Kuruluşların genellikle olağanüstü bir hızla büyüyen yüksek hacimli verileri yönetmeleri gerekir. Aynı zamanda, zamanında öngörüler elde etmek için bu verilerin değerini açığa çıkarmak ve bunu tutarlı bir performansla gerçekleştirmek amacıyla operasyonel maliyetleri optimize etmeleri gerekiyor.
Bu devasa veri büyümesiyle birlikte, veri depolarınız, veri ambarınız ve veri gölleriniz genelinde veri çoğalması da aynı derecede zorlu hale gelebilir. Birlikte modern veri mimarisi AWS'de hızla ölçeklenebilir veri gölleri oluşturabilirsiniz; amaca yönelik olarak oluşturulmuş geniş ve derin bir veri hizmetleri koleksiyonunu kullanın; birleşik veri erişimi, güvenlik ve yönetişim yoluyla uyumluluğu sağlamak; performanstan ödün vermeden sistemlerinizi düşük maliyetle ölçeklendirin; Verileri kurumsal sınırlar ötesinde kolaylıkla paylaşarak geniş ölçekte hızlı ve çevik bir şekilde kararlar almanıza olanak tanır.
Tüm verilerinizi çeşitli silolardan alabilir, bu verileri veri gölünüzde toplayabilir ve doğrudan bu verilerin üzerinde analiz ve makine öğrenimi (ML) gerçekleştirebilirsiniz. Ayrıca hem yapılandırılmış hem de yapılandırılmamış verileri analiz etmek ve bunlardan hızlı içgörüler elde etmek için diğer verileri amaca yönelik olarak oluşturulmuş veri depolarında saklayabilirsiniz. Bu veri hareketi içeriden dışarıya, dışarıdan içeriye, çevre çevresinde veya karşılıklı paylaşım şeklinde olabilir.
Örneğin, uygulama günlükleri ve web uygulamalarından gelen izler doğrudan bir veri gölünde toplanabilir ve bu verilerin bir kısmı, günlük analiz için Amazon OpenSearch Service gibi bir günlük analizi deposuna taşınabilir. Biz bu kavramı şu şekilde düşünüyoruz: tersyüz veri hareketi. Amazon OpenSearch Service'te depolanan analiz edilmiş ve birleştirilmiş veriler, uygulamalardan aşağı akış tüketimi için ML algoritmalarını çalıştırmak üzere tekrar veri gölüne taşınabilir. Bu kavramı şu şekilde adlandırıyoruz: dıştan içe veri hareketi.
Örnek bir kullanım durumuna bakalım. Örnek Corp., sosyal içerik konusunda uzmanlaşmış lider bir Fortune 500 şirketidir. Günde yaklaşık 500 TB veri ve iz üreten yüzlerce uygulamaya sahiptirler ve aşağıdaki kriterlere sahiptirler:
- Hızlı analiz için günlükleri 2 gün boyunca hazır bulundurun
- 2 günden sonra, verileri makul bir SLA ile analiz için kullanılabilecek bir depolama katmanında bulundurun
- Verileri 1 haftadan uzun bir süre boyunca soğuk depoda 30 gün boyunca saklayın (uyumluluk, denetim ve diğer amaçlar için)
Aşağıdaki bölümlerde benzer kullanım durumlarına yönelik üç olası çözümü tartışıyoruz:
- Amazon OpenSearch Service'te katmanlı depolama ve veri yaşam döngüsü yönetimi
- Günlüklerin isteğe bağlı olarak alınması Amazon Açık Arama Alımı
- Amazon Simple Storage Service (Amazon S3) ile Amazon OpenSearch Service doğrudan sorguları
1. Çözüm: OpenSearch Hizmetinde katmanlı depolama ve veri yaşam döngüsü yönetimi
OpenSearch Hizmeti üç entegre depolama katmanını destekler: sıcak, UltraWarm ve soğuk depolama. Veri saklama, sorgu gecikme süresi ve bütçeleme gereksinimlerinize bağlı olarak maliyet ve performansı dengelemek için en iyi stratejiyi seçebilirsiniz. Verileri farklı depolama katmanları arasında da taşıyabilirsiniz.
Sıcak depolama, indeksleme ve güncelleme için kullanılır ve verilere en hızlı erişimi sağlar. Sıcak depolama, bir örnek deposu biçimini alır veya Amazon Elastik Blok Mağazası (Amazon EBS) birimleri her düğüme eklenir.
UltraWarm, daha az sorguladığınız ve sıcak depolamayla aynı performansı gerektirmeyen salt okunur veriler için GiB başına önemli ölçüde daha düşük maliyetler sunar. UltraWarm düğümleri, performansı artırmak için Amazon S3'ü ilgili önbellekleme çözümleriyle birlikte kullanır.
Soğuk depolama, nadiren erişilen veya geçmiş verileri depolamak için optimize edilmiştir. Soğuk depolamayı kullandığınızda, dizinlerinizi UltraWarm katmanından ayırarak erişilemez hale getirirsiniz. Bu verileri sorgulamanız gerektiğinde bu dizinleri birkaç saniye içinde yeniden ekleyebilirsiniz.
OpenSearch Hizmeti içindeki veri katmanları hakkında daha fazla ayrıntı için bkz. Amazon OpenSearch Hizmetinde ihtiyaçlarınız için doğru depolama katmanını seçin.
Çözüme genel bakış
Bu çözümün iş akışı aşağıdaki adımlardan oluşur:
- Uygulamalar tarafından oluşturulan gelen veriler bir S3 veri gölüne aktarılır.
- Veriler Amazon OpenSearch'e aşağıdakiler kullanılarak alınır: S3-SQS neredeyse gerçek zamanlıya alım S3 paketlerinde ayarlanan bildirimler aracılığıyla.
- 2 gün sonra sıcak veriler, okuma sorgularını desteklemek için UltraWarm depolamaya taşınır.
- UltraWarm'da geçen 5 günün ardından veriler 21 gün boyunca soğuk depolamaya taşınır ve tüm bilgisayarlardan ayrılır. Gerektiğinde veriler UltraWarm'a yeniden eklenebilir. Veriler 21 gün sonra soğuk depodan silinir.
- Kolay geçiş için günlük indeksler korunur. Dizin Durumu Yönetimi (ISM) politikası, 2 günden eski dizinlerin devredilmesini veya silinmesini otomatikleştirir.
Aşağıda, verileri 2 gün sonra UltraWarm katmanına aktaran, 5 gün sonra soğuk depoya taşıyan ve 21 gün sonra soğuk depodan silen örnek bir ISM politikası yer almaktadır:
Hususlar
UltraWarm, nadiren erişilen verilerin sorgulanmasını sağlamak için gelişmiş önbellekleme teknikleri kullanır. Her ne kadar veri erişimi seyrek olsa da, bu erişimi mümkün kılmak için UltraWarm düğümlerine yönelik bilgi işlemin her zaman çalışıyor olması gerekir.
PB ölçeğinde çalışırken, herhangi bir hatanın etki alanını azaltmak için, katmanlı depolamayı kullanırken uygulamayı birden çok OpenSearch Hizmeti etki alanına ayırmanızı öneririz.
Sonraki iki model, uzun süreli hesaplama ihtiyacını ortadan kaldırır ve verilerin ihtiyaç duyulduğunda getirildiği veya doğrudan bulunduğu yerde sorgulandığı isteğe bağlı teknikleri açıklar.
2. Çözüm: Günlük verilerinin OpenSearch Ingestion aracılığıyla isteğe bağlı olarak alınması
OpenSearch Ingestion, OpenSearch Hizmeti etki alanlarına gerçek zamanlı günlük ve izleme verileri sağlayan, tam olarak yönetilen bir veri toplayıcıdır. OpenSearch Ingestion, açık kaynaklı veri toplayıcı tarafından desteklenmektedir Veri Hazırlayıcı. Veri Hazırlayıcı, açık kaynak OpenSearch projesi.
OpenSearch Ingestion ile verilerinizi aşağı yönlü analiz ve görselleştirme için filtreleyebilir, zenginleştirebilir, dönüştürebilir ve sunabilirsiniz. Veri üreticilerinizi OpenSearch Ingestion'a veri gönderecek şekilde yapılandırırsınız. Verileri belirttiğiniz alana veya koleksiyona otomatik olarak iletir. OpenSearch Ingestion'ı verilerinizi teslim etmeden önce dönüştürecek şekilde de yapılandırabilirsiniz. OpenSearch Ingestion sunucusuz olduğundan altyapınızı ölçeklendirme, besleme filonuzu çalıştırma ve yazılımı yamalama veya güncelleme konusunda endişelenmenize gerek yoktur.
OpenSearch Ingestion ile verileri işlemek için Amazon S3'ü kaynak olarak kullanmanın iki yolu vardır. İlk seçenek S3-SQS işlemedir. Dosyaların S3'e yazıldıktan sonra gerçek zamanlıya yakın taranmasını istediğinizde S3-SQS işlemeyi kullanabilirsiniz. Bu bir gerektirir Amazon Basit Kuyruk Hizmeti (Amazon S3) alan kuyruk S3 Etkinlik Bildirimleri. S3 klasörlerini, işlenecek pakette bir nesne depolandığında veya değiştirildiğinde herhangi bir olay oluşturacak şekilde yapılandırabilirsiniz.
Alternatif olarak, bir S3 klasöründeki verileri toplu olarak işlemek için tek seferlik veya yinelenen zamanlanmış taramayı kullanabilirsiniz. Zamanlanmış bir tarama ayarlamak için işlem hattınızı, tüm S3 klasörleriniz için geçerli olan tarama düzeyinde veya klasör düzeyinde bir zamanlamayla yapılandırın. Toplu işleme için zamanlanmış taramaları tek seferlik bir tarama veya yinelenen bir tarama ile yapılandırabilirsiniz.
OpenSearch Beslemesine kapsamlı bir genel bakış için bkz. Amazon Açık Arama Alımı. Data Prepper açık kaynak projesi hakkında daha fazla bilgi için şu adresi ziyaret edin: Veri Hazırlayıcı.
Çözüme genel bakış
Aşağıdaki temel bileşenlere sahip bir mimari modeli sunuyoruz:
- Uygulama günlükleri veri gölüne aktarılır ve bu, OpenSearch Ingestion kullanılarak sıcak verilerin OpenSearch Hizmeti'ne neredeyse gerçek zamanlı olarak beslenmesine yardımcı olur S3-SQS işleme.
- OpenSearch Hizmeti içindeki ISM politikaları, dizin geçişlerini veya silme işlemlerini yönetir. ISM politikaları, bu periyodik yönetim işlemlerini, dizin yaşı, dizin boyutu veya belge sayısındaki değişikliklere göre tetikleyerek otomatikleştirmenize olanak tanır. Örneğin, dizininizi 2 gün sonra salt okunur duruma getiren ve 3 günlük belirli bir süre sonunda silen bir politika tanımlayabilirsiniz.
- OpenSearch Ingestion kullanılarak talep üzerine OpenSearch Hizmetinde tüketilmek üzere S3 veri gölünde soğuk veriler mevcuttur planlanmış taramalar
Aşağıdaki şemada çözüm mimarisi gösterilmektedir.
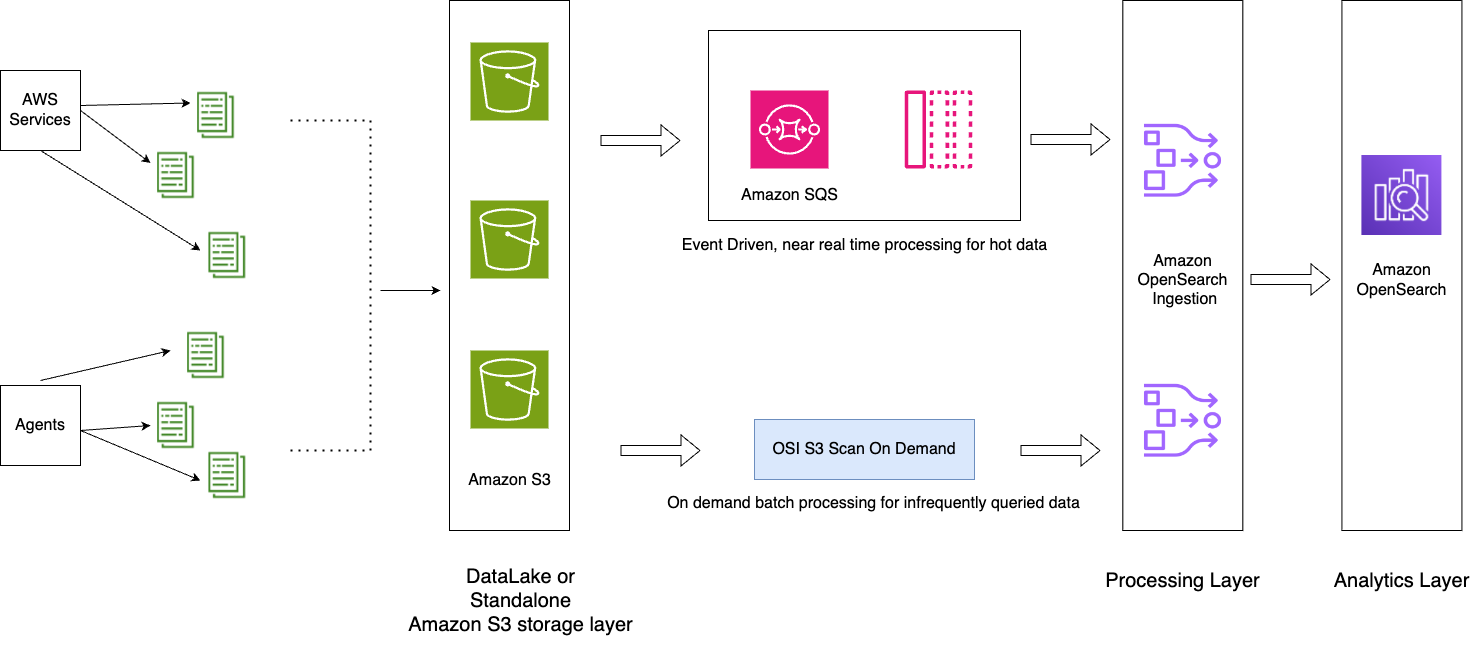
İş akışı aşağıdaki adımları içerir:
- Uygulamalar tarafından oluşturulan gelen veriler S3 veri gölüne aktarılır.
- Geçerli gün için veriler, S3 paketlerinde ayarlanan bildirimler aracılığıyla S3-SQS'nin neredeyse gerçek zamanlı alımı kullanılarak OpenSearch Hizmetine alınır.
- Kolay geçiş için günlük indeksler korunur. ISM politikası, 2 günden eski dizinlerin devredilmesini veya silinmesini otomatikleştirir.
- Verilerin analizi için 2 günü aşan bir talepte bulunulursa ve veriler UltraWarm katmanında değilse veriler, belirli zaman aralığı arasında Amazon S3'ün tek seferlik tarama özelliği kullanılarak alınacaktır.
Örneğin, günümüz 10 Ocak 2024 ise ve analiz için belirli bir aralıktaki 6 Ocak 2024 tarihine ait verilere ihtiyacınız varsa, YAML yapılandırmanızda Amazon S3 taramasıyla bir OpenSearch Ingestion işlem hattı oluşturabilirsiniz. start_time ve end_time paketteki nesnelerin ne zaman taranmasını istediğinizi belirtmek için:
Hususlar
Sıkıştırmanın avantajlarından yararlanın
Amazon S3'teki veriler sıkıştırılabilir, bu da genel veri ayak izinizi azaltır ve önemli ölçüde maliyet tasarrufu sağlar. Örneğin, ayda 15 PB ham JSON uygulama günlüğü oluşturuyorsanız, boyutu yaklaşık 1 PB veya daha aza indirebilen GZIP gibi bir sıkıştırma mekanizması kullanabilirsiniz, bu da önemli ölçüde maliyet tasarrufu sağlar.
Mümkün olduğunda boru hattını durdurun
OpenSearch Ingestion, işlem hattı için ayarlanan minimum ve maksimum OCU'lar arasında otomatik olarak ölçeklenir. İşlem hattı, işlem hattı yapılandırmasında belirtilen süre boyunca Amazon S3 taramasını tamamladıktan sonra işlem hattı, minimum OCU'larda sürekli izleme için çalışmaya devam eder.
Yeni nesnelerin oluşturulmasını beklemediğiniz geçmiş zaman sürelerine yönelik isteğe bağlı besleme için aşağıdakiler gibi desteklenen işlem hattı ölçümlerini kullanmayı düşünün: recordsOut.count oluşturmak için Amazon Bulut İzleme boru hattını durdurabilecek alarmlar. Desteklenen metriklerin listesi için bkz. Boru hattı ölçümlerini izleme.
CloudWatch alarmları, CloudWatch ölçümü belirli bir süre boyunca belirtilen değeri aştığında bir eylem gerçekleştirir. Örneğin, izlemek isteyebilirsiniz recordsOut.count bir istek başlatmak için 0 dakikadan uzun süre 5 olmak boru hattını durdur içinden AWS Komut Satırı Arayüzü (AWS CLI) veya API.
3. Çözüm: Amazon S3 ile OpenSearch Hizmeti doğrudan sorguları
Amazon S3 ile OpenSearch Hizmeti doğrudan sorguları (önizleme) hizmetler arasında geçiş yapmaya gerek kalmadan Amazon S3 ve S3 veri göllerindeki operasyonel günlükleri sorgulamanın yeni bir yoludur. Artık bulut nesne depolarında nadiren sorgulanan verileri analiz edebilir ve aynı anda OpenSearch Hizmetinin operasyonel analitik ve görselleştirme yeteneklerini kullanabilirsiniz.
Amazon S3 ile OpenSearch Service doğrudan sorguları sağlar sıfır ETL entegrasyonu Operasyonel verilerinizi doğrudan sorgulamanıza olanak tanıyarak, verileri kopyalamanın veya birden fazla analiz aracını yönetmenin operasyonel karmaşıklığını azaltmak, maliyetleri ve eyleme geçme süresini azaltmak. Bu sıfır ETL entegrasyonu, önceden tanımlanmış kontrol panelleri de dahil olmak üzere çeşitli günlük türü şablonlarından yararlanabileceğiniz ve bu günlük türüne göre uyarlanmış veri hızlandırmalarını yapılandırabileceğiniz OpenSearch Hizmeti içerisinde yapılandırılabilir. Şablonlar şunları içerir: VPC Akış Günlükleri, Elastik Yük Dengeleme günlükler ve NGINX günlükleri ve hızlandırmalar, atlama dizinlerini, gerçekleştirilmiş görünümleri ve kapsanan dizinleri içerir.
Amazon S3 ile OpenSearch Service doğrudan sorguları sayesinde, güvenlik adli bilişimi ve tehdit analizi açısından kritik olan karmaşık sorguları gerçekleştirebilir ve birden fazla veri kaynağındaki verileri ilişkilendirebilirsiniz; bu, ekiplerin hizmet kesintisi ve güvenlik olaylarını araştırmasına yardımcı olur. Bir entegrasyon oluşturduktan sonra verilerinizi doğrudan OpenSearch Dashboard'lardan veya OpenSearch API'sinden sorgulamaya başlayabilirsiniz. Ölçeklenebilir, uygun maliyetli ve güvenli bir şekilde kurulduklarından emin olmak için bağlantıları denetleyebilirsiniz.
OpenSearch Service'ten Amazon S3'e yapılan doğrudan sorgular, AWS Tutkal Veri Kataloğu. Tablo, AWS Glue meta veri kataloğunuzda kataloglandıktan sonra, OpenSearch Kontrol Panelleri aracılığıyla doğrudan S3 veri gölünüzdeki verileriniz üzerinde sorgular çalıştırabilirsiniz.
Çözüme genel bakış
Aşağıdaki şemada çözüm mimarisi gösterilmektedir.
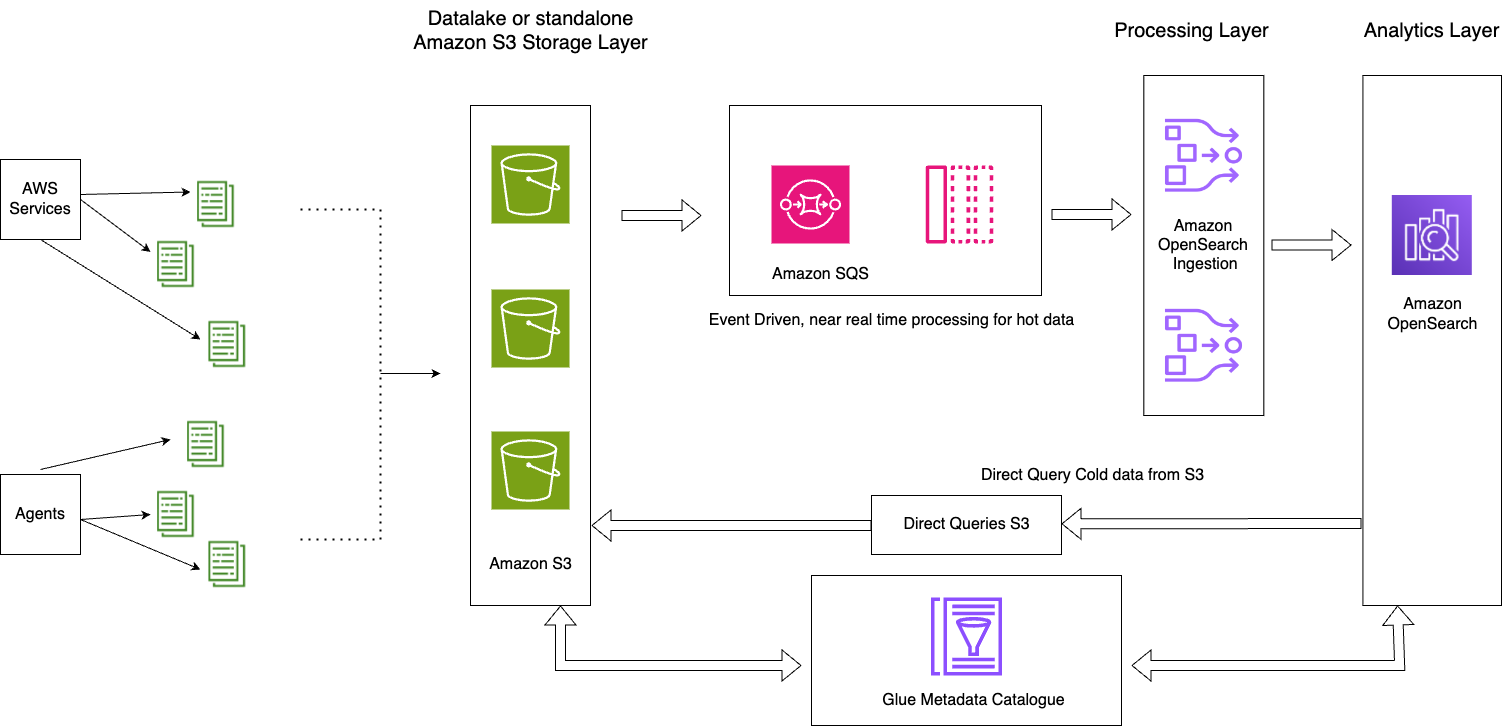
Bu çözüm aşağıdaki temel bileşenlerden oluşur:
- Geçerli günün sıcak verileri, OpenSearch Ingestion S3-SQS işleme özelliği kullanılarak olay odaklı mimari modeli aracılığıyla OpenSearch Hizmeti etki alanlarına akış halinde işlenir
- Sıcak veri yaşam döngüsü, günlük endekslere eklenen ISM politikaları aracılığıyla yönetilir
- Soğuk veriler Amazon S3 klasörünüzde bulunur ve bölümlenmiş ve kataloglanmıştır
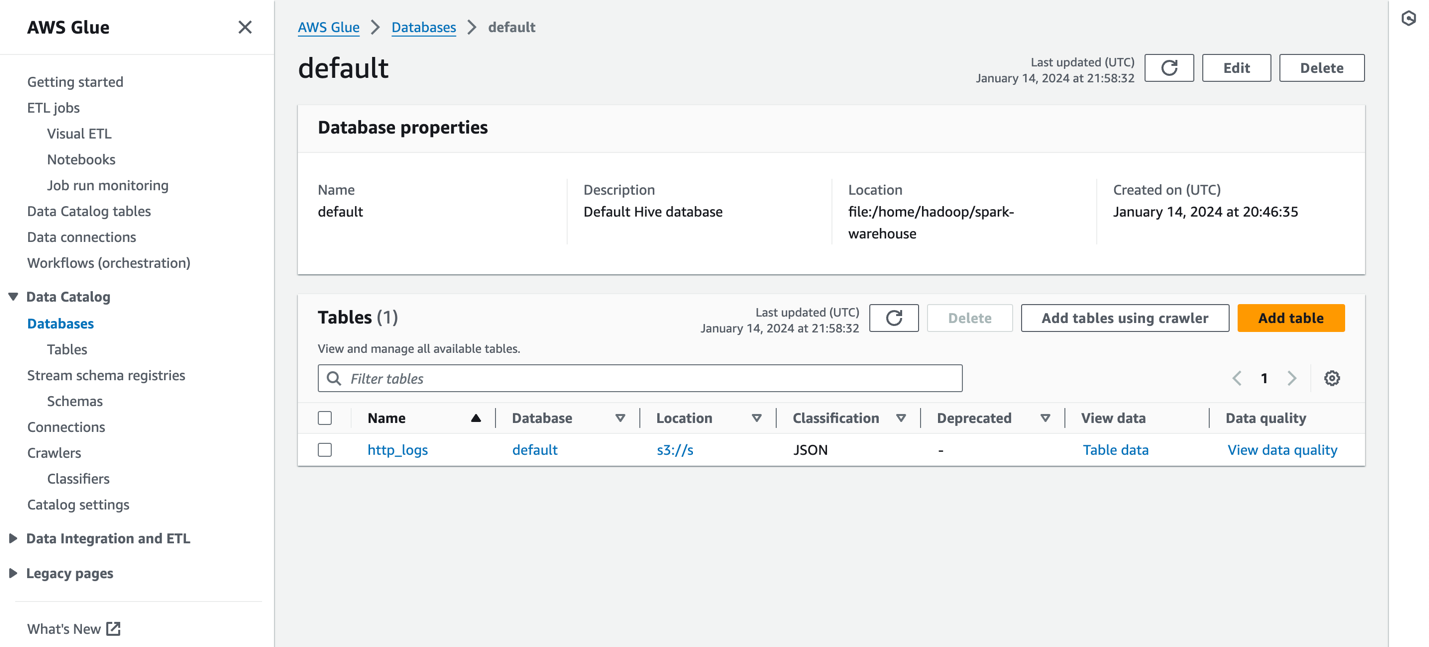
Aşağıdaki ekran görüntüsü bir örneği göstermektedir http_logs AWS Glue meta veri kataloğunda kataloglanan tablo. Ayrıntılı adımlar için bkz. AWS Glue'daki Veri Kataloğu ve tarayıcılar.
Bir veri kaynağı oluşturmadan önce, sürüm 2.11 veya üzeri bir OpenSearch Service etki alanına ve AWS Glue Veri Katalogunda uygun S3 tablosuna sahip bir hedef SXNUMX tablosuna sahip olmanız gerekir. AWS Kimlik ve Erişim Yönetimi (IAM) izinleri. IAM'in istenen S3 klasörlerine erişmesi ve AWS Glue Data Catalog'a okuma ve yazma erişimine sahip olması gerekir. Aşağıda, OpenSearch Hizmeti aracılığıyla AWS Glue Data Catalog'a erişim için uygun izinlere sahip örnek bir rol ve güven politikası yer almaktadır:
Aşağıda Amazon S3 ve AWS Glue erişimine sahip örnek bir özel politika yer almaktadır:
OpenSearch Hizmeti konsolunda yeni bir veri kaynağı oluşturmak için yeni veri kaynağınızın adını girin, veri kaynağı türünü şu şekilde belirtin: AWS Glue Veri Kataloğu ile Amazon S3ve veri kaynağınız için IAM rolünü seçin.
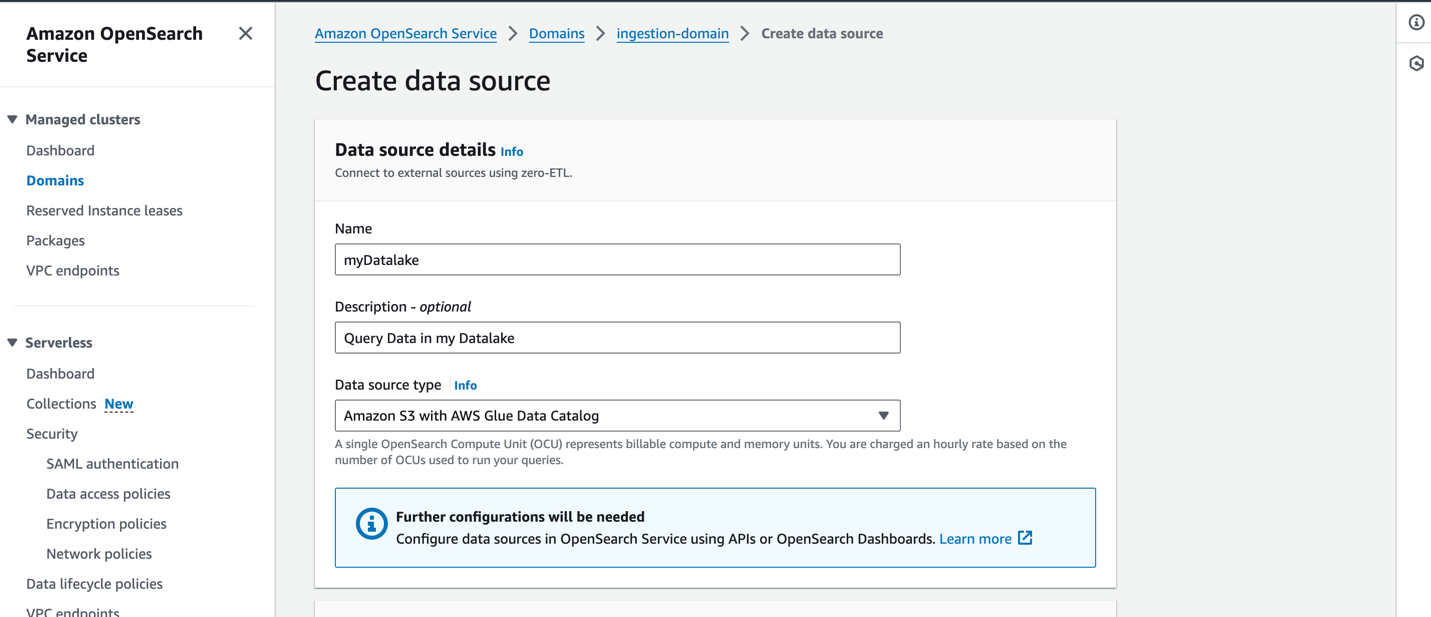
Bir veri kaynağı oluşturduktan sonra erişim kontrolünü yapılandırmak, tabloları tanımlamak, popüler günlük türleri için günlük türüne dayalı kontrol panelleri ayarlamak ve verilerinizi sorgulamak için kullandığınız etki alanının OpenSearch kontrol paneline gidebilirsiniz.

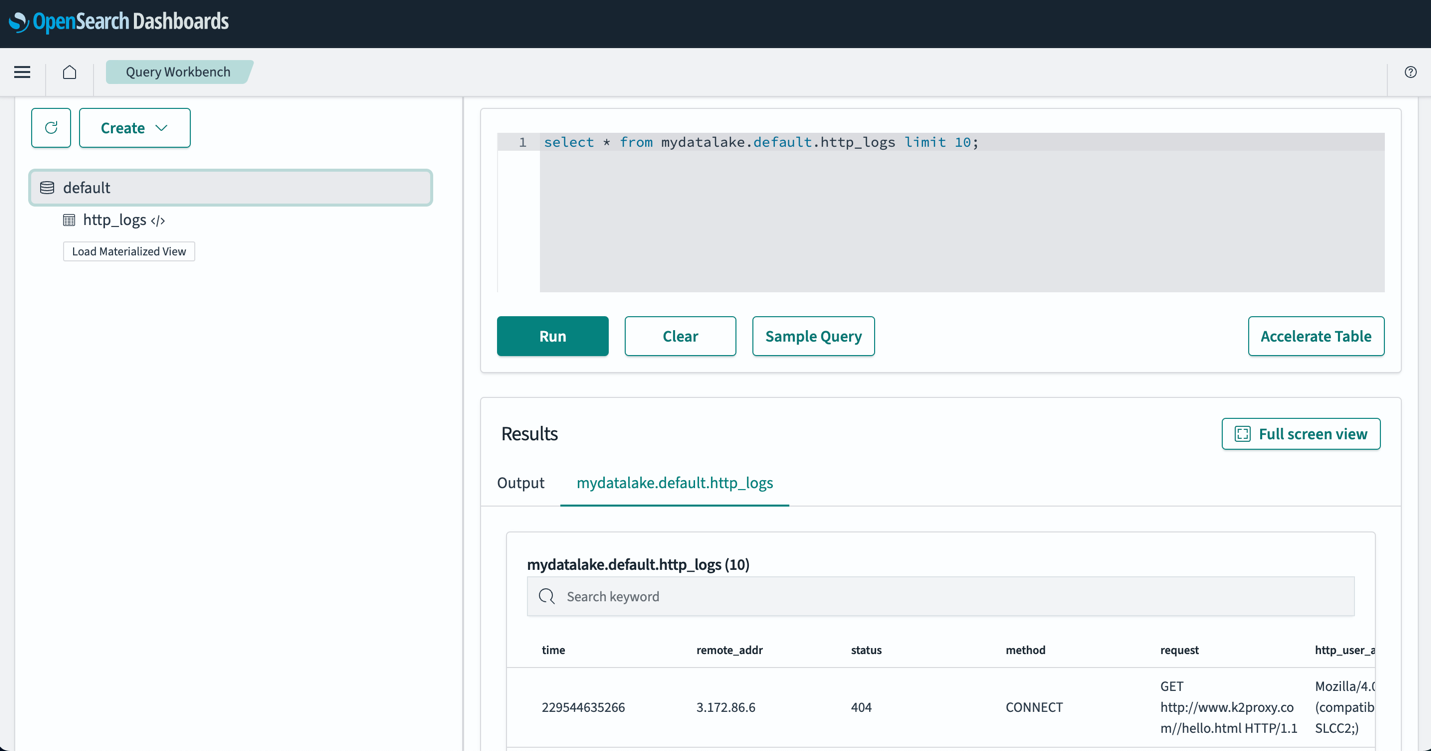
Tablolarınızı ayarladıktan sonra S3 veri gölünüzdeki verilerinizi OpenSearch Kontrol Panelleri aracılığıyla sorgulayabilirsiniz. Örnek bir SQL sorgusu çalıştırabilirsiniz. http_logs Aşağıdaki ekran görüntüsünde gösterildiği gibi AWS Glue Data Catalog tablolarında oluşturduğunuz tablo.
En iyi uygulamalar
Yalnızca ihtiyacınız olan verileri alın
İş gereksinimlerinizden geriye doğru çalışın ve ihtiyaç duyacağınız doğru veri kümelerini oluşturun. Gürültülü verileri almaktan kaçınıp yalnızca seçilmiş, örneklenmiş veya toplanmış verileri alıp alamayacağınızı değerlendirin. Bu temizlenmiş ve seçilmiş veri kümelerini kullanmak, bu verileri almak için gereken işlem ve depolama kaynaklarını optimize etmenize yardımcı olacaktır.
Beslemeden önce veri boyutunu azaltın
Veri alımı işlem hatlarınızı tasarlarken, alınan verilerin boyutunu azaltmak için sıkıştırma, filtreleme ve toplama gibi stratejiler kullanın. Bu, daha küçük veri boyutlarının ağ üzerinden aktarılmasına ve veri katmanınızda saklanmasına olanak tanır.
Sonuç
Bu yazıda, modern bir veri mimarisinde OpenSearch Hizmetini kullanarak petabayt ölçekli günlük analitiğine olanak tanıyan çözümleri tartıştık. Günlükleri bir OpenSearch Hizmeti etki alanına teslim etmek için sunucusuz bir besleme hattı oluşturmayı, ISM politikaları aracılığıyla dizinleri yönetmeyi, OpenSearch Ingestion'ı kullanmaya başlamak için IAM izinlerini yapılandırmayı ve veri gölünüzdeki veriler için ardışık düzen yapılandırmasını nasıl oluşturacağınızı öğrendiniz. Ayrıca veri gölünüzden veri sorgulamak için Amazon S3 özelliği (önizleme) ile OpenSearch Service doğrudan sorgularını nasıl ayarlayıp kullanacağınızı da öğrendiniz.
OpenSearch Hizmetini geniş ölçekte kullanırken iş yükleriniz için doğru mimari modelini seçmek amacıyla doğru kararı vermek amacıyla performansı, gecikmeyi, maliyeti ve zaman içinde veri hacmi artışını göz önünde bulundurun.
- Sıcak verilerinize hızlı erişime ihtiyaç duyduğunuzda ve salt okunur veriler için UltraWarm düğümleriyle maliyet ve performansı dengelemek istediğinizde Dizin Durumu Yönetimi ilkeleriyle Katmanlı depolama mimarisini kullanın.
- Etkin düğümlerinizde tutulmayan verilerinizi sorgulamak için alma gecikmelerini tolere edebildiğinizde, verilerinizin OpenSearch Hizmetine İsteğe Bağlı Aktarımı'nı kullanın. Amazon S3'te sıkıştırılmış verileri kullanırken ve isteğe bağlı verileri OpenSearch Hizmetine aktarırken önemli ölçüde maliyet tasarrufu elde edebilirsiniz.
- OpenSearch Hizmetinin zengin analiz ve görselleştirme özellikleriyle Amazon S3'teki operasyonel günlüklerinizi doğrudan analiz etmek istediğinizde S3 ile Doğrudan sorgulama özelliğini kullanın.
Bir sonraki adım olarak, bkz. Amazon OpenSearch Geliştirici Kılavuzu kurumsal uygulamalarınız için ölçeklenebilir bir gözlemlenebilirlik çözümü oluşturmak için kullanabileceğiniz günlükleri ve ölçüm ardışık düzenlerini keşfetmek için.
Yazarlar Hakkında
 Jagadish Kumar (Jag) AWS'de Amazon OpenSearch Hizmetine odaklanan Kıdemli Uzman Çözüm Mimarıdır. Veri Mimarisi konusunda derin bir tutkuya sahiptir ve müşterilerin AWS'de geniş ölçekte analiz çözümleri oluşturmasına yardımcı olur.
Jagadish Kumar (Jag) AWS'de Amazon OpenSearch Hizmetine odaklanan Kıdemli Uzman Çözüm Mimarıdır. Veri Mimarisi konusunda derin bir tutkuya sahiptir ve müşterilerin AWS'de geniş ölçekte analiz çözümleri oluşturmasına yardımcı olur.
 Muthu Pitchaimani Amazon OpenSearch Hizmetinde Kıdemli Uzman Çözüm Mimarıdır. Büyük ölçekli arama uygulamaları ve çözümleri geliştiriyor. Muthu ağ oluşturma ve güvenlik konularıyla ilgileniyor ve Austin, Teksas'ta yaşıyor.
Muthu Pitchaimani Amazon OpenSearch Hizmetinde Kıdemli Uzman Çözüm Mimarıdır. Büyük ölçekli arama uygulamaları ve çözümleri geliştiriyor. Muthu ağ oluşturma ve güvenlik konularıyla ilgileniyor ve Austin, Teksas'ta yaşıyor.
 Sam Selvan Amazon OpenSearch Hizmetinde Baş Uzman Çözüm Mimarıdır.
Sam Selvan Amazon OpenSearch Hizmetinde Baş Uzman Çözüm Mimarıdır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/petabyte-scale-log-analytics-with-amazon-s3-amazon-opensearch-service-and-amazon-opensearch-ingestion/

