Takviyeli öğrenme (RL), sıralı karar verme problemlerini çözmek için kullanılabilecek bir makine öğrenimi (ML) teknikleri sınıfını kapsar. RL teknikleri, finansal hizmetler, otonom navigasyon, endüstriyel kontrol ve e-ticaret dahil olmak üzere çok sayıda alanda yaygın uygulamalar bulmuştur. Bir RL probleminin amacı, ortamından bir gözlem verildiğinde, kümülatif ödülü en üst düzeye çıkaran en uygun eylemi seçecek bir etmen yetiştirmektir. RL ile bir iş problemini çözmek, aracının ortamını, eylem alanını, gözlem yapısını ve hedef iş sonucu için doğru ödül işlevini belirlemeyi içerir. Politika tabanlı RL yöntemlerinde, model eğitiminin sonucu genellikle, gözlem verilen eylemler üzerinde bir olasılık dağılımını tanımlayan bir politikadır. Optimal politika, temsilci tarafından elde edilen kümülatif getirileri maksimize edecektir.
Kısıtlı karar verme problemlerinde, aracı, kısıtlamalar altında en uygun eylemleri seçmekle görevlendirilir. Duruma bağlı olarak, aracının yalnızca tüm eylemlerin bir alt kümesinden seçim yapmasına izin verilebildiği bu tür sorunların farklı bir sınıfı mevcuttur. Kalan eylemler kabul edilemez.
Örneğin, 10 olası hız seviyesine sahip otonom bir araba düşünün. Bu arabanın, bir yerleşim bölgesinden geçerken yalnızca hız seviyelerinin bir alt kümesinden seçim yapmasına izin verilebilir. Burada hız seviyelerindeki kısıtlama, arabanın konumuna göre belirlenir. Eylemler üzerindeki bu tür parametreleştirilmiş kısıtlamalar, birçok gerçek dünya probleminde yaygındır. Bu tür sorunları RL ile çözmek, kısıtlamaların eğitim sürecine dahil edilmesini gerektirir. Eylem maskeleme kabul edilemezlik kısıtlamaları içeren RL problemlerini örnek verimli bir şekilde çözmek için bir yaklaşımdır. Adından da anlaşılacağı gibi, örnekleme olasılıklarını sıfıra ayarlayarak kabul edilemez eylemlerin maskelenmesini içerir. Aşağıdaki şekil, eylem maskelemeli RL döngüsünü göstermektedir. Bir aracıdan, eylem maskelerini belirleyen kısıtlamalardan, maskelerden, durum geçişlerinden ve gözlemlenen ödüllerden oluşur.
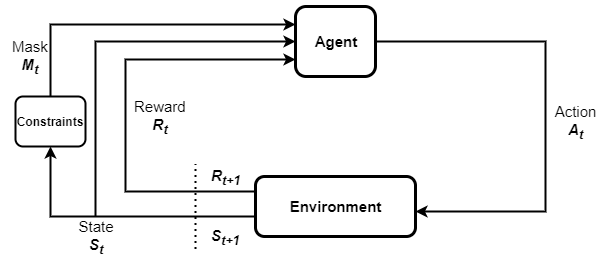
Bu yazıda, ile eylem maskelemenin nasıl uygulanacağını açıklıyoruz. Amazon SageMaker RL parametrik eylem alanlarını kullanarak ışın RLlib. Ayrık çok boyutlu eylem alanlarını ve çoklu kısıtlamaları içeren örnek bir problemi açıklıyoruz. Bu yazının not defterinin tamamına erişmek için bkz. SageMaker dizüstü bilgisayar örneği GitHub'da.
Kullanım örneğine genel bakış
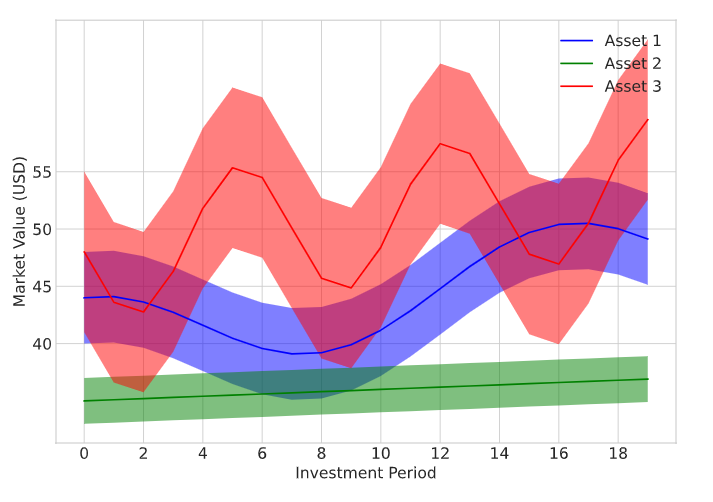
Bir yatırımcının toplam portföy değerini maksimize etmek için birden çok varlık türünü alıp sattığı örnek bir portföy optimizasyon problemini ele alıyoruz. Portföy, üç farklı varlık türünden ve banka hesabınızdaki parayı ifade eden bir nakit bakiyesinden oluşur. Her yatırım dönemi boyunca, acentenin satın aldığı veya sattığı her bir varlık türünün miktarını seçmesi gerekir. Temsilci, herhangi bir varlık alımını finanse etmek için mevcut nakit bakiyesini kullanır. Her varlık alım/satım eylemiyle ilişkili işlem maliyetleri de vardır. Her varlığın piyasa fiyatının zaman içinde değiştiği varsayılır. Fiyatlar rastgele örneklenir, ancak farklı oynaklık seviyeleri ile farklı davranışlar gösterecek şekilde modellenir. Üç varlık sınıfı için fiyat aralıkları aşağıdaki şekilde gösterilmektedir.
Temsilci için kabul edilebilir eylemler seti, mevcut toplam portföy değeri, mevcut nakit bakiyesi, elde tutulan her bir varlık türünün sayısı ve bunların mevcut piyasa değeri gibi parametreler tarafından belirlenir. Bu sorun için, olası eylemler üzerinde aşağıdaki kısıtlamaları uyguluyoruz:
- C1 – Aracı, şu anda sahip olduklarından daha fazla herhangi bir varlık türü birimi satamaz. Örneğin, temsilcinin portföyünde k zamanında 100 birim Varlık 3 varsa, o zaman o varlıktan 120 birim satamaz.
- C2 – Varlık 3, yatırımcılar tarafından oldukça değişken olarak kabul edilir. Varlık 3'teki varlıklarının toplam değeri, toplam portföy değerinin üçte birinden fazlaysa, acentenin Varlık 3'ü satın almasına izin verilmez.
- C3 – RL modelinin tüketicileri, orta derecede bir risk tercihine sahiptir ve Varlık 2'yi ihtiyatlı bir satın alma olarak kabul eder. Sonuç olarak, Varlık 2'nin toplam değeri toplam portföy değerinin üçte ikisini geçtiğinde aracının Varlık 2'yi satın almasına izin verilmez.
- C4 – Temsilci, mevcut nakit bakiyesi 1 USD'den azsa herhangi bir varlık satın alamaz.
ortamı kurun
Başlamak için, aracılığıyla bir SageMaker not defteri örneği sağlayın Amazon SageMaker Stüdyosu. Daha fazla bilgi için bakınız Amazon SageMaker Notebook bulut sunucularını kullanın.
Ardından, portföy ticaret problemini özel bir şekilde uyguluyoruz. AI Gym'i açın ortam oluşturun ve SageMaker RL'yi kullanarak bir RL temsilcisini eğitin. Bir Spor Salonu ortamı, RL temsilcisinin ortamıyla etkileşim kurması ve ödüller ile gözlemler oluşturması için bir arabirim sağlar. Portföy ticareti ortamı, trading.py modül. biz kullanıyoruz __init__ bazı ortam parametrelerini tanımlama ve başlatma yöntemi. Bu, varlık alım/satım işlemleriyle ilişkili işlem maliyetlerini, varlık fiyatlarının ortalama değerini, fiyat sapmalarını ve daha fazlasını içerir. Gözlem ve eylem alanlarını da tanımlarız. __init__ yöntem. Aşağıdaki koda bakın:
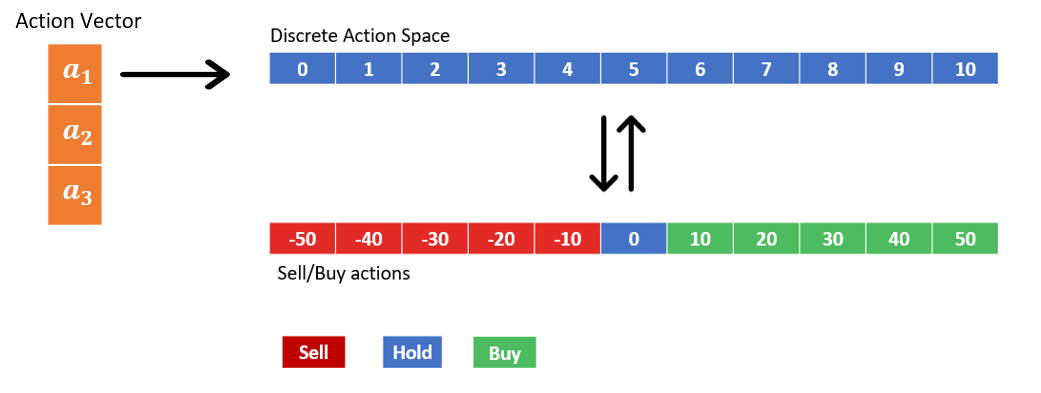
Temsilci herhangi bir zamanda üç varlık alıp sattığı için, aracı tarafından gerçekleştirilen eylemler üç boyutlu bir eylem vektörü kullanılarak temsil edilir. Eylem vektörünü oluşturan üç ayrı eylem, her bir varlık sınıfındaki işlemleri temsil eder ve her biri 11 olası değer alabilir. 11 ayrık değer, aşağıdaki şekilde gösterildiği gibi farklı satış, satın alma ve tutma eylemlerini kodlar. Örneğin, bir1=3, aracının 20 varlık türünden 1 birim satması anlamına gelir. Varlıklar 10'un katları halinde alınır ve satılır.
Gözlem uzayı iki elemanlı bir sözlük yapısına sahiptir. Bunlar, mevcut işlem durumunu ve mevcut işlem maskesi değerlerini temsil eder. Alım satım durumu, temsilci tarafından şu anda tutulan her bir varlığın miktarından, cari nakit bakiyesinden ve üç varlığın her birinin cari piyasa değerinden oluşan 7×1'lik bir vektördür. Eylem maskesi, her bir olası eyleme karşılık gelen maske değerlerine sahip 3×11'lik bir matristir. Ortam, her seferinde maske değerlerini hesaplar. update_mask() yöntem. C1:C4 kısıtlamalarından herhangi birini ihlal eden eylemlere sıfır maskesi atanır. Kabul edilebilir eylemler için mask değeri 1 olarak ayarlanmıştır. Aşağıdaki koda bakın:
Her bölümün başında bir reset() ticaret durumunu, gözlemleri ve diğer parametreleri yeniden başlatmak için yöntem çağrılır. Temsilci, her eğitim bölümüne nakit bakiyesinde 1,000 USD ve sıfır varlıkla başlar. Her bölüm 20 yatırım döneminden oluşuyor.
Temsilci, her yatırım döneminin başında, kaydettiği en son gözlemlere dayalı olarak bir eylemi örnekler ve portföyünü günceller. Bu bir kullanılarak modellenmiştir step() yöntem. Portföy güncellendikten sonra durumu yeniden hesaplıyoruz. Eylem maskesi de çağrılarak güncellenir. update_mask() yöntemi.
Ödül fonksiyonu, nihai toplam portföy değeri olarak tanımlanır ve 20 yatırım döneminden sonra gerçekleşen her bölümün sonunda hesaplanır.
maskeleme modeli
Her zaman adımında ortam, sözlük durumunu döndürür ve ilkeyi temsil eden makine öğrenimi modeli, bu duruma dayalı bir eylem örneği verir. Bir parametrik eylem modeli, yalnızca maskelenmemiş (maske ≠ 0) eylemlerin örneklenmesini kolaylaştırır. Burada, eylem maskelemeyi etkinleştiren parametrik eylem modelini açıklıyoruz:
Eylemler, bir eylem gömme modeli tarafından verilen logitleri kullanan bir Softmax işlevi aracılığıyla model tarafından örneklenir. Bu model, __init__ yöntem. Maskeleme davranışının kendisi, forward() yöntem. Burada, işlem maskelerini ve ticaret durumunu çevreden alınan sözlük durumundan ayırıyoruz. İşlem yerleştirmeleri daha sonra ticaret durumunu eylem yerleştirme ağına geçirerek elde edilir. Ardından, her eylemin yerleştirme değerini ekleyerek değiştiririz. logit_mod logitlere. Dikkat edin logit_mod eylem maskesinin logaritmasının bir işlevidir. Mask = 1 olan eylemler için, mask'ın logaritması sıfır olur ve bu da onların yerleştirmelerini bozulmadan bırakır. Öte yandan, maske=0 olduğunda, maskenin logaritması → -∞. çünkü Softmax(x) →x olarak 0→ -∞, bu, maskelenmiş eylemlerin aracı tarafından örneklenmemesini sağlar.
Maskenin beklendiği gibi çalışıp çalışmadığını test edelim. Bir ışın eğitmeni nesnesi başlatıyoruz ve bazı eylemleri maskeliyoruz ve eğitmenin yalnızca maskesiz eylemleri örnekleyip örneklemediğine bakıyoruz:
Aşağıdaki ekran görüntüsündeki çıktı, ilk eylem maskesi dizisini gösterir.

Şimdi maske vektörlerini değiştirelim, böylece1, eylem 8 hariç tüm seçenekler (30 adet Varlık 1 satın alın); için2 eylem 5 hariç her şey (Varlık 2'yi mevcut rakamlarda tutun); ve bir için3, 1. ve 2. işlemler (40 veya 30 adet Varlık 3 satmak) dışındaki her şey maskelenir:
Artık eylem maskesi dizisini değiştirdiğimize göre, yeni bir eylemi deneyip örnekleyeceğiz.

Aracı yalnızca maskesi kaldırılmış eylemleri örnekler. Bu, eylem maskelemenin beklendiği gibi çalıştığını doğrular.
Sonuçlar
Artık ortam ve parametrik eylem modeli tanımlandığına göre, SageMaker RL'yi kullanarak portföy optimizasyon problemini çözmek için bir aracı eğitiyoruz. C1:C4 kısıtlamaları altında ödülü en üst düzeye çıkarmak için en uygun politikayı öğrenmek üzere bir RL temsilcisini eğitiyoruz. RL aracısını 500,000 bölüm için eğitmek üzere SageMaker RL'deki yakın politika optimizasyonu (PPO) algoritmasını kullanıyoruz. Aşağıdaki eğitim yapılandırması, kullanılacak aracıyı nasıl belirlediğimizi gösterir. trading_mask bir şekilde custom_model kullanılacak olan:
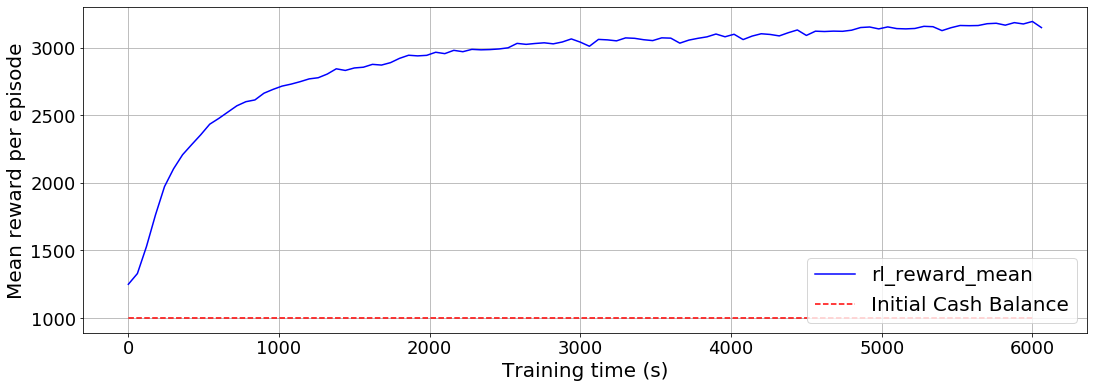
Acente, ilk nakit bakiyesinde 1,000 USD ile başlar. Bölüm başına ortalama ödül, aşağıdaki tabloda gösterildiği gibi eğitim süresinin bir fonksiyonu olarak çizilir. Nihai toplam portföy değerini ödül olarak kullandığımızı hatırlayın. 20 yatırım dönemi sonunda acente portföyünün ortalama değerinin 3,000 USD'nin üzerinde olduğunu gözlemliyoruz.
Temizlemek
Bir SageMaker not defteri örneğinin kullanımının ötesinde herhangi bir altyapı sağlamadık. Studio aracılığıyla bir SageMaker not defteri örneği kullanıyorsanız, içindeki talimatları izleyerek onu kapatabilirsiniz. Açık Bir Not Defterini Kapatın.
Sonuç
Bu gönderide, RL modeli eğitiminde kısıtlamaları uygulamak için eylem maskelemeyi nasıl uygulayabileceğinizi tartıştık. Kabul edilemez eylemleri maskeleyerek, temsilcinin yalnızca geçerli eylemleri örneklemesini ve en uygun politikayı örnek verimli bir şekilde öğrenmesini sağlıyoruz. Temsilcinin, çoklu kısıtlamalar altında üç varlık türünün ticaretini yaparak portföy değerini en üst düzeye çıkarmakla görevlendirildiği bir portföy optimizasyon problemi sunduk. Ray RLlib kullanarak bu problem için çok boyutlu eylem maskelemenin nasıl uygulanacağını gösterdik. Kısıtlı portföy optimizasyon problemini SageMaker RL kullanarak çözmesi için bir RL aracısı eğittik.
Portföy optimizasyonunda SageMaker RL ve Ray RLlib kullanarak eylem maskelemeyi nasıl gerçekleştireceğinizi artık bildiğinize göre, bunu kabul edilemez eylemler içeren diğer RL problemlerinde deneyebilirsiniz. Bu gönderide geliştirilen eylem maskeleme kodunu, tek boyutlu eylem uzayını içeren daha basit problemler için de uyarlayabilirsiniz. Burada geliştirilen yaklaşımı RL kullanım durumlarınıza uygulamanızı ve herhangi bir sorunuz veya geri bildiriminiz varsa bize bildirmenizi öneririz.
Ek referanslar
Ek bilgi ve ilgili içerik için aşağıdaki kaynaklara bakın:
Yazarlar Hakkında
 Dilşad Raihan Akkam Veettin AWS Profesyonel Hizmetlerinde çalışan bir Veri Bilimcisidir ve burada makine öğrenimi ve bulut bilgi işlem kullanarak iş zorluklarını çözmek için farklı sektörlerden müşterilerle iletişim kurar. Texas A&M Üniversitesi, College Station'dan Havacılık ve Uzay Mühendisliği alanında doktora derecesine sahiptir. Boş zamanlarında futbol izlemekten ve kitap okumaktan hoşlanır.
Dilşad Raihan Akkam Veettin AWS Profesyonel Hizmetlerinde çalışan bir Veri Bilimcisidir ve burada makine öğrenimi ve bulut bilgi işlem kullanarak iş zorluklarını çözmek için farklı sektörlerden müşterilerle iletişim kurar. Texas A&M Üniversitesi, College Station'dan Havacılık ve Uzay Mühendisliği alanında doktora derecesine sahiptir. Boş zamanlarında futbol izlemekten ve kitap okumaktan hoşlanır.
 Paul Budnarain Amazon'un Envanter Tahmin Sistemleri (IFS) grubunda bir Uygulamalı Bilim Adamıdır ve Los Angeles, California merkezlidir.
Paul Budnarain Amazon'un Envanter Tahmin Sistemleri (IFS) grubunda bir Uygulamalı Bilim Adamıdır ve Los Angeles, California merkezlidir.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/portfolio-optimization-through-multidimensional-action-optimization-using-amazon-sagemaker-rl/

