Birçok kuruluş şirket içi veri depolarını AWS Cloud'a taşıyor. Veri geçişi sırasında temel gereksinim, kaynaktan hedefe taşınan tüm verilerin doğrulanmasıdır. Bu veri doğrulaması kritik bir adımdır ve doğru şekilde yapılmazsa tüm projenin başarısız olmasına neden olabilir. Ancak, kaynak ve hedef arasındaki verileri karşılaştırarak geçişin doğruluğunu belirlemek için özel çözümler geliştirmek çoğu zaman zaman alıcı olabilir.
Bu yazıda, büyük veri kümelerini geçişten sonra yapılandırma tabanlı bir araç kullanarak doğrulamak için adım adım bir süreçten geçiyoruz. Amazon EMR'si ve Apache Griffin açık kaynak kitaplığı. Griffin, büyük veriler için hem toplu hem de akış modunu destekleyen açık kaynaklı bir veri kalitesi çözümüdür.
Kuruluşların petabaytlarca veriyle uğraştığı günümüzün veri odaklı ortamında, otomatik veri doğrulama çerçevelerine olan ihtiyaç giderek daha kritik hale geldi. Manuel doğrulama süreçleri yalnızca zaman alıcı olmakla kalmaz, aynı zamanda özellikle büyük hacimli verilerle uğraşırken hatalara da açıktır. Otomatik veri doğrulama çerçeveleri, büyük veri kümelerini verimli bir şekilde karşılaştırarak, tutarsızlıkları belirleyerek ve geniş ölçekte veri doğruluğunu sağlayarak kolaylaştırılmış bir çözüm sunar. Bu tür çerçevelerle kuruluşlar, verilerinin bütünlüğüne olan güveni korurken değerli zaman ve kaynaklardan tasarruf edebilir, böylece bilinçli karar alma olanağı sağlayabilir ve genel operasyonel verimliliği artırabilir.
Bu çerçevenin öne çıkan özellikleri şunlardır:
- Yapılandırma odaklı bir çerçeve kullanır
- Sorunsuz entegrasyon için tak ve çalıştır işlevselliği sunar
- Herhangi bir eşitsizliği belirlemek için sayım karşılaştırması yapar
- Güçlü veri doğrulama prosedürlerini uygular
- Sistematik kontroller yoluyla veri kalitesini sağlar
- Ayrıntılı analiz için eşleşmeyen kayıtları içeren bir dosyaya erişim sağlar
- Analizler ve izleme amaçları için kapsamlı raporlar oluşturur
Çözüme genel bakış
Bu çözüm aşağıdaki hizmetleri kullanır:
- Amazon Basit Depolama Hizmeti Kaynak ve hedef olarak (Amazon S3) veya Hadoop Dağıtılmış Dosya Sistemini (HDFS).
- Amazon EMR'si PySpark betiğini çalıştırmak için. HDFS veya Amazon S3 üzerinden oluşturulan Hadoop tabloları arasındaki verileri doğrulamak için Griffin'in üzerinde bir Python sarmalayıcı kullanıyoruz.
- AWS Tutkal Griffin işinin sonuçlarını saklayan teknik tabloyu kataloglamak için.
- Amazon Atina Sonuçları doğrulamak için çıktı tablosunu sorgulamak için.
Her kaynak ve hedef tablonun sayısını saklayan tablolar kullanıyoruz ve ayrıca kaynak ve hedef arasındaki kayıt farkını gösteren dosyalar oluşturuyoruz.
Aşağıdaki şemada çözüm mimarisi gösterilmektedir.
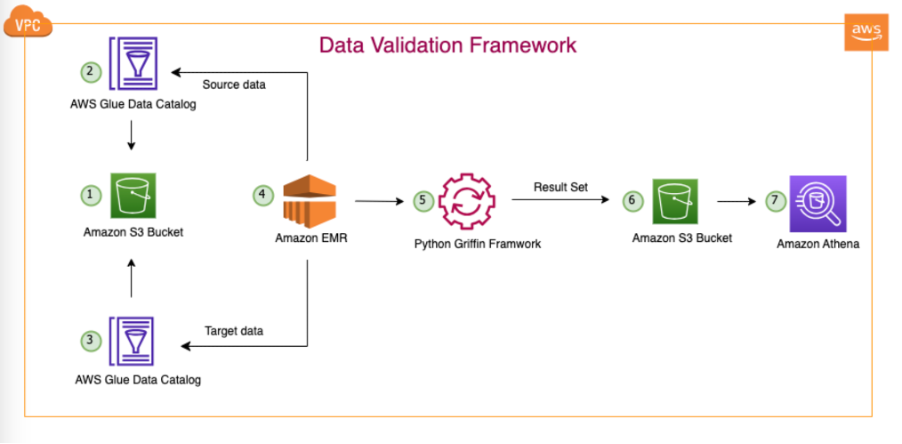
Gösterilen mimaride ve tipik veri gölü kullanım örneğimizde verilerimiz ya Amazon S3'te bulunur ya da aşağıdaki gibi çoğaltma araçları kullanılarak şirket içinden Amazon S3'e taşınır. AWS Veri Eşzamanlama or AWS Veritabanı Geçiş Hizmeti (AWS DMS). Bu çözüm, hem Hive Metastore hem de AWS Glue Veri Kataloğu ile sorunsuz bir şekilde etkileşim kuracak şekilde tasarlanmış olsa da, bu yazıda örnek olarak Veri Kataloğu'nu kullanıyoruz.
Bu çerçeve, Amazon EMR içerisinde çalışarak, planlanan görevleri günlük olarak tanımlanan sıklığa göre otomatik olarak çalıştırır. Amazon S3'te raporlar oluşturup yayınlıyor ve bu raporlara daha sonra Athena aracılığıyla erişilebiliyor. Bu çerçevenin dikkate değer bir özelliği, Amazon S3'te eşleşmeyen tam kayıtları içeren bir dosya oluşturmanın yanı sıra sayım uyuşmazlıklarını ve veri tutarsızlıklarını tespit etme yeteneğidir ve bu da daha fazla analiz yapılmasını kolaylaştırır.
Bu örnekte, kaynak ve hedef arasında doğrulama yapmak için şirket içi veritabanındaki üç tabloyu kullanıyoruz: balance_sheet, covid, ve survery_financial_report.
Önkoşullar
Başlamadan önce, aşağıdaki ön koşullara sahip olduğunuzdan emin olun:
Çözümü dağıtın
Başlamanızı kolaylaştırmak için çözümü sizin için otomatik olarak yapılandıran ve dağıtan bir CloudFormation şablonu oluşturduk. Aşağıdaki adımları tamamlayın:
- AWS hesabınızda adında bir S3 grubu oluşturun
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}(AWS hesap kimliğinizi ve AWS Bölgenizi belirtin). - Aşağıdakileri açın dosya yerel sisteminize.
- Dosyayı yerel sisteminize çıkardıktan sonra değiştirin hesabınızda oluşturduğunuz kişiye (
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}) aşağıdaki dosyalarda:bootstrap-bdb-3070-datavalidation.shValidation_Metrics_Athena_tables.hqldatavalidation/totalcount/totalcount_input.txtdatavalidation/accuracy/accuracy_input.txt
- Yerel klasörünüzdeki tüm klasörleri ve dosyaları S3 klasörünüze yükleyin:
- Aşağıdakileri çalıştırın CloudFormation şablonu izin verir.
CloudFormation şablonu adlı bir veritabanı oluşturur. griffin_datavalidation_blog ve bir AWS Glue tarayıcısı çağrıldı griffin_data_validation_blog .zip dosyasındaki veri klasörünün üstünde.
- Klinik Sonraki.
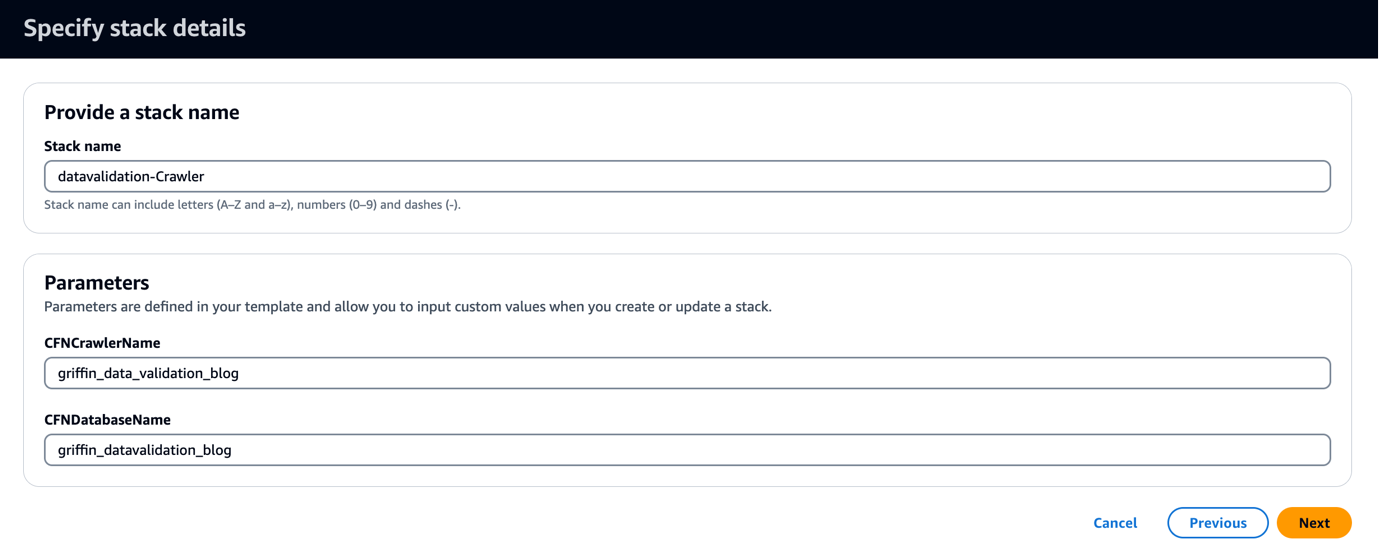
- Klinik Sonraki tekrar.
- Üzerinde Değerlendirme sayfa seç AWS CloudFormation'ın özel adlarla IAM kaynakları oluşturabileceğini kabul ediyorum.
- Klinik Yığın oluştur.
Yapabilirsin yığın çıktılarını görüntüle üzerinde AWS Yönetim Konsolu veya aşağıdaki AWS CLI komutunu kullanarak:
- AWS Glue tarayıcısını çalıştırın ve Veri Kataloğunda altı tablonun oluşturulduğunu doğrulayın.
- Aşağıdakileri çalıştırın CloudFormation şablonu izin verir.
Bu şablon, Griffin ile ilgili JAR'ları ve yapıtları kopyalamak için bir önyükleme komut dosyası içeren bir EMR kümesi oluşturur. Ayrıca üç EMR adımını da çalıştırır:
- Griffin çerçevesi tarafından üretilen doğrulama matrisini görmek için iki Athena tablosu ve iki Athena görünümü oluşturun
- Kaynak ve hedef tabloyu karşılaştırmak için üç tablonun tümü için sayım doğrulamasını çalıştırın
- Kaynak ve hedef tablo arasında karşılaştırma yapmak üzere üç tablonun tamamı için kayıt düzeyinde ve sütun düzeyinde doğrulamalar çalıştırın
- İçin Alt ağ kimliği, alt ağ kimliğinizi girin.
- Klinik Sonraki.
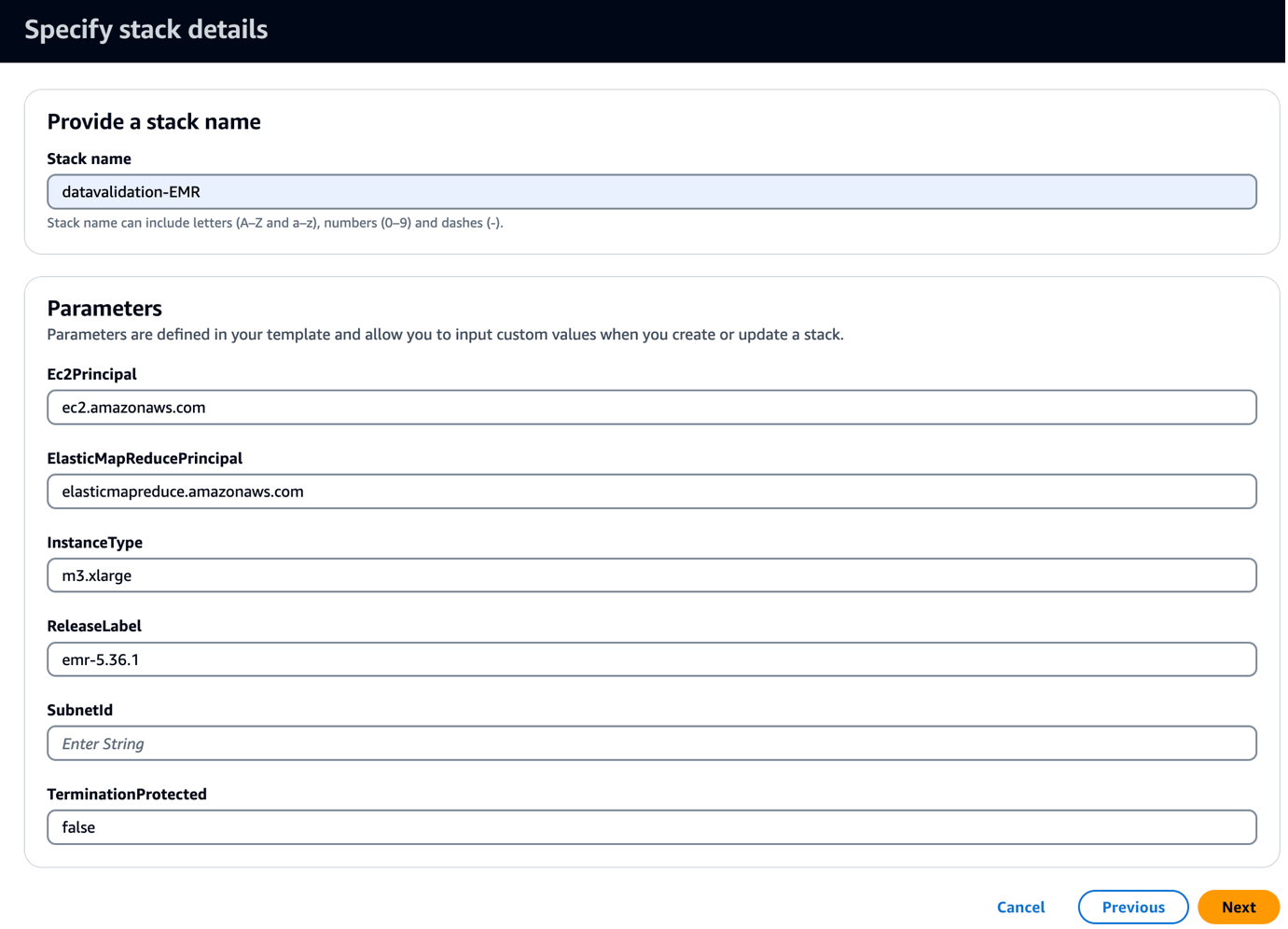
- Klinik Sonraki tekrar.
- Üzerinde Değerlendirme sayfa seç AWS CloudFormation'ın özel adlarla IAM kaynakları oluşturabileceğini kabul ediyorum.
- Klinik Yığın oluştur.
Yığın çıktılarını konsolda veya aşağıdaki AWS CLI komutunu kullanarak görüntüleyebilirsiniz:
Dağıtımın tamamlanması yaklaşık 5 dakika sürer. Yığın tamamlandığında şunu görmelisiniz: EMRCluster kaynak başlatıldı ve hesabınızda mevcut.
EMR kümesi başlatıldığında, küme sonrası başlatmanın bir parçası olarak aşağıdaki adımları çalıştırır:
- Önyükleme eylemi – Bu çerçeveye ait Griffin JAR dosyasını ve dizinlerini kurar. Ayrıca bir sonraki adımda kullanılacak örnek veri dosyalarını da indirir.
- Athena_Table_Creation – Sonuç raporlarını okumak için Athena’da tablolar oluşturur.
- Count_Validation – Veri Kataloğu tablosundaki kaynak ve hedef veriler arasındaki veri sayısını karşılaştırmak için işi çalıştırır ve sonuçları, bir Athena tablosu aracılığıyla okunacak olan bir S3 klasöründe saklar.
- doğruluk – Veri Kataloğu tablosundaki kaynak ve hedef veriler arasındaki veri satırlarını karşılaştırmak ve sonuçları Athena tablosu aracılığıyla okunacak bir S3 klasöründe depolamak için işi çalıştırır.
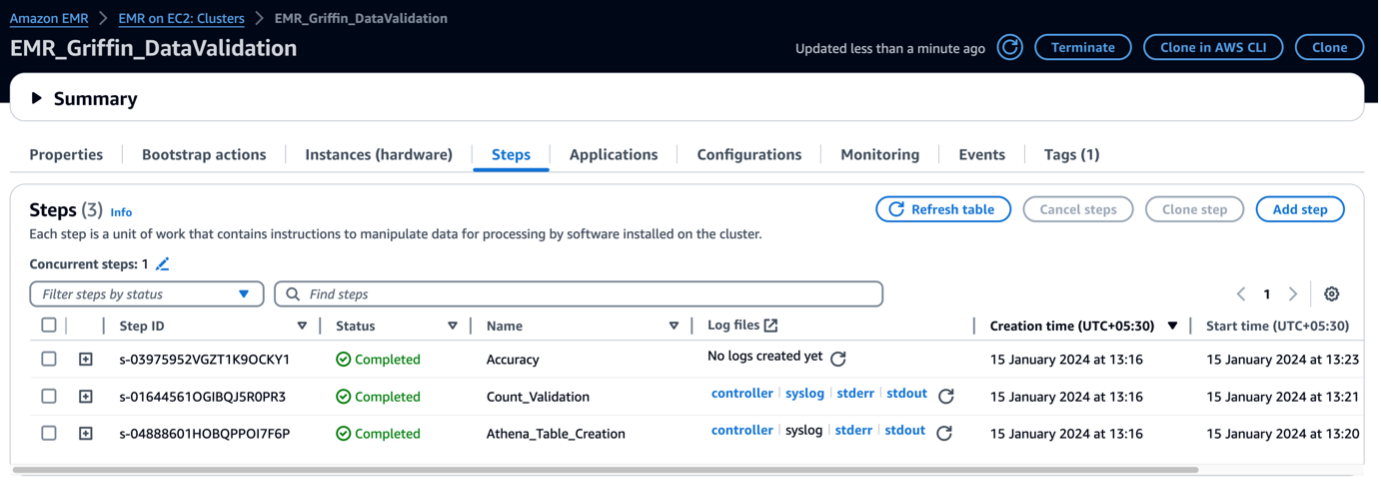
EMR adımları tamamlandığında tablo karşılaştırmanız otomatik olarak yapılır ve Athena'da görüntülenmeye hazır hale gelir. Doğrulama için manuel müdahaleye gerek yoktur.
Verileri Python Griffin ile doğrulama
EMR kümeniz hazır olduğunda ve tüm işler tamamlandığında, sayım doğrulaması ve veri doğrulaması tamamlanmış demektir. Sonuçlar Amazon S3'te saklandı ve bunun üzerine Athena tablosu zaten oluşturuldu. Aşağıdaki ekran görüntüsünde gösterildiği gibi sonuçları görüntülemek için Athena tablolarını sorgulayabilirsiniz.
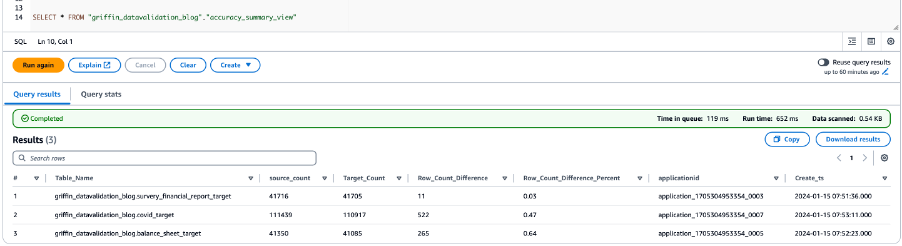
Aşağıdaki ekran görüntüsü tüm tablolara ilişkin sayım sonuçlarını göstermektedir.
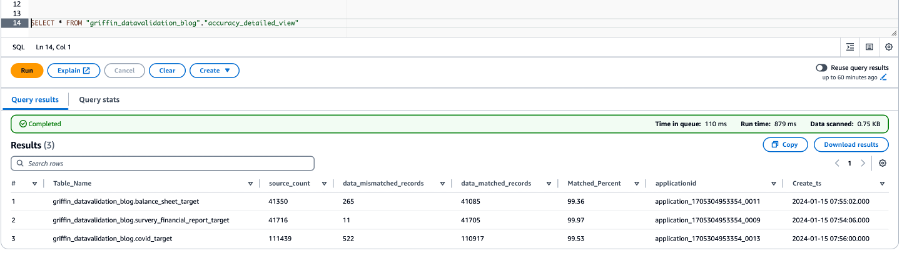
Aşağıdaki ekran görüntüsü tüm tablolar için veri doğruluğu sonuçlarını göstermektedir.
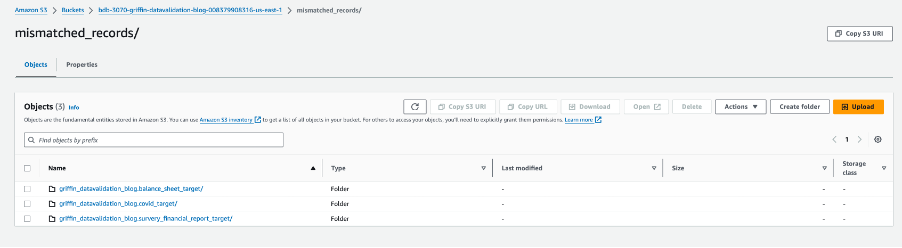
Aşağıdaki ekran görüntüsü, eşleşmeyen kayıtlara sahip her tablo için oluşturulan dosyaları göstermektedir. Her tablo için doğrudan işten ayrı klasörler oluşturulur.
Her tablo klasörü işin çalıştırıldığı her gün için bir dizin içerir.
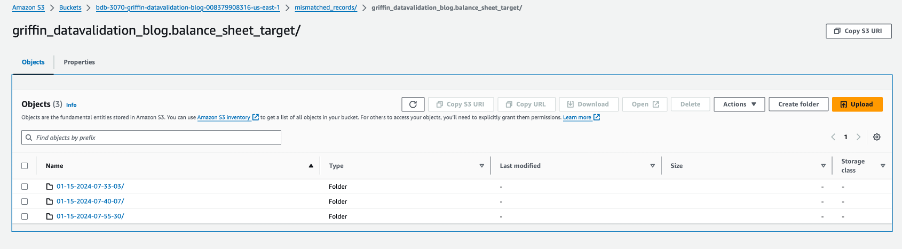
Bu belirli tarih içinde, adlı bir dosya __missRecords eşleşmeyen kayıtları içerir.

Aşağıdaki ekran görüntüsü içeriği göstermektedir. __missRecords dosyası.

Temizlemek
Ek ücret ödemenizi önlemek amacıyla, çözümle işiniz bittiğinde kaynaklarınızı temizlemek üzere aşağıdaki adımları tamamlayın:
- AWS Glue veritabanını silin
griffin_datavalidation_blogve veritabanını bırakgriffin_datavalidation_blogÇağlayan. - Paketten oluşturduğunuz önekleri ve nesneleri silin
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}. - Ek kaynaklarınızı kaldıran CloudFormation yığınını silin.
Sonuç
Bu gönderi, geçiş sonrası veri doğrulama sürecini hızlandırmak için Python Griffin'i nasıl kullanabileceğinizi gösterdi. Python Griffin, herhangi bir kod yazmadan eşleşmeyen kayıtları belirleyerek sayım ve satır ve sütun düzeyinde doğrulamayı hesaplamanıza yardımcı olur.
Veri kalitesi kullanım durumları hakkında daha fazla bilgi için bkz. AWS Glue Data Catalog'dan AWS Glue Data Quality'ye Başlarken ve AWS Glue Veri Kalitesi.
Yazarlar Hakkında
 Dipal Mahajan Amazon Web Services'te Baş Danışman olarak görev yapmakta ve küresel müşterilere son derece güvenli, ölçeklenebilir, güvenilir ve uygun maliyetli bulut uygulamaları geliştirme konusunda uzman rehberliği sağlamaktadır. Finans, telekomünikasyon, perakende ve sağlık gibi farklı sektörlerdeki yazılım geliştirme, mimari ve analitik alanlarındaki zengin deneyimiyle görevine paha biçilmez bilgiler katıyor. Profesyonel alanın ötesinde, istek listesindeki 14 ülkeden 30'ünü ziyaret eden Dipal, yeni destinasyonlar keşfetmekten hoşlanıyor.
Dipal Mahajan Amazon Web Services'te Baş Danışman olarak görev yapmakta ve küresel müşterilere son derece güvenli, ölçeklenebilir, güvenilir ve uygun maliyetli bulut uygulamaları geliştirme konusunda uzman rehberliği sağlamaktadır. Finans, telekomünikasyon, perakende ve sağlık gibi farklı sektörlerdeki yazılım geliştirme, mimari ve analitik alanlarındaki zengin deneyimiyle görevine paha biçilmez bilgiler katıyor. Profesyonel alanın ötesinde, istek listesindeki 14 ülkeden 30'ünü ziyaret eden Dipal, yeni destinasyonlar keşfetmekten hoşlanıyor.
 Akhil AWS Profesyonel Hizmetler'de Baş Danışmandır. Müşterilerin ölçeklenebilir veri analitiği çözümleri tasarlamasına ve oluşturmasına, veri işlem hatlarını ve veri ambarlarını AWS'ye taşımasına yardımcı olur. Boş zamanlarında seyahat etmeyi, oyun oynamayı ve film izlemeyi seviyor.
Akhil AWS Profesyonel Hizmetler'de Baş Danışmandır. Müşterilerin ölçeklenebilir veri analitiği çözümleri tasarlamasına ve oluşturmasına, veri işlem hatlarını ve veri ambarlarını AWS'ye taşımasına yardımcı olur. Boş zamanlarında seyahat etmeyi, oyun oynamayı ve film izlemeyi seviyor.
 Ramesh Raghupathy AWS'de WWCO ProServe ile Kıdemli Veri Mimarıdır. AWS Bulut üzerindeki veri ambarlarını ve veri göllerini tasarlamak, dağıtmak ve bunlara geçiş yapmak için AWS müşterileriyle birlikte çalışır. Ramesh, işte olmadığı zamanlarda seyahat etmekten, ailesiyle vakit geçirmekten ve yoga yapmaktan hoşlanır.
Ramesh Raghupathy AWS'de WWCO ProServe ile Kıdemli Veri Mimarıdır. AWS Bulut üzerindeki veri ambarlarını ve veri göllerini tasarlamak, dağıtmak ve bunlara geçiş yapmak için AWS müşterileriyle birlikte çalışır. Ramesh, işte olmadığı zamanlarda seyahat etmekten, ailesiyle vakit geçirmekten ve yoga yapmaktan hoşlanır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/automate-large-scale-data-validation-using-amazon-emr-and-apache-griffin/

