Een van de meest populaire modellen die vandaag beschikbaar is, is XGBoost. Met de mogelijkheid om verschillende problemen op te lossen, zoals classificatie en regressie, is XGBoost een populaire optie geworden die ook in de categorie van op bomen gebaseerde modellen valt. In dit bericht duiken we diep om te zien hoe Amazon Sage Maker kan deze modellen bedienen met behulp van NVIDIA Triton Inference-server. Realtime inferentieworkloads kunnen verschillende niveaus van vereisten en serviceniveau-overeenkomsten (SLA's) hebben in termen van latentie en doorvoer, en hieraan kan worden voldaan met behulp van SageMaker real-time eindpunten.
SageMaker biedt: eindpunten van één model, waarmee u één machine learning (ML)-model kunt implementeren tegen een logisch eindpunt. Voor andere use-cases kunt u ervoor kiezen om kosten en prestaties te beheren met behulp van eindpunten met meerdere modellen, waarmee u meerdere modellen kunt opgeven om achter een logisch eindpunt te hosten. Ongeacht de optie die u kiest, SageMaker-eindpunten bieden een schaalbaar mechanisme voor zelfs de meest veeleisende zakelijke klanten, terwijl ze waarde bieden in een overvloed aan functies, waaronder schaduw varianten, automatisch schalen, en native integratie met Amazon Cloud Watch (voor meer informatie, zie CloudWatch-statistieken voor implementaties van meerdere modellen van eindpunten).
Triton ondersteunt verschillende backends als engines om het draaien en serveren van verschillende ML-modellen voor inferentie te ondersteunen. Voor elke Triton-implementatie is het van cruciaal belang om te weten hoe het backend-gedrag van invloed is op uw workloads en wat u kunt verwachten, zodat u succesvol kunt zijn. In dit bericht helpen we je de Forest Inference Library (FIL)-backend, dat wordt ondersteund door Triton op SageMaker, zodat u een weloverwogen beslissing kunt nemen voor uw workloads en de best mogelijke prestatie- en kostenoptimalisatie kunt krijgen.
Duik diep in de FIL-backend
Triton ondersteunt de FIL-backend om boommodellen te bedienen, zoals XGBoost, LichtGBM, scikit-leren Willekeurig bos, RAPIDS cuML willekeurig bos, en elk ander model ondersteund door Treeliet. Deze modellen worden al lang gebruikt voor het oplossen van problemen zoals classificatie of regressie. Hoewel dit soort modellen van oudsher op CPU's draaiden, hebben de populariteit van deze modellen en de gevolgtrekkingseisen geleid tot verschillende technieken om de gevolgtrekkingsprestaties te verbeteren. De FIL-backend maakt gebruik van veel van deze technieken door gebruik te maken van cuML-constructies en is gebouwd op C++ en de CUDA-kernbibliotheek om de inferentieprestaties op GPU-versnellers te optimaliseren.
De FIL-backend gebruikt de bibliotheken van cuML om CPU- of GPU-kernen te gebruiken om het leren te versnellen. Om deze processors te gebruiken, wordt verwezen naar gegevens uit het hostgeheugen (bijvoorbeeld NumPy-arrays) of GPU-arrays (uDF, Numba, cuPY of een bibliotheek die de __cuda_array_interface__)API. Nadat de gegevens in het geheugen zijn opgeslagen, kan de FIL-backend verwerking uitvoeren op alle beschikbare CPU- of GPU-kernen.
De FIL-backend-threads kunnen met elkaar communiceren zonder gebruik te maken van gedeeld geheugen van de host, maar bij ensemble-workloads moet hostgeheugen worden overwogen. Het volgende diagram toont een runtime-architectuur van een ensemble-scheduler waarin u de geheugengebieden kunt verfijnen, inclusief CPU-adresseerbaar gedeeld geheugen dat wordt gebruikt voor communicatie tussen processen tussen Triton (C++) en het Python-proces (Python-backend) voor het uitwisselen van tensoren (invoer/uitvoer) met de FIL-backend.

Triton Inference Server biedt configureerbare opties voor ontwikkelaars om hun workloads af te stemmen en modelprestaties te optimaliseren. De configuratie dynamic_batching stelt Triton in staat om verzoeken aan de clientzijde vast te houden en ze aan de serverzijde in batches te verwerken, zodat de parallelle berekening van FIL efficiënt kan worden gebruikt om de volledige batch samen te concluderen. De optie max_queue_delay_microseconds biedt een veilige controle over hoe lang Triton wacht om een batch te vormen.
Er zijn een aantal andere FIL-specifieke beschikbare opties die van invloed zijn op prestaties en gedrag. We raden aan om te beginnen met storage_type. Wanneer de backend op GPU wordt uitgevoerd, creëert FIL een nieuwe geheugen-/gegevensstructuur die een weergave is van de boom waarvoor FIL de prestaties en voetafdruk kan beïnvloeden. Dit is configureerbaar via de omgevingsparameter storage_type, met de opties compact, sparse en auto. Het kiezen van de dichte optie verbruikt meer GPU-geheugen en resulteert niet altijd in betere prestaties, dus het is het beste om dit te controleren. De sparse-optie verbruikt daarentegen minder GPU-geheugen en kan mogelijk net zo goed of zelfs beter presteren dan compact. Als u automatisch kiest, wordt het model standaard verdicht, tenzij dit aanzienlijk meer GPU-geheugen verbruikt dan schaars.
Als het gaat om modelprestaties, kunt u overwegen om de nadruk te leggen op de threads_per_tree keuze. Een ding dat u in real-world scenario's misschien te veel dient, is dat threads_per_tree kan een grotere impact hebben op de doorvoer dan welke andere parameter dan ook. Het is legitiem om het in te stellen op een macht van 2 van 1-32. De optimale waarde voor deze parameter is moeilijk te voorspellen, maar wanneer wordt verwacht dat de server een hogere belasting aankan of grotere batches verwerkt, profiteert deze meestal van een grotere waarde dan wanneer er een paar rijen tegelijk worden verwerkt.
Een andere parameter om op te letten is algo, die ook beschikbaar is als u op GPU werkt. Deze parameter bepaalt het algoritme dat wordt gebruikt om de deductieverzoeken te verwerken. De ondersteunde opties hiervoor zijn ALGO_AUTO, NAIVE, TREE_REORG en BATCH_TREE_REORG. Deze opties bepalen hoe knooppunten binnen een boomstructuur zijn georganiseerd en kunnen ook leiden tot prestatieverbeteringen. De ALGO_AUTO optie staat standaard op NAIVE voor schaarse opslag en BATCH_TREE_REORG voor dichte opslag.
Ten slotte wordt FIL geleverd met Shapley-uitleg, die kan worden geactiveerd met behulp van de treeshap_output parameter. Houd er echter rekening mee dat Shapley-uitvoer de prestaties schaadt vanwege de uitvoergrootte.
Model formaat
Er is momenteel geen standaard bestandsindeling om op forest gebaseerde modellen op te slaan; elk raamwerk heeft de neiging om zijn eigen formaat te definiëren. Om meerdere invoerbestandsindelingen te ondersteunen, importeert FIL gegevens met behulp van de open-source Treeliet bibliotheek. Hierdoor kan FIL modellen ondersteunen die zijn getraind in populaire frameworks, zoals XGBoost en LichtGBM. Houd er rekening mee dat de indeling van het model dat u verstrekt, moet worden ingesteld in de model_type configuratiewaarde gespecificeerd in de config.pbtxt bestand.
Configuratie.pbtxt
Elk model in een model opslagplaats moet een modelconfiguratie bevatten die de vereiste en optionele informatie over het model biedt. Meestal wordt deze configuratie geleverd in een config.pbtxt bestand gespecificeerd als ModelConfig-protobuf. Raadpleeg voor meer informatie over de configuratie-instellingen Modelconfiguratie. Hier volgen enkele configuratieparameters van het model:
- max_batch_grootte – Dit bepaalt de maximale batchgrootte die aan dit model kan worden doorgegeven. Over het algemeen is de enige limiet voor de grootte van batches die aan een FIL-backend worden doorgegeven, het beschikbare geheugen waarmee ze kunnen worden verwerkt. Voor GPU-runs wordt het beschikbare geheugen bepaald door de grootte van Triton's CUDA-geheugenpool, die kan worden ingesteld via een opdrachtregelargument bij het starten van de server.
- invoer – Opties in deze sectie vertellen Triton het aantal functies dat voor elk invoermonster kan worden verwacht.
- uitgang – Opties in deze sectie vertellen Triton hoeveel uitvoerwaarden er zullen zijn voor elk monster. Als de
predict_probaoptie is ingesteld op waar, dan wordt voor elke klasse een waarschijnlijkheidswaarde geretourneerd. Anders wordt een enkele waarde geretourneerd, die de voorspelde klasse voor de gegeven steekproef aangeeft. - instantie_groep - Dit bepaalt hoeveel exemplaren van dit model worden gemaakt en of ze GPU of CPU zullen gebruiken.
- model type – Deze string geeft aan in welk formaat het model is (
xgboost_jsonin dit voorbeeld, maarxgboost,lightgbmentl_checkpointzijn ook geldige formaten). - voorspellen_proba – Indien ingesteld op waar, worden waarschijnlijkheidswaarden voor elke klasse geretourneerd in plaats van alleen een klassevoorspelling.
- uitvoer_klasse – Dit is ingesteld op waar voor classificatiemodellen en op onwaar voor regressiemodellen.
- drempel – Dit is een scoredrempel voor het bepalen van classificatie. Wanneer
output_classis ingesteld op true, moet dit worden opgegeven, hoewel het niet wordt gebruikt alspredict_probais ook ingesteld op waar. - opslag type – Over het algemeen zou het gebruik van AUTO voor deze instelling aan de meeste gebruikssituaties moeten voldoen. Als AUTO-opslag is geselecteerd, laadt FIL het model met behulp van een schaarse of dichte weergave op basis van de geschatte grootte van het model. In sommige gevallen wilt u dit misschien expliciet instellen op SPARSE om de geheugenvoetafdruk van grote modellen te verkleinen.
Triton Inference Server op SageMaker
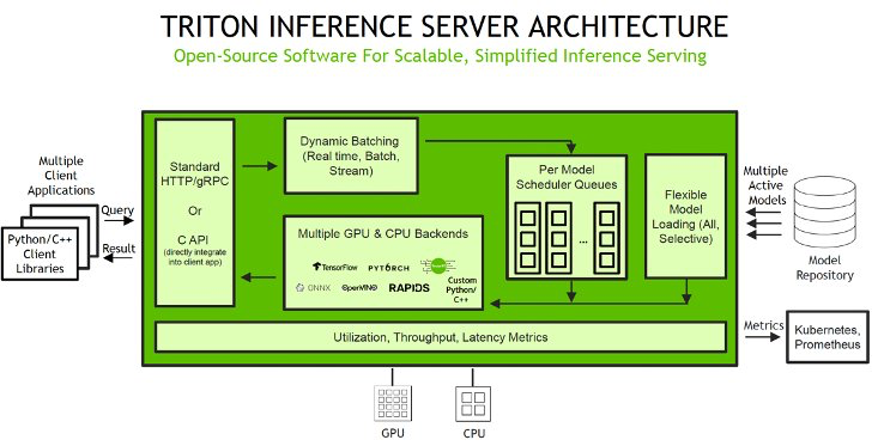
SageMaker toestaat u kunt zowel single-model als multi-model endpoints implementeren met NVIDIA Triton Inference Server. De volgende afbeelding toont de Triton Inference Server-architectuur op hoog niveau. De model opslagplaats is een op bestandssystemen gebaseerde repository van de modellen die Triton beschikbaar zal stellen voor deductie. Deductieverzoeken komen aan bij de server en worden doorgestuurd naar de juiste planner per model. Triton-werktuigen meerdere plannings- en batchalgoritmen die per model kan worden geconfigureerd. De planner van elk model voert optioneel batches van inferentieverzoeken uit en geeft de verzoeken vervolgens door aan de backend overeenkomend met het modeltype. De backend voert gevolgtrekkingen uit met behulp van de invoer in de batchverzoeken om de gevraagde uitvoer te produceren. De uitvoer wordt vervolgens geretourneerd.
Bij het configureren van uw automatisch schalende groepen voor SageMaker-eindpunten, kunt u overwegen SageMakerVariantInvocationsPerInstance als de primaire criteria om de schaalkenmerken van uw groep voor automatisch schalen te bepalen. Bovendien kunt u, afhankelijk van of uw modellen op GPU of CPU draaien, ook overwegen om CPUUtilization of GPUUtilization als aanvullende criteria te gebruiken. Houd er rekening mee dat voor eindpunten met één model, omdat de geïmplementeerde modellen allemaal hetzelfde zijn, het vrij eenvoudig is om het juiste beleid in te stellen om aan uw SLA's te voldoen. Voor eindpunten met meerdere modellen raden we aan om vergelijkbare modellen achter een bepaald eindpunt te implementeren voor meer stabiele, voorspelbare prestaties. In use-cases waarbij modellen van verschillende groottes en vereisten worden gebruikt, wilt u deze workloads mogelijk verdelen over meerdere eindpunten met meerdere modellen of enige tijd besteden aan het verfijnen van uw automatisch schalende groepsbeleid om de beste balans tussen kosten en prestaties te verkrijgen.
Raadpleeg voor een lijst met NVIDIA Triton Deep Learning Containers (DLC's) die worden ondersteund door SageMaker-inferentie Beschikbare Deep Learning Containers-afbeeldingen.
SageMaker-notebook-walkthrough
ML-toepassingen zijn complex en vereisen vaak voorverwerking van gegevens. In dit notitieboek gaan we in op het implementeren van een op een boom gebaseerd ML-model zoals XGBoost met behulp van de FIL-backend in Triton op een SageMaker-eindpunt met meerdere modellen. We bespreken ook hoe u een op Python gebaseerde inferentiepijplijn voor gegevensvoorverwerking voor uw model implementeert met behulp van de ensemblefunctie in Triton. Hierdoor kunnen we de onbewerkte gegevens van de clientzijde insturen en zowel gegevensvoorverwerking als modelinferentie laten plaatsvinden in een Triton SageMaker-eindpunt voor optimale inferentieprestaties.
Triton-model ensemble-functie
Triton Inference Server vereenvoudigt de inzet van AI-modellen op schaal in productie aanzienlijk. Triton Inference Server wordt geleverd met een handige oplossing die het bouwen van preprocessing- en postprocessing-pijplijnen vereenvoudigt. Het Triton Inference Server-platform biedt de ensemble-planner, die verantwoordelijk is voor het pijplijnen van modellen die deelnemen aan het inferentieproces, terwijl de efficiëntie en de doorvoer worden geoptimaliseerd. Het gebruik van ensemblemodellen kan de overhead van het overdragen van tussenliggende tensoren vermijden en het aantal verzoeken dat naar Triton moet worden verzonden, minimaliseren.

In dit notitieboek laten we zien hoe u de ensemblefunctie kunt gebruiken voor het bouwen van een pijplijn van gegevensvoorverwerking met XGBoost-modelinferentie, en u kunt hieruit extrapoleren om aangepaste naverwerking aan de pijplijn toe te voegen.
Stel de omgeving in
We beginnen met het opzetten van de gewenste omgeving. We installeren de afhankelijkheden die nodig zijn om onze modelpijplijn te verpakken en inferenties uit te voeren met behulp van Triton Inference Server. We definiëren ook de AWS Identiteits- en toegangsbeheer (IAM) rol die SageMaker toegang geeft tot de modelartefacten en de NVIDIA Triton Amazon Elastic Container-register (Amazon ECR) afbeelding. Zie de volgende code:
Maak een Conda-omgeving voor het voorverwerken van afhankelijkheden
De Python-backend in Triton vereist dat we een Conda omgeving voor eventuele aanvullende afhankelijkheden. In dit geval gebruiken we de Python-backend om de onbewerkte gegevens voor te verwerken voordat deze worden ingevoerd in het XGBoost-model dat wordt uitgevoerd in de FIL-backend. Hoewel we oorspronkelijk RAPIDS cuDF en cuML gebruikten om de gegevens voor te verwerken, gebruiken we hier Panda's en scikit-learn als voorverwerkingsafhankelijkheden tijdens inferentie. We doen dit om drie redenen:
- We laten zien hoe u een Conda-omgeving kunt maken voor uw afhankelijkheden en hoe u deze kunt verpakken in het formaat verwacht door Triton's Python-backend.
- Door het voorverwerkingsmodel te laten draaien in de Python-backend op de CPU terwijl de XGBoost draait op de GPU in de FIL-backend, illustreren we hoe elk model in Triton's ensemble-pijplijn kan draaien op een andere framework-backend en op verschillende hardwareconfiguraties.
- Het benadrukt hoe de RAPIDS-bibliotheken (cuDF, cuML) compatibel zijn met hun CPU-tegenhangers (Pandas, scikit-learn). We kunnen bijvoorbeeld laten zien hoe
LabelEncodersgemaakt in cuML kan worden gebruikt in scikit-learn en vice versa.
We volgen de instructies van de Triton-documentatie voor afhankelijkheden voor het voorbewerken van pakketten (scikit-learn en Panda's) die in de Python-backend moeten worden gebruikt als een TAR-bestand in de Conda-omgeving. Het bash-script create_prep_env.sh maakt het TAR-bestand van de Conda-omgeving en vervolgens verplaatsen we het naar de preprocessing-modeldirectory. Zie de volgende code:
Nadat we het voorgaande script hebben uitgevoerd, wordt het gegenereerd preprocessing_env.tar.gz, die we naar de preprocessing-directory kopiëren:
Stel preprocessing in met de Triton Python-backend
Voor de voorbewerking gebruiken we Triton's Python-backend om voorverwerking van tabelgegevens (categorische codering) uit te voeren tijdens inferentie voor onbewerkte gegevensverzoeken die de server binnenkomen. Voor meer informatie over de voorbewerking die tijdens de training is uitgevoerd, raadpleegt u de trainingsboekje.
De Python-backend maakt preprocessing, postprocessing en elke andere aangepaste logica mogelijk die in Python kan worden geïmplementeerd en met Triton kan worden bediend. Het gebruik van Triton op SageMaker vereist dat we eerst een modelrepositorymap opzetten met daarin de modellen die we willen bedienen. We hebben al een model opgezet voor het voorbewerken van Python-gegevens, genaamd preprocessing in cpu_model_repository en gpu_model_repository.

Triton heeft specifieke vereisten voor de lay-out van de modelrepository. Binnen de modelrepositorydirectory op het hoogste niveau heeft elk model zijn eigen subdirectory met de informatie voor het overeenkomstige model. Elke modeldirectory in Triton moet ten minste één numerieke subdirectory hebben die een versie van het model vertegenwoordigt. De waarde 1 vertegenwoordigt versie 1 van ons Python-voorverwerkingsmodel. Elk model wordt beheerd door een specifieke backend, dus binnen elke subdirectory van de versie moet er het modelartefact zijn dat door die backend wordt vereist. Voor dit voorbeeld gebruiken we de Python-backend, waarvoor vereist is dat het Python-bestand dat u aanbiedt model.py heet, en het bestand moet implementeren bepaalde functies. Als we een PyTorch-backend zouden gebruiken, zou een model.pt-bestand vereist zijn, enzovoort. Raadpleeg voor meer informatie over naamgevingsconventies voor modelbestanden Modelbestanden.
De model.py Het Python-bestand dat we hier gebruiken, implementeert alle logica voor het voorbewerken van gegevens in tabelvorm om onbewerkte gegevens om te zetten in functies die kunnen worden ingevoerd in ons XGBoost-model.
Elk Triton-model moet ook een config.pbtxt bestand dat de modelconfiguratie beschrijft. Raadpleeg voor meer informatie over de configuratie-instellingen Modelconfiguratie. Onze config.pbtxt bestand specificeert de backend als python en alle invoerkolommen voor onbewerkte gegevens samen met voorverwerkte uitvoer, die uit 15 functies bestaat. We specificeren ook dat we dit Python-voorverwerkingsmodel op de CPU willen uitvoeren. Zie de volgende code:
Stel een op een boom gebaseerd ML-model in voor de FIL-backend
Vervolgens hebben we de modeldirectory ingesteld voor een op een boom gebaseerd ML-model zoals XGBoost, dat de FIL-backend zal gebruiken.
De verwachte lay-out voor cpu_memory_repository en gpu_memory_repository zijn vergelijkbaar met degene die we eerder lieten zien.

Hier FIL is de naam van het model. We kunnen het een andere naam geven, zoals xgboost als we willen. 1 is de subdirectory version, die het modelartefact bevat. In dit geval is dat de xgboost.json model dat we hebben opgeslagen. Laten we deze verwachte lay-out maken:
We hebben het configuratiebestand nodig config.pbtxt het beschrijven van de modelconfiguratie voor het op bomen gebaseerde ML-model, zodat de FIL-backend in Triton kan begrijpen hoe deze moet worden bediend. Raadpleeg de nieuwste generieke versie voor meer informatie Triton-configuratieopties en de configuratie-opties die specifiek zijn voor de FIL-backend. We concentreren ons op slechts enkele van de meest voorkomende en relevante opties in dit voorbeeld.
creëren config.pbtxt For model_cpu_repository:
Evenzo instellen config.pbtxt For model_gpu_repository (let op het verschil is USE_GPU = True):
Stel een inferentiepijplijn in van de gegevensvoorverwerking van Python-backend en FIL-backend met behulp van ensembles
Nu zijn we klaar om de inferentiepijplijn in te stellen voor gegevensvoorverwerking en op bomen gebaseerde modelinferentie met behulp van een ensemble-model. Een ensemblemodel vertegenwoordigt een pijplijn van een of meer modellen en de verbinding van invoer- en uitvoertensoren tussen die modellen. Hier gebruiken we het ensemblemodel om een pijplijn van gegevensvoorverwerking in de Python-backend te bouwen, gevolgd door XGBoost in de FIL-backend.
De verwachte lay-out voor de ensemble model directory is vergelijkbaar met degene die we eerder lieten zien:


We hebben de ensemblemodellen gemaakt config.pbtxt de begeleiding volgen in Ensemble-modellen. Belangrijk is dat we de ensembleplanner moeten instellen config.pbtxt, die de gegevensstroom tussen modellen binnen het ensemble specificeert. De ensemble-scheduler verzamelt de uitvoertensoren in elke stap en levert deze als invoertensoren voor andere stappen volgens de specificatie.
Verpak de modelrepository en upload deze naar Amazon S3
Uiteindelijk eindigen we met de volgende modelrepository-directorystructuur, die een Python-voorverwerkingsmodel en zijn afhankelijkheden bevat, samen met het XGBoost FIL-model en het modellensemble.


We verpakken de directory en de inhoud ervan als model.tar.gz voor het uploaden naar Amazon eenvoudige opslagservice (Amazone S3). In dit voorbeeld hebben we twee opties: een op CPU gebaseerde instantie of een op GPU gebaseerde instantie gebruiken. Een op GPU gebaseerde instantie is geschikter wanneer u meer verwerkingskracht nodig heeft en CUDA-kernen wilt gebruiken.
Maak en upload het modelpakket voor een CPU-gebaseerde instantie (geoptimaliseerd voor CPU) met de volgende code:
Maak en upload het modelpakket voor een op GPU gebaseerde instantie (geoptimaliseerd voor GPU) met de volgende code:
Een SageMaker-eindpunt maken
We hebben nu de modelartefacten opgeslagen in een S3-bucket. In deze stap kunnen we ook de aanvullende omgevingsvariabele opgeven SAGEMAKER_TRITON_DEFAULT_MODEL_NAME, die de naam specificeert van het model dat door Triton moet worden geladen. De waarde van deze sleutel moet overeenkomen met de mapnaam in het modelpakket dat is geüpload naar Amazon S3. Deze variabele is optioneel in het geval van een enkel model. In het geval van ensemble-modellen moet deze sleutel worden opgegeven om Triton in SageMaker te laten opstarten.
Bovendien kunt u instellen: SAGEMAKER_TRITON_BUFFER_MANAGER_THREAD_COUNT en SAGEMAKER_TRITON_THREAD_COUNT voor het optimaliseren van het aantal threads.
We gebruiken het voorgaande model om een eindpuntconfiguratie te maken waarin we het type en aantal instanties kunnen specificeren dat we in het eindpunt willen hebben
We gebruiken deze eindpuntconfiguratie om een SageMaker-eindpunt te maken en te wachten tot de implementatie is voltooid. Met SageMaker MME's hebben we de mogelijkheid om meerdere ensemble-modellen te hosten door dit proces te herhalen, maar we houden het bij één implementatie voor dit voorbeeld:
De status verandert in InService wanneer de implementatie is gelukt.
Roep uw model aan dat wordt gehost op het SageMaker-eindpunt
Nadat het eindpunt is uitgevoerd, kunnen we enkele onbewerkte voorbeeldgegevens gebruiken om gevolgtrekkingen uit te voeren met JSON als het payload-formaat. Voor het deductieverzoekformaat gebruikt Triton de KFServing gemeenschapsnorm inferentie protocollen. Zie de volgende code:
Het notitieboek waarnaar in de blog wordt verwezen, is te vinden in de GitHub-repository.
Beste praktijken
Naast de eerder genoemde opties om de instellingen van de FIL-backend te verfijnen, kunnen datawetenschappers er ook voor zorgen dat de invoergegevens voor de backend worden geoptimaliseerd voor verwerking door de engine. Voer waar mogelijk gegevens in rijhoofdformaat in de GPU-array in. Andere formaten vereisen interne conversie en opnamecycli, waardoor de prestaties afnemen.
Houd rekening met de boomdiepte vanwege de manier waarop FIL-gegevensstructuren worden onderhouden in het GPU-geheugen. Hoe dieper de boomdiepte, hoe groter uw GPU-geheugenvoetafdruk zal zijn.
Gebruik de instance_group_count parameter om werkprocessen toe te voegen en de doorvoer van de FIL-backend te verhogen, wat zal resulteren in een groter CPU- en GPU-geheugenverbruik. Overweeg daarnaast SageMaker-specifieke variabelen die beschikbaar zijn om de doorvoer te vergroten, zoals HTTP-threads, HTTP-buffergrootte, batchgrootte en maximale vertraging.
Conclusie
In dit bericht zijn we diep ingegaan op de FIL-backend die Triton Inference Server ondersteunt op SageMaker. Deze backend zorgt voor zowel CPU- als GPU-versnelling van uw op bomen gebaseerde modellen, zoals het populaire XGBoost-algoritme. Er zijn veel opties die u kunt overwegen om de beste prestaties voor inferentie te krijgen, zoals batchgroottes, indelingen voor gegevensinvoer en andere factoren die kunnen worden afgestemd op uw behoeften. Met SageMaker kunt u deze mogelijkheid gebruiken met endpoints met één of meerdere modellen om een balans te vinden tussen prestaties en kostenbesparingen.
We moedigen u aan om de informatie in dit bericht te gebruiken en te kijken of SageMaker kan voldoen aan uw hostingbehoeften om op bomen gebaseerde modellen te bedienen, die voldoen aan uw vereisten voor kostenreductie en werklastprestaties.
De notebook waarnaar in dit bericht wordt verwezen, is te vinden in de SageMaker-voorbeelden GitHub-repository. Verder vindt u de meest recente documentatie over de FIL-backend op GitHub.
Over de auteurs
 Raghu Ramesha is een Senior ML Solutions Architect bij het Amazon SageMaker Service-team. Hij richt zich op het helpen van klanten bij het op grote schaal bouwen, implementeren en migreren van ML-productieworkloads naar SageMaker. Hij is gespecialiseerd in machine learning, AI en computervisie, en heeft een masterdiploma in Computer Science van UT Dallas. In zijn vrije tijd houdt hij van reizen en fotografie.
Raghu Ramesha is een Senior ML Solutions Architect bij het Amazon SageMaker Service-team. Hij richt zich op het helpen van klanten bij het op grote schaal bouwen, implementeren en migreren van ML-productieworkloads naar SageMaker. Hij is gespecialiseerd in machine learning, AI en computervisie, en heeft een masterdiploma in Computer Science van UT Dallas. In zijn vrije tijd houdt hij van reizen en fotografie.
 James Park is Solutions Architect bij Amazon Web Services. Hij werkt met Amazon.com aan het ontwerpen, bouwen en implementeren van technologische oplossingen op AWS, en heeft een bijzondere interesse in AI en machine learning. In zijn vrije tijd gaat hij graag op zoek naar nieuwe culturen, nieuwe ervaringen en blijft hij op de hoogte van de laatste technologische trends.
James Park is Solutions Architect bij Amazon Web Services. Hij werkt met Amazon.com aan het ontwerpen, bouwen en implementeren van technologische oplossingen op AWS, en heeft een bijzondere interesse in AI en machine learning. In zijn vrije tijd gaat hij graag op zoek naar nieuwe culturen, nieuwe ervaringen en blijft hij op de hoogte van de laatste technologische trends.
 Dhawal Patel is Principal Machine Learning Architect bij AWS. Hij heeft met organisaties, variërend van grote ondernemingen tot middelgrote startups, gewerkt aan problemen met betrekking tot gedistribueerde computing en kunstmatige intelligentie. Hij richt zich op deep learning, inclusief NLP en computer vision domeinen. Hij helpt klanten om hoogwaardige modelinferentie te bereiken op Amazon SageMaker.
Dhawal Patel is Principal Machine Learning Architect bij AWS. Hij heeft met organisaties, variërend van grote ondernemingen tot middelgrote startups, gewerkt aan problemen met betrekking tot gedistribueerde computing en kunstmatige intelligentie. Hij richt zich op deep learning, inclusief NLP en computer vision domeinen. Hij helpt klanten om hoogwaardige modelinferentie te bereiken op Amazon SageMaker.
 Jiahong Liu is Solution Architect in het Cloud Service Provider-team van NVIDIA. Hij helpt klanten bij het adopteren van machine learning en AI-oplossingen die gebruikmaken van NVIDIA Accelerated Computing om hun trainings- en inferentie-uitdagingen aan te pakken. In zijn vrije tijd houdt hij van origami, doe-het-zelfprojecten en basketbal.
Jiahong Liu is Solution Architect in het Cloud Service Provider-team van NVIDIA. Hij helpt klanten bij het adopteren van machine learning en AI-oplossingen die gebruikmaken van NVIDIA Accelerated Computing om hun trainings- en inferentie-uitdagingen aan te pakken. In zijn vrije tijd houdt hij van origami, doe-het-zelfprojecten en basketbal.
 Kshitiz Gupta is Solutions Architect bij NVIDIA. Hij vindt het leuk om cloudklanten te informeren over de GPU AI-technologieën die NVIDIA te bieden heeft en hen te helpen bij het versnellen van hun machine learning en deep learning-applicaties. Naast zijn werk houdt hij van hardlopen, wandelen en het spotten van dieren in het wild.
Kshitiz Gupta is Solutions Architect bij NVIDIA. Hij vindt het leuk om cloudklanten te informeren over de GPU AI-technologieën die NVIDIA te bieden heeft en hen te helpen bij het versnellen van hun machine learning en deep learning-applicaties. Naast zijn werk houdt hij van hardlopen, wandelen en het spotten van dieren in het wild.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/hosting-ml-models-on-amazon-sagemaker-using-triton-xgboost-lightgbm-and-treelite-models/

