Georuimtelijke gegevens zijn gegevens over specifieke locaties op het aardoppervlak. Het kan een geografisch gebied als geheel vertegenwoordigen, of het kan een gebeurtenis vertegenwoordigen die verband houdt met een geografisch gebied. In een aantal bedrijfstakken is analyse van georuimtelijke gegevens gewild. Het gaat om het begrijpen waar de gegevens zich bevinden vanuit een ruimtelijk perspectief en waarom ze daar bestaan.
Er zijn twee soorten georuimtelijke gegevens: vectorgegevens en rastergegevens. Rastergegevens zijn een matrix van cellen die worden weergegeven als een raster en die meestal foto's en satellietbeelden vertegenwoordigen. In dit bericht concentreren we ons op vectorgegevens, die worden weergegeven als geografische coördinaten van lengte- en breedtegraad, evenals lijnen en polygonen (gebieden) die deze verbinden of omvatten. Vectordata kent een groot aantal gebruiksscenario's bij het afleiden van mobiliteitsinzichten. Mobiele data van gebruikers zijn daar zo'n onderdeel van, en worden grotendeels afgeleid van de geografische positie van mobiele apparaten die GPS gebruiken of van app-uitgevers die SDK's of soortgelijke integraties gebruiken. Voor de doeleinden van dit bericht verwijzen we naar deze gegevens als mobiliteitsgegevens.
Dit is een tweedelige serie. In dit eerste bericht introduceren we mobiliteitsgegevens, de bronnen ervan en een typisch schema van deze gegevens. Vervolgens bespreken we de verschillende gebruiksscenario's en onderzoeken we hoe u AWS-services kunt gebruiken om de gegevens op te schonen, hoe machine learning (ML) hierbij kan helpen en hoe u ethisch gebruik kunt maken van de gegevens bij het genereren van visuals en inzichten. Het tweede bericht zal meer technisch van aard zijn en deze stappen in detail behandelen naast de voorbeeldcode. Dit bericht bevat geen voorbeelddataset of voorbeeldcode, maar behandelt hoe u de gegevens kunt gebruiken nadat deze zijn gekocht bij een gegevensaggregator.
Je kunt gebruiken Amazon SageMaker georuimtelijke mogelijkheden om mobiliteitsgegevens op een basiskaart te leggen en gelaagde visualisatie te bieden om samenwerking eenvoudiger te maken. De GPU-aangedreven interactieve visualisator en Python-notebooks bieden een naadloze manier om miljoenen datapunten in één venster te verkennen en inzichten en resultaten te delen.
Bronnen en schema
Er zijn weinig bronnen van mobiliteitsgegevens. Naast GPS-pings en app-uitgevers worden andere bronnen gebruikt om de dataset uit te breiden, zoals Wi-Fi-toegangspunten, biedstroomgegevens verkregen via het weergeven van advertenties op mobiele apparaten, en specifieke hardwarezenders die door bedrijven worden geplaatst (bijvoorbeeld in fysieke winkels ). Het is vaak moeilijk voor bedrijven om deze gegevens zelf te verzamelen, dus kunnen ze deze kopen bij data-aggregators. Data-aggregators verzamelen mobiliteitsgegevens uit verschillende bronnen, zuiveren deze, voegen ruis toe en maken de gegevens dagelijks beschikbaar voor specifieke geografische regio's. Vanwege de aard van de gegevens zelf en omdat deze moeilijk te verkrijgen zijn, kan de nauwkeurigheid en kwaliteit van deze gegevens aanzienlijk variëren. Het is aan de bedrijven om dit te beoordelen en te verifiëren door gebruik te maken van statistieken zoals dagelijks actieve gebruikers, totale dagelijkse pings, en gemiddelde dagelijkse pings per apparaat. De volgende tabel laat zien hoe een typisch schema van een dagelijkse datafeed die door gegevensaggregators wordt verzonden, eruit kan zien.
| Kenmerk | Omschrijving |
| Identiteitskaart of MEID | Mobile Advertising ID (MAID) van het apparaat (gehasht) |
| lat | Breedtegraad van het apparaat |
| lng | Lengtegraad van het apparaat |
| gehash | Geohash-locatie van het apparaat |
| soort apparaat | Besturingssysteem van het apparaat = IDFA of GAID |
| horizontale_nauwkeurigheid | Nauwkeurigheid van horizontale GPS-coördinaten (in meters) |
| tijdstempel | Tijdstempel van de gebeurtenis |
| ip | IP-adres |
| alt | Hoogte van het apparaat (in meters) |
| snelheid | Snelheid van het apparaat (in meter/seconde) |
| Land | ISO tweecijferige code voor het land van herkomst |
| staat | Codes die de staat vertegenwoordigen |
| stadsappartementen | Codes die de stad vertegenwoordigen |
| postcode | Postcode van waar apparaat-ID wordt gezien |
| carrier | Vervoerder van het apparaat |
| apparaat_fabrikant | Fabrikant van het apparaat |
Use cases
Mobiliteitsgegevens hebben wijdverbreide toepassingen in uiteenlopende sectoren. Hieronder volgen enkele van de meest voorkomende gebruiksscenario's:
- Dichtheidsstatistieken – Voetverkeersanalyse kan worden gecombineerd met bevolkingsdichtheid om activiteiten en bezoeken aan nuttige plaatsen (POI's) te observeren. Deze statistieken geven een beeld van hoeveel apparaten of gebruikers actief stoppen en interactie hebben met een bedrijf, wat verder kan worden gebruikt voor locatieselectie of zelfs voor het analyseren van bewegingspatronen rond een evenement (bijvoorbeeld mensen die op reis zijn voor een speldag). Om dergelijke inzichten te verkrijgen, doorlopen de binnenkomende onbewerkte gegevens een extractie-, transformatie- en laadproces (ETL) om activiteiten of opdrachten te identificeren uit de continue stroom apparaatlocatiepings. We kunnen activiteiten analyseren door stops van de gebruiker of het mobiele apparaat te identificeren door pings te clusteren met behulp van ML-modellen Amazon Sage Maker.
- Reizen en trajecten – De dagelijkse locatiefeed van een apparaat kan worden uitgedrukt als een verzameling activiteiten (stops) en ritten (beweging). Een paar activiteiten kunnen een reis tussen hen vertegenwoordigen, en het volgen van de reis door het bewegende apparaat in de geografische ruimte kan leiden tot het in kaart brengen van het daadwerkelijke traject. Trajectpatronen van gebruikersbewegingen kunnen tot interessante inzichten leiden, zoals verkeerspatronen, brandstofverbruik, stadsplanning en meer. Het kan ook gegevens leveren om de route vanaf reclamepunten zoals een reclamebord te analyseren, de meest efficiënte bezorgroutes te identificeren om de supply chain-operaties te optimaliseren, of evacuatieroutes te analyseren bij natuurrampen (bijvoorbeeld evacuatie door orkanen).
- Analyse van het stroomgebied - A verzorgingsgebied verwijst naar plaatsen van waaruit een bepaald gebied bezoekers trekt, die klanten of potentiële klanten kunnen zijn. Detailhandelsbedrijven kunnen deze informatie gebruiken om de optimale locatie te bepalen om een nieuwe winkel te openen, of om te bepalen of twee winkellocaties te dicht bij elkaar liggen met overlappende verzorgingsgebieden en elkaars activiteiten belemmeren. Ze kunnen ook achterhalen waar de daadwerkelijke klanten vandaan komen, potentiële klanten identificeren die langs het gebied komen op weg naar hun werk of naar huis, vergelijkbare bezoekstatistieken voor concurrenten analyseren, en meer. Marketing Tech (MarTech) en Advertising Tech (AdTech) bedrijven kunnen deze analyse ook gebruiken om marketingcampagnes te optimaliseren door het publiek in de buurt van de winkel van een merk te identificeren of winkels te rangschikken op basis van prestaties voor buitenshuis adverteren.
Er zijn verschillende andere gebruiksscenario's, waaronder het genereren van locatie-informatie voor commercieel onroerend goed, het aanvullen van satellietbeelden met bezoekersaantallen, het identificeren van bezorghubs voor restaurants, het bepalen van de waarschijnlijkheid van buurtevacuatie, het ontdekken van bewegingspatronen van mensen tijdens een pandemie, en meer.
Uitdagingen en ethisch gebruik
Ethisch gebruik van mobiliteitsgegevens kan tot veel interessante inzichten leiden die organisaties kunnen helpen hun activiteiten te verbeteren, effectieve marketing uit te voeren of zelfs een concurrentievoordeel te behalen. Om deze gegevens ethisch te gebruiken, moeten verschillende stappen worden gevolgd.
Het begint met het verzamelen van gegevens zelf. Hoewel de meeste mobiliteitsgegevens vrij blijven van persoonlijk identificeerbare informatie (PII), zoals naam en adres, moeten gegevensverzamelaars en -aggregators toestemming van de gebruiker hebben om hun gegevens te verzamelen, gebruiken, opslaan en delen. Wetten op het gebied van gegevensprivacy, zoals GDPR en CCPA, moeten worden nageleefd, omdat ze gebruikers in staat stellen te bepalen hoe bedrijven hun gegevens kunnen gebruiken. Deze eerste stap is een substantiële stap in de richting van ethisch en verantwoord gebruik van mobiliteitsgegevens, maar er kan meer worden gedaan.
Aan elk apparaat wordt een gehashte Mobile Advertising ID (MAID) toegewezen, die wordt gebruikt om de individuele pings te verankeren. Dit kan verder worden verdoezeld door gebruik te maken van Amazone Macie, Amazon S3 Object Lambda, Amazon begrijpt het, of zelfs de AWS Lijm Studio PII-transformatie detecteren. Voor meer informatie, zie Algemene technieken om PHI- en PII-gegevens te detecteren met behulp van AWS Services.
Afgezien van PII moeten er overwegingen worden gemaakt om de thuislocatie van de gebruiker te maskeren, evenals andere gevoelige locaties zoals militaire bases of gebedshuizen.
De laatste stap voor ethisch gebruik is het afleiden en exporteren van alleen geaggregeerde statistieken uit Amazon SageMaker. Dit betekent dat je statistieken moet verzamelen zoals het gemiddelde aantal of het totale aantal bezoekers, in tegenstelling tot individuele reispatronen; dagelijkse, wekelijkse, maandelijkse of jaarlijkse trends verkrijgen; of het indexeren van mobiliteitspatronen op basis van openbaar beschikbare gegevens zoals censusgegevens.
Overzicht oplossingen
Zoals eerder vermeld, zijn de AWS-services die u kunt gebruiken voor de analyse van mobiliteitsgegevens de geospatiale mogelijkheden van Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend en Amazon SageMaker. De georuimtelijke mogelijkheden van Amazon SageMaker maken het voor datawetenschappers en ML-ingenieurs gemakkelijk om modellen te bouwen, trainen en implementeren met behulp van georuimtelijke gegevens. U kunt grootschalige georuimtelijke datasets efficiënt transformeren of verrijken, de modelbouw versnellen met vooraf getrainde ML-modellen, en modelvoorspellingen en georuimtelijke gegevens verkennen op een interactieve kaart met behulp van versnelde 3D-afbeeldingen en ingebouwde visualisatietools.
De volgende referentiearchitectuur toont een workflow waarbij gebruik wordt gemaakt van ML met georuimtelijke gegevens.
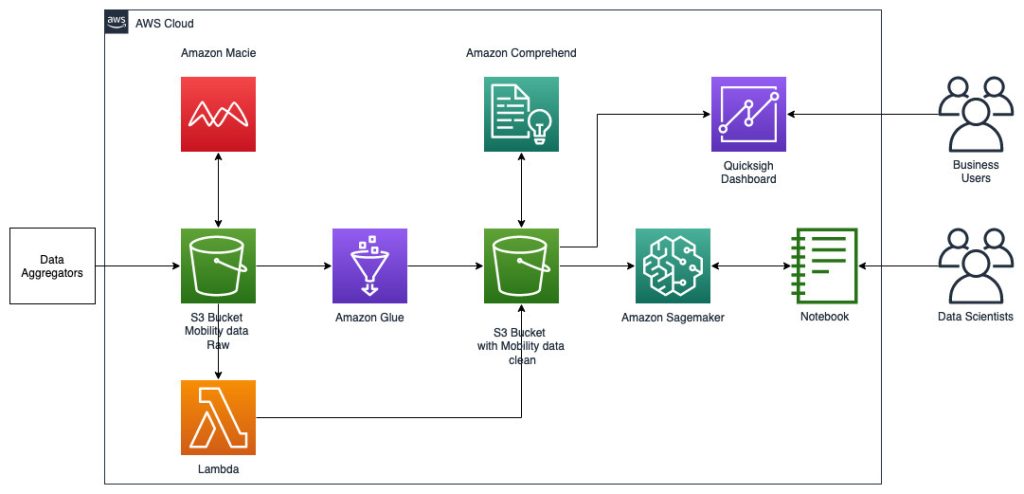
In deze workflow worden ruwe gegevens uit verschillende gegevensbronnen samengevoegd en opgeslagen in een Amazon eenvoudige opslagservice (S3) emmer. Amazon Macie wordt op deze S3-bucket gebruikt om PII te identificeren en te redigeren. AWS Glue wordt vervolgens gebruikt om de onbewerkte gegevens op te schonen en te transformeren naar het vereiste formaat, waarna de gewijzigde en opgeschoonde gegevens worden opgeslagen in een aparte S3-bucket. Voor die datatransformaties die niet via AWS Glue mogelijk zijn, gebruik je AWS Lambda om de onbewerkte gegevens te wijzigen en op te schonen. Wanneer de gegevens zijn opgeschoond, kunt u Amazon SageMaker gebruiken om ML-modellen te bouwen, trainen en implementeren op de voorbereide georuimtelijke gegevens. Je kunt ook gebruik maken van de georuimtelijke verwerkingstaken functie van de geospatiale mogelijkheden van Amazon SageMaker om de gegevens voor te verwerken, bijvoorbeeld door een Python-functie en SQL-instructies te gebruiken om activiteiten uit de onbewerkte mobiliteitsgegevens te identificeren. Datawetenschappers kunnen dit proces voltooien door verbinding te maken via Amazon SageMaker-notebooks. Je kan ook gebruiken Amazon QuickSight om bedrijfsresultaten en andere belangrijke statistieken uit de gegevens te visualiseren.
Geospatiale mogelijkheden en geospatiale verwerkingstaken van Amazon SageMaker
Nadat de gegevens zijn verkregen en met een dagelijkse feed in Amazon S3 zijn ingevoerd en zijn opgeschoond van eventuele gevoelige gegevens, kunnen deze in Amazon SageMaker worden geïmporteerd met behulp van een Amazon SageMaker Studio notitieboekje met een georuimtelijk beeld. De volgende schermafbeelding toont een voorbeeld van dagelijkse apparaatpings die als CSV-bestand naar Amazon S3 zijn geüpload en vervolgens in een panda-dataframe zijn geladen. De Amazon SageMaker Studio-notebook met georuimtelijke afbeelding wordt vooraf geladen met georuimtelijke bibliotheken zoals GDAL, GeoPandas, Fiona en Shapely, en maakt het eenvoudig om deze gegevens te verwerken en te analyseren.
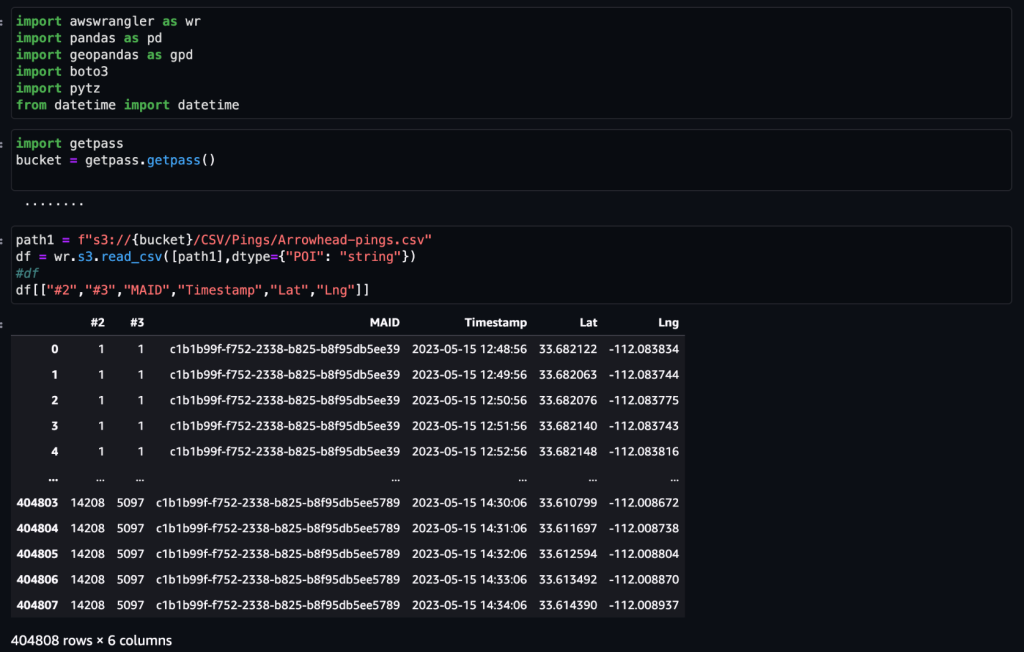
Deze voorbeelddataset bevat ongeveer 400,000 dagelijkse apparaatpings vanaf 5,000 apparaten vanaf 14,000 unieke plaatsen, geregistreerd door gebruikers die de Arrowhead Mall bezochten, een populair winkelcentrumcomplex in Phoenix, Arizona, op 15 mei 2023. De voorgaande schermafbeelding toont een subset van kolommen in de gegevensschema. De MAID kolom vertegenwoordigt de apparaat-ID, en elke MAID genereert elke minuut pings die de breedte- en lengtegraad van het apparaat doorgeven, vastgelegd in het voorbeeldbestand als Lat en Lng kolommen.
Hieronder volgen schermafbeeldingen van de kaartvisualisatietool van de geospatiale mogelijkheden van Amazon SageMaker, mogelijk gemaakt door Foursquare Studio, die de lay-out weergeven van pings van apparaten die het winkelcentrum bezoeken tussen 7 uur en 00 uur.
De volgende schermafbeelding toont pings uit het winkelcentrum en de omliggende gebieden.

Hieronder ziet u pings vanuit verschillende winkels in het winkelcentrum.
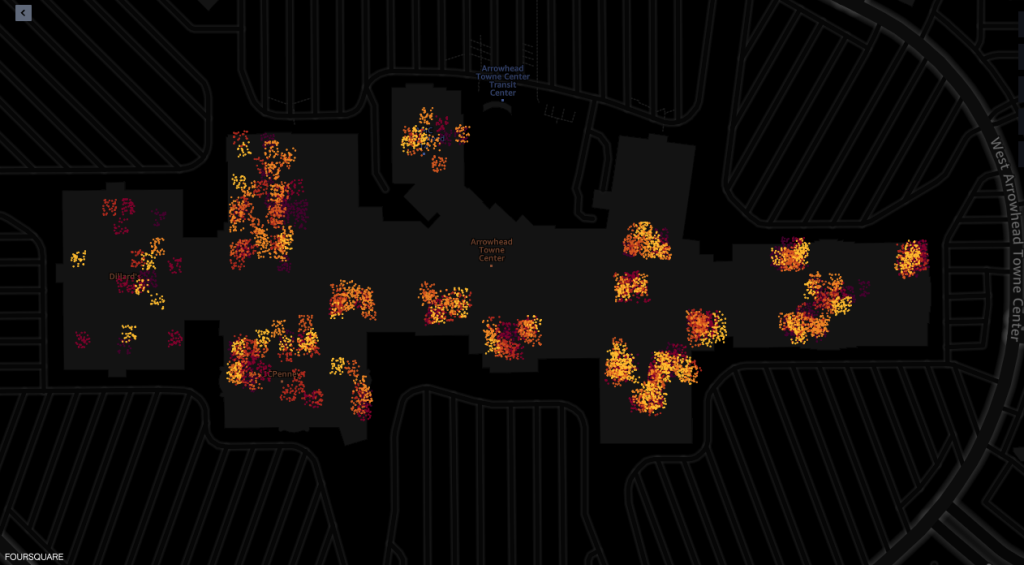
Elke stip in de schermafbeeldingen geeft een ping weer van een bepaald apparaat op een bepaald tijdstip. Een cluster van pings vertegenwoordigt populaire plekken waar apparaten zich verzamelen of stoppen, zoals winkels of restaurants.
Als onderdeel van de initiële ETL kunnen deze onbewerkte gegevens met AWS Glue in tabellen worden geladen. U kunt een AWS Glue-crawler maken om het schema van de gegevens te identificeren en tabellen te vormen door naar de onbewerkte gegevenslocatie in Amazon S3 als gegevensbron te verwijzen.

Zoals hierboven vermeld, vertegenwoordigen de onbewerkte gegevens (de dagelijkse apparaatpings), zelfs na de initiële ETL, een continue stroom GPS-pings die de apparaatlocaties aangeven. Om bruikbare inzichten uit deze gegevens te halen, moeten we stops en trips (trajecten) identificeren. Dit kan worden bereikt met behulp van de georuimtelijke verwerkingstaken kenmerk van de geospatiale mogelijkheden van SageMaker. Amazon SageMaker-verwerking maakt gebruik van een vereenvoudigde, beheerde ervaring op SageMaker om werklasten voor gegevensverwerking uit te voeren met de speciaal gebouwde georuimtelijke container. De onderliggende infrastructuur voor een SageMaker Processing-taak wordt volledig beheerd door SageMaker. Met deze functie kan aangepaste code worden uitgevoerd op georuimtelijke gegevens die zijn opgeslagen op Amazon S3 door een georuimtelijke ML-container uit te voeren op een SageMaker Processing-taak. U kunt aangepaste bewerkingen uitvoeren op open of privé georuimtelijke gegevens door aangepaste code te schrijven met open source-bibliotheken, en de bewerking op schaal uitvoeren met behulp van SageMaker Processing-taken. De containergebaseerde aanpak komt tegemoet aan de behoeften rond standaardisatie van de ontwikkelomgeving met veelgebruikte open source-bibliotheken.
Om dergelijke grootschalige workloads uit te voeren, hebt u een flexibel rekencluster nodig dat kan worden opgeschaald van tientallen exemplaren om een stadsblok te verwerken, tot duizenden exemplaren voor verwerking op planetaire schaal. Het handmatig beheren van een doe-het-zelf-computercluster is traag en duur. Deze functie is met name handig wanneer de mobiliteitsdataset meer dan een paar steden tot meerdere staten of zelfs landen omvat en kan worden gebruikt om een ML-aanpak in twee stappen uit te voeren.
De eerste stap is het gebruik van op dichtheid gebaseerde ruimtelijke clustering van applicaties met ruisalgoritme (DBSCAN) om stops van pings te clusteren. De volgende stap is het gebruik van de Support Vector Machines (SVM's)-methode om de nauwkeurigheid van de geïdentificeerde stops verder te verbeteren en ook om stops met afspraken met een POI te onderscheiden van stops zonder een POI (zoals thuis of op het werk). U kunt de SageMaker Processing-taak ook gebruiken om ritten en trajecten te genereren op basis van de dagelijkse apparaatpingen door opeenvolgende stops te identificeren en het pad tussen de bron- en bestemmingsstops in kaart te brengen.
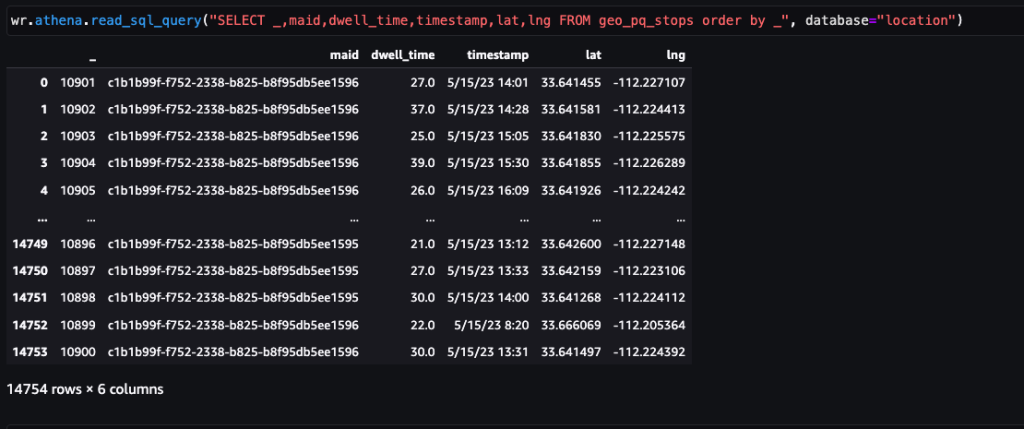
Na het op schaal verwerken van de onbewerkte gegevens (dagelijkse apparaatpings) met georuimtelijke verwerkingstaken, moet de nieuwe gegevensset met de naam stops het volgende schema hebben.
| Kenmerk | Omschrijving |
| Identiteitskaart of MEID | Mobiele advertentie-ID van het apparaat (gehasht) |
| lat | Breedtegraad van het zwaartepunt van het stopcluster |
| lng | Lengtegraad van het zwaartepunt van de stopcluster |
| gehash | Geohash-locatie van de POI |
| soort apparaat | Besturingssysteem van het apparaat (IDFA of GAID) |
| tijdstempel | Begintijd van de halte |
| verblijftijd | Verblijftijd van de stop (in seconden) |
| ip | IP-adres |
| alt | Hoogte van het apparaat (in meters) |
| Land | ISO tweecijferige code voor het land van herkomst |
| staat | Codes die de staat vertegenwoordigen |
| stadsappartementen | Codes die de stad vertegenwoordigen |
| postcode | Postcode van waar de apparaat-ID wordt gezien |
| carrier | Vervoerder van het apparaat |
| apparaat_fabrikant | Fabrikant van het apparaat |
Stops worden geconsolideerd door de pings per apparaat te clusteren. Op dichtheid gebaseerde clustering wordt gecombineerd met parameters zoals de stopdrempel van 300 seconden en de minimale afstand tussen stops van 50 meter. Deze parameters kunnen worden aangepast volgens uw gebruiksscenario.
De volgende schermafbeelding toont ongeveer 15,000 stops die zijn geïdentificeerd op basis van 400,000 pings. Er is ook een subset van het voorgaande schema aanwezig, waarbij de column Dwell Time vertegenwoordigt de stopduur, en de Lat en Lng kolommen vertegenwoordigen de breedte- en lengtegraad van de zwaartepunten van de haltescluster per apparaat per locatie.
Na ETL worden gegevens opgeslagen in de Parquet-bestandsindeling, een kolomvormige opslagindeling waarmee het eenvoudiger wordt om grote hoeveelheden gegevens te verwerken.
De volgende schermafbeelding toont de stops geconsolideerd op basis van pings per apparaat in het winkelcentrum en de omliggende gebieden.

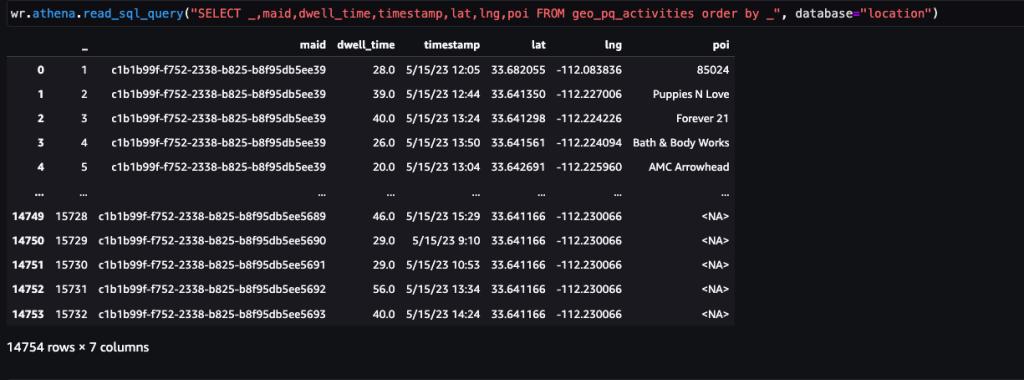
Na het identificeren van stops kan deze dataset worden samengevoegd met openbaar beschikbare POI-gegevens of aangepaste POI-gegevens die specifiek zijn voor het gebruiksscenario om activiteiten te identificeren, zoals betrokkenheid bij merken.
De volgende schermafbeelding toont de haltes die zijn geïdentificeerd bij de belangrijkste POI's (winkels en merken) in de Arrowhead Mall.
Er zijn postcodes voor thuisgebruik gebruikt om de thuislocatie van elke bezoeker te maskeren om de privacy te behouden voor het geval dat deel uitmaakt van hun reis in de dataset. De breedte- en lengtegraad zijn in dergelijke gevallen de respectievelijke coördinaten van het zwaartepunt van de postcode.
De volgende schermafbeelding is een visuele weergave van dergelijke activiteiten. De linkerafbeelding brengt de haltes naar de winkels in kaart en de rechterafbeelding geeft een idee van de indeling van het winkelcentrum zelf.

Deze resulterende dataset kan op een aantal manieren worden gevisualiseerd, die we in de volgende paragrafen bespreken.
Dichtheidsstatistieken
Wij kunnen de dichtheid aan activiteiten en bezoeken berekenen en visualiseren.
Voorbeeld 1 – De volgende schermafbeelding toont de 15 best bezochte winkels in het winkelcentrum.

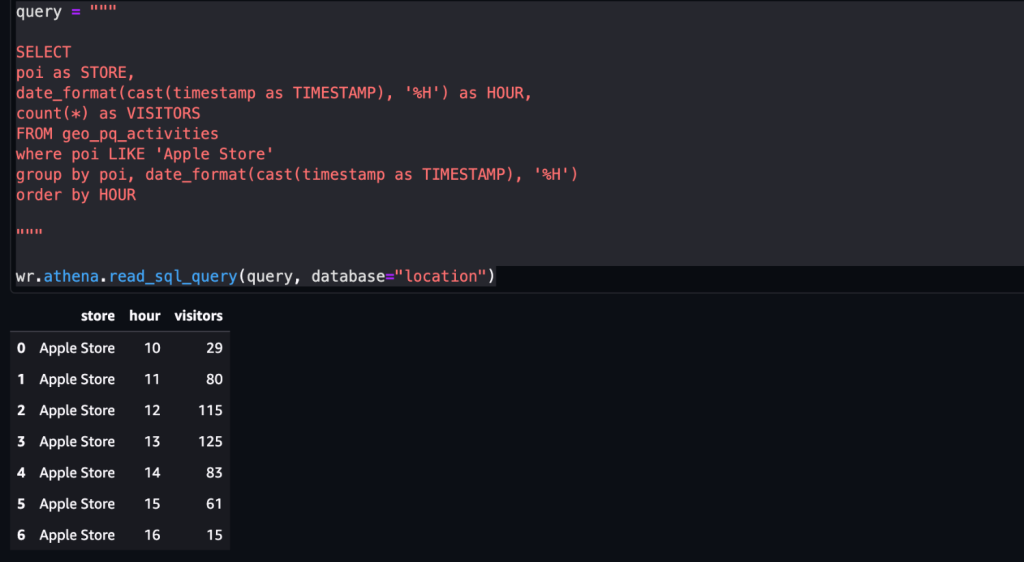
Voorbeeld 2 – De volgende schermafbeelding toont het aantal bezoeken aan de Apple Store per uur.
Reizen en trajecten
Zoals eerder vermeld vertegenwoordigt een paar opeenvolgende activiteiten een reis. We kunnen de volgende aanpak gebruiken om ritten af te leiden uit de activiteitengegevens. Hier worden vensterfuncties met SQL gebruikt om de trips tabel, zoals weergegeven in de schermafbeelding.
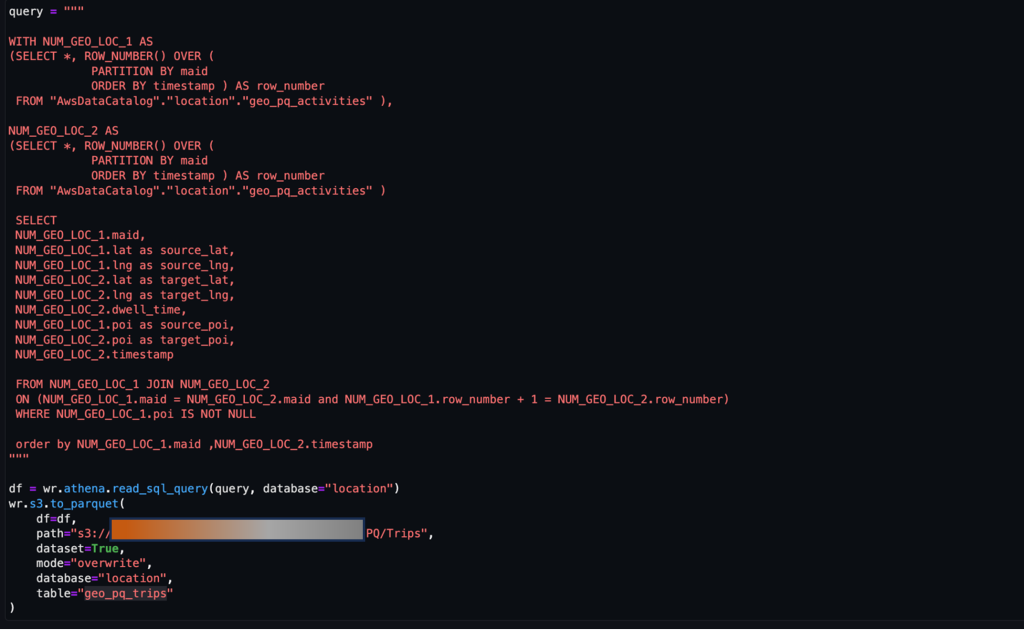
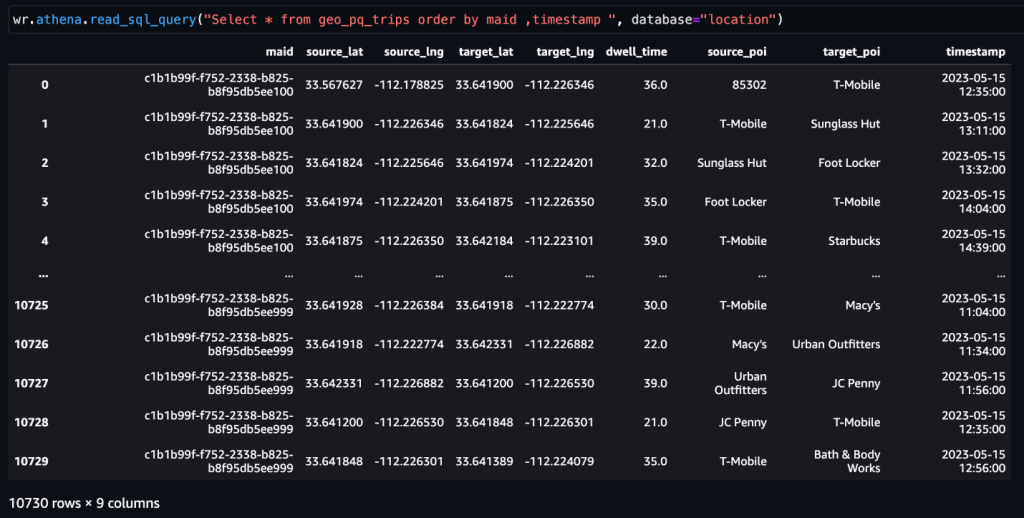
Na het trips tabel wordt gegenereerd, kunnen ritten naar een POI worden bepaald.
Voorbeeld 1 – De volgende schermafbeelding toont de top 10 winkels die voetgangers naar de Apple Store leiden.

Voorbeeld 2 – De volgende schermafbeelding toont alle uitstapjes naar de Arrowhead Mall.

Voorbeeld 3 – De volgende video toont de bewegingspatronen in het winkelcentrum.

Voorbeeld 4 – De volgende video toont de bewegingspatronen buiten het winkelcentrum.
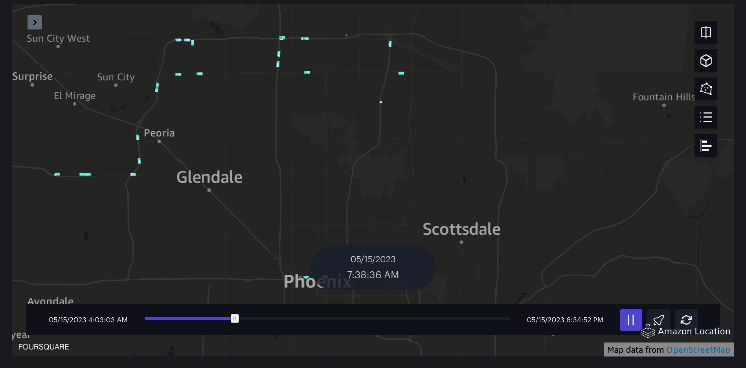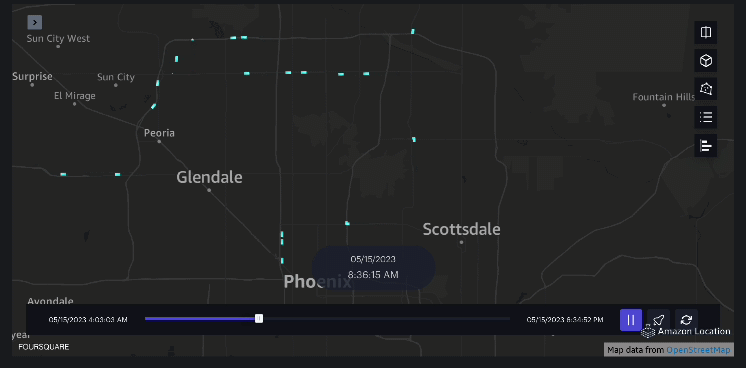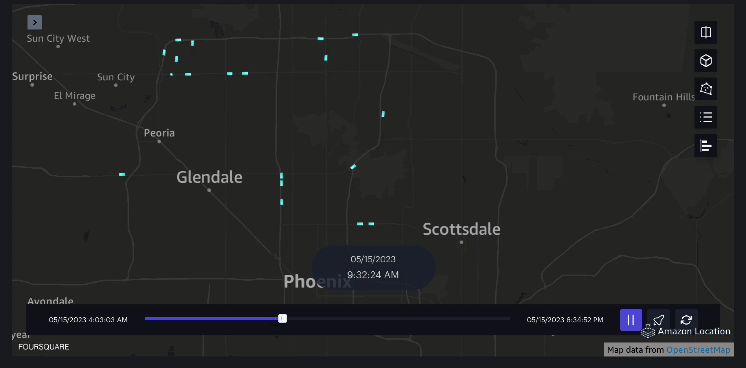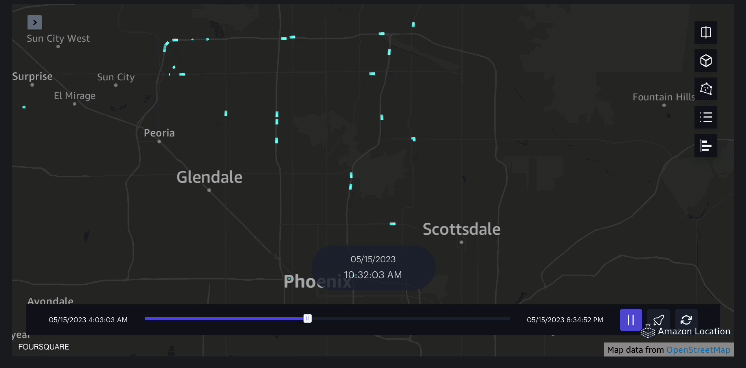
Analyse van het stroomgebied
We kunnen alle bezoeken aan een POI analyseren en het verzorgingsgebied bepalen.
Voorbeeld 1 – De volgende schermafbeelding toont alle bezoeken aan de Macy's-winkel.
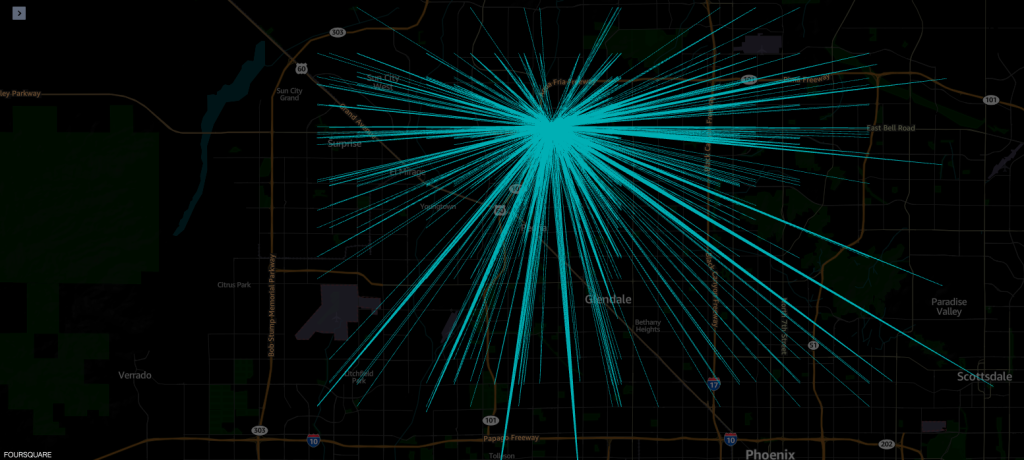
Voorbeeld 2 – De volgende schermafbeelding toont de top 10 postcodes van het thuisgebied (grenzen gemarkeerd) van waaruit de bezoeken plaatsvonden.
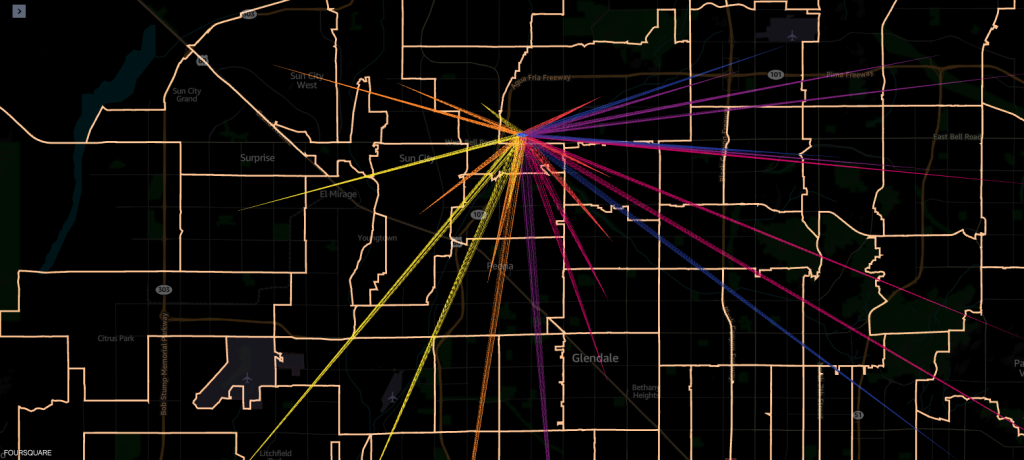
Controle van de gegevenskwaliteit
Met behulp van QuickSight-dashboards en data-analyses kunnen we de dagelijks binnenkomende datafeed controleren op kwaliteit en afwijkingen detecteren. De volgende schermafbeelding toont een voorbeelddashboard.
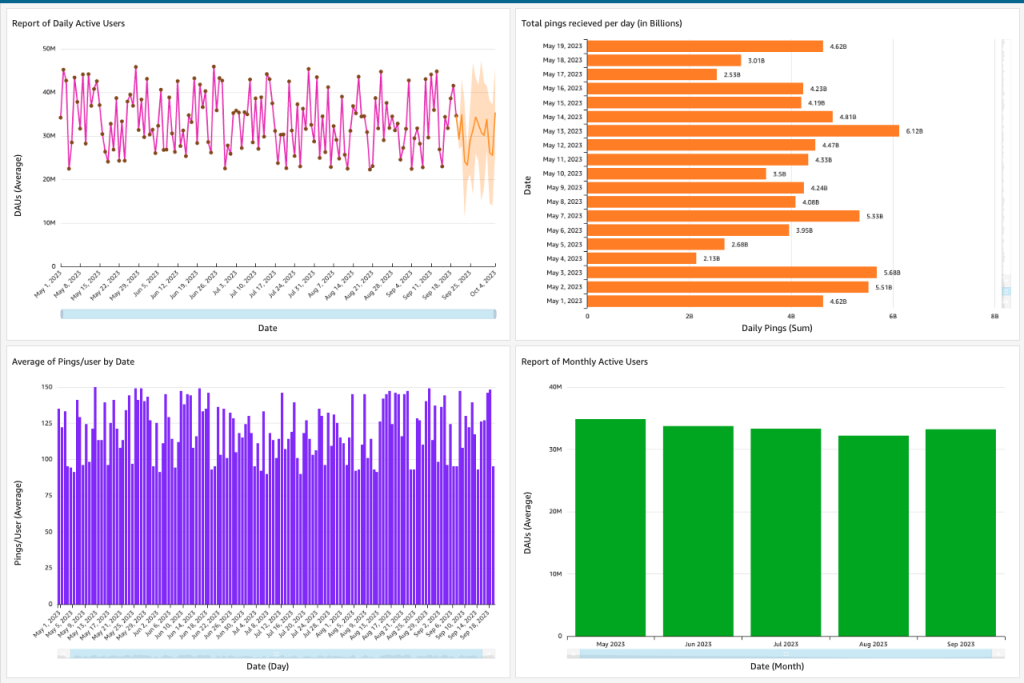
Conclusie
Mobiliteitsgegevens en de analyse ervan voor het verkrijgen van klantinzichten en het verkrijgen van concurrentievoordeel blijven een nichegebied omdat het moeilijk is om een consistente en nauwkeurige dataset te verkrijgen. Deze gegevens kunnen organisaties echter helpen context toe te voegen aan bestaande analyses en zelfs nieuwe inzichten te verschaffen over klantbewegingspatronen. De georuimtelijke mogelijkheden en georuimtelijke verwerkingstaken van Amazon SageMaker kunnen helpen deze gebruiksscenario's te implementeren en op een intuïtieve en toegankelijke manier inzichten te verkrijgen.
In dit bericht hebben we gedemonstreerd hoe we AWS-services kunnen gebruiken om de mobiliteitsgegevens op te schonen en vervolgens de geospatiale mogelijkheden van Amazon SageMaker kunnen gebruiken om afgeleide datasets zoals stops, activiteiten en reizen te genereren met behulp van ML-modellen. Vervolgens hebben we de afgeleide datasets gebruikt om bewegingspatronen te visualiseren en inzichten te genereren.
U kunt op twee manieren aan de slag met de geospatiale mogelijkheden van Amazon SageMaker:
Voor meer informatie, bezoek Amazon SageMaker georuimtelijke mogelijkheden en Aan de slag met georuimtelijke Amazon SageMaker. Bezoek ook onze GitHub repo, dat verschillende voorbeeldnotebooks heeft met geospatiale mogelijkheden van Amazon SageMaker.
Over de auteurs
 Jim Matthews is een AWS Solutions Architect, met expertise in AI/ML-technologie. Jimy is gevestigd in Boston en werkt met zakelijke klanten terwijl zij hun bedrijf transformeren door de cloud te adopteren en hen te helpen efficiënte en duurzame oplossingen te ontwikkelen. Hij is gepassioneerd door zijn familie, auto's en mixed martial arts.
Jim Matthews is een AWS Solutions Architect, met expertise in AI/ML-technologie. Jimy is gevestigd in Boston en werkt met zakelijke klanten terwijl zij hun bedrijf transformeren door de cloud te adopteren en hen te helpen efficiënte en duurzame oplossingen te ontwikkelen. Hij is gepassioneerd door zijn familie, auto's en mixed martial arts.
 Girish Keshav is een Solutions Architect bij AWS en helpt klanten bij hun cloudmigratietraject om workloads veilig en efficiënt te moderniseren en uit te voeren. Hij werkt samen met leiders van technologieteams om hen te begeleiden op het gebied van applicatiebeveiliging, machine learning, kostenoptimalisatie en duurzaamheid. Hij is gevestigd in San Francisco en houdt van reizen, wandelen, sport kijken en ambachtelijke brouwerijen ontdekken.
Girish Keshav is een Solutions Architect bij AWS en helpt klanten bij hun cloudmigratietraject om workloads veilig en efficiënt te moderniseren en uit te voeren. Hij werkt samen met leiders van technologieteams om hen te begeleiden op het gebied van applicatiebeveiliging, machine learning, kostenoptimalisatie en duurzaamheid. Hij is gevestigd in San Francisco en houdt van reizen, wandelen, sport kijken en ambachtelijke brouwerijen ontdekken.
 Ramesh-steiger is een senior leider van Solutions Architecture die zich richt op het helpen van zakelijke AWS-klanten om inkomsten te genereren met hun datamiddelen. Hij adviseert leidinggevenden en ingenieurs bij het ontwerpen en bouwen van zeer schaalbare, betrouwbare en kosteneffectieve cloudoplossingen, vooral gericht op machine learning, data en analytics. In zijn vrije tijd geniet hij van het buitenleven, fietsen en wandelen met zijn gezin.
Ramesh-steiger is een senior leider van Solutions Architecture die zich richt op het helpen van zakelijke AWS-klanten om inkomsten te genereren met hun datamiddelen. Hij adviseert leidinggevenden en ingenieurs bij het ontwerpen en bouwen van zeer schaalbare, betrouwbare en kosteneffectieve cloudoplossingen, vooral gericht op machine learning, data en analytics. In zijn vrije tijd geniet hij van het buitenleven, fietsen en wandelen met zijn gezin.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/use-mobility-data-to-derive-insights-using-amazon-sagemaker-geospatial-capabilities/

