Amazon-Lex is een service waarmee u snel en eenvoudig conversatiebots ("chatbots"), virtuele agenten en interactieve voice response (IVR)-systemen kunt bouwen voor toepassingen zoals Amazon Connect.
Kunstmatige intelligentie (AI) en machine learning (ML) zijn al meer dan 20 jaar een focus voor Amazon, en veel van de mogelijkheden die klanten gebruiken met Amazon worden aangestuurd door ML. Tegenwoordig veranderen grote taalmodellen (LLM's) de manier waarop ontwikkelaars en ondernemingen historisch complexe uitdagingen met betrekking tot het begrijpen van natuurlijke talen (NLU) oplossen. wij hebben aangekondigd Amazonebodem onlangs, dat toegang tot het basismodel democratiseert voor ontwikkelaars om eenvoudig generatieve, op AI gebaseerde applicaties te bouwen en te schalen, met behulp van bekende AWS-tools en -mogelijkheden. Een van de uitdagingen waarmee ondernemingen worden geconfronteerd, is om hun bedrijfskennis op te nemen in LLM's om nauwkeurige en relevante antwoorden te geven. Wanneer ze effectief worden benut, kunnen bedrijfskennisbanken worden gebruikt om op maat gemaakte selfservice- en geassisteerde service-ervaringen te leveren, door informatie te leveren die klanten helpt om zelfstandig problemen op te lossen en/of de kennis van een agent te vergroten. Tegenwoordig kan een botontwikkelaar op een aantal manieren selfservice-ervaringen verbeteren zonder LLM's te gebruiken. Ten eerste door intenties, voorbeelduitingen en antwoorden te creëren, waardoor alle verwachte gebruikersvragen binnen een Amazon Lex-bot worden behandeld. Ten tweede kunnen ontwikkelaars ook bots integreren met zoekoplossingen, die documenten kunnen indexeren die zijn opgeslagen in een breed scala aan opslagplaatsen en het meest relevante document kunnen vinden om de vraag van hun klant te beantwoorden. Deze methoden zijn effectief, maar vereisen ontwikkelaarsbronnen waardoor het moeilijk wordt om aan de slag te gaan.
Een van de voordelen van LLM's is de mogelijkheid om relevante en boeiende conversatie-selfservice-ervaringen te creëren. Ze doen dit door gebruik te maken van de kennisbank(en) van de onderneming en nauwkeurigere en contextuelere antwoorden te geven. Deze blogpost introduceert een krachtige oplossing voor het uitbreiden van Amazon Lex met op LLM gebaseerde FAQ-functies met behulp van de Retrieval Augmented Generation (RAG). We zullen bekijken hoe de RAG-benadering de antwoorden op veelgestelde vragen over Amazon Lex verbetert met behulp van uw bedrijfsgegevensbronnen. Daarnaast demonstreren we ook de integratie van Amazon Lex met LlamaIndex, een open-source dataframework dat kennisbron- en formaatflexibiliteit biedt aan de botontwikkelaar. Naarmate een botontwikkelaar meer vertrouwen krijgt in het gebruik van een LlamaIndex om LLM-integratie te verkennen, kunnen ze de mogelijkheden van Amazon Lex verder opschalen. Ze kunnen ook gebruikmaken van enterprise search-services zoals Amazon Kendra, dat standaard is geïntegreerd met Amazon Lex.
In deze oplossing demonstreren we de praktische toepassing van een Amazon Lex-chatbot met op LLM gebaseerde RAG-verbetering. Wij gebruiken de Zappos klantondersteuning use case als voorbeeld om de effectiviteit van deze oplossing te demonstreren, die de gebruiker door een verbeterde FAQ-ervaring leidt (met LLM), in plaats van hem naar fallback te leiden (standaard, zonder LLM).
Overzicht oplossingen
RAG combineert de sterke punten van traditionele retrieval-gebaseerde en generatieve AI-gebaseerde benaderingen van Q&A-systemen. Deze methodologie maakt gebruik van de kracht van grote taalmodellen, zoals Amazone Titan of open-sourcemodellen (bijvoorbeeld Falcon), om generatieve taken uit te voeren in ophaalsystemen. Het houdt ook effectiever en efficiënter rekening met de semantische context van opgeslagen documenten.
RAG begint met een eerste ophaalstap om relevante documenten uit een collectie op te halen op basis van de vraag van de gebruiker. Vervolgens gebruikt het een taalmodel om een antwoord te genereren door rekening te houden met zowel de opgehaalde documenten als de oorspronkelijke vraag. Door RAG te integreren in Amazon Lex, kunnen we nauwkeurige en uitgebreide antwoorden geven op vragen van gebruikers, wat resulteert in een meer boeiende en bevredigende gebruikerservaring.
De RAG-benadering vereist documentopname, zodat inbedding kan worden gemaakt om op LLM gebaseerd zoeken mogelijk te maken. Het volgende diagram laat zien hoe het opnameproces de insluitingen maakt die vervolgens door de chatbot worden gebruikt tijdens fallback om de vraag van de klant te beantwoorden.
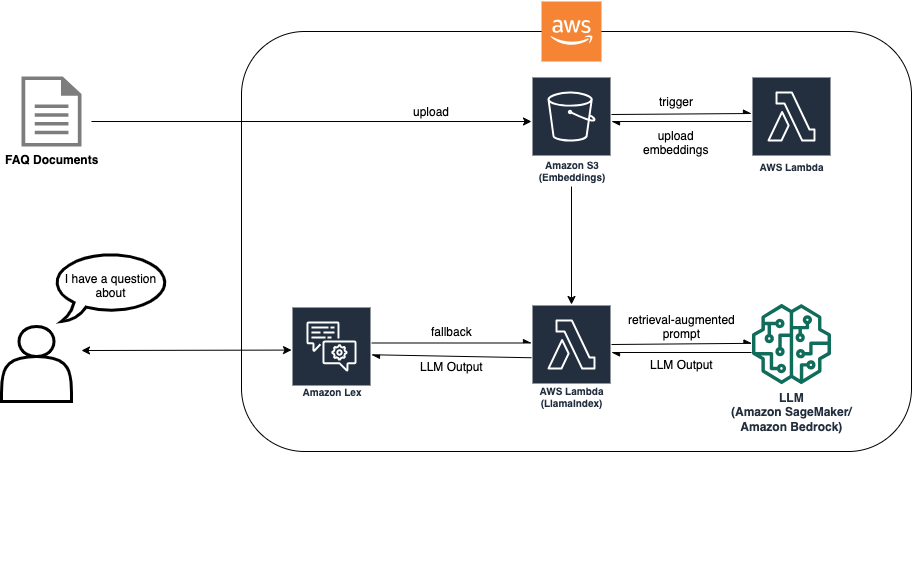
Met deze oplossingsarchitectuur moet u de meest geschikte LLM kiezen voor uw use case. Het biedt ook een eindpuntkeuze tussen Amazon Bedrock (in beperkte preview) en modellen die worden gehost op Amazon SageMaker JumpStart, wat extra LLM-flexibiliteit biedt.
Het document wordt geüpload naar een Amazon eenvoudige opslagservice (Amazon S3) emmer. Aan de S3-bucket is een gebeurtenislistener gekoppeld die een AWS Lambda functie bij wijzigingen aan de emmer. De gebeurtenislistener neemt het nieuwe document op en plaatst de insluitingen in een andere S3-bucket. De inbeddingen worden vervolgens gebruikt door de RAG-implementatie in de Amazon Lex-bot tijdens de fallback-intentie om de vraag van de klant te beantwoorden. Het volgende diagram toont de architectuur van hoe een FAQ-bot binnen Lex kan worden uitgebreid met LLM's en RAG.
Laten we eens kijken hoe we RAG op basis van LlamaIndex kunnen integreren in een Amazon Lex-bot. We bieden codevoorbeelden en een AWS Cloud-ontwikkelingskit (AWS CDK) importeren om u te helpen bij het opzetten van de integratie. U vindt de codevoorbeelden in ons GitHub-repository. De volgende secties bevatten een stapsgewijze handleiding om u te helpen bij het instellen van de omgeving en het implementeren van de benodigde bronnen.
Hoe RAG werkt met Amazon Lex
De stroom van RAG omvat een iteratief proces waarbij de retrievercomponent relevante passages ophaalt, de vraag en passages helpen bij het construeren van de prompt en de generatiecomponent een antwoord produceert. Deze combinatie van ophaal- en generatietechnieken stelt het RAG-model in staat om te profiteren van de sterke punten van beide benaderingen, door nauwkeurige en contextueel geschikte antwoorden te geven op vragen van gebruikers. De workflow biedt de volgende mogelijkheden:
- Retriever-motor – Het RAG-model begint met een retriever-component die verantwoordelijk is voor het ophalen van relevante documenten uit een groot corpus. Deze component gebruikt doorgaans een techniek voor het ophalen van informatie, zoals TF-IDF of BM25, om documenten te rangschikken en te selecteren die waarschijnlijk het antwoord op een bepaalde vraag bevatten. De retriever scant het documentcorpus en haalt een reeks relevante passages op.
- Snelle helper – Nadat de retriever de relevante passages heeft geïdentificeerd, gaat het RAG-model naar het maken ervan. De prompt is een combinatie van de vraag en de opgehaalde passages en dient als aanvullende context voor de prompt, die wordt gebruikt als invoer voor de generatorcomponent. Om de prompt te maken, vult het model de vraag meestal aan met de geselecteerde passages in een specifiek formaat.
- Reactie generatie – De prompt, bestaande uit de vraag en relevante passages, wordt ingevoerd in de generatiecomponent van het RAG-model. De generatiecomponent is meestal een taalmodel dat in staat is om door de prompt heen te redeneren om een samenhangend en relevant antwoord te genereren.
- Laatste reactie – Ten slotte selecteert het RAG-model het hoogst gerangschikte antwoord als uitvoer en presenteert dit als het antwoord op de oorspronkelijke vraag. Het geselecteerde antwoord kan indien nodig verder worden nabewerkt of geformatteerd voordat het wordt teruggestuurd naar de gebruiker. Bovendien maakt de oplossing het filteren van de gegenereerde respons mogelijk als de ophaalresultaten een lage betrouwbaarheidsscore opleveren, wat impliceert dat het waarschijnlijk buiten de distributie (OOD) valt.
LlamaIndex: een open-source dataframework voor LLM-gebaseerde applicaties
In dit bericht demonstreren we de RAG-oplossing op basis van LlamaIndex. LlamaIndex is een open-source dataframework dat speciaal is ontworpen om LLM-gebaseerde applicaties mogelijk te maken. Het biedt een robuuste en schaalbare oplossing voor het beheer van documentverzameling in verschillende formaten. Met LlamaIndex kunnen botontwikkelaars moeiteloos LLM-gebaseerde QA-mogelijkheden (vragen beantwoorden) integreren in hun applicaties, waardoor de complexiteit wordt geëlimineerd die gepaard gaat met het beheer van oplossingen voor grootschalige documentverzamelingen. Bovendien blijkt deze aanpak kosteneffectief te zijn voor kleinere documentopslagplaatsen.
Voorwaarden
U moet de volgende vereisten hebben:
Stel uw ontwikkelomgeving in
De belangrijkste pakketvereisten van derden zijn lama_index en saliemaker sdk. Volg de opgegeven opdrachten in onze De README van de GitHub-repository om uw omgeving goed in te richten.
Implementeer de vereiste resources
Deze stap omvat het maken van een Amazon Lex-bot, S3-buckets en een SageMaker-eindpunt. Bovendien moet u de code in de Docker-afbeeldingsmap Dockeriseren en de afbeeldingen naar Amazon Elastic Container-register (Amazon ECR) zodat het in Lambda kan draaien. Volg de opgegeven opdrachten in onze De README van de GitHub-repository om de diensten in te zetten.
Tijdens deze stap demonstreren we LLM-hosting via SageMaker Deep Learning-containers. Pas de instellingen aan volgens uw rekenbehoeften:
- Model – Om een model te vinden dat aan uw eisen voldoet, kunt u bronnen verkennen zoals de Hugging Face-modelhub. Het biedt een verscheidenheid aan modellen zoals Valk 7B or Vlaai-T5-XXL. Bovendien kunt u gedetailleerde informatie vinden over verschillende officieel ondersteunde modelarchitecturen, zodat u een weloverwogen beslissing kunt nemen. Voor meer informatie over verschillende modeltypes, zie geoptimaliseerde architecturen.
- Model inferentie-eindpunt – Definieer het pad van het model (bijvoorbeeld Falcon 7B), kies uw instantietype (bijvoorbeeld g5.4xlarge) en gebruik kwantisatie (bijvoorbeeld int-8-kwantisatie).Note: Deze oplossing biedt u de flexibiliteit om een ander eindpunt voor modelafleiding te kiezen. Je kan ook gebruiken Amazonebodem, die toegang biedt tot andere LLM's zoals Amazone Titan.Opmerking: Deze oplossing biedt u de flexibiliteit om een ander eindpunt voor modelafleiding te kiezen. U kunt ook Amazon Bedrock gebruiken, dat toegang biedt tot andere LLM's zoals Amazon Titan.
Stel uw documentindex in via LlamaIndex
Upload eerst uw documentgegevens om uw documentindex in te stellen. We gaan ervan uit dat u de bron van uw FAQ-inhoud hebt, zoals een pdf- of tekstbestand.
Nadat de documentgegevens zijn geüpload, start het LlamaIndex-systeem automatisch het proces van het maken van de documentindex. Deze taak wordt uitgevoerd door een Lambda-functie, die de index genereert en opslaat in een S3-bucket.
Om het efficiënt ophalen van relevante informatie mogelijk te maken, configureert u de documentretriever met behulp van de LlamaIndex Retriever Query Engine. Deze engine biedt verschillende aanpassingsopties, zoals de volgende:
- Modellen inbedden – U kunt uw inbeddingsmodel kiezen, zoals Knuffelen Gezicht insluiten.
- Vertrouwensonderbreking – Specificeer een betrouwbaarheidsdrempel om de kwaliteit van ophaalresultaten te bepalen. Als de betrouwbaarheidsscore onder deze drempel valt, kunt u ervoor kiezen antwoorden te geven die buiten het bereik vallen, waarmee wordt aangegeven dat de zoekopdracht buiten het bereik van de geïndexeerde documenten valt.
Test de integratie
Definieer uw botdefinitie met een fallback-intentie en gebruik de Amazon Lex-console om uw veelgestelde vragen te testen. Voor meer details verwijzen wij u naar GitHub-repository. De volgende schermafbeelding toont een voorbeeldgesprek met de bot.


Tips om de efficiëntie van uw bot te vergroten
De volgende tips kunnen de efficiëntie van uw bot mogelijk verder verbeteren:
- Index opslag - Sla uw index op in een S3-bucket of een service met vectordatabasemogelijkheden zoals AmazonOpenSearch. Door cloudgebaseerde opslagoplossingen te gebruiken, kunt u de toegankelijkheid en schaalbaarheid van uw index verbeteren, wat leidt tot snellere ophaaltijden en verbeterde algehele prestaties. Zie ook deze blog post voor een Amazon Lex-bot die gebruikmaakt van een Amazon Kendra zoek oplossing.
- Ophaaloptimalisatie – Experimenteer met verschillende formaten inbeddingsmodellen voor de retriever. De keuze van het inbeddingsmodel kan een aanzienlijke invloed hebben op de invoervereisten van uw LLM. Het vinden van de optimale balans tussen modelgrootte en ophaalprestaties kan resulteren in verbeterde efficiëntie en snellere responstijden.
- Snelle techniek – Experimenteer met verschillende formaten, lengtes en stijlen voor prompts om de prestaties en kwaliteit van de antwoorden van uw bot te optimaliseren.
- LLM-modelselectie – Selecteer het meest geschikte LLM-model voor uw specifieke gebruikssituatie. Houd rekening met factoren zoals modelgrootte, taalmogelijkheden en compatibiliteit met uw toepassingsvereisten. Het kiezen van het juiste LLM-model zorgt voor optimale prestaties en efficiënt gebruik van systeembronnen.
Contactcentergesprekken kunnen variëren van zelfbediening tot live menselijke interactie. Voor use-cases met interacties van mens tot mens via Amazon Connect, kunt u gebruiken Wijsheid om inhoud te zoeken en te vinden in meerdere opslagplaatsen, zoals veelgestelde vragen (FAQ's), wiki's, artikelen en stapsgewijze instructies voor het afhandelen van verschillende problemen van klanten.
Opruimen
Om toekomstige kosten te voorkomen, gaat u verder met het verwijderen van alle bronnen die als onderdeel van deze oefening zijn ingezet. We hebben een script geleverd om het SageMaker-eindpunt correct af te sluiten. Gebruiksgegevens staan in de README. Bovendien, om alle andere bronnen te verwijderen die u kunt uitvoeren cdk destroy in dezelfde map als de andere cdk-opdrachten om alle bronnen in uw stapel ongedaan te maken.
Samengevat
Dit bericht besprak de volgende stappen om Amazon Lex te verbeteren met op LLM gebaseerde QA-functies met behulp van de RAG-strategie en LlamaIndex:
- Installeer de benodigde afhankelijkheden, inclusief LlamaIndex-bibliotheken
- Modelhosting opzetten via Amazon SageMaker of Amazon Bedrock (in beperkte preview)
- Configureer LlamaIndex door een index te maken en deze te vullen met relevante documenten
- Integreer RAG in Amazon Lex door de configuratie aan te passen en RAG te configureren om LlamaIndex te gebruiken voor het ophalen van documenten
- Test de integratie door gesprekken aan te gaan met de chatbot en te observeren hoe hij nauwkeurige antwoorden ophaalt en genereert
Door deze stappen te volgen, kunt u krachtige op LLM gebaseerde QA-mogelijkheden en efficiënte documentindexering naadloos integreren in uw Amazon Lex-chatbot, wat resulteert in nauwkeurigere, uitgebreidere en contextbewustere interacties met gebruikers. Als follow-up nodigen we u ook uit om onze volgende blogpost, waarin wordt onderzocht hoe de Amazon Lex FAQ-ervaring kan worden verbeterd met behulp van URL-opname en LLM's.
Over de auteurs
 Max Henkel Wallace is Software Development Engineer bij AWS Lex. Hij geniet van het gebruik van technologie om het succes van de klant te maximaliseren. Buiten zijn werk is hij gepassioneerd door koken, tijd doorbrengen met vrienden en backpacken.
Max Henkel Wallace is Software Development Engineer bij AWS Lex. Hij geniet van het gebruik van technologie om het succes van de klant te maximaliseren. Buiten zijn werk is hij gepassioneerd door koken, tijd doorbrengen met vrienden en backpacken.
 Lied Feng is een Senior Applied Scientist bij AWS AI Labs, gespecialiseerd in natuurlijke taalverwerking en kunstmatige intelligentie. Haar onderzoek verkent verschillende aspecten van deze gebieden, waaronder modellering van op documenten gebaseerde dialogen, redenering voor taakgerichte dialogen en interactieve tekstgeneratie met behulp van multimodale gegevens.
Lied Feng is een Senior Applied Scientist bij AWS AI Labs, gespecialiseerd in natuurlijke taalverwerking en kunstmatige intelligentie. Haar onderzoek verkent verschillende aspecten van deze gebieden, waaronder modellering van op documenten gebaseerde dialogen, redenering voor taakgerichte dialogen en interactieve tekstgeneratie met behulp van multimodale gegevens.
 Saket Saurabh is een ingenieur bij het AWS Lex-team. Hij werkt aan het verbeteren van de Lex-ontwikkelaarservaring om ontwikkelaars te helpen meer mensachtige chatbots te bouwen. Buiten zijn werk houdt hij van reizen, het ontdekken van verschillende keukens en het leren kennen van verschillende culturen.
Saket Saurabh is een ingenieur bij het AWS Lex-team. Hij werkt aan het verbeteren van de Lex-ontwikkelaarservaring om ontwikkelaars te helpen meer mensachtige chatbots te bouwen. Buiten zijn werk houdt hij van reizen, het ontdekken van verschillende keukens en het leren kennen van verschillende culturen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/enhance-amazon-lex-with-conversational-faq-features-using-llms/

