Een van de meest voorkomende toepassingen van generatieve AI en grote taalmodellen (LLM’s) is het beantwoorden van vragen op basis van een specifiek extern kenniscorpus. Retrieval-Augmented Generation (RAG) is een populaire techniek voor het bouwen van vraag-antwoordsystemen die gebruik maken van een externe kennisbank. Raadpleeg voor meer informatie Bouw een krachtige bot voor het beantwoorden van vragen met Amazon SageMaker, Amazon OpenSearch Service, Streamlit en LangChain.
Traditionele RAG-systemen hebben vaak moeite om bevredigende antwoorden te geven wanneer gebruikers vage of dubbelzinnige vragen stellen zonder voldoende context te bieden. Dit leidt tot nutteloze antwoorden zoals 'Ik weet het niet' of onjuiste, verzonnen antwoorden van een LLM. In dit bericht demonstreren we een oplossing om de kwaliteit van antwoorden in dergelijke gebruiksgevallen te verbeteren ten opzichte van traditionele RAG-systemen door een interactieve verduidelijkingscomponent te introduceren met behulp van LangChain.
Het belangrijkste idee is om het RAG-systeem in staat te stellen een conversatiedialoog met de gebruiker aan te gaan wanneer de initiële vraag onduidelijk is. Door verhelderende vragen te stellen, de gebruiker om meer details te vragen en de nieuwe contextuele informatie op te nemen, kan het RAG-systeem de noodzakelijke context verzamelen om een accuraat, nuttig antwoord te geven, zelfs op basis van een dubbelzinnige initiële gebruikersvraag.
Overzicht oplossingen
Om onze oplossing te demonstreren, hebben we een Amazon Kendra-index (samengesteld uit de AWS online documentatie voor Amazon Kendra, Amazon-Lex en Amazon Sage Maker), een LangChain-agent met een Amazonebodem LLM, en een eenvoudig Gestroomlijnd gebruikersomgeving.
Voorwaarden
Om deze demo in uw AWS-account uit te voeren, moet u aan de volgende vereisten voldoen:
- Kloon het GitHub-repository en volg de stappen die worden uitgelegd in de README.
- Implementeer een Amazon Kendra-index in uw AWS-account. U kunt het volgende gebruiken AWS CloudFormatie sjabloon om een nieuwe index te maken of een reeds actieve index te gebruiken. Als u een nieuwe index implementeert, kunnen er extra kosten aan uw factuur worden toegevoegd. Daarom raden we u aan deze te verwijderen als u deze niet langer nodig heeft. Houd er rekening mee dat de gegevens in de index naar het geselecteerde Amazon Bedrock Foundation-model (FM) worden verzonden.
- De LangChain-agent vertrouwt op FM's die beschikbaar zijn in Amazon Bedrock, maar dit kan worden aangepast aan elke andere LLM die LangChain ondersteunt.
- Als u wilt experimenteren met de voorbeeldfrontend die met de code wordt gedeeld, kunt u gebruiken Amazon SageMaker Studio om een lokale implementatie van de Streamlit-app uit te voeren. Houd er rekening mee dat het uitvoeren van deze demo enkele extra kosten met zich meebrengt.
Implementeer de oplossing
Traditionele RAG-middelen zijn vaak als volgt ontworpen. De agent heeft toegang tot een tool die wordt gebruikt om documenten op te halen die relevant zijn voor een gebruikersquery. De opgehaalde documenten worden vervolgens in de LLM-prompt ingevoegd, zodat de agent op basis van de opgehaalde documentfragmenten een antwoord kan geven.
In dit bericht implementeren we een agent die toegang heeft tot KendraRetrievalTool en ontleent relevante documenten aan de Amazon Kendra-index en geeft het antwoord gegeven de opgehaalde context:
Verwijs naar de GitHub repo voor de volledige implementatiecode. Voor meer informatie over traditionele RAG-gebruiksscenario's raadpleegt u Vraag beantwoorden met behulp van Retrieval Augmented Generation met basismodellen in Amazon SageMaker JumpStart.
Beschouw het volgende voorbeeld. Een gebruiker vraagt: "Hoeveel GPU's heeft mijn EC2-instantie?" Zoals in de volgende schermafbeelding te zien is, zoekt de agent naar het antwoord met behulp van KendraRetrievalTool. De agent realiseert zich echter dat hij niet weet welke Amazon Elastic Compute-cloud (Amazon EC2) instantietype waarnaar de gebruiker verwijst en biedt daarom geen nuttig antwoord aan de gebruiker, wat leidt tot een slechte klantervaring.

Om dit probleem aan te pakken, definiëren we een extra aangepast hulpmiddel genaamd AskHumanTool en geef deze aan de makelaar. De tool instrueert een LLM om de gebruikersvraag te lezen en indien nodig een vervolgvraag aan de gebruiker te stellen KendraRetrievalTool kan geen goed antwoord geven. Dit impliceert dat de agent nu twee instrumenten tot zijn beschikking heeft:
Hierdoor kan de agent de vraag verfijnen of aanvullende context bieden die nodig is om op de prompt te reageren. Om de agent te begeleiden bij het gebruik AskHumanTool Voor dit doeleinde, we geven de volgende toolbeschrijving aan de LLM:
Gebruik deze tool als u geen antwoord vindt met de KendraRetrievalTool. Vraag de mens om de vraag te verduidelijken of de ontbrekende informatie te verstrekken. De input moet een vraag voor de mens zijn.
Zoals geïllustreerd in de volgende schermafbeelding, door gebruik te maken van AskHumanTool, identificeert de agent nu vage gebruikersvragen en stuurt een vervolgvraag terug naar de gebruiker waarin wordt gevraagd om op te geven welk EC2-instantietype wordt gebruikt.

Nadat de gebruiker het instantietype heeft opgegeven, neemt de agent het aanvullende antwoord op in de context van de oorspronkelijke vraag, voordat het juiste antwoord wordt afgeleid.
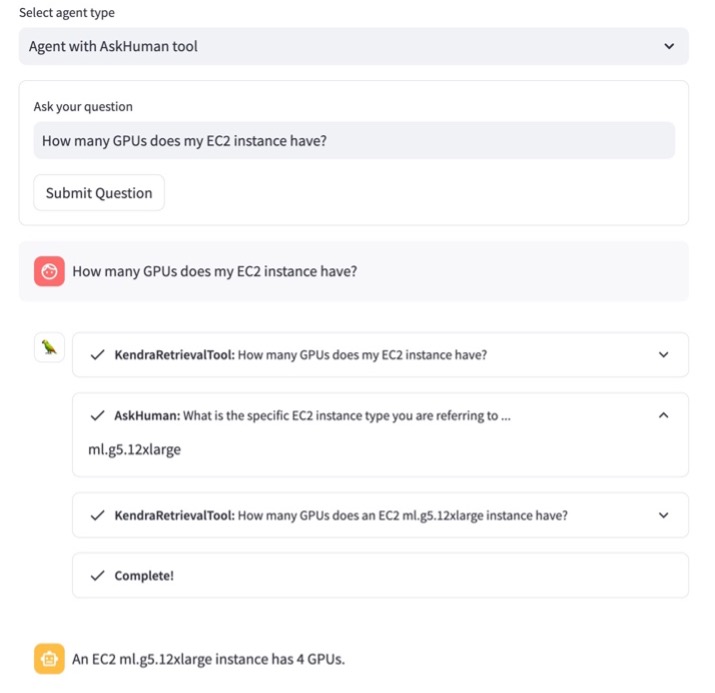
Houd er rekening mee dat de agent nu kan beslissen of hij deze wil gebruiken KendraRetrievalTool om de relevante documenten op te halen of een verduidelijkende vraag te stellen via AskHumanTool. De beslissing van de agent is gebaseerd op de vraag of de documentfragmenten die in de prompt zijn ingevoegd, voldoende zijn om het uiteindelijke antwoord te geven. Dankzij deze flexibiliteit kan het RAG-systeem verschillende vragen ondersteunen die een gebruiker kan indienen, inclusief zowel goed geformuleerde als vage vragen.
In ons voorbeeld is de volledige agentworkflow als volgt:
- De gebruiker doet een verzoek aan de RAG-app en vraagt: "Hoeveel GPU's heeft mijn EC2-instantie?"
- De agent gebruikt de LLM om te beslissen welke actie moet worden ondernomen: Vind relevante informatie om het verzoek van de gebruiker te beantwoorden door de
KendraRetrievalTool. - Met behulp van de tool haalt de agent informatie op uit de Amazon Kendra-index. De fragmenten uit de opgehaalde documenten worden ingevoegd in de agentprompt.
- De LLM (van de agent) leidt hieruit af dat de opgehaalde documenten van Amazon Kendra niet nuttig zijn of niet voldoende context bevatten om een antwoord te geven op het verzoek van de gebruiker.
- De agent gebruikt
AskHumanToolom een vervolgvraag te formuleren: “Wat is het specifieke EC2-instantietype dat u gebruikt? Als u het instantietype kent, kunt u bepalen hoeveel GPU’s er zijn.” De gebruiker geeft het antwoord “ml.g5.12xlarge” en de agent beltKendraRetrievalToolnogmaals, maar deze keer wordt het EC2-instantietype toegevoegd aan de zoekopdracht. - Nadat hij de stappen 2 tot en met 4 opnieuw heeft doorlopen, komt de agent met een nuttig antwoord en stuurt dit terug naar de gebruiker.
Het volgende diagram illustreert deze workflow.
Het voorbeeld dat in dit bericht wordt beschreven, illustreert hoe de toevoeging van de custom AskHumanTool stelt de agent in staat om verduidelijkende details op te vragen wanneer dat nodig is. Dit kan de betrouwbaarheid en nauwkeurigheid van de antwoorden verbeteren, wat leidt tot een betere klantervaring in een groeiend aantal RAG-applicaties in verschillende domeinen.
Opruimen
Om onnodige kosten te voorkomen, verwijdert u de Amazon Kendra-index als u deze niet meer gebruikt en sluit u de SageMaker Studio-instantie af als u deze hebt gebruikt om de demo uit te voeren.
Conclusie
In dit bericht hebben we laten zien hoe we een betere klantervaring voor de gebruikers van een RAG-systeem mogelijk kunnen maken door een aangepaste tool toe te voegen waarmee het systeem een gebruiker om een ontbrekend stukje informatie kan vragen. Deze interactieve conversatiebenadering vertegenwoordigt een veelbelovende richting voor het verbeteren van traditionele RAG-architecturen. Het vermogen om vaagheden op te lossen door middel van een dialoog kan leiden tot het leveren van bevredigender antwoorden vanuit een kennisbank.
Merk op dat deze aanpak niet beperkt is tot RAG-gebruiksscenario's; je kunt het gebruiken in andere generatieve AI-gebruiksscenario's die afhankelijk zijn van een agent in de kern, waar een gewoonte bestaat AskHumanTool kan toegevoegd worden.
Voor meer informatie over het gebruik van Amazon Kendra met generatieve AI raadpleegt u Bouw snel zeer nauwkeurige generatieve AI-applicaties op bedrijfsgegevens met behulp van Amazon Kendra, LangChain en grote taalmodellen.
Over de auteurs
 Antonia Wiebeler is datawetenschapper bij het AWS Genative AI Innovation Center, waar ze graag proofs of concept voor klanten bouwt. Haar passie is onderzoeken hoe generatieve AI echte problemen kan oplossen en waarde voor klanten kan creëren. Hoewel ze niet aan het programmeren is, houdt ze van hardlopen en meedoen aan triatlons.
Antonia Wiebeler is datawetenschapper bij het AWS Genative AI Innovation Center, waar ze graag proofs of concept voor klanten bouwt. Haar passie is onderzoeken hoe generatieve AI echte problemen kan oplossen en waarde voor klanten kan creëren. Hoewel ze niet aan het programmeren is, houdt ze van hardlopen en meedoen aan triatlons.
 Nikita Kozodoi is een Applied Scientist bij het AWS Generative AI Innovation Center, waar hij ML-oplossingen ontwikkelt om klantproblemen in verschillende sectoren op te lossen. In zijn rol richt hij zich op het bevorderen van generatieve AI om uitdagingen in de echte wereld aan te pakken. In zijn vrije tijd houdt hij van beachvolleybal en lezen.
Nikita Kozodoi is een Applied Scientist bij het AWS Generative AI Innovation Center, waar hij ML-oplossingen ontwikkelt om klantproblemen in verschillende sectoren op te lossen. In zijn rol richt hij zich op het bevorderen van generatieve AI om uitdagingen in de echte wereld aan te pakken. In zijn vrije tijd houdt hij van beachvolleybal en lezen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/improve-llm-responses-in-rag-use-cases-by-interacting-with-the-user/

