Grote taalmodellen (LLM's) worden steeds populairder en er worden voortdurend nieuwe gebruiksscenario's onderzocht. Over het algemeen kunt u applicaties bouwen die worden aangedreven door LLM's door prompt engineering in uw code op te nemen. Er zijn echter gevallen waarin het vragen om een bestaande LLM tekortschiet. Dit is waar het verfijnen van modellen kan helpen. Prompt-engineering gaat over het begeleiden van de uitvoer van het model door invoerprompts te maken, terwijl het bij fine-tunen gaat over het trainen van het model op aangepaste datasets om het beter geschikt te maken voor specifieke taken of domeinen.
Voordat u een model kunt verfijnen, moet u een taakspecifieke gegevensset vinden. Een dataset die vaak wordt gebruikt is de Algemene crawl-gegevensset. Het Common Crawl-corpus bevat petabytes aan gegevens, die sinds 2008 regelmatig worden verzameld, en bevat onbewerkte webpaginagegevens, metadata-extracten en tekstextracten. Naast het bepalen welke dataset moet worden gebruikt, is het opschonen en verwerken van de gegevens volgens de specifieke behoefte van de afstemming vereist.
We hebben onlangs samengewerkt met een klant die een subset van de nieuwste Common Crawl-dataset wilde voorbewerken en vervolgens zijn LLM wilde verfijnen met opgeschoonde gegevens. De klant was op zoek naar hoe ze dit op de meest kosteneffectieve manier konden bereiken op AWS. Nadat we de vereisten hadden besproken, adviseerden we het gebruik ervan Amazon EMR Serverloos als hun platform voor gegevensvoorverwerking. EMR Serverless is zeer geschikt voor grootschalige gegevensverwerking en elimineert de noodzaak voor infrastructuuronderhoud. Wat de kosten betreft, worden er alleen kosten in rekening gebracht op basis van de middelen en de duur die voor elke taak worden gebruikt. De klant kon binnen een week honderden TB's aan gegevens voorbewerken met behulp van EMR Serverless. Nadat ze de gegevens hadden voorbewerkt, gebruikten ze Amazon Sage Maker om de LLM te verfijnen.
In dit bericht leiden we u door de use case en de gebruikte architectuur van de klant.
In de volgende secties introduceren we eerst de Common Crawl-gegevensset en hoe we de gegevens die we nodig hebben, kunnen verkennen en filteren. Amazone Athene brengt alleen kosten in rekening voor de gegevensgrootte die wordt gescand en wordt gebruikt om de gegevens snel te verkennen en te filteren, terwijl het kosteneffectief is. EMR Serverless biedt een kostenefficiënte en onderhoudsvrije optie voor Spark-gegevensverwerking en wordt gebruikt om de gefilterde gegevens te verwerken. Vervolgens gebruiken we Amazon SageMaker JumpStart om het te verfijnen Lama 2-model met de voorbewerkte dataset. SageMaker JumpStart biedt een reeks oplossingen voor de meest voorkomende gebruiksscenario's die met slechts een paar klikken kunnen worden geïmplementeerd. U hoeft geen code te schrijven om een LLM zoals Llama 2 te verfijnen. Ten slotte implementeren we het verfijnde model met behulp van Amazon Sage Maker en vergelijk de verschillen in tekstuitvoer voor dezelfde vraag tussen de originele en verfijnde Llama 2-modellen.
Het volgende diagram illustreert de architectuur van deze oplossing.
Voordat u diep in de details van de oplossing duikt, voltooit u de volgende vereiste stappen:
Common Crawl is een open corpusdataset die wordt verkregen door het crawlen van meer dan 50 miljard webpagina's. Het bevat enorme hoeveelheden ongestructureerde gegevens in meerdere talen, beginnend in 2008 en bereikend het petabyteniveau. Het wordt voortdurend bijgewerkt.
In de training van GPT-3 is de Common Crawl-dataset verantwoordelijk voor 60% van de trainingsgegevens, zoals weergegeven in het volgende diagram (bron: Taalmodellen zijn weinig geschoten leerlingen).
Een andere belangrijke dataset die het vermelden waard is, is de C4-gegevensset. C4, een afkorting voor Colossal Clean Crawled Corpus, is een dataset die is afgeleid van de nabewerking van de Common Crawl-dataset. In Meta's LLaMA-paper schetsten ze de gebruikte datasets, waarbij Common Crawl 67% voor zijn rekening nam (waarbij 3.3 TB aan gegevens werd gebruikt) en C4 voor 15% (waarbij 783 GB aan gegevens werd gebruikt). Het artikel benadrukt het belang van het opnemen van verschillend voorbewerkte gegevens voor het verbeteren van de modelprestaties. Ondanks dat de originele C4-gegevens deel uitmaakten van Common Crawl, koos Meta voor de opnieuw verwerkte versie van deze gegevens.
In deze sectie bespreken we veelgebruikte manieren om de Common Crawl-gegevensset te interageren, filteren en verwerken.
De onbewerkte dataset van Common Crawl bevat drie soorten gegevensbestanden: onbewerkte webpaginagegevens (WARC), metagegevens (WAT) en tekstextractie (WET).
Gegevens verzameld na 2013 worden opgeslagen in WARC-formaat en bevatten bijbehorende metadata (WAT) en tekstextractiegegevens (WET). De dataset bevindt zich in Amazon S3, wordt maandelijks bijgewerkt en is rechtstreeks toegankelijk via AWS Marketplace.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzDe Common Crawl-gegevensset biedt ook een indextabel voor het filteren van gegevens, die cc-index-table wordt genoemd.
De cc-index-tabel is een index van de bestaande gegevens en biedt een tabelgebaseerde index van WARC-bestanden. Hiermee kunt u eenvoudig informatie opzoeken, zoals welk WARC-bestand overeenkomt met een specifieke URL.
U kunt bijvoorbeeld een Athena-tabel maken om cc-indexgegevens in kaart te brengen met de volgende code:
De voorgaande SQL-instructies laten zien hoe u een Athena-tabel maakt, partities toevoegt en een query uitvoert.
Filter gegevens uit de Common Crawl-gegevensset
Zoals u kunt zien in de SQL-instructie Create Table, zijn er verschillende velden die kunnen helpen bij het filteren van de gegevens. Als u bijvoorbeeld het aantal Chinese documenten gedurende een specifieke periode wilt weten, kan de SQL-instructie er als volgt uitzien:
Als u verdere verwerking wilt uitvoeren, kunt u de resultaten opslaan in een andere S3-bucket.
Analyseer de gefilterde gegevens
De Algemene Crawl GitHub-repository biedt verschillende PySpark-voorbeelden voor het verwerken van de onbewerkte gegevens.
Laten we eens kijken naar een voorbeeld van hardlopen server_count.py (voorbeeldscript geleverd door de Common Crawl GitHub-repository) op de gegevens in s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
Ten eerste heb je een Spark-omgeving nodig, zoals EMR Spark. U kunt bijvoorbeeld een Amazon EMR op het EC2-cluster lanceren us-east-1 (omdat de dataset binnen is us-east-1). Het gebruik van een EMR op het EC2-cluster kan u helpen bij het uitvoeren van tests voordat u taken naar de productieomgeving verzendt.
Nadat u een EMR op het EC2-cluster hebt gestart, moet u SSH inloggen op het primaire knooppunt van het cluster. Verpak vervolgens de Python-omgeving en dien het script in (zie de Conda-documentatie om Miniconda te installeren):
Het kan enige tijd duren om alle verwijzingen in warc.path te verwerken. Voor demodoeleinden kunt u de verwerkingstijd verbeteren met de volgende strategieën:
- Download het bestand
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gznaar uw lokale computer, pak het uit en upload het vervolgens naar HDFS of Amazon S3. Dit komt omdat het .gzip-bestand niet splitsbaar is. U moet het uitpakken om dit bestand parallel te kunnen verwerken. - Wijzig de
warc.pathbestand, verwijder de meeste regels en bewaar slechts twee regels om de taak veel sneller te laten verlopen.
Nadat de taak is voltooid, kunt u het resultaat zien s3://xxxx-common-crawl/output/, in Parquet-formaat.
Implementeer aangepaste bezitslogica
De Common Crawl GitHub-opslagplaats biedt een algemene aanpak voor het verwerken van WARC-bestanden. Over het algemeen kunt u de CCSparkJob een enkele methode overschrijven (process_record), wat in veel gevallen voldoende is.
Laten we naar een voorbeeld kijken om de IMDB-recensies van recente films te krijgen. Eerst moet u bestanden op de IMDB-site filteren:
Vervolgens kunt u WARC-bestandslijsten verkrijgen die IMDB-beoordelingsgegevens bevatten, en de WARC-bestandsnamen opslaan als een lijst in een tekstbestand.
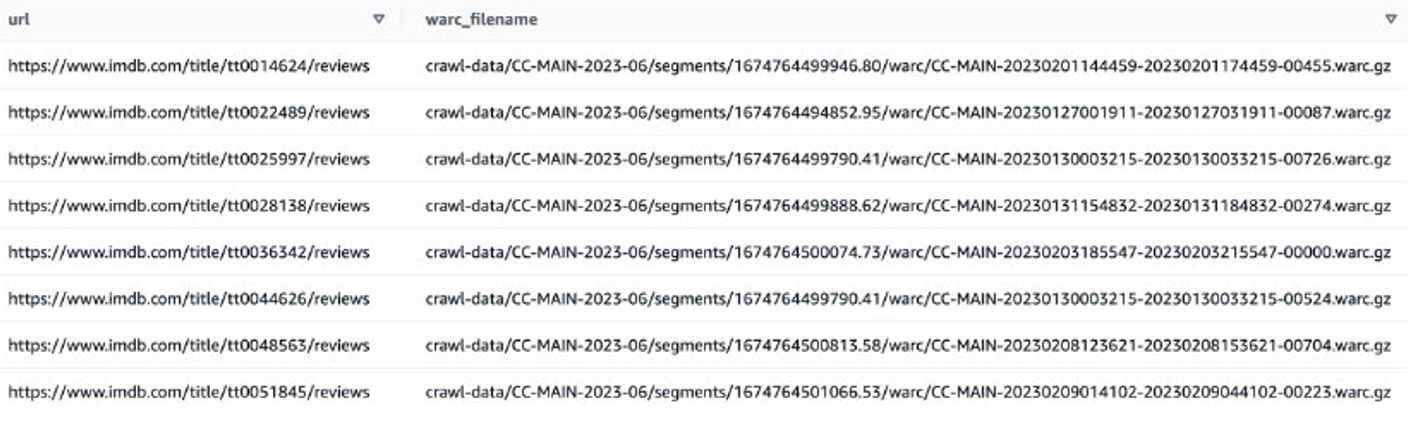
Als alternatief kunt u EMR Spark gebruiken om de WARC-bestandslijst op te halen en deze op te slaan in Amazon S3. Bijvoorbeeld:
Het uitvoerbestand zou er ongeveer zo uit moeten zien s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
De volgende stap is het extraheren van gebruikersrecensies uit deze WARC-bestanden. Je kunt de CCSparkJob het overschrijven process_record() methode:
U kunt het voorgaande script opslaan als imdb_extractor.py, dat u in de volgende stappen gaat gebruiken. Nadat u de gegevens en scripts heeft voorbereid, kunt u EMR Serverless gebruiken om de gefilterde gegevens te verwerken.
EMR-serverloos
EMR Serverless is een serverloze implementatieoptie om big data-analysetoepassingen uit te voeren met behulp van open source-frameworks zoals Apache Spark en Hive zonder clusters of servers te configureren, beheren en schalen.
Met EMR Serverless kunt u analyseworkloads op elke schaal uitvoeren met automatische schaling, waarbij de grootte van resources binnen enkele seconden wordt aangepast om te voldoen aan veranderende gegevensvolumes en verwerkingsvereisten. EMR Serverless schaalt bronnen automatisch op en neer om de juiste hoeveelheid capaciteit voor uw applicatie te bieden, en u betaalt alleen voor wat u gebruikt.
Het verwerken van de Common Crawl-gegevensset is over het algemeen een eenmalige verwerkingstaak, waardoor deze geschikt is voor EMR-serverloze werkbelastingen.
Maak een EMR-serverloze applicatie
U kunt een EMR Serverless-toepassing maken op de EMR Studio-console. Voer de volgende stappen uit:
- Kies op de EMR Studio-console Toepassingen voor Serverless in het navigatievenster.
- Kies Maak een applicatie.

- Geef een naam op voor de applicatie en kies een Amazon EMR-versie.
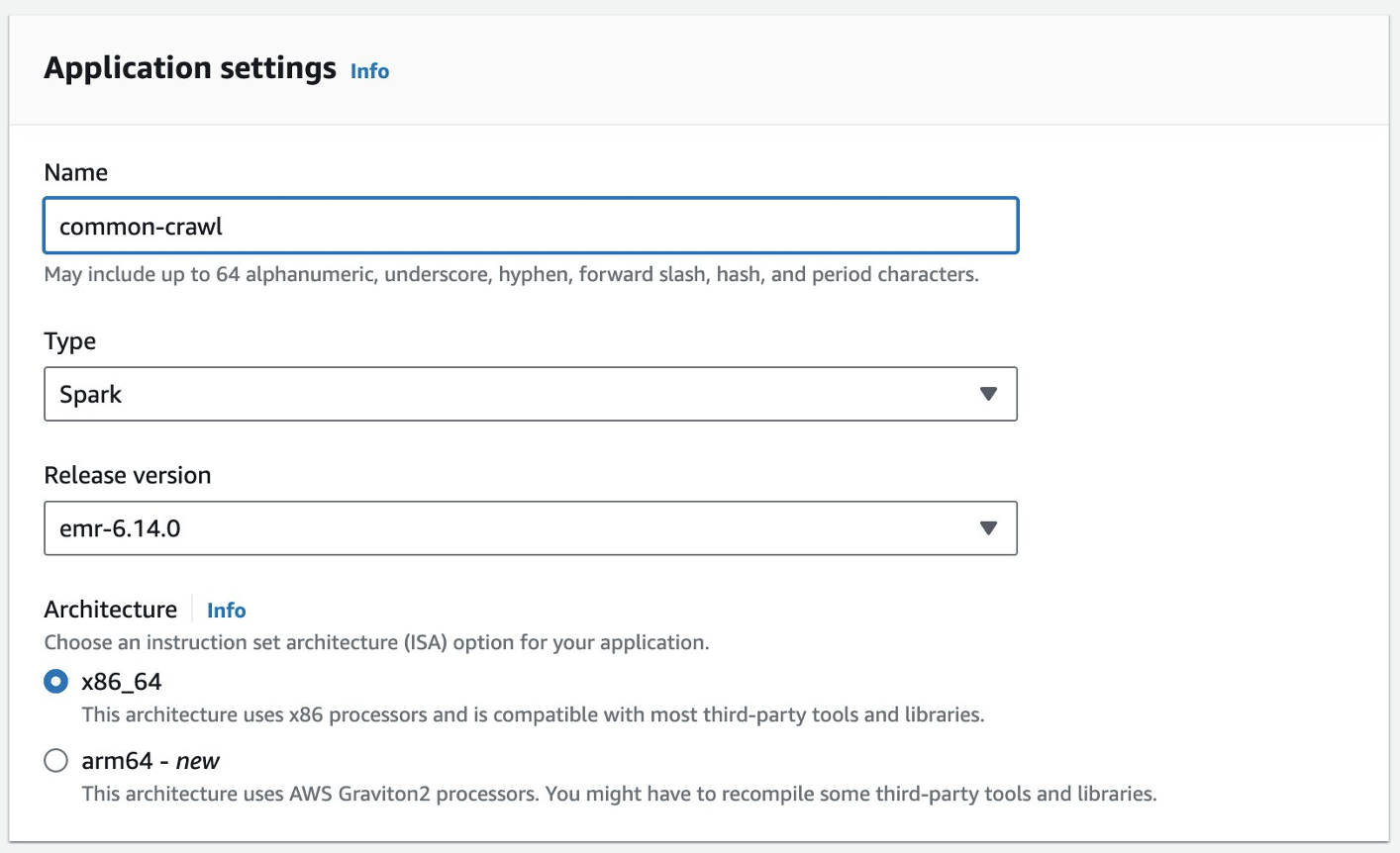
- Als toegang tot VPC-bronnen vereist is, voegt u een aangepaste netwerkinstelling toe.

- Kies Maak een applicatie.
Uw Spark serverloze omgeving is dan klaar.
Voordat u een taak kunt indienen bij EMR Spark Serverless, moet u nog een uitvoeringsrol aanmaken. Verwijzen naar Aan de slag met Amazon EMR Serverloos voor meer details.
Verwerk algemene crawlgegevens met EMR Serverless
Nadat uw EMR Spark Serverless-applicatie gereed is, voert u de volgende stappen uit om de gegevens te verwerken:
- Bereid een Conda-omgeving voor en upload deze naar Amazon S3, die zal worden gebruikt als de omgeving in EMR Spark Serverless.
- Upload de scripts die moeten worden uitgevoerd naar een S3-bucket. In het volgende voorbeeld zijn er twee scripts:
- imbd_extractor.py – Aangepaste logica om inhoud uit de dataset te extraheren. De inhoud vind je eerder in dit bericht.
- cc-pyspark/sparkcc.py – Het voorbeeld PySpark-framework uit de Algemene crawl GitHub-opslagplaats, die moet worden opgenomen.
- Verzend de PySpark-taak naar EMR Serverless Spark. Definieer de volgende parameters om dit voorbeeld in uw omgeving uit te voeren:
- Applicatie ID – De applicatie-ID van uw EMR Serverless-applicatie.
- uitvoering-rol-arn – Uw EMR Serverloze uitvoeringsrol. Raadpleeg om het te maken Maak een taakruntimerol.
- WARC-bestandslocatie – De locatie van uw WARC-bestanden.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtbevat de gefilterde WARC-bestandslijst, die je eerder in dit bericht hebt verkregen. - spark.sql.warehouse.dir – De standaardmagazijnlocatie (gebruik uw S3-directory).
- spark.archieven – De S3-locatie van de voorbereide Conda-omgeving.
- spark.submit.pyFiles – Het voorbereide PySpark-script sparkcc.py.
Zie de volgende code:
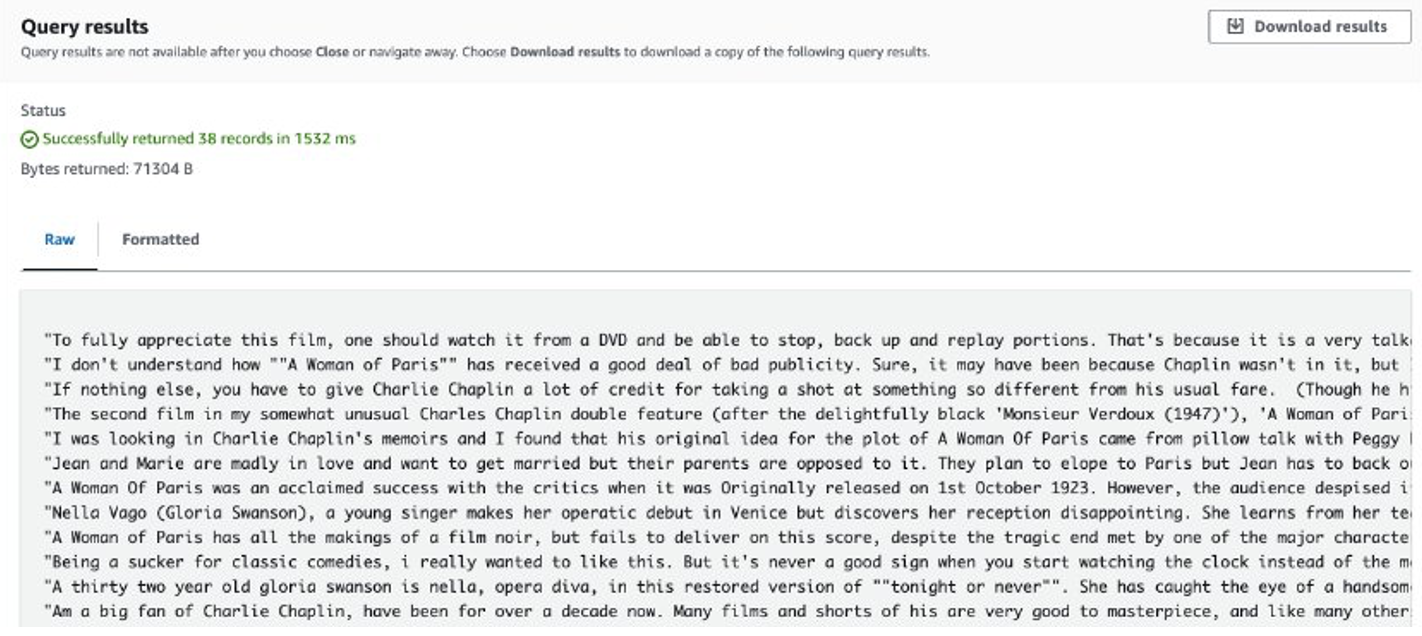
Nadat de taak is voltooid, worden de opgehaalde beoordelingen opgeslagen in Amazon S3. Om de inhoud te controleren, kunt u Amazon S3 Select gebruiken, zoals weergegeven in de volgende schermafbeelding.
Overwegingen
Hier volgen de punten waarmee u rekening moet houden bij het verwerken van enorme hoeveelheden gegevens met aangepaste code:
- Sommige Python-bibliotheken van derden zijn mogelijk niet beschikbaar in Conda. In dergelijke gevallen kunt u overschakelen naar een virtuele Python-omgeving om de PySpark-runtimeomgeving te bouwen.
- Als er een enorme hoeveelheid gegevens moet worden verwerkt, probeer dan meerdere EMR Serverless Spark-applicaties te maken en te gebruiken om deze te parallelliseren. Elke toepassing behandelt een subset van bestandslijsten.
- Er kan een vertragingsprobleem optreden met Amazon S3 bij het filteren of verwerken van de Common Crawl-gegevens. Dit komt omdat de S3-bucket waarin de gegevens worden opgeslagen, openbaar toegankelijk is en andere gebruikers tegelijkertijd toegang hebben tot de gegevens. Om dit probleem te verhelpen, kunt u een mechanisme voor opnieuw proberen toevoegen of specifieke gegevens uit de Common Crawl S3-bucket naar uw eigen bucket synchroniseren.
Verfijn Llama 2 met SageMaker
Nadat de gegevens zijn voorbereid, kunt u er een Llama 2-model mee finetunen. U kunt dit doen met SageMaker JumpStart, zonder code te schrijven. Voor meer informatie, zie Verfijn Llama 2 voor het genereren van tekst op Amazon SageMaker JumpStart.
In dit scenario voert u een verfijning van de domeinaanpassing uit. Bij deze dataset bestaat de invoer uit een CSV-, JSON- of TXT-bestand. U moet alle beoordelingsgegevens in een TXT-bestand plaatsen. Om dit te doen, kunt u een eenvoudige Spark-taak indienen bij EMR Spark Serverless. Zie het volgende voorbeeldcodefragment:
Nadat u de trainingsgegevens hebt voorbereid, voert u de gegevenslocatie in voor Trainingsgegevensset, kies dan Trainen.
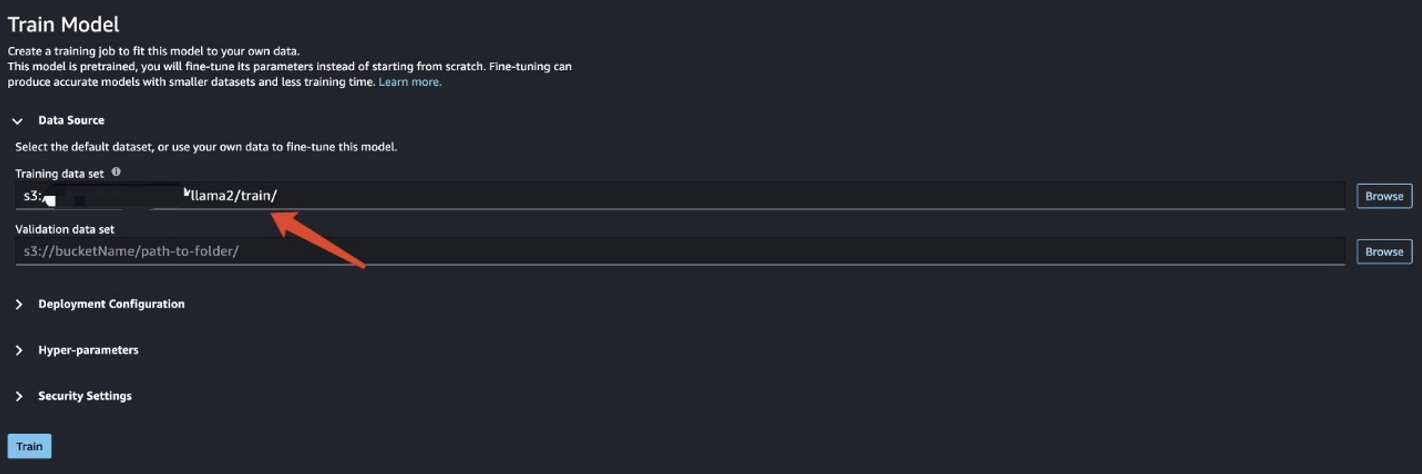
U kunt de status van de trainingstaak volgen.
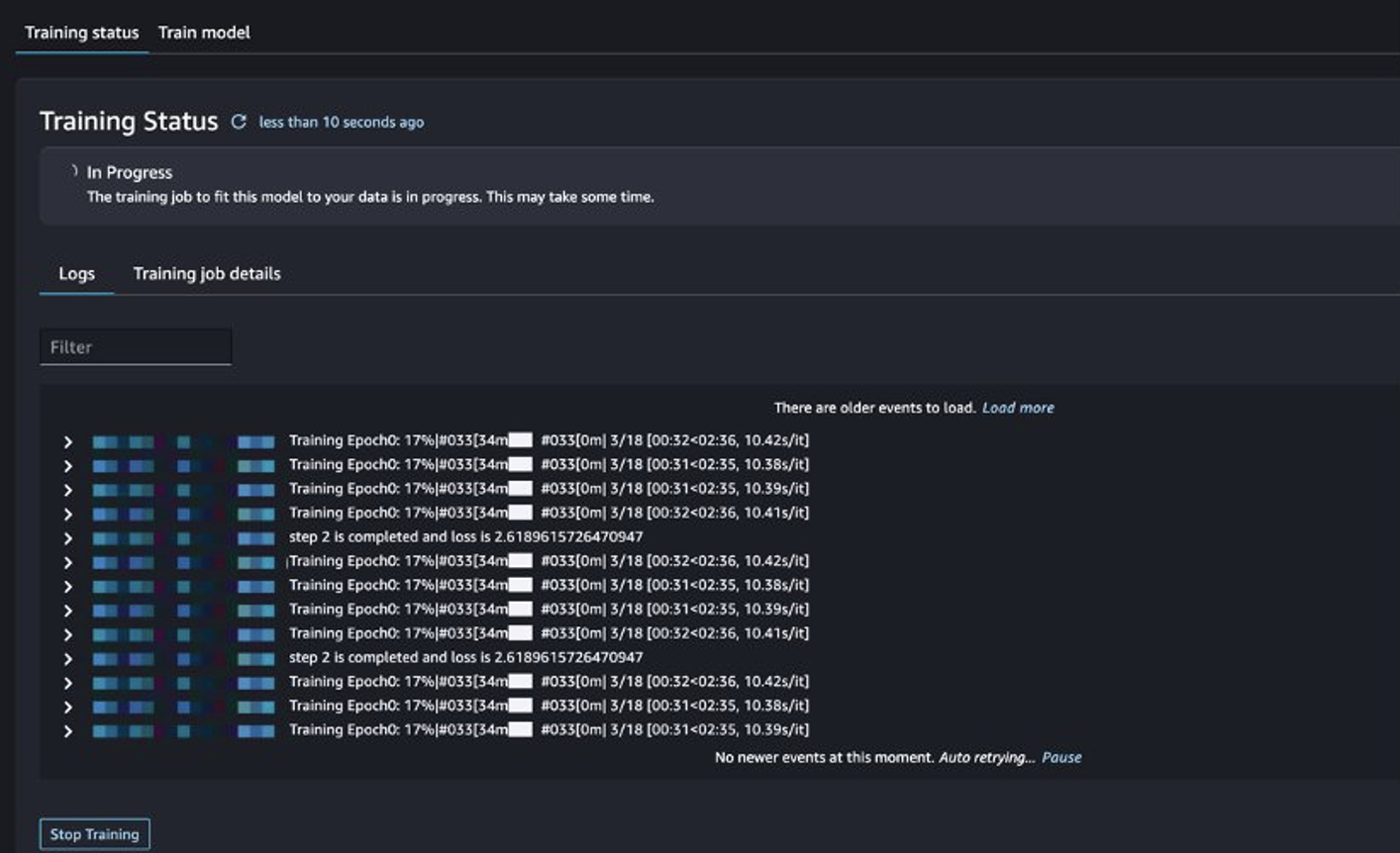
Evalueer het verfijnde model
Nadat de training is voltooid, kiest u Implementeren in SageMaker JumpStart om uw verfijnde model te implementeren.

Nadat het model met succes is geïmplementeerd, kiest u Notitieblok openen, waarmee u wordt omgeleid naar een voorbereid Jupyter-notebook waar u uw Python-code kunt uitvoeren.

U kunt de afbeelding Data Science 2.0 en de Python 3-kernel voor de notebook gebruiken.

Vervolgens kunt u het verfijnde model en het originele model in deze notebook evalueren.
Hieronder volgen twee antwoorden die zijn geretourneerd door het oorspronkelijke model en het verfijnde model voor dezelfde vraag.
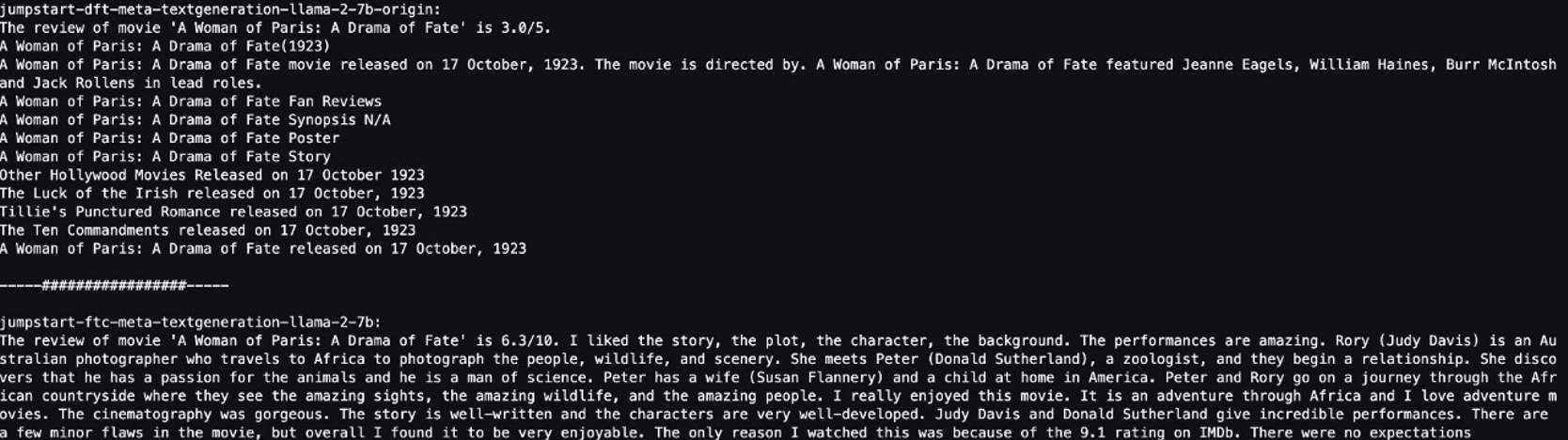
We voorzagen beide modellen van dezelfde zin: “De recensie van de film 'A Woman of Paris: A Drama of Fate' is” en lieten ze de zin afmaken.
Het originele model levert betekenisloze zinnen op:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
De resultaten van het verfijnde model lijken daarentegen meer op een filmrecensie:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
Het is duidelijk dat het verfijnde model beter presteert in dit specifieke scenario.
Opruimen
Nadat u deze oefening hebt voltooid, voert u de volgende stappen uit om uw bronnen op te ruimen:
- Verwijder de S3-bucket waarin de opgeschoonde gegevensset wordt opgeslagen.
- Stop de EMR Serverloze omgeving.
- Verwijder het SageMaker-eindpunt dat het LLM-model host.
- Verwijder het SageMaker-domein waarop uw notebooks draaien.
De applicatie die u hebt gemaakt, zou standaard automatisch moeten stoppen na 15 minuten inactiviteit.
Over het algemeen hoeft u de Athena-omgeving niet op te ruimen, omdat er geen kosten aan verbonden zijn als u deze niet gebruikt.
Conclusie
In dit bericht hebben we de Common Crawl-dataset geïntroduceerd en hoe u EMR Serverless kunt gebruiken om de gegevens te verwerken voor LLM-verfijning. Vervolgens hebben we gedemonstreerd hoe u SageMaker JumpStart kunt gebruiken om de LLM te verfijnen en zonder enige code te implementeren. Voor meer gebruiksscenario's van EMR Serverless raadpleegt u Amazon EMR serverloos. Voor meer informatie over het hosten en afstemmen van modellen op Amazon SageMaker JumpStart raadpleegt u de Sagemaker JumpStart-documentatie.
Over de auteurs
 Shijian Tang is een Analytics Specialist Solution Architect bij Amazon Web Services.
Shijian Tang is een Analytics Specialist Solution Architect bij Amazon Web Services.
 Matthijs Liem is Senior Solution Architecture Manager bij Amazon Web Services.
Matthijs Liem is Senior Solution Architecture Manager bij Amazon Web Services.
 Dalei Xu is een Analytics Specialist Solution Architect bij Amazon Web Services.
Dalei Xu is een Analytics Specialist Solution Architect bij Amazon Web Services.
 Yuanjun Xiao is een Senior Solution Architect bij Amazon Web Services.
Yuanjun Xiao is een Senior Solution Architect bij Amazon Web Services.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/

