KT Corporation is een van de grootste telecommunicatieaanbieders in Zuid-Korea en biedt een breed scala aan diensten, waaronder vaste telefonie, mobiele communicatie en internet, en AI-diensten. KT's AI Food Tag is een op AI gebaseerde oplossing voor voedingsbeheer die het type en de voedingswaarde van voedsel op foto's identificeert met behulp van een computervisiemodel. Dit door KT ontwikkelde visiemodel is gebaseerd op een model dat vooraf is getraind met een grote hoeveelheid ongelabelde beeldgegevens om de voedingswaarde en calorie-informatie van verschillende voedingsmiddelen te analyseren. De AI Food Tag kan patiënten met chronische ziekten zoals diabetes helpen hun dieet te beheren. KT gebruikte AWS en Amazon Sage Maker om dit AI Food Tag-model 29 keer sneller dan voorheen te trainen en te optimaliseren voor productie-implementatie met een modeldistillatietechniek. In dit bericht beschrijven we het modelontwikkelingstraject en het succes van KT met behulp van SageMaker.
Het KT-project introduceren en het probleem definiëren
Het AI Food Tag-model dat vooraf is getraind door KT is gebaseerd op de vision transformers (ViT)-architectuur en heeft meer modelparameters dan hun vorige vision-model om de nauwkeurigheid te verbeteren. Om de modelgrootte voor productie te verkleinen, gebruikt KT een kennisdistillatietechniek (KD) om het aantal modelparameters te verminderen zonder significante gevolgen voor de nauwkeurigheid. Bij kennisdistillatie wordt het vooraf getrainde model a genoemd leraar model, en een lichtgewicht uitvoermodel wordt getraind als a studentenmodel, zoals geïllustreerd in de volgende afbeelding. Het lichtgewicht studentenmodel heeft minder modelparameters dan de docent, waardoor er minder geheugen nodig is en implementatie op kleinere, goedkopere instanties mogelijk is. De leerling behoudt een aanvaardbare nauwkeurigheid, ook al is deze kleiner, door te leren van de resultaten van het lerarenmodel.

Het lerarenmodel blijft tijdens KD ongewijzigd, maar het leerlingmodel wordt getraind met behulp van de uitvoerlogits van het lerarenmodel als labels om het verlies te berekenen. Met dit KD-paradigma moeten zowel de leraar als de leerling voor training gebruik maken van één GPU-geheugen. KT gebruikte aanvankelijk twee GPU's (A100 80 GB) in hun interne, lokale omgeving om het studentenmodel te trainen, maar het proces duurde ongeveer 40 dagen en besloeg 300 tijdperken. Om de training te versnellen en in minder tijd een studentenmodel te genereren, werkte KT samen met AWS. Samen hebben de teams de modeltrainingstijd aanzienlijk verkort. Dit bericht beschrijft hoe het team gebruikte Amazon SageMaker-training SageMaker Data Parallellisme Bibliotheek, Amazon SageMaker-foutopsporing en Amazon SageMaker-profiler om met succes een lichtgewicht AI Food Tag-model te ontwikkelen.
Een gedistribueerde trainingsomgeving bouwen met SageMaker
SageMaker Training is een beheerde machine learning (ML)-trainingsomgeving op AWS die een reeks functies en hulpmiddelen biedt om de trainingservaring te vereenvoudigen en die nuttig kan zijn bij gedistribueerd computergebruik, zoals geïllustreerd in het volgende diagram.
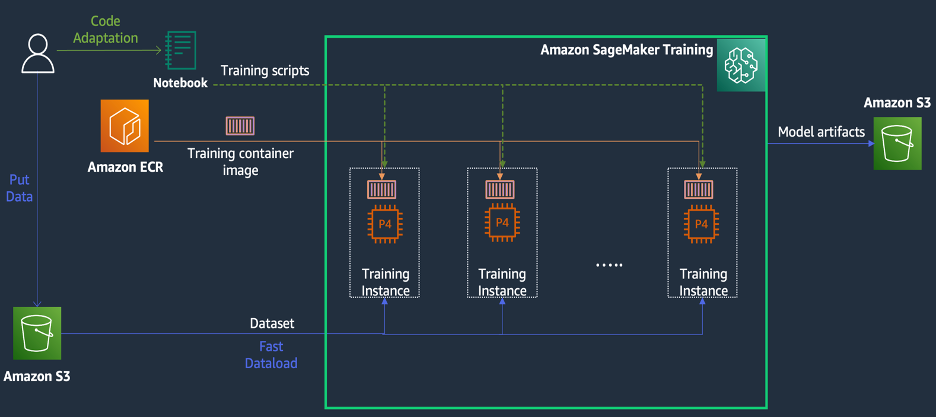
Klanten van SageMaker hebben ook toegang tot ingebouwde Docker-images met verschillende vooraf geïnstalleerde deep learning-frameworks en de benodigde Linux-, NCCL- en Python-pakketten voor modeltraining. Datawetenschappers of ML-ingenieurs die modeltraining willen uitvoeren, kunnen dit doen zonder de last van het configureren van de trainingsinfrastructuur of het beheren van Docker en de compatibiliteit van verschillende bibliotheken.
Tijdens een workshop van één dag konden we een gedistribueerde trainingsconfiguratie opzetten op basis van SageMaker binnen het AWS-account van KT, de trainingsscripts van KT versnellen met behulp van de SageMaker Distributed Data Parallel (DDP)-bibliotheek, en zelfs een trainingstaak testen met behulp van twee ml. p1d.4xgrote exemplaren. In deze sectie beschrijven we de ervaring van KT met het werken met het AWS-team en het gebruik van SageMaker om hun model te ontwikkelen.
In de proof of concept wilden we een trainingsopdracht versnellen door gebruik te maken van de SageMaker DDP-bibliotheek, die is geoptimaliseerd voor de AWS-infrastructuur tijdens gedistribueerde training. Om van PyTorch DDP naar SageMaker DDP te veranderen, hoeft u alleen maar het torch_smddp package en verander de backend naar smddp, zoals weergegeven in de volgende code:
Voor meer informatie over de SageMaker DDP-bibliotheek raadpleegt u SageMaker's data-parallellismebibliotheek.
Analyseren van de oorzaken van een trage trainingssnelheid met de SageMaker Debugger en Profiler
De eerste stap bij het optimaliseren en versnellen van de trainingswerklast omvat het begrijpen en diagnosticeren van waar knelpunten optreden. Voor de trainingstaak van KT hebben we de trainingstijd gemeten per iteratie van de gegevenslader, voorwaartse pass en achterwaartse pass:
| 1 itertijd – dataloader: 0.00053 sec, vooruit: 7.77474 sec, achteruit: 1.58002 sec |
| 2 itertijd – dataloader: 0.00063 sec, vooruit: 0.67429 sec, achteruit: 24.74539 sec |
| 3 itertijd – dataloader: 0.00061 sec, vooruit: 0.90976 sec, achteruit: 8.31253 sec |
| 4 itertijd – dataloader: 0.00060 sec, vooruit: 0.60958 sec, achteruit: 30.93830 sec |
| 5 itertijd – dataloader: 0.00080 sec, vooruit: 0.83237 sec, achteruit: 8.41030 sec |
| 6 itertijd – dataloader: 0.00067 sec, vooruit: 0.75715 sec, achteruit: 29.88415 sec |
Als we voor elke iteratie naar de tijd in de standaarduitvoer keken, zagen we dat de looptijd van de achterwaartse doorgang aanzienlijk fluctueerde van iteratie tot iteratie. Deze variatie is ongebruikelijk en kan van invloed zijn op de totale trainingstijd. Om de oorzaak van deze inconsistente trainingssnelheid te vinden, hebben we eerst geprobeerd knelpunten in de bronnen te identificeren door gebruik te maken van de System Monitor (SageMaker Debugger UI), waarmee u trainingstaken op SageMaker Training kunt debuggen en de status van bronnen kunt bekijken, zoals die van het beheerde trainingsplatform. CPU, GPU, netwerk en I/O binnen een bepaald aantal seconden.
De gebruikersinterface van SageMaker Debugger biedt gedetailleerde en essentiële gegevens die kunnen helpen bij het identificeren en diagnosticeren van knelpunten in een trainingstaak. Met name het CPU-gebruikslijndiagram en de CPU/GPU-gebruiksheatmap per instance-tabellen trokken onze aandacht.
In het lijndiagram voor CPU-gebruik merkten we dat sommige CPU's voor 100% werden gebruikt.
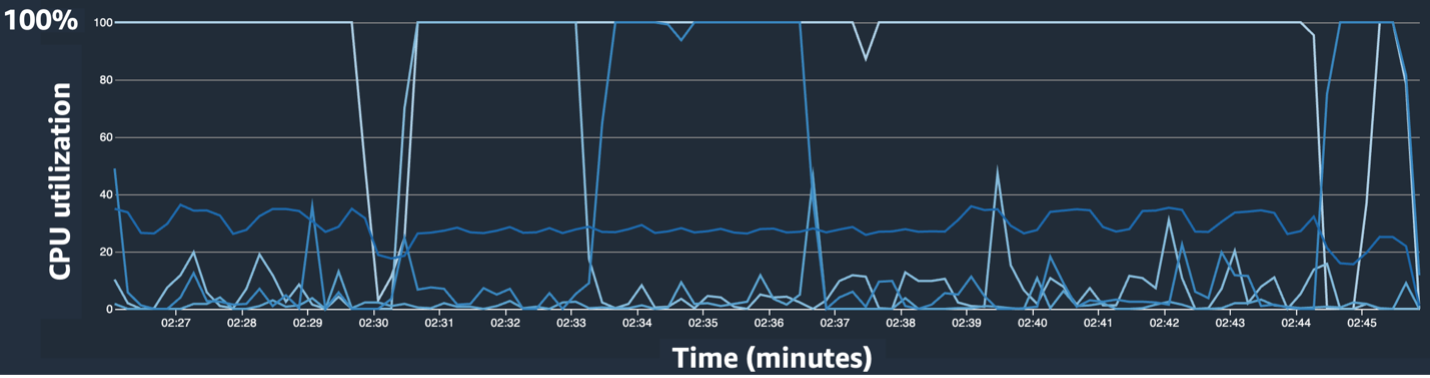
In de heatmap (waar donkere kleuren een hoger gebruik aangeven) zagen we dat een aantal CPU-kernen tijdens de training een hoog gebruik hadden, terwijl het GPU-gebruik in de loop van de tijd niet consistent hoog was.

Vanaf hier begonnen we te vermoeden dat een van de redenen voor de trage trainingssnelheid een CPU-knelpunt was. We hebben de trainingsscriptcode beoordeeld om te zien of iets het CPU-knelpunt veroorzaakte. Het meest verdachte was de grote waarde van num_workers in de dataloader, dus hebben we deze waarde gewijzigd in 0 of 1 om het CPU-gebruik te verminderen. Vervolgens hebben we de trainingsopdracht opnieuw uitgevoerd en de resultaten gecontroleerd.
De volgende schermafbeeldingen tonen het lijndiagram van het CPU-gebruik, het GPU-gebruik en de heatmap nadat het CPU-knelpunt is verholpen.
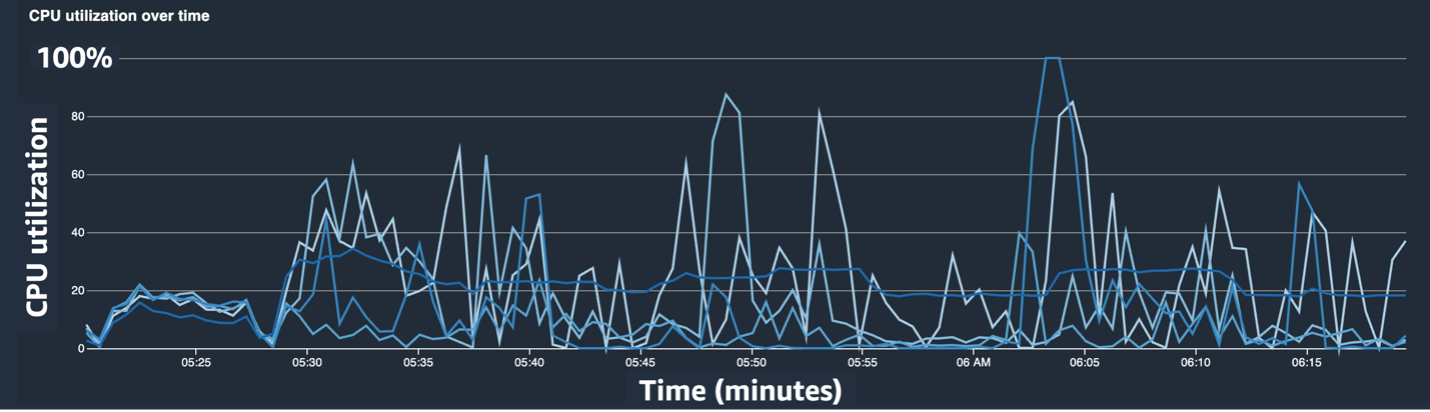


Door simpelweg te veranderen num_workerszagen we een aanzienlijke afname in het CPU-gebruik en een algehele toename in het GPU-gebruik. Dit was een belangrijke verandering die de trainingssnelheid aanzienlijk verbeterde. Toch wilden we kijken waar we het GPU-gebruik konden optimaliseren. Hiervoor hebben we SageMaker Profiler gebruikt.
SageMaker Profiler helpt bij het identificeren van optimalisatie-aanwijzingen door inzicht te geven in het gebruik door bewerkingen, inclusief het volgen van GPU- en CPU-gebruiksstatistieken en het kernelverbruik van GPU/CPU binnen trainingsscripts. Het helpt gebruikers te begrijpen welke bewerkingen bronnen verbruiken. Om SageMaker Profiler te gebruiken, moet u eerst toevoegen ProfilerConfig naar de functie die de trainingstaak aanroept met behulp van de SageMaker SDK, zoals weergegeven in de volgende code:
In de SageMaker Python SDK heeft u de flexibiliteit om de annotate functies voor SageMaker Profiler om code of stappen in het trainingsscript te selecteren waarvoor profilering nodig is. Het volgende is een voorbeeld van de code die u voor SageMaker Profiler moet declareren in de trainingsscripts:
Als u na het toevoegen van de voorgaande code een trainingstaak uitvoert met behulp van de trainingsscripts, kunt u informatie krijgen over de bewerkingen die door de GPU-kernel worden verbruikt (zoals weergegeven in de volgende afbeelding) nadat de training gedurende een bepaalde periode is uitgevoerd. In het geval van de trainingsscripts van KT hebben we deze gedurende één tijdperk uitgevoerd en kregen de volgende resultaten.
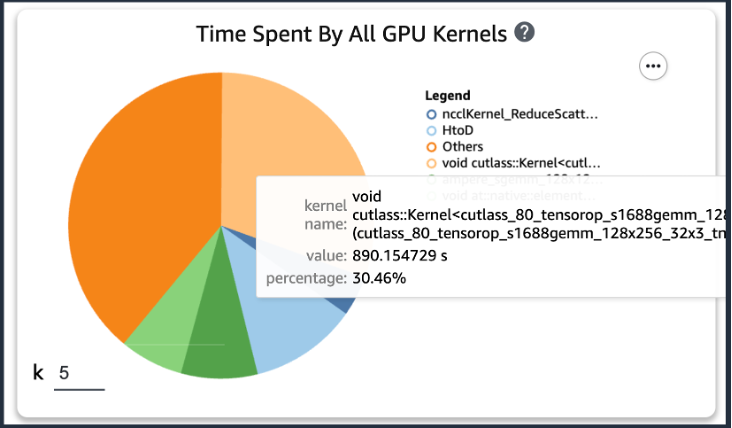
Toen we de top vijf gebruikstijden van de GPU-kernel onder de resultaten van SageMaker Profiler controleerden, ontdekten we dat voor het KT-trainingsscript de meeste tijd wordt verbruikt door de matrixproductbewerking, wat een algemene matrixvermenigvuldiging (GEMM) is. op GPU's. Met dit belangrijke inzicht uit de SageMaker Profiler zijn we begonnen met het onderzoeken van manieren om deze bewerkingen te versnellen en het GPU-gebruik te verbeteren.
Versnel de trainingstijd
We hebben verschillende manieren besproken om de rekentijd van matrixvermenigvuldiging te verkorten en twee PyTorch-functies toegepast.
Shard-optimalisatiestatussen met ZeroRedundancyOptimizer
Als je kijkt naar de Zero Redundancy Optimizer (ZeRO), maakt de DeepSpeed/ZeRO-techniek het mogelijk om een groot model efficiënt te trainen met een betere trainingssnelheid door de redundanties in het door het model gebruikte geheugen te elimineren. ZeroRedundancyOptimizer in PyTorch gebruikt de techniek van het sharden van de optimalisatiestatus om het geheugengebruik per proces in Distributed Data Parallel (DDP) te verminderen. DDP gebruikt gesynchroniseerde gradiënten in de achterwaartse doorgang, zodat alle replica's van de optimalisatie dezelfde parameters en gradiëntwaarden herhalen, maar in plaats van alle modelparameters te hebben, wordt elke optimalisatiestatus onderhouden door alleen sharding voor verschillende DDP-processen om het geheugengebruik te verminderen.
Om het te gebruiken, kunt u uw bestaande Optimizer laten staan optimizer_class en verklaar a ZeroRedundancyOptimizer met de rest van de modelparameters en de leersnelheid als parameters.
Automatische gemengde precisie
Automatische gemengde precisie (AMP) gebruikt het gegevenstype torch.float32 voor sommige bewerkingen en fakkel.bfloat16 of torch.float16 voor anderen, voor het gemak van snelle berekeningen en minder geheugengebruik. Omdat deep learning-modellen in hun berekeningen doorgaans gevoeliger zijn voor exponentbits dan voor fractiebits, is torch.bfloat16 met name gelijkwaardig aan de exponentbits van torch.float32, waardoor ze snel kunnen leren met minimaal verlies. torch.bfloat16 werkt alleen op instances met A100 NVIDIA-architectuur (Ampere) of hoger, zoals ml.p4d.24xlarge, ml.p4de.24xlarge en ml.p5.48xlarge.
Om AMP toe te passen, kunt u aangifte doen torch.cuda.amp.autocast in de trainingsscripts zoals weergegeven in de bovenstaande code en declareer dtype als fakkel.bfloat16.
Resultaten in SageMaker Profiler
Nadat we de twee functies op de trainingsscripts hadden toegepast en opnieuw een treintaak voor één tijdperk hadden uitgevoerd, controleerden we de top vijf van het verbruik van bewerkingen voor de GPU-kernel in SageMaker Profiler. De volgende afbeelding toont onze resultaten.
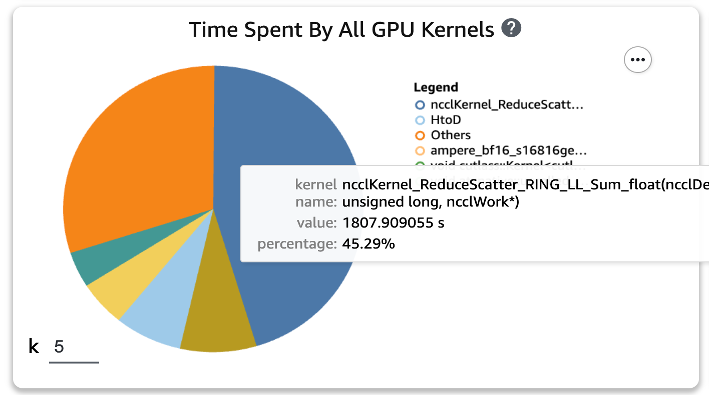
We kunnen zien dat de GEMM-bewerking, die bovenaan de lijst stond voordat de twee Torch-functies werden toegepast, uit de top vijf van bewerkingen is verdwenen en vervangen door de ReduceScatter-bewerking, die doorgaans plaatsvindt bij gedistribueerde training.
Trainingssnelheidsresultaten van het KT-gedistilleerde model
We hebben de batchgrootte van de training met 128 extra vergroot om rekening te houden met de geheugenbesparing door het toepassen van de twee Torch-functies, wat resulteerde in een uiteindelijke batchgrootte van 1152 in plaats van 1024. De training van het uiteindelijke studentenmodel kon 210 tijdperken per dag uitvoeren ; de trainingstijd en snelheid tussen de interne trainingsomgeving van KT en SageMaker zijn samengevat in de volgende tabel.
| Trainingsomgeving | GPU-specificatie trainen. | Aantal GPU's | Trainingstijd (uren) | Tijdperk | Uren per tijdperk | overbrengingsverhouding |
| De interne trainingsomgeving van KT | A100 (80 GB) | 2 | 960 | 300 | 3.20 | 29 |
| Amazon Sage Maker | A100 (40 GB) | 32 | 24 | 210 | 0.11 | 1 |
Dankzij de schaalbaarheid van AWS konden we de trainingstaak 29 keer sneller voltooien dan voorheen, waarbij we 32 GPU's gebruikten in plaats van twee op locatie. Als gevolg hiervan zou het gebruik van meer GPU's op SageMaker de trainingstijd aanzienlijk hebben verkort, zonder verschil in de totale trainingskosten.
Conclusie
Park Sang-min (teamleider Vision AI Serving Technology) van het AI2XL Lab in KT's Convergence Technology Center gaf commentaar op de samenwerking met AWS om het AI Food Tag-model te ontwikkelen:
“De laatste tijd, omdat er meer op transformatoren gebaseerde modellen in het gezichtsveld zijn, nemen de modelparameters en het vereiste GPU-geheugen toe. We gebruiken lichtgewicht technologie om dit probleem op te lossen, en het kost veel tijd, ongeveer een maand om het eenmaal te leren. Via deze PoC met AWS konden we de knelpunten in de bronnen identificeren met behulp van SageMaker Profiler en Debugger, deze oplossen en vervolgens de gegevensparallellismebibliotheek van SageMaker gebruiken om de training in ongeveer één dag te voltooien met geoptimaliseerde modelcode op vier ml.p4d. 24xgrote exemplaren.”
SageMaker hielp het team van Sang-min weken tijd te besparen bij het trainen en ontwikkelen van modellen.
Op basis van deze samenwerking op het visiemodel zullen AWS en het SageMaker-team blijven samenwerken met KT aan verschillende AI/ML-onderzoeksprojecten om de modelontwikkeling en de serviceproductiviteit te verbeteren door de mogelijkheden van SageMaker toe te passen.
Bekijk het volgende voor meer informatie over gerelateerde functies in SageMaker:
Over de auteurs
 Young Joon Choi, AI/ML Expert SA, heeft ervaring met zakelijke IT in verschillende sectoren, zoals productie, hightech en financiën, als ontwikkelaar, architect en datawetenschapper. Hij deed onderzoek naar machine learning en deep learning, met name naar onderwerpen als hyperparameteroptimalisatie en domeinaanpassing, waarbij hij algoritmen en papers presenteerde. Bij AWS is hij gespecialiseerd in AI/ML in verschillende sectoren, waarbij hij technische validatie levert met behulp van AWS-services voor gedistribueerde training/grootschalige modellen en het bouwen van MLOps. Hij stelt architecturen voor en beoordeelt deze, met als doel bij te dragen aan de uitbreiding van het AI/ML-ecosysteem.
Young Joon Choi, AI/ML Expert SA, heeft ervaring met zakelijke IT in verschillende sectoren, zoals productie, hightech en financiën, als ontwikkelaar, architect en datawetenschapper. Hij deed onderzoek naar machine learning en deep learning, met name naar onderwerpen als hyperparameteroptimalisatie en domeinaanpassing, waarbij hij algoritmen en papers presenteerde. Bij AWS is hij gespecialiseerd in AI/ML in verschillende sectoren, waarbij hij technische validatie levert met behulp van AWS-services voor gedistribueerde training/grootschalige modellen en het bouwen van MLOps. Hij stelt architecturen voor en beoordeelt deze, met als doel bij te dragen aan de uitbreiding van het AI/ML-ecosysteem.
 Jung Hoon Kim is een account SA van AWS Korea. Gebaseerd op ervaringen met het ontwerpen, ontwikkelen en modelleren van applicatiearchitectuur in verschillende sectoren, zoals hi-tech, productie, financiën en de publieke sector, werkt hij aan het AWS Cloud-traject en de optimalisatie van werklasten op AWS voor zakelijke klanten.
Jung Hoon Kim is een account SA van AWS Korea. Gebaseerd op ervaringen met het ontwerpen, ontwikkelen en modelleren van applicatiearchitectuur in verschillende sectoren, zoals hi-tech, productie, financiën en de publieke sector, werkt hij aan het AWS Cloud-traject en de optimalisatie van werklasten op AWS voor zakelijke klanten.
 Rots Sakong is onderzoeker bij KT R&D. Hij heeft onderzoek en ontwikkeling uitgevoerd voor de vision AI op verschillende gebieden en heeft voornamelijk gezichtskenmerken (geslacht/bril, hoeden, enz.)/gezichtsherkenningstechnologie met betrekking tot het gezicht uitgevoerd. Momenteel werkt hij aan lichtgewichttechnologie voor de vision-modellen.
Rots Sakong is onderzoeker bij KT R&D. Hij heeft onderzoek en ontwikkeling uitgevoerd voor de vision AI op verschillende gebieden en heeft voornamelijk gezichtskenmerken (geslacht/bril, hoeden, enz.)/gezichtsherkenningstechnologie met betrekking tot het gezicht uitgevoerd. Momenteel werkt hij aan lichtgewichttechnologie voor de vision-modellen.
 Manoj Ravi is een senior productmanager voor Amazon SageMaker. Hij heeft een passie voor het bouwen van AI-producten van de volgende generatie en werkt aan software en tools om grootschalige machine learning voor klanten eenvoudiger te maken. Hij heeft een MBA van de Haas School of Business en een Masters in Information Systems Management van de Carnegie Mellon University. In zijn vrije tijd speelt Manoj graag tennis en houdt hij zich bezig met landschapsfotografie.
Manoj Ravi is een senior productmanager voor Amazon SageMaker. Hij heeft een passie voor het bouwen van AI-producten van de volgende generatie en werkt aan software en tools om grootschalige machine learning voor klanten eenvoudiger te maken. Hij heeft een MBA van de Haas School of Business en een Masters in Information Systems Management van de Carnegie Mellon University. In zijn vrije tijd speelt Manoj graag tennis en houdt hij zich bezig met landschapsfotografie.
 Robert van Dusen is een Senior Product Manager bij Amazon SageMaker. Hij leidt raamwerken, compilers en optimalisatietechnieken voor deep learning-trainingen.
Robert van Dusen is een Senior Product Manager bij Amazon SageMaker. Hij leidt raamwerken, compilers en optimalisatietechnieken voor deep learning-trainingen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/kts-journey-to-reduce-training-time-for-a-vision-transformers-model-using-amazon-sagemaker/

