Introductie
Op het gebied van big data en geavanceerde analyses is PySpark uitgegroeid tot een krachtig hulpmiddel voor het verwerken van grote datasets en het analyseren van gedistribueerde gegevens. Het implementeren van PySpark op AWS-applicaties in de cloud kan een gamechanger zijn en schaalbaarheid en flexibiliteit bieden voor data-intensieve taken. Amazon Web Services (AWS) biedt een ideaal platform voor dergelijke implementaties, en in combinatie met Docker-containers wordt het een naadloze en efficiënte oplossing.

Het implementeren van PySpark op een cloudinfrastructuur kan echter complex en intimiderend zijn. De complexiteit van het opzetten van een gedistribueerde computeromgeving, het configureren van Spark-clusters en het beheren van bronnen weerhoudt velen er vaak van om hun volledige potentieel te benutten.
leerdoelen
- Leer de fundamentele concepten van PySpark, AWS en Docker en zorg voor een solide basis voor de implementatie van PySpark-clusters in de cloud.
- Volg een uitgebreide, stapsgewijze handleiding om PySpark op AWS in te stellen met behulp van Docker, inclusief het configureren van AWS, het voorbereiden van Docker-images en het beheren van Spark-clusters.
- Ontdek strategieën voor het optimaliseren van de PySpark-prestaties op AWS, inclusief monitoring, schaling en het naleven van best practices om het meeste uit uw gegevensverwerkingsworkflows te halen.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.

Voorwaarden
Voordat u aan de reis begint om PySpark op AWS te implementeren met behulp van Docker, moet u ervoor zorgen dat u aan de volgende vereisten voldoet:
🚀 Lokale PySpark-installatie: Om PySpark-applicaties te ontwikkelen en te testen, is het essentieel dat PySpark op uw lokale computer is geïnstalleerd. U kunt PySpark installeren door de officiële documentatie voor uw besturingssysteem te volgen. Deze lokale installatie zal dienen als uw ontwikkelomgeving, zodat u PySpark-code kunt schrijven en testen voordat u deze op AWS implementeert.
🌐 AWS-account: U hebt een actief AWS-account (Amazon Web Services) nodig om toegang te krijgen tot de cloudinfrastructuur en -services die nodig zijn voor de implementatie van PySpark. U kunt zich aanmelden op de AWS-website als u geen AWS-account heeft. Wees voorbereid op het verstrekken van uw betalingsgegevens, hoewel AWS een gratis laag biedt met beperkte middelen voor nieuwe gebruikers.
🐳 Docker-installatie: Docker is een cruciaal onderdeel in dit implementatieproces. Installeer Docker op uw lokale computer door de installatie-instructies voor het Ubuntu-besturingssysteem te volgen. Met Docker-containers kunt u uw PySpark-applicaties consistent inkapselen en implementeren.
Dakramen en raamkozijnen
- Bezoek de
- Download de Docker Desktop voor Windows installateur.
- Dubbelklik op het installatieprogramma om het uit te voeren.
- Volg de instructies van de installatiewizard.
- Eenmaal geïnstalleerd, start u Docker Desktop vanuit uw applicaties.
macOS
- Ga naar de
- Download de Docker Desktop voor Mac installateur.
- Dubbelklik op het installatieprogramma om het te openen.
- Sleep het Docker-pictogram naar uw map Programma's.
- Start Docker vanuit uw applicaties.
Linux (Ubuntu)
1. Open uw terminal en update uw pakketbeheerder:
sudo apt-get update2. Installeer de benodigde afhankelijkheden:
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common3. Voeg de officiële GPG-sleutel van Docker toe:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg4. Stel de Docker-repository in:
echo "deb [signed-by=/usr/share/keyrings/docker-archive-keyring.gpg]
https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null5. Update uw pakketindex opnieuw:
sudo apt-get update6. Docker installeren:
sudo apt-get install -y docker-ce docker-ce-cli containerd.io7. Start en schakel de Docker-service in:
sudo systemctl start docker
sudo systemctl enable docker8. Controleer de installatie:
sudo docker --version**** Voeg gesplitste regels toe op één regel
Bekijk een video-tutorial over de Docker-installatie
AWS instellen
Amazon Web Services (AWS) vormt de ruggengraat van onze PySpark-implementatie en we zullen twee essentiële services gebruiken, Elastic Container Registry (ECR) en Elastic Compute Cloud (EC2), om een dynamische cloudomgeving te creëren.
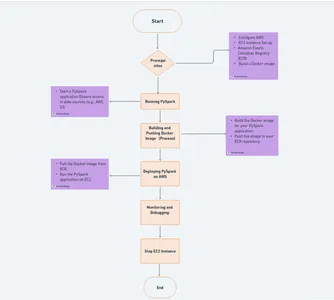
AWS-accountregistratie
Als je dat nog niet hebt gedaan, ga dan naar de AWS-aanmeldingspagina om een account aan te maken. Volg het registratieproces, geef de nodige informatie op en houd uw betalingsgegevens bij de hand als u verder wilt gaan dan de AWS Free Tier.
AWS-vrije laag
Voor degenen die nieuw zijn bij AWS: profiteer van de AWS Free Tier, die gedurende 12 maanden gratis beperkte middelen en diensten biedt. Dit is een uitstekende manier om AWS te verkennen zonder dat er kosten aan verbonden zijn.
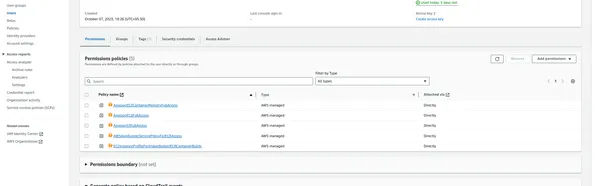
AWS-toegangssleutel en geheime sleutel
U hebt een Access Key ID en Secret Access Key nodig om programmatisch met AWS te kunnen communiceren. Volg deze stappen om ze te genereren:
- Meld u aan bij de AWS-beheerconsole.
- Navigeer naar de dienst Identity & Access Management (IAM).
- Klik op “Gebruikers” in het linkernavigatievenster.
- Maak een nieuwe gebruiker aan of selecteer een bestaande.
- Genereer op het tabblad 'Beveiligingsgegevens' een toegangssleutel.
- Noteer de toegangssleutel-ID en de geheime toegangssleutel, aangezien we deze later zullen gebruiken
- Na klik op gebruiker
Elastisch containerregister (ECR)
ECR is een beheerde Docker-containerregistratieservice die wordt aangeboden door AWS. Het wordt onze opslagplaats voor het opslaan van Docker-images. U kunt uw ECR instellen door deze stappen te volgen:
- Navigeer in de AWS Management Console naar de Amazon ECR-service.
- Maak een nieuwe repository aan, geef deze een naam en configureer de repository-instellingen.
- Noteer de URI van uw ECR-repository; je hebt het nodig voor Docker-image-pushs.
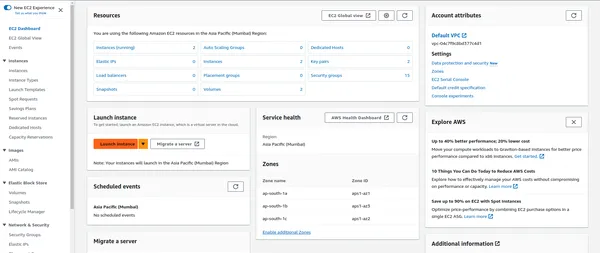
Elastische rekencloud (EC2)
EC2 biedt schaalbare rekencapaciteit in de cloud en host uw PySpark-applicaties. Een EC2-instantie instellen:
- Navigeer in de AWS Management Console naar de EC2-service.
- Start een nieuw EC2-exemplaar en kies het exemplaartype dat bij uw werklast past.
- Configureer de exemplaardetails en opslagopties.
- Maak of selecteer een bestaand sleutelpaar om veilig verbinding te maken met uw EC2-instantie.
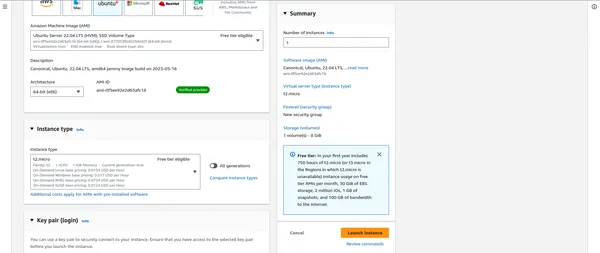
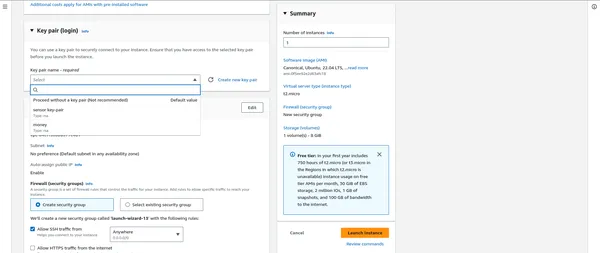
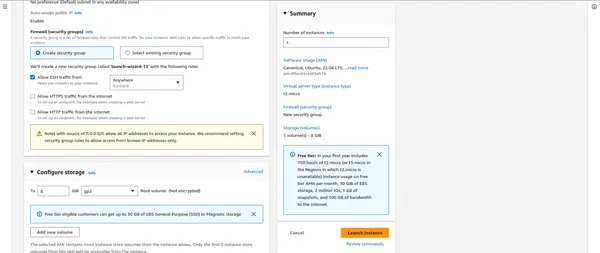
“””” HIER BELANGRIJK NA DAT BEVESTIG DE BEVEILIGINGSGROEPEN “”””
Uw AWS-installatiewaarden opslaan voor toekomstig gebruik
AWS_ACCESS_KEY_ID: AKIAYOURSAMPLEACCESSKEY
AWS_ECR_LOGIN_URI: 123456789012.dkr.ecr.region.amazonaws.com
AWS_REGION: us-east-1
AWS_SECRET_ACCESS_KEY: YOURSAMPLESECRETACCESSKEY12345
ECR_REPOSITORY_NAME: your-ecr-repository-nameGitHub-geheimen en variabelen instellen
Nu u uw AWS-installatiewaarden gereed heeft, is het tijd om ze veilig te configureren in uw GitHub-repository met behulp van GitHub-geheimen en -variabelen. Dit voegt een extra beveiligingslaag en gemak toe aan uw PySpark-implementatieproces.
Volg deze stappen om uw AWS-waarden in te stellen:
Toegang tot uw GitHub-opslagplaats
- U kunt gewoon naar uw GitHub-repository navigeren, waar u uw PySpark-project host.
Toegang tot opslagplaatsinstellingen
- Klik in uw repository op het tabblad "Instellingen".
Geheimenbeheer
- In de linkerzijbalk vindt u een optie genaamd 'Geheimen'. Klik erop om toegang te krijgen tot de GitHub-geheimenbeheerinterface.
Voeg een nieuw geheim toe
- Hier kunt u uw AWS-installatiewaarden als geheimen toevoegen.
- Klik op “Nieuw repositorygeheim” om een nieuw geheim aan te maken.
- Maak voor elke AWS-waarde een geheim aan met een naam die overeenkomt met het doel van de waarde (bijvoorbeeld “AWS_ACCESS_KEY_ID”, “AWS_SECRET_ACCESS_KEY”, “AWS_REGION”, enz.).
- Voer de werkelijke waarde in het veld “Waarde” in.
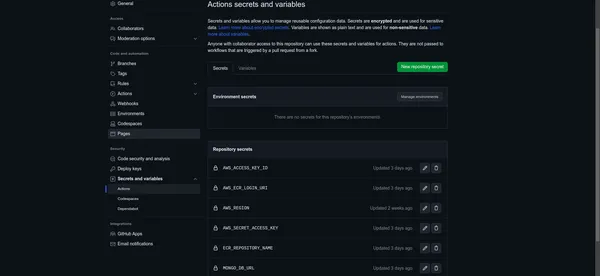
Bewaar uw geheimen
- Klik op de knop 'Geheim toevoegen' voor elke waarde om deze op te slaan als een GitHub-geheim.
Omdat uw AWS-geheimen veilig zijn opgeslagen in GitHub, kunt u er eenvoudig naar verwijzen in uw GitHub Actions-workflows en veilig toegang krijgen tot AWS-services tijdens de implementatie.
Best Practice
- GitHub-geheimen zijn gecodeerd en zijn alleen toegankelijk voor geautoriseerde gebruikers met de benodigde machtigingen. Dit garandeert de veiligheid van uw gevoelige AWS-waarden.
- Door GitHub-geheimen te gebruiken, vermijdt u dat gevoelige informatie rechtstreeks in uw code- of configuratiebestanden wordt vrijgegeven, waardoor de beveiliging van uw project wordt verbeterd.
Uw AWS-installatiewaarden zijn nu veilig geconfigureerd in uw GitHub-repository, waardoor ze direct beschikbaar zijn voor uw PySpark-implementatieworkflow.
De codestructuur begrijpen
Om PySpark effectief op AWS te implementeren met behulp van Docker, is het essentieel om de structuur van de code van uw project te begrijpen. Laten we de componenten waaruit de codebase bestaat, opsplitsen:
├── .github
│ ├── workflows
│ │ ├── build.yml
├── airflow
├── configs
├── consumerComplaint
│ ├── cloud_storage
│ ├── components
│ ├── config
│ │ ├── py_sparkmanager.py
│ ├── constants
│ ├── data_access
│ ├── entity
│ ├── exceptions
│ ├── logger
│ ├── ml
│ ├── pipeline
│ ├── utils
├── output
│ ├── .png
├── prediction_data
├── research
│ ├── jupyter_notebooks
├── saved_models
│ ├── model.pkl
├── tests
├── venv
├── Dockerfile
├── app.py
├── requirements.txt
├── .gitignore
├── .dockerignore
Applicatiecode (app.py)
- app.py is uw belangrijkste Python-script dat verantwoordelijk is voor het uitvoeren van de PySpark-applicatie.
- Het is het toegangspunt voor uw PySpark-taken en dient als de kern van uw applicatie.
- U kunt dit script aanpassen om uw pijplijnen voor gegevensverwerking, taakplanning en meer te definiëren.
Dockerfile
- Het Dockerbestand bevat instructies voor het bouwen van een Docker-installatiekopie voor uw PySpark-toepassing.
- Het specificeert de basisimage, voegt de nodige afhankelijkheden toe, kopieert de applicatiecode naar de container en stelt de runtime-omgeving in.
- Dit bestand speelt een cruciale rol bij het containeriseren van uw applicatie voor een naadloze implementatie.
Vereisten (requirements.txt)
- eisen.txt geeft een overzicht van de Python-pakketten en afhankelijkheden die vereist zijn voor uw PySpark-toepassing.
- Deze pakketten worden in de Docker-container geïnstalleerd om ervoor te zorgen dat uw applicatie soepel werkt.
GitHub-actiesworkflows
- GitHub Actions-workflows worden gedefinieerd in .github/workflows/ binnen uw projectrepository.
- Ze automatiseren de bouw-, test- en implementatieprocessen.
- Werkstroombestanden, zoals main.yml, schetsen de stappen die moeten worden uitgevoerd wanneer specifieke gebeurtenissen plaatsvinden, zoals code-push- of pull-verzoeken.
Bouw py_sparkmanager.py
import os
from dotenv import load_dotenv
from pyspark.sql import SparkSession # Load environment variables from .env
load_dotenv() access_key_id = os.getenv("AWS_ACCESS_KEY_ID")
secret_access_key = os.getenv("AWS_SECRET_ACCESS_KEY") # Initialize SparkSession
spark_session = SparkSession.builder.master('local[*]').appName('consumer_complaint') .config("spark.executor.instances", "1") .config("spark.executor.memory", "6g") .config("spark.driver.memory", "6g") .config("spark.executor.memoryOverhead", "8g") .config('spark.jars.packages', "com.amazonaws:aws-java-sdk:1.7.4, org.apache.hadoop:hadoop-aws:2.7.3") .getOrCreate() # Configure SparkSession for AWS S3 access
spark_session._jsc.hadoopConfiguration().set("fs.s3a.awsAccessKeyId", access_key_id)
spark_session._jsc.hadoopConfiguration().set("fs.s3a.awsSecretAccessKey", secret_access_key)
spark_session._jsc.hadoopConfiguration().set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
spark_session._jsc.hadoopConfiguration().set("com.amazonaws.services.s3.enableV4", "true")
spark_session._jsc.hadoopConfiguration().set("fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.BasicAWSCredentialsProvider")
spark_session._jsc.hadoopConfiguration().set("fs.s3a.endpoint", "ap-south-1.amazonaws.com")
spark_session._jsc.hadoopConfiguration().set("fs.s3.buffer.dir", "tmp")
Deze code stelt uw SparkSession in, configureert deze voor AWS S3-toegang en laadt AWS-inloggegevens uit omgevingsvariabelen, zodat u naadloos met AWS-services kunt werken in uw PySpark-applicatie
PySpark Docker-images voorbereiden (IMP)
In deze sectie wordt onderzocht hoe u Docker-images kunt maken die uw PySpark-applicatie inkapselen, waardoor deze draagbaar, schaalbaar en klaar voor implementatie op AWS wordt. Docker-containers bieden een consistente omgeving voor uw PySpark-applicaties, waardoor een naadloze uitvoering in verschillende omgevingen wordt gegarandeerd.
Dockerfile
De sleutel tot het bouwen van Docker-images voor PySpark is een goed gedefinieerd Docker-bestand. Dit bestand specificeert de instructies voor het instellen van de containeromgeving, inclusief Python- en PySpark-afhankelijkheden.
FROM python:3.8.5-slim-buster
# Use an Ubuntu base image
FROM ubuntu:20.04 # Set JAVA_HOME and install OpenJDK 8
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
RUN apt-get update -y && apt-get install -y openjdk-8-jdk && apt-get install python3-pip -y && apt-get clean && rm -rf /var/lib/apt/lists/* # Set environment variables for your application
ENV AIRFLOW_HOME="/app/airflow"
ENV PYSPARK_PYTHON=/usr/bin/python3
ENV PYSPARK_DRIVER_PYTHON=/usr/bin/python3 # Create a directory for your application and set it as the working directory
WORKDIR /app # Copy the contents of the current directory to the working directory in the container
COPY . /app # Install Python dependencies from requirements.txt
RUN pip3 install -r requirements.txt # Set the entry point to run your app.py script
CMD ["python3", "app.py"]
Het bouwen van de Docker-image
Zodra u uw Dockerfile gereed heeft, kunt u de Docker-image bouwen met behulp van de volgende opdracht:
docker build -t your-image-namevervangen jouw-afbeeldingsnaam met de gewenste naam en versie voor uw Docker-image.
Het lokale beeld verifiëren
Nadat u de installatiekopie hebt gemaakt, kunt u uw lokale Docker-installatiekopieën weergeven met behulp van de volgende opdracht:
docker images docker ps -a docker system dfPySpark uitvoeren in Docker
Als uw Docker-image is voorbereid, kunt u doorgaan en uw PySpark-applicatie uitvoeren in een Docker-container. Gebruik de volgende opdracht:
docker run -your-image-name“”” SOMS voert docker COMMAND NIET WERK VOLG ONDER OPDRACHT. “””
docker run 80:8080 your-image-name docker run 8080:8080 your-image-name
PySpark implementeren op AWS
In deze sectie wordt uitgelegd hoe u uw PySpark-applicatie op AWS kunt implementeren met behulp van Docker-containers. Deze implementatie omvat de lancering van Amazon Elastic Compute Cloud (EC2)-instanties voor het creëren van een PySpark-cluster.
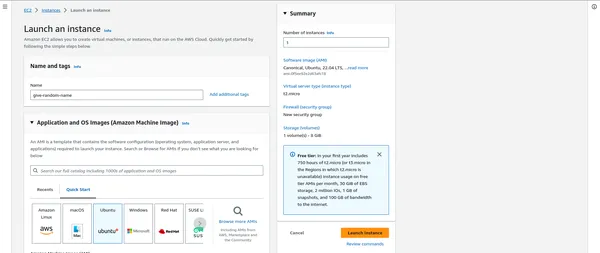
Start EC2-instanties
- Klik in het EC2-dashboard op ‘Instances starten’.
- U kunt een Amazon Machine Image (AMI) selecteren die bij uw behoeften past, vaak op Linux gebaseerd.
- Afhankelijk van uw werklast kiest u het instancetype (bijvoorbeeld m5.large, c5.xlarge).
- Configureer exemplaardetails, inclusief het aantal exemplaren in uw cluster.
- Voeg indien nodig opslag, tags en beveiligingsgroepen toe.
Dit is alles wat ik hierboven noemde.
Maak verbinding met EC2-instanties
- Zodra de instanties zijn uitgevoerd, kunt u er een SSH-verbinding mee maken om uw PySpark-cluster te beheren.
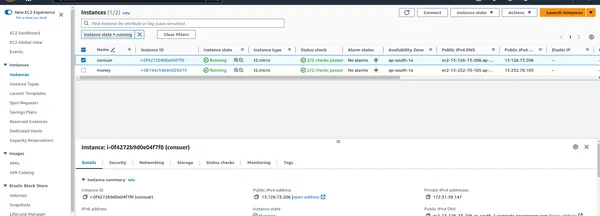
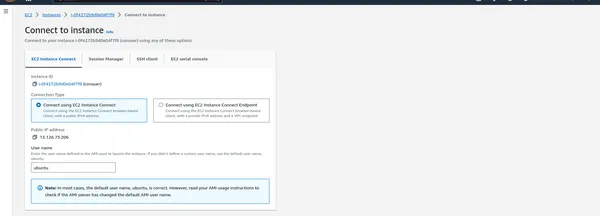
Schrijf het onderstaande commando
Download het Docker-installatiescript
curl -fsSL https://get.docker.com -o get-docker.shVoer het Docker-installatiescript uit met rootrechten
sudo sh get-docker.shVoeg de huidige gebruiker toe aan de dockergroep (vervang 'ubuntu' door uw gebruikersnaam)
sudo usermod -aG docker ubuntuActiveer de wijzigingen door een nieuwe shell-sessie uit te voeren of 'newgrp' te gebruiken
newgrp dockerEen GitHub zelfgehoste runner bouwen
We zetten een zelfgehoste runner op voor GitHub Actions, die verantwoordelijk is voor het uitvoeren van uw CI/CD-workflows. Een zelfgehoste runner draait op uw infrastructuur en is een goede keuze voor het uitvoeren van workflows waarvoor specifieke configuraties of toegang tot lokale bronnen nodig zijn.
De zelfgehoste runner instellen
- Klik op Instelling
- Klik op Actie -> Loper
- Klik Nieuwe zelfgehoste Runner
Schrijf het onderstaande commando op de EC2-machine
- Maak een map: Met deze opdracht wordt een map gemaakt met de naam actions-runner en wordt de huidige map gewijzigd in deze nieuw gemaakte map.
$ mkdir actions-runner && cd actions-runner
- Download het nieuwste runner-pakket: met deze opdracht downloadt u het GitHub Actions runner-pakket voor Linux x64. Het specificeert de URL van het pakket dat moet worden gedownload en slaat het op met de bestandsnaam actions-runner-linux-x64-2.309.0.tar.gz.
$ curl -o actions-runner-linux-x64-2.309.0.tar.gz -L https://github.com/actions/runner/releases/download/v2.309.0/actions-runner-linux-x64-2.309.0.tar.gz
- Optioneel: Valideer de hash: Deze opdracht controleert de integriteit van het gedownloade pakket door de hash te valideren. Het berekent de SHA-256-hash van het gedownloade pakket en vergelijkt deze met een bekende, verwachte hash. Als deze overeenkomen, wordt het pakket als geldig beschouwd.
$ echo "2974243bab2a282349ac833475d241d5273605d3628f0685bd07fb5530f9bb1a actions-runner-linux-x64-2.309.0.tar.gz" | shasum -a 256 -c
- Pak het installatieprogramma uit: Deze opdracht extraheert de inhoud van het gedownloade pakket, dat een tarball (gecomprimeerd archief) is.
$ tar xzf ./actions-runner-linux-x64-2.309.0.tar.gz
- Laatste stap, voer het uit: Met deze opdracht wordt de runner gestart met de opgegeven configuratie-instellingen. Het stelt de runner in om GitHub Actions-workflows uit te voeren voor de opgegeven repository.
$ ./run.sh
Continue integratie en continue levering (CICD) workflowconfiguratie
In een CI/CD-pijplijn is het bestand build.yaml cruciaal bij het definiëren van de stappen die nodig zijn om uw applicatie te bouwen en te implementeren. Dit configuratiebestand specificeert de workflow voor uw CI/CD-proces, inclusief hoe code wordt gebouwd, getest en geïmplementeerd. Laten we eens kijken naar de kritische aspecten van de build.yaml-configuratie en het belang ervan:
Overzicht van de workflow
Het build.yaml-bestand schetst de taken die worden uitgevoerd tijdens de CI/CD-pijplijn. Het definieert de stappen voor continue integratie, wat het bouwen en testen van uw applicatie en continue levering omvat, waarbij de applicatie in verschillende omgevingen wordt geïmplementeerd.
Continue integratie (CI)
Deze fase omvat doorgaans taken zoals het compileren van code, het testen van eenheden en controles van de codekwaliteit. Het build.yaml-bestand specificeert de tools, scripts en opdrachten die nodig zijn om deze taken uit te voeren. Het kan bijvoorbeeld de uitvoering van unit-tests activeren om de kwaliteit van de code te garanderen.
Continue levering (CD)
Na een succesvolle CI omvat de CD-fase de implementatie van de applicatie in verschillende omgevingen, zoals staging of productie. Het build.yaml-bestand specificeert hoe de implementatie moet plaatsvinden, inclusief waar en wanneer moet worden geïmplementeerd en welke configuraties moeten worden gebruikt.
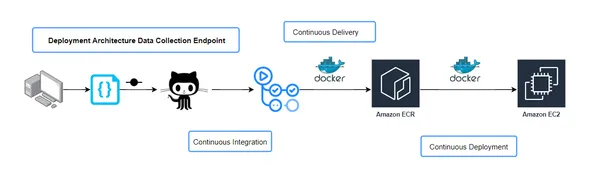
Afhankelijkheidsbeheer
Het build.yaml-bestand bevat vaak details over projectafhankelijkheden. Het definieert waar externe bibliotheken of afhankelijkheden vandaan moeten worden gehaald, wat cruciaal kan zijn voor het succesvol bouwen en implementeren van de applicatie.
Omgevingsvariabelen
CI/CD-workflows vereisen vaak omgevingsspecifieke configuraties, zoals API-sleutels of verbindingsreeksen. Het bestand build.yaml kan definiëren hoe deze omgevingsvariabelen worden ingesteld voor elke pijplijnfase.
Meldingen en waarschuwingen
Bij storingen of problemen tijdens het CI/CD-proces zijn notificaties en alerts essentieel. Het build.yaml-bestand kan configureren hoe en naar wie deze waarschuwingen worden verzonden, zodat problemen snel worden aangepakt.
Artefacten en outputs
Afhankelijk van de CI/CD-workflow kan het bestand build.yaml specificeren welke artefacten of build-uitvoer moeten worden gegenereerd en waar deze moeten worden opgeslagen. Deze artefacten kunnen worden gebruikt voor implementaties of verder testen.
Door het build.yaml-bestand en de componenten ervan te begrijpen, kunt u uw CI/CD-workflow effectief beheren en aanpassen aan de behoeften van uw project. Het is de blauwdruk voor het hele automatiseringsproces, van codewijzigingen tot productie-implementaties.
CI/CD-pijplijn
U kunt de inhoud verder aanpassen op basis van de specifieke details van uw build.yaml-configuratie en hoe deze in uw CI/CD-pijplijn past.
name: workflow on: push: branches: - main paths-ignore: - 'README.md' permissions: id-token: write contents: read jobs: integration: name: Continuous Integration runs-on: ubuntu-latest steps: - name: Checkout Code uses: actions/checkout@v3 - name: Lint code run: echo "Linting repository" - name: Run unit tests run: echo "Running unit tests" build-and-push-ecr-image: name: Continuous Delivery needs: integration runs-on: ubuntu-latest steps: - name: Checkout Code uses: actions/checkout@v3 - name: Install Utilities run: | sudo apt-get update sudo apt-get install -y jq unzip - name: Configure AWS credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ${{ secrets.AWS_REGION }} - name: Login to Amazon ECR id: login-ecr uses: aws-actions/amazon-ecr-login@v1 - name: Build, tag, and push image to Amazon ECR id: build-image env: ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }} ECR_REPOSITORY: ${{ secrets.ECR_REPOSITORY_NAME }} IMAGE_TAG: latest run: | # Build a docker container and # push it to ECR so that it can # be deployed to ECS. docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG . docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG echo "::set-output name=image::$ECR_REGISTRY/$ECR_REPOSITORY :$IMAGE_TAG" Continuous-Deployment: needs: build-and-push-ecr-image runs-on: self-hosted steps: - name: Checkout uses: actions/checkout@v3 - name: Configure AWS credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ${{ secrets.AWS_REGION }} - name: Login to Amazon ECR id: login-ecr uses: aws-actions/amazon-ecr-login@v1 - name: Pull latest images run: | docker pull ${{secrets.AWS_ECR_LOGIN_URI}}/${{ secrets. ECR_REPOSITORY_NAME }}:latest - name: Stop and remove sensor container if running run: | docker ps -q --filter "name=sensor" | grep -q . && docker stop sensor && docker rm -fv sensor - name: Run Docker Image to serve users run: | docker run -d -p 80:8080 --name=sensor -e 'AWS_ACCESS_KEY_ID= ${{ secrets.AWS_ACCESS_KEY_ID }} ' -e 'AWS_SECRET_ACCESS_KEY=${{ secrets.AWS_SECRET_ACCESS_KEY }}' -e 'AWS_REGION=${{ secrets.AWS_REGION }}' ${{secrets.AWS_ECR_LOGIN_URI}}/ ${{ secrets.ECR_REPOSITORY_NAME }}:latest - name: Clean previous images and containers run: | docker system prune -fOpmerking: Alle gesplitste lijnen worden samengevoegd als één
Als er een probleem optreedt, volg dan de GitHub-repository die ik laatst noemde.
Taak voor continue implementatie:
- Deze taak is afhankelijk van de “Build-and-Push-ECR-Image Job” en is geconfigureerd om te worden uitgevoerd op een zelf-hostende runner.
- Het controleert de code en configureert AWS-inloggegevens.
- Het logt in op Amazon ECR.
- Het haalt de nieuwste Docker-image uit de opgegeven ECR-repository.
- Het stopt en verwijdert een Docker-container met de naam “sensor” als deze actief is.
- Het voert een Docker-container uit met de naam 'sensor' met de opgegeven instellingen, omgevingsvariabelen en de eerder opgehaalde Docker-image.
- Ten slotte ruimt het eerdere Docker-images en containers op met behulp van docker-systeemprune.
Automatiseer de uitvoering van de workflow bij codewijzigingen
Om het hele CI/CD-proces naadloos te laten verlopen en te laten reageren op codewijzigingen, kunt u uw repository configureren om de workflow te activeren bij het automatisch vastleggen of pushen van code. Elke keer dat u wijzigingen opslaat en naar uw repository pusht, begint de CI/CD-pijplijn zijn magische werk te doen.
Door de workflowuitvoering te automatiseren, zorgt u ervoor dat uw applicatie zonder handmatige tussenkomst up-to-date blijft van de laatste wijzigingen. Deze automatisering kan de ontwikkelingsefficiëntie aanzienlijk verbeteren en snelle feedback geven over codewijzigingen, waardoor het gemakkelijker wordt om problemen vroeg in de ontwikkelingscyclus op te sporen en op te lossen.
Volg deze stappen om geautomatiseerde workflowuitvoering bij codewijzigingen in te stellen:
git add . git commit -m "message" git push origin mainConclusie
In deze uitgebreide handleiding hebben we u door het ingewikkelde proces geleid van het implementeren van PySpark op AWS met behulp van EC2 en ECR. Door gebruik te maken van containerisatie en continue integratie en levering biedt deze aanpak een robuuste en aanpasbare oplossing voor het beheer van grootschalige data-analyse en verwerkingstaken. Door de stappen in deze blog te volgen, kunt u de volledige kracht van PySpark in een cloudomgeving benutten en profiteren van de schaalbaarheid en flexibiliteit die AWS biedt.
Het is belangrijk op te merken dat AWS vele implementatieopties biedt, van EC2 en ECR tot gespecialiseerde diensten zoals EMR. De keuze van de methode hangt uiteindelijk af van de unieke vereisten van uw project. Of u nu de voorkeur geeft aan de containerisatieaanpak die hier wordt gedemonstreerd of kiest voor een andere AWS-service, de sleutel is om de mogelijkheden van PySpark effectief te benutten in uw datagestuurde applicaties. Met AWS als uw platform bent u goed uitgerust om het volledige potentieel van PySpark te ontsluiten, waarmee u een nieuw tijdperk van data-analyse en -verwerking inluidt. Ontdek services zoals EMR als deze beter aansluiten bij uw specifieke gebruiksscenario's en voorkeuren, aangezien AWS een gevarieerde toolkit biedt voor het inzetten van PySpark om aan de unieke behoeften van uw projecten te voldoen.
Key Takeaways
- De implementatie van PySpark op AWS met Docker stroomlijnt de verwerking van big data en biedt schaalbaarheid en automatisering.
- GitHub-acties vereenvoudigen de CI/CD-pijplijn, waardoor een naadloze code-implementatie mogelijk wordt.
- Het benutten van AWS-services zoals EC2 en ECR zorgt voor robuust PySpark-clusterbeheer.
- Met deze tutorial kunt u de kracht van cloud computing benutten voor data-intensieve taken.
Veelgestelde Vragen / FAQ
A. PySpark is de Python-bibliotheek voor Apache Spark, een robuust, uitgebreid raamwerk voor gegevensverwerking. De implementatie van PySpark op AWS biedt schaalbare en flexibele oplossingen voor data-intensieve taken, waardoor het een ideale keuze is voor gedistribueerde data-analyse.
A. Hoewel u PySpark lokaal kunt uitvoeren, wordt cloudimplementatie aanbevolen voor het efficiënt verwerken van grote datasets. AWS biedt de infrastructuur en tools die nodig zijn voor het schalen van PySpark-applicaties.
A. Gebruik GitHub Secrets om AWS-inloggegevens op te slaan en deze veilig te openen in uw workflow. Dit zorgt ervoor dat uw inloggegevens beschermd blijven en niet zichtbaar zijn in uw code.
A. Docker-containers bieden een consistente omgeving op verschillende platforms, waardoor uw PySpark-applicatie op dezelfde manier wordt uitgevoerd tijdens de ontwikkeling, het testen en de productie. Ze vereenvoudigen ook het proces van het bouwen en implementeren van PySpark-applicaties.
De kosten voor het uitvoeren van PySpark op AWS zijn afhankelijk van verschillende factoren, waaronder het type en aantal gebruikte EC2-instanties, gegevensopslag, gegevensoverdracht en meer. Het monitoren van uw AWS-gebruik en het optimaliseren van middelen om de kosten efficiënt te beheren is essentieel.
Bronnen voor verder leren
- GitHub-opslagplaats: Krijg toegang tot de volledige broncode en configuraties die in deze zelfstudie worden gebruikt op de Consumentenklachten Geschilvoorspelling GitHub-repository.
- Docker-documentatie: Duik dieper in Docker en containerisatie door de officiële Docker-documentatie. U vindt uitgebreide handleidingen, best practices en tips om Docker onder de knie te krijgen.
- Documentatie over GitHub-acties: Ontketen de volledige kracht van GitHub Actions door te verwijzen naar de Documentatie over GitHub-acties. Deze hulpbron helpt u bij het creëren, aanpassen en automatiseren van uw workflows.
- Officiële PySpark-documentatie: Voor diepgaande kennis van PySpark kunt u gewoon de officiële PySpark-documentatie. Leer meer over API's, functies en bibliotheken voor de verwerking van big data.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/11/what-are-the-best-practices-for-deploying-pyspark-on-aws/

