De lancering van ChatGPT en de stijgende populariteit van generatieve AI hebben tot de verbeelding gesproken van klanten die nieuwsgierig zijn naar hoe ze deze technologie kunnen gebruiken om nieuwe producten en diensten op AWS te creëren, zoals zakelijke chatbots, die meer gemoedelijk zijn. Dit bericht laat zien hoe u een webinterface kunt maken, die we Chat Studio noemen, om een gesprek te starten en te communiceren met basismodellen die beschikbaar zijn in Amazon SageMaker JumpStart zoals Llama 2, Stable Diffusion en andere modellen die beschikbaar zijn Amazon Sage Maker. Nadat u deze oplossing heeft geïmplementeerd, kunnen gebruikers snel aan de slag en via een webinterface de mogelijkheden van meerdere basismodellen in conversationele AI ervaren.
Chat Studio kan optioneel ook het Stable Diffusion-modeleindpunt aanroepen om een collage van relevante afbeeldingen en video's te retourneren als de gebruiker vraagt om media weer te geven. Deze functie kan de gebruikerservaring helpen verbeteren door het gebruik van media als begeleidende middelen bij de respons. Dit is slechts één voorbeeld van hoe u Chat Studio kunt verrijken met extra integraties om uw doelen te bereiken.
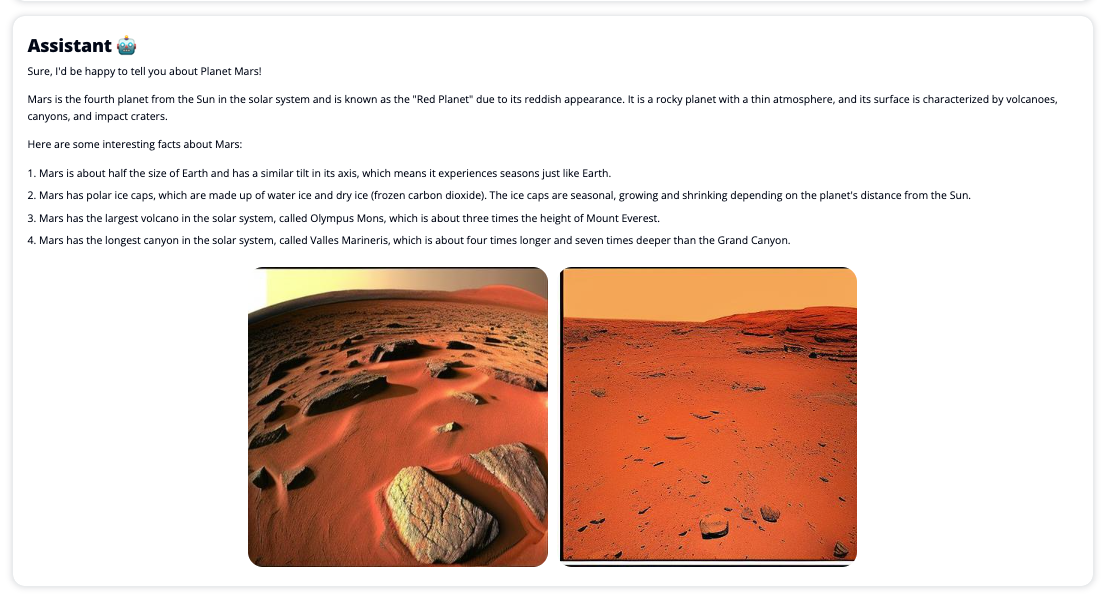
De volgende schermafbeeldingen tonen voorbeelden van hoe een gebruikersquery en -antwoord eruit zien.

Grote taalmodellen
Generatieve AI-chatbots zoals ChatGPT worden aangedreven door grote taalmodellen (LLM's), die zijn gebaseerd op een deep learning neuraal netwerk dat kan worden getraind op grote hoeveelheden ongelabelde tekst. Het gebruik van LLM's zorgt voor een betere gesprekservaring die sterk lijkt op interacties met echte mensen, waardoor een gevoel van verbondenheid en verbeterde gebruikerstevredenheid wordt bevorderd.
SageMaker-funderingsmodellen
In 2021 noemde het Stanford Institute for Human-Centered Artificial Intelligence enkele LLM's als funderingsmodellen. Basismodellen zijn vooraf getraind op een grote en brede set algemene gegevens en zijn bedoeld als basis voor verdere optimalisaties in een breed scala aan gebruiksscenario's, van het genereren van digitale kunst tot meertalige tekstclassificatie. Deze basismodellen zijn populair bij klanten omdat het helemaal opnieuw trainen van een nieuw model tijd kost en duur kan zijn. SageMaker JumpStart biedt toegang tot honderden basismodellen die worden onderhouden door open source- en eigen providers van derden.
Overzicht oplossingen
Dit bericht doorloopt een low-code workflow voor het implementeren van vooraf getrainde en aangepaste LLM's via SageMaker, en het creëren van een webgebruikersinterface die kan communiceren met de geïmplementeerde modellen. We behandelen de volgende stappen:
- Implementeer SageMaker-basismodellen.
- Implementeren AWS Lambda en AWS Identiteits- en toegangsbeheer (IAM)-machtigingen gebruiken AWS CloudFormatie.
- De gebruikersinterface instellen en uitvoeren.
- Voeg optioneel andere SageMaker-funderingsmodellen toe. Deze stap breidt de mogelijkheden van Chat Studio uit om te communiceren met aanvullende basismodellen.
- Implementeer desgewenst de toepassing met behulp van AWS versterken. Met deze stap wordt Chat Studio op internet geïmplementeerd.
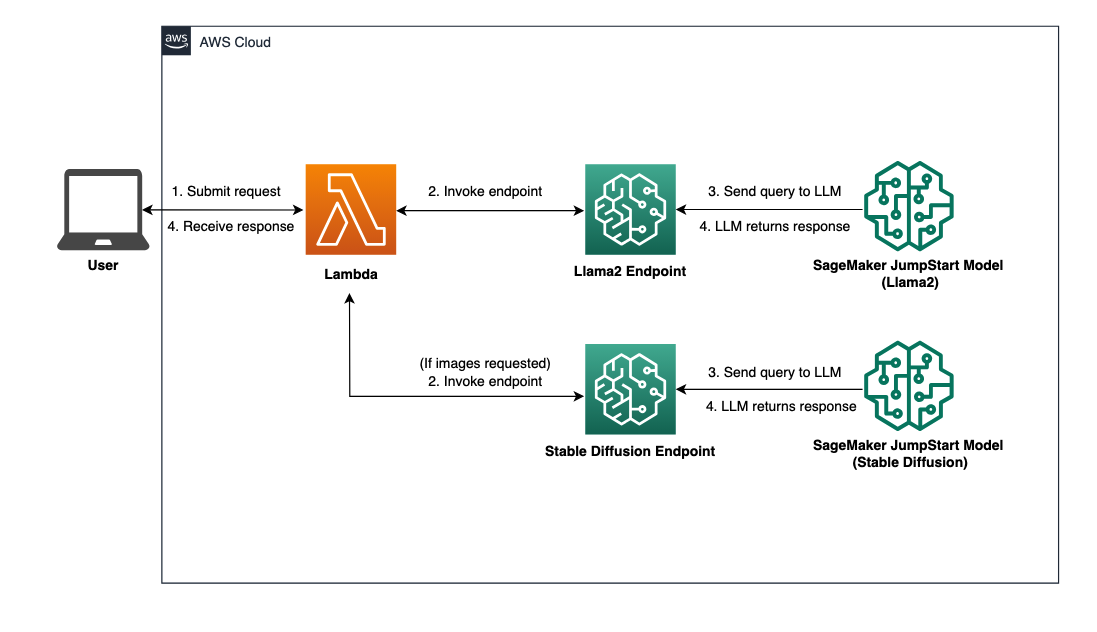
Raadpleeg het volgende diagram voor een overzicht van de oplossingsarchitectuur.
Voorwaarden
Om door de oplossing te lopen, moet u aan de volgende vereisten voldoen:
- An AWS-account met voldoende IAM-gebruikersrechten.
npmgeïnstalleerd in uw lokale omgeving. Voor instructies over hoe te installerennpm, verwijzen naar Node.js en npm downloaden en installeren.- Een servicequotum van 1 voor de overeenkomstige SageMaker-eindpunten. Voor Llama 2 13b Chat gebruiken we een ml.g5.48xlarge-instantie en voor Stable Diffusion 2.1 gebruiken we een ml.p3.2xlarge-instantie.
Als u een verhoging van het servicequotum wilt aanvragen, gaat u naar de AWS Service Quota-console, navigeren naar AWS-diensten, SageMakeren het verzoek om een servicequotum wordt verhoogd naar een waarde van 1 voor ml.g5.48xlarge voor eindpuntgebruik en ml.p3.2xlarge voor eindpuntgebruik.
Het kan enkele uren duren voordat de servicequotaaanvraag wordt goedgekeurd, afhankelijk van de beschikbaarheid van het exemplaartype.
Implementeer SageMaker-basismodellen
SageMaker is een volledig beheerde machine learning-service (ML) waarmee ontwikkelaars snel en eenvoudig ML-modellen kunnen bouwen en trainen. Voer de volgende stappen uit om de Llama 2 13b Chat- en Stable Diffusion 2.1-basismodellen te implementeren met behulp van Amazon SageMaker Studio:
- Maak een SageMaker-domein. Voor instructies, zie Onboard naar Amazon SageMaker Domain met behulp van Snelle installatie.
Een domein stelt alle opslagruimte in en stelt u in staat gebruikers toe te voegen voor toegang tot SageMaker.
- Kies op de SageMaker-console studio in het navigatievenster en kies vervolgens Studio openen.
- Bij het starten van Studio, onder SageMaker JumpStart in het navigatievenster, kies Modellen, notebooks, oplossingen.
- Zoek in de zoekbalk naar Llama 2 13b Chat.
- Onder Implementatie configuratievoor SageMaker-hostinginstantie, kiezen ml.g5.48xgroot en voor Eindpuntnaam, ga naar binnen
meta-textgeneration-llama-2-13b-f. - Kies Implementeren.
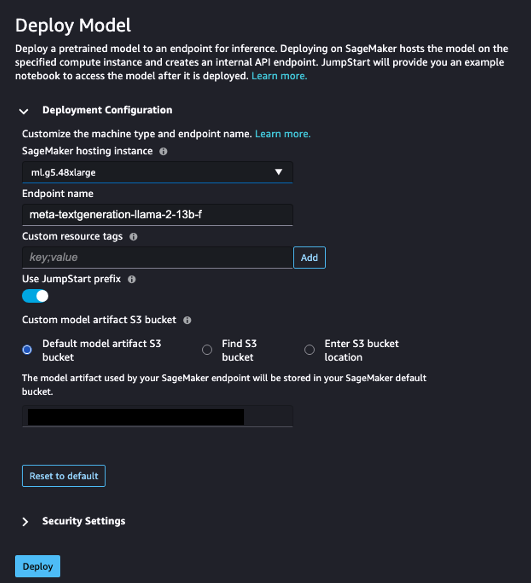
Nadat de implementatie is voltooid, zou u de In Service statuut.
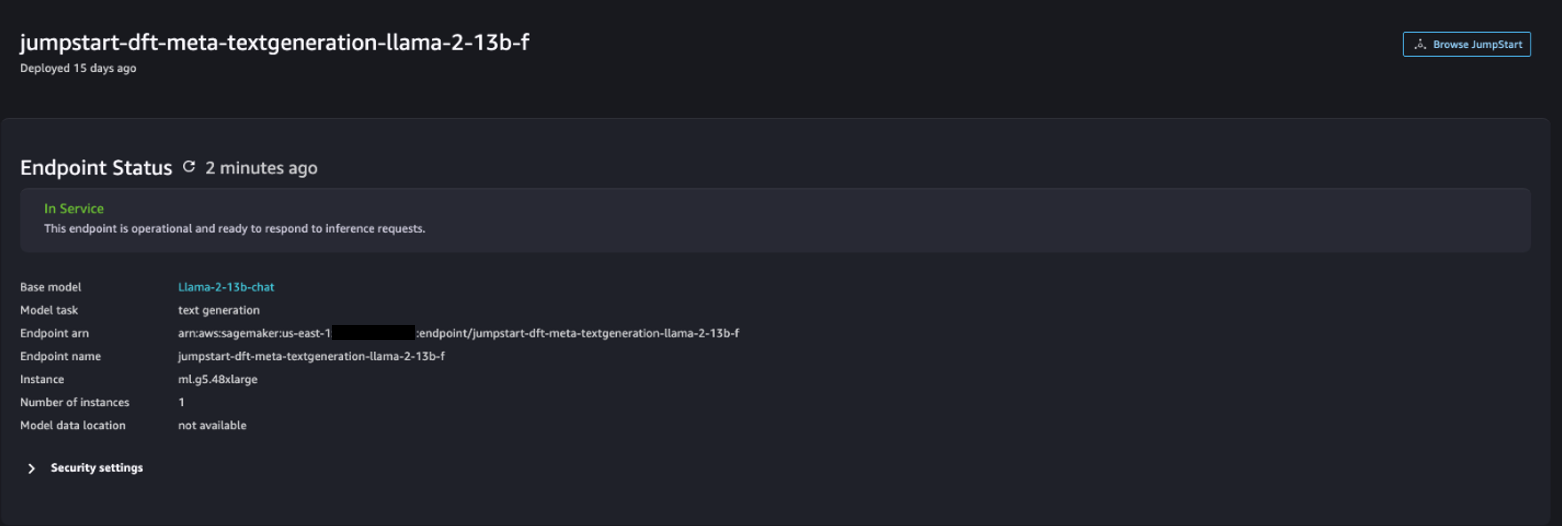
- Op de Modellen, notebooks, oplossingen pagina, zoek naar Stabiele Diffusie 2.1.
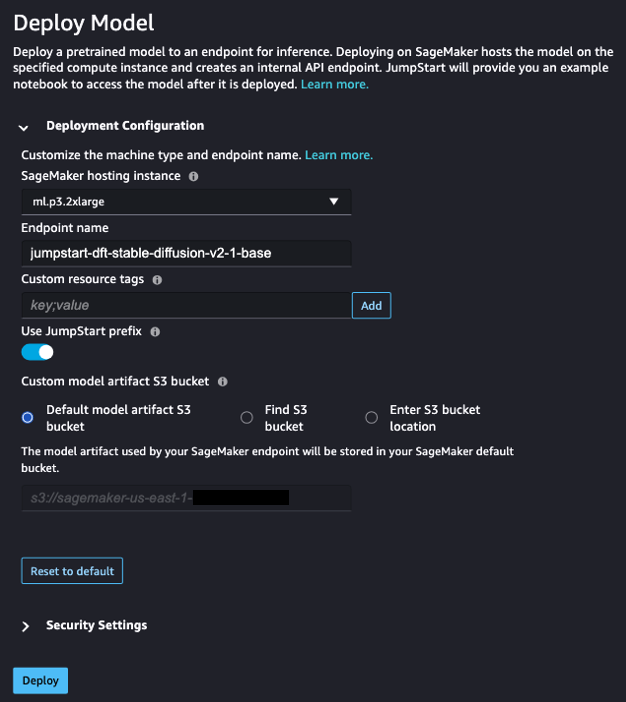
- Onder Implementatie configuratievoor SageMaker-hostinginstantie, kiezen ml.p3.2xgroot en voor Eindpuntnaam, ga naar binnen
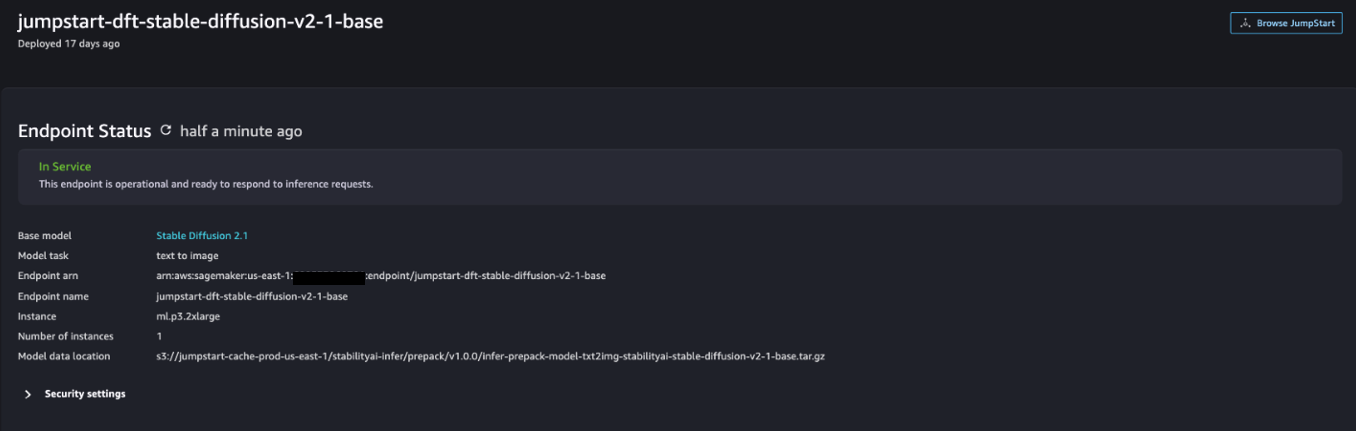
jumpstart-dft-stable-diffusion-v2-1-base. - Kies Implementeren.
Nadat de implementatie is voltooid, zou u de In Service statuut.
Implementeer Lambda- en IAM-machtigingen met AWS CloudFormation
In deze sectie wordt beschreven hoe u een CloudFormation-stack kunt starten die een Lambda-functie implementeert die uw gebruikersverzoek verwerkt en het SageMaker-eindpunt aanroept dat u hebt geïmplementeerd, en alle benodigde IAM-machtigingen implementeert. Voer de volgende stappen uit:
- Navigeer naar de GitHub-repository en download de CloudFormation-sjabloon (
lambda.cfn.yaml) naar uw lokale computer. - Kies op de CloudFormation-console het Maak een stapel vervolgkeuzemenu en kies Met nieuwe middelen (standaard).
- Op de Specificeer sjabloon 4040 hand404040 details hand4040 hand 3 details hand40 hand40 hand details details details details hand 3 Upload een sjabloonbestand en Kies bestand.
- Kies de
lambda.cfn.yamlbestand dat u hebt gedownload en kies vervolgens Volgende. - Op de Geef stapeldetails op pagina, voer een stapelnaam en de API-sleutel in die u bij de vereisten hebt verkregen en kies vervolgens Volgende.
- Op de Configureer stapelopties pagina, kies Volgende.
- Bekijk en erken de wijzigingen en maak een keuze Verzenden.
Stel de webinterface in
In dit gedeelte worden de stappen beschreven voor het uitvoeren van de webgebruikersinterface (gemaakt met behulp van Cloudscape-ontwerpsysteem) op uw lokale computer:
- Navigeer op de IAM-console naar de gebruiker
functionUrl. - Op de Beveiligingsreferenties tabblad, kies Toegangssleutel maken.
- Op de Krijg toegang tot de belangrijkste best practices en alternatieven 4040 hand404040 details hand4040 hand 3 details hand40 hand40 hand details details details details hand 3 Command Line Interface (CLI) En kies Volgende.
- Op de Beschrijvingstag instellen pagina, kies Toegangssleutel maken.
- Kopieer de toegangssleutel en de geheime toegangssleutel.
- Kies Klaar .
- Navigeer naar de GitHub-repository en download de
react-llm-chat-studiocode. - Start de map in uw favoriete IDE en open een terminal.
- Navigeer naar
src/configs/aws.jsonen voer de toegangssleutel en de geheime toegangssleutel in die u heeft verkregen. - Voer de volgende opdrachten in de terminal in:
- Openen http://localhost:3000 in uw browser en begin met de interactie met uw modellen!
Om Chat Studio te gebruiken, kiest u een basismodel in het vervolgkeuzemenu en voert u uw vraag in het tekstvak in. Om door AI gegenereerde afbeeldingen bij het antwoord te krijgen, voegt u de zinsnede 'met afbeeldingen' toe aan het einde van uw zoekopdracht.
Voeg andere SageMaker-basismodellen toe
U kunt de mogelijkheden van deze oplossing verder uitbreiden met extra SageMaker-funderingsmodellen. Omdat elk model verschillende invoer- en uitvoerformaten verwacht bij het aanroepen van het SageMaker-eindpunt, moet u een transformatiecode schrijven in de callSageMakerEndpoints Lambda-functie om met het model te communiceren.
In dit gedeelte worden de algemene stappen en codewijzigingen beschreven die nodig zijn om een aanvullend model van uw keuze te implementeren. Houd er rekening mee dat basiskennis van de Python-taal vereist is voor de stappen 6–8.
- Implementeer in SageMaker Studio het SageMaker-basismodel van uw keuze.
- Kies SageMaker JumpStart en Start JumpStart-middelen.
- Kies uw nieuw geïmplementeerde modeleindpunt en kies Notitieblok openen.
- Zoek op de notebookconsole de payloadparameters.
Dit zijn de velden die het nieuwe model verwacht bij het aanroepen van het SageMaker-eindpunt. De volgende schermafbeelding toont een voorbeeld.

- Navigeer op de Lambda-console naar
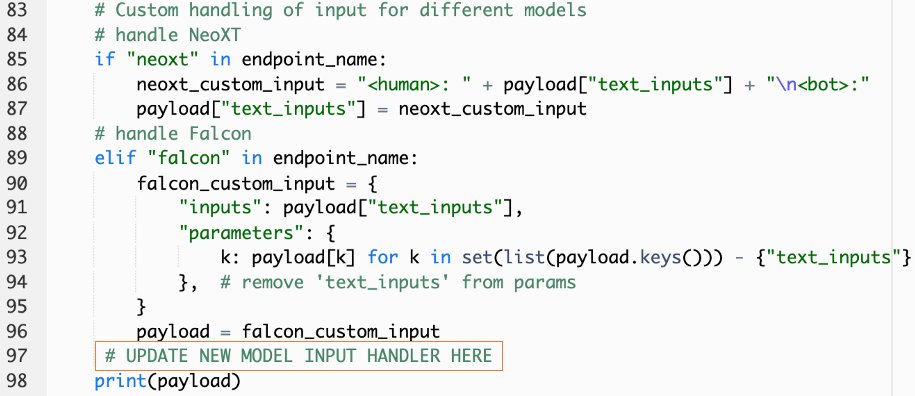
callSageMakerEndpoints. - Voeg een aangepaste invoerhandler toe voor uw nieuwe model.
In de volgende schermafbeelding hebben we de invoer voor Falcon 40B Instruct BF16 en GPT NeoXT Chat Base 20B FP16 getransformeerd. U kunt uw aangepaste parameterlogica invoegen zoals aangegeven om de invoertransformatielogica toe te voegen met verwijzing naar de payloadparameters die u hebt gekopieerd.
- Ga terug naar de notebookconsole en zoek
query_endpoint.
Deze functie geeft u een idee hoe u de uitvoer van de modellen kunt transformeren om het uiteindelijke tekstantwoord te extraheren.
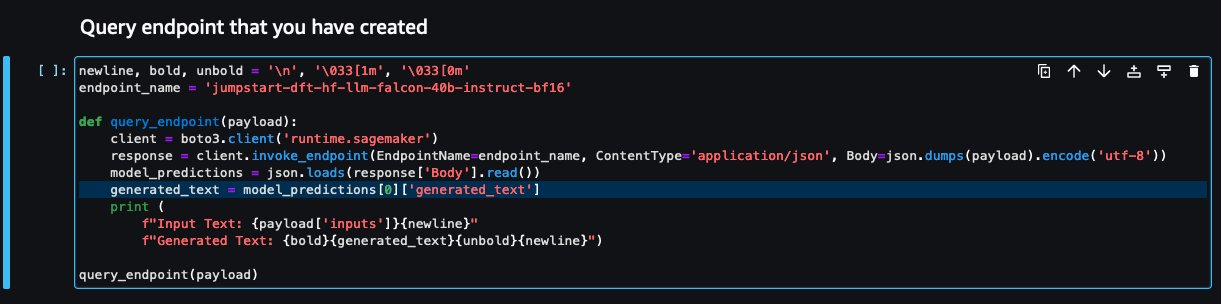
- Met verwijzing naar de code in
query_endpoint, voeg een aangepaste uitvoerhandler toe voor uw nieuwe model.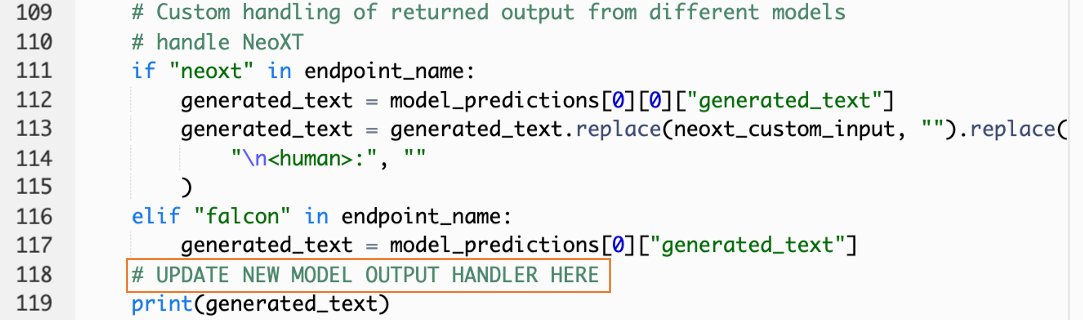
- Kies Implementeren.
- Open uw IDE, start het
react-llm-chat-studiocode en navigeer naarsrc/configs/models.json. - Voeg uw modelnaam en modeleindpunt toe en voer de payloadparameters uit stap 4 hieronder in
payloadin het volgende formaat: - Vernieuw uw browser om te beginnen met de interactie met uw nieuwe model!
Implementeer de applicatie met Amplify
Amplify is een complete oplossing waarmee u uw applicatie snel en efficiënt kunt implementeren. In deze sectie worden de stappen beschreven om Chat Studio te implementeren in een Amazon CloudFront distributie met behulp van Amplify als u uw applicatie met andere gebruikers wilt delen.
- Navigeer naar de
react-llm-chat-studiocodemap die u eerder hebt gemaakt. - Voer de volgende opdrachten in de terminal in en volg de installatie-instructies:
- Initialiseer een nieuw Amplify-project met behulp van de volgende opdracht. Geef een projectnaam op, accepteer de standaardconfiguraties en kies AWS-toegangssleutels wanneer u wordt gevraagd de authenticatiemethode te selecteren.
- Host het Amplify-project met behulp van de volgende opdracht. Kiezen Amazon CloudFront en S3 wanneer u wordt gevraagd de plug-inmodus te selecteren.
- Bouw en implementeer ten slotte het project met de volgende opdracht:
- Nadat de implementatie is gelukt, opent u de URL in uw browser en begint u met uw modellen te communiceren!
Opruimen
Voer de volgende stappen uit om toekomstige kosten te voorkomen:
- Verwijder de CloudFormation-stack. Raadpleeg voor instructies Een stapel verwijderen op de AWS CloudFormation-console.
- Verwijder het SageMaker JumpStart-eindpunt. Voor instructies, zie Eindpunten en bronnen verwijderen.
- Verwijder het SageMaker-domein. Voor instructies, zie Een Amazon SageMaker-domein verwijderen.
Conclusie
In dit bericht hebben we uitgelegd hoe u een webinterface kunt maken voor interactie met LLM's die op AWS zijn geïmplementeerd.
Met deze oplossing kunt u op een gebruiksvriendelijke manier communiceren met uw LLM en een gesprek voeren om de LLM-vragen te testen of te stellen, en indien nodig een collage van afbeeldingen en video's te krijgen.
U kunt deze oplossing op verschillende manieren uitbreiden, bijvoorbeeld door extra funderingsmodellen te integreren, integreren met Amazon Kendra om ML-aangedreven intelligent zoeken mogelijk te maken voor het begrijpen van bedrijfsinhoud, en meer!
Wij nodigen u uit om mee te experimenteren verschillende vooraf opgeleide LLM's beschikbaar op AWS, of bouw bovenop of maak zelfs uw eigen LLM's in SageMaker. Laat ons uw vragen en bevindingen weten in de reacties en veel plezier!
Over de auteurs
 Jarrett Yeo Shan Wei is een Associate Cloud Architect in AWS Professional Services voor de publieke sector in de ASEAN en is een voorstander van het helpen van klanten bij het moderniseren en migreren naar de cloud. Hij heeft vijf AWS-certificeringen behaald en heeft ook een onderzoekspaper gepubliceerd over machine-ensembles voor gradiëntversterking tijdens de 8e Internationale Conferentie over AI. In zijn vrije tijd concentreert Jarrett zich op en draagt hij bij aan de generatieve AI-scene bij AWS.
Jarrett Yeo Shan Wei is een Associate Cloud Architect in AWS Professional Services voor de publieke sector in de ASEAN en is een voorstander van het helpen van klanten bij het moderniseren en migreren naar de cloud. Hij heeft vijf AWS-certificeringen behaald en heeft ook een onderzoekspaper gepubliceerd over machine-ensembles voor gradiëntversterking tijdens de 8e Internationale Conferentie over AI. In zijn vrije tijd concentreert Jarrett zich op en draagt hij bij aan de generatieve AI-scene bij AWS.
 Tammy Lim Lee Xin is Associate Cloud Architect bij AWS. Ze gebruikt technologie om klanten te helpen de gewenste resultaten te behalen tijdens hun overstap naar de cloud en heeft een passie voor AI/ML. Buiten haar werk houdt ze van reizen, wandelen en tijd doorbrengen met familie en vrienden.
Tammy Lim Lee Xin is Associate Cloud Architect bij AWS. Ze gebruikt technologie om klanten te helpen de gewenste resultaten te behalen tijdens hun overstap naar de cloud en heeft een passie voor AI/ML. Buiten haar werk houdt ze van reizen, wandelen en tijd doorbrengen met familie en vrienden.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/create-a-web-ui-to-interact-with-llms-using-amazon-sagemaker-jumpstart/

