Üretken yapay zeka uygulamalarının hızla benimsenmesiyle birlikte, bu uygulamaların daha yüksek verimle algılanan gecikmeyi azaltmak için zamanında yanıt vermesine ihtiyaç duyulmaktadır. Temel modeller (FM'ler) genellikle milyonlarca, milyarlarca ve ötesinde parametrelere sahip geniş bir veri kümesi üzerinde önceden eğitilir. Büyük dil modelleri (LLM'ler), kullanıcı çıkarımına yanıt olarak metin üreten bir FM türüdür. Bu modellerin çıkarım parametrelerinin değişen yapılandırmalarıyla çıkarımlanması tutarsız gecikmelere yol açabilir. Tutarsızlık, modelden beklediğiniz yanıt belirteçlerinin değişen sayısı veya modelin konuşlandırıldığı hızlandırıcı türü nedeniyle olabilir.
Her iki durumda da, tam yanıtı beklemek yerine, çıkarımlarınız için bilgi yığınlarını oluşturuldukları anda geri gönderen yanıt akışı yaklaşımını benimseyebilirsiniz. Bu, gecikmeli tam yanıt yerine gerçek zamanlı olarak yayınlanan kısmi yanıtları görmenize olanak tanıyarak etkileşimli bir deneyim yaratır.
Resmi duyuruyla birlikte Amazon SageMaker gerçek zamanlı çıkarım artık yanıt akışını destekliyorkullanarak, artık çıkarım yanıtlarını istemciye sürekli olarak aktarabilirsiniz. Amazon Adaçayı Yapıcı Yanıt akışıyla gerçek zamanlı çıkarım. Bu çözüm, sohbet robotları, sanal asistanlar ve müzik oluşturucular gibi çeşitli üretken yapay zeka uygulamaları için etkileşimli deneyimler oluşturmanıza yardımcı olacaktır. Bu gönderi, İlk Bayta Kadar Geçen Süre (TTFB) biçiminde daha hızlı yanıt sürelerini nasıl gerçekleştireceğinizi ve Llama 2 modellerini çıkarım yaparken algılanan genel gecikmeyi nasıl azaltacağınızı gösterir.
Çözümü uygulamak için, verileri hazırlamak ve tam olarak yönetilen altyapı, araçlar ve iş akışlarıyla her türlü kullanım senaryosuna yönelik makine öğrenimi (ML) modellerini oluşturmak, eğitmek ve dağıtmak için tam olarak yönetilen bir hizmet olan SageMaker'ı kullanıyoruz. SageMaker'ın sağladığı çeşitli dağıtım seçenekleri hakkında daha fazla bilgi için bkz. Amazon SageMaker Model Barındırma SSS'leri. Yanıt akışıyla gerçek zamanlı çıkarımı kullanarak gecikme sorunlarını nasıl çözebileceğimizi anlayalım.
Çözüme genel bakış
Yüksek Lisans ile gerçek zamanlı çıkarımla ilişkili yukarıda belirtilen gecikmeleri ele almak istediğimiz için, öncelikle Llama 2 için gerçek zamanlı çıkarım için yanıt akışı desteğini nasıl kullanabileceğimizi anlayalım. Ancak herhangi bir Yüksek Lisans, gerçek zamanlı çıkarımla yanıt akışı desteğinden yararlanabilir. -zaman çıkarımı.
Llama 2, ölçeği 7 milyar ile 70 milyar parametre arasında değişen, önceden eğitilmiş ve ince ayar yapılmış üretken metin modellerinden oluşan bir koleksiyondur. Llama 2 modelleri yalnızca kod çözücü mimarisine sahip otoregresif modellerdir. İstem ve çıkarım parametreleri sağlandığında, Llama 2 modelleri metin yanıtları oluşturma yeteneğine sahiptir. Bu modeller çeviri, özetleme, soru cevaplama ve sohbet için kullanılabilir.
Bu yazı için Llama 2 Chat modelini konuşlandırıyoruz meta-llama/Llama-2-13b-chat-hf Yanıt akışıyla gerçek zamanlı çıkarım için SageMaker'da.
Modellerin SageMaker uç noktalarına dağıtılması söz konusu olduğunda, modelleri uzmanlaşmış AWS Derin Öğrenme Kapsayıcısı Popüler açık kaynak kütüphaneler için mevcut (DLC) görseller. Llama 2 modelleri metin oluşturma modelleridir; ikisinden birini kullanabilirsiniz SageMaker'da Hugging Face LLM çıkarım kapsayıcıları Hugging Face tarafından desteklenmektedir Metin Oluşturma Çıkarımı (TGI) veya AWS DLC'leri Büyük Model Çıkarımı (LMI).
Bu yazıda, G2 bulut sunucuları tarafından desteklenen gerçek zamanlı çıkarım için SageMaker Hosting'deki DLC'leri kullanarak Llama 13 5B Chat modelini dağıtıyoruz. G5 bulut sunucuları, grafik ağırlıklı uygulamalar ve makine öğrenimi çıkarımı için yüksek performanslı GPU tabanlı bulut sunucularıdır. Bulut sunucusu yapılandırmasına göre uygun değişikliklerle desteklenen p4d, p3, g5 ve g4dn bulut sunucusu türlerini de kullanabilirsiniz.
Önkoşullar
Bu çözümü uygulamak için aşağıdakilere sahip olmalısınız:
- ile bir AWS hesabı AWS Kimlik ve Erişim Yönetimi Çözümün bir parçası olarak oluşturulan kaynakları yönetme izinlerine sahip (IAM) rolü.
- Eğer bu ilk kez çalışıyorsanız Amazon SageMaker Stüdyosu, önce bir oluşturmanız gerekir SageMaker etki alanı.
- Hugging Face hesabı. Kayıt ol Henüz hesabınız yoksa e-posta adresinizle.
- Hugging Face'te bulunan modellere, özellikle de Llama gibi kapılı modellere ince ayar ve çıkarım yapma amacıyla kusursuz erişim için, okuma erişim jetonu almak üzere bir Hugging Face hesabınızın olması gerekir. Hugging Face hesabınıza kaydolduktan sonra, oturum aç ziyaret etmek https://huggingface.co/settings/tokens okuma erişim belirteci oluşturmak için.
- Hugging Face'e kaydolurken kullandığınız e-posta kimliğini kullanarak Llama 2'ye erişin.
- Hugging Face aracılığıyla sunulan Llama 2 modelleri kapılı modellerdir. Llama modelinin kullanımı Meta lisansına tabidir. Model ağırlıklarını ve tokenizer'ı indirmek için, Lama'ya erişim isteğinde bulun ve lisanslarını kabul edin.
- Size erişim izni verildikten sonra (genellikle birkaç gün içinde), bir e-posta onayı alacaksınız. Bu örnek için şu modeli kullanıyoruz:
Llama-2-13b-chat-hf, ancak diğer değişkenlere de erişebilmeniz gerekir.
Yaklaşım 1: Sarılma Yüzü TGI
Bu bölümde size nasıl dağıtılacağını göstereceğiz. meta-llama/Llama-2-13b-chat-hf modeli, Hugging Face TGI kullanarak yanıt akışıyla SageMaker gerçek zamanlı uç noktasına bağlayın. Aşağıdaki tabloda bu dağıtımın özellikleri özetlenmektedir.
| Özellikler | Özellik |
| Konteyner | Sarılma Yüzü TGI |
| Model adı | meta-llama/Llama-2-13b-sohbet-hf |
| ML Örneği | ml.g5.12xlarge |
| sonuç | Yanıt akışıyla gerçek zamanlı |
Modeli dağıtın
İlk olarak, dağıtılacak LLM'nin temel görüntüsünü alırsınız. Daha sonra modeli temel görüntü üzerinde oluşturursunuz. Son olarak, gerçek zamanlı çıkarım için SageMaker Hosting'e yönelik modeli makine öğrenimi örneğine dağıtırsınız.
Dağıtımın programlı olarak nasıl gerçekleştirileceğini görelim. Kısaca belirtmek gerekirse, bu bölümde yalnızca dağıtım adımlarına yardımcı olan kod ele alınmaktadır. Dağıtım için tam kaynak kodu dizüstü bilgisayarda mevcuttur llama-2-hf-tgi/llama-2-13b-chat-hf/1-deploy-llama-2-13b-chat-hf-tgi-sagemaker.ipynb.
Önceden oluşturulmuş aracılığıyla TGI tarafından desteklenen en yeni Hugging Face LLM DLC'sini edinin SageMaker DLC'leri. Bu görüntüyü dağıtmak için kullanırsınız meta-llama/Llama-2-13b-chat-hf SageMaker'daki model. Aşağıdaki koda bakın:
Modelin ortamını aşağıdaki gibi tanımlanan yapılandırma parametreleriyle tanımlayın:
değiştirmek <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> yapılandırma parametresi için HUGGING_FACE_HUB_TOKEN Bu gönderinin önkoşullar bölümünde ayrıntılı olarak açıklanan Hugging Face profilinizden elde edilen jetonun değeri ile. Yapılandırmada, bir modelin kopyası başına kullanılan GPU sayısını 4 olarak tanımlarsınız. SM_NUM_GPUS. Daha sonra dağıtabilirsiniz meta-llama/Llama-2-13b-chat-hf 5.12 GPU ile birlikte gelen ml.g4xlarge örneğindeki model.
Artık örneğini oluşturabilirsiniz HuggingFaceModel yukarıda belirtilen ortam yapılandırmasıyla:
Son olarak, modelde mevcut konuşlandırma yöntemine aşağıdaki gibi çeşitli parametre değerleriyle argümanlar sağlayarak modeli konuşlandırın. endpoint_name, initial_instance_count, ve instance_type:
Çıkarım gerçekleştir
Hugging Face TGI DLC, modelde herhangi bir özelleştirme veya kod değişikliği olmadan yanıtları yayınlama yeteneğiyle birlikte gelir. Kullanabilirsiniz invoke_endpoint_with_response_stream Boto3 kullanıyorsanız veya InvokeEndpointWithResponseStream SageMaker Python SDK ile programlama yaparken.
The InvokeEndpointWithResponseStream SageMaker API'si, geliştiricilerin SageMaker modellerinden gelen yanıtları geri göndermesine olanak tanır; bu da algılanan gecikmeyi azaltarak müşteri memnuniyetini artırmaya yardımcı olabilir. Bu, özellikle anında işlemenin, yanıtın tamamını beklemekten daha önemli olduğu, üretken yapay zeka modelleriyle oluşturulan uygulamalar için önemlidir.
Bu örnekte modeli çıkarmak için Boto3'ü kullanıyoruz ve SageMaker API'sini kullanıyoruz. invoke_endpoint_with_response_stream aşağıdaki gibidir:
Argüman CustomAttributes değere ayarlandı accept_eula=false. The accept_eula parametre şu şekilde ayarlanmalıdır true Llama 2 modellerinden başarıyla yanıt almak için. Başarılı çağrımdan sonra kullanarak invoke_endpoint_with_response_stream, yöntem baytlardan oluşan bir yanıt akışı döndürecektir.
Aşağıdaki şemada bu iş akışı gösterilmektedir.
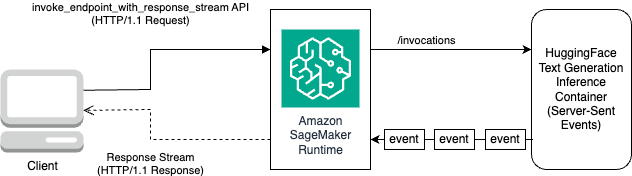
Bayt akışı üzerinde döngü yapan ve bunları okunabilir metne ayrıştıran bir yineleyiciye ihtiyacınız var. LineIterator uygulamaya şu adresten ulaşılabilir: llama-2-hf-tgi/llama-2-13b-chat-hf/utils/LineIterator.py. Artık modeli çıkarım yaparken bunları veri yükü olarak kullanmak için komut istemini ve talimatları hazırlamaya hazırsınız.
Bir bilgi istemi ve talimatlar hazırlayın
Bu adımda, LLM'niz için istemi ve talimatları hazırlarsınız. Lama 2'yi yönlendirmek için aşağıdaki bilgi istemi şablonuna sahip olmanız gerekir:
Yöntemde programlı olarak tanımlanan bilgi istemi şablonunu oluşturursunuz build_llama2_prompt, yukarıda belirtilen bilgi istemi şablonuyla uyumludur. Daha sonra kullanım senaryosuna göre talimatları tanımlarsınız. Bu durumda, modele, bu bölümde anlatıldığı gibi bir pazarlama kampanyası için bir e-posta oluşturması talimatını veriyoruz. get_instructions yöntem. Bu yöntemlerin kodu llama-2-hf-tgi/llama-2-13b-chat-hf/2-sagemaker-realtime-inference-llama-2-13b-chat-hf-tgi-streaming-response.ipynb not defteri. Talimatı, aşağıda ayrıntılı olarak belirtildiği gibi gerçekleştirilecek görevle birleştirerek oluşturun. user_ask_1 aşağıdaki gibidir:
Komut istemini build_llama2_prompt tarafından oluşturulan bilgi istemi şablonuna göre oluşturmak için talimatları aktarıyoruz.
Çıkarım parametrelerini istemle birlikte anahtarla birleştiriyoruz stream değeri ile True son bir yük oluşturmak için. Yükü şuraya gönder: get_realtime_response_streamYanıt akışıyla bir uç noktayı çağırmak için kullanılacak olan:
LLM'den oluşturulan metin, aşağıdaki animasyonda gösterildiği gibi çıktıya aktarılacaktır.
Yaklaşım 2: DJL Hizmetli LMI
Bu bölümde, nasıl dağıtılacağını gösteriyoruz. meta-llama/Llama-2-13b-chat-hf modeli, DJL Hizmetli LMI kullanarak yanıt akışıyla SageMaker gerçek zamanlı uç noktasına bağlayın. Aşağıdaki tabloda bu dağıtımın özellikleri özetlenmektedir.
| Özellikler | Özellik |
| Konteyner | DJL Sunumu ile LMI kapsayıcı görüntüsü |
| Model adı | meta-llama/Llama-2-13b-sohbet-hf |
| ML Örneği | ml.g5.12xlarge |
| sonuç | Yanıt akışıyla gerçek zamanlı |
İlk önce modeli indirip saklıyorsunuz Amazon Basit Depolama Hizmeti (Amazon S3). Daha sonra modelin S3 önekini belirten S3 URI'sini belirtirsiniz. serving.properties dosya. Daha sonra, dağıtılacak LLM'nin temel görüntüsünü alırsınız. Daha sonra modeli temel görüntü üzerinde oluşturursunuz. Son olarak, gerçek zamanlı çıkarım için SageMaker Hosting'e yönelik modeli makine öğrenimi örneğine dağıtırsınız.
Yukarıda belirtilen dağıtım adımlarının programlı olarak nasıl gerçekleştirileceğini görelim. Kısaca belirtmek gerekirse, bu bölümde yalnızca dağıtım adımlarına yardımcı olan kod ayrıntılı olarak açıklanmaktadır. Bu dağıtımın kaynak kodunun tamamı dizüstü bilgisayarda mevcuttur llama-2-lmi/llama-2-13b-chat/1-deploy-llama-2-13b-chat-lmi-response-streaming.ipynb.
Hugging Face'ten model anlık görüntüsünü indirin ve model yapıtlarını Amazon S3'e yükleyin
Yukarıda belirtilen ön koşullarla, modeli SageMaker dizüstü bilgisayar örneğine indirin ve ardından daha fazla dağıtım için S3 klasörüne yükleyin:
Geçerli bir erişim belirteci sağlamasanız bile modelin indirileceğini unutmayın. Ancak böyle bir modeli dağıttığınızda model sunumu başarılı olmaz. Bu nedenle değiştirilmesi önerilir <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> argüman için token Önkoşullarda ayrıntılı olarak açıklanan Hugging Face profilinizden elde edilen jetonun değeri ile. Bu yazı için, Llama 2'nin resmi modelinin adını, Hugging Face'te tanımlandığı şekliyle şu değerle belirtiyoruz: meta-llama/Llama-2-13b-chat-hf. Sıkıştırılmamış model şuraya indirilecektir: local_model_path Yukarıda belirtilen kodu çalıştırmanın bir sonucu olarak.
Dosyaları Amazon S3'e yükleyin ve daha sonra kullanılacak URI'yi edinin. serving.properties.
Paketleyeceksin meta-llama/Llama-2-13b-chat-hf belirtilen yapılandırmayı kullanarak DJL Hizmetine sahip LMI kapsayıcı görüntüsündeki model serving.properties. Daha sonra modeli, SageMaker ML örneğinin ml.g5.12xlarge üzerindeki kapsayıcı görüntüsünde paketlenmiş model yapıtlarıyla birlikte dağıtırsınız. Daha sonra bu makine öğrenimi örneğini, gerçek zamanlı çıkarım yapmak amacıyla SageMaker Hosting için kullanırsınız.
DJL Sunumu için model yapıtlarını hazırlayın
Bir model oluşturarak model yapıtlarınızı hazırlayın. serving.properties yapılandırma dosyası:
Bu yapılandırma dosyasında aşağıdaki ayarları kullanıyoruz:
- motor – Bu, DJL'nin kullanacağı çalışma zamanı motorunu belirtir. Olası değerler şunları içerir:
Python,DeepSpeed,FasterTransformer, veMPI. Bu durumda bunu şu şekilde ayarladık:MPI. Model Paralelleştirme ve Çıkarım (MPI), modeli mevcut tüm GPU'lara bölmeyi kolaylaştırır ve dolayısıyla çıkarımı hızlandırır. - seçenek.giriş Noktası – Bu seçenek, DJL Serving tarafından sunulan hangi işleyiciyi kullanmak istediğinizi belirtir. Olası değerler şunlardır
djl_python.huggingface,djl_python.deepspeed, vedjl_python.stable-diffusion. Kullanırızdjl_python.huggingfaceSarılma Yüzü Hızlandırmak için. - seçenek.tensor_parallel_degree – Bu seçenek, modelde gerçekleştirilen tensör paralel bölümlerinin sayısını belirtir. Accelerate'in modeli bölümlendirmesi gereken GPU cihazlarının sayısını ayarlayabilirsiniz. Bu parametre aynı zamanda DJL hizmeti çalıştırıldığında model başına başlatılacak çalışan sayısını da kontrol eder. Örneğin, 4 GPU'lu bir makinemiz varsa ve dört bölüm oluşturuyorsak, istekleri yerine getirmek için model başına bir çalışanımız olacaktır.
- option.low_cpu_mem_usage – Bu, modelleri yüklerken CPU bellek kullanımını azaltır. Bunu şu şekilde ayarlamanızı öneririz:
TRUE. - option.rolling_batch – Bu, desteklenen stratejilerden birini kullanarak yineleme düzeyinde toplu işleme olanak tanır. Değerler şunları içerir:
auto,scheduler, velmi-dist. Kullanırızlmi-distLama 2 için sürekli gruplamayı açmak için. - option.max_rolling_batch_size – Bu, sürekli toplu işteki eşzamanlı isteklerin sayısını sınırlar. Değer varsayılan olarak 32'dir.
- seçenek.model_id – Değiştirmelisin
{{model_id}}içinde barındırılan önceden eğitilmiş bir modelin model kimliğiyle Hugging Face'teki model deposu veya model yapılarının S3 yolu.
Daha fazla yapılandırma seçeneğini şu adreste bulabilirsiniz: Yapılandırmalar ve ayarlar.
DJL Serving, model yapıtlarının bir .tar dosyasında paketlenmesini ve biçimlendirilmesini beklediğinden, .tar dosyasını sıkıştırıp Amazon S3'e yüklemek için aşağıdaki kod parçacığını çalıştırın:
DJL Sunumu ile en son LMI konteyner görüntüsünü alın
Daha sonra, modeli dağıtmak için SageMaker for LMI'da bulunan DLC'leri kullanırsınız. için SageMaker görüntü URI'sini alın. djl-deepspeed Aşağıdaki kodu kullanarak programlı olarak kapsayıcı:
Yukarıda belirtilen görüntüyü dağıtmak için kullanabilirsiniz. meta-llama/Llama-2-13b-chat-hf SageMaker'daki model. Artık modeli oluşturmaya devam edebilirsiniz.
Modeli oluşturun
Kullanarak konteyneri oluşturulan modeli oluşturabilirsiniz. inference_image_uri ve S3 URI'sinde bulunan model sunma kodu ile gösterilir. s3_code_artifact:
Artık uç nokta yapılandırmasının tüm ayrıntılarını içeren model yapılandırmasını oluşturabilirsiniz.
Model yapılandırmasını oluşturun
Tarafından tanımlanan model için bir model yapılandırması oluşturmak üzere aşağıdaki kodu kullanın. model_name:
Model yapılandırması aşağıdakiler için tanımlanmıştır: ProductionVariants parametre InstanceType ML örneği için ml.g5.12xlarge. Ayrıca şunları da sağlarsınız: ModelName önceki adımda modeli oluşturmak için kullandığınız adın aynısını kullanarak model ile uç nokta yapılandırması arasında bir ilişki kurabilirsiniz.
Artık modeli ve model yapılandırmasını tanımladığınıza göre SageMaker uç noktasını oluşturabilirsiniz.
SageMaker uç noktasını oluşturun
Aşağıdaki kod parçacığını kullanarak modeli dağıtmak için uç noktayı oluşturun:
Aşağıdaki kod parçacığını kullanarak dağıtımın ilerlemesini görüntüleyebilirsiniz:
Dağıtım başarılı olduktan sonra uç nokta durumu şu şekilde olacaktır: InService. Artık uç nokta hazır olduğuna göre yanıt akışıyla çıkarım yapalım.
Yanıt akışıyla gerçek zamanlı çıkarım
Hugging Face TGI için daha önceki yaklaşımda ele aldığımız gibi, aynı yöntemi kullanabilirsiniz. get_realtime_response_stream SageMaker uç noktasından yanıt akışını başlatmak için. LMI yaklaşımını kullanarak çıkarım yapma kodu llama-2-lmi/llama-2-13b-chat/2-inference-llama-2-13b-chat-lmi-response-streaming.ipynb not defteri. LineIterator uygulama yer almaktadır llama-2-lmi/utils/LineIterator.py. Unutmayın ki LineIterator LMI konteynerine konuşlandırılan Llama 2 Chat modeli için LineIterator Hugging Face TGI bölümünde referans alınmıştır. LineIterator LMI kapsayıcısı ile çıkarım yapılan Llama 2 Chat modellerinden gelen bayt akışı üzerinde döngüler djl-deepspeed sürüm 0.25.0. Aşağıdaki yardımcı işlev, aracılığıyla yapılan çıkarım talebinden alınan yanıt akışını ayrıştıracaktır. invoke_endpoint_with_response_stream API:
Önceki yöntem, sunucu tarafından okunan veri akışını yazdırır. LineIterator insan tarafından okunabilir bir formatta.
Modeli çıkarım yaparken bilgi istemi ve talimatlarını payload olarak kullanmak için nasıl hazırlanacağını keşfedelim.
Hem Hugging Face TGI hem de LMI'da aynı modelden çıkarım yaptığınız için istem ve talimatları hazırlama süreci aynıdır. Bu nedenle yöntemleri kullanabilirsiniz. get_instructions ve build_llama2_prompt çıkarım yapmak için.
The get_instructions yöntem talimatları döndürür. Talimatlarda ayrıntılı olarak belirtildiği gibi gerçekleştirilecek görevle birleştirilmiş talimatlar oluşturun. user_ask_2 aşağıdaki gibidir:
tarafından oluşturulan bilgi istemi şablonuna göre istemi oluşturmak için talimatları iletin. build_llama2_prompt:
Çıkarım parametrelerini son bir yük oluşturma istemiyle birlikte bir araya getiriyoruz. Daha sonra yükü şu adrese gönderirsiniz: get_realtime_response_stream, yanıt akışıyla bir uç noktayı çağırmak için kullanılır:
LLM'den oluşturulan metin, aşağıdaki animasyonda gösterildiği gibi çıktıya aktarılacaktır.

Temizlemek
Gereksiz masraflardan kaçınmak için, AWS Yönetim Konsolu gönderide bahsedilen yaklaşımları çalıştırırken oluşturulan uç noktaları ve bununla ilişkili kaynakları silmek için. Her iki dağıtım yaklaşımı için de aşağıdaki temizleme rutinini gerçekleştirin:
değiştirmek <SageMaker_Real-time_Endpoint_Name> değişken için endpoint_name gerçek son nokta ile.
İkinci yaklaşım için model ve kod yapıtlarını Amazon S3'te depoladık. Aşağıdaki kodu kullanarak S3 kovasını temizleyebilirsiniz:
Sonuç
Bu yazıda, değişen sayıda yanıt jetonunun veya farklı çıkarım parametreleri kümesinin LLM'lerle ilişkili gecikmeleri nasıl etkileyebileceğini tartıştık. Yanıt akışının yardımıyla sorunun nasıl çözüleceğini gösterdik. Daha sonra AWS DLC'leri kullanarak Llama 2 Chat modellerini dağıtmaya ve çıkarım yapmaya yönelik iki yaklaşım belirledik: LMI ve Hugging Face TGI.
Artık akış yanıtının önemini ve bunun algılanan gecikmeyi nasıl azaltabileceğini anlamalısınız. Akış yanıtı kullanıcı deneyimini iyileştirebilir; aksi takdirde LLM tüm yanıtı oluşturana kadar beklemenize neden olur. Ek olarak, Llama 2 Chat modellerinin yanıt akışıyla dağıtılması, kullanıcı deneyimini iyileştirir ve müşterilerinizi mutlu eder.
Resmi aws örneklerine başvurabilirsiniz amazon-sagemaker-llama2-yanıt-akış-tarifleri diğer Llama 2 model çeşitlerinin dağıtımını kapsar.
Referanslar
Yazarlar Hakkında
 Pavan Kumar Rao Navule Amazon Web Services'te Çözüm Mimarıdır. AWS'de yenilik yapmalarına yardımcı olmak için Hindistan'daki ISV'lerle birlikte çalışıyor. “V Programlamaya Başlarken” kitabının yayınlanmış yazarıdır. Haydarabad'daki Hindistan Teknoloji Enstitüsü'nde (IIT) Veri Bilimi alanında Yönetici Yüksek Teknoloji eğitimi aldı. Ayrıca Hindistan İşletme Yönetimi ve Yönetimi Okulu'nda BT uzmanlığı alanında Executive MBA yaptı ve Vaagdevi Teknoloji ve Bilim Enstitüsü'nden Elektronik ve Haberleşme Mühendisliği alanında B.Tech derecesine sahiptir. Pavan, AWS Sertifikalı Çözüm Mimarı Uzmanıdır ve AWS Sertifikalı Makine Öğrenimi Uzmanlığı, Microsoft Sertifikalı Profesyonel (MCP) ve Microsoft Sertifikalı Teknoloji Uzmanı (MCTS) gibi diğer sertifikalara sahiptir. Aynı zamanda açık kaynak meraklısıdır. Boş zamanlarında Sia ve Rihanna'nın muhteşem büyülü seslerini dinlemeyi seviyor.
Pavan Kumar Rao Navule Amazon Web Services'te Çözüm Mimarıdır. AWS'de yenilik yapmalarına yardımcı olmak için Hindistan'daki ISV'lerle birlikte çalışıyor. “V Programlamaya Başlarken” kitabının yayınlanmış yazarıdır. Haydarabad'daki Hindistan Teknoloji Enstitüsü'nde (IIT) Veri Bilimi alanında Yönetici Yüksek Teknoloji eğitimi aldı. Ayrıca Hindistan İşletme Yönetimi ve Yönetimi Okulu'nda BT uzmanlığı alanında Executive MBA yaptı ve Vaagdevi Teknoloji ve Bilim Enstitüsü'nden Elektronik ve Haberleşme Mühendisliği alanında B.Tech derecesine sahiptir. Pavan, AWS Sertifikalı Çözüm Mimarı Uzmanıdır ve AWS Sertifikalı Makine Öğrenimi Uzmanlığı, Microsoft Sertifikalı Profesyonel (MCP) ve Microsoft Sertifikalı Teknoloji Uzmanı (MCTS) gibi diğer sertifikalara sahiptir. Aynı zamanda açık kaynak meraklısıdır. Boş zamanlarında Sia ve Rihanna'nın muhteşem büyülü seslerini dinlemeyi seviyor.
 Sudhanshu Nefreti AWS'nin baş AI/ML uzmanıdır ve müşterilere MLOps ve üretken yapay zeka yolculukları hakkında tavsiyelerde bulunmak için onlarla birlikte çalışır. Amazon'dan önceki görevinde, temelden açık kaynak tabanlı yapay zeka ve oyunlaştırma platformları oluşturmak için ekipleri kavramsallaştırdı, oluşturdu ve yönetti ve bunu 100'den fazla müşteriyle başarıyla ticarileştirdi. Sudhanshu birkaç patente sahiptir, iki kitap, birkaç makale ve blog yazmıştır ve çeşitli teknik forumlarda bakış açılarını sunmuştur. Kendisi bir düşünce lideri ve konuşmacıdır ve yaklaşık 25 yıldır sektördedir. Dünyanın dört bir yanındaki Fortune 1000 müşterileriyle ve son olarak Hindistan'daki dijital yerli müşterilerle çalıştı.
Sudhanshu Nefreti AWS'nin baş AI/ML uzmanıdır ve müşterilere MLOps ve üretken yapay zeka yolculukları hakkında tavsiyelerde bulunmak için onlarla birlikte çalışır. Amazon'dan önceki görevinde, temelden açık kaynak tabanlı yapay zeka ve oyunlaştırma platformları oluşturmak için ekipleri kavramsallaştırdı, oluşturdu ve yönetti ve bunu 100'den fazla müşteriyle başarıyla ticarileştirdi. Sudhanshu birkaç patente sahiptir, iki kitap, birkaç makale ve blog yazmıştır ve çeşitli teknik forumlarda bakış açılarını sunmuştur. Kendisi bir düşünce lideri ve konuşmacıdır ve yaklaşık 25 yıldır sektördedir. Dünyanın dört bir yanındaki Fortune 1000 müşterileriyle ve son olarak Hindistan'daki dijital yerli müşterilerle çalıştı.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/inference-llama-2-models-with-real-time-response-streaming-using-amazon-sagemaker/

