Tegenwoordig gebruiken klanten uit alle sectoren – of het nu gaat om financiële dienstverlening, gezondheidszorg en biowetenschappen, reizen en horeca, media en entertainment, telecommunicatie, software as a service (SaaS) en zelfs propriëtaire modelaanbieders – grote taalmodellen (LLM's) om applicaties bouwen zoals vraag- en antwoordchatbots (QnA), zoekmachines en kennisbanken. Deze generatieve AI applicaties worden niet alleen gebruikt om bestaande bedrijfsprocessen te automatiseren, maar hebben ook de mogelijkheid om de ervaring voor klanten die deze applicaties gebruiken te transformeren. Met de vooruitgang die wordt geboekt met LLM's zoals de Mixtral-8x7B Instrueer, afgeleide van architecturen zoals de mix van experts (MoE)zijn klanten voortdurend op zoek naar manieren om de prestaties en nauwkeurigheid van generatieve AI-applicaties te verbeteren, terwijl ze tegelijkertijd een breder scala aan gesloten en open source-modellen effectief kunnen gebruiken.
Er wordt doorgaans een aantal technieken gebruikt om de nauwkeurigheid en prestaties van de output van een LLM te verbeteren, zoals het afstemmen met parameter efficiënte fijnafstemming (PEFT), versterking leren van menselijke feedback (RLHF), en optreden kennis distillatie. Wanneer u generatieve AI-toepassingen bouwt, kunt u echter een alternatieve oplossing gebruiken die de dynamische integratie van externe kennis mogelijk maakt en waarmee u controle kunt uitoefenen over de informatie die voor het genereren wordt gebruikt, zonder dat u uw bestaande basismodel hoeft te verfijnen. Dit is waar Retrieval Augmented Generation (RAG) om de hoek komt kijken, specifiek voor generatieve AI-toepassingen, in tegenstelling tot de duurdere en robuustere verfijningsalternatieven die we hebben besproken. Als u complexe RAG-toepassingen in uw dagelijkse taken implementeert, kunt u veelvoorkomende problemen met uw RAG-systemen tegenkomen, zoals onnauwkeurig ophalen, toenemende omvang en complexiteit van documenten en een overdaad aan context, die een aanzienlijke invloed kunnen hebben op de kwaliteit en betrouwbaarheid van de gegenereerde antwoorden. .
Dit bericht bespreekt RAG-patronen om de responsnauwkeurigheid te verbeteren met behulp van LangChain en tools zoals de parent document retriever, naast technieken zoals contextuele compressie om ontwikkelaars in staat te stellen bestaande generatieve AI-applicaties te verbeteren.
Overzicht oplossingen
In dit bericht demonstreren we het gebruik van Mixtral-8x7B Instruct-tekstgeneratie gecombineerd met het BGE Large En-inbeddingsmodel om efficiënt een RAG QnA-systeem te construeren op een Amazon SageMaker-notebook met behulp van de bovenliggende documentretrievertool en contextuele compressietechniek. Het volgende diagram illustreert de architectuur van deze oplossing.
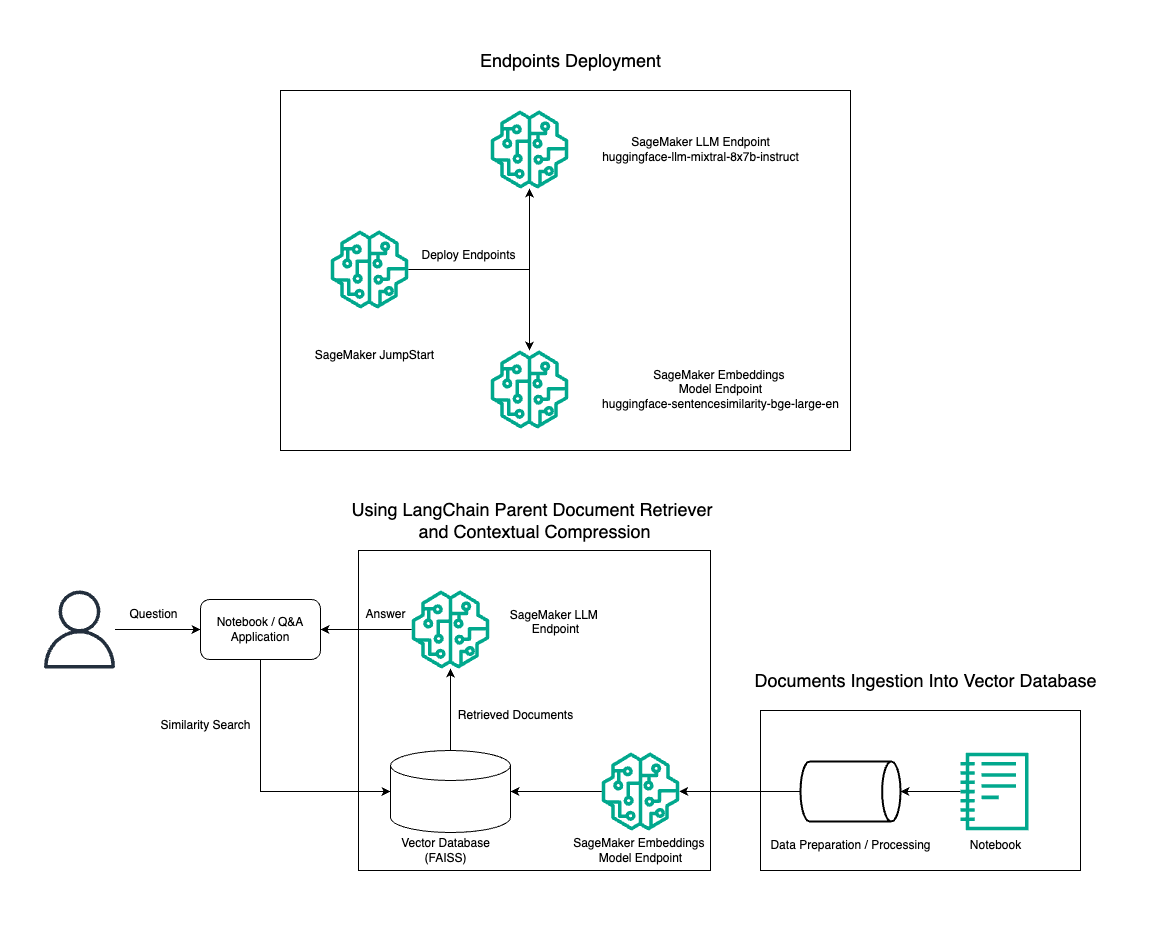
U kunt deze oplossing met slechts een paar klikken implementeren met behulp van Amazon SageMaker JumpStart, een volledig beheerd platform dat ultramoderne basismodellen biedt voor verschillende gebruiksscenario's, zoals het schrijven van inhoud, het genereren van code, het beantwoorden van vragen, copywriting, samenvattingen, classificatie en het ophalen van informatie. Het biedt een verzameling vooraf getrainde modellen die u snel en gemakkelijk kunt implementeren, waardoor de ontwikkeling en implementatie van machine learning-applicaties (ML) wordt versneld. Een van de belangrijkste componenten van SageMaker JumpStart is de Model Hub, die een uitgebreide catalogus van vooraf getrainde modellen biedt, zoals de Mixtral-8x7B, voor een verscheidenheid aan taken.
Mixtral-8x7B maakt gebruik van een MoE-architectuur. Dankzij deze architectuur kunnen verschillende delen van een neuraal netwerk zich specialiseren in verschillende taken, waardoor de werklast effectief over meerdere experts wordt verdeeld. Deze aanpak maakt de efficiënte training en inzet van grotere modellen mogelijk in vergelijking met traditionele architecturen.
Een van de belangrijkste voordelen van de MoE-architectuur is de schaalbaarheid ervan. Door de werklast over meerdere experts te verdelen, kunnen MoE-modellen worden getraind op grotere datasets en betere prestaties behalen dan traditionele modellen van dezelfde omvang. Bovendien kunnen MoE-modellen efficiënter zijn tijdens gevolgtrekkingen, omdat slechts een subset van experts hoeft te worden geactiveerd voor een bepaalde invoer.
Voor meer informatie over Mixtral-8x7B Instrueer over AWS, zie Mixtral-8x7B is nu beschikbaar in Amazon SageMaker JumpStart. Het Mixtral-8x7B-model wordt beschikbaar gesteld onder de tolerante Apache 2.0-licentie, voor gebruik zonder beperkingen.
In dit bericht bespreken we hoe u deze kunt gebruiken LangChain om effectieve en efficiëntere RAG-toepassingen te creëren. LangChain is een open source Python-bibliotheek die is ontworpen om applicaties met LLM's te bouwen. Het biedt een modulair en flexibel raamwerk voor het combineren van LLM's met andere componenten, zoals kennisbanken, ophaalsystemen en andere AI-tools, om krachtige en aanpasbare applicaties te creëren.
We doorlopen de aanleg van een RAG-pijpleiding op SageMaker met Mixtral-8x7B. We gebruiken het Mixtral-8x7B Instruct-tekstgeneratiemodel met het BGE Large En-inbeddingsmodel om een efficiënt QnA-systeem te creëren met behulp van RAG op een SageMaker-notebook. We gebruiken een ml.t3.medium-instantie om de implementatie van LLM's via SageMaker JumpStart te demonstreren, die toegankelijk is via een door SageMaker gegenereerd API-eindpunt. Deze opstelling maakt het verkennen, experimenteren en optimaliseren van geavanceerde RAG-technieken met LangChain mogelijk. We illustreren ook de integratie van de FAISS Embedding-winkel in de RAG-workflow, waarbij we de rol ervan benadrukken bij het opslaan en ophalen van inbedding om de prestaties van het systeem te verbeteren.
We voeren een korte walkthrough uit van het SageMaker-notebook. Voor meer gedetailleerde en stapsgewijze instructies raadpleegt u de Geavanceerde RAG-patronen met Mixtral op SageMaker Jumpstart GitHub-repository.
De behoefte aan geavanceerde RAG-patronen
Geavanceerde RAG-patronen zijn essentieel om de huidige mogelijkheden van LLM's op het gebied van het verwerken, begrijpen en genereren van mensachtige tekst te verbeteren. Naarmate de omvang en complexiteit van documenten toenemen, kan het weergeven van meerdere facetten van het document in één enkele inbedding leiden tot een verlies aan specificiteit. Hoewel het essentieel is om de algemene essentie van een document vast te leggen, is het net zo belangrijk om de verschillende subcontexten daarin te herkennen en weer te geven. Dit is een uitdaging waarmee u vaak wordt geconfronteerd als u met grotere documenten werkt. Een ander probleem met RAG is dat u bij het ophalen niet op de hoogte bent van de specifieke vragen die uw documentopslagsysteem bij opname zal afhandelen. Dit kan ertoe leiden dat informatie die het meest relevant is voor een zoekopdracht, onder tekst wordt begraven (contextoverflow). Om fouten te beperken en de bestaande RAG-architectuur te verbeteren, kunt u geavanceerde RAG-patronen (bovenliggende documentretriever en contextuele compressie) gebruiken om ophaalfouten te verminderen, de antwoordkwaliteit te verbeteren en complexe vraagafhandeling mogelijk te maken.
Met de technieken die in dit bericht worden besproken, kunt u de belangrijkste uitdagingen aanpakken die verband houden met het ophalen en integreren van externe kennis, waardoor uw toepassing nauwkeurigere en contextueel bewustere antwoorden kan leveren.
In de volgende secties onderzoeken we hoe ophaalprogramma's voor bovenliggende documenten en contextuele compressie kan u helpen bij het omgaan met enkele van de problemen die we hebben besproken.
Ophaalprogramma voor bovenliggende documenten
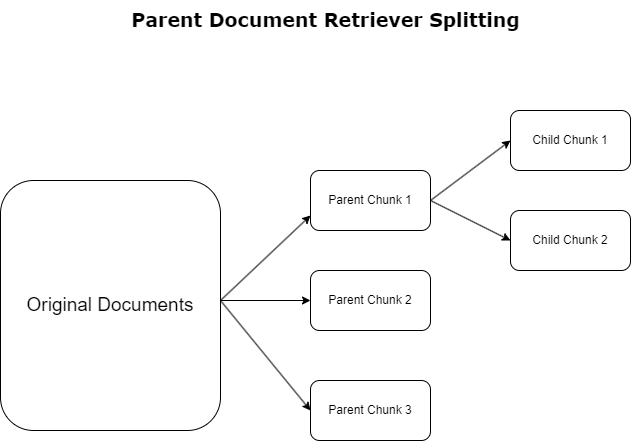
In de vorige sectie hebben we de uitdagingen belicht waarmee RAG-applicaties te maken krijgen bij het omgaan met uitgebreide documenten. Om deze uitdagingen aan te pakken, ophaalprogramma's voor bovenliggende documenten binnenkomende documenten categoriseren en aanwijzen als ouderdocumenten. Deze documenten staan bekend om hun uitgebreide aard, maar worden niet direct in hun oorspronkelijke vorm gebruikt voor insluitingen. In plaats van een volledig document in één enkele inbedding te comprimeren, ontleden de bovenliggende documentretrievers deze bovenliggende documenten in kind documenten. Elk onderliggend document legt verschillende aspecten of onderwerpen uit het bredere bovenliggende document vast. Na de identificatie van deze onderliggende segmenten worden er individuele inbeddingen aan elk segment toegewezen, waarbij hun specifieke thematische essentie wordt vastgelegd (zie het volgende diagram). Tijdens het ophalen wordt het bovenliggende document aangeroepen. Deze techniek biedt gerichte maar brede zoekmogelijkheden, waardoor de LLM een breder perspectief krijgt. Opvragers van bovenliggende documenten bieden LLM's een tweeledig voordeel: de specificiteit van de inbedding van onderliggende documenten voor het nauwkeurig en relevant ophalen van informatie, gekoppeld aan het aanroepen van bovenliggende documenten voor het genereren van antwoorden, wat de output van de LLM verrijkt met een gelaagde en grondige context.
Contextuele compressie
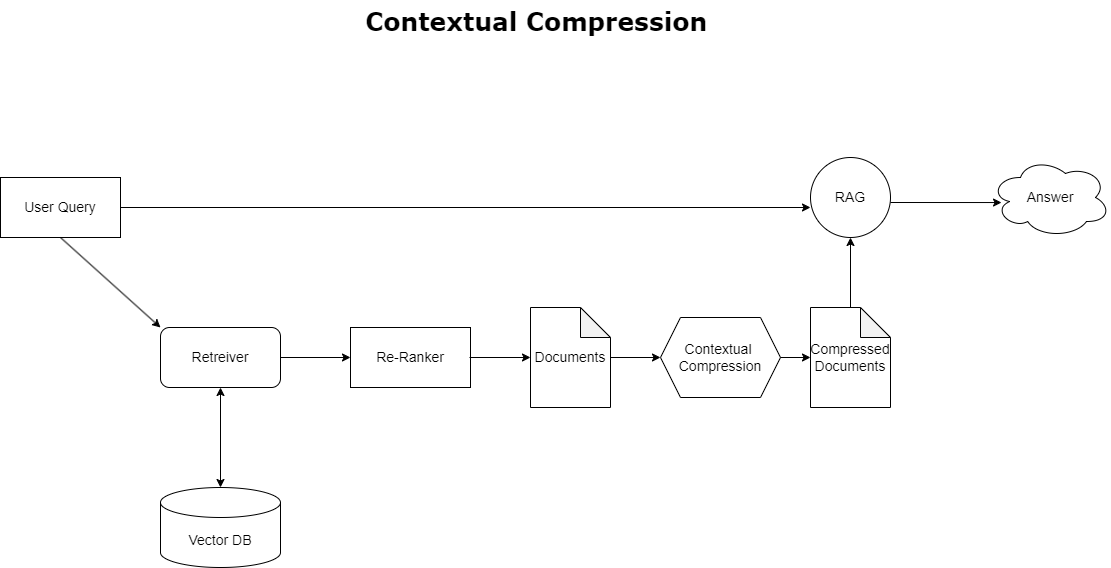
Om het eerder besproken probleem van contextoverloop aan te pakken, kunt u gebruiken contextuele compressie om de opgehaalde documenten te comprimeren en te filteren in overeenstemming met de context van de zoekopdracht, zodat alleen relevante informatie wordt bewaard en verwerkt. Dit wordt bereikt door een combinatie van een basisretriever voor het ophalen van initiële documenten en een documentcompressor voor het verfijnen van deze documenten door de inhoud ervan te beperken of ze volledig uit te sluiten op basis van relevantie, zoals geïllustreerd in het volgende diagram. Deze gestroomlijnde aanpak, mogelijk gemaakt door de contextuele compressie-retriever, verbetert de efficiëntie van RAG-applicaties aanzienlijk door een methode te bieden om alleen datgene te extraheren en te gebruiken dat essentieel is uit een massa aan informatie. Het pakt het probleem van de overdaad aan informatie en irrelevante gegevensverwerking frontaal aan, wat leidt tot een betere responskwaliteit, kosteneffectievere LLM-operaties en een soepeler algemeen ophaalproces. In wezen is het een filter dat de informatie afstemt op de betreffende zoekopdracht, waardoor het een broodnodige tool is voor ontwikkelaars die hun RAG-applicaties willen optimaliseren voor betere prestaties en gebruikerstevredenheid.
Voorwaarden
Als u nieuw bent bij SageMaker, raadpleeg dan de Amazon SageMaker-ontwikkelingsgids.
Voordat u met de oplossing aan de slag gaat, maak een AWS-account aan. Wanneer u een AWS-account aanmaakt, krijgt u een single sign-on (SSO)-identiteit die volledige toegang heeft tot alle AWS-services en -bronnen in het account. Deze identiteit wordt het AWS-account genoemd root gebruiker.
Aanmelden bij de AWS-beheerconsole Als u het e-mailadres en wachtwoord gebruikt dat u hebt gebruikt om het account aan te maken, krijgt u volledige toegang tot alle AWS-bronnen in uw account. We raden u ten zeerste aan de rootgebruiker niet te gebruiken voor alledaagse taken, zelfs niet voor administratieve taken.
Houd u in plaats daarvan aan de best practices voor beveiliging in AWS Identiteits- en toegangsbeheer (Ik ben en maak een administratieve gebruiker en groep aan. Vergrendel vervolgens de inloggegevens van de rootgebruiker veilig en gebruik deze om slechts enkele account- en servicebeheertaken uit te voeren.
Het Mixtral-8x7b-model vereist een ml.g5.48xlarge-instantie. SageMaker JumpStart biedt een vereenvoudigde manier om toegang te krijgen tot meer dan 100 verschillende open source-modellen en basismodellen van derden. Om te lanceer een eindpunt om Mixtral-8x7B te hosten vanuit SageMaker JumpStart, moet u mogelijk een verhoging van het servicequotum aanvragen om toegang te krijgen tot een ml.g5.48xlarge-instantie voor eindpuntgebruik. Jij kan servicequota voor aanvragen worden verhoogd via de console, AWS-opdrachtregelinterface (AWS CLI) of API om toegang tot die extra bronnen mogelijk te maken.
Stel een SageMaker-notebookinstantie in en installeer afhankelijkheden
Om aan de slag te gaan, maakt u een SageMaker-notebookinstantie en installeert u de vereiste afhankelijkheden. Verwijs naar de GitHub repo om een succesvolle installatie te garanderen. Nadat u het notebookexemplaar hebt ingesteld, kunt u het model implementeren.
U kunt de notebook ook lokaal gebruiken in de geïntegreerde ontwikkelomgeving (IDE) van uw voorkeur. Zorg ervoor dat u het Jupyter Notebook Lab hebt geïnstalleerd.
Implementeer het model
Implementeer het Mixtral-8X7B Instruct LLM-model op SageMaker JumpStart:
Implementeer het BGE Large En-inbeddingsmodel op SageMaker JumpStart:
LangChain instellen
Nadat u alle benodigde bibliotheken heeft geïmporteerd en het Mixtral-8x7B-model en het BGE Large En-embeddingsmodel heeft geïmplementeerd, kunt u nu LangChain instellen. Voor stapsgewijze instructies raadpleegt u de GitHub repo.
Data voorbereiding
In dit bericht gebruiken we een aantal jaren aan brieven van Amazon aan aandeelhouders als tekstcorpus waarop we QnA kunnen uitvoeren. Voor meer gedetailleerde stappen om de gegevens voor te bereiden, raadpleegt u de GitHub repo.
Vraag beantwoorden
Zodra de gegevens zijn voorbereid, kunt u de door LangChain geleverde wrapper gebruiken, die zich om de vectoropslag heen wikkelt en invoer voor de LLM opneemt. Deze wrapper voert de volgende stappen uit:
- Neem de invoervraag.
- Maak een vraaginsluiting.
- Haal relevante documenten op.
- Verwerk de documenten en de vraag in een prompt.
- Roep het model aan met de prompt en genereer het antwoord op een leesbare manier.
Nu de vectoropslag aanwezig is, kunt u vragen gaan stellen:
Reguliere retrieverketting
In het voorgaande scenario hebben we de snelle en eenvoudige manier onderzocht om een contextbewust antwoord op uw vraag te krijgen. Laten we nu eens kijken naar een meer aanpasbare optie met behulp van RetrievalQA, waar u kunt aanpassen hoe de opgehaalde documenten aan de prompt moeten worden toegevoegd met behulp van de parameter chain_type. Om te bepalen hoeveel relevante documenten moeten worden opgehaald, kunt u ook de parameter k in de volgende code wijzigen om verschillende uitvoer te zien. In veel scenario's wilt u misschien weten welke brondocumenten de LLM heeft gebruikt om het antwoord te genereren. U kunt die documenten in de uitvoer krijgen met behulp van return_source_documents, waarmee de documenten worden geretourneerd die aan de context van de LLM-prompt zijn toegevoegd. Met RetrievalQA kunt u ook een aangepaste aanwijzingssjabloon opgeven die specifiek kan zijn voor het model.
Laten we een vraag stellen:
Ophaalketen voor bovenliggende documenten
Laten we eens kijken naar een meer geavanceerde RAG-optie met behulp van ParentDocumentRetriever. Wanneer u werkt met het ophalen van documenten, kunt u een afweging tegenkomen tussen het opslaan van kleine delen van een document voor nauwkeurige insluiting en grotere documenten om meer context te behouden. De bovenliggende documentretriever vindt dat evenwicht door kleine stukjes gegevens te splitsen en op te slaan.
We gebruiken een parent_splitter om de originele documenten in grotere stukken te verdelen, de zogenaamde ouderdocumenten, en a child_splitter om kleinere onderliggende documenten te maken van de originele documenten:
De onderliggende documenten worden vervolgens geïndexeerd in een vectorarchief met behulp van inbedding. Dit maakt het efficiënt ophalen van relevante onderliggende documenten mogelijk op basis van gelijkenis. Om relevante informatie op te halen, haalt de bovenliggende documentophaler eerst de onderliggende documenten op uit het vectorarchief. Vervolgens worden de bovenliggende ID's voor die onderliggende documenten opgezocht en worden de overeenkomstige grotere bovenliggende documenten geretourneerd.
Laten we een vraag stellen:
Contextuele compressieketen
Laten we eens kijken naar een andere geavanceerde RAG-optie genaamd contextuele compressie. Een probleem bij het ophalen is dat we meestal niet weten met welke specifieke vragen uw documentopslagsysteem te maken krijgt als u gegevens in het systeem invoert. Dit betekent dat de informatie die het meest relevant is voor een zoekopdracht verborgen kan zijn in een document met veel irrelevante tekst. Als u dat volledige document door uw toepassing stuurt, kan dit leiden tot duurdere LLM-oproepen en slechtere reacties.
De contextuele compressie-retriever pakt de uitdaging aan van het ophalen van relevante informatie uit een documentopslagsysteem, waarbij de relevante gegevens verborgen kunnen zijn in documenten die veel tekst bevatten. Door de opgehaalde documenten te comprimeren en te filteren op basis van de gegeven querycontext, wordt alleen de meest relevante informatie geretourneerd.
Om de contextuele compressie-retriever te gebruiken, hebt u het volgende nodig:
- Een basisretriever – Dit is de initiële retriever die op basis van de zoekopdracht documenten uit het opslagsysteem ophaalt
- Een documentcompressor – Deze component neemt de aanvankelijk opgehaalde documenten en verkort deze door de inhoud van individuele documenten te verkleinen of irrelevante documenten helemaal weg te laten, waarbij de querycontext wordt gebruikt om de relevantie te bepalen
Contextuele compressie toevoegen met een LLM-ketenextractor
Wikkel eerst uw basisretriever in met een ContextualCompressionRetriever. Je voegt een LLMChainExtractor, die de aanvankelijk geretourneerde documenten herhaalt en uit elk document alleen de inhoud haalt die relevant is voor de zoekopdracht.
Initialiseer de keten met behulp van de ContextualCompressionRetriever een LLMChainExtractor en geef de prompt door via de chain_type_kwargs argument.
Laten we een vraag stellen:
Filter documenten met een LLM-ketenfilter
De LLMChainFilter is een iets eenvoudigere maar robuustere compressor die een LLM-keten gebruikt om te beslissen welke van de aanvankelijk opgehaalde documenten moeten worden uitgefilterd en welke moeten worden geretourneerd, zonder de inhoud van het document te manipuleren:
Initialiseer de keten met behulp van de ContextualCompressionRetriever een LLMChainFilter en geef de prompt door via de chain_type_kwargs argument.
Laten we een vraag stellen:
Vergelijk resultaten
In de volgende tabel worden de resultaten van verschillende query's vergeleken op basis van de techniek.
| Techniek | Vraag 1 | Vraag 2 | Vergelijk |
| Hoe is AWS geëvolueerd? | Waarom is Amazon succesvol? | ||
| Regelmatige retrieverketenuitvoer | AWS (Amazon Web Services) evolueerde van een aanvankelijk onrendabele investering naar een bedrijf met een jaarlijkse omzet van $85 miljard met een sterke winstgevendheid, dat een breed scala aan diensten en functies biedt en een belangrijk onderdeel wordt van Amazons portfolio. Ondanks de scepsis en tegenwind op de korte termijn bleef AWS innoveren, nieuwe klanten aantrekken en actieve klanten migreren, met voordelen als flexibiliteit, innovatie, kostenefficiëntie en veiligheid. AWS breidde ook zijn langetermijninvesteringen uit, waaronder chipontwikkeling, om nieuwe mogelijkheden te bieden en te veranderen wat mogelijk is voor zijn klanten. | Amazon is succesvol dankzij zijn voortdurende innovatie en uitbreiding naar nieuwe gebieden, zoals technologische infrastructuurdiensten, digitale leesapparaten, stemgestuurde persoonlijke assistenten en nieuwe bedrijfsmodellen zoals de marktplaats van derden. Het vermogen om activiteiten snel op te schalen, zoals blijkt uit de snelle uitbreiding van de fulfilment- en transportnetwerken, draagt ook bij aan het succes ervan. Bovendien heeft de focus van Amazon op optimalisatie en efficiëntiewinst in zijn processen geresulteerd in productiviteitsverbeteringen en kostenbesparingen. Het voorbeeld van Amazon Business benadrukt het vermogen van het bedrijf om zijn sterke punten op het gebied van e-commerce en logistiek in verschillende sectoren te benutten. | Op basis van de antwoorden van de reguliere retrieverketen merken we dat deze, hoewel deze lange antwoorden geeft, last heeft van contextoverflow en geen significante details uit het corpus vermeldt met betrekking tot het reageren op de gegeven vraag. De reguliere ophaalketen is niet in staat de nuances met diepgang of contextueel inzicht vast te leggen, waardoor mogelijk kritische aspecten van het document worden gemist. |
| Uitvoer van het bovenliggende document | AWS (Amazon Web Services) begon met een slechte eerste lancering van de Elastic Compute Cloud (EC2)-service in 2006, waarbij slechts één instantiegrootte werd geboden, in één datacenter, in één regio van de wereld, met alleen Linux-besturingssysteeminstanties , en zonder veel belangrijke functies zoals monitoring, taakverdeling, automatisch schalen of permanente opslag. Het succes van AWS stelde hen echter in staat om snel de ontbrekende mogelijkheden te herhalen en toe te voegen, en uiteindelijk uit te breiden met verschillende smaken, maten en optimalisaties van rekenkracht, opslag en netwerken, en hun eigen chips (Graviton) te ontwikkelen om de prijs en prestaties verder te verhogen. . Het iteratieve innovatieproces van AWS vereiste aanzienlijke investeringen in financiële en personele middelen gedurende twintig jaar, vaak ruim vóór het moment waarop het zou uitbetalen, om aan de behoeften van klanten te voldoen en de klantervaringen, loyaliteit en rendementen op lange termijn voor aandeelhouders te verbeteren. | Amazon is succesvol vanwege zijn vermogen om voortdurend te innoveren, zich aan te passen aan veranderende marktomstandigheden en te voldoen aan de behoeften van klanten in verschillende marktsegmenten. Dit blijkt duidelijk uit het succes van Amazon Business, dat is uitgegroeid tot een bruto-omzet van ongeveer $35 miljard op jaarbasis door het leveren van keuze, waarde en gemak aan zakelijke klanten. De investeringen van Amazon in e-commerce en logistieke mogelijkheden hebben ook de creatie mogelijk gemaakt van diensten zoals Buy with Prime, waarmee verkopers met direct-to-consumer-websites de conversie van weergaven naar aankopen kunnen stimuleren. | De bovenliggende documentretriever gaat dieper in op de specifieke kenmerken van de groeistrategie van AWS, inclusief het iteratieve proces van het toevoegen van nieuwe functies op basis van feedback van klanten en het gedetailleerde traject van een initiële lancering met weinig functies naar een dominante marktpositie, terwijl het een contextrijk antwoord biedt . De antwoorden bestrijken een breed scala aan aspecten, van technische innovaties en marktstrategie tot organisatorische efficiëntie en klantgerichtheid, en bieden een holistisch beeld van de factoren die bijdragen aan succes, samen met voorbeelden. Dit kan worden toegeschreven aan de gerichte maar brede zoekmogelijkheden van de bovenliggende documentretriever. |
| LLM Chain Extractor: contextuele compressie-uitvoer | AWS is ontstaan door te beginnen als een klein project binnen Amazon, dat aanzienlijke kapitaalinvesteringen vergde en te maken kreeg met scepsis van zowel binnen als buiten het bedrijf. AWS had echter een voorsprong op potentiële concurrenten en geloofde in de waarde die het voor klanten en Amazon kon opleveren. AWS heeft zich voor de lange termijn verbonden om te blijven investeren, wat heeft geresulteerd in de lancering van meer dan 3,300 nieuwe functies en diensten in 2022. AWS heeft de manier waarop klanten hun technologie-infrastructuur beheren getransformeerd en is uitgegroeid tot een runrate-bedrijf met een jaarlijkse omzet van $85 miljard en een sterke winstgevendheid. AWS heeft zijn aanbod ook voortdurend verbeterd, zoals het uitbreiden van EC2 met extra functies en diensten na de eerste lancering. | Op basis van de geboden context kan het succes van Amazon worden toegeschreven aan de strategische expansie van een boekverkoopplatform naar een mondiale marktplaats met een levendig ecosysteem van externe verkopers, vroege investeringen in AWS, innovatie bij de introductie van de Kindle en Alexa, en substantiële groei. in jaarlijkse omzet van 2019 tot 2022. Deze groei leidde tot de uitbreiding van de voetafdruk van het fulfilmentcentrum, de creatie van een last-mile transportnetwerk en de bouw van een nieuw sorteercentrumnetwerk, dat werd geoptimaliseerd voor productiviteit en kostenbesparingen. | De LLM-kettingtrekker handhaaft een evenwicht tussen het uitgebreid behandelen van belangrijke punten en het vermijden van onnodige diepgang. Het past zich dynamisch aan de context van de zoekopdracht aan, zodat de uitvoer direct relevant en uitgebreid is. |
| LLM-ketenfilter: contextuele compressie-uitvoer | AWS (Amazon Web Services) is geëvolueerd door aanvankelijk weinig functies te lanceren, maar snel te itereren op basis van feedback van klanten om de nodige mogelijkheden toe te voegen. Dankzij deze aanpak kon AWS EC2 in 2006 lanceren met beperkte functies en vervolgens voortdurend nieuwe functionaliteiten toevoegen, zoals extra exemplaargroottes, datacenters, regio's, besturingssysteemopties, monitoringtools, taakverdeling, automatisch schalen en permanente opslag. In de loop van de tijd transformeerde AWS van een dienst met gebrekkige functies naar een miljardenbedrijf door zich te concentreren op klantbehoeften, flexibiliteit, innovatie, kostenefficiëntie en beveiliging. AWS heeft nu een jaarlijkse omzet van $85 miljard en biedt elk jaar meer dan 3,300 nieuwe functies en diensten, waarmee een breed scala aan klanten wordt bediend, van start-ups tot multinationals en organisaties in de publieke sector. | Amazon is succesvol dankzij zijn innovatieve bedrijfsmodellen, voortdurende technologische vooruitgang en strategische organisatorische veranderingen. Het bedrijf heeft de traditionele industrieën voortdurend ontwricht door nieuwe ideeën te introduceren, zoals een e-commerceplatform voor verschillende producten en diensten, een marktplaats van derden, cloudinfrastructuurdiensten (AWS), de Kindle-e-reader en de spraakgestuurde persoonlijke assistent Alexa. . Daarnaast heeft Amazon structurele veranderingen doorgevoerd om zijn efficiëntie te verbeteren, zoals het reorganiseren van zijn Amerikaanse fulfilmentnetwerk om de kosten en levertijden te verlagen, wat verder bijdraagt aan het succes. | Net als de LLM-ketenextractor zorgt het LLM-ketenfilter ervoor dat, hoewel de belangrijkste punten worden gedekt, de output efficiënt is voor klanten die op zoek zijn naar beknopte en contextuele antwoorden. |
Bij het vergelijken van deze verschillende technieken kunnen we zien dat in contexten zoals het gedetailleerd beschrijven van de transitie van AWS van een eenvoudige dienst naar een complexe entiteit van meerdere miljarden dollars, of het verklaren van de strategische successen van Amazon, de reguliere retrieverketen de precisie mist die de meer geavanceerde technieken bieden. waardoor minder gerichte informatie ontstaat. Hoewel er zeer weinig verschillen zichtbaar zijn tussen de besproken geavanceerde technieken, zijn ze veel informatiever dan reguliere retrieverketens.
Voor klanten in sectoren zoals de gezondheidszorg, telecommunicatie en financiële dienstverlening die RAG in hun toepassingen willen implementeren, maken de beperkingen van de reguliere retrieverketen bij het bieden van precisie, het vermijden van redundantie en het effectief comprimeren van informatie deze minder geschikt om aan deze behoeften te voldoen. tot de meer geavanceerde technieken voor het ophalen van bovenliggende documenten en contextuele compressie. Deze technieken zijn in staat grote hoeveelheden informatie te destilleren tot de geconcentreerde, impactvolle inzichten die u nodig heeft, terwijl ze de prijs-prestatie helpen verbeteren.
Opruimen
Wanneer u klaar bent met het uitvoeren van het notitieblok, verwijdert u de bronnen die u hebt gemaakt om te voorkomen dat er kosten in rekening worden gebracht voor de bronnen die in gebruik zijn:
Conclusie
In dit bericht hebben we een oplossing gepresenteerd waarmee u de technieken voor het ophalen van bovenliggende documenten en contextuele compressieketen kunt implementeren om het vermogen van LLM's om informatie te verwerken en te genereren te vergroten. We hebben deze geavanceerde RAG-technieken getest met de Mixtral-8x7B Instruct- en BGE Large En-modellen die beschikbaar zijn met SageMaker JumpStart. We hebben ook het gebruik van permanente opslag voor insluitingen en documentfragmenten en de integratie met bedrijfsdatastores onderzocht.
De technieken die we hebben uitgevoerd verfijnen niet alleen de manier waarop LLM-modellen toegang krijgen tot externe kennis en deze integreren, maar verbeteren ook aanzienlijk de kwaliteit, relevantie en efficiëntie van hun output. Door het ophalen uit grote tekstcorpora te combineren met taalgeneratiemogelijkheden, stellen deze geavanceerde RAG-technieken LLM's in staat om meer feitelijke, coherente en contextgeschikte antwoorden te produceren, waardoor hun prestaties bij verschillende natuurlijke taalverwerkingstaken worden verbeterd.
SageMaker JumpStart vormt de kern van deze oplossing. Met SageMaker JumpStart krijgt u toegang tot een uitgebreid assortiment open en gesloten source-modellen, waardoor het proces om aan de slag te gaan met ML wordt gestroomlijnd en snel kan worden geëxperimenteerd en geïmplementeerd. Om aan de slag te gaan met het implementeren van deze oplossing, navigeert u naar het notitieblok in de GitHub repo.
Over de auteurs
 Niithiyn Vijeaswaran is een oplossingsarchitect bij AWS. Zijn aandachtsgebied is generatieve AI en AWS AI Accelerators. Hij heeft een bachelordiploma in computerwetenschappen en bio-informatica. Niithiyn werkt nauw samen met het Generative AI GTM-team om AWS-klanten op meerdere fronten te ondersteunen en hun adoptie van generatieve AI te versnellen. Hij is een fervent fan van de Dallas Mavericks en verzamelt graag sneakers.
Niithiyn Vijeaswaran is een oplossingsarchitect bij AWS. Zijn aandachtsgebied is generatieve AI en AWS AI Accelerators. Hij heeft een bachelordiploma in computerwetenschappen en bio-informatica. Niithiyn werkt nauw samen met het Generative AI GTM-team om AWS-klanten op meerdere fronten te ondersteunen en hun adoptie van generatieve AI te versnellen. Hij is een fervent fan van de Dallas Mavericks en verzamelt graag sneakers.
 Sebastiaan Bustillo is een oplossingsarchitect bij AWS. Hij richt zich op AI/ML-technologieën met een diepgaande passie voor generatieve AI en rekenversnellers. Bij AWS helpt hij klanten bedrijfswaarde te ontsluiten door middel van generatieve AI. Als hij niet aan het werk is, zet hij graag een perfect kopje koffiespecialiteit en ontdekt hij samen met zijn vrouw de wereld.
Sebastiaan Bustillo is een oplossingsarchitect bij AWS. Hij richt zich op AI/ML-technologieën met een diepgaande passie voor generatieve AI en rekenversnellers. Bij AWS helpt hij klanten bedrijfswaarde te ontsluiten door middel van generatieve AI. Als hij niet aan het werk is, zet hij graag een perfect kopje koffiespecialiteit en ontdekt hij samen met zijn vrouw de wereld.
 Armando Díaz is een oplossingsarchitect bij AWS. Hij richt zich op generatieve AI, AI/ML en Data Analytics. Bij AWS helpt Armando klanten bij het integreren van geavanceerde generatieve AI-mogelijkheden in hun systemen, waardoor innovatie en concurrentievoordeel worden bevorderd. Als hij niet aan het werk is, brengt hij graag tijd door met zijn vrouw en gezin, wandelt hij en reist hij de wereld rond.
Armando Díaz is een oplossingsarchitect bij AWS. Hij richt zich op generatieve AI, AI/ML en Data Analytics. Bij AWS helpt Armando klanten bij het integreren van geavanceerde generatieve AI-mogelijkheden in hun systemen, waardoor innovatie en concurrentievoordeel worden bevorderd. Als hij niet aan het werk is, brengt hij graag tijd door met zijn vrouw en gezin, wandelt hij en reist hij de wereld rond.
 Dr. Farooq Sabir is een Senior Artificial Intelligence en Machine Learning Specialist Solutions Architect bij AWS. Hij heeft een doctoraat en een MS-graad in Electrical Engineering van de Universiteit van Texas in Austin en een MS in Computer Science van het Georgia Institute of Technology. Hij heeft meer dan 15 jaar werkervaring en geeft ook graag les en begeleidt studenten. Bij AWS helpt hij klanten bij het formuleren en oplossen van hun zakelijke problemen op het gebied van datawetenschap, machine learning, computervisie, kunstmatige intelligentie, numerieke optimalisatie en aanverwante domeinen. Gevestigd in Dallas, Texas, houden hij en zijn gezin van reizen en lange roadtrips maken.
Dr. Farooq Sabir is een Senior Artificial Intelligence en Machine Learning Specialist Solutions Architect bij AWS. Hij heeft een doctoraat en een MS-graad in Electrical Engineering van de Universiteit van Texas in Austin en een MS in Computer Science van het Georgia Institute of Technology. Hij heeft meer dan 15 jaar werkervaring en geeft ook graag les en begeleidt studenten. Bij AWS helpt hij klanten bij het formuleren en oplossen van hun zakelijke problemen op het gebied van datawetenschap, machine learning, computervisie, kunstmatige intelligentie, numerieke optimalisatie en aanverwante domeinen. Gevestigd in Dallas, Texas, houden hij en zijn gezin van reizen en lange roadtrips maken.
 Marco Punio is een Solutions Architect gericht op generatieve AI-strategie, toegepaste AI-oplossingen en het uitvoeren van onderzoek om klanten te helpen op AWS te hyperschalen. Marco is een digital native cloud-adviseur met ervaring in de FinTech, Healthcare & Life Sciences, Software-as-a-service en meest recentelijk in de telecommunicatie-industrie. Hij is een gekwalificeerde technoloog met een passie voor machine learning, kunstmatige intelligentie en fusies en overnames. Marco is gevestigd in Seattle, WA en houdt in zijn vrije tijd van schrijven, lezen, sporten en het bouwen van applicaties.
Marco Punio is een Solutions Architect gericht op generatieve AI-strategie, toegepaste AI-oplossingen en het uitvoeren van onderzoek om klanten te helpen op AWS te hyperschalen. Marco is een digital native cloud-adviseur met ervaring in de FinTech, Healthcare & Life Sciences, Software-as-a-service en meest recentelijk in de telecommunicatie-industrie. Hij is een gekwalificeerde technoloog met een passie voor machine learning, kunstmatige intelligentie en fusies en overnames. Marco is gevestigd in Seattle, WA en houdt in zijn vrije tijd van schrijven, lezen, sporten en het bouwen van applicaties.
 AJ Dhimine is een oplossingsarchitect bij AWS. Hij is gespecialiseerd in generatieve AI, serverless computing en data-analyse. Hij is een actief lid/mentor in de Machine Learning Technical Field Community en heeft verschillende wetenschappelijke artikelen gepubliceerd over verschillende AI/ML-onderwerpen. Hij werkt met klanten, variërend van start-ups tot ondernemingen, om geweldige generatieve AI-oplossingen te ontwikkelen. Hij is vooral gepassioneerd door het inzetten van grote taalmodellen voor geavanceerde data-analyse en het verkennen van praktische toepassingen die uitdagingen in de echte wereld aanpakken. Buiten het werk houdt AJ van reizen en is momenteel in 53 landen met als doel elk land ter wereld te bezoeken.
AJ Dhimine is een oplossingsarchitect bij AWS. Hij is gespecialiseerd in generatieve AI, serverless computing en data-analyse. Hij is een actief lid/mentor in de Machine Learning Technical Field Community en heeft verschillende wetenschappelijke artikelen gepubliceerd over verschillende AI/ML-onderwerpen. Hij werkt met klanten, variërend van start-ups tot ondernemingen, om geweldige generatieve AI-oplossingen te ontwikkelen. Hij is vooral gepassioneerd door het inzetten van grote taalmodellen voor geavanceerde data-analyse en het verkennen van praktische toepassingen die uitdagingen in de echte wereld aanpakken. Buiten het werk houdt AJ van reizen en is momenteel in 53 landen met als doel elk land ter wereld te bezoeken.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

