Foundation-modellen (FM's) zijn grote machine learning-modellen (ML) die zijn getraind op een breed spectrum van ongelabelde en gegeneraliseerde datasets. FM's vormen, zoals de naam al doet vermoeden, de basis voor het bouwen van meer gespecialiseerde downstream-applicaties en zijn uniek in hun aanpassingsvermogen. Ze kunnen een breed scala aan verschillende taken uitvoeren, zoals natuurlijke taalverwerking, het classificeren van afbeeldingen, het voorspellen van trends, het analyseren van sentiment en het beantwoorden van vragen. Deze schaal en het algemene aanpassingsvermogen maken FM's anders dan traditionele ML-modellen. FM's zijn multimodaal; ze werken met verschillende gegevenstypen, zoals tekst, video, audio en afbeeldingen. Grote taalmodellen (LLM's) zijn een soort FM en zijn vooraf getraind in grote hoeveelheden tekstgegevens en hebben doorgaans toepassingsmogelijkheden zoals het genereren van tekst, intelligente chatbots of samenvattingen.
Het streamen van gegevens vergemakkelijkt de constante stroom van diverse en actuele informatie, waardoor het vermogen van de modellen om zich aan te passen en nauwkeurigere, contextueel relevante resultaten te genereren wordt vergroot. Deze dynamische integratie van streaminggegevens maakt dit mogelijk generatieve AI applicaties om snel te reageren op veranderende omstandigheden, waardoor hun aanpassingsvermogen en algehele prestaties bij verschillende taken worden verbeterd.
Om dit beter te begrijpen, kunt u zich een chatbot voorstellen die reizigers helpt bij het boeken van hun reizen. In dit scenario heeft de chatbot realtime toegang nodig tot de inventaris van luchtvaartmaatschappijen, de vluchtstatus, de hotelinventaris, de laatste prijswijzigingen en meer. Deze gegevens zijn meestal afkomstig van derden en ontwikkelaars moeten een manier vinden om deze gegevens op te nemen en de gegevenswijzigingen te verwerken zodra ze zich voordoen.
Batchverwerking past niet het beste in dit scenario. Wanneer gegevens snel veranderen, kan het batchgewijs verwerken ervan ertoe leiden dat verouderde gegevens door de chatbot worden gebruikt, waardoor de klant onnauwkeurige informatie krijgt, wat van invloed is op de algehele klantervaring. Streamverwerking kan de chatbot echter in staat stellen toegang te krijgen tot realtime gegevens en zich aan te passen aan veranderingen in beschikbaarheid en prijs, waardoor de klant de beste begeleiding wordt geboden en de klantervaring wordt verbeterd.
Een ander voorbeeld is een AI-gestuurde observatie- en monitoringoplossing waarbij FM's realtime interne statistieken van een systeem monitoren en waarschuwingen produceren. Wanneer het model een afwijking of abnormale metrische waarde vindt, moet het onmiddellijk een waarschuwing genereren en de operator op de hoogte stellen. De waarde van dergelijke belangrijke gegevens neemt echter in de loop van de tijd aanzienlijk af. Deze meldingen zouden idealiter binnen enkele seconden of zelfs terwijl het gebeurt, moeten worden ontvangen. Als operators deze meldingen minuten of uren nadat ze hebben plaatsgevonden ontvangen, is een dergelijk inzicht niet bruikbaar en heeft het mogelijk zijn waarde verloren. Soortgelijke gebruiksscenario's vindt u in andere sectoren, zoals de detailhandel, autoproductie, energie en de financiële sector.
In dit bericht bespreken we waarom datastreaming een cruciaal onderdeel is van generatieve AI-toepassingen vanwege het realtime karakter ervan. We bespreken de waarde van AWS-datastreamingdiensten zoals Amazon Managed Streaming voor Apache Kafka (Amazone MSK), Amazon Kinesis-gegevensstromen, Amazon Managed Service voor Apache Flink en Amazon Kinesis-gegevens Firehose bij het bouwen van generatieve AI-toepassingen.
In-context leren
LLM's zijn getraind met point-in-time-gegevens en hebben geen inherent vermogen om toegang te krijgen tot nieuwe gegevens op het moment van inferentie. Naarmate er nieuwe data verschijnen, zul je het model voortdurend moeten verfijnen of verder trainen. Dit is niet alleen een dure operatie, maar in de praktijk ook zeer beperkend omdat de snelheid waarmee nieuwe gegevens worden gegenereerd de snelheid van de fijnafstelling ruimschoots overstijgt. Bovendien missen LLM's contextueel begrip en vertrouwen ze uitsluitend op hun trainingsgegevens, en zijn daarom vatbaar voor hallucinaties. Dit betekent dat ze een vloeiend, coherent en syntactisch verantwoord maar feitelijk onjuist antwoord kunnen genereren. Ze zijn ook verstoken van relevantie, personalisatie en context.
LLM's hebben echter het vermogen om te leren van de gegevens die zij uit de context ontvangen, zodat ze nauwkeuriger kunnen reageren zonder de modelgewichten te wijzigen. Dit heet contextueel leren, en kan worden gebruikt om gepersonaliseerde antwoorden te geven of een accuraat antwoord te geven in de context van het organisatiebeleid.
In een chatbot kunnen gegevensgebeurtenissen bijvoorbeeld betrekking hebben op een inventaris van vluchten en hotels of prijswijzigingen die voortdurend worden opgenomen in een streaming-opslagengine. Bovendien worden gegevensgebeurtenissen gefilterd, verrijkt en getransformeerd naar een verbruiksformaat met behulp van een streamprocessor. Het resultaat wordt beschikbaar gesteld aan de applicatie door de laatste momentopname op te vragen. De momentopname wordt voortdurend bijgewerkt via streamverwerking; daarom worden de actuele gegevens verstrekt in de context van een gebruikersprompt voor het model. Hierdoor kan het model zich aanpassen aan de laatste veranderingen in prijs en beschikbaarheid. Het volgende diagram illustreert een basisworkflow voor in-context leren.
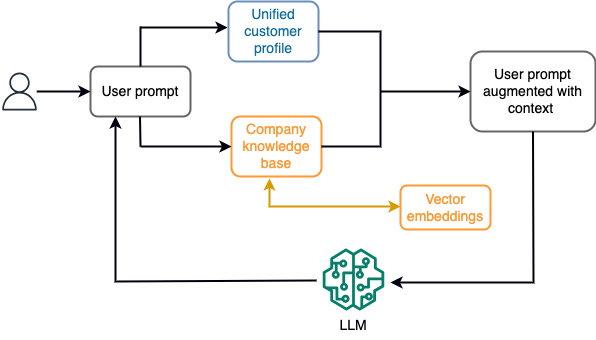
Een veelgebruikte benadering van in-context leren is het gebruik van een techniek genaamd Retrieval Augmented Generation (RAG). In RAG verstrekt u de relevante informatie, zoals de meest relevante polis- en klantgegevens, samen met de gebruikersvraag aan de prompt. Op deze manier genereert de LLM een antwoord op de gebruikersvraag met behulp van aanvullende informatie die als context wordt verstrekt. Voor meer informatie over RAG, zie Vraag beantwoorden met behulp van Retrieval Augmented Generation met basismodellen in Amazon SageMaker JumpStart.
Een op RAG gebaseerde generatieve AI-toepassing kan alleen generieke antwoorden produceren op basis van de trainingsgegevens en de relevante documenten in de kennisbank. Deze oplossing schiet tekort wanneer er van de applicatie een bijna realtime gepersonaliseerde reactie wordt verwacht. Van een reischatbot wordt bijvoorbeeld verwacht dat hij rekening houdt met de huidige boekingen van de gebruiker, de beschikbare hotel- en vluchtinventaris, en meer. Bovendien kunnen de relevante persoonsgegevens van klanten (algemeen bekend als de uniform klantprofiel) is doorgaans aan verandering onderhevig. Als een batchproces wordt gebruikt om de database met gebruikersprofielen van de generatieve AI bij te werken, kan de klant ontevreden reacties ontvangen op basis van oude gegevens.
In dit bericht bespreken we de toepassing van stroomverwerking om een RAG-oplossing te verbeteren die wordt gebruikt voor het bouwen van vraagbeantwoorders met context van realtime toegang tot uniforme klantprofielen en organisatorische kennisbank.
Bijna realtime klantprofielupdates
Klantrecords worden doorgaans verspreid over datastores binnen een organisatie. Om ervoor te zorgen dat uw generatieve AI-toepassing een relevant, accuraat en actueel klantprofiel biedt, is het essentieel om streamingdatapijplijnen te bouwen die identiteitsresolutie en profielaggregatie kunnen uitvoeren in de gedistribueerde datastores. Streamingtaken nemen voortdurend nieuwe gegevens op om deze tussen systemen te synchroniseren en kunnen verrijking, transformaties, samenvoegingen en aggregaties in verschillende tijdsperioden efficiënter uitvoeren. Gebeurtenissen voor het vastleggen van wijzigingsgegevens (CDC) bevatten informatie over de bronrecord, updates en metagegevens, zoals tijd, bron, classificatie (invoegen, bijwerken of verwijderen) en de initiator van de wijziging.
Het volgende diagram illustreert een voorbeeldworkflow voor opname en verwerking van CDC-streaming voor uniforme klantprofielen.

In deze sectie bespreken we de belangrijkste componenten van een CDC-streamingpatroon dat nodig is om op RAG gebaseerde generatieve AI-applicaties te ondersteunen.
CDC-streamingopname
Een CDC-replicator is een proces dat gegevenswijzigingen van een bronsysteem verzamelt (meestal door transactielogboeken of binlogs te lezen) en CDC-gebeurtenissen schrijft in exact dezelfde volgorde waarin ze plaatsvonden in een streaminggegevensstroom of onderwerp. Het gaat hierbij om een log-gebaseerde vastlegging met tools zoals AWS-databasemigratieservice (AWS DMS) of open source-connectoren zoals Debezium voor Apache Kafka connect. Apache Kafka Connect maakt deel uit van de Apache Kafka-omgeving, waardoor gegevens uit verschillende bronnen kunnen worden opgenomen en op verschillende bestemmingen kunnen worden afgeleverd. U kunt uw Apache Kafka-connector uitvoeren Amazon MSK Connect binnen enkele minuten zonder dat u zich zorgen hoeft te maken over de configuratie, installatie en bediening van een Apache Kafka-cluster. U hoeft alleen de gecompileerde code van uw connector te uploaden naar Amazon eenvoudige opslagservice (Amazon S3) en stel uw connector in met de specifieke configuratie van uw werkbelasting.
Er zijn ook andere methoden voor het vastleggen van gegevenswijzigingen. Bijvoorbeeld, Amazon DynamoDB biedt een functie voor het streamen van CDC-gegevens naar Amazon DynamoDB-streams of Kinesis-gegevensstromen. Amazon S3 biedt een trigger om een AWS Lambda functie wanneer een nieuw document wordt opgeslagen.
Streaming-opslag
Streamingopslag fungeert als tussenbuffer om CDC-gebeurtenissen op te slaan voordat ze worden verwerkt. Streamingopslag biedt betrouwbare opslag voor streaminggegevens. Door het ontwerp is het in hoge mate beschikbaar en bestand tegen hardware- of knooppuntstoringen en wordt de volgorde van de gebeurtenissen gehandhaafd zoals ze worden geschreven. Streamingopslag kan gegevensgebeurtenissen permanent of voor een bepaalde periode opslaan. Hierdoor kunnen streamprocessors uit een deel van de stream lezen als er een storing is of herverwerking nodig is. Kinesis Data Streams is een serverloze streaming-dataservice waarmee u eenvoudig datastromen op schaal kunt vastleggen, verwerken en opslaan. Amazon MSK is een volledig beheerde, zeer beschikbare en veilige service die wordt aangeboden door AWS voor het uitvoeren van Apache Kafka.
Streamverwerking
Streamverwerkingssystemen moeten worden ontworpen met het oog op parallellisme om een hoge gegevensdoorvoer te kunnen verwerken. Ze moeten de invoerstroom verdelen over meerdere taken die op meerdere rekenknooppunten worden uitgevoerd. Taken moeten het resultaat van de ene bewerking via het netwerk naar de volgende kunnen sturen, waardoor het mogelijk wordt gegevens parallel te verwerken terwijl bewerkingen zoals joins, filtering, verrijking en aggregaties worden uitgevoerd. Streamverwerkingstoepassingen moeten in staat zijn gebeurtenissen te verwerken met betrekking tot de gebeurtenistijd voor gebruiksscenario's waarbij gebeurtenissen te laat kunnen arriveren of de juiste berekening afhankelijk is van het tijdstip waarop gebeurtenissen plaatsvinden in plaats van van de systeemtijd. Voor meer informatie, zie Noties van tijd: gebeurtenistijd en verwerkingstijd.
Stroomprocessen produceren voortdurend resultaten in de vorm van gegevensgebeurtenissen die naar een doelsysteem moeten worden uitgevoerd. Een doelsysteem kan elk systeem zijn dat rechtstreeks met het proces kan worden geïntegreerd of via streaming-opslag als tussenproduct. Afhankelijk van het raamwerk dat u kiest voor streamverwerking, heeft u verschillende opties voor doelsystemen, afhankelijk van de beschikbare sink-connectoren. Als u besluit de resultaten naar een tussenliggende streaming-opslag te schrijven, kunt u een afzonderlijk proces bouwen dat gebeurtenissen leest en wijzigingen op het doelsysteem toepast, zoals het uitvoeren van een Apache Kafka-sink-connector. Welke optie u ook kiest, CDC-gegevens hebben vanwege hun aard extra verwerking nodig. Omdat CDC-gebeurtenissen informatie over updates of verwijderingen bevatten, is het belangrijk dat ze in de juiste volgorde in het doelsysteem worden samengevoegd. Als wijzigingen in de verkeerde volgorde worden toegepast, loopt het doelsysteem niet meer synchroon met de bron.
Apache Flink is een krachtig raamwerk voor streamverwerking dat bekend staat om zijn lage latentie en hoge doorvoermogelijkheden. Het ondersteunt de tijdverwerking van gebeurtenissen, de semantiek van de verwerking van precies één keer en een hoge fouttolerantie. Bovendien biedt het native ondersteuning voor CDC-gegevens via een speciale structuur genaamd dynamische tabellen. Dynamische tabellen bootsen de brondatabasetabellen na en bieden een kolomvormige weergave van de streaminggegevens. De gegevens in dynamische tabellen veranderen bij elke gebeurtenis die wordt verwerkt. Nieuwe records kunnen op elk moment worden toegevoegd, bijgewerkt of verwijderd. Dynamische tabellen nemen de extra logica weg die u voor elke recordbewerking (invoegen, bijwerken, verwijderen) afzonderlijk moet implementeren. Voor meer informatie, zie Dynamische tabellen.
met Amazon Managed Service voor Apache Flink, kunt u Apache Flink-taken uitvoeren en integreren met andere AWS-services. Er hoeven geen servers en clusters te worden beheerd, en er hoeft geen reken- en opslaginfrastructuur te worden opgezet.
AWS lijm is een volledig beheerde extractie-, transformatie- en laadservice (ETL), wat betekent dat AWS de levering, schaalvergroting en het onderhoud van de infrastructuur voor u afhandelt. Hoewel het vooral bekend staat om zijn ETL-mogelijkheden, kan AWS Glue ook worden gebruikt voor Spark-streamingtoepassingen. AWS Glue kan communiceren met streaming datadiensten zoals Kinesis Data Streams en Amazon MSK voor het verwerken en transformeren van CDC-gegevens. AWS Glue kan ook naadloos integreren met andere AWS-diensten zoals Lambda, AWS Stap Functiesen DynamoDB, waarmee u een uitgebreid ecosysteem krijgt voor het bouwen en beheren van pijplijnen voor gegevensverwerking.
Uniform klantprofiel
Het overwinnen van de unificatie van het klantprofiel over verschillende bronsystemen vereist de ontwikkeling van robuuste datapijplijnen. U hebt gegevenspijplijnen nodig die alle records in één gegevensarchief kunnen samenbrengen en synchroniseren. Deze dataopslag biedt uw organisatie het holistische overzicht van klantgegevens dat nodig is voor de operationele efficiëntie van op RAG gebaseerde generatieve AI-toepassingen. Voor het bouwen van een dergelijke dataopslag zou een ongestructureerde dataopslag het beste zijn.
Een identiteitsgrafiek is een nuttige structuur voor het creëren van een uniform klantprofiel, omdat het klantgegevens uit verschillende bronnen consolideert en integreert, de nauwkeurigheid en deduplicatie van gegevens garandeert, realtime updates biedt, inzichten uit meerdere systemen met elkaar verbindt, personalisatie mogelijk maakt, de klantervaring verbetert en ondersteunt naleving van de regelgeving. Dit uniforme klantprofiel stelt de generatieve AI-toepassing in staat om klanten effectief te begrijpen en ermee om te gaan, en zich te houden aan de regelgeving inzake gegevensprivacy, waardoor uiteindelijk de klantervaringen worden verbeterd en de bedrijfsgroei wordt gestimuleerd. U kunt uw identiteitsgrafiekoplossing bouwen met behulp van Amazone Neptunus, een snelle, betrouwbare, volledig beheerde grafiekdatabaseservice.
AWS biedt een aantal andere beheerde en serverloze NoSQL-opslagservices voor ongestructureerde sleutelwaardeobjecten. Amazon DocumentDB (met MongoDB-compatibiliteit) is een snelle, schaalbare, zeer beschikbare en volledig beheerde onderneming documentendatabase service die native JSON-workloads ondersteunt. DynamoDB is een volledig beheerde NoSQL-databaseservice die snelle en voorspelbare prestaties biedt met naadloze schaalbaarheid.
Bijna realtime updates van de kennisbank van de organisatie
Net als bij klantgegevens worden interne kennisopslagplaatsen, zoals bedrijfsbeleid en organisatiedocumenten, verspreid over opslagsystemen verspreid. Dit zijn doorgaans ongestructureerde gegevens en worden op niet-incrementele wijze bijgewerkt. Het gebruik van ongestructureerde gegevens voor AI-toepassingen is effectief bij het gebruik van vectorinbedding, een techniek om hoogdimensionale gegevens zoals tekstbestanden, afbeeldingen en audiobestanden als multidimensionaal numeriek weer te geven.
AWS biedt er verschillende vectormotordiensten, zoals Amazon OpenSearch Serverloos, Amazon Kendra en Amazon Aurora PostgreSQL-compatibele editie met de pgvector-extensie voor het opslaan van vectorinbedding. Generatieve AI-toepassingen kunnen de gebruikerservaring verbeteren door de gebruikersprompt in een vector te transformeren en deze te gebruiken om de vectorengine te bevragen om contextueel relevante informatie op te halen. Zowel de prompt als de opgehaalde vectorgegevens worden vervolgens doorgegeven aan de LLM om een nauwkeuriger en persoonlijker antwoord te ontvangen.
Het volgende diagram illustreert een voorbeeld van een stroomverwerkingsworkflow voor vectorinbedding.
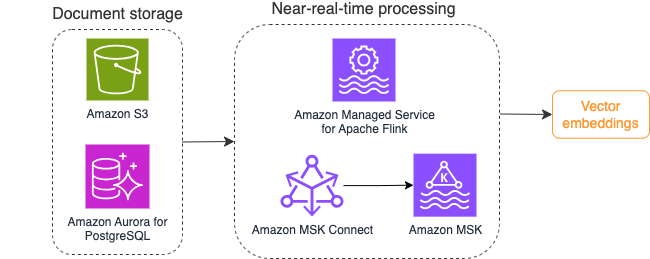
De inhoud van de kennisbank moet worden geconverteerd naar vectorinbedding voordat deze naar de vectorgegevensopslag wordt geschreven. Amazonebodem or Amazon Sage Maker kan u helpen toegang te krijgen tot het model van uw keuze en een privé-eindpunt voor deze conversie beschikbaar te maken. Bovendien kunt u bibliotheken zoals LangChain gebruiken om met deze eindpunten te integreren. Door een batchproces te bouwen, kunt u de inhoud van uw kennisbank omzetten naar vectorgegevens en deze in eerste instantie opslaan in een vectordatabase. U moet echter vertrouwen op een interval om de documenten opnieuw te verwerken om uw vectordatabase te synchroniseren met wijzigingen in de inhoud van uw kennisbank. Bij een groot aantal documenten kan dit proces inefficiënt zijn. Tussen deze intervallen zullen de gebruikers van uw generatieve AI-applicatie antwoorden ontvangen volgens de oude inhoud, of een onnauwkeurig antwoord ontvangen omdat de nieuwe inhoud nog niet is gevectoriseerd.
Streamverwerking is een ideale oplossing voor deze uitdagingen. Het produceert in eerste instantie gebeurtenissen op basis van bestaande documenten, bewaakt verder het bronsysteem en creëert een documentwijzigingsgebeurtenis zodra deze zich voordoen. Deze gebeurtenissen kunnen worden opgeslagen in streaming-opslag en wachten om te worden verwerkt door een streaming-taak. Een streamingtaak leest deze gebeurtenissen, laadt de inhoud van het document en transformeert de inhoud naar een reeks gerelateerde tokens van woorden. Elk token wordt verder omgezet in vectorgegevens via een API-aanroep naar een insluitende FM. Resultaten worden via een sink-operator voor opslag naar de vectoropslag verzonden.
Als u Amazon S3 gebruikt voor het opslaan van uw documenten, kunt u een gebeurtenisbronarchitectuur bouwen op basis van S3-objectwijzigingstriggers voor Lambda. Een Lambda-functie kan een evenement in het gewenste formaat aanmaken en dat naar uw streamingopslag schrijven.
U kunt Apache Flink ook gebruiken om als streamingtaak uit te voeren. Apache Flink biedt de native FileSystem-bronconnector, die bestaande bestanden kan ontdekken en in eerste instantie hun inhoud kan lezen. Daarna kan het uw bestandssysteem voortdurend controleren op nieuwe bestanden en de inhoud ervan vastleggen. De connector ondersteunt het lezen van een reeks bestanden van gedistribueerde bestandssystemen zoals Amazon S3 of HDFS met een indeling van platte tekst, Avro, CSV, Parquet en meer, en produceert een streamingrecord. Als volledig beheerde service elimineert Managed Service voor Apache Flink de operationele overhead van het implementeren en onderhouden van Flink-taken, zodat u zich kunt concentreren op het bouwen en schalen van uw streamingapplicaties. Met naadloze integratie in de AWS-streamingdiensten zoals Amazon MSK of Kinesis Data Streams, biedt het functies zoals automatische schaling, beveiliging en veerkracht, waardoor betrouwbare en efficiënte Flink-applicaties worden geboden voor het verwerken van realtime streaminggegevens.
Op basis van uw DevOps-voorkeur kunt u kiezen tussen Kinesis Data Streams of Amazon MSK voor het opslaan van de streamingrecords. Kinesis Data Streams vereenvoudigt de complexiteit van het bouwen en beheren van aangepaste streaming data-applicaties, waardoor u zich kunt concentreren op het afleiden van inzichten uit uw data in plaats van op het onderhoud van de infrastructuur. Klanten die Apache Kafka gebruiken kiezen vaak voor Amazon MSK vanwege de eenvoud, schaalbaarheid en betrouwbaarheid bij het toezicht op Apache Kafka-clusters binnen de AWS-omgeving. Als volledig beheerde service neemt Amazon MSK de operationele complexiteiten over die gepaard gaan met het inzetten en onderhouden van Apache Kafka-clusters, zodat u zich kunt concentreren op het bouwen en uitbreiden van uw streaming-applicaties.
Omdat een RESTful API-integratie past bij de aard van dit proces, hebt u een raamwerk nodig dat een stateful verrijkingspatroon ondersteunt via RESTful API-aanroepen om fouten op te sporen en opnieuw te proberen voor de mislukte aanvraag. Apache Flink is opnieuw een raamwerk dat stateful bewerkingen kan uitvoeren met geheugensnelheid. Om de beste manieren te begrijpen om API-aanroepen te doen via Apache Flink, raadpleegt u Veelgebruikte verrijkingspatronen voor streaminggegevens in Amazon Kinesis Data Analytics voor Apache Flink.
Apache Flink biedt native sink-connectors voor het schrijven van gegevens naar vectordatastores zoals Amazon Aurora voor PostgreSQL met pgvector of Amazon OpenSearch-service met VectorDB. Als alternatief kunt u de uitvoer van de Flink-taak (gevectoriseerde gegevens) in een MSK-onderwerp of een Kinesis-gegevensstroom plaatsen. OpenSearch Service biedt ondersteuning voor native opname van Kinesis-datastreams of MSK-onderwerpen. Voor meer informatie, zie Introductie van Amazon MSK als bron voor Amazon OpenSearch Ingestion en Streaminggegevens laden van Amazon Kinesis Data Streams.
Feedbackanalyse en verfijning
Het is belangrijk voor data-operation managers en AI/ML-ontwikkelaars om inzicht te krijgen in de prestaties van de generatieve AI-applicatie en de FM's die in gebruik zijn. Om dat te bereiken moet u datapijplijnen bouwen die belangrijke Key Performance Indicator (KPI)-gegevens berekenen op basis van de gebruikersfeedback en de verscheidenheid aan applicatielogboeken en -statistieken. Deze informatie is nuttig voor belanghebbenden om realtime inzicht te krijgen in de prestaties van de FM, de applicatie en de algehele gebruikerstevredenheid over de kwaliteit van de ondersteuning die zij van uw applicatie ontvangen. U moet ook de gespreksgeschiedenis verzamelen en opslaan om uw FM's verder af te stemmen en hun vermogen bij het uitvoeren van domeinspecifieke taken te verbeteren.
Deze use case past heel goed in het domein van streaming analytics. Uw toepassing moet elk gesprek opslaan in streamingopslag. Uw toepassing kan gebruikers vragen naar hun beoordeling van de nauwkeurigheid van elk antwoord en hun algemene tevredenheid. Deze gegevens kunnen een binaire indeling hebben of een vrije tekstvorm. Deze gegevens kunnen worden opgeslagen in een Kinesis-datastroom of MSK-onderwerp en worden verwerkt om in realtime KPI's te genereren. U kunt FM's inzetten voor de sentimentanalyse van gebruikers. FM's kunnen elk antwoord analyseren en een categorie van gebruikerstevredenheid toekennen.
De architectuur van Apache Flink maakt complexe gegevensaggregatie over tijdsperioden mogelijk. Het biedt ook ondersteuning voor SQL-query's via stroom van gegevensgebeurtenissen. Door Apache Flink te gebruiken, kunt u daarom snel ruwe gebruikersinvoer analyseren en in realtime KPI's genereren door bekende SQL-query's te schrijven. Voor meer informatie, zie Tabel-API & SQL.
met Amazon Managed Service voor Apache Flink Studio, kunt u Apache Flink-streamverwerkingstoepassingen bouwen en uitvoeren met behulp van standaard SQL, Python en Scala in een interactief notitieblok. Studio-notebooks worden mogelijk gemaakt door Apache Zeppelin en gebruiken Apache Flink als de streamverwerkingsengine. Studio-notebooks combineren deze technologieën naadloos om geavanceerde analyses van datastromen toegankelijk te maken voor ontwikkelaars van alle vaardigheden. Met ondersteuning voor door de gebruiker gedefinieerde functies (UDF's) maakt Apache Flink het mogelijk om aangepaste operators te bouwen die kunnen worden geïntegreerd met externe bronnen zoals FM's voor het uitvoeren van complexe taken zoals sentimentanalyse. U kunt UDF's gebruiken om verschillende statistieken te berekenen of onbewerkte gegevens van gebruikersfeedback te verrijken met aanvullende inzichten, zoals gebruikerssentiment. Voor meer informatie over dit patroon raadpleegt u Proactief in realtime omgaan met klantproblemen met GenAI, Flink, Apache Kafka en Kinesis.
Met Managed Service voor Apache Flink Studio kunt u uw Studio-notebook met één klik inzetten als streamingtaak. U kunt de native sink-connectoren van Apache Flink gebruiken om de uitvoer naar de opslag van uw keuze te sturen of deze in een Kinesis-gegevensstroom of MSK-onderwerp te plaatsen. Amazon roodverschuiving en OpenSearch Service zijn beide ideaal voor het opslaan van analytische gegevens. Beide motoren bieden native opnameondersteuning van Kinesis Data Streams en Amazon MSK via een afzonderlijke streamingpijplijn naar een datameer of datawarehouse voor analyse.
Amazon Redshift gebruikt SQL om gestructureerde en semi-gestructureerde gegevens in datawarehouses en datameren te analyseren, met behulp van door AWS ontworpen hardware en machine learning om op grote schaal de beste prijs-prestatieverhouding te leveren. OpenSearch Service biedt visualisatiemogelijkheden mogelijk gemaakt door OpenSearch Dashboards en Kibana (versies 1.5 tot 7.10).
U kunt de uitkomst van een dergelijke analyse gebruiken, gecombineerd met gebruikerspromptgegevens, om de FM te verfijnen wanneer dat nodig is. SageMaker is de meest eenvoudige manier om uw FM's te verfijnen. Het gebruik van Amazon S3 met SageMaker biedt een krachtige en naadloze integratie voor het verfijnen van uw modellen. Amazon S3 dient als een schaalbare en duurzame oplossing voor objectopslag, die het eenvoudig opslaan en ophalen van grote datasets, trainingsgegevens en modelartefacten mogelijk maakt. SageMaker is een volledig beheerde ML-service die de gehele ML-levenscyclus vereenvoudigt. Door Amazon S3 te gebruiken als opslagbackend voor SageMaker, kunt u profiteren van de schaalbaarheid, betrouwbaarheid en kosteneffectiviteit van Amazon S3, terwijl u deze naadloos integreert met de trainings- en implementatiemogelijkheden van SageMaker. Deze combinatie maakt efficiënt gegevensbeheer mogelijk, vergemakkelijkt de ontwikkeling van samenwerkingsmodellen en zorgt ervoor dat ML-workflows gestroomlijnd en schaalbaar zijn, waardoor uiteindelijk de algehele flexibiliteit en prestaties van het ML-proces worden verbeterd. Voor meer informatie, zie Verfijn Falcon 7B en andere LLM's op Amazon SageMaker met @remote decorateur.
Met een sink-connector voor het bestandssysteem kunnen Apache Flink-taken gegevens in open formaat (zoals JSON, Avro, Parquet en meer) aan Amazon S3 leveren als gegevensobjecten. Als u uw data lake liever beheert met behulp van een transactioneel data lake-framework (zoals Apache Hudi, Apache Iceberg of Delta Lake), bieden al deze frameworks een aangepaste connector voor Apache Flink. Voor meer details, zie Maak een low-latency source-to-data lake-pijplijn met Amazon MSK Connect, Apache Flink en Apache Hudi.
Samengevat
Voor een generatieve AI-toepassing op basis van een RAG-model moet je overwegen om twee dataopslagsystemen te bouwen, en moet je databewerkingen bouwen die deze up-to-date houden met alle bronsystemen. Traditionele batchtaken zijn niet voldoende om de omvang en diversiteit van de gegevens te verwerken die u nodig hebt om te integreren met uw generatieve AI-toepassing. Vertragingen bij het verwerken van de wijzigingen in bronsystemen resulteren in een onnauwkeurige reactie en verminderen de efficiëntie van uw generatieve AI-toepassing. Met gegevensstreaming kunt u gegevens uit verschillende databases op verschillende systemen opnemen. Het stelt u ook in staat om gegevens uit vele bronnen efficiënt en vrijwel in realtime te transformeren, te verrijken, samen te voegen en samen te voegen. Datastreaming biedt een vereenvoudigde dataarchitectuur voor het verzamelen en transformeren van realtime reacties van gebruikers of opmerkingen over de applicatiereacties, zodat u de resultaten kunt leveren en opslaan in een datameer voor het verfijnen van modellen. Met gegevensstreaming kunt u ook gegevenspijplijnen optimaliseren door alleen de wijzigingsgebeurtenissen te verwerken, zodat u sneller en efficiënter op gegevenswijzigingen kunt reageren.
Lees verder over AWS-gegevensstreamingdiensten en ga aan de slag met het bouwen van uw eigen oplossing voor datastreaming.
Over de auteurs
 Ali Alemi is een Streaming Specialist Solutions Architect bij AWS. Ali adviseert AWS-klanten met best practices op het gebied van architectuur en helpt hen bij het ontwerpen van realtime analysegegevenssystemen die betrouwbaar, veilig, efficiënt en kosteneffectief zijn. Hij werkt achterwaarts vanuit de gebruiksscenario's van klanten en ontwerpt data-oplossingen om hun zakelijke problemen op te lossen. Voordat hij bij AWS kwam, ondersteunde Ali verschillende klanten in de publieke sector en AWS-consultingpartners bij het moderniseren van applicaties en de migratie naar de cloud.
Ali Alemi is een Streaming Specialist Solutions Architect bij AWS. Ali adviseert AWS-klanten met best practices op het gebied van architectuur en helpt hen bij het ontwerpen van realtime analysegegevenssystemen die betrouwbaar, veilig, efficiënt en kosteneffectief zijn. Hij werkt achterwaarts vanuit de gebruiksscenario's van klanten en ontwerpt data-oplossingen om hun zakelijke problemen op te lossen. Voordat hij bij AWS kwam, ondersteunde Ali verschillende klanten in de publieke sector en AWS-consultingpartners bij het moderniseren van applicaties en de migratie naar de cloud.
 Imtiaz (Taz) zei is de World Wide Tech Leader voor Analytics bij AWS. Hij houdt ervan om met de gemeenschap in gesprek te gaan over alles wat met data en analytics te maken heeft. Hij is te bereiken via LinkedIn.
Imtiaz (Taz) zei is de World Wide Tech Leader voor Analytics bij AWS. Hij houdt ervan om met de gemeenschap in gesprek te gaan over alles wat met data en analytics te maken heeft. Hij is te bereiken via LinkedIn.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

