Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Hier is een geheim: synthetische controlemethoden kunnen dit probleem met het grootste gemak en zonder verlies van inkomsten of klanten oplossen. Als dit een experiment was, zou de hypothese zijn: het verwijderen van kaarten als betaalmethode heeft geen invloed op de omzet en verkoop. De testbasis zou bestaan uit klanten die geen kaart als betalingsoptie hebben, en de controlebasis zou kaarten als betalingsoptie hebben.
Synthetische controlemethode: casestudy
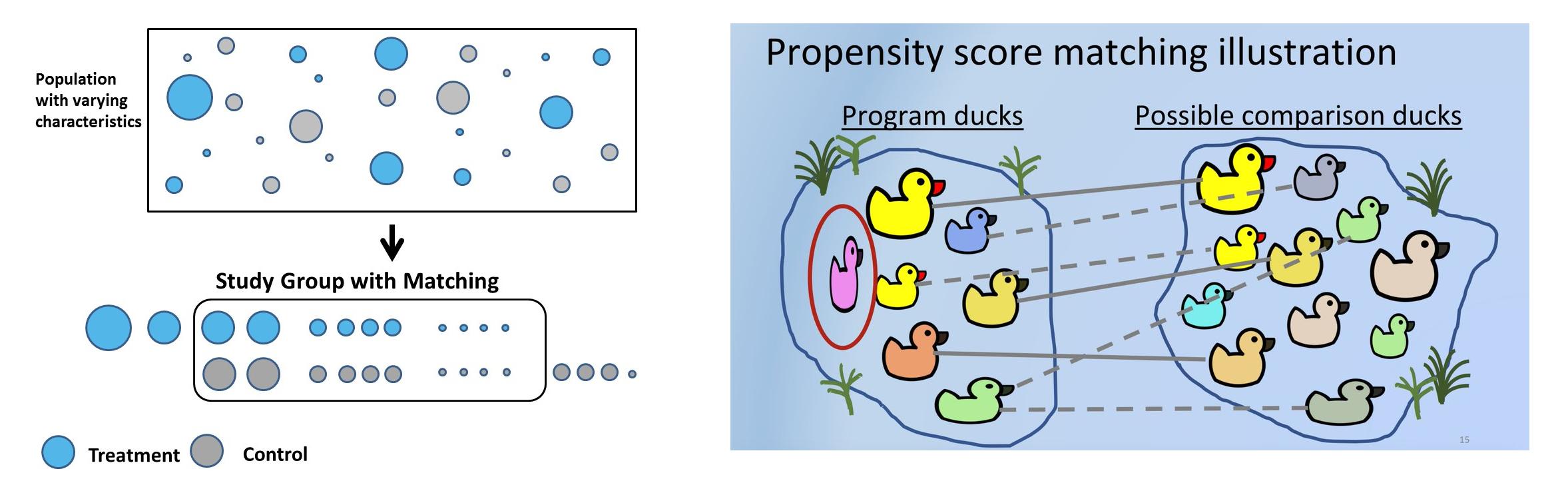
Synthetische controlemethoden (SCM), in eenvoudige bewoordingen, zullen voor elke testklant een vergelijkbare controleklant kiezen met behulp van een vooraf gedefinieerde set kenmerken of covariaten waarvan de kenmerken van voor de behandeling vergelijkbaar zijn, maar die geen behandeling hebben ondergaan. In SCM worden klanten units genoemd, interventies worden behandelingen genoemd en kenmerken worden covariaten genoemd. Bedrijven gebruiken SCM voor veel praktische use-cases. Uber gebruikte bijvoorbeeld SCM om te testen of het verstrekken van contactgegevens van de chauffeur vóór een rit de klanttevredenheid verhoogt.
Soms kunnen hypothesen niet worden getest in een experimentele opstelling vanwege juridische, zakelijke of platformredenen. Bijvoorbeeld: in Bangalore is Meghana's biryani een van de beste, en online bezorgplatforms (Swiggy of Zomato) merkten dat de kans groot is dat klanten met een hoge besteding ook bij Meghana bestellen. De hypothese is dat Meghana-klanten gemiddeld meer uitgeven dan de rest. Maar Swiggy of Zomato kunnen Meghana's niet voor 50% van de klanten van het platform verwijderen, alleen maar omwille van het experiment. Er zou zowel klant- als restaurantterugslag zijn. Met behulp van SCM kan een synthetische controle worden gemaakt waarbij test- en controleklanten vergelijkbare covariaten voor de behandeling hebben, en de hypothese kan worden gevalideerd.
Het oplossen van selectiebias en het gebruik van de juiste zakelijke heuristieken bij het kiezen van de juiste controle wordt erg belangrijk en kan zelfs de uitkomst van experimenten omkeren. De test zal bijvoorbeeld een reeks klanten zijn die Meghana's hebben besteld. Ter controle kunnen vegetarische klanten worden gekozen. Maar intrinsiek zijn test en controle verschillend omdat controle nooit een niet-vegetarische keuken heeft uitgeprobeerd. Een andere manier om te controleren zijn klanten die nooit biryani hebben besteld, maar dit zou geen geschikte controle zijn, aangezien Meghana's een zwaar biryani-restaurant is. Een andere manier om controle uit te oefenen, is door geografieën te gebruiken. Aangezien Meghana's niet aanwezig is in Delhi, kunnen Delhi-klanten als controle worden gebruikt. Maar de eetgewoonten van Delhi-gebruikers verschillen van die van Zuid-Indiase gebruikers en dit zal vooroordelen veroorzaken als het experiment wordt opgesplitst in verschillende dimensies, zoals leeftijdsgroep, geslacht en keuken. Juiste zakelijke heuristiek wordt zo een essentieel onderdeel bij het oplossen van synthetische controle.
Inhoudsopgave
Synthetische besturingselementen kunnen worden gemaakt met behulp van matching. Propensity score matching is de meest gebruikte methode om SC te maken, omdat het gemakkelijk en minder tijdrovend is, veel geld bespaart en kan worden geschaald naar een groot gebruikersbestand. Het proces kan N keer worden herhaald tot de meest vergelijkbare test en controle cohorten komen overeen.
Stappen betrokken bij het matchen van propensityscores:
- Selecteer een grote groep klanten – leeftijd, geslacht, verkoop, eenheden, enz. Dit zijn covariabelen die vooroordelen kunnen veroorzaken.
- Het belangrijkste doel is om de covariaten te matchen voordat wordt ingegrepen. Voor elke klant die met een creditcard heeft betaald – testklant, in controle, moet er een klant zijn wiens covariabelen voor de behandeling vergelijkbaar zijn met die van de test, maar die niet met een kaart heeft betaald, maar in plaats daarvan UPI of internetbankieren heeft gebruikt.
- Fit classificatiemodel om neigingsscores te krijgen. Nauwkeurigheid is niet belangrijk omdat voorspelde waarschijnlijkheden worden gebruikt om verschillende gebruikers te matchen. Boomgebaseerde of logistische regressie kan worden gebruikt. Het voordeel van op bomen gebaseerd is dat aannames van logistische regressie kunnen worden genegeerd.
- Met behulp van de waarschijnlijkheidsscore kunnen bijvoorbeeld 0.6 en 0.61 worden gematcht met behulp van k naaste buur. Matching kan 1:1 of 1:many zijn, waarbij duplicaten worden gebruikt.
- Onderzoek nu hoe de behandeling de uitkomst heeft beïnvloed. De behandeling is binair, 1 of 0. Meghana's besteld of niet, gebruikte kaart of niet. Maar de uitkomst kan continu zijn - toekomstige inkomsten of binair - gekarnd of niet, enz.
Probleemstelling
De hier gebruikte dataset is gebaseerd op klant betalingsgeschiedenis. Laten we het opsplitsen door een richtsnoer te nemen uit de probleemstelling van de debetkaart.
Hypothese: H0:Klanten die met kaarten betalen hebben hogere postinkomsten. Alternatieve hypothese: H1: Klanten die met kaarten betalen, hebben geen hogere postinkomsten (vandaar het experiment om kaartbetalingen helemaal van het platform te verwijderen). Als P<0.05, kunnen we de nulhypothese verwerpen en onomstotelijk zeggen dat klanten die met kaarten betalen geen hogere postinkomsten hebben.
Er zijn hier drie tijdsperioden: Pre-periode, waarop de kenmerken/covariaten zijn gebaseerd. Behandelingsperiode, waarbij klanten betalen met kaarten. Postperiode waarin het resultaat, in dit geval postomzet, wordt gemeten. Het is belangrijk om deze periodes zorgvuldig te kiezen om vooringenomenheid door evenementen te voorkomen en ervoor te zorgen dat er in deze periode geen promotioneel evenement is gepland en uitgevoerd. Tijdens oktober, november geven gebruikers bijvoorbeeld vanwege feestelijkheden en cashback van bankpartners de voorkeur aan creditcards omdat ze 500 tot 5000 kortingen bieden. Als we deze periode voor de analyse in aanmerking nemen, zouden de resultaten duidelijk vertekend zijn.
Laten we voor deze analyse aannemen dat de pre-periode 21 januari tot 21 juni was en dat de covariabelen die werden gebruikt om het model te trainen, uit deze periode zijn afgeleid. De behandeling gebruikt debet-/creditcards tijdens de behandelingsperiode en is de afhankelijke variabele van het model. Laten we aannemen dat de behandelingsperiode de eerste week van juli was en de uitkomst na de periode de volgende 30 dagen.
Verkennende gegevensanalyse van deze dataset is bijgewerkt hier.
Gegevensvoorverwerking
- Lees de dataset en verwijder irrelevante functies. Kaart betaling is de afhankelijke variabele:
df_fintec = pd.read_csv("https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/07_cred/Analytics%20Assignment/data_for_churn_analysis.csv") cols_basic_model = ['aantal_kaarten', 'betalingen_geïnitieerd', 'betalingen_failed', ' payments_completed', 'payments_completed_amount_first_7days', 'reward_purchase_count_first_7days', 'coins_redeemed_first_7days', 'is_referral', 'visits_feature_1', 'visits_feature_2', 'given_permission_1', 'given_permission_2'] df_fintec_LR = df_fintec[cols_basic_model] df_fintec_LR["is_referral"] = df_fintec_LR[ "is_referral"].astype(int) df_fintec_LR.fillna(0, inplace = True) oh_cols = ["is_referral","given_permission_1","given_permission_2"] df_fintec_LR.drop(columns = oh_cols, inplace = True)
Druk op Uitvoeren om de uitvoer te zien
- Bereid treintest split- en schaalfuncties voor (catboost werkt ook zonder functiestandaardisatie):
df_fintec = df_fintec.rename(columns={'is_churned': 'card_payment'}) X_train, X_test, y_train, y_test = train_test_split(df_fintec_LR, df_fintec[["card_payment"]],random_state = 70, test_size=0.30) scaler = StandardScaler () scaler.fit(X_train) X_train_Scaled = scaler.transform(X_train) X_test_Scaled = scaler.transform(X_test) X, y =X_train_Scaled,y_train
Modellering
- Gebruik een eenvoudig model, aangezien we meer geïnteresseerd zijn in de propensityscore:
clf = CatBoostClassifier( iteraties=5, learning_rate=0.1, #loss_function='CrossEntropy' ) clf.fit(X_train, y_train, verbose=False) y_pred = clf.predict(X_test, predict_type='Probability') y_pred y_pred_df = pd. DataFrame(y_pred,kolommen = ["nul","één"]) y_pred_df.head() df_test = pd.concat([X_test.reset_index(drop=True), y_test.reset_index(drop=True)], as=1 ) df_test = pd.concat([df_test.reset_index(drop=True), y_pred_df[["one"]].reset_index(drop=True)], as=1) df_test['revenue'] = np.random.randint (0,50000, size=len(df_test)) display(df_test.head()) sns.histplot(data=df_test, x='one', hue='card_payment') # multiple="dodge" voor
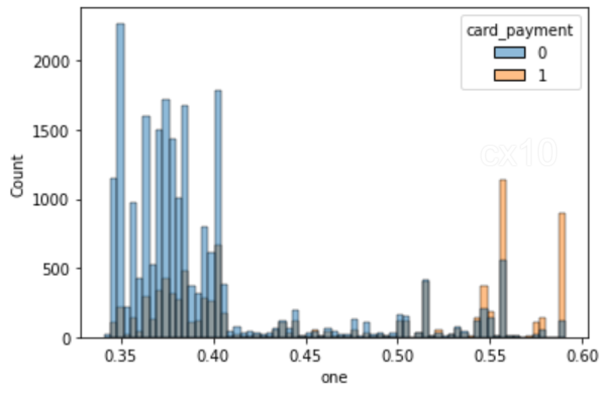
Zoals te zien is in het histogram, zijn er duidelijke overlappingsgebieden, dus vergelijkbare eenheden kunnen worden verkregen met behulp van PSM. Als er geen overall tussen zit, is het niet mogelijk om overeenkomsten te vinden.
Matchen met NearestNeighbors
- Matchen met NearestNeighbors.
from sklearn.neighbors import NearestNeighbors caliper = np.std(df_test.one) * 0.25 print(f'caliper (radius) is: {caliper:.4f}') n_neighbors = 10 # setup knn knn = NearestNeighbors(n_neighbors=n_neighbors, radius=caliper) ps = df_test[['one']] # dubbele haakjes als een dataframe knn.fit(ps)
# afstanden en indexen afstanden, Neighbor_indexes = knn.kneighbors(ps) print(neighbor_indexes.shape) # de 10 punten die het dichtst bij het eerste punt liggen print(distances[0]) print(neighbor_indexes[0])
# voor elk punt in behandeling vinden we een overeenkomend punt in controle zonder vervanging # merk op dat de 10 buren zowel punten in behandeling als controle kunnen bevatten matched_control = [] # houd de overeenkomende waarnemingen in controle bij voor current_index, rij in df_test.iterrows (): # herhaal het dataframe als row.card_payment == 0: # de huidige rij bevindt zich in de stuurgroep df_test.loc[current_index, 'matched'] = np.nan # set matched to nan else: for idx in Neighbor_indexes [current_index, :]: # zoek voor elke rij in behandeling de k buren # zorg ervoor dat de huidige rij niet de idx is - komt niet overeen met zichzelf # en de buur is in de controle if (current_index != idx) en (df_test.loc[idx].card_payment == 0): als idx niet in matched_control: # deze controle is nog niet gematcht df_test.loc[current_index, 'matched'] = idx # noteer de overeenkomende matched_control.append(idx) # voeg de overeenkomende toe aan de lijstonderbreking
# probeer het aantal buren en/of schuifmaat te vergroten om meer overeenkomsten te krijgen print('total observations in treatment:', len(df_test[df_test.card_payment==1])) print('total matched observations in control:', len(matched_control))
totaal aantal observaties in behandeling: 8988
totale gematchte waarnemingen in controle: 1296
# controle heeft geen match treatment_matched = df_test.dropna(subset=['matched']) # drop niet matched # matched controle observatie-indexen control_matched_idx = treatment_matched.matched control_matched_idx = control_matched_idx.astype(int) # verander naar int control_matched = df_test.loc [control_matched_idx, :] # selecteer gematchte controlewaarnemingen # combineer de gematchte behandeling en controle df_matched = pd.concat([treatment_matched, control_matched]) df_matched.card_payment.value_counts()
1 1296
0 1296
Naam: card_payment, dtype: int64
sns.histplot(data=df_matched, x='number_of_cards', hue='card_payment') sns.histplot(data=df_matched, x='payments_completed_amount_first_7days', hue='card_payment')
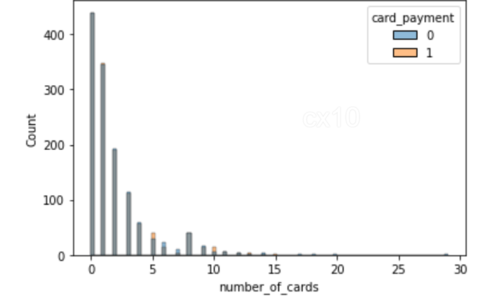
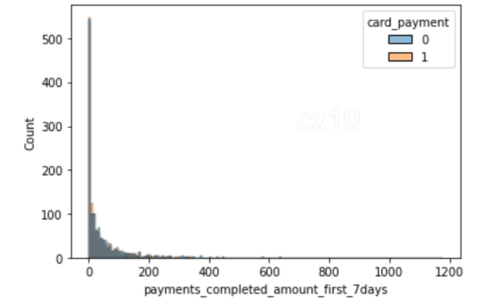
Uit de 2 histogrammen is het duidelijk dat na propensity-matching de verdeling van covariaten bijna hetzelfde is voor 2 kenmerken: het aantal voltooide kaarten en betalingen in de eerste zeven dagen. Hetzelfde kan ook worden geplot voor andere functies.
Voor en na
De verdeling van covariaten ervoor en erna zou significante verschillen in SD moeten vertonen; alleen dan kan worden geconcludeerd dat matching effectief is geweest.
from numpy import mean from numpy import var from math import sqrt # functie om Cohen's d te berekenen voor onafhankelijke steekproeven def cohen_d(d1, d2): # bereken de grootte van steekproeven n1, n2 = len(d1), len(d2) # bereken de variantie van de steekproeven s1, s2 = var(d1, ddof=1), var(d2, ddof=1) # bereken de gepoolde standaarddeviatie s = sqrt(((n1 - 1) * s1 + (n2 - 1) * s2) / (n1 + n2 - 2)) # bereken de gemiddelden van de steekproeven u1, u2 = mean(d1), mean(d2) # bereken de effectgrootte return (u1 - u2) / s
effect_sizes = [] cols = lijst(X_train.columns) # afzonderlijke controle en behandeling voor t-toets df_control = df_fintec[df_fintec.card_payment==0] df_treatment = df_fintec[df_fintec.card_payment==1] voor cl in cols: _, p_before = ttest_ind(df_control[cl], df_treatment[cl]) _, p_after = ttest_ind(df_matched_control[cl], df_matched_treatment[cl]) cohen_d_before = cohen_d(df_treatment[cl], df_control[cl]) cohen_d_after = cohen_d(df_matched_treatment[ cl], df_matched_control[cl]) effect_sizes.append([cl,'before', cohen_d_before, p_before]) effect_sizes.append([cl,'after', cohen_d_after, p_after])
df_effect_sizes = pd.DataFrame(effect_sizes, columns=['feature', 'matching', 'effect_size', 'p-value']) fig, ax = plt.subplots(figsize=(15, 5)) sns.barplot( data=df_effect_sizes, x='effect_size', y='feature', hue='matching', orient='h')
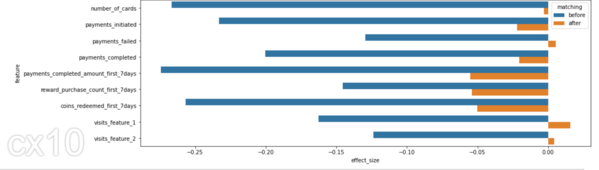
Cohen's D, of gestandaardiseerd gemiddeld verschil, is een van de meest gebruikelijke manieren om de effectgrootte te meten. Voor matching is het verschil in SD groter tussen de test en de controle (blauwe balken). Na matching is het SD-verschil kleiner, de test en controle hebben vergelijkbare verdelingen vóór de behandelingsperiode.
Statistische test om de impact van de behandeling te meten
Studenten T-toetsen om de gemiddelden van twee groepen te vergelijken. Als het retentie of verloop na de periode was, zou de Chi-Squared Test kunnen worden gebruikt.
# student's t-test voor omzet (afhankelijke variabele) na matchen # p-waarde is nu niet significant van scipy.stats import ttest_ind print(df_matched_control.revenue.mean(), df_matched_treatment.revenue.mean()) # vergelijk monsters _, p = ttest_ind(df_matched_control.revenue, df_matched_treatment.revenue) print(f'p={p:.3f}') # interpret alpha = 0.05 # significantieniveau als p > alpha: print('dezelfde distributies/hetzelfde groepsgemiddelde (kan niet verwerp H0 - we hebben niet genoeg bewijs om H0 te verwerpen)') else: print('verschillende distributies/ander groepsgemiddelde (verwerp H0)')
25105.91898148148 24040.162037037036
p = 0.062
dezelfde verdelingen/zelfde groepsgemiddelde (verwerpt H0 niet – we hebben niet genoeg bewijs om H0 te verwerpen)
Als P-waarde > 0.05, slagen we er niet in de nulhypothese te verwerpen, dus klanten die met kaarten betalen hebben hogere postinkomsten. Dit bespaart tijd en middelen die nodig zouden zijn geweest om deze nieuwe functie te bouwen.
Een andere manier om te matchen met NearestNeighbors
Naast PSM zijn er ook andere matchingmethoden. Een stukje code voor hetzelfde.
van sklearn.preprocessing import StandardScaler van sklearn.neighbors import NearestNeighbors def get_matching_pairs(treated_df, non_treated_df, scaler=True): behandeld_x = behandeld_df.values non_treated_x = niet_behandelde_df.waarden if scaler == True: scaler = StandardScaler() if scaler: scaler. fit(treated_x) prepared_x = scaler.transform(treated_x) non_treated_x = scaler.transform(non_treated_x) nbrs = NearestNeighbors(n_neighbors=1, algoritme='ball_tree').fit(non_treated_x) afstanden, indices = nbrs.kneighbors(treated_x) indices = indices.reshape(indices.shape[0]) komt overeen = non_treated_df.iloc[indices] komt overeen
importeer panda's als pd importeer numpy als np importeer matplotlib.pyplot als plt behandeld_df = pd.DataFrame() np.random.seed(1) size_1 = 200 size_2 = 1000 behandeld_df['x'] = np.random.normal(0,1, 1,maat=maat_50,20) behandeld_df['y'] = np.willekeurig.normaal(1,grootte=maat_0,100) behandeld_df['z'] = np.willekeurig.normaal(1,grootte=maat_0,3) niet_behandeld_df = pd. DataFrame() # twee verschillende populaties non_treated_df['x'] = lijst(np.random.normal(2,size=size_1,2)) + lijst(np.random.normal(-2,size=2*size_50,30 )) non_treated_df['y'] = lijst(np.random.normal(2,size=size_100,2)) + lijst(np.random.normal(-2,size=2*size_0,200)) non_treated_df[' z'] = lijst(np.random.normal(2,size=size_13,200)) + lijst(np.random.normal(2,size=2*size_6,6)) matched_df = get_matching_pairs(treated_df, non_treated_df) fig, ax = plt .subplots(figsize=(0.3)) plt.scatter(non_treated_df['x'], non_treated_df['y'], alpha=1,2, label='All non-treated') plt.scatter(treated_df['x '], treated_df['y'], label='Treated') plt.scatter(matched_df['x'], matched_df['y'], marker='x' , label='matched') plt.legend() plt.xlim(-XNUMX)
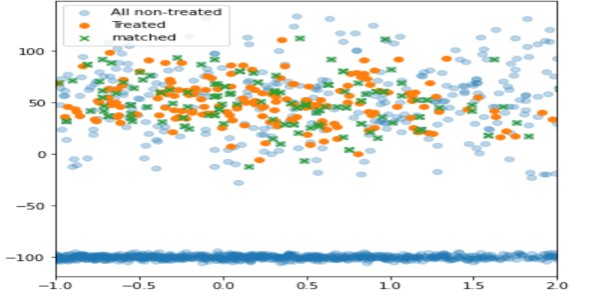
Door deze techniek te gebruiken, worden alleen niet-behandelde eenheden die dicht bij de behandelde liggen, gematcht (in groen), terwijl de rest is weggelaten (lichtblauw).
psmpy - Python Propensity Score Matching-bibliotheek
PSMPY vereenvoudigt PSM en reduceert het effectief tot slechts 10 regels code. Het bouwen, matchen en schalen van modellen wordt verzorgd door het framework. Een nadeel is dat het slecht schaalt voor meer dan 50 eenheden.
van psmpy import PsmPy van psmpy.plotting import * df_fintec.fillna(0, inplace = True) psm = PsmPy(df_fintec, treatment='card_payment', indx='user_id', exclude = ['is_referral', 'age', ' city', 'device']) # hetzelfde als mijn code met balance=False psm.logistic_ps(balance=False) psm.predicted_data psm.knn_matched(matcher='propensity_logit', replacement=False, caliper=None) psm.plot_match( Title='Overeenkomend resultaat', Ylabel='# obs', Xlabel= 'propensity logit', names = ['treatment', 'control']) display(psm.effect_size) psm.effect_size_plot()
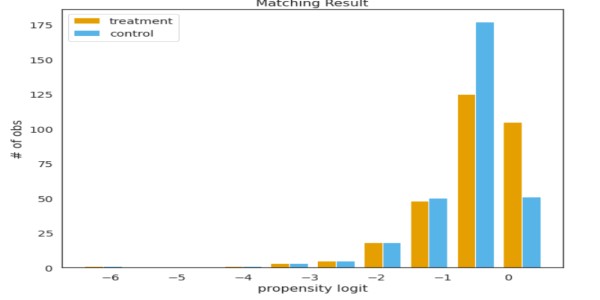
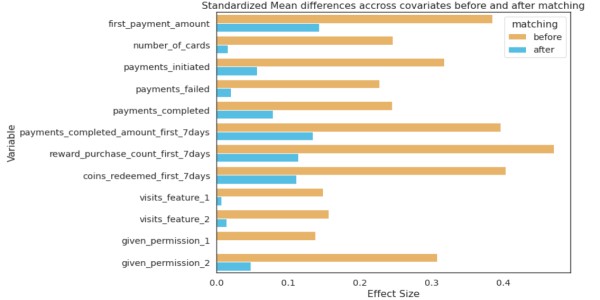
Nadelen van
De waarden van hun covariabelen zullen niet identiek zijn voor twee individuen met identieke propensityscores. PSM balanceert effectief de gemiddelde waarden van covariaten tussen cohorten. Kortom, als het gemiddelde van het aantal kaarten voor de test en controle hetzelfde is, maar als twee gebruikers worden gekozen met dezelfde neigingswaarden, zullen hun covariabelen verschillen.
Naarmate het aantal covariaten toeneemt, beïnvloedt de vloek van dimensionaliteit het matchen, waardoor de kansen tot bijna nul worden verkleind.
Conclusie
- Controle op inherente bias kan tot goede resultaten leiden.
- Kies geschikte pre-periode covariaten op basis van het probleem bij de hand.
- De hypothese moet worden ondersteund door zakelijk inzicht en gegevens.
Laat me de andere use-cases van PSM weten in de comments hieronder.
Succes! Hier is mijn Linkedin profiel als je met mij in contact wilt komen of wilt helpen het artikel te verbeteren. Bekijk ook mijn andere artikelen over datawetenschap en -analyse hier.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2022/12/introduction-to-synthetic-control-using-propensity-score-matching/

