İşletmeler çeşitli kaynaklardan artan miktarlarda veri topladıkça, bu verilerin yapısı ve organizasyonunun, gelişen analitik ihtiyaçları karşılamak için sıklıkla zaman içinde değişmesi gerekir. Bununla birlikte, geleneksel veri göllerindeki şema ve tablo bölümlerini değiştirmek, tüm tabloların yeniden adlandırılmasını veya yeniden oluşturulmasını ve büyük veri kümelerinin yeniden işlenmesini gerektiren, işleri aksatan ve zaman alan bir görev olabilir. Bu, çevikliği ve içgörü süresini engeller.
Şema gelişimi, mevcut verileri yeniden yazmaya gerek kalmadan sütunların eklenmesine, silinmesine, yeniden adlandırılmasına veya değiştirilmesine olanak tanır. Bu, hızlı hareket eden kuruluşların yeni kullanım senaryolarını destekleyecek şekilde veri yapılarını güçlendirmesi açısından kritik öneme sahiptir. Örneğin bir e-ticaret şirketi, analitiği zenginleştirmek için yeni müşteri demografik özellikleri veya sipariş durumu bayrakları ekleyebilir. Apaçi Buzdağı yenilikçi meta veri tablosu evrim mimarisi aracılığıyla bu şema değişikliklerini geriye dönük olarak uyumlu bir şekilde yönetir.
Benzer şekilde bölüm evrimi, bölümlerin kesintisiz eklenmesine, bırakılmasına veya bölünmesine olanak tanır. Örneğin, bir e-ticaret pazarı başlangıçta sipariş verilerini günlere göre bölümlendirebilir. Siparişler biriktikçe ve güne göre sorgulama verimsiz hale geldikçe, bunlar gün ve müşteri kimliği bölümlerine bölünebilir. Tablo bölümleme, sorgu performansı için büyük veri kümelerini en verimli şekilde düzenler. Iceberg, işletmelere sıkıcı yeniden inşa prosedürleri gerektirmek yerine bölümleri aşamalı olarak ayarlama esnekliği sağlar. Yeni bölümler, kesinti olmadan veya mevcut veri dosyalarını yeniden yazmaya gerek kalmadan tamamen uyumlu bir şekilde eklenebilir.
Bu yazı Iceberg'i nasıl kullanabileceğinizi gösteriyor. Amazon Basit Depolama Hizmeti (Amazon S3), AWS Tutkal, AWS Göl Oluşumu, ve AWS Kimlik ve Erişim Yönetimi (IAM) kesintisiz gelişimi destekleyen işlemsel bir veri gölü uygulamak. Veri öngörüleri geliştikçe sorunsuz şema ve bölüm ayarlamalarına izin vererek, iş başarısı için gereken geleceğe yönelik esneklikten yararlanabilirsiniz.
Çözüme genel bakış
Örnek kullanım örneğimiz için, hayali büyük bir e-ticaret şirketi her gün binlerce siparişi işliyor. Siparişler alındığında, güncellendiğinde, iptal edildiğinde, gönderildiğinde, teslim edildiğinde veya iade edildiğinde değişiklikler şirket içi sistemlerde yapılır ve veri analistlerinin sorguları çalıştırabilmesi için bu değişikliklerin bir S3 veri gölüne kopyalanması gerekir. Amazon Atina. Değişiklikler şema güncellemelerini de içerebilir. Farklı kuruluşların güvenlik gereksinimleri nedeniyle, Lake Formation aracılığıyla analistler için ayrıntılı erişim kontrolünü yönetmeleri gerekiyor.
Aşağıdaki şemada çözüm mimarisi gösterilmektedir.
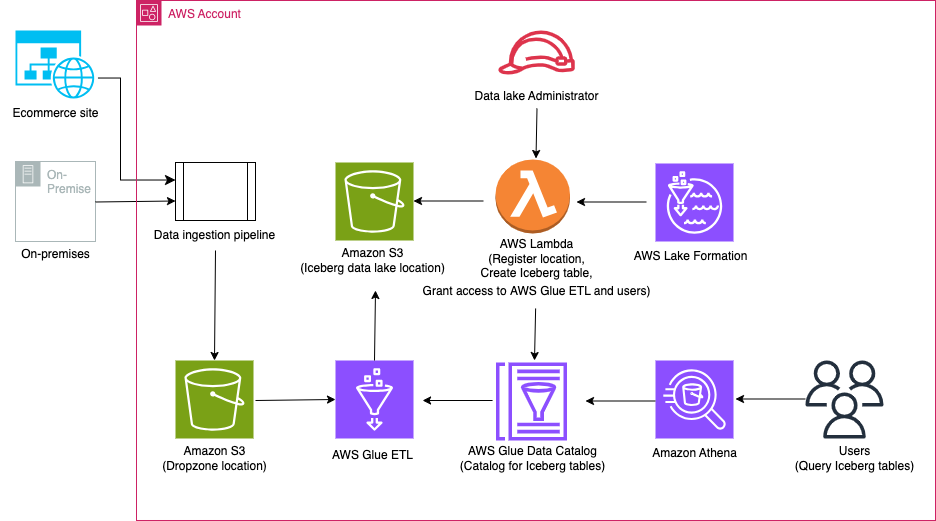
Çözüm iş akışı aşağıdaki temel adımları içerir:
- Veri alımı ardışık düzenini kullanarak verileri şirket içinden Dropzone konumuna aktarın.
- AWS Glue'yu kullanarak Dropzone konumundaki verileri Iceberg'e birleştirin.
- Athena'yı kullanarak verileri sorgulayın.
Önkoşullar
Bu izlenecek yol için aşağıdaki ön koşullara sahip olmalısınız:
AWS CloudFormation ile altyapıyı kurun
Altyapınızı oluşturmak için AWS CloudFormation şablon, aşağıdaki adımları tamamlayın:
- AWS hesabınızda yönetici olarak oturum açın.
- AWS CloudFormation konsolunu açın.
- Klinik Yığını Başlat:

- İçin Yığın adı, bir ad girin (bu gönderi için, icebergdemo1).
- Klinik Sonraki.
- Aşağıdaki parametreler için bilgi sağlayın:
DatalakeUserNameDatalakeUserPasswordDatabaseNameTableNameDatabaseLFTagKeyDatabaseLFTagValueTableLFTagKeyTableLFTagValue
- Klinik Sonraki.
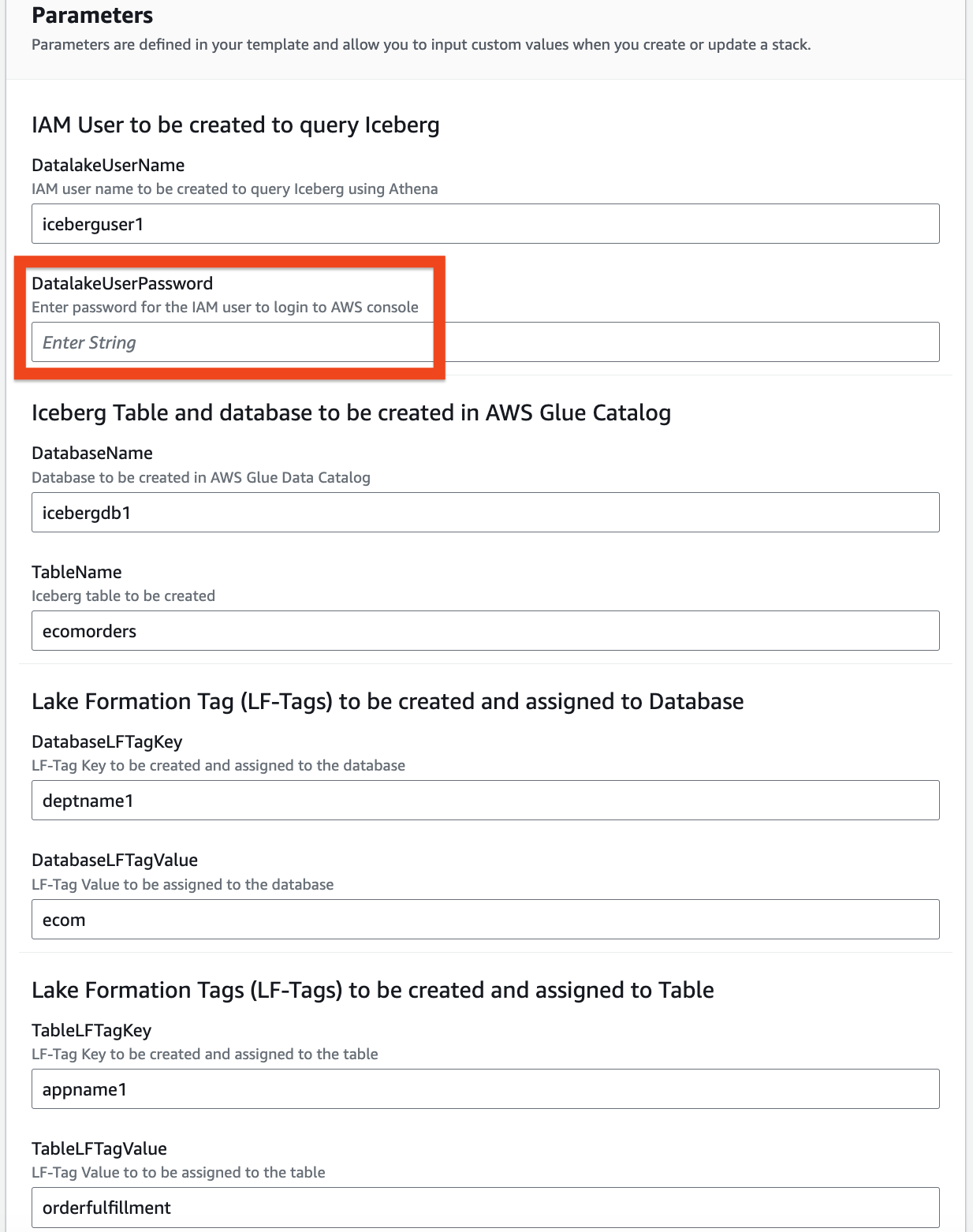
- Klinik Sonraki tekrar.
- içinde Değerlendirme bölümünde girdiğiniz değerleri gözden geçirin.
- seç AWS CloudFormation'ın özel adlarla IAM kaynakları oluşturabileceğini kabul ediyorum Ve seç Gönder.
Birkaç dakika içinde yığın durumu şu şekilde değişecek: CREATE_COMPLETE.
Şuraya gidebilirsiniz: Çıkışlar sekmesi Sağladığı tüm kaynakları görmek için yığının. Kaynakların önüne sağladığınız yığın adı eklenir (bu yazı için, icebergdemo1).
Lambda'yı kullanarak bir Buzdağı tablosu oluşturun ve Lake Formation'ı kullanarak erişim izni verin
Bir Buzdağı tablosu oluşturmak ve bu tabloya erişim izni vermek için aşağıdaki adımları tamamlayın:
- gidin Kaynaklar CloudFormation yığını icebergdemo1'in sekmesini açın ve adlı mantıksal kimliği arayın
LambdaFunctionIceberg. - İlişkili fiziksel kimliğin köprüsünü seçin.
Lambda işlevine yönlendirildiniz icebergdemo1-Lambda-Create-Iceberg-and-Grant-access.
- Üzerinde yapılandırma sekmesini seçin Ortam Değişkenleri sol bölmede

- Üzerinde Kod sekmesinde fonksiyon kodunu inceleyebilirsiniz.
İşlev şunu kullanır: Python için AWS SDK (Boto3) Kaynakların sağlanmasına yönelik API'ler. Aşağıdaki görevleri gerçekleştirmek için sağlanan veri gölü yöneticisi rolünü üstlenir:
- Hibe DATA_LOCATION_ACCESS kayıtlı veri gölü konumunda veri gölü yöneticisi rolüne erişim
- oluşturmak Göl Oluşumu Etiketleri (LF-Tags)
- AWS Glue kullanarak AWS Glue Veri Kataloğunda bir veritabanı oluşturun CREATE_DATABASE API
- LF Etiketlerini veritabanına atayın
- Data lake IAM kullanıcısına ve AWS Glue ETL IAM rolüne LF Etiketlerini kullanarak veritabanında DESCRIBE erişimi verin
- AWS Glue'yu kullanarak bir Buzdağı tablosu oluşturun create_table API:
- LF Etiketlerini tabloya atayın
- Data lake IAM kullanıcısı için Iceberg tablosunda LF-Etiketleri üzerinde DESCRIBE ve SELECT'i verin
- AWS Glue ETL IAM rolüne Iceberg tablosundaki LF-Tag'lerde ALL, DESCRIBE, SELECT, INSERT, DELETE ve ALTER erişim izni verin
- Üzerinde test sekmesini seçin test işlevi çalıştırmak için.

İşlev tamamlandığında “İşlev yürütülüyor: başarılı oldu” mesajını göreceksiniz.
Lake Formation, analitik ve makine öğrenimi için verileri merkezi olarak yönetmenize, güvence altına almanıza ve küresel olarak paylaşmanıza yardımcı olur. Lake Formation ile Amazon S3'teki data lake verileriniz ve Veri Kataloğu'ndaki meta verileri için ayrıntılı erişim kontrolünü yönetebilirsiniz.
Veri gölünüze Iceberg depolama alanı olarak bir Amazon S3 konumu eklemek için, konumu kaydet Göl Oluşumu ile. Daha sonra, bu konuma işaret eden Veri Kataloğu nesnelerine ve konumdaki temel verilere ayrıntılı erişim kontrolü sağlamak için Lake Formation izinlerini kullanabilirsiniz.
CloudFormation yığını veri gölü konumunu kaydetti.

Veri konumu izinleri Lake Formation'da, sorumluların belirlenmiş kayıtlı Amazon S3 konumlarına işaret eden Veri Kataloğu kaynakları oluşturmasına ve değiştirmesine olanak tanır. Veri konumu izinleri Lake Formation'a ek olarak çalışır veri izinleri Veri gölünüzdeki bilgilerin güvenliğini sağlamak için.
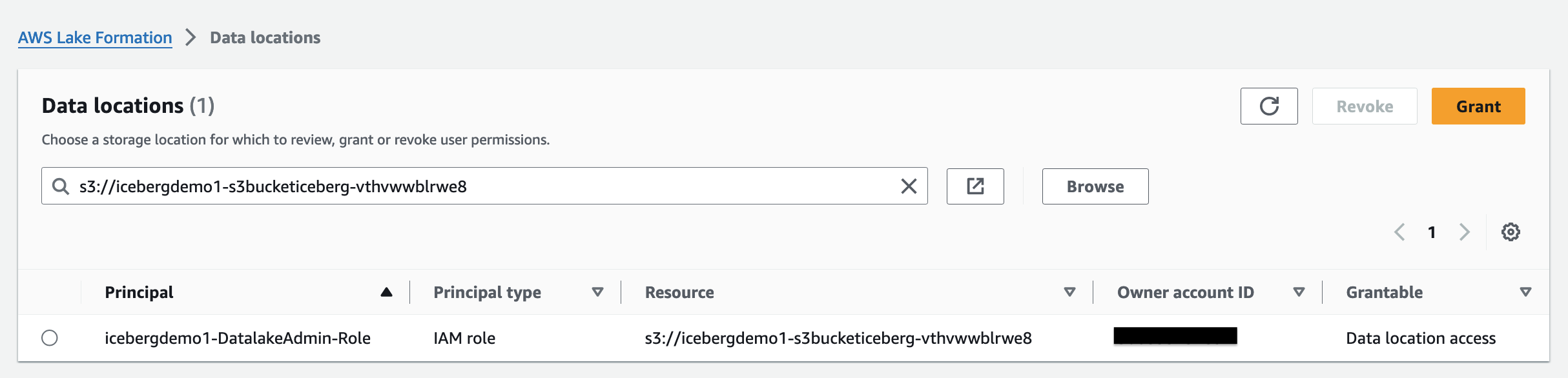
Göl Oluşumu etiket tabanlı erişim kontrolü (LF-TBAC) izinleri niteliklere göre tanımlayan bir yetkilendirme stratejisidir. Göl Oluşumunda bu niteliklere LF Etiketleri adı verilir. LF Etiketlerini Data Catalog kaynaklarına, Lake Formation ilkelerine ve tablo sütunlarına ekleyebilirsiniz. Bu LF Etiketlerini kullanarak Lake Formation kaynaklarına ilişkin izinleri atayabilir ve iptal edebilirsiniz. Göl Oluşumu, müdürün etiketi kaynak etiketiyle eşleştiğinde bu kaynaklar üzerinde işlemlere izin verir.
Buzdağı tablosunu Lake Formation konsolundan doğrulayın
Buzdağı tablosunu doğrulamak için aşağıdaki adımları tamamlayın:
- Göl Oluşumu konsolunda seçin veritabanları Gezinti bölmesinde.
- Şunun için ayrıntılar sayfasını açın:
icebergdb1.
İlgili veritabanı LF Etiketlerini görebilirsiniz.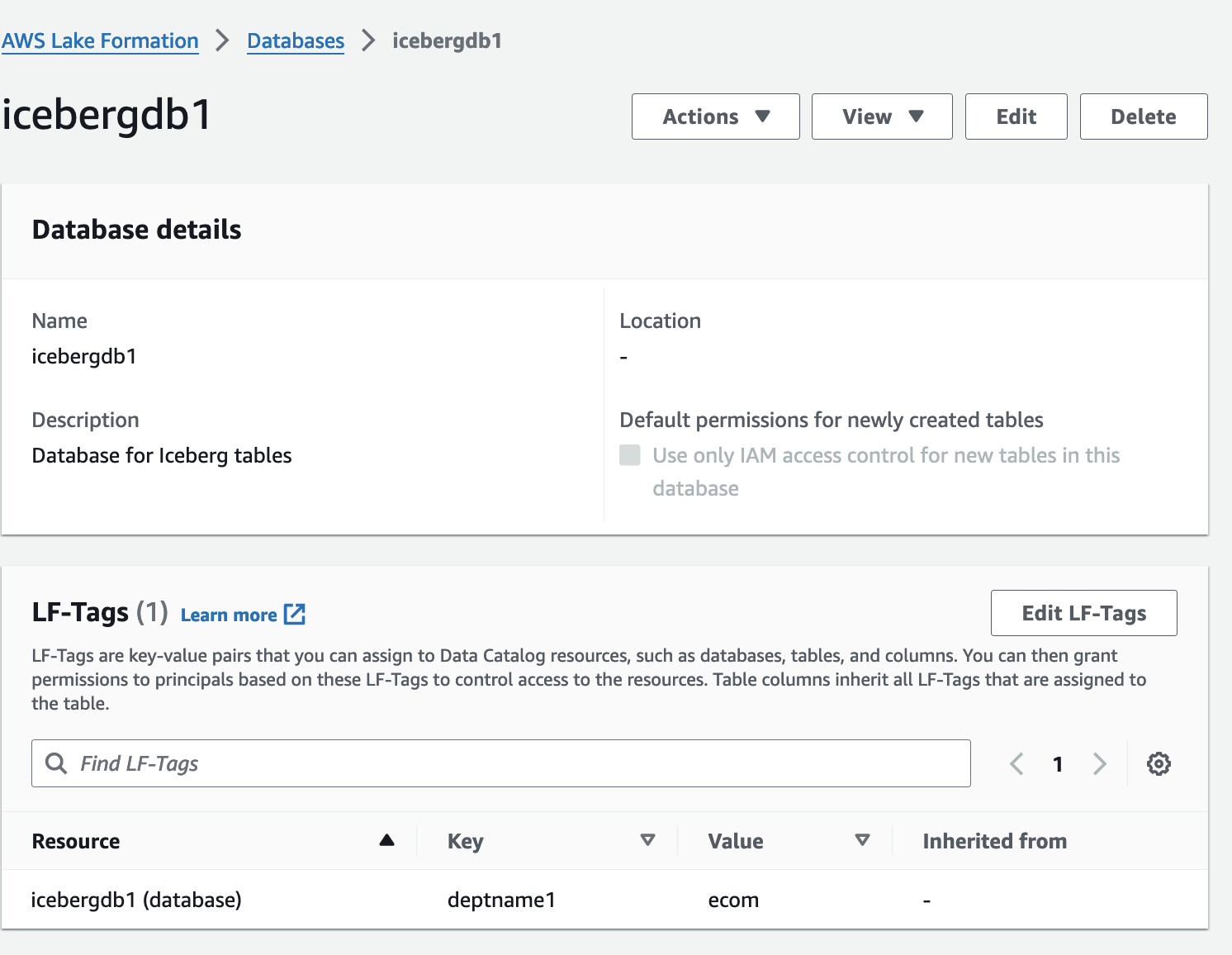
- Klinik tablolar Gezinti bölmesinde.
- Şunun için ayrıntılar sayfasını açın:
ecomorders.
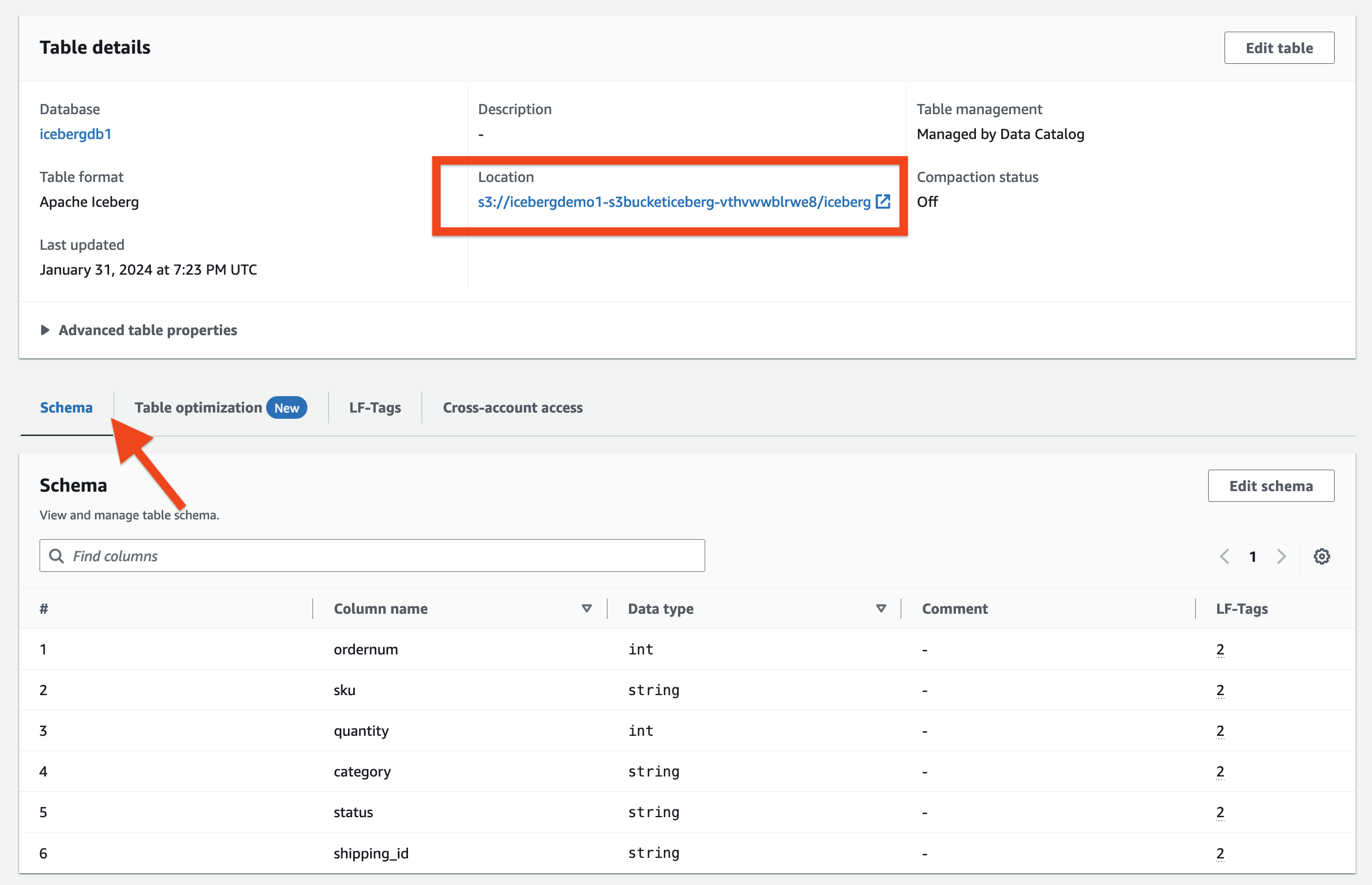
içinde Tablo ayrıntıları bölümünde aşağıdakileri gözlemleyebilirsiniz:
- tablo formatı olarak gösterir Apaçi Buzdağı
- Tablo yönetimi olarak gösterir Data Catalog tarafından yönetilmektedir
- Lokasyon Buzdağı tablosunun veri gölü konumunu listeler
içinde LF-Etiketler bölümünde ilgili LF-Etiketleri tablosunu görebilirsiniz.
içinde Tablo ayrıntıları bölüm, genişlet Gelişmiş tablo özellikleri aşağıdakileri görüntülemek için:
metadata_locationBuzdağı tablosunun meta veri dosyasının konumunu gösterirtable_typeolarak gösterirICEBERG
Üzerinde Şema sekmesinde Iceberg tablosunda tanımlanan sütunları görüntüleyebilirsiniz.
Iceberg'i AWS Glue Data Catalog ve Amazon S3 ile entegre edin
Iceberg, dizinler yerine bir tablodaki bireysel veri dosyalarını izler. Tabloda açık bir taahhüt olduğunda Iceberg veri dosyaları oluşturur ve bunları tabloya ekler. Iceberg meta veri dosyalarındaki tablo durumunu korur. Tablo durumundaki herhangi bir değişiklik, eski meta verilerin atomik olarak yerini alan yeni bir meta veri dosyası oluşturur. Meta veri dosyaları tablo şemasını, bölümleme yapılandırmasını ve diğer özellikleri izler.
Iceberg, işlemleri destekleyen dosya sistemlerinin Amazon S3 gibi nesne depolarıyla uyumlu olmasını gerektirir.
Iceberg, tablo içerikleri için anlık görüntüler oluşturur. Her anlık görüntü, belirli bir zamanda tablodaki veri dosyalarının eksiksiz bir kümesidir. Anlık görüntülerdeki veri dosyaları, tablodaki her veri dosyası, bölüm verileri ve ölçümleri için bir satır içeren bir veya daha fazla bildirim dosyasında depolanır.
Aşağıdaki diyagram bu hiyerarşiyi göstermektedir.
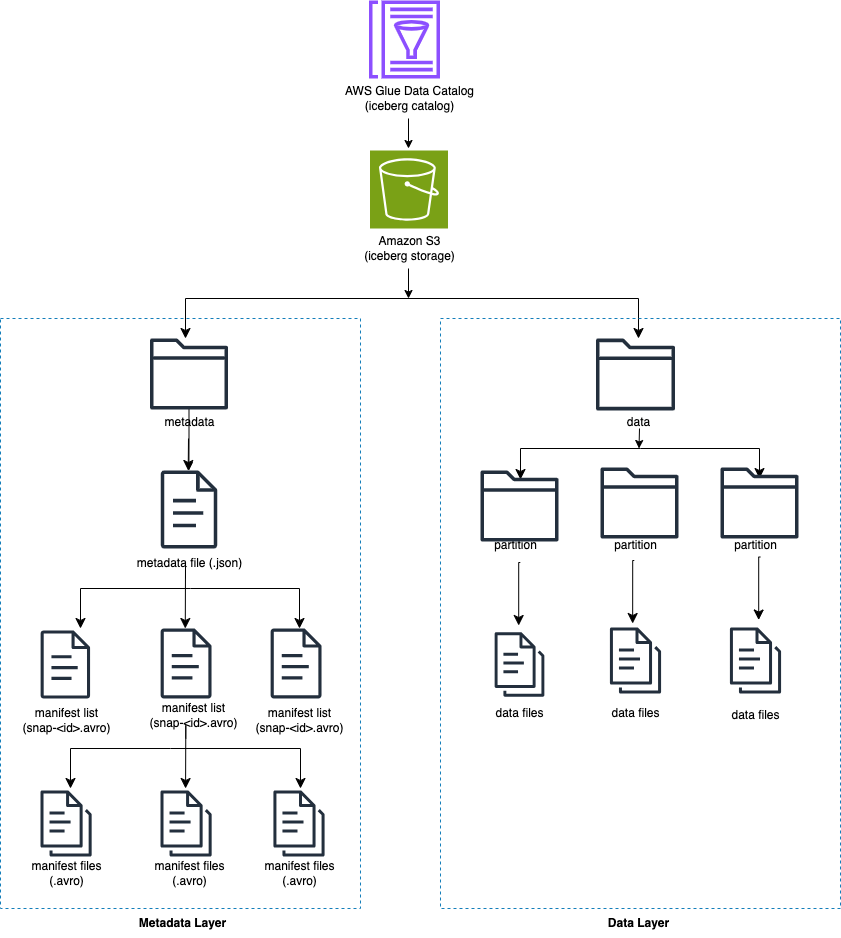
Bir Iceberg tablosu oluşturduğunuzda, önce meta veri klasörünü ve meta veri klasöründe bir meta veri dosyası oluşturur. Veri klasörü, verileri Iceberg tablosuna yüklediğinizde oluşturulur.

Iceberg meta veri dosyasının içeriği
Iceberg meta veri dosyası aşağıdakiler de dahil olmak üzere birçok bilgi içerir:
- format-sürüm –Buzdağı tablosunun versiyonu
- Lokasyon – Tablonun Amazon S3 konumu
- Şemalar – Tablodaki tüm sütunların adı ve veri türü
- bölüm özellikleri – Bölümlenmiş sütunlar
- sıralama düzenleri – Sütunların sıralama düzeni
- özellikleri – Tablo özellikleri
- geçerli anlık görüntü kimliği – Mevcut anlık görüntü
- ref – Tablo referansları
- anlık – Her biri aşağıdaki bilgileri içeren anlık görüntülerin listesi:
- Sıra numarası – Anlık görüntülerin kronolojik sırayla sıra numarası (en yüksek sayı geçerli anlık görüntüyü temsil eder, ilk anlık görüntü için 1)
- anlık görüntü kimliği – Anlık görüntü kimliği
- zaman damgası-ms – Anlık görüntünün işlendiği zaman damgası
- özet – Gerçekleştirilen değişikliklerin özeti
- manifest listesi – Bildirimlerin listesi; bu dosya adı snap-< snapshot-id > ile başlar
- şema kimliği – Şemanın kronolojik sıra numarası (en yüksek sayı mevcut şemayı temsil eder)
- anlık görüntü günlüğü – Anlık görüntülerin kronolojik sırayla listesi
- meta veri günlüğü – Meta veri dosyalarının kronolojik sırayla listesi
Meta veri dosyası, tablonun verilerinde ve şemasında yapılan tüm geçmiş değişiklikleri içerir. Meta dosyası dosyasının içeriğini doğrudan gözden geçirmek zaman alıcı bir iş olabilir. Neyse ki, sorgulayabilirsiniz Athena'yı kullanan buzdağı meta verileri.
AWS Glue'da buzdağı çerçevesi
AWS Glue 4.0, Lake Formation'a kayıtlı Iceberg tablolarını destekler. AWS Glue ETL işlerinde aşağıdaki koda ihtiyacınız vardır: Buzdağı çerçevesini etkinleştir:
Temel verilere okuma/yazma erişimi için Lake Formation izinlerine ek olarak, AWS Glue ETL işlerini çalıştırmaya yönelik AWS Glue IAM rolü de verildi göl oluşumu: GetDataAccess IAM izni. Bu izinle Lake Formation, verilere erişim için geçici kimlik bilgileri talebini kabul eder.
CloudFormation yığını sizin için dört AWS Glue ETL işini sağladı. Her işin adı yığın adınızla (icebergdemo1) başlar. İşleri görüntülemek için aşağıdaki adımları tamamlayın:
- AWS hesabınızda yönetici olarak oturum açın.
- AWS Glue konsolunda seçin ETL işleri Gezinti bölmesinde.
- Şununla iş ara:
icebergdemo1adında.
Dropzone'daki verileri Iceberg tablosuyla birleştirin
Kullanım örneğimizde şirket, e-ticaret sipariş verilerini günlük olarak şirket içi konumundan Amazon S3 Dropzone konumuna alıyor. CloudFormation yığını, aşağıdaki şekillerde gösterildiği gibi, 3 gün boyunca örnek siparişleri içeren üç dosyayı yükledi. Verileri Dropzone konumunda görüyorsunuz s3://icebergdemo1-s3bucketdropzone-kunftrcblhsk/data.
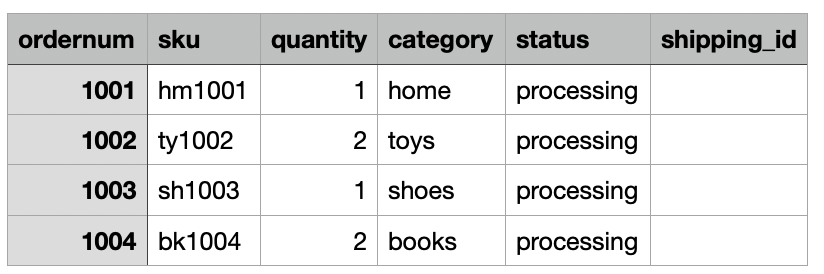


AWS Glue ETL işi icebergdemo1-GlueETL1-merge verileri Iceberg tablosuyla birleştirmek için günlük olarak çalışacaktır. Iceberg'e veri eklemek veya güncellemek için aşağıdaki mantığa sahiptir:
- Giriş verilerinden bir Spark DataFrame oluşturun:
- Yeni bir sipariş için tabloya ekleyin
- Tablonun eşleşen bir sırası varsa durumu güncelleyin ve
shipping_id:
AWS Glue birleştirme işini çalıştırmak için aşağıdaki adımları tamamlayın:
- AWS Glue konsolunda seçin ETL işleri Gezinti bölmesinde.
- ETL işini seçin
icebergdemo1-GlueETL1-merge. - Üzerinde İşlemler açılır menü, seçin Parametrelerle çalıştır.
- Üzerinde Parametreleri çalıştır sayfasına git İş parametreleri.
- Için
--dropzone_pathparametresi, giriş verilerinin S3 konumunu sağlayın (icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge1). - Tüm siparişleri eklemek için işi çalıştırın: 1001, 1002, 1003 ve 1004.
- Için
--dropzone_path parameter, S3 konumunu şu şekilde değiştirin:icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge2. - 2001 ve 2002 numaralı siparişleri eklemek ve 1001, 1002 ve 1003 numaralı siparişleri güncellemek için işi yeniden çalıştırın.
- Için
--dropzone_pathparametre, S3 konumunu şu şekilde değiştirin:icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge3. - 3001 numaralı siparişi eklemek ve 1001, 1003, 2001 ve 2002 numaralı siparişleri güncellemek için işi yeniden çalıştırın.
Glue ETL işini kullanarak verileri tabloyla birleştirdiğinizde Iceberg tarafından yazılan veri dosyalarını görmek için tablonun veri klasörüne gidin. icebergdemo1-GlueETL1-merge.

Athena'yı kullanarak Buzdağını sorgula
CloudFormation yığını, LF Etiketlerini kullanarak Iceberg tablosunda okuma erişimine sahip olan IAM kullanıcısı iceberguser1'i oluşturdu. Bu kullanıcı aracılığıyla Athena'yı kullanarak Iceberg'i sorgulamak için aşağıdaki adımları tamamlayın:
- Olarak giriş yap
iceberguser1için AWS Yönetim Konsolu. - Athena konsolunda, seçin Çalışma Grupları Gezinti bölmesinde.
- CloudFormation'ın sağladığı çalışma grubunu bulun (
icebergdemo1-workgroup) - Athena motorunun 3. sürümünü doğrulayın.
Athena motoru sürüm 3 destekler Buzdağı dosya formatlarıParke, ORC ve Avro dahil.
- Athena sorgu düzenleyicisine gidin.
- Açılır menüden icebergdemo1-workgroup çalışma grubunu seçin.
- İçin veritabanı, seçmek
icebergdb1. Tabloyu göreceksinizecomorders. - Iceberg tablosundaki verileri görmek için aşağıdaki sorguyu çalıştırın:
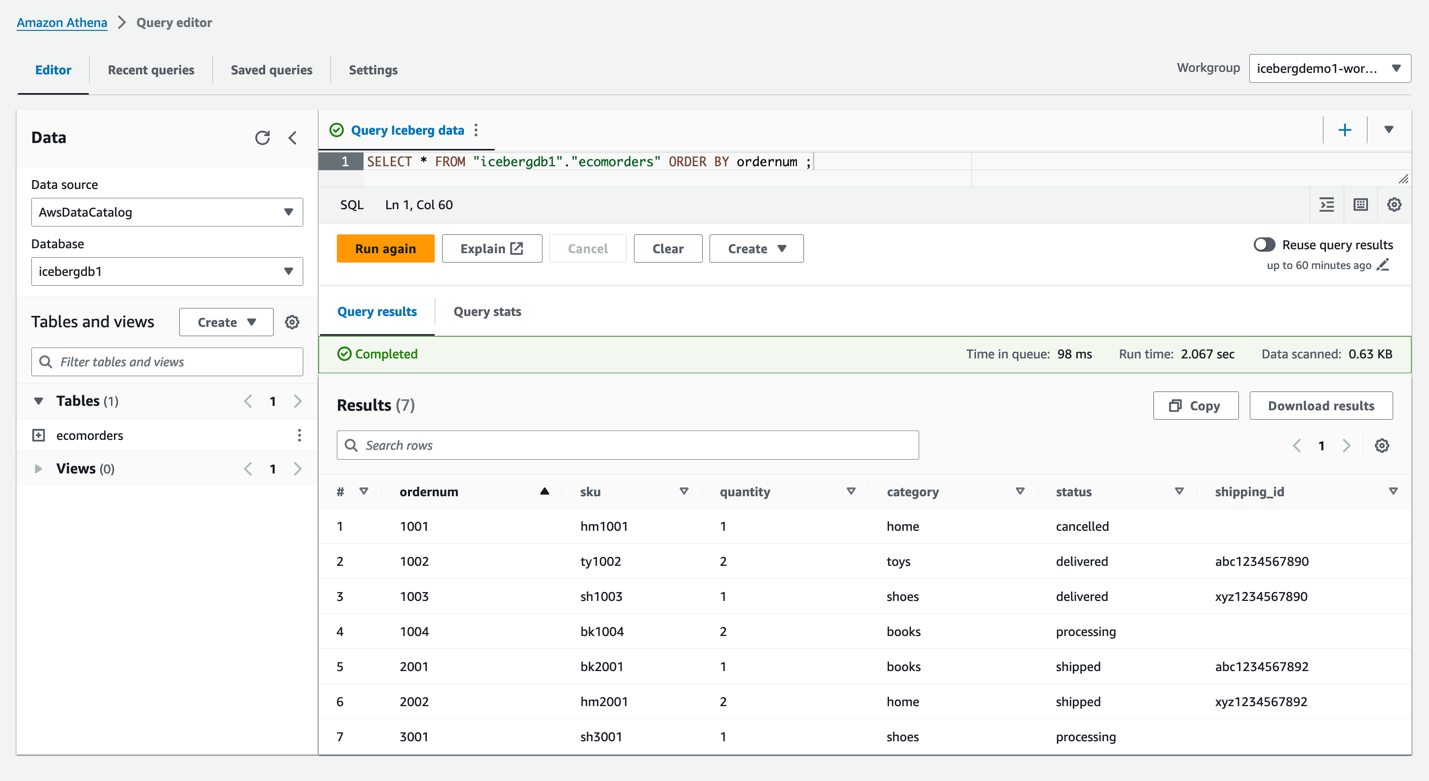
- Tablonun geçerli bölümlerini görmek için aşağıdaki sorguyu çalıştırın:
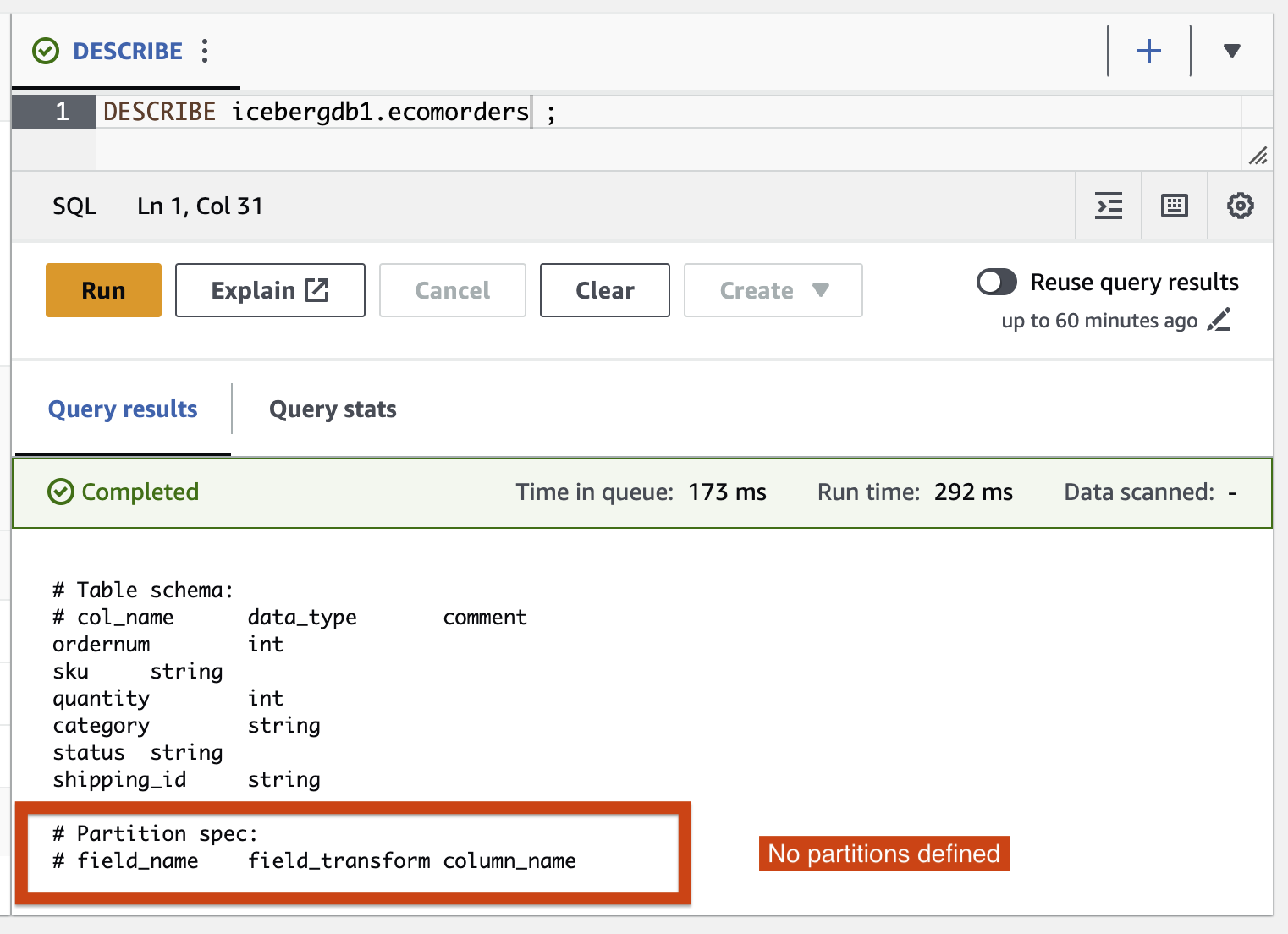
Partition-spec tablonun nasıl bölümlendiğini açıklar. Bu örnekte, tabloda herhangi bir bölüm tanımlamadığınız için bölümlenmiş alan yoktur.
Buzdağı bölümünün evrimi
Bölüm yapınızı değiştirmeniz gerekebilir; örneğin, aşağı yönlü analizlerdeki ortak sorgu modellerindeki trend değişiklikleri nedeniyle. Geleneksel tablolar için bölüm yapısının değiştirilmesi, tüm veri kopyasını gerektiren önemli bir işlemdir.
Iceberg bunu basitleştiriyor. Iceberg'deki bölüm yapısını değiştirdiğinizde veri dosyalarını yeniden yazmanızı gerektirmez. Daha önceki bölümlerle yazılan eski veriler değişmeden kalır. Yeni veriler, yeni düzende yeni özellikler kullanılarak yazılır. Bölümleme sürümlerinin her birine ait meta veriler ayrı ayrı tutulur.
AWS Glue ETL işini kullanarak bölüm alanı kategorisini Buzdağı tablosuna ekleyelim icebergdemo1-GlueETL2-partition-evolution:
AWS Glue konsolunda ETL işini çalıştırın icebergdemo1-GlueETL2-partition-evolution. İş tamamlandığında Athena'yı kullanarak bölümleri sorgulayabilirsiniz.
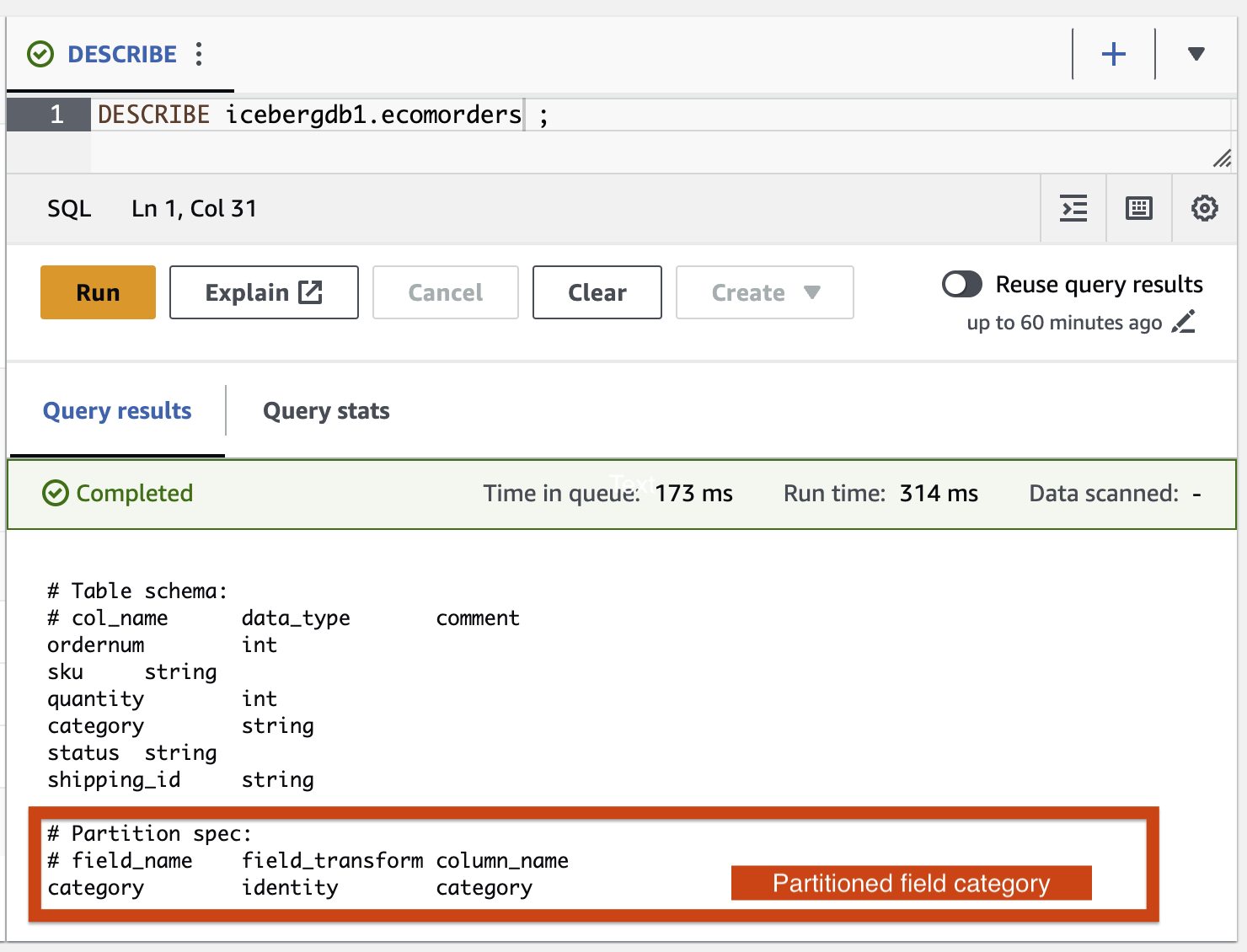
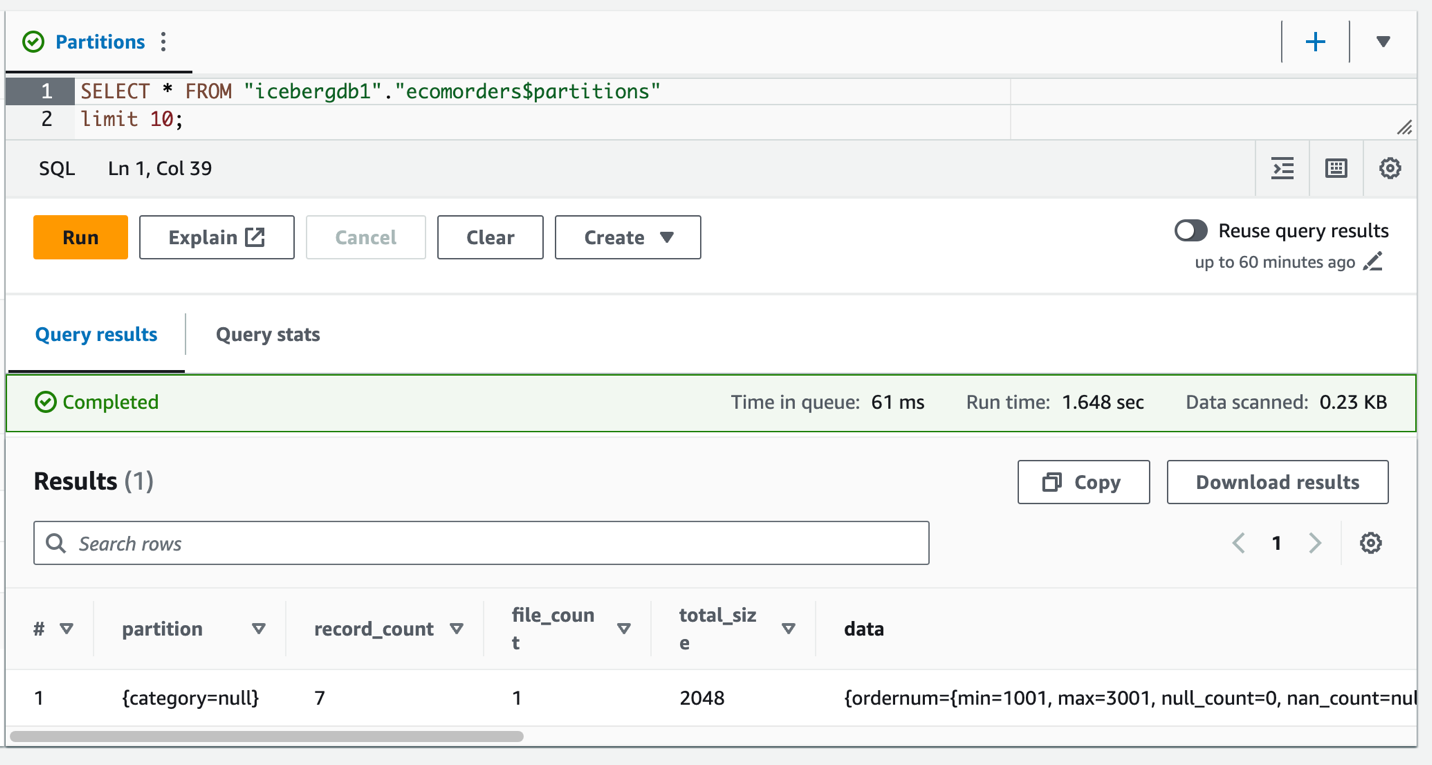
Bölüm alanı kategorisini görebilirsiniz ancak bölüm değerleri boştur. Veri klasöründe yeni veri dosyası yoktur çünkü bölüm geliştirme bir meta veri işlemidir ve veri dosyalarını yeniden yazmaz. Veri eklediğinizde veya güncellediğinizde, karşılık gelen bölüm değerlerinin doldurulduğunu göreceksiniz.
Buzdağı şeması gelişimi
Iceberg yerinde tablo gelişimini destekler. Yapabilirsiniz bir tablo şeması geliştirin tıpkı SQL'deki gibi. Buzdağı şema güncellemeleri meta veri değişiklikleridir, dolayısıyla şema gelişimini gerçekleştirmek için hiçbir veri dosyasının yeniden yazılmasına gerek yoktur.
Iceberg şeması gelişimini keşfetmek için ETL işini çalıştırın icebergdemo1-GlueETL3-schema-evolution AWS Glue konsolu aracılığıyla. İş aşağıdaki SparkSQL ifadelerini çalıştırır:
Athena sorgu düzenleyicisinde aşağıdaki sorguyu çalıştırın:

Şema değişikliklerini Iceberg tablosunda doğrulayabilirsiniz:
- adlı yeni bir sütun eklendi.
shipping_carrier - Sütun
shipping_idolarak yeniden adlandırıldıtracking_number - Sütunun veri türü
ordernumint'ten bigint'e değişti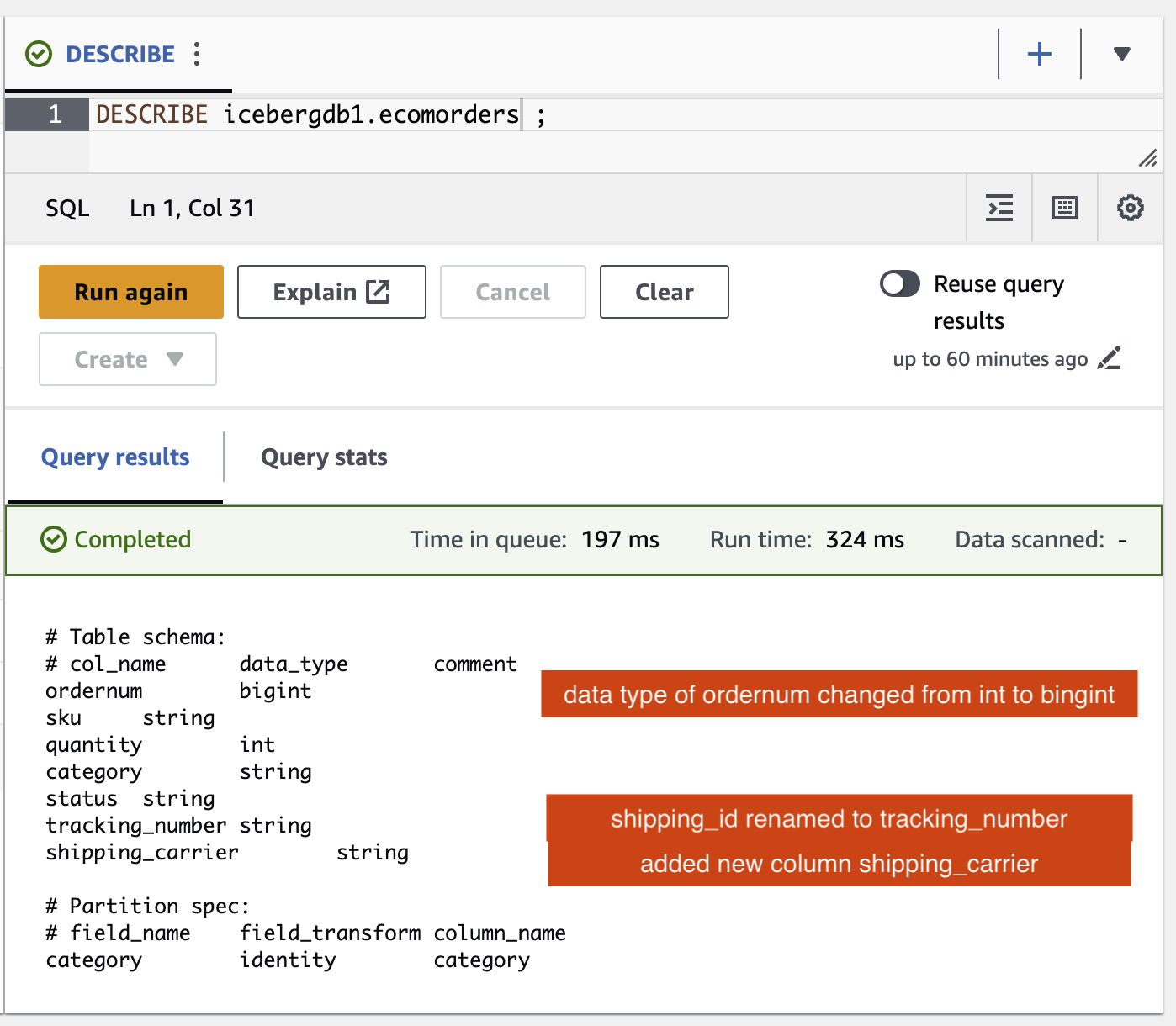
Konumsal güncelleme
İçindeki veriler tracking_number takip numarasıyla birleştirilmiş nakliye taşıyıcısını içerir. Nakliye şirketini bölgede tutmak için bu verileri bölmek istediğimizi varsayalım. shipping_carrier alanı ve takip numarası tracking_number alan.
AWS Glue konsolunda ETL işini çalıştırın icebergdemo1-GlueETL4-update-table. İş, tabloyu güncellemek için aşağıdaki SparkSQL deyimini çalıştırır:
Güncellenen verileri doğrulamak için Iceberg tablosunu sorgulayın tracking_number ve shipping_carrier.
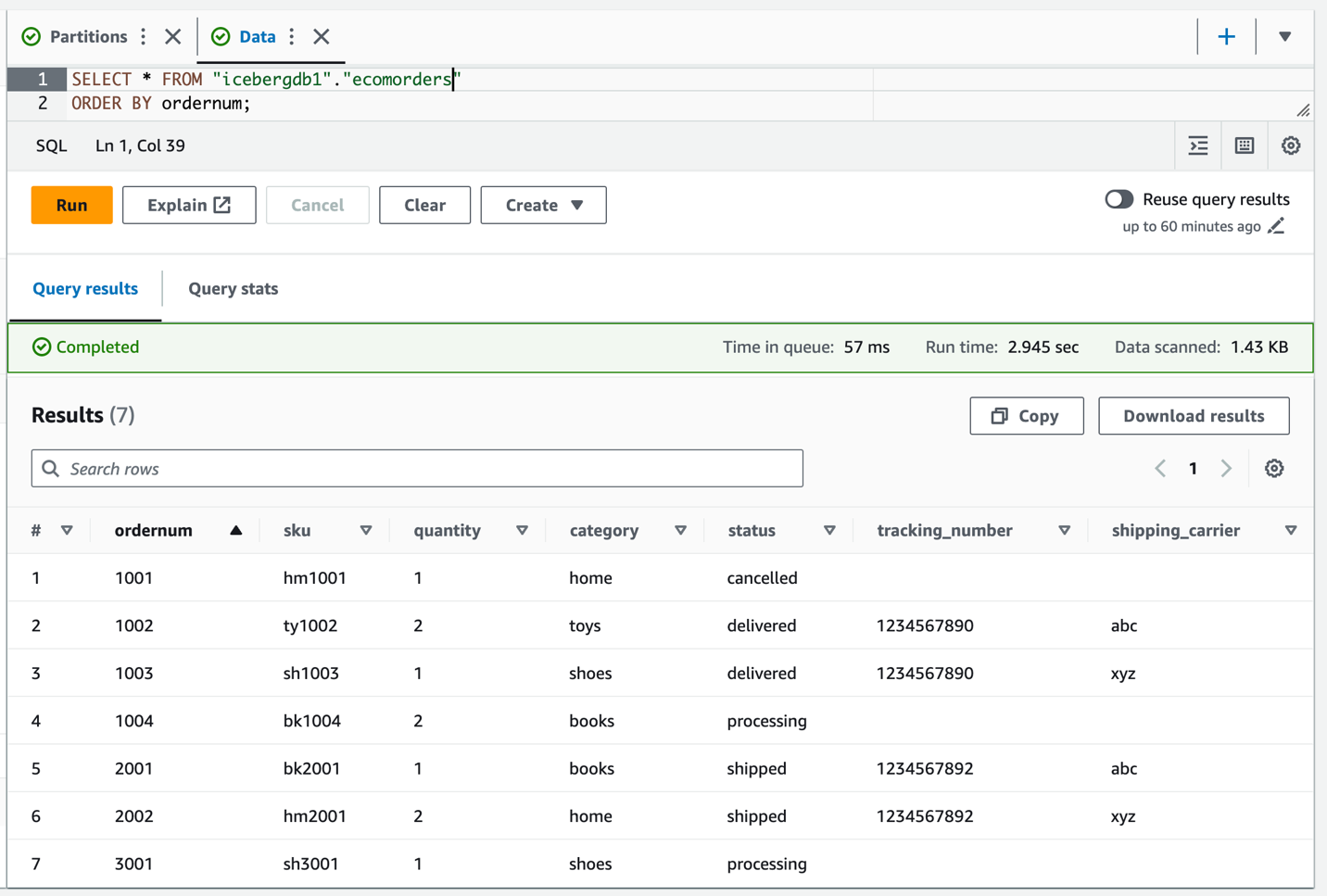
Artık veriler tabloda güncellendiğine göre, kategori için doldurulmuş bölüm değerlerini görmelisiniz:

Temizlemek
Gelecekte ücret alınmasını önlemek için oluşturduğunuz kaynakları temizleyin:
- Lambda konsolunda işlevin ayrıntılar sayfasını açın
icebergdemo1-Lambda-Create-Iceberg-and-Grant-access. - içinde Ortam Değişkenleri bölümünde anahtarı seçin
Task_To_Performve değeri şu şekilde güncelleyin:CLEANUP. - Veritabanını, tabloyu ve bunlarla ilişkili LF Etiketlerini bırakan işlevi çalıştırın.
- AWS CloudFormation konsolunda icebergdemo1 yığınını silin.
Sonuç
Bu yazıda, AWS Glue API'sini kullanarak bir Iceberg tablosu oluşturdunuz ve işlemsel veri gölündeki Iceberg tablosuna erişimi kontrol etmek için Lake Formation'ı kullandınız. AWS Glue ETL işleriyle verileri Iceberg tablosuyla birleştirdiniz ve Iceberg tablosunu yeniden yazmaya veya yeniden oluşturmaya gerek kalmadan şema geliştirme ve bölüm geliştirme gerçekleştirdiniz. Athena ile Iceberg verilerini ve meta verilerini sorguladınız.
Bu gönderideki konseptlere ve gösterimlere dayanarak artık Iceberg, AWS Glue, Lake Formation ve Amazon S3 kullanarak bir kuruluşta işlemsel veri gölü oluşturabilirsiniz.
Yazar Hakkında
 Satya Adimula Boston merkezli AWS'de Kıdemli Veri Mimarıdır. Veri ve analitik alanında yirmi yılı aşkın deneyimiyle Satya, kuruluşların verilerinden geniş ölçekte iş öngörüleri elde etmelerine yardımcı oluyor.
Satya Adimula Boston merkezli AWS'de Kıdemli Veri Mimarıdır. Veri ve analitik alanında yirmi yılı aşkın deneyimiyle Satya, kuruluşların verilerinden geniş ölçekte iş öngörüleri elde etmelerine yardımcı oluyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/use-aws-glue-etl-to-perform-merge-partition-evolution-and-schema-evolution-on-apache-iceberg/

