Amazon Sage Maker multi-model eindpunten (MME's) zijn een volledig beheerde mogelijkheid van SageMaker-inferentie waarmee u duizenden modellen op één eindpunt kunt implementeren. Voorheen wezen MME's vooraf bepaald CPU-rekenkracht toe aan modellen, ongeacht de verkeersbelasting van het model, met behulp van Multimodelserver (MMS) als modelserver. In dit bericht bespreken we een oplossing waarbij een MME de rekenkracht die aan elk model wordt toegewezen dynamisch kan aanpassen op basis van het verkeerspatroon van het model. Met deze oplossing kunt u de onderliggende rekenkracht van MME's efficiënter gebruiken en kosten besparen.
MME's laden en ontladen modellen dynamisch op basis van inkomend verkeer naar het eindpunt. Wanneer MMS als modelserver wordt gebruikt, wijzen MME's een vast aantal modelwerkers toe voor elk model. Voor meer informatie, zie Modelleer hostingpatronen in Amazon SageMaker, deel 3: voer en optimaliseer inferentie voor meerdere modellen met Amazon SageMaker multi-model-eindpunten.
Dit kan echter tot een aantal problemen leiden als uw verkeerspatroon variabel is. Stel dat u een enkel of enkele modellen heeft die een grote hoeveelheid verkeer ontvangen. U kunt MMS configureren om een groot aantal werknemers voor deze modellen toe te wijzen, maar dit wordt toegewezen aan alle modellen achter de MME omdat het een statische configuratie is. Dit leidt ertoe dat een groot aantal werknemers hardwarecomputers gebruikt, zelfs de inactieve modellen. Het tegenovergestelde probleem kan optreden als u een kleine waarde instelt voor het aantal werknemers. De populaire modellen zullen niet genoeg werknemers op modelserverniveau hebben om voldoende hardware achter het eindpunt voor deze modellen op de juiste manier toe te wijzen. Het belangrijkste probleem is dat het moeilijk is om verkeerspatroon-agnostisch te blijven als u uw werknemers niet dynamisch kunt schalen op modelserverniveau om de benodigde hoeveelheid rekenkracht toe te wijzen.
De oplossing die we in dit bericht bespreken, gebruikt DJLServing als de modelserver, wat kan helpen een aantal van de problemen die we hebben besproken te verminderen en schaalvergroting per model mogelijk te maken en MME's in staat te stellen verkeerspatroon-agnostisch te zijn.
MME-architectuur
Met SageMaker MME's kunt u meerdere modellen implementeren achter één enkel inferentie-eindpunt dat een of meer instanties kan bevatten. Elke instance is ontworpen om meerdere modellen te laden en te bedienen, afhankelijk van de geheugen- en CPU/GPU-capaciteit. Met deze architectuur kan een Software as a Service (SaaS)-bedrijf de lineair stijgende kosten van het hosten van meerdere modellen doorbreken en hergebruik van de infrastructuur realiseren in overeenstemming met het multi-tenancy-model dat elders in de applicatiestack wordt toegepast. Het volgende diagram illustreert deze architectuur.
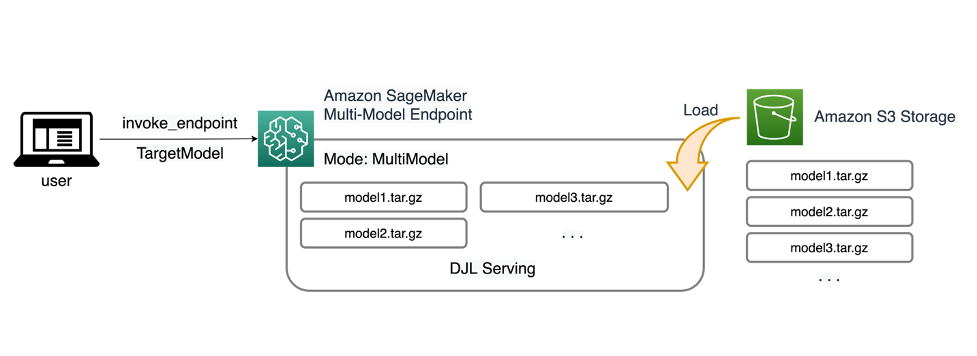
Een SageMaker MME laadt dynamisch modellen uit Amazon eenvoudige opslagservice (Amazon S3) wanneer het wordt aangeroepen, in plaats van alle modellen te downloaden wanneer het eindpunt voor het eerst wordt gemaakt. Als gevolg hiervan kan een initiële aanroep van een model een hogere gevolgtrekkingslatentie opleveren dan de daaropvolgende gevolgtrekkingen, die met een lage latentie worden voltooid. Als het model al in de container is geladen wanneer het wordt aangeroepen, wordt de downloadstap overgeslagen en retourneert het model de gevolgtrekkingen met een lage latentie. Stel bijvoorbeeld dat u een model heeft dat slechts enkele keren per dag wordt gebruikt. Het wordt automatisch op verzoek geladen, terwijl veelgebruikte modellen in het geheugen worden bewaard en met een consistent lage latentie worden aangeroepen.
Achter elke MME bevinden zich modelhostinginstanties, zoals weergegeven in het volgende diagram. Deze instanties laden en verwijderen meerdere modellen van en naar het geheugen op basis van de verkeerspatronen naar de modellen.
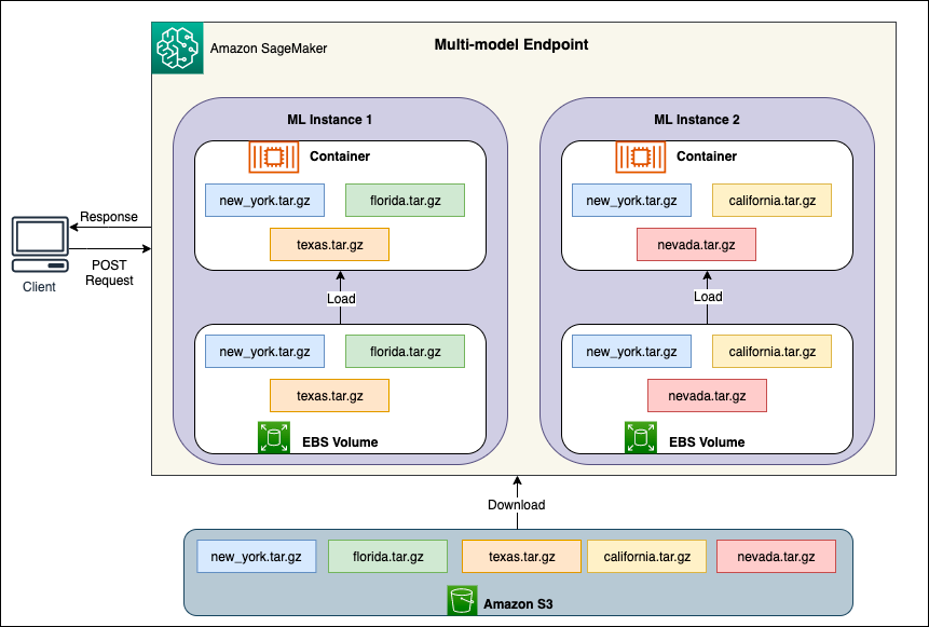
SageMaker gaat door met het routeren van inferentieverzoeken voor een model naar de instantie waar het model al is geladen, zodat de verzoeken worden geleverd vanuit een in de cache opgeslagen modelkopie (zie het volgende diagram, dat het verzoekpad toont voor het eerste voorspellingsverzoek versus de in de cache opgeslagen voorspelling verzoekpad). Als het model echter veel aanroepverzoeken ontvangt en er extra exemplaren voor de MME zijn, stuurt SageMaker enkele verzoeken door naar een ander exemplaar om aan de toename tegemoet te komen. Als u wilt profiteren van de automatische schaalvergroting van modellen in SageMaker, zorg er dan voor dat u dat heeft gedaan instantie automatisch schalen instellen om extra instantiecapaciteit te leveren. Stel uw schaalbeleid op eindpuntniveau in met aangepaste parameters of aanroepen per minuut (aanbevolen) om meer instanties toe te voegen aan de eindpuntvloot.

Overzicht van modelservers
Een modelserver is een softwarecomponent die een runtime-omgeving biedt voor het implementeren en bedienen van machine learning-modellen (ML). Het fungeert als interface tussen de getrainde modellen en clientapplicaties die met behulp van die modellen voorspellingen willen doen.
Het primaire doel van een modelserver is het mogelijk maken van moeiteloze integratie en efficiënte inzet van ML-modellen in productiesystemen. In plaats van het model rechtstreeks in een applicatie of een specifiek raamwerk in te bedden, biedt de modelserver een gecentraliseerd platform waarop meerdere modellen kunnen worden geïmplementeerd, beheerd en bediend.
Modelservers bieden doorgaans de volgende functionaliteiten:
- Model laden – De server laadt de getrainde ML-modellen in het geheugen, waardoor ze gereed zijn voor het weergeven van voorspellingen.
- Inferentie-API – De server stelt een API beschikbaar waarmee clienttoepassingen invoergegevens kunnen verzenden en voorspellingen kunnen ontvangen van de geïmplementeerde modellen.
- scaling – Modelservers zijn ontworpen om gelijktijdige verzoeken van meerdere clients te verwerken. Ze bieden mechanismen voor parallelle verwerking en efficiënt beheer van bronnen om een hoge doorvoer en lage latentie te garanderen.
- Integratie met backend-engines – Modelservers hebben integraties met backend-frameworks zoals DeepSpeed en FasterTransformer om grote modellen te partitioneren en zeer geoptimaliseerde gevolgtrekkingen uit te voeren.
DJL-architectuur
DJL serveren is een open source, krachtige, universele modelserver. DJL Serving is er bovenop gebouwd Djl, een deep learning-bibliotheek geschreven in de programmeertaal Java. Het kan een deep learning-model, verschillende modellen of workflows zijn en deze beschikbaar maken via een HTTP-eindpunt. DJL Serving ondersteunt de implementatie van modellen uit meerdere frameworks zoals PyTorch, TensorFlow, Apache MXNet, ONNX, TensorRT, Hugging Face Transformers, DeepSpeed, FasterTransformer en meer.
DJL Serving biedt vele functies waarmee u uw modellen met hoge prestaties kunt inzetten:
- Gebruiksgemak – DJL Serving kan de meeste modellen direct uit de doos bedienen. Breng gewoon de modelartefacten mee en DJL Serving kan ze hosten.
- Ondersteuning voor meerdere apparaten en versnellers – DJL Serving ondersteunt de implementatie van modellen op CPU, GPU en AWS Inferentie.
- Performance – DJL Serving voert multithreaded inferentie uit in een enkele JVM om de doorvoer te vergroten.
- Dynamische batchverwerking – DJL Serving ondersteunt dynamische batching om de doorvoer te vergroten.
- Automatisch schalen – DJL Serving zal werknemers automatisch op- en afschalen op basis van de verkeersdruk.
- Ondersteuning voor meerdere motoren – DJL Serving kan tegelijkertijd modellen hosten met behulp van verschillende frameworks (zoals PyTorch en TensorFlow).
- Ensemble- en workflowmodellen – DJL Serving ondersteunt de implementatie van complexe workflows die uit meerdere modellen bestaan, en voert delen van de workflow uit op CPU en delen op GPU. Modellen binnen een workflow kunnen verschillende raamwerken gebruiken.
Met name de automatische schalingsfunctie van DJL Serving maakt het eenvoudig om ervoor te zorgen dat de modellen op de juiste manier worden geschaald voor het binnenkomende verkeer. Standaard bepaalt DJL Serving het maximale aantal werknemers voor een model dat kan worden ondersteund op basis van de beschikbare hardware (CPU-kernen, GPU-apparaten). U kunt voor elk model onder- en bovengrenzen instellen om ervoor te zorgen dat er altijd een minimaal verkeersniveau kan worden bediend en dat één model niet alle beschikbare bronnen verbruikt.
DJL Serving gebruikt een Netty frontend bovenop de threadpools van backend-werknemers. De frontend gebruikt een enkele Netty-installatie met meerdere HttpRequestHandlers. Verschillende verzoekbehandelaars zullen ondersteuning bieden voor de Inferentie-API, Beheer APIof andere API's die beschikbaar zijn via verschillende plug-ins.
De backend is gebaseerd op de WorkLoadManager (WLM)-module. De WLM zorgt voor meerdere werkthreads voor elk model, samen met de batching en aanvraagroutering ernaartoe. Wanneer er meerdere modellen worden aangeboden, controleert WLM eerst de wachtrijgrootte van elk model. Als de wachtrijgrootte groter is dan tweemaal de batchgrootte van een model, schaalt WLM het aantal werknemers dat aan dat model is toegewezen op.
Overzicht oplossingen
De implementatie van DJL met een MME verschilt van de standaard MMS-configuratie. Voor DJL Serving met een MME comprimeren we de volgende bestanden in het model.tar.gz-formaat dat SageMaker Inference verwacht:
- model.joblib – Voor deze implementatie pushen we de modelmetagegevens rechtstreeks naar de tarball. In dit geval werken we met een
.joblibbestand, dus we bieden dat bestand aan in onze tarball zodat ons inferentiescript het kan lezen. Als het artefact te groot is, kun je het ook naar Amazon S3 pushen en daarnaar verwijzen in de serveerconfiguratie die je voor DJL definieert. - serveren.eigenschappen – Hier kunt u elk model servergerelateerd configureren omgevingsvariabelen. De kracht van DJL hier is dat je kunt configureren
minWorkersenmaxWorkersvoor elk model tarball. Hierdoor kan elk model op- en afschalen op modelserverniveau. Als een enkelvoudig model bijvoorbeeld het merendeel van het verkeer voor een MME ontvangt, zal de modelserver de werkers dynamisch opschalen. In dit voorbeeld configureren we deze variabelen niet en laten we DJL het benodigde aantal werknemers bepalen, afhankelijk van ons verkeerspatroon. - model.py – Dit is het inferentiescript voor elke aangepaste voor- of nabewerking die u wilt implementeren. Model.py verwacht dat uw logica standaard is ingekapseld in een handle-methode.
- vereisten.txt (optioneel) – Standaard wordt DJL geïnstalleerd met PyTorch, maar eventuele extra afhankelijkheden die je nodig hebt, kunnen hier worden gepusht.
Voor dit voorbeeld laten we de kracht van DJL zien met een MME door een voorbeeld van een SKLearn-model te nemen. We voeren een trainingsopdracht uit met dit model en maken vervolgens 1,000 exemplaren van dit modelartefact ter ondersteuning van onze MME. Vervolgens laten we zien hoe DJL dynamisch kan schalen om elk type verkeerspatroon dat uw MME ontvangt, te verwerken. Dit kan een gelijkmatige verdeling van het verkeer over alle modellen omvatten, of zelfs een paar populaire modellen die het merendeel van het verkeer ontvangen. Hieronder vindt u alle code GitHub repo.
Voorwaarden
Voor dit voorbeeld gebruiken we een SageMaker-notebookinstantie met een conda_python3-kernel en ml.c5.xlarge-instantie. Om de belastingstests uit te voeren, kunt u een Amazon Elastic Compute-cloud (Amazon EC2)-instantie of een grotere SageMaker-notebookinstantie. In dit voorbeeld schalen we naar meer dan duizend transacties per seconde (TPS), dus we raden aan om te testen op een zwaardere EC2-instantie, zoals een ml.c5.18xlarge, zodat u meer rekenkracht heeft om mee te werken.
Maak een modelartefact
We moeten eerst ons modelartefact en de gegevens maken die we in dit voorbeeld gebruiken. Voor dit geval genereren we enkele kunstmatige gegevens met NumPy en trainen we met behulp van een SKLearn lineair regressiemodel met het volgende codefragment:
Nadat u de voorgaande code hebt uitgevoerd, zou u een model.joblib bestand gemaakt in uw lokale omgeving.
Trek de DJL Docker-image eruit
De Docker-image djl-inference:0.23.0-cpu-full-v1.0 is onze DJL-serveercontainer die in dit voorbeeld wordt gebruikt. Afhankelijk van uw regio kunt u de volgende URL aanpassen:
inference_image_uri = "474422712127.dkr.ecr.us-east-1.amazonaws.com/djl-serving-cpu:latest"
Optioneel kunt u deze image ook als basisimage gebruiken en uitbreiden om uw eigen Docker-image op te bouwen Amazon Elastic Container-register (Amazon ECR) met eventuele andere afhankelijkheden die u nodig heeft.
Maak het modelbestand
Eerst maken we een bestand met de naam serving.properties. Dit instrueert DJLServing om de Python-engine te gebruiken. Wij definiëren ook de max_idle_time van een werknemer bedraagt 600 seconden. Dit zorgt ervoor dat het langer duurt voordat we het aantal werknemers per model hebben teruggeschroefd. Wij passen ons niet aan minWorkers en maxWorkers dat we kunnen definiëren en we laten DJL dynamisch het aantal benodigde werknemers berekenen, afhankelijk van het verkeer dat elk model ontvangt. De serve.properties worden als volgt weergegeven. Raadpleeg voor de volledige lijst met configuratieopties Motor configuratie.
Vervolgens maken we ons model.py-bestand, dat de logica voor het laden van het model en de gevolgtrekking definieert. Voor MME's is elk model.py-bestand specifiek voor een model. Modellen worden opgeslagen in hun eigen paden onder het modelarchief (meestal /opt/ml/model/). Bij het laden van modellen worden ze geladen onder het modelarchiefpad in hun eigen map. Het volledige model.py-voorbeeld in deze demo is te zien in de GitHub repo.
We creëren een model.tar.gz bestand dat ons model bevat (model.joblib), model.py en serving.properties:
Voor demonstratiedoeleinden maken we er 1,000 exemplaren van model.tar.gz -bestand dat het grote aantal te hosten modellen vertegenwoordigt. In de productie moet u een model.tar.gz bestand voor elk van uw modellen.
Ten slotte uploaden we deze modellen naar Amazon S3.
Een SageMaker-model maken
We maken nu een SageMaker-model. We gebruiken de eerder gedefinieerde ECR-afbeelding en het modelartefact uit de vorige stap om het SageMaker-model te maken. In de modelconfiguratie configureren we Mode als MultiModel. Dit vertelt DJLServing dat we een MME aan het maken zijn.
Een SageMaker-eindpunt maken
In deze demo gebruiken we 20 ml.c5d.18xlarge-instanties om te schalen naar een TPS in het bereik van duizenden. Zorg ervoor dat u, indien nodig, een limietverhoging voor uw instantietype krijgt om de TPS te bereiken die u target.
Load testen
Op het moment van schrijven is er de interne tool voor het testen van de belasting van SageMaker Amazon SageMaker Inferentie-aanbeveler biedt geen native ondersteuning voor testen voor MME's. Daarom gebruiken we de open source Python-tool Sprinkhaan. Locust is eenvoudig in te stellen en kan statistieken zoals TPS en end-to-end latentie volgen. Voor een volledig begrip van hoe u het kunt instellen met SageMaker, zie Best practices voor het testen van real-time deductie-eindpunten van Amazon SageMaker.
In dit gebruiksscenario hebben we drie verschillende verkeerspatronen die we willen simuleren met MME's, dus we hebben de volgende drie Python-scripts die bij elk patroon aansluiten. Ons doel hier is om te bewijzen dat we, ongeacht ons verkeerspatroon, dezelfde doel-TPS kunnen bereiken en op de juiste manier kunnen schalen.
We kunnen een gewicht specificeren in ons Locust-script om verkeer toe te wijzen aan verschillende delen van onze modellen. Met ons enkele hot-model implementeren we bijvoorbeeld twee methoden als volgt:
We kunnen vervolgens aan elke methode een bepaald gewicht toekennen, namelijk wanneer een bepaalde methode een specifiek percentage van het verkeer ontvangt:
Voor 20 ml.c5d.18xlarge-instanties zien we de volgende aanroepstatistieken op de Amazon Cloud Watch troosten. Deze waarden blijven redelijk consistent in alle drie de verkeerspatronen. Om de CloudWatch-statistieken voor realtime inferentie en MME's van SageMaker beter te begrijpen, raadpleegt u SageMaker Endpoint-aanroepstatistieken.
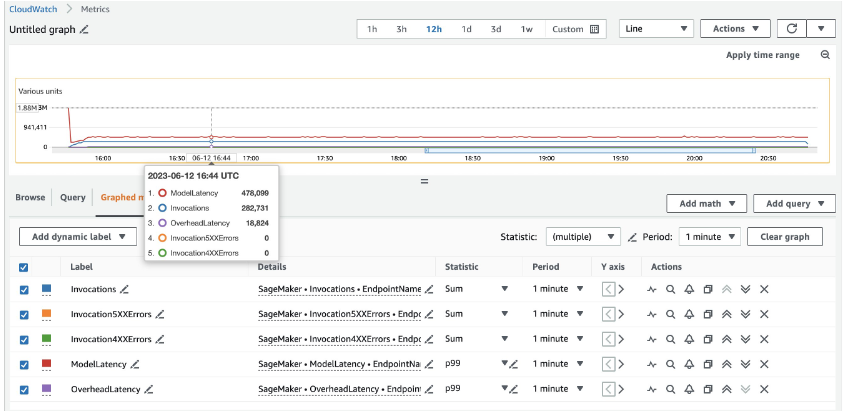
Je kunt de rest van de Locust-scripts vinden in de locust-utils map in de GitHub-repository.
Samengevat
In dit bericht hebben we besproken hoe een MME de rekenkracht die aan elk model is toegewezen dynamisch kan aanpassen op basis van het verkeerspatroon van het model. Deze nieuw gelanceerde functie is beschikbaar in alle AWS-regio's waar SageMaker beschikbaar is. Houd er rekening mee dat op het moment van aankondiging alleen CPU-instanties worden ondersteund. Raadpleeg voor meer informatie Ondersteunde algoritmen, frameworks en instances.
Over de auteurs
 Ram Vegiraju is een ML Architect bij het SageMaker Service-team. Hij richt zich op het helpen van klanten bij het bouwen en optimaliseren van hun AI/ML-oplossingen op Amazon SageMaker. In zijn vrije tijd houdt hij van reizen en schrijven.
Ram Vegiraju is een ML Architect bij het SageMaker Service-team. Hij richt zich op het helpen van klanten bij het bouwen en optimaliseren van hun AI/ML-oplossingen op Amazon SageMaker. In zijn vrije tijd houdt hij van reizen en schrijven.
 Qingwei Li is Machine Learning Specialist bij Amazon Web Services. Hij behaalde zijn Ph.D. in Operations Research nadat hij de onderzoeksbeursrekening van zijn adviseur had verbroken en de beloofde Nobelprijs niet kon leveren. Momenteel helpt hij klanten in de financiële dienstverlening en de verzekeringssector bij het bouwen van machine learning-oplossingen op AWS. In zijn vrije tijd houdt hij van lezen en lesgeven.
Qingwei Li is Machine Learning Specialist bij Amazon Web Services. Hij behaalde zijn Ph.D. in Operations Research nadat hij de onderzoeksbeursrekening van zijn adviseur had verbroken en de beloofde Nobelprijs niet kon leveren. Momenteel helpt hij klanten in de financiële dienstverlening en de verzekeringssector bij het bouwen van machine learning-oplossingen op AWS. In zijn vrije tijd houdt hij van lezen en lesgeven.
 James Wu is Senior AI/ML Specialist Solution Architect bij AWS. klanten helpen bij het ontwerpen en bouwen van AI/ML-oplossingen. James' werk omvat een breed scala aan ML-gebruikscasussen, met een primaire interesse in computervisie, deep learning en het opschalen van ML in de hele onderneming. Voordat hij bij AWS kwam, was James meer dan 10 jaar architect, ontwikkelaar en technologieleider, waarvan 6 jaar in engineering en 4 jaar in marketing- en reclamesectoren.
James Wu is Senior AI/ML Specialist Solution Architect bij AWS. klanten helpen bij het ontwerpen en bouwen van AI/ML-oplossingen. James' werk omvat een breed scala aan ML-gebruikscasussen, met een primaire interesse in computervisie, deep learning en het opschalen van ML in de hele onderneming. Voordat hij bij AWS kwam, was James meer dan 10 jaar architect, ontwikkelaar en technologieleider, waarvan 6 jaar in engineering en 4 jaar in marketing- en reclamesectoren.
 Saurabh Trikande is Senior Product Manager voor Amazon SageMaker Inference. Hij heeft een passie voor het werken met klanten en wordt gemotiveerd door het doel om machine learning te democratiseren. Hij richt zich op kernuitdagingen met betrekking tot het inzetten van complexe ML-applicaties, multi-tenant ML-modellen, kostenoptimalisaties en het toegankelijker maken van de inzet van deep learning-modellen. In zijn vrije tijd houdt Saurabh van wandelen, leren over innovatieve technologieën, TechCrunch volgen en tijd doorbrengen met zijn gezin.
Saurabh Trikande is Senior Product Manager voor Amazon SageMaker Inference. Hij heeft een passie voor het werken met klanten en wordt gemotiveerd door het doel om machine learning te democratiseren. Hij richt zich op kernuitdagingen met betrekking tot het inzetten van complexe ML-applicaties, multi-tenant ML-modellen, kostenoptimalisaties en het toegankelijker maken van de inzet van deep learning-modellen. In zijn vrije tijd houdt Saurabh van wandelen, leren over innovatieve technologieën, TechCrunch volgen en tijd doorbrengen met zijn gezin.
 Xu Deng is een Software Engineer Manager bij het SageMaker-team. Hij richt zich op het helpen van klanten bij het bouwen en optimaliseren van hun AI/ML-inferentie-ervaring op Amazon SageMaker. In zijn vrije tijd houdt hij van reizen en snowboarden.
Xu Deng is een Software Engineer Manager bij het SageMaker-team. Hij richt zich op het helpen van klanten bij het bouwen en optimaliseren van hun AI/ML-inferentie-ervaring op Amazon SageMaker. In zijn vrije tijd houdt hij van reizen en snowboarden.
 Siddharth Venkatesan is een Software Engineer in AWS Deep Learning. Hij richt zich momenteel op het bouwen van oplossingen voor grote modelinferentie. Voordat hij bij AWS kwam, werkte hij in de Amazon Grocery-organisatie aan het ontwikkelen van nieuwe betalingsfuncties voor klanten over de hele wereld. Buiten zijn werk houdt hij van skiën, het buitenleven en sport kijken.
Siddharth Venkatesan is een Software Engineer in AWS Deep Learning. Hij richt zich momenteel op het bouwen van oplossingen voor grote modelinferentie. Voordat hij bij AWS kwam, werkte hij in de Amazon Grocery-organisatie aan het ontwikkelen van nieuwe betalingsfuncties voor klanten over de hele wereld. Buiten zijn werk houdt hij van skiën, het buitenleven en sport kijken.
 Rohith Nallamaddi is Software Development Engineer bij AWS. Hij werkt aan het optimaliseren van deep learning-workloads op GPU's, het bouwen van hoogwaardige ML-inferentie en het leveren van oplossingen. Daarvoor werkte hij aan het bouwen van microservices op basis van AWS voor Amazon F3-business. Naast zijn werk houdt hij van spelen en sport kijken.
Rohith Nallamaddi is Software Development Engineer bij AWS. Hij werkt aan het optimaliseren van deep learning-workloads op GPU's, het bouwen van hoogwaardige ML-inferentie en het leveren van oplossingen. Daarvoor werkte hij aan het bouwen van microservices op basis van AWS voor Amazon F3-business. Naast zijn werk houdt hij van spelen en sport kijken.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/run-ml-inference-on-unplanned-and-spiky-traffic-using-amazon-sagemaker-multi-model-endpoints/

