Dit bericht is geschreven in samenwerking met Pramod Nayak, LakshmiKanth Mannem en Vivek Aggarwal van de Low Latency Group van LSEG.
Transactiekostenanalyse (TCA) wordt veel gebruikt door handelaren, portefeuillebeheerders en makelaars voor analyse vóór en na de handel, en helpt hen de transactiekosten en de effectiviteit van hun handelsstrategieën te meten en te optimaliseren. In dit bericht analyseren we de bied-laatspreads van de opties LSEG-tekengeschiedenis – PCAP dataset gebruikt Amazon Athena voor Apache Spark. We laten u zien hoe u toegang krijgt tot gegevens, aangepaste functies definieert om op gegevens toe te passen, de gegevensset opvraagt en filtert en de resultaten van de analyse visualiseert, allemaal zonder dat u zich zorgen hoeft te maken over het opzetten van infrastructuur of het configureren van Spark, zelfs voor grote datasets.
Achtergrond
Options Price Reporting Authority (OPRA) fungeert als een cruciale verwerker van effecteninformatie en verzamelt, consolideert en verspreidt laatste verkooprapporten, koersen en relevante informatie voor Amerikaanse opties. Met 18 actieve Amerikaanse optiebeurzen en meer dan 1.5 miljoen in aanmerking komende contracten speelt OPRA een cruciale rol bij het verstrekken van uitgebreide marktgegevens.
Op 5 februari 2024 zal de Securities Industry Automation Corporation (SIAC) de OPRA-feed upgraden van 48 naar 96 multicast-kanalen. Deze verbetering heeft tot doel de symbooldistributie en het gebruik van lijncapaciteit te optimaliseren als reactie op de escalerende handelsactiviteit en volatiliteit op de Amerikaanse optiemarkt. SIAC heeft aanbevolen dat bedrijven zich voorbereiden op piekdatasnelheden tot 37.3 GBits per seconde.
Ondanks dat de upgrade het totale volume aan gepubliceerde gegevens niet onmiddellijk verandert, kan OPRA gegevens aanzienlijk sneller verspreiden. Deze transitie is van cruciaal belang om tegemoet te komen aan de eisen van de dynamische optiemarkt.
OPRA valt op als een van de meest omvangrijke feeds, met een piek van 150.4 miljard berichten op één dag in het derde kwartaal van 3 en een capaciteitsvereiste van 2023 miljard berichten op één dag. Het vastleggen van elk afzonderlijk bericht is van cruciaal belang voor analyse van transactiekosten, monitoring van de marktliquiditeit, evaluatie van handelsstrategieën en marktonderzoek.
Over de gegevens
LSEG-tekengeschiedenis – PCAP is een cloudgebaseerde opslagplaats van meer dan 30 PB, die ultrahoge kwaliteit wereldwijde marktgegevens bevat. Deze gegevens worden nauwgezet rechtstreeks in de uitwisselingsdatacentra vastgelegd, waarbij gebruik wordt gemaakt van redundante vastlegprocessen die strategisch zijn gepositioneerd in de belangrijkste primaire en back-upuitwisselingsdatacentra over de hele wereld. De vastlegtechnologie van LSEG zorgt voor verliesvrije gegevensvastlegging en maakt gebruik van een GPS-tijdbron voor tijdstempelprecisie van nanoseconden. Bovendien worden geavanceerde dataarbitragetechnieken gebruikt om eventuele datalacunes naadloos op te vullen. Na het vastleggen ondergaan de gegevens een nauwgezette verwerking en arbitrage, en worden vervolgens genormaliseerd naar het Parquet-formaat met behulp van LSEG's realtime ultradirect (RTUD) voerbehandelaars.
Het normalisatieproces, dat een integraal onderdeel is van het voorbereiden van de gegevens voor analyse, genereert tot 6 TB aan gecomprimeerde Parquet-bestanden per dag. De enorme hoeveelheid gegevens wordt toegeschreven aan het allesomvattende karakter van OPRA, dat meerdere beurzen omvat en talrijke optiecontracten bevat die worden gekenmerkt door uiteenlopende kenmerken. De toegenomen marktvolatiliteit en marktmakingactiviteiten op de optiebeurzen dragen verder bij aan de hoeveelheid gegevens die op OPRA worden gepubliceerd.
De kenmerken van Tick History – PCAP stellen bedrijven in staat verschillende analyses uit te voeren, waaronder de volgende:
- Analyse vóór de handel – Evalueer de potentiële handelsimpact en verken verschillende uitvoeringsstrategieën op basis van historische gegevens
- Evaluatie na de handel – Meet de werkelijke uitvoeringskosten aan de hand van benchmarks om de prestaties van uitvoeringsstrategieën te beoordelen
- Geoptimaliseerde uitvoering – Verfijn uitvoeringsstrategieën op basis van historische marktpatronen om de marktimpact te minimaliseren en de totale handelskosten te verlagen
- Risicomanagement – Identificeer slippatronen, identificeer uitschieters en beheer proactief de risico's die verband houden met handelsactiviteiten
- Prestatie attributie – Scheid de impact van handelsbeslissingen van investeringsbeslissingen bij het analyseren van portefeuilleprestaties
De LSEG Tick History – PCAP-dataset is beschikbaar in AWS-gegevensuitwisseling en is toegankelijk via AWS Marketplace. Met AWS-gegevensuitwisseling voor Amazon S3, heeft u rechtstreeks toegang tot PCAP-gegevens vanuit LSEG's Amazon eenvoudige opslagservice (Amazon S3)-buckets, waardoor bedrijven niet langer hun eigen kopie van de gegevens hoeven op te slaan. Deze aanpak stroomlijnt het gegevensbeheer en de opslag, waardoor klanten onmiddellijke toegang krijgen tot hoogwaardige PCAP of genormaliseerde gegevens met gebruiksgemak, integratie en aanzienlijke besparingen op gegevensopslag.
Athena voor Apache Spark
Voor analytische inspanningen, Athena voor Apache Spark biedt een vereenvoudigde notebookervaring die toegankelijk is via de Athena-console of Athena API's, waardoor u interactieve Apache Spark-applicaties kunt bouwen. Met een geoptimaliseerde Spark-runtime helpt Athena bij de analyse van petabytes aan gegevens door het aantal Spark-engines dynamisch te schalen in minder dan een seconde. Bovendien zijn veelgebruikte Python-bibliotheken zoals Panda's en NumPy naadloos geïntegreerd, waardoor ingewikkelde applicatielogica kan worden gecreëerd. De flexibiliteit strekt zich uit tot de import van aangepaste bibliotheken voor gebruik in notebooks. Athena for Spark is geschikt voor de meeste open-dataformaten en is naadloos geïntegreerd met de AWS lijm Gegevenscatalogus.
dataset
Voor deze analyse hebben we de LSEG Tick History – PCAP OPRA-dataset van 17 mei 2023 gebruikt. Deze dataset bestaat uit de volgende componenten:
- Beste bied- en laatprijs (BBO) – Rapporteert het hoogste bod en de laagste vraag voor een effect op een bepaalde beurs
- Nationaal beste bod en laat (NBBO) – Rapporteert het hoogste bod en de laagste vraag voor een effect op alle beurzen
- Trades – Registreert voltooide transacties op alle beurzen
De dataset omvat de volgende datavolumes:
- Trades – 160 MB verdeeld over ongeveer 60 gecomprimeerde Parquet-bestanden
- BBO – 2.4 TB verdeeld over ongeveer 300 gecomprimeerde Parquet-bestanden
- NBBO – 2.8 TB verdeeld over ongeveer 200 gecomprimeerde Parquet-bestanden
Analyse overzicht
Het analyseren van OPRA Tick History-gegevens voor Transaction Cost Analysis (TCA) omvat het nauwkeurig onderzoeken van marktnoteringen en transacties rond een specifiek handelsevenement. We gebruiken de volgende statistieken als onderdeel van dit onderzoek:
- Geciteerde spread (QS) – Berekend als het verschil tussen de BBO-vraag en het BBO-bod
- Effectieve spreiding (ES) – Berekend als het verschil tussen de handelsprijs en het middelpunt van de BBO (BBO-bod + (BBO ask – BBO-bod)/2)
- Effectieve/geciteerde spread (EQF) – Berekend als (ES / QS) * 100
We berekenen deze spreads vóór de transactie en bovendien met vier intervallen na de transactie (net erna, 1 seconde, 10 seconden en 60 seconden na de transactie).
Configureer Athena voor Apache Spark
Voer de volgende stappen uit om Athena voor Apache Spark te configureren:
- Op de Athena-console, onder Startselecteer Analyseer uw gegevens met PySpark en Spark SQL.
- Als dit de eerste keer is dat u Athena Spark gebruikt, kies dan Werkgroep maken.

- Voor Werkgroep naam¸ voer een naam in voor de werkgroep, bijvoorbeeld
tca-analysis. - In het Analytics-engine sectie, selecteer Apache Spark.
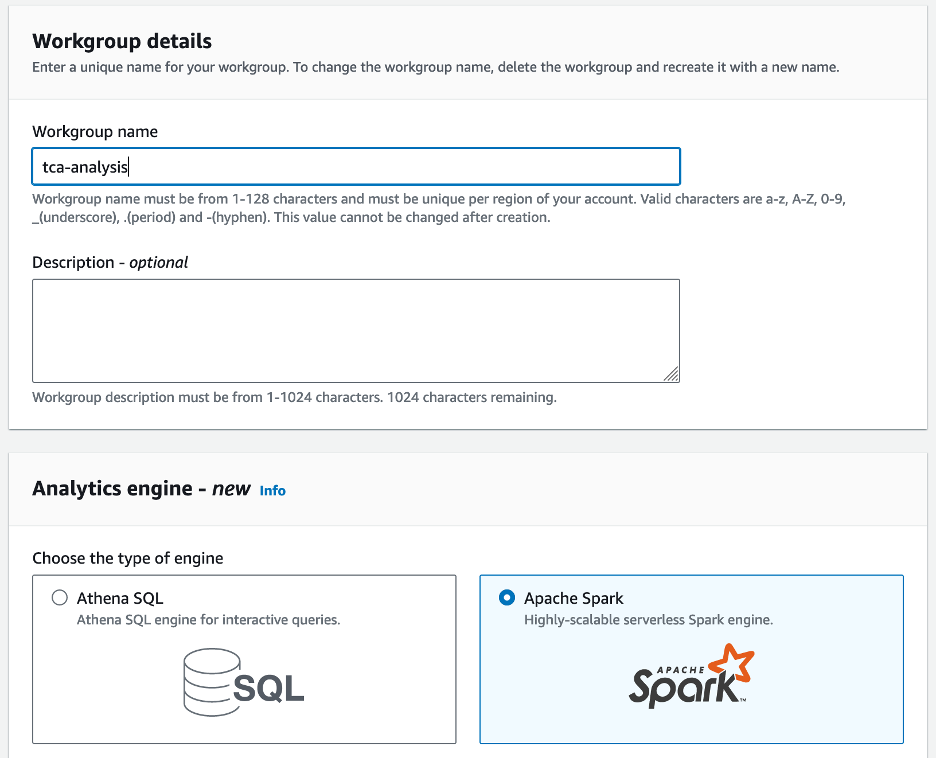
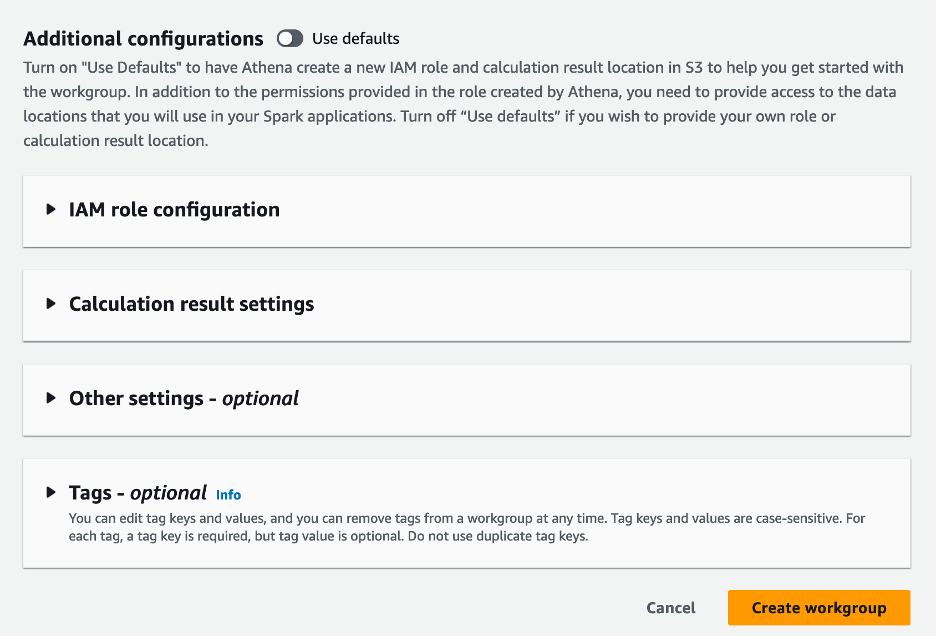
- In het Aanvullende configuraties sectie, u kunt kiezen Standaardinstellingen gebruiken of geef een gewoonte aan AWS Identiteits- en toegangsbeheer (IAM)-rol en Amazon S3-locatie voor berekeningsresultaten.
- Kies Werkgroep maken.
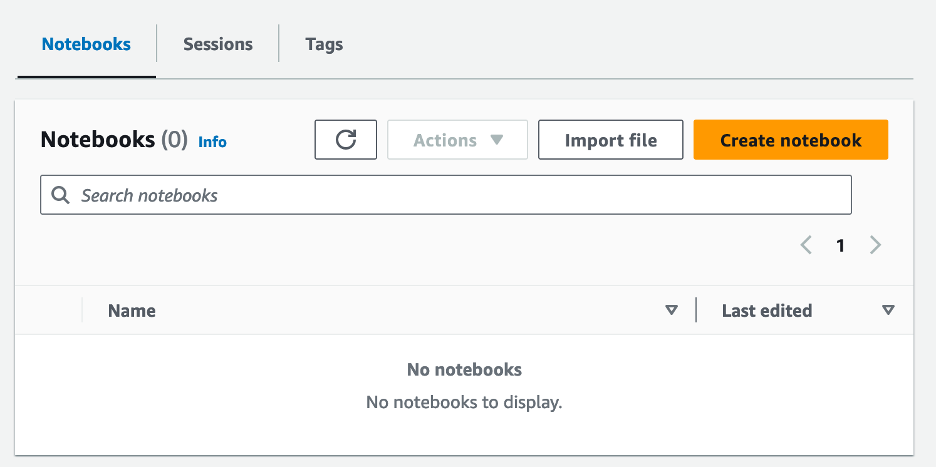
- Nadat u de werkgroep hebt gemaakt, navigeert u naar de Notitieboekjes tab en kies Maak een notitieboekje.
- Voer een naam in voor uw notitieblok, bijvoorbeeld
tca-analysis-with-tick-history. - Kies creëren om uw notitieboekje te maken.
Start uw notitieboekje
Als u al een Spark-werkgroep hebt gemaakt, selecteert u Start de notitieboekjeeditor voor Start.
![]()
Nadat uw notitieblok is aangemaakt, wordt u doorgestuurd naar de interactieve notitieboekeditor.
![]()
Nu kunnen we de volgende code aan onze notebook toevoegen en uitvoeren.
Maak een analyse
Voer de volgende stappen uit om een analyse te maken:
- Gemeenschappelijke bibliotheken importeren:
- Creëer onze dataframes voor BBO, NBBO en transacties:
- Nu kunnen we een transactie identificeren die we kunnen gebruiken voor de analyse van transactiekosten:
We krijgen de volgende uitvoer:
We gebruiken de gemarkeerde handelsinformatie in de toekomst voor het handelsproduct (tp), de handelsprijs (tpr) en de handelstijd (tt).
- Hier creëren we een aantal helperfuncties voor onze analyse
- In de volgende functie creëren we de dataset die alle koersen voor en na de transactie bevat. Athena Spark bepaalt automatisch hoeveel DPU's moeten worden gestart voor het verwerken van onze dataset.
- Laten we nu de TCA-analysefunctie oproepen met de informatie van onze geselecteerde transactie:
Visualiseer de analyseresultaten
Laten we nu de dataframes maken die we voor onze visualisatie gebruiken. Elk dataframe bevat offertes voor een van de vijf tijdsintervallen voor elke datafeed (BBO, NBBO):
In de volgende secties bieden we voorbeeldcode om verschillende visualisaties te maken.
Plot QS en NBBO vóór de transactie
Gebruik de volgende code om de genoteerde spread en NBBO vóór de transactie in kaart te brengen:
![]()
Teken QS voor elke markt en NBBO na de transactie
Gebruik de volgende code om de genoteerde spread voor elke markt en NBBO onmiddellijk na de transactie in kaart te brengen:
![]()
Teken QS voor elk tijdsinterval en elke markt voor BBO
Gebruik de volgende code om de genoteerde spread voor elk tijdsinterval en elke markt voor BBO in kaart te brengen:
![]()
Teken ES voor elk tijdsinterval en markt voor BBO
Gebruik de volgende code om de effectieve spread voor elk tijdsinterval en elke markt voor BBO in kaart te brengen:
Teken het EQF voor elk tijdsinterval en elke markt voor BBO
Gebruik de volgende code om de effectieve/geciteerde spread voor elk tijdsinterval en elke markt voor BBO in kaart te brengen:
Athena Spark-berekeningsprestaties
Wanneer u een codeblok uitvoert, bepaalt Athena Spark automatisch hoeveel DPU's er nodig zijn om de berekening te voltooien. In het laatste codeblok, waar we de tca_analysis functie, instrueren we Spark feitelijk om de gegevens te verwerken, en vervolgens zetten we de resulterende Spark-dataframes om in Pandas-dataframes. Dit vormt het meest intensieve verwerkingsgedeelte van de analyse en wanneer Athena Spark dit blok uitvoert, worden de voortgangsbalk, de verstreken tijd en het aantal DPU's weergegeven dat momenteel gegevens verwerken. In de volgende berekening gebruikt Athena Spark bijvoorbeeld 18 DPU's.
![]()
Wanneer u uw Athena Spark-notebook configureert, heeft u de mogelijkheid om het maximale aantal DPU's in te stellen dat deze kan gebruiken. De standaardwaarde is 20 DPU's, maar we hebben deze berekening getest met 10, 20 en 40 DPU's om aan te tonen hoe Athena Spark automatisch schaalt om onze analyse uit te voeren. We hebben vastgesteld dat Athena Spark lineair schaalt, wat 15 minuten en 21 seconden duurt als de notebook is geconfigureerd met maximaal 10 DPU's, 8 minuten en 23 seconden als de notebook is geconfigureerd met 20 DPU's, en 4 minuten en 44 seconden als de notebook is geconfigureerd geconfigureerd met 40 DPU's. Omdat Athena Spark kosten in rekening brengt op basis van DPU-gebruik, zijn de kosten van deze berekeningen vergelijkbaar per seconde, maar als u een hogere maximale DPU-waarde instelt, kan Athena Spark het resultaat van de analyse veel sneller retourneren. Klik voor meer informatie over de prijzen van Athena Spark hier.
Conclusie
In dit bericht hebben we laten zien hoe u hoogwaardige OPRA-gegevens van LSEG's Tick History-PCAP kunt gebruiken om transactiekostenanalyses uit te voeren met Athena Spark. De tijdige beschikbaarheid van OPRA-gegevens, aangevuld met toegankelijkheidsinnovaties van AWS Data Exchange voor Amazon S3, verkort op strategische wijze de tijd die nodig is voor analyse voor bedrijven die bruikbare inzichten willen creëren voor cruciale handelsbeslissingen. OPRA genereert elke dag ongeveer 7 TB aan genormaliseerde Parquet-gegevens, en het beheren van de infrastructuur om analyses te bieden op basis van OPRA-gegevens is een uitdaging.
De schaalbaarheid van Athena bij het verwerken van grootschalige gegevensverwerking voor Tick History – PCAP voor OPRA-gegevens maakt het een aantrekkelijke keuze voor organisaties die op zoek zijn naar snelle en schaalbare analyseoplossingen in AWS. Dit bericht toont de naadloze interactie tussen het AWS-ecosysteem en Tick History-PCAP-gegevens en hoe financiële instellingen kunnen profiteren van deze synergie om datagestuurde besluitvorming voor cruciale handels- en investeringsstrategieën te stimuleren.
Over de auteurs
![]() Pramod Najak is directeur Product Management van de Low Latency Group bij LSEG. Pramod heeft meer dan 10 jaar ervaring in de financiële technologie-industrie, met de nadruk op softwareontwikkeling, analyse en gegevensbeheer. Pramod is een voormalig software-ingenieur en gepassioneerd door marktgegevens en kwantitatieve handel.
Pramod Najak is directeur Product Management van de Low Latency Group bij LSEG. Pramod heeft meer dan 10 jaar ervaring in de financiële technologie-industrie, met de nadruk op softwareontwikkeling, analyse en gegevensbeheer. Pramod is een voormalig software-ingenieur en gepassioneerd door marktgegevens en kwantitatieve handel.
![]() LakshmiKanth Mannem is productmanager bij de Low Latency Group van LSEG. Hij richt zich op data- en platformproducten voor de marktdata-industrie met lage latentie. LakshmiKanth helpt klanten bij het bouwen van de meest optimale oplossingen voor hun marktgegevensbehoeften.
LakshmiKanth Mannem is productmanager bij de Low Latency Group van LSEG. Hij richt zich op data- en platformproducten voor de marktdata-industrie met lage latentie. LakshmiKanth helpt klanten bij het bouwen van de meest optimale oplossingen voor hun marktgegevensbehoeften.
![]() Vivek Aggarwal is een Senior Data Engineer in de Low Latency Group van LSEG. Vivek werkt aan het ontwikkelen en onderhouden van datapijplijnen voor de verwerking en levering van vastgelegde marktdatafeeds en referentiedatafeeds.
Vivek Aggarwal is een Senior Data Engineer in de Low Latency Group van LSEG. Vivek werkt aan het ontwikkelen en onderhouden van datapijplijnen voor de verwerking en levering van vastgelegde marktdatafeeds en referentiedatafeeds.
![]() Alket Memushaj is hoofdarchitect in het Financial Services Market Development-team van AWS. Alket is verantwoordelijk voor de technische strategie en werkt samen met partners en klanten om zelfs de meest veeleisende kapitaalmarktworkloads in de AWS Cloud te implementeren.
Alket Memushaj is hoofdarchitect in het Financial Services Market Development-team van AWS. Alket is verantwoordelijk voor de technische strategie en werkt samen met partners en klanten om zelfs de meest veeleisende kapitaalmarktworkloads in de AWS Cloud te implementeren.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/

