Dit bericht is geschreven in samenwerking met Santosh Waddi en Nanda Kishore Thatikonda van BigBasket.
BigBasket is India's grootste online voedings- en supermarktwinkel. Ze zijn actief in meerdere e-commercekanalen, zoals snelle handel, bezorging met slots en dagelijkse abonnementen. Je kunt ook kopen in hun fysieke winkels en automaten. Ze bieden een groot assortiment van meer dan 50,000 producten, verdeeld over 1,000 merken, en zijn actief in meer dan 500 steden en dorpen. BigBasket bedient meer dan 10 miljoen klanten.
In dit bericht bespreken we hoe BigBasket gebruikte Amazon Sage Maker om hun computer vision-model te trainen voor productidentificatie van Fast-Moving Consumer Goods (FMCG), waardoor ze de trainingstijd met ongeveer 50% konden verkorten en de kosten met 20% konden besparen.
Uitdagingen van klanten
Tegenwoordig bieden de meeste supermarkten en fysieke winkels in India handmatig afrekenen aan de kassa. Dit heeft twee problemen:
- Het vereist extra mankracht, gewichtsstickers en herhaalde training voor het operationele team in de winkel terwijl ze opschalen.
- In de meeste winkels is de kassa anders dan de weegbalies, wat de wrijving tijdens het aankooptraject van de klant vergroot. Klanten verliezen vaak de gewichtssticker en moeten terug naar de weegbalies om er weer een op te halen voordat ze verder kunnen gaan met het afrekenproces.
Zelf afrekenproces
BigBasket introduceerde een door AI aangedreven kassasysteem in hun fysieke winkels dat camera's gebruikt om artikelen op een unieke manier te onderscheiden. De volgende afbeelding geeft een overzicht van het afrekenproces.
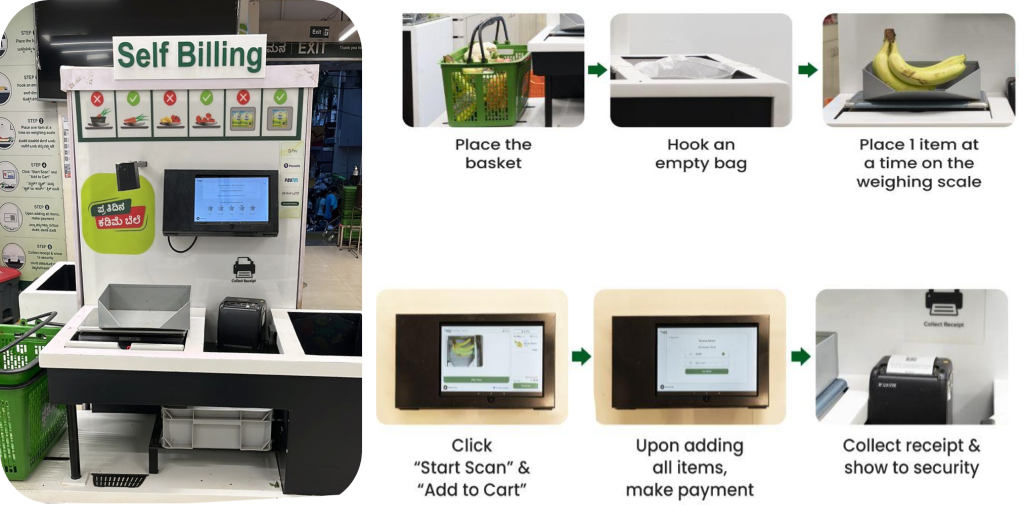
Het BigBasket-team maakte gebruik van open source, interne ML-algoritmen voor computer vision-objectherkenning om het afrekenen met AI mogelijk te maken bij hun klanten. Vers (fysieke) winkels. We werden geconfronteerd met de volgende uitdagingen bij het exploiteren van hun bestaande opstelling:
- Met de voortdurende introductie van nieuwe producten moest het computer vision-model voortdurend nieuwe productinformatie integreren. Het systeem moest een grote catalogus van meer dan 12,000 Stock Keeping Units (SKU's) verwerken, waarbij voortdurend nieuwe SKU's werden toegevoegd met een snelheid van meer dan 600 per maand.
- Om gelijke tred te houden met nieuwe producten, werd elke maand een nieuw model geproduceerd op basis van de nieuwste trainingsgegevens. Het was kostbaar en tijdrovend om de modellen regelmatig te trainen om ze aan nieuwe producten aan te passen.
- BigBasket wilde ook de trainingcyclustijd verkorten om de time-to-market te verbeteren. Door de toename van het aantal SKU's nam de tijd die het model in beslag nam lineair toe, wat van invloed was op de time-to-market omdat de trainingsfrequentie erg hoog was en lang duurde.
- Gegevensvergroting voor modeltraining en het handmatig beheren van de volledige end-to-end trainingscyclus zorgden voor aanzienlijke overhead. BigBasket draaide dit op een platform van derden, wat aanzienlijke kosten met zich meebracht.
Overzicht oplossingen
We hebben BigBasket aanbevolen om hun bestaande FMCG-productdetectie- en classificatieoplossing opnieuw te ontwerpen met behulp van SageMaker om deze uitdagingen aan te pakken. Voordat BigBasket overging op volledige productie, probeerde het een pilot uit met SageMaker om de prestatie-, kosten- en gemaksgegevens te evalueren.
Hun doel was om een bestaand Computer Vision Machine Learning (ML)-model voor SKU-detectie te verfijnen. We hebben gebruik gemaakt van een convolutioneel neuraal netwerk (CNN)-architectuur ResNet 152 voor beeldclassificatie. Voor modeltraining werd een aanzienlijke dataset van ongeveer 300 afbeeldingen per SKU geschat, wat resulteerde in in totaal meer dan 4 miljoen trainingsafbeeldingen. Voor bepaalde SKU's hebben we de gegevens uitgebreid om een breder scala aan omgevingsomstandigheden te omvatten.
Het volgende diagram illustreert de oplossingsarchitectuur.

Het volledige proces kan worden samengevat in de volgende stappen op hoog niveau:
- Voer gegevensopschoning, annotatie en augmentatie uit.
- Gegevens opslaan in een Amazon eenvoudige opslagservice (Amazon S3) emmer.
- Gebruik SageMaker en Amazon FSx voor Luster voor efficiënte gegevensvergroting.
- Splits gegevens op in trein-, validatie- en testsets. We gebruikten FSx voor Lustre en Amazon relationele databaseservice (Amazon RDS) voor snelle parallelle gegevenstoegang.
- Gebruik een gewoonte PyTorch Docker-container inclusief andere open source-bibliotheken.
- Te gebruiken SageMaker gedistribueerd dataparallellisme (SMDDP) voor versnelde gedistribueerde training.
- Gegevens over modeltraining registreren.
- Kopieer het definitieve model naar een S3-bucket.
BigBasket gebruikt SageMaker-notitieboekjes om hun ML-modellen te trainen en konden hun bestaande open source PyTorch en andere open source-afhankelijkheden eenvoudig overbrengen naar een SageMaker PyTorch-container en de pijplijn naadloos laten draaien. Dit was het eerste voordeel dat het BigBasket-team zag, omdat er nauwelijks wijzigingen in de code nodig waren om deze compatibel te maken voor gebruik in een SageMaker-omgeving.
Het modelnetwerk bestaat uit een ResNet 152-architectuur gevolgd door volledig verbonden lagen. We hebben de lagen op laag niveau bevroren en de gewichten behouden die zijn verkregen door het leren van overdrachten uit het ImageNet-model. Het totale aantal modelparameters bedroeg 66 miljoen, bestaande uit 23 miljoen trainbare parameters. Deze op transfer learning gebaseerde aanpak hielp hen minder beelden te gebruiken tijdens de training, maakte ook een snellere convergentie mogelijk en verkortte de totale trainingstijd.
Het interne model bouwen en trainen Amazon SageMaker Studio voorzag in een geïntegreerde ontwikkelomgeving (IDE) met alles wat nodig was om modellen voor te bereiden, te bouwen, te trainen en af te stemmen. Door de trainingsgegevens uit te breiden met behulp van technieken zoals het bijsnijden, roteren en omdraaien van afbeeldingen, zijn de modeltrainingsgegevens en de modelnauwkeurigheid verbeterd.
De modeltraining werd met 50% versneld door het gebruik van de SMDDP-bibliotheek, die geoptimaliseerde communicatie-algoritmen bevat die speciaal zijn ontworpen voor de AWS-infrastructuur. Om de lees-/schrijfprestaties van gegevens tijdens modeltraining en gegevensvergroting te verbeteren, hebben we FSx voor Lustre gebruikt voor krachtige doorvoer.
De gegevensgrootte bij aanvang van de training was meer dan 1.5 TB. Wij hebben er twee gebruikt Amazon Elastic Compute-cloud (Amazone EC2) p4d.24 grote exemplaren met 8 GPU en 40 GB GPU-geheugen. Voor gedistribueerde SageMaker-training moeten de instanties zich in dezelfde AWS-regio en beschikbaarheidszone bevinden. Ook moeten trainingsgegevens die zijn opgeslagen in een S3-bucket zich in dezelfde Beschikbaarheidszone bevinden. Dankzij deze architectuur kan BigBasket ook overstappen op andere instancetypen of meer instances toevoegen aan de huidige architectuur om tegemoet te komen aan eventuele significante datagroei of om een verdere verkorting van de trainingstijd te bereiken.
Hoe de SMDDP-bibliotheek de trainingstijd, -kosten en -complexiteit heeft helpen verminderen
Bij traditionele gedistribueerde datatraining wijst het trainingsframework rangen toe aan GPU's (werknemers) en wordt op elke GPU een replica van uw model gemaakt. Tijdens elke trainingsiteratie wordt de globale gegevensbatch in stukken verdeeld (batchscherven) en wordt er een stuk aan elke werker gedistribueerd. Elke werknemer gaat vervolgens verder met de voorwaartse en achterwaartse pass die in uw trainingsscript op elke GPU is gedefinieerd. Ten slotte worden modelgewichten en gradiënten van de verschillende modelreplica's aan het einde van de iteratie gesynchroniseerd via een collectieve communicatiebewerking genaamd AllReduce. Nadat elke werker en GPU een gesynchroniseerde replica van het model heeft, begint de volgende iteratie.
De SMDDP-bibliotheek is een collectieve communicatiebibliotheek die de prestaties van dit parallelle trainingsproces met gedistribueerde gegevens verbetert. De SMDDP-bibliotheek vermindert de communicatieoverhead van de belangrijkste collectieve communicatiebewerkingen zoals AllReduce. De implementatie van AllReduce is ontworpen voor de AWS-infrastructuur en kan de training versnellen door de AllReduce-operatie te overlappen met de achterwaartse pass. Deze aanpak bereikt een vrijwel lineaire schaalefficiëntie en een hogere trainingssnelheid door kernelbewerkingen tussen CPU's en GPU's te optimaliseren.
Let op de volgende berekeningen:
- De grootte van de globale batch is (aantal knooppunten in een cluster) * (aantal GPU's per knooppunt) * (per batch-shard)
- Een batch-shard (kleine batch) is een subset van de gegevensset die per iteratie aan elke GPU (werknemer) is toegewezen
BigBasket gebruikte de SMDDP-bibliotheek om hun totale trainingstijd te verkorten. Met FSx voor Lustre hebben we de lees-/schrijfsnelheid van gegevens tijdens modeltraining en gegevensvergroting verminderd. Dankzij data-parallellisme was BigBasket in staat om bijna 50% snellere en 20% goedkopere training te realiseren in vergelijking met andere alternatieven, waardoor de beste prestaties op AWS werden geleverd. SageMaker sluit de trainingspijplijn na voltooiing automatisch af. Het project werd succesvol afgerond met een 50% snellere trainingstijd in AWS (4.5 dagen in AWS versus 9 dagen op hun oude platform).
Op het moment dat dit bericht wordt geschreven, draait BigBasket de complete oplossing al meer dan zes maanden in productie en schaalt het systeem door zich te richten op nieuwe steden, en we voegen elke maand nieuwe winkels toe.
“Onze samenwerking met AWS op het gebied van de migratie naar gedistribueerde training met behulp van hun SMDDP-aanbod is een grote overwinning geweest. Het verkortte niet alleen onze trainingstijd met 50%, het was ook 20% goedkoper. In ons hele partnerschap heeft AWS de lat hoog gelegd op het gebied van klantobsessie en het leveren van resultaten. We hebben de hele weg met ons samengewerkt om de beloofde voordelen te realiseren.”
– Keshav Kumar, hoofd engineering bij BigBasket.
Conclusie
In dit bericht hebben we besproken hoe BigBasket SageMaker gebruikte om hun computer vision-model te trainen voor FMCG-productidentificatie. De implementatie van een door AI aangedreven geautomatiseerd self-checkout-systeem zorgt voor een verbeterde klantervaring in de detailhandel door innovatie, terwijl menselijke fouten in het afrekenproces worden geëlimineerd. Het versnellen van de onboarding van nieuwe producten door gebruik te maken van gedistribueerde training van SageMaker vermindert de onboardingtijd en -kosten van SKU's. De integratie van FSx voor Luster maakt snelle parallelle gegevenstoegang mogelijk voor een efficiënte modelhertraining met maandelijks honderden nieuwe SKU's. Over het geheel genomen biedt deze op AI gebaseerde self-checkout-oplossing een verbeterde winkelervaring zonder frontend-afrekenfouten. De automatisering en innovatie hebben hun kassa- en onboarding-activiteiten in de detailhandel getransformeerd.
SageMaker biedt end-to-end ML-ontwikkelings-, implementatie- en monitoringmogelijkheden, zoals een SageMaker Studio-notebookomgeving voor het schrijven van code, data-acquisitie, datatagging, modeltraining, modelafstemming, implementatie, monitoring en nog veel meer. Als uw bedrijf met een van de uitdagingen wordt geconfronteerd die in dit bericht worden beschreven en tijd wil besparen om op de markt te komen en de kosten wil verbeteren, neem dan contact op met het AWS-accountteam in uw regio en ga aan de slag met SageMaker.
Over de auteurs
 Santosh Waddi is een hoofdingenieur bij BigBasket en brengt meer dan tien jaar expertise mee in het oplossen van AI-uitdagingen. Met een sterke achtergrond in computer vision, data science en deep learning, heeft hij een postdoctorale graad behaald aan IIT Bombay. Santosh heeft opmerkelijke IEEE-publicaties geschreven en als doorgewinterde techblogauteur heeft hij tijdens zijn ambtsperiode bij Samsung ook belangrijke bijdragen geleverd aan de ontwikkeling van computer vision-oplossingen.
Santosh Waddi is een hoofdingenieur bij BigBasket en brengt meer dan tien jaar expertise mee in het oplossen van AI-uitdagingen. Met een sterke achtergrond in computer vision, data science en deep learning, heeft hij een postdoctorale graad behaald aan IIT Bombay. Santosh heeft opmerkelijke IEEE-publicaties geschreven en als doorgewinterde techblogauteur heeft hij tijdens zijn ambtsperiode bij Samsung ook belangrijke bijdragen geleverd aan de ontwikkeling van computer vision-oplossingen.
 Nanda Kishore Thatikonda is een Engineering Manager die leiding geeft aan Data Engineering en Analytics bij BigBasket. Nanda heeft meerdere applicaties gebouwd voor de detectie van afwijkingen en heeft een patent aangevraagd in een vergelijkbare ruimte. Hij heeft gewerkt aan het bouwen van bedrijfsapplicaties, het bouwen van dataplatforms in meerdere organisaties en rapportageplatforms om beslissingen op basis van data te stroomlijnen. Nanda heeft meer dan 18 jaar ervaring met het werken in Java/J2EE, Spring-technologieën en big data-frameworks met behulp van Hadoop en Apache Spark.
Nanda Kishore Thatikonda is een Engineering Manager die leiding geeft aan Data Engineering en Analytics bij BigBasket. Nanda heeft meerdere applicaties gebouwd voor de detectie van afwijkingen en heeft een patent aangevraagd in een vergelijkbare ruimte. Hij heeft gewerkt aan het bouwen van bedrijfsapplicaties, het bouwen van dataplatforms in meerdere organisaties en rapportageplatforms om beslissingen op basis van data te stroomlijnen. Nanda heeft meer dan 18 jaar ervaring met het werken in Java/J2EE, Spring-technologieën en big data-frameworks met behulp van Hadoop en Apache Spark.
 Sudhanshu-haat is een Principal AI & ML Specialist bij AWS en werkt samen met klanten om hen te adviseren over hun MLOps en generatieve AI-reis. In zijn vorige rol heeft hij teams geconceptualiseerd, gecreëerd en geleid om een volledig op open source gebaseerd AI- en gamificatieplatform te bouwen, en dit met succes op de markt gebracht bij meer dan 100 klanten. Sudhanshu heeft een aantal patenten op zijn naam staan; heeft twee boeken, verschillende artikelen en blogs geschreven; en heeft zijn standpunt op verschillende fora gepresenteerd. Hij is een thought leader en spreker en is al bijna 2 jaar actief in de branche. Hij heeft met Fortune 25-klanten over de hele wereld gewerkt en meest recentelijk met digital native-klanten in India.
Sudhanshu-haat is een Principal AI & ML Specialist bij AWS en werkt samen met klanten om hen te adviseren over hun MLOps en generatieve AI-reis. In zijn vorige rol heeft hij teams geconceptualiseerd, gecreëerd en geleid om een volledig op open source gebaseerd AI- en gamificatieplatform te bouwen, en dit met succes op de markt gebracht bij meer dan 100 klanten. Sudhanshu heeft een aantal patenten op zijn naam staan; heeft twee boeken, verschillende artikelen en blogs geschreven; en heeft zijn standpunt op verschillende fora gepresenteerd. Hij is een thought leader en spreker en is al bijna 2 jaar actief in de branche. Hij heeft met Fortune 25-klanten over de hele wereld gewerkt en meest recentelijk met digital native-klanten in India.
 Ayush Kumar is oplossingsarchitect bij AWS. Hij werkt met een grote verscheidenheid aan AWS-klanten en helpt hen de nieuwste moderne applicaties te adopteren en sneller te innoveren met cloud-native technologieën. In zijn vrije tijd zie je hem experimenteren in de keuken.
Ayush Kumar is oplossingsarchitect bij AWS. Hij werkt met een grote verscheidenheid aan AWS-klanten en helpt hen de nieuwste moderne applicaties te adopteren en sneller te innoveren met cloud-native technologieën. In zijn vrije tijd zie je hem experimenteren in de keuken.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/how-bigbasket-improved-ai-enabled-checkout-at-their-physical-stores-using-amazon-sagemaker/

