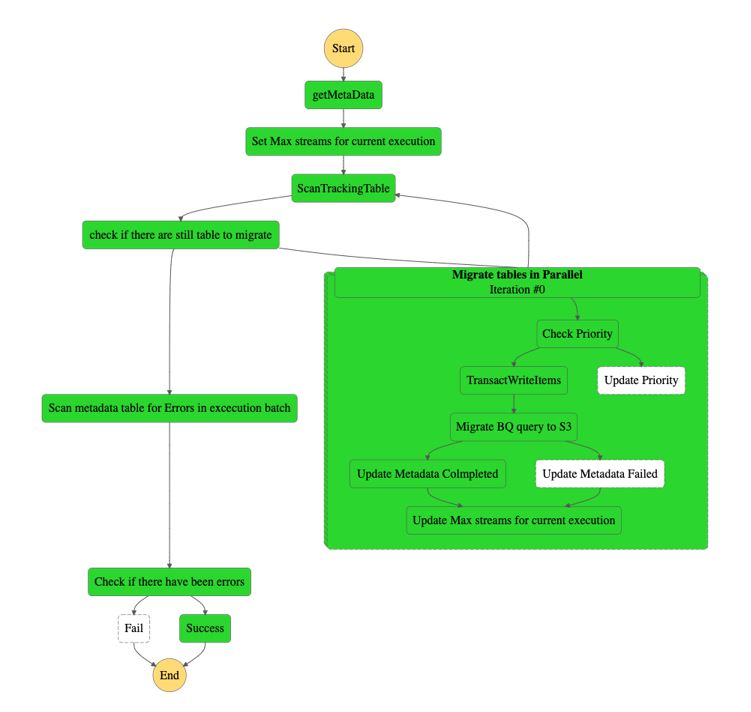
- Meta verileri Google BigQuery'den çıkarmak için kullanılan bir AWS Glue Python kabuk işi. Meta veriler, geçiş işini önceliklendirmek için hesaplanmış bir öznitelikle bir DynamoDB tablosunda depolanacaktır. Varsayılan olarak, bağlayıcı her 400 MB için bir bölüm oluşturur okunan tabloda (filtrelemeden önce). Bu yazı itibariyle, Google BigQuery Depolama API'sı maksimum var paralel okuma akışları için kota, bu nedenle, 400 GB'tan büyük tablolar için çalışan düğümleri sınırını belirledik. Ayrıca, bu değerlere göre paralel olarak çalışabilecek maksimum iş sayısını da hesaplıyoruz.
- Her bir Google BigQuery tablosundan verileri ayıklamak ve Amazon S3'te Parquet biçiminde kaydetmek için kullanılan bir AWS Glue ETL işi.
- Bir DynamoDB tablosu (
bq_to_s3_tracking) taşınacak her tablo için meta verileri depolamak için kullanılır (tablonun boyutu, taşınan verileri depolamak için kullanılan S3 yolu ve tabloyu geçirmek için gereken çalışan sayısı). - Bir DynamoDB tablosu (
bq_to_s3_maxstreams) durum makinesi çalıştırması başına maksimum akış sayısını depolamak için kullanılır. Bu, sınırlar veya kotalar nedeniyle iş başarısızlıklarını en aza indirmemize yardımcı olur. DynamoDB tablosunun adını özelleştirmek için Bulut Oluşumu şablonunu kullanın. DynamoDB tablosunun öneki şudur:bq_to_s3. - Durum makinesi ve AWS Glue işleri için gereken IAM rolleri.
- Klinik Sonraki.
- İçin Yığın adı, isim girin.
- İçin parametreler, aşağıdaki tabloda listelenen parametreleri girin ve ardından oluşturmak.
| CloudFormation Şablon Parametresi | İzin Verilen Değerler | Açıklama |
InputBucketName |
S3 grup adı |
AWS Glue işinin taşınan verileri depoladığı S3 klasörü. Veriler aslında adlı bir klasörde saklanacak. |
InputConnectionName |
AWS Glue bağlantı adı, varsayılan değer: glue-bq-connector-24 |
Google BigQuery bağlayıcısı kullanılarak oluşturulan AWS Glue bağlantısının adı. |
InputDynamoDBTablePrefix |
DynamoDB tablo adı öneki, varsayılan değer: bq_to_s3 |
Çözüm tarafından oluşturulan iki DynamoDB tablosunu adlandırırken kullanılacak önek. |
InputGlueETLJob |
AWS Glue ETL iş adı, varsayılan değer: bq-migration-ETL |
AWS Glue ETL işine vermek istediğiniz ad. Gerçek komut dosyası, parametrede belirtilen S3 yoluna kaydedilir. InputGlueS3Path. |
InputGlueMetaJob |
AWS Glue Python kabuk işi adı, varsayılan değer: bq-get-metadata |
AWS Glue Python kabuk işine vermek istediğiniz ad. Gerçek komut dosyası, parametrede belirtilen S3 yoluna kaydedilir. InputGlueS3Path. |
InputGlueS3Path |
S3 yolu, varsayılan s3://aws-glue-scripts-${AWS::Account}-${AWS::Region}/admin/ |
Bu, yığının AWS Glue işleri için betikleri kopyalayacağı S3 yoludur. Değiştirmeyi unutmayın: ${AWS::Account} gerçek AWS hesap kimliğiyle ve ${AWS::Region} kullanmayı planladığınız Bölge ile veya tam bir yolda kendi grubunuzu ve ön ekinizi sağlayın. |
InputMaxParallelism |
Çalıştırılacak paralel geçiş işi sayısı, varsayılan değer 30'dur | Eşzamanlı olarak taşımak istediğiniz maksimum tablo sayısı. |
InputBQSecret |
AWS Secrets Manager gizli adı | Google BigQuery kimlik bilgilerini depoladığınız AWS Secrets Manager sırrının adı. |
InputBQProjectName |
Google BigQuery proje adı | Geçici tabloları depolamak istediğiniz projenizin Google BigQuery'deki adı; projede yazma izinlerine ihtiyacınız olacak. |
StateMachineName |
Adım İşlevleri makine adını belirtir, varsayılan değer
|
Adım İşlevleri durum makinesinin adı. |
SourceS3BucketName |
S3 grup adı, varsayılan değer: aws-blogs-artifacts-public |
Bu gönderinin yapıtlarının depolandığı S3 klasörü. Varsayılanı değiştirmeyin. |
Amazon S3'ten Amazon Redshift'e dosya yüklemek için Özel Otomatik Yükleyici Çerçevesini dağıtın ve yapılandırın
Özel Otomatik Yükleyici Çerçevesi yardımcı programı, Amazon Redshift'e veri alımını kolaylaştırır ve veri dosyalarını Amazon S3'ten Amazon Redshift'e otomatik olarak yükler. Dosyalar, Amazon S3'te önceden yapılandırılmış konumlara basitçe bırakılarak ilgili tablolarla eşlenir. Mimari ve dahili iş akışı hakkında daha fazla ayrıntı için bkz. Özel Otomatik Yükleyici Çerçevesi.
Özel Otomatik Yükleyici Çerçevesini ayarlamak için aşağıdaki adımları tamamlayın:
- Klinik Yığını Başlat CloudFormation yığınını dağıtmak için
us-east-1Bölge:
![]()
- AWS CloudFormation konsolunda şunu seçin: Sonraki.
- Kaynakların başarılı bir şekilde oluşturulmasını sağlamak için aşağıdaki parametreleri sağlayın. Bu değerleri önceden topladığınızdan emin olun.
| Parametre adı | İzin Verilen Değerler | Açıklama |
|---|---|---|
CopyCommandSchedule |
cron(0/5 * ? * * *) |
EventBridge kuralları KickoffFileProcessingSchedule ve QueueRSProcessingSchedule bu programa göre tetiklenir. Varsayılan 5 dakikadır. |
DatabaseName |
dev |
Amazon Redshift veritabanı adı. |
DatabaseSchemaName |
public |
Amazon Redshift şema adı. |
DatabaseUserName |
demo |
Amazon Redshift veritabanında ve şemasında COPY komutlarını çalıştırma erişimi olan Amazon Redshift kullanıcı adı. |
RedshiftClusterIdentifier |
democluster |
Amazon Redshift küme adı. |
RedshiftIAMRoleARN |
arn:aws:iam::7000000000:role/RedshiftDemoRole |
S3 klasörüne erişimi olan Amazon Redshift kümesi ekli rolü. Bu rol COPY komutlarında kullanılır. |
SourceS3Bucket |
Your-bucket-name |
Verilerin bulunduğu S3 klasörü. Önceki yığında belirtildiği gibi, taşınan verileri depolamak için kullandığınız aynı grubu kullanın. |
CopyCommandOptions |
delimiter '|' gzip |
Ek COPY komutu veri formatı parametrelerini aşağıdaki gibi sağlayın:
|
InitiateSchemaDetection |
Yes |
Dosya yüklemeden önce şemayı dinamik olarak algılama ayarı. |
Aşağıdaki ekran görüntüsü parametrelerimizin bir örneğini göstermektedir.
- Klinik oluşturmak.
- Yığın oluşturmanın ilerlemesini izleyin ve tamamlanana kadar bekleyin.
- Özel Otomatik Yükleyici Çerçevesi yapılandırmasını doğrulamak için şu adreste oturum açın: Amazon S3 konsolu ve bir değer olarak sağladığınız S3 klasörüne gidin.
SourceS3Bucketparametre.
adlı yeni bir dizin görmelisiniz. s3-redshift-loader-source yaratıldı.
Çözümü test edin
Çözümü test etmek için aşağıdaki adımları tamamlayın:
- Yapılandırma dosyasını önkoşullara göre oluşturun. Ayrıca indirebilirsiniz tanıtım dosyası.
- S3 klasörünü kurmak için Amazon S3 konsolunda klasöre gidin
bq-mig-configyığında sağladığınız kovada. - Yapılandırma dosyasını içine yükleyin.
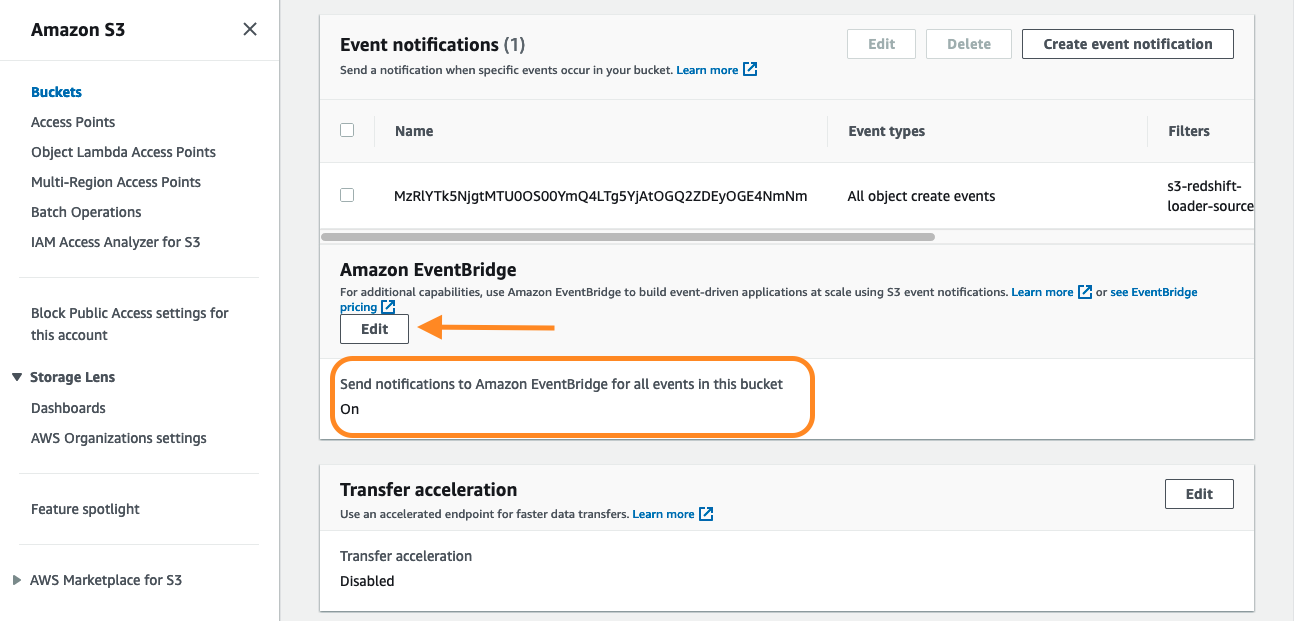
- Bölüme EventBridge bildirimlerini etkinleştirmek için, klasörü konsolda ve Emlaklar sekmesini bulun Etkinlik bildirimleri.
- içinde Amazon EventBridge bölümü, seçim Düzenle.
- seç On, Daha sonra seçmek Değişiklikleri Kaydet.
- AWS Step Function konsolunda durum makinesinin çalışmasını izleyin.
- Amazon Redshift'te yüklerin durumunu izleyin. Talimatlar için bkz. Mevcut Yükleri Görüntüleme.
- Amazon Redshift Query Editor V2'yi açın ve verilerinizi sorgulayın.
Fiyatlandırma hususları
Verileri Google BigQuery'den Amazon S3'e taşımak için çıkış ücretleriniz olabilir. Verilerinizi Google bulut faturalandırma konsolunuzda taşımanın maliyetini inceleyin ve hesaplayın. Bu yazının yazıldığı tarihte, AWS Glue 3.0 veya sonraki sürümü, Spark ETL işleri için minimum 0.44 dakikalık olmak üzere saniye başına faturalanan DPU saati başına 1 USD ücret almaktadır. Daha fazla bilgi için bakınız AWS Glue Fiyatlandırması. Ile otomatik ölçeklendirme etkinleştirildiğinde AWS Glue, çalıştırılan işin her aşamasındaki paralelliğe veya mikro partiye bağlı olarak çalışanları otomatik olarak kümeye ekler ve kümeden çıkarır.
Temizlemek
Gelecekte masraflara maruz kalmamak için kaynaklarınızı temizleyin:
- CloudFormation çözüm yığınını silin.
- CloudFormation Özel Otomatik Yükleyici Çerçevesi yığınını silin.
Sonuç
Bu gönderide, verilerinizi Google BigQuery'den Amazon Redshift'e taşımak için ölçeklenebilir ve otomatikleştirilmiş bir veri ardışık düzeninin nasıl oluşturulacağını gösterdik. Özel Otomatik Yükleyici çerçevesinin şema algılamayı nasıl otomatik hale getirebileceğini, S3 dosyalarınız için tablolar oluşturabileceğini ve dosyaları sürekli olarak Amazon Redshift deponuza yükleyebileceğini de vurguladık. Bu yaklaşımla, Google BigQuery'deki tüm projelerin (hatta aynı anda birden çok projenin) Amazon Redshift'e taşınmasını otomatikleştirebilirsiniz. Bu, otomatik tablo geçişi paralelleştirme aracılığıyla Amazon Redshift'e veri taşıma sürelerini önemli ölçüde iyileştirmeye yardımcı olur.
Amazon Redshift'teki otomatik kopyalama özelliği, basit bir SQL komutuyla Amazon S3'ten otomatik veri yüklemeyi basitleştirir; kullanıcılar, Amazon Redshift'i kullanarak Amazon S3'ten Amazon Redshift'e veri alımını kolayca otomatikleştirebilir otomatik kopya önizleme özelliği
AWS Glue için Google BigQuery Connector'ın performansı hakkında daha fazla bilgi için bkz. AWS Glue Connector for Google BigQuery ile terabaytlarca veriyi Google Cloud'dan Amazon S3'e hızla taşıyın ve büyük miktarda veriyi (1.9 TB) hızlı bir şekilde (yaklaşık 3 dakika) Amazon S8'e nasıl taşıyacağınızı öğrenin.
AWS Glue ETL işleri hakkında daha fazla bilgi edinmek için bkz. AWS Glue otomatik kod oluşturma ve iş akışları ile veri işlem hatlarını basitleştirin ve AWS Glue Studio ile ETL'yi kolaylaştırma.
Yazarlar Hakkında
 tahir aziz AWS'de Analitik Çözüm Mimarıdır. 13 yılı aşkın bir süredir veri ambarları ve büyük veri çözümleri oluşturmak için çalıştı. Müşterilerin AWS'de uçtan uca analiz çözümleri tasarlamasına yardımcı olmayı seviyor. İş dışında seyahat etmeyi ve yemek yapmayı sever.
tahir aziz AWS'de Analitik Çözüm Mimarıdır. 13 yılı aşkın bir süredir veri ambarları ve büyük veri çözümleri oluşturmak için çalıştı. Müşterilerin AWS'de uçtan uca analiz çözümleri tasarlamasına yardımcı olmayı seviyor. İş dışında seyahat etmeyi ve yemek yapmayı sever.
 Ritesh Kumar Sinha San Francisco merkezli bir Analitik Uzmanı Çözüm Mimarıdır. 16 yılı aşkın bir süredir müşterilerin ölçeklenebilir veri ambarı ve büyük veri çözümleri oluşturmasına yardımcı olmuştur. AWS'de verimli uçtan uca çözümler tasarlamayı ve oluşturmayı seviyor. Boş zamanlarında kitap okumayı, yürümeyi ve yoga yapmayı çok seviyor.
Ritesh Kumar Sinha San Francisco merkezli bir Analitik Uzmanı Çözüm Mimarıdır. 16 yılı aşkın bir süredir müşterilerin ölçeklenebilir veri ambarı ve büyük veri çözümleri oluşturmasına yardımcı olmuştur. AWS'de verimli uçtan uca çözümler tasarlamayı ve oluşturmayı seviyor. Boş zamanlarında kitap okumayı, yürümeyi ve yoga yapmayı çok seviyor.
 Fabrizio Napolitano DB ve Analitik için Baş Uzman Çözüm Mimarıdır. Son 20 yıldır analitik alanında çalıştı ve Kanada'ya taşındıktan sonra kısa süre önce ve oldukça sürpriz bir şekilde Hokey Babası oldu.
Fabrizio Napolitano DB ve Analitik için Baş Uzman Çözüm Mimarıdır. Son 20 yıldır analitik alanında çalıştı ve Kanada'ya taşındıktan sonra kısa süre önce ve oldukça sürpriz bir şekilde Hokey Babası oldu.
 manjula nagineni New York merkezli bir AWS Kıdemli Çözüm Mimarıdır. AWS Cloud hizmetlerini benimserken büyük finansal hizmet kurumlarıyla birlikte çalışarak büyük ölçekli uygulamalarını mimari ve modernize ediyor. Büyük veri iş yüklerini bulutta yerel olarak tasarlama konusunda tutkulu. Finans, perakende ve telekom gibi birçok alanda yazılım geliştirme, analitik ve mimaride 20 yılı aşkın BT deneyimine sahiptir.
manjula nagineni New York merkezli bir AWS Kıdemli Çözüm Mimarıdır. AWS Cloud hizmetlerini benimserken büyük finansal hizmet kurumlarıyla birlikte çalışarak büyük ölçekli uygulamalarını mimari ve modernize ediyor. Büyük veri iş yüklerini bulutta yerel olarak tasarlama konusunda tutkulu. Finans, perakende ve telekom gibi birçok alanda yazılım geliştirme, analitik ve mimaride 20 yılı aşkın BT deneyimine sahiptir.
 Sohaib Katariwala AWS'de Analitik Uzmanı Çözüm Mimarıdır. Kuruluşların verilerinden içgörü elde etmelerine yardımcı olma konusunda 12 yıldan fazla deneyime sahiptir.
Sohaib Katariwala AWS'de Analitik Uzmanı Çözüm Mimarıdır. Kuruluşların verilerinden içgörü elde etmelerine yardımcı olma konusunda 12 yıldan fazla deneyime sahiptir.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Adryenn Ashley ile Geleceği Basmak. Buradan Erişin.
- PREIPO® ile PRE-IPO Şirketlerinde Hisse Al ve Sat. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/migrate-from-google-bigquery-to-amazon-redshift-using-aws-glue-and-custom-auto-loader-framework/

