Met de snelle adoptie van generatieve AI-applicaties is het nodig dat deze applicaties op tijd reageren om de waargenomen latentie met een hogere doorvoer te verminderen. Fundamentele modellen (FM's) zijn vaak vooraf getraind op enorme hoeveelheden gegevens met parameters die in omvang variëren van miljoenen tot miljarden en daarbuiten. Grote taalmodellen (LLM's) zijn een type FM dat tekst genereert als reactie op de gevolgtrekking van de gebruiker. Het afleiden van deze modellen met variërende configuraties van inferentieparameters kan leiden tot inconsistente latenties. De inconsistentie kan te wijten zijn aan het variërende aantal responstokens dat u van het model verwacht, of aan het type accelerator waarop het model wordt geïmplementeerd.
In beide gevallen kunt u, in plaats van te wachten op het volledige antwoord, de aanpak van antwoordstreaming voor uw gevolgtrekkingen hanteren, waarbij stukjes informatie worden teruggestuurd zodra ze worden gegenereerd. Dit creëert een interactieve ervaring doordat u gedeeltelijke reacties in realtime kunt zien gestreamd in plaats van een vertraagde volledige reactie.
Met de officiële aankondiging dat Real-time inferentie van Amazon SageMaker ondersteunt nu responsstreaming, kunt u nu tijdens het gebruik continu gevolgtrekkingsreacties terugsturen naar de client Amazon Sage Maker realtime gevolgtrekking met antwoordstreaming. Met deze oplossing kunt u interactieve ervaringen bouwen voor verschillende generatieve AI-toepassingen, zoals chatbots, virtuele assistenten en muziekgeneratoren. Dit bericht laat zien hoe u snellere responstijden kunt realiseren in de vorm van Time to First Byte (TTFB) en de algehele waargenomen latentie kunt verminderen terwijl u Llama 2-modellen afleidt.
Om de oplossing te implementeren, gebruiken we SageMaker, een volledig beheerde service om gegevens voor te bereiden en machine learning-modellen (ML) te bouwen, trainen en implementeren voor elk gebruiksscenario met volledig beheerde infrastructuur, tools en workflows. Voor meer informatie over de verschillende implementatieopties die SageMaker biedt, raadpleegt u Veelgestelde vragen over Amazon SageMaker-modelhosting. Laten we eens kijken hoe we de latentieproblemen kunnen aanpakken met behulp van realtime gevolgtrekking met antwoordstreaming.
Overzicht oplossingen
Omdat we de bovengenoemde latenties die verband houden met realtime inferentie met LLM's willen aanpakken, gaan we eerst begrijpen hoe we de ondersteuning voor responsstreaming kunnen gebruiken voor realtime inferentie voor Llama 2. Elke LLM kan echter profiteren van ondersteuning voor responsstreaming met echte -tijdconclusie.
Llama 2 is een verzameling vooraf getrainde en verfijnde generatieve tekstmodellen, variërend in schaal van 7 miljard tot 70 miljard parameters. Llama 2-modellen zijn autoregressieve modellen met alleen een decoderarchitectuur. Wanneer de Llama 2-modellen zijn voorzien van een prompt en gevolgtrekkingsparameters, kunnen ze tekstreacties genereren. Deze modellen kunnen worden gebruikt voor vertaling, samenvatten, beantwoorden van vragen en chatten.
Voor dit bericht gebruiken we het Llama 2 Chat-model meta-llama/Llama-2-13b-chat-hf op SageMaker voor realtime gevolgtrekking met responsstreaming.
Als het gaat om het implementeren van modellen op SageMaker-eindpunten, kunt u de modellen in containers plaatsen met behulp van gespecialiseerde AWS Deep Learning-container (DLC)-afbeeldingen beschikbaar voor populaire open source-bibliotheken. Llama 2-modellen zijn modellen voor het genereren van tekst; je kunt de Hugging Face LLM-inferentiecontainers op SageMaker aangedreven door knuffelend gezicht Inferentie voor het genereren van tekst (TGI) of AWS DLC's voor Grote modelinferentie (LMI).
In dit bericht implementeren we het Llama 2 13B Chat-model met behulp van DLC's op SageMaker Hosting voor realtime gevolgtrekking, mogelijk gemaakt door G5-instanties. G5-instanties zijn krachtige GPU-gebaseerde instanties voor grafisch-intensieve applicaties en ML-inferentie. U kunt ook de ondersteunde exemplaartypen p4d, p3, g5 en g4dn gebruiken met de juiste wijzigingen volgens de exemplaarconfiguratie.
Voorwaarden
Om deze oplossing te implementeren, moet u over het volgende beschikken:
- Een AWS-account met een AWS Identiteits- en toegangsbeheer (IAM)-rol met machtigingen voor het beheren van bronnen die zijn gemaakt als onderdeel van de oplossing.
- Als dit de eerste keer is dat u ermee werkt Amazon SageMaker Studio, moet je eerst een SageMaker-domein.
- Een Hugging Face-account. Aanmelden met uw e-mailadres als u nog geen account heeft.
- Voor naadloze toegang tot de modellen die beschikbaar zijn op Hugging Face, met name gated modellen zoals Llama, voor fijnafstemming en gevolgtrekkingsdoeleinden, moet u een Hugging Face-account hebben om een leestoegangstoken te verkrijgen. Nadat u zich heeft aangemeld voor uw Hugging Face-account, Log in bezoeken https://huggingface.co/settings/tokens om een leestoegangstoken te maken.
- Toegang tot Llama 2, met hetzelfde e-mailadres dat u heeft gebruikt om u aan te melden voor Hugging Face.
- De Llama 2-modellen die beschikbaar zijn via Hugging Face zijn gated-modellen. Het gebruik van het Llama-model valt onder de Meta-licentie. Om de modelgewichten en tokenizer te downloaden, toegang vragen tot Lama en accepteer hun licentie.
- Nadat u toegang heeft gekregen (meestal binnen een paar dagen), ontvangt u een e-mailbevestiging. Voor dit voorbeeld gebruiken we het model
Llama-2-13b-chat-hf, maar je zou ook toegang moeten hebben tot andere varianten.
Benadering 1: Gezicht knuffelen TGI
In deze sectie laten we u zien hoe u de meta-llama/Llama-2-13b-chat-hf model naar een real-time eindpunt van SageMaker met antwoordstreaming met behulp van Hugging Face TGI. In de volgende tabel worden de specificaties voor deze implementatie beschreven.
| Specificaties | Waarde |
| Containers | Knuffelend gezicht TGI |
| Modelnaam | meta-lama/Llama-2-13b-chat-hf |
| ML-instantie | ml.g5.12xgroot |
| Gevolgtrekking | Realtime met responsstreaming |
Implementeer het model
Eerst haalt u de basisimage op voor de LLM die moet worden geïmplementeerd. Vervolgens bouwt u het model op de basisafbeelding. Ten slotte implementeert u het model op de ML-instantie voor SageMaker Hosting voor realtime gevolgtrekking.
Laten we eens kijken hoe we de implementatie programmatisch kunnen realiseren. Kortheidshalve wordt in deze sectie alleen de code besproken die helpt bij de implementatiestappen. De volledige broncode voor implementatie is beschikbaar in de notebook llama-2-hf-tgi/llama-2-13b-chat-hf/1-deploy-llama-2-13b-chat-hf-tgi-sagemaker.ipynb.
Haal de nieuwste Hugging Face LLM DLC op, mogelijk gemaakt door TGI via vooraf gebouwd SageMaker DLC's. U gebruikt deze installatiekopie om de meta-llama/Llama-2-13b-chat-hf model op SageMaker. Zie de volgende code:
Definieer de omgeving voor het model met de configuratieparameters die als volgt zijn gedefinieerd:
vervangen <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> voor de configuratieparameter HUGGING_FACE_HUB_TOKEN met de waarde van het token verkregen uit uw Hugging Face-profiel zoals beschreven in het gedeelte met vereisten van dit bericht. In de configuratie definieert u het aantal GPU's dat per replica van een model wordt gebruikt als 4 SM_NUM_GPUS. Dan kun je de meta-llama/Llama-2-13b-chat-hf model op een ml.g5.12xlarge-instantie die wordt geleverd met 4 GPU's.
Nu kunt u de instantie van bouwen HuggingFaceModel met de bovengenoemde omgevingsconfiguratie:
Implementeer ten slotte het model door argumenten op te geven voor de implementatiemethode die beschikbaar is in het model met verschillende parameterwaarden, zoals endpoint_name, initial_instance_count en instance_type:
Gevolgtrekking uitvoeren
De Hugging Face TGI DLC wordt geleverd met de mogelijkheid om reacties te streamen zonder aanpassingen of codewijzigingen aan het model. Je kunt gebruiken roep_endpoint_with_response_stream aan als u Boto3 of Roep EndpointWithResponseStream aan bij het programmeren met de SageMaker Python SDK.
De InvokeEndpointWithResponseStream Met de API van SageMaker kunnen ontwikkelaars reacties terugstreamen vanuit SageMaker-modellen, wat de klanttevredenheid kan helpen verbeteren door de waargenomen latentie te verminderen. Dit is vooral belangrijk voor applicaties die zijn gebouwd met generatieve AI-modellen, waarbij onmiddellijke verwerking belangrijker is dan wachten op het volledige antwoord.
Voor dit voorbeeld gebruiken we Boto3 om het model af te leiden en de SageMaker API te gebruiken invoke_endpoint_with_response_stream als volgt:
Het argument CustomAttributes is ingesteld op de waarde accept_eula=false. De accept_eula parameter moet worden ingesteld true om met succes het antwoord van de Llama 2-modellen te verkrijgen. Na de succesvolle aanroep met behulp van invoke_endpoint_with_response_stream, retourneert de methode een antwoordstroom van bytes.
Het volgende diagram illustreert deze workflow.
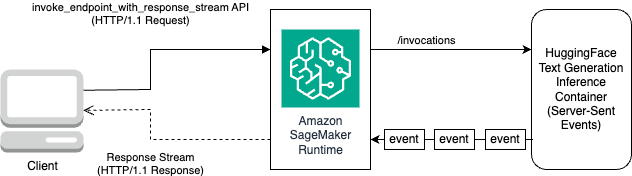
Je hebt een iterator nodig die de stroom bytes doorloopt en deze ontleedt tot leesbare tekst. De LineIterator uitvoering vindt u op lama-2-hf-tgi/llama-2-13b-chat-hf/utils/LineIterator.py. Nu bent u klaar om de prompt en instructies voor te bereiden om ze als payload te gebruiken bij het afleiden van het model.
Bereid een prompt en instructies voor
In deze stap bereidt u de prompt en instructies voor uw LLM voor. Om Llama 2 te kunnen oproepen, moet u over het volgende promptsjabloon beschikken:
U bouwt de aanwijzingssjabloon die programmatisch in de methode is gedefinieerd build_llama2_prompt, wat aansluit bij de bovengenoemde promptsjabloon. Vervolgens definieert u de instructies volgens de use case. In dit geval geven we het model opdracht om een e-mail te genereren voor een marketingcampagne, zoals beschreven in de get_instructions methode. De code voor deze methoden staat in de llama-2-hf-tgi/llama-2-13b-chat-hf/2-sagemaker-realtime-inference-llama-2-13b-chat-hf-tgi-streaming-response.ipynb notitieboekje. Bouw de instructie samen met de uit te voeren taak, zoals beschreven in user_ask_1 als volgt:
We geven de instructies door om de prompt te bouwen volgens de promptsjabloon gegenereerd door build_llama2_prompt.
We combineren de gevolgtrekkingsparameters samen met de prompt met de sleutel stream met de waarde True om een uiteindelijke lading te vormen. Stuur de lading naar get_realtime_response_stream, die zal worden gebruikt om een eindpunt aan te roepen met antwoordstreaming:
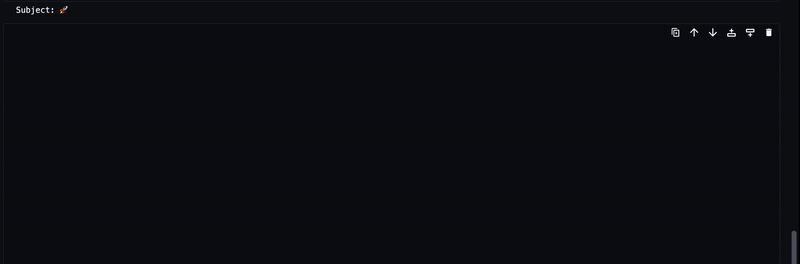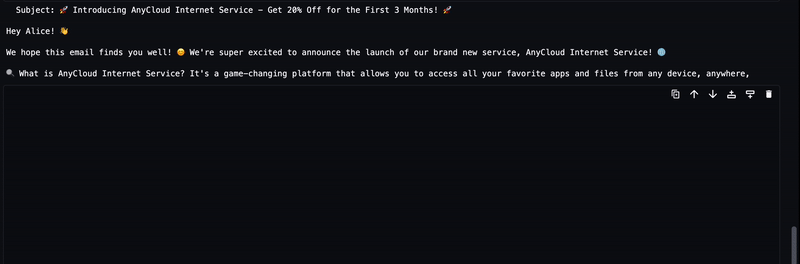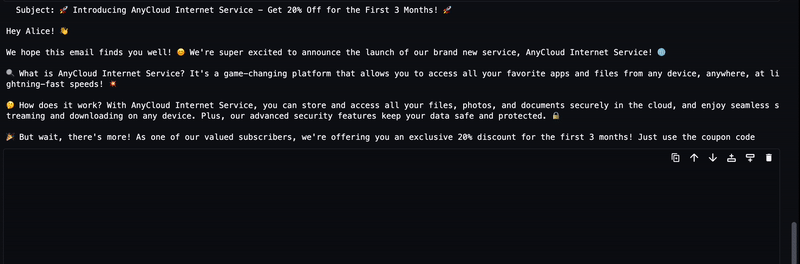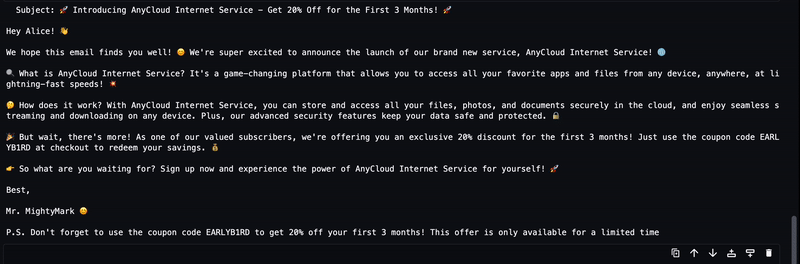
De gegenereerde tekst van de LLM wordt naar de uitvoer gestreamd, zoals weergegeven in de volgende animatie.
Aanpak 2: LMI met DJL Serving
In deze sectie laten we zien hoe u de meta-llama/Llama-2-13b-chat-hf model naar een real-time eindpunt van SageMaker met responsstreaming met behulp van LMI met DJL Serving. In de volgende tabel worden de specificaties voor deze implementatie beschreven.
| Specificaties | Waarde |
| Containers | LMI-containerimage met DJL Serving |
| Modelnaam | meta-lama/Llama-2-13b-chat-hf |
| ML-instantie | ml.g5.12xgroot |
| Gevolgtrekking | Realtime met responsstreaming |
Je downloadt eerst het model en slaat het op Amazon eenvoudige opslagservice (Amazone S3). Vervolgens geeft u de S3-URI op die het S3-voorvoegsel van het model aangeeft in het serving.properties bestand. Vervolgens haalt u de basisimage op voor de LLM die moet worden geïmplementeerd. Vervolgens bouwt u het model op de basisafbeelding. Ten slotte implementeert u het model op de ML-instantie voor SageMaker Hosting voor realtime gevolgtrekking.
Laten we eens kijken hoe we de bovengenoemde implementatiestappen programmatisch kunnen realiseren. Kortheidshalve wordt in deze sectie alleen de code beschreven die helpt bij de implementatiestappen. De volledige broncode voor deze implementatie is beschikbaar in de notebook llama-2-lmi/llama-2-13b-chat/1-deploy-llama-2-13b-chat-lmi-response-streaming.ipynb.
Download de modelmomentopname van Hugging Face en upload de modelartefacten op Amazon S3
Met de bovengenoemde vereisten downloadt u het model op de SageMaker-notebookinstantie en uploadt u het vervolgens naar de S3-bucket voor verdere implementatie:
Houd er rekening mee dat, ook al geeft u geen geldig toegangstoken op, het model wordt gedownload. Maar als je zo’n model inzet, zal het dienende model niet slagen. Daarom wordt aanbevolen om te vervangen <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> voor het argument token met de waarde van het token verkregen uit uw Hugging Face-profiel zoals beschreven in de vereisten. Voor dit bericht specificeren we de officiële modelnaam voor Llama 2 zoals aangegeven op Hugging Face met de waarde meta-llama/Llama-2-13b-chat-hf. Het ongecomprimeerde model wordt gedownload naar local_model_path als resultaat van het uitvoeren van de bovengenoemde code.
Upload de bestanden naar Amazon S3 en verkrijg de URI, die later zal worden gebruikt serving.properties.
Je gaat de verpakking verpakken meta-llama/Llama-2-13b-chat-hf model op de LMI-containerimage met DJL Serving met behulp van de configuratie gespecificeerd via serving.properties. Vervolgens implementeert u het model samen met modelartefacten die zijn verpakt in de containerimage op de SageMaker ML-instantie ml.g5.12xlarge. Vervolgens gebruikt u deze ML-instantie voor SageMaker Hosting voor realtime gevolgtrekking.
Modelartefacten voorbereiden voor DJL Serving
Bereid uw modelartefacten voor door een serving.properties configuratiebestand:
In dit configuratiebestand gebruiken we de volgende instellingen:
- machine – Dit specificeert de runtime-engine die DJL moet gebruiken. De mogelijke waarden omvatten
Python,DeepSpeed,FasterTransformerenMPI. In dit geval stellen we dit in opMPI. Model Parallelization and Inference (MPI) vergemakkelijkt het verdelen van het model over alle beschikbare GPU's en versnelt daardoor de gevolgtrekking. - optie.entryPoint – Deze optie geeft aan welke handler van DJL Serving u wilt gebruiken. De mogelijke waarden zijn
djl_python.huggingface,djl_python.deepspeedendjl_python.stable-diffusion. We gebruikendjl_python.huggingfacevoor knuffelen gezicht versnellen. - optie.tensor_parallel_degree – Deze optie specificeert het aantal parallelle tensorpartities dat op het model wordt uitgevoerd. U kunt het aantal GPU-apparaten instellen waarover Accelerate het model moet verdelen. Deze parameter bepaalt ook het aantal werkers per model dat zal worden opgestart wanneer DJL-servering wordt uitgevoerd. Als we bijvoorbeeld een machine met 4 GPU's hebben en we vier partities maken, hebben we één medewerker per model om aan de verzoeken te voldoen.
- optie.low_cpu_mem_usage – Dit vermindert het CPU-geheugengebruik bij het laden van modellen. Wij raden u aan dit in te stellen
TRUE. - optie.rolling_batch – Dit maakt batchverwerking op iteratieniveau mogelijk met behulp van een van de ondersteunde strategieën. Waarden omvatten
auto,schedulerenlmi-dist. We gebruikenlmi-distvoor het inschakelen van continue batchverwerking voor Llama 2. - optie.max_rolling_batch_size – Dit beperkt het aantal gelijktijdige verzoeken in de continue batch. De waarde is standaard 32.
- optie.model_id – Je moet vervangen
{{model_id}}met de model-ID van een vooraf getraind model dat wordt gehost in een modelrepository op Hugging Face of S3-pad naar de modelartefacten.
Meer configuratieopties vindt u in Configuraties en instellingen.
Omdat DJL Serving verwacht dat de modelartefacten worden verpakt en geformatteerd in een .tar-bestand, voert u het volgende codefragment uit om het .tar-bestand te comprimeren en te uploaden naar Amazon S3:
Haal de nieuwste LMI-containerimage op met DJL Serving
Vervolgens gebruikt u de DLC's die beschikbaar zijn bij SageMaker voor LMI om het model te implementeren. Haal de SageMaker-afbeeldings-URI op voor de djl-deepspeed container programmatisch met behulp van de volgende code:
U kunt de bovengenoemde afbeelding gebruiken om de meta-llama/Llama-2-13b-chat-hf model op SageMaker. Nu kunt u doorgaan met het maken van het model.
Maak het model
U kunt het model maken waarvan de container is gebouwd met behulp van de inference_image_uri en de modelserveercode die zich bevindt op de S3-URI aangegeven door s3_code_artifact:
Nu kunt u de modelconfiguratie maken met alle details voor de eindpuntconfiguratie.
Maak de modelconfiguratie
Gebruik de volgende code om een modelconfiguratie te maken voor het model dat wordt geïdentificeerd door model_name:
De modelconfiguratie is gedefinieerd voor de ProductionVariants parameter InstanceType voor de ML-instantie ml.g5.12xlarge. Tevens verzorgt u de ModelName waarbij u dezelfde naam gebruikt die u in de eerdere stap hebt gebruikt om het model te maken, waardoor een relatie tot stand wordt gebracht tussen het model en de eindpuntconfiguratie.
Nu u het model en de modelconfiguratie hebt gedefinieerd, kunt u het SageMaker-eindpunt maken.
Maak het SageMaker-eindpunt
Maak het eindpunt om het model te implementeren met behulp van het volgende codefragment:
U kunt de voortgang van de implementatie bekijken met behulp van het volgende codefragment:
Nadat de implementatie is geslaagd, is de eindpuntstatus InService. Nu het eindpunt gereed is, gaan we gevolgtrekkingen maken met antwoordstreaming.
Realtime gevolgtrekking met responsstreaming
Zoals we in de eerdere aanpak voor Hugging Face TGI hebben besproken, kunt u dezelfde methode gebruiken get_realtime_response_stream om antwoordstreaming vanaf het SageMaker-eindpunt aan te roepen. De code voor het afleiden met behulp van de LMI-aanpak staat in de llama-2-lmi/llama-2-13b-chat/2-inference-llama-2-13b-chat-lmi-response-streaming.ipynb notitieboekje. De LineIterator uitvoering bevindt zich in lama-2-lmi/utils/LineIterator.py. Merk op dat de LineIterator voor het Llama 2 Chat-model dat op de LMI-container is geïmplementeerd, verschilt van het LineIterator waarnaar wordt verwezen in de TGI-sectie Knuffelgezicht. De LineIterator loopt over de bytestream van Llama 2 Chat-modellen afgeleid met de LMI-container met djl-deepspeed versie 0.25.0. De volgende helperfunctie parseert de antwoordstroom die wordt ontvangen op basis van het gevolgtrekkingsverzoek dat is gedaan via de invoke_endpoint_with_response_stream API:
De voorgaande methode drukt de gegevensstroom af die is gelezen door de LineIterator in een voor mensen leesbaar formaat.
Laten we eens kijken hoe we de prompt en instructies kunnen voorbereiden om ze als payload te gebruiken bij het afleiden van het model.
Omdat u hetzelfde model afleidt in zowel Hugging Face TGI als LMI, is het proces van het voorbereiden van de prompt en instructies hetzelfde. Daarom kunt u de methoden gebruiken get_instructions en build_llama2_prompt voor gevolgtrekking.
De get_instructions methode retourneert de instructies. Bouw de instructies samen met de uit te voeren taak, zoals beschreven in user_ask_2 als volgt:
Geef de instructies door om de prompt te bouwen volgens de promptsjabloon die is gegenereerd door build_llama2_prompt:
We combineren de gevolgtrekkingsparameters samen met de prompt om een uiteindelijke payload te vormen. Vervolgens stuur je de lading naar get_realtime_response_stream, die wordt gebruikt om een eindpunt aan te roepen met antwoordstreaming:
De gegenereerde tekst van de LLM wordt naar de uitvoer gestreamd, zoals weergegeven in de volgende animatie.

Opruimen
Om te voorkomen dat er onnodige kosten in rekening worden gebracht, kunt u gebruik maken van de AWS-beheerconsole om de eindpunten en de bijbehorende bronnen te verwijderen die zijn gemaakt tijdens het uitvoeren van de benaderingen die in het bericht worden genoemd. Voer voor beide implementatiebenaderingen de volgende opschoonroutine uit:
vervangen <SageMaker_Real-time_Endpoint_Name> voor variabele endpoint_name met het werkelijke eindpunt.
Voor de tweede benadering hebben we het model en de codeartefacten opgeslagen op Amazon S3. U kunt de S3-bucket opruimen met de volgende code:
Conclusie
In dit bericht hebben we besproken hoe een variërend aantal responstokens of een andere set inferentieparameters de latenties kunnen beïnvloeden die aan LLM's zijn gekoppeld. We lieten zien hoe je het probleem kunt aanpakken met behulp van responsstreaming. Vervolgens hebben we twee benaderingen geïdentificeerd voor het inzetten en afleiden van Llama 2 Chat-modellen met behulp van AWS DLC's: LMI en Hugging Face TGI.
U zou nu het belang van streamingrespons moeten begrijpen en hoe deze de waargenomen latentie kan verminderen. Het streamen van reacties kan de gebruikerservaring verbeteren, waardoor u anders zou moeten wachten totdat de LLM de hele reactie heeft opgebouwd. Bovendien verbetert de inzet van Llama 2 Chat-modellen met responsstreaming de gebruikerservaring en maakt uw klanten blij.
U kunt de officiële aws-voorbeelden raadplegen amazon-sagemaker-llama2-response-streaming-recepten dat omvat de inzet voor andere Llama 2-modelvarianten.
Referenties
Over de auteurs
 Pavan Kumar Rao Navule is oplossingsarchitect bij Amazon Web Services. Hij werkt samen met ISV's in India om hen te helpen innoveren op AWS. Hij is een gepubliceerde auteur van het boek 'Getting Started with V Programming'. Hij volgde een Executive M.Tech in Data Science aan het Indian Institute of Technology (IIT), Hyderabad. Hij volgde ook een Executive MBA in IT-specialisatie aan de Indian School of Business Management and Administration, en behaalde een B.Tech in Electronics and Communication Engineering aan het Vaagdevi Institute of Technology and Science. Pavan is een AWS Certified Solutions Architect Professional en beschikt over andere certificeringen zoals AWS Certified Machine Learning Specialty, Microsoft Certified Professional (MCP) en Microsoft Certified Technology Specialist (MCTS). Hij is ook een open source-liefhebber. In zijn vrije tijd luistert hij graag naar de grote magische stemmen van Sia en Rihanna.
Pavan Kumar Rao Navule is oplossingsarchitect bij Amazon Web Services. Hij werkt samen met ISV's in India om hen te helpen innoveren op AWS. Hij is een gepubliceerde auteur van het boek 'Getting Started with V Programming'. Hij volgde een Executive M.Tech in Data Science aan het Indian Institute of Technology (IIT), Hyderabad. Hij volgde ook een Executive MBA in IT-specialisatie aan de Indian School of Business Management and Administration, en behaalde een B.Tech in Electronics and Communication Engineering aan het Vaagdevi Institute of Technology and Science. Pavan is een AWS Certified Solutions Architect Professional en beschikt over andere certificeringen zoals AWS Certified Machine Learning Specialty, Microsoft Certified Professional (MCP) en Microsoft Certified Technology Specialist (MCTS). Hij is ook een open source-liefhebber. In zijn vrije tijd luistert hij graag naar de grote magische stemmen van Sia en Rihanna.
 Sudhanshu-haat is de belangrijkste AI/ML-specialist bij AWS en werkt samen met klanten om hen te adviseren over hun MLOps en generatieve AI-reis. In zijn vorige rol bij Amazon bedacht, creëerde en leidde hij teams om vanaf de grond op open source gebaseerde AI- en gamificatieplatforms te bouwen, en deze met succes op de markt te brengen bij meer dan 100 klanten. Sudhanshu heeft een aantal patenten op zijn naam staan, heeft twee boeken en verschillende artikelen en blogs geschreven, en heeft zijn standpunten op verschillende technische fora gepresenteerd. Hij is een thought leader en spreker en is al bijna 25 jaar actief in de branche. Hij heeft met Fortune 1000-klanten over de hele wereld gewerkt en meest recentelijk met digital native-klanten in India.
Sudhanshu-haat is de belangrijkste AI/ML-specialist bij AWS en werkt samen met klanten om hen te adviseren over hun MLOps en generatieve AI-reis. In zijn vorige rol bij Amazon bedacht, creëerde en leidde hij teams om vanaf de grond op open source gebaseerde AI- en gamificatieplatforms te bouwen, en deze met succes op de markt te brengen bij meer dan 100 klanten. Sudhanshu heeft een aantal patenten op zijn naam staan, heeft twee boeken en verschillende artikelen en blogs geschreven, en heeft zijn standpunten op verschillende technische fora gepresenteerd. Hij is een thought leader en spreker en is al bijna 25 jaar actief in de branche. Hij heeft met Fortune 1000-klanten over de hele wereld gewerkt en meest recentelijk met digital native-klanten in India.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/inference-llama-2-models-with-real-time-response-streaming-using-amazon-sagemaker/

