Vandaag kondigen we met trots de mogelijkheid aan om Code Llama-modellen van Meta te verfijnen Amazon SageMaker JumpStart. De Code Llama-familie van grote taalmodellen (LLM's) is een verzameling vooraf getrainde en nauwkeurig afgestemde modellen voor het genereren van code, variërend in schaal van 7 miljard tot 70 miljard parameters. Verfijnde Code Llama-modellen bieden een betere nauwkeurigheid en uitlegbaarheid dan de basis Code Llama-modellen, zoals blijkt uit de tests met MenselijkEval en MBPP-datasets. U kunt Code Llama-modellen verfijnen en implementeren met SageMaker JumpStart met behulp van de Amazon SageMaker Studio UI met een paar klikken of met behulp van de SageMaker Python SDK. Het verfijnen van lamamodellen is gebaseerd op de scripts in de lama-recepten GitHub-repository van Meta met behulp van PyTorch FSDP-, PEFT/LoRA- en Int8-kwantiseringstechnieken.
In dit bericht laten we zien hoe u vooraf getrainde Code Llama-modellen kunt verfijnen via SageMaker JumpStart via een gebruikersinterface met één klik en SDK-ervaring die beschikbaar is in het volgende GitHub-repository.
Wat is SageMaker JumpStart
Met SageMaker JumpStart kunnen beoefenaars van machine learning (ML) kiezen uit een brede selectie van openbaar beschikbare basismodellen. ML-beoefenaars kunnen basismodellen inzetten voor specifieke toepassingen Amazon Sage Maker instances uit een netwerkgeïsoleerde omgeving en pas modellen aan met SageMaker voor modeltraining en -implementatie.
Wat is Code Lama
Code Llama is een code-gespecialiseerde versie van Lama 2 die is gemaakt door Llama 2 verder te trainen in zijn codespecifieke datasets en langer meer gegevens uit diezelfde dataset te bemonsteren. Code Llama beschikt over verbeterde codeermogelijkheden. Het kan code en natuurlijke taal over code genereren, op basis van zowel code- als natuurlijke taalprompts (bijvoorbeeld: "Schrijf me een functie die de Fibonacci-reeks uitvoert"). U kunt het ook gebruiken voor het voltooien van code en het opsporen van fouten. Het ondersteunt veel van de meest populaire programmeertalen die tegenwoordig worden gebruikt, waaronder Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash en meer.
Waarom Code Llama-modellen verfijnen
Meta heeft prestatiebenchmarks van Code Llama gepubliceerd op HumanEval en MBPP voor veelgebruikte codeertalen zoals Python, Java en JavaScript. De prestaties van Code Llama Python-modellen op HumanEval lieten wisselende prestaties zien in verschillende codeertalen en -taken, variërend van 38% op het 7B Python-model tot 57% op de 70B Python-modellen. Bovendien hebben verfijnde Code Llama-modellen op de SQL-programmeertaal betere resultaten laten zien, zoals blijkt uit SQL-evaluatiebenchmarks. Deze gepubliceerde benchmarks benadrukken de potentiële voordelen van het verfijnen van Code Llama-modellen, waardoor betere prestaties, maatwerk en aanpassing aan specifieke codeerdomeinen en -taken mogelijk worden.
Fijnafstelling zonder code via de gebruikersinterface van SageMaker Studio
Om te beginnen met het verfijnen van uw lamamodellen met SageMaker Studio, voert u de volgende stappen uit:
- Kies op de SageMaker Studio-console snelle start in het navigatievenster.
U vindt lijsten met meer dan 350 modellen, variërend van open source en eigen modellen.
- Zoek naar Code Llama-modellen.

Als u geen Code Llama-modellen ziet, kunt u uw SageMaker Studio-versie bijwerken door af te sluiten en opnieuw op te starten. Voor meer informatie over versie-updates raadpleegt u Sluit Studio-apps af en werk ze bij. Door te kiezen, kunt u ook andere modelvarianten vinden Ontdek alle modellen voor het genereren van code of zoek naar Code Llama in het zoekvak.
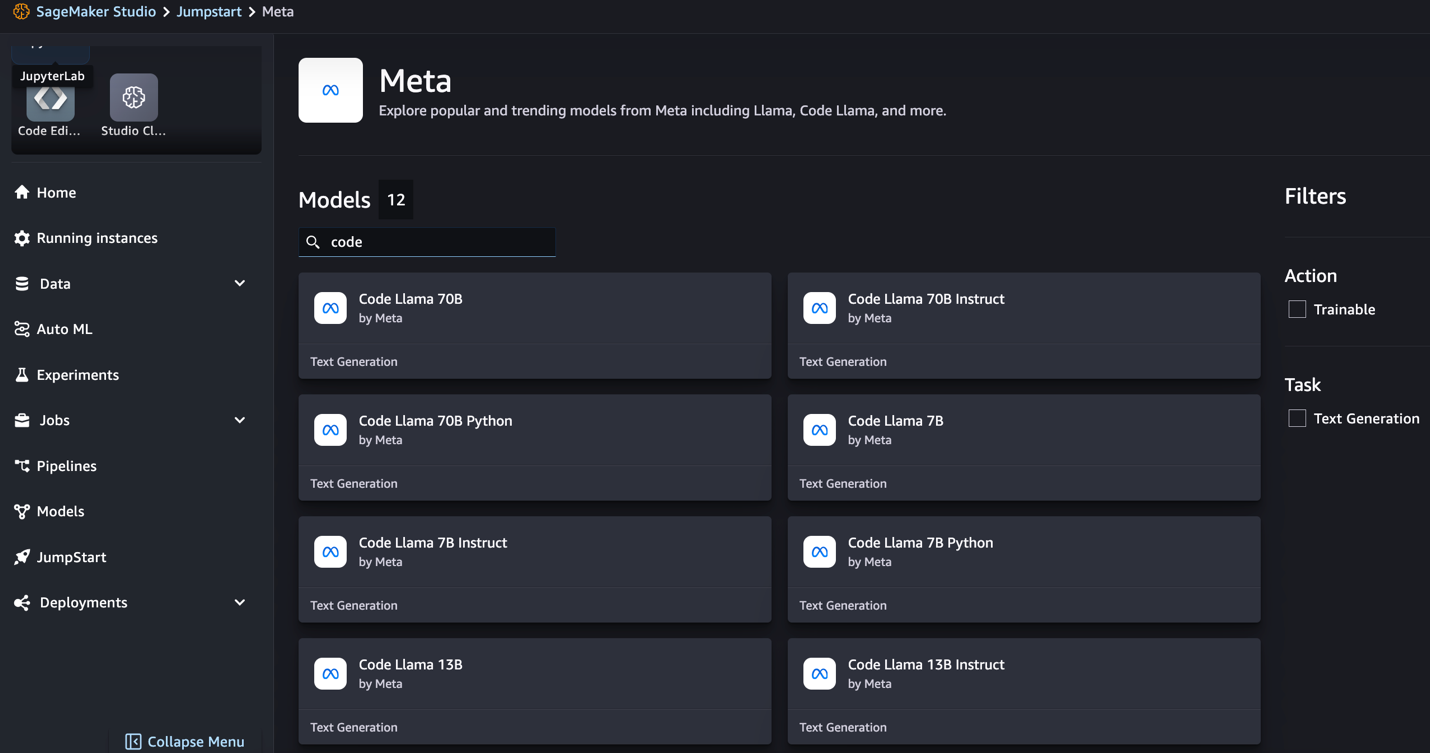
SageMaker JumpStart ondersteunt momenteel het afstemmen van instructies voor Code Llama-modellen. De volgende schermafbeelding toont de verfijningspagina voor het Code Llama 2 70B-model.
- Voor Locatie van trainingsdataset, kunt u verwijzen naar de Amazon eenvoudige opslagservice (Amazon S3)-bucket met de trainings- en validatiegegevenssets voor verfijning.
- Stel uw implementatieconfiguratie, hyperparameters en beveiligingsinstellingen in voor fijnafstemming.
- Kies Trainen om de verfijningstaak op een SageMaker ML-instantie te starten.
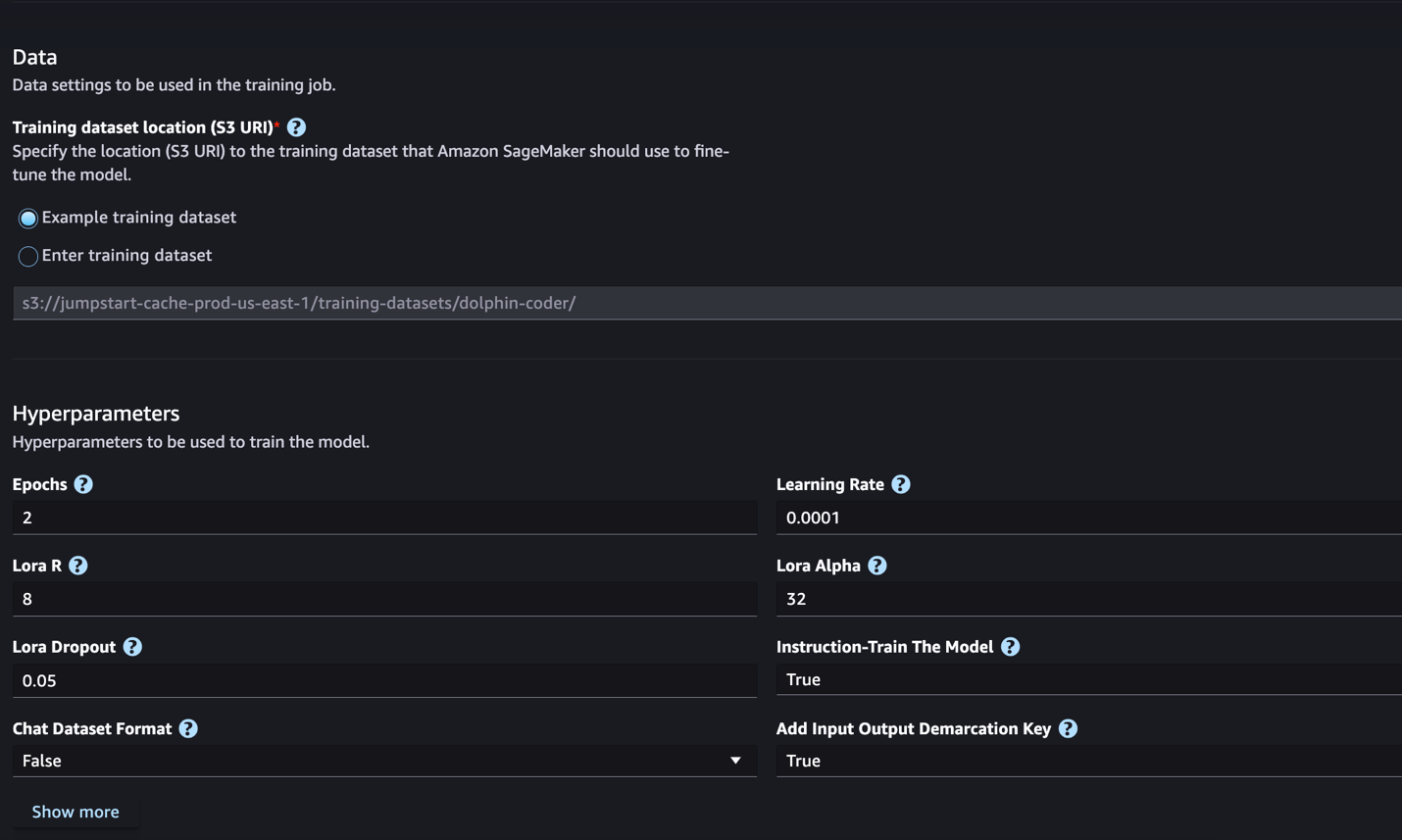
In de volgende sectie bespreken we het datasetformaat dat u nodig heeft om de instructies te verfijnen.
- Nadat het model is verfijnd, kunt u het implementeren met behulp van de modelpagina op SageMaker JumpStart.
De optie om het verfijnde model te implementeren verschijnt wanneer het afstemmen is voltooid, zoals weergegeven in de volgende schermafbeelding.

Verfijn via de SageMaker Python SDK
In deze sectie laten we zien hoe u Code LIama-modellen kunt verfijnen met behulp van de SageMaker Python SDK op een instructiegeformatteerde dataset. Het model is specifiek afgestemd op een reeks taken voor natuurlijke taalverwerking (NLP) die worden beschreven met behulp van instructies. Dit helpt de prestaties van het model te verbeteren voor onzichtbare taken met zero-shot-prompts.
Voer de volgende stappen uit om uw fijnafstemmingstaak te voltooien. U kunt de volledige fijnafstemmingscode verkrijgen via de GitHub-repository.
Laten we eerst eens kijken naar het datasetformaat dat nodig is voor het afstemmen van de instructies. De trainingsgegevens moeten worden opgemaakt in een JSON-regelsindeling (.jsonl), waarbij elke regel een woordenboek is dat een gegevensvoorbeeld vertegenwoordigt. Alle trainingsgegevens moeten in één map staan. Het kan echter in meerdere .jsonl-bestanden worden opgeslagen. Het volgende is een voorbeeld in JSON-regelindeling:
De trainingsmap kan een template.json bestand dat de invoer- en uitvoerformaten beschrijft. Het volgende is een voorbeeldsjabloon:
Om overeen te komen met de sjabloon moet elk voorbeeld in de JSON-regelbestanden het volgende bevatten system_prompt, question en response velden. In deze demonstratie gebruiken we de Dolphin Coder-gegevensset van Knuffelgezicht.
Nadat u de gegevensset hebt voorbereid en naar de S3-bucket hebt geüpload, kunt u beginnen met het afstemmen met behulp van de volgende code:
U kunt het verfijnde model rechtstreeks vanuit de schatter implementeren, zoals weergegeven in de volgende code. Voor meer informatie, zie het notitieboekje in de GitHub-repository.
Verfijningstechnieken
Taalmodellen zoals Llama zijn ruim 10 GB of zelfs 100 GB groot. Voor het verfijnen van zulke grote modellen zijn instances nodig met een aanzienlijk hoog CUDA-geheugen. Bovendien kan het trainen van deze modellen erg traag zijn vanwege de grootte van het model. Voor een efficiënte afstemming gebruiken we daarom de volgende optimalisaties:
- Aanpassing op lage rang (LoRA) – Dit is een soort parameter-efficiënte fijnafstelling (PEFT) voor efficiënte fijnafstelling van grote modellen. Met deze methode bevriest u het hele model en voegt u slechts een kleine set aanpasbare parameters of lagen toe aan het model. In plaats van alle 7 miljard parameters voor Llama 2 7B te trainen, kunt u bijvoorbeeld minder dan 1% van de parameters verfijnen. Dit helpt bij het aanzienlijk verminderen van de geheugenbehoefte, omdat u slechts gradiënten, optimalisatiestatussen en andere trainingsgerelateerde informatie voor slechts 1% van de parameters hoeft op te slaan. Bovendien helpt dit bij het verminderen van de trainingstijd en de kosten. Voor meer details over deze methode, zie LoRA: aanpassing op laag niveau van grote taalmodellen.
- Int8-kwantisering – Zelfs met optimalisaties zoals LoRA zijn modellen zoals Llama 70B nog steeds te groot om te trainen. Om de geheugenvoetafdruk tijdens de training te verkleinen, kunt u tijdens de training Int8-kwantisering gebruiken. Kwantisering vermindert doorgaans de precisie van gegevenstypen met drijvende komma. Hoewel dit het geheugen dat nodig is om modelgewichten op te slaan, vermindert, verslechtert het de prestatie als gevolg van informatieverlies. Int8-kwantisering gebruikt slechts een kwart precisie, maar leidt niet tot prestatieverlies omdat de bits niet simpelweg worden weggelaten. Het rondt de gegevens af van het ene type naar het andere. Raadpleeg voor meer informatie over Int8-kwantisering LLM.int8(): 8-bit matrixvermenigvuldiging voor transformatoren op schaal.
- Volledig gedeelde gegevens parallel (FSDP) – Dit is een type data-parallel trainingsalgoritme dat de parameters van het model verdeelt over data-parallelle werkers en optioneel een deel van de trainingsberekening naar de CPU's kan overbrengen. Hoewel de parameters over verschillende GPU's zijn verdeeld, is de berekening van elke microbatch lokaal voor de GPU-werknemer. Het verdeelt parameters op uniformere wijze en behaalt geoptimaliseerde prestaties via overlappende communicatie en berekeningen tijdens de training.
De volgende tabel vat de details van elk model met verschillende instellingen samen.
| Model | Standaardinstelling | LORA + FSDP | LORA + Geen FSDP | Int8 kwantisering + LORA + geen FSDP |
| Code Lama 2 7B | LORA + FSDP | Ja | Ja | Ja |
| Code Lama 2 13B | LORA + FSDP | Ja | Ja | Ja |
| Code Lama 2 34B | INT8 + LORA + GEEN FSDP | Nee | Nee | Ja |
| Code Lama 2 70B | INT8 + LORA + GEEN FSDP | Nee | Nee | Ja |
Het verfijnen van lamamodellen is gebaseerd op de onderstaande scripts GitHub repo.
Ondersteunde hyperparameters voor training
De verfijning van Code Llama 2 ondersteunt een aantal hyperparameters, die elk van invloed kunnen zijn op de geheugenvereiste, trainingssnelheid en prestaties van het verfijnde model:
- tijdperk – Het aantal passages dat het algoritme voor fijnafstemming door de trainingsgegevensset voert. Moet een geheel getal groter dan 1 zijn. De standaardwaarde is 5.
- leertempo – De snelheid waarmee de modelgewichten worden bijgewerkt na het doornemen van elke reeks trainingsvoorbeelden. Moet een positieve float groter dan 0 zijn. De standaardwaarde is 1e-4.
- instructie_afgestemd – Of het model al dan niet via instructie moet worden getraind. Moet zijn
TrueorFalse. Standaard isFalse. - per_device_train_batch_size – De batchgrootte per GPU-kern/CPU voor training. Moet een positief geheel getal zijn. Standaard is 4.
- per_device_eval_batch_size – De batchgrootte per GPU-kern/CPU voor evaluatie. Moet een positief geheel getal zijn. Standaard is 1.
- max_train_samples – Voor foutopsporingsdoeleinden of snellere training verkort u het aantal trainingsvoorbeelden tot deze waarde. Waarde -1 betekent dat alle trainingsvoorbeelden worden gebruikt. Moet een positief geheel getal of -1 zijn. De standaardwaarde is -1.
- max_val_monsters – Voor foutopsporingsdoeleinden of snellere training kunt u het aantal validatievoorbeelden afkappen tot deze waarde. Waarde -1 betekent dat alle validatiemonsters worden gebruikt. Moet een positief geheel getal of -1 zijn. De standaardwaarde is -1.
- max_invoer_lengte – Maximale totale lengte van de invoerreeks na tokenisatie. Reeksen die langer zijn, worden afgekapt. Als -1,
max_input_lengthis ingesteld op het minimum van 1024 en de maximale modellengte gedefinieerd door de tokenizer. Indien ingesteld op een positieve waarde,max_input_lengthis ingesteld op het minimum van de opgegeven waarde en demodel_max_lengthgedefinieerd door de tokenizer. Moet een positief geheel getal of -1 zijn. De standaardwaarde is -1. - validatie_split_ratio – Als validatiekanaal is
nonemoet de verhouding tussen de treinvalidatie en de treingegevens tussen 0 en 1 liggen. De standaardwaarde is 0.2. - train_data_split_seed – Als er geen validatiegegevens aanwezig zijn, wordt hiermee de willekeurige opsplitsing van de invoertrainingsgegevens naar trainings- en validatiegegevens die door het algoritme worden gebruikt, opgelost. Moet een geheel getal zijn. Standaard is 0.
- preprocessing_num_workers – Het aantal processen dat moet worden gebruikt voor voorbewerking. Als
None, wordt het hoofdproces gebruikt voor voorbewerking. Standaard isNone. - lora_r – Lora R. Moet een positief geheel getal zijn. Standaard is 8.
- lora_alpha – Lora Alpha. Moet een positief geheel getal zijn. Standaard is 32
- lora_dropout – Lora Drop-out. moet een positieve float zijn tussen 0 en 1. De standaardwaarde is 0.05.
- int8_kwantisering - Indien
True, is het model geladen met 8-bits precisie voor training. Standaard voor 7B en 13B isFalse. Standaard voor 70B isTrue. - enable_fsdp – Indien True, gebruikt de training FSDP. De standaardinstelling voor 7B en 13B is True. De standaardinstelling voor 70B is False. Let daar op
int8_quantizationwordt niet ondersteund door FSDP.
Houd bij het kiezen van de hyperparameters rekening met het volgende:
- omgeving
int8_quantization=Truevermindert de geheugenbehoefte en leidt tot een snellere training. - Afnemende
per_device_train_batch_sizeenmax_input_lengthvermindert de geheugenbehoefte en kan daarom op kleinere instanties worden uitgevoerd. Het instellen van zeer lage waarden kan echter de trainingstijd verlengen. - Als u Int8-kwantisering niet gebruikt (
int8_quantization=False), gebruik FSDP (enable_fsdp=True) voor snellere en efficiëntere training.
Ondersteunde exemplaartypen voor training
De volgende tabel bevat een overzicht van de ondersteunde exemplaartypen voor het trainen van verschillende modellen.
| Model | Standaard instantietype | Ondersteunde exemplaartypen |
| Code Lama 2 7B | ml.g5.12xgroot |
ml.g5.12xgroot, ml.g5.24xgroot, ml.g5.48xgroot, ml.p3dn.24xgroot, ml.g4dn.12xgroot |
| Code Lama 2 13B | ml.g5.12xgroot |
ml.g5.24xgroot, ml.g5.48xgroot, ml.p3dn.24xgroot, ml.g4dn.12xgroot |
| Code Lama 2 70B | ml.g5.48xgroot |
ml.g5.48xgroot ml.p4d.24xgroot |
Houd bij het kiezen van het exemplaartype rekening met het volgende:
- G5-instances bieden de meest efficiënte training onder de ondersteunde instancetypen. Als u G5-instanties beschikbaar heeft, moet u deze daarom gebruiken.
- De trainingstijd hangt grotendeels af van de hoeveelheid GPU's en het beschikbare CUDA-geheugen. Daarom is training op instances met hetzelfde aantal GPU's (bijvoorbeeld ml.g5.2xlarge en ml.g5.4xlarge) ongeveer hetzelfde. Daarom kunt u de goedkopere instantie gebruiken voor training (ml.g5.2xlarge).
- Wanneer u p3-instanties gebruikt, wordt de training uitgevoerd met een precisie van 32 bits, omdat bfloat16 niet wordt ondersteund op deze instanties. Daarom zal de trainingstaak de dubbele hoeveelheid CUDA-geheugen verbruiken bij het trainen op p3-instanties vergeleken met g5-instanties.
Voor meer informatie over de kosten van training per exemplaar, raadpleegt u Amazon EC2 G5-instanties.
Evaluatie
Evaluatie is een belangrijke stap om de prestaties van verfijnde modellen te beoordelen. We presenteren zowel kwalitatieve als kwantitatieve evaluaties om de verbetering van verfijnde modellen ten opzichte van niet-verfijnde modellen aan te tonen. Bij kwalitatieve evaluatie laten we een voorbeeldreactie zien van zowel verfijnde als niet-verfijnde modellen. Bij kwantitatieve evaluatie gebruiken we MenselijkEval, een testpakket ontwikkeld door OpenAI om Python-code te genereren om de mogelijkheden voor het produceren van correcte en nauwkeurige resultaten te testen. De HumanEval-repository valt onder een MIT-licentie. We hebben Python-varianten van alle Code LIama-modellen verfijnd over verschillende formaten (Code LIama Python 7B, 13B, 34B en 70B op de Dolphin Coder-gegevensset), en presenteer de evaluatieresultaten in de volgende secties.
Kwalitatieve evaluatie
Nu uw verfijnde model is geïmplementeerd, kunt u het eindpunt gaan gebruiken om code te genereren. In het volgende voorbeeld presenteren we antwoorden van zowel basis- als verfijnde Code LIama 34B Python-varianten op een testvoorbeeld in de Dolphin Coder-gegevensset:
Het verfijnde Code Llama-model genereert niet alleen de code voor de voorgaande vraag, maar genereert ook een gedetailleerde uitleg van de aanpak en een pseudocode.
Code Llama 34b Python niet-afgestemde respons:
Code Llama 34B Python verfijnde respons
Grond waarheid
Interessant is dat onze verfijnde versie van Code Llama 34B Python een dynamische, op programmeren gebaseerde oplossing biedt voor de langste palindromische substring, die verschilt van de oplossing die in de grondwaarheid van het geselecteerde testvoorbeeld wordt geboden. Ons verfijnde model redeneert en legt de op dynamisch programmeren gebaseerde oplossing in detail uit. Aan de andere kant hallucineert het niet-afgestemde model potentiële outputs direct na de print statement (weergegeven in de linkercel) omdat de output axyzzyx is niet het langste palindroom in de gegeven string. In termen van tijdscomplexiteit is de dynamische programmeeroplossing over het algemeen beter dan de oorspronkelijke aanpak. De dynamische programmeeroplossing heeft een tijdscomplexiteit van O(n^2), waarbij n de lengte van de invoerreeks is. Dit is efficiënter dan de initiële oplossing uit het niet-gefinetunede model, dat ook een kwadratische tijdscomplexiteit van O(n^2) had, maar met een minder geoptimaliseerde aanpak.
Dit ziet er veelbelovend uit! Vergeet niet dat we de Code LIama Python-variant alleen hebben verfijnd met 10% van de Dolphin Coder-gegevensset. Er valt nog veel meer te ontdekken!
Ondanks de grondige instructies in het antwoord moeten we nog steeds de juistheid van de Python-code in de oplossing onderzoeken. Vervolgens gebruiken we een evaluatiekader genaamd Menselijke evaluatie om integratietests uit te voeren op de gegenereerde reactie van Code LIama om de kwaliteit ervan systematisch te onderzoeken.
Kwantitatieve evaluatie met HumanEval
HumanEval is een evaluatieharnas voor het evalueren van de probleemoplossende capaciteiten van een LLM voor op Python gebaseerde codeerproblemen, zoals beschreven in het artikel Evaluatie van grote taalmodellen die zijn getraind in code. Concreet bestaat het uit 164 originele op Python gebaseerde programmeerproblemen die het vermogen van een taalmodel beoordelen om code te genereren op basis van verstrekte informatie zoals functiehandtekening, docstring, body en unit-tests.
Voor elke op Python gebaseerde programmeervraag sturen we deze naar een Code LIama-model dat is geïmplementeerd op een SageMaker-eindpunt om k antwoorden te krijgen. Vervolgens voeren we elk van de k antwoorden uit op de integratietests in de HumanEval-repository. Als een van de k antwoorden de integratietests doorstaat, beschouwen we dat testgeval als geslaagd; anders mislukt. Vervolgens herhalen we het proces om de verhouding van succesvolle cases te berekenen als de uiteindelijke evaluatiescore pass@k. Volgens de standaardpraktijk stellen we k in onze evaluatie in op 1, om slechts één antwoord per vraag te genereren en te testen of het de integratietest doorstaat.
Het volgende is een voorbeeldcode om de HumanEval-repository te gebruiken. U hebt toegang tot de dataset en kunt één antwoord genereren met behulp van een SageMaker-eindpunt. Voor meer informatie, zie het notitieboekje in de GitHub-repository.
De volgende tabel toont de verbeteringen van de verfijnde Code LIama Python-modellen ten opzichte van de niet-verfijnde modellen in verschillende modelgroottes. Om de juistheid te garanderen, implementeren we ook de niet-verfijnde Code LIama-modellen in SageMaker-eindpunten en doorlopen we Human Eval-evaluaties. De pas@1 nummers (de eerste rij in de volgende tabel) komen overeen met de gerapporteerde nummers in de Code Llama-onderzoekspaper. De gevolgtrekkingsparameters worden consequent ingesteld als "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
Zoals we uit de resultaten kunnen zien, vertonen alle verfijnde Code LIama Python-varianten een aanzienlijke verbetering ten opzichte van de niet-gefinetunede modellen. Met name Code LIama Python 70B presteert ongeveer 12% beter dan het niet-gefinetunede model.
| . | 7B Python | 13B Python | 34B | 34B Python | 70B Python |
| Prestaties van vooraf getraind model (pass@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| Verfijnde modelprestaties (pass@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
Nu kunt u Code LIama-modellen proberen te verfijnen op uw eigen dataset.
Opruimen
Als u besluit dat u het SageMaker-eindpunt niet langer actief wilt houden, kunt u het verwijderen met AWS SDK voor Python (Boto3), AWS-opdrachtregelinterface (AWS CLI) of SageMaker-console. Voor meer informatie, zie Eindpunten en bronnen verwijderen. Bovendien kunt u: sluit de SageMaker Studio-bronnen af die niet langer nodig zijn.
Conclusie
In dit bericht hebben we het verfijnen van Meta's Code Llama 2-modellen besproken met behulp van SageMaker JumpStart. We hebben laten zien dat je de SageMaker JumpStart-console in SageMaker Studio of de SageMaker Python SDK kunt gebruiken om deze modellen te verfijnen en te implementeren. We hebben ook de verfijningstechniek, exemplaartypen en ondersteunde hyperparameters besproken. Daarnaast hebben we aanbevelingen gedaan voor een geoptimaliseerde training op basis van verschillende tests die we hebben uitgevoerd. Zoals we uit deze resultaten van het afstemmen van drie modellen over twee datasets kunnen zien, verbetert het afstemmen de samenvatting in vergelijking met niet-verfijnde modellen. Als volgende stap kunt u proberen deze modellen op uw eigen dataset af te stemmen met behulp van de code in de GitHub-repository om de resultaten voor uw gebruiksscenario's te testen en te benchmarken.
Over de auteurs
 Dr Xin Huang is een Senior Applied Scientist voor Amazon SageMaker JumpStart en Amazon SageMaker ingebouwde algoritmen. Hij richt zich op het ontwikkelen van schaalbare machine learning-algoritmen. Zijn onderzoeksinteresses liggen op het gebied van natuurlijke taalverwerking, verklaarbaar diep leren op tabelgegevens en robuuste analyse van niet-parametrische ruimte-tijd clustering. Hij heeft veel artikelen gepubliceerd in ACL-, ICDM-, KDD-conferenties en Royal Statistical Society: Series A.
Dr Xin Huang is een Senior Applied Scientist voor Amazon SageMaker JumpStart en Amazon SageMaker ingebouwde algoritmen. Hij richt zich op het ontwikkelen van schaalbare machine learning-algoritmen. Zijn onderzoeksinteresses liggen op het gebied van natuurlijke taalverwerking, verklaarbaar diep leren op tabelgegevens en robuuste analyse van niet-parametrische ruimte-tijd clustering. Hij heeft veel artikelen gepubliceerd in ACL-, ICDM-, KDD-conferenties en Royal Statistical Society: Series A.
 Vishaal Yalamanchali is een Startup Solutions Architect die werkt met beginnende generatieve AI-, robotica- en autonome voertuigbedrijven. Vishaal werkt samen met zijn klanten om geavanceerde ML-oplossingen te leveren en is persoonlijk geïnteresseerd in versterkend leren, LLM-evaluatie en het genereren van code. Vóór AWS was Vishaal een student aan de UCI, gericht op bio-informatica en intelligente systemen.
Vishaal Yalamanchali is een Startup Solutions Architect die werkt met beginnende generatieve AI-, robotica- en autonome voertuigbedrijven. Vishaal werkt samen met zijn klanten om geavanceerde ML-oplossingen te leveren en is persoonlijk geïnteresseerd in versterkend leren, LLM-evaluatie en het genereren van code. Vóór AWS was Vishaal een student aan de UCI, gericht op bio-informatica en intelligente systemen.
 Meenakshisundaram Thandavarayan werkt voor AWS als AI/ML Specialist. Hij heeft een passie voor het ontwerpen, creëren en promoten van mensgerichte data- en analyse-ervaringen. Meena richt zich op het ontwikkelen van duurzame systemen die meetbare, concurrentievoordelen opleveren voor strategische klanten van AWS. Meena is een verbinder en ontwerpdenker en streeft ernaar bedrijven naar nieuwe manieren van werken te leiden door middel van innovatie, incubatie en democratisering.
Meenakshisundaram Thandavarayan werkt voor AWS als AI/ML Specialist. Hij heeft een passie voor het ontwerpen, creëren en promoten van mensgerichte data- en analyse-ervaringen. Meena richt zich op het ontwikkelen van duurzame systemen die meetbare, concurrentievoordelen opleveren voor strategische klanten van AWS. Meena is een verbinder en ontwerpdenker en streeft ernaar bedrijven naar nieuwe manieren van werken te leiden door middel van innovatie, incubatie en democratisering.
 Dr Ashish Khetan is een Senior Applied Scientist met ingebouwde algoritmen van Amazon SageMaker en helpt bij het ontwikkelen van algoritmen voor machine learning. Hij promoveerde aan de Universiteit van Illinois in Urbana-Champaign. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie, en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
Dr Ashish Khetan is een Senior Applied Scientist met ingebouwde algoritmen van Amazon SageMaker en helpt bij het ontwikkelen van algoritmen voor machine learning. Hij promoveerde aan de Universiteit van Illinois in Urbana-Champaign. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie, en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

