Büyük Dil Modelleri (LLM'ler), doğal dil işleme (NLP) alanında devrim yaratarak dil çevirisi, metin özetleme ve duygu analizi gibi görevleri iyileştirdi. Ancak bu modellerin boyutu ve karmaşıklığı büyümeye devam ettikçe performanslarını ve davranışlarını izlemek giderek zorlaşıyor.
Yüksek Lisans'ların performansını ve davranışlarını izlemek, güvenliklerini ve etkinliklerini sağlamak açısından kritik bir görevdir. Önerilen mimarimiz, çevrimiçi LLM izleme için ölçeklenebilir ve özelleştirilebilir bir çözüm sağlayarak ekiplerin izleme çözümünüzü özel kullanım durumlarınıza ve gereksinimlerinize göre uyarlamasına olanak tanır. Mimarimiz, AWS hizmetlerini kullanarak LLM davranışına ilişkin gerçek zamanlı görünürlük sağlar ve ekiplerin tüm sorunları veya anormallikleri hızlı bir şekilde belirleyip çözmesine olanak tanır.
Bu yazıda, çevrimiçi LLM izleme için birkaç ölçüm ve AWS hizmetlerini kullanarak ölçeklendirmeye yönelik ilgili mimarilerini gösteriyoruz: Amazon Bulut İzleme ve AWS Lambda. Bu, mümkün olanın ötesinde özelleştirilebilir bir çözüm sunar. model değerlendirmesi olan işler Amazon Ana Kayası.
Çözüme genel bakış
Dikkate alınması gereken ilk şey, farklı ölçümlerin farklı hesaplama hususları gerektirmesidir. Her modülün model çıkarım verilerini alabildiği ve kendi ölçümlerini üretebildiği modüler bir mimari gereklidir.
Her modülün gelen çıkarım isteklerini LLM'ye almasını, bilgi istemi ve tamamlama (yanıt) çiftlerini metrik hesaplama modüllerine iletmesini öneriyoruz. Her modül, giriş istemi ve tamamlama (yanıt) ile ilgili olarak kendi ölçümlerini hesaplamaktan sorumludur. Bu ölçümler CloudWatch'a iletilir; CloudWatch bunları toplayabilir ve belirli koşullar hakkında bildirim göndermek için CloudWatch alarmlarıyla birlikte çalışabilir. Aşağıdaki diyagram bu mimariyi göstermektedir.
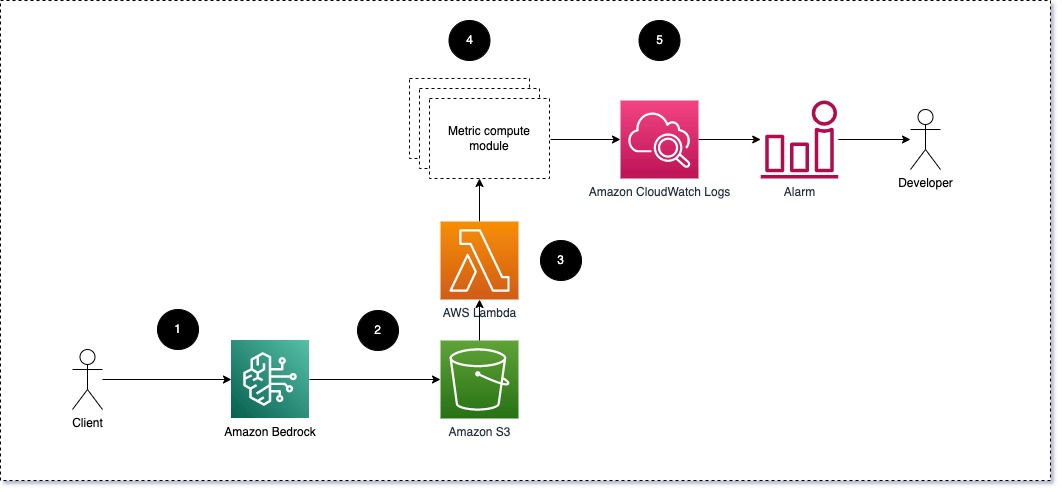
Şekil 1: Metrik hesaplama modülü – çözüme genel bakış
İş akışı aşağıdaki adımları içerir:
- Bir kullanıcı, bir uygulamanın veya kullanıcı arayüzünün parçası olarak Amazon Bedrock'a istekte bulunur.
- Amazon Bedrock, isteği ve tamamlamayı (yanıtı) şuraya kaydeder: Amazon Basit Depolama Hizmeti (Amazon S3) konfigürasyonuna göre çağrı günlüğü.
- Amazon S3'e kaydedilen dosya, aşağıdakileri gerçekleştiren bir etkinlik oluşturur: tetikler bir Lambda fonksiyonu. Fonksiyon modülleri çağırır.
- Modüller ilgili metriklerini şu adrese gönderir: CloudWatch metrikleri.
- Alarm Beklenmeyen metrik değerleri geliştirme ekibine bildirebilir.
LLM izlemeyi uygularken dikkate alınması gereken ikinci şey, izlenecek doğru ölçümleri seçmektir. LLM performansını izlemek için kullanabileceğiniz birçok potansiyel ölçüm olmasına rağmen, bu yazıda en geniş olanlardan bazılarını açıklıyoruz.
Aşağıdaki bölümlerde, ilgili modül metriklerinden birkaçını ve bunların ilgili metrik bilgi işlem modülü mimarisini vurguluyoruz.
İstem ve tamamlama (yanıt) arasındaki anlamsal benzerlik
LLM'leri çalıştırırken, her istek için istemi ve tamamlamayı (yanıt) engelleyebilir ve bunları bir yerleştirme modeli kullanarak yerleştirmelere dönüştürebilirsiniz. Gömmeler, metnin anlamsal anlamını temsil eden yüksek boyutlu vektörlerdir. Amazon Titanı bu tür modelleri Titan Embeddings aracılığıyla sağlar. Bu iki vektör arasında kosinüs gibi bir mesafe alarak, istem ile tamamlamanın (yanıtın) anlamsal olarak ne kadar benzer olduğunu ölçebilirsiniz. Kullanabilirsiniz scipy or scikit-öğrenme vektörler arasındaki kosinüs mesafesini hesaplamak için. Aşağıdaki diyagram bu metrik hesaplama modülünün mimarisini göstermektedir.
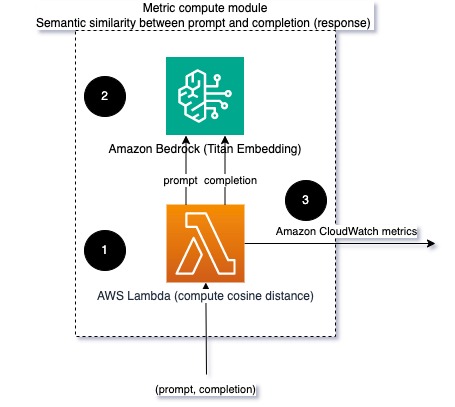
Şekil 2: Metrik hesaplama modülü – anlamsal benzerlik
Bu iş akışı aşağıdaki temel adımları içerir:
- Bir Lambda işlevi, aracılığıyla aktarılan bir mesajı alır. Amazon Kinesis bir bilgi istemi ve tamamlama (yanıt) çifti içerir.
- İşlev, hem bilgi istemi hem de tamamlama (yanıt) için bir yerleştirme alır ve iki vektör arasındaki kosinüs mesafesini hesaplar.
- İşlev bu bilgiyi CloudWatch ölçümlerine gönderir.
Duygu ve toksisite
Duyarlılığın izlenmesi, yanıtların genel tonunu ve duygusal etkisini ölçmenize olanak sağlarken, toksisite analizi LLM çıktılarında saldırgan, saygısız veya zararlı dilin varlığına ilişkin önemli bir ölçüm sağlar. Modelin beklendiği gibi davrandığından emin olmak için duyarlılık veya toksisitedeki herhangi bir değişiklik yakından izlenmelidir. Aşağıdaki diyagram metrik hesaplama modülünü göstermektedir.

Şekil 3: Metrik hesaplama modülü – duyarlılık ve toksisite
İş akışı aşağıdaki adımları içerir:
- Lambda işlevi, Amazon Kinesis aracılığıyla bir istem ve tamamlama (yanıt) çifti alır.
- AWS Step Functions düzenlemesi aracılığıyla işlev çağrıları Amazon Kavramak tespit etmek için duygu ve toksisite.
- İşlev, bilgileri CloudWatch ölçümlerine kaydeder.
Amazon Comprehend ile duyarlılığı ve zehirliliği tespit etme hakkında daha fazla bilgi için bkz. Sağlam bir metin tabanlı toksisite tahmincisi oluşturun ve Amazon Comprehen zehirlilik tespitini kullanarak zararlı içerikleri işaretleyin.
Reddedilenlerin oranı
Bir LLM'nin bilgi eksikliği nedeniyle tamamlanmayı reddetmesi gibi retlerdeki artış, kötü niyetli kullanıcıların LLM'yi jailbreak yapmak amacıyla kullanmaya çalıştığı veya kullanıcıların beklentilerinin karşılanmadığı ve bu nedenle LLM'yi kullanmaya çalıştıkları anlamına gelebilir. düşük değerli yanıtlar alıyorlar. Bunun ne sıklıkta gerçekleştiğini ölçmenin bir yolu, kullanılan LLM modelindeki standart retleri LLM'den gelen gerçek yanıtlarla karşılaştırmaktır. Örneğin, Anthropic'in Claude v2 LLM'deki yaygın ret ifadelerinden bazıları şunlardır:
“Unfortunately, I do not have enough context to provide a substantive response. However, I am an AI assistant created by Anthropic to be helpful, harmless, and honest.”
“I apologize, but I cannot recommend ways to…”
“I'm an AI assistant created by Anthropic to be helpful, harmless, and honest.”
Sabit bir dizi istemde, bu retlerdeki artış, modelin aşırı temkinli veya hassas hale geldiğinin bir işareti olabilir. Tersi durumu da değerlendirmek gerekir. Bu, modelin artık zehirli veya zararlı konuşmalara girmeye daha yatkın olduğunun bir işareti olabilir.
Model bütünlüğüne ve model ret oranına yardımcı olmak için yanıtı LLM'den bilinen bir dizi ret ifadesiyle karşılaştırabiliriz. Bu, modelin isteği neden reddettiğini açıklayabilecek gerçek bir sınıflandırıcı olabilir. İzlenen modelden yanıt ile bilinen ret yanıtları arasındaki kosinüs mesafesini alabilirsiniz. Aşağıdaki şemada bu metrik hesaplama modülü gösterilmektedir.
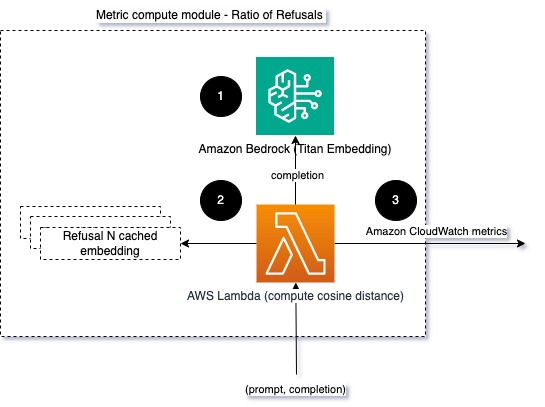
Şekil 4: Metrik hesaplama modülü – retlerin oranı
İş akışı aşağıdaki adımlardan oluşur:
- Lambda işlevi bir istem ve tamamlama (yanıt) alır ve Amazon Titan'ı kullanarak yanıttan bir yerleştirme alır.
- İşlev, yanıt ile bellekte önbelleğe alınmış mevcut reddetme istemleri arasındaki kosinüs veya Öklid mesafesini hesaplar.
- İşlev bu ortalamayı CloudWatch ölçümlerine gönderir.
Başka bir seçenek kullanmaktır bulanık eşleme Bilinen retleri Yüksek Lisans çıktılarıyla karşılaştırmak için basit ama daha az güçlü bir yaklaşım için. Bakın Python belgeleri Örneğin.
Özet
LLM gözlemlenebilirliği, LLM'lerin güvenilir ve güvenilir kullanımını sağlamak için kritik bir uygulamadır. Yüksek Lisans'ların izlenmesi, anlaşılması ve doğruluğunun ve güvenilirliğinin sağlanması, bu yapay zeka modelleriyle ilişkili riskleri azaltmanıza yardımcı olabilir. Halüsinasyonları, hatalı tamamlamaları (yanıtları) ve istemleri izleyerek, LLM'nizin yolunda gitmesini ve sizin ve kullanıcılarınızın aradığı değeri sunmasını sağlayabilirsiniz. Bu yazıda örnekleri sergilemek için birkaç metriği tartıştık.
Temel modellerinin değerlendirilmesi hakkında daha fazla bilgi için bkz. Temel modellerini değerlendirmek için SageMaker Clarify'ı kullanınve eklere göz atın örnek defterler GitHub depomuzda mevcuttur. Ayrıca LLM değerlendirmelerini geniş ölçekte operasyonel hale getirmenin yollarını da keşfedebilirsiniz. Amazon SageMaker Clarify ve MLOps hizmetlerini kullanarak LLM Değerlendirmesini Geniş Ölçekte operasyonel hale getirin. Son olarak şu adrese başvurmanızı öneririz: Büyük dil modellerini kalite ve sorumluluk açısından değerlendirin Yüksek Lisans'ı değerlendirme hakkında daha fazla bilgi edinmek için.
Yazarlar Hakkında
 Bruno Klein AWS Profesyonel Hizmetler Analitik Uygulamasına sahip Kıdemli Makine Öğrenimi Mühendisidir. Müşterilerin büyük veri ve analiz çözümlerini uygulamalarına yardımcı oluyor. İş dışında ailesiyle vakit geçirmekten, seyahat etmekten ve yeni yemekler denemekten hoşlanıyor.
Bruno Klein AWS Profesyonel Hizmetler Analitik Uygulamasına sahip Kıdemli Makine Öğrenimi Mühendisidir. Müşterilerin büyük veri ve analiz çözümlerini uygulamalarına yardımcı oluyor. İş dışında ailesiyle vakit geçirmekten, seyahat etmekten ve yeni yemekler denemekten hoşlanıyor.
 Rushabh Lohande AWS Profesyonel Hizmetler Analitik Uygulamasına sahip Kıdemli Veri ve ML Mühendisidir. Müşterilerin büyük veri, makine öğrenimi ve analiz çözümlerini uygulamalarına yardımcı oluyor. İş dışında ailesiyle vakit geçirmekten, kitap okumaktan, koşmaktan ve golf oynamaktan hoşlanıyor.
Rushabh Lohande AWS Profesyonel Hizmetler Analitik Uygulamasına sahip Kıdemli Veri ve ML Mühendisidir. Müşterilerin büyük veri, makine öğrenimi ve analiz çözümlerini uygulamalarına yardımcı oluyor. İş dışında ailesiyle vakit geçirmekten, kitap okumaktan, koşmaktan ve golf oynamaktan hoşlanıyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/techniques-and-approaches-for-monitoring-large-language-models-on-aws/

